基于空间预处理联合稀疏表示高光谱图像分类
2021-08-23陈善学王欣欣
陈善学,王欣欣
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.移动通信教育部工程研究中心,重庆 400065;3.移动通信技术重庆市重点实验室,重庆 400065)
0 引 言
高光谱传感器提供对土地覆盖光谱特征的密集采样,以获取地表物体数十至数百的连续光谱波段信息[1],由于其高分辨率以及丰富的光谱信息,使得高光谱遥感广泛应用于农业、军事、矿物学等诸多领域[2-7]。分类是高光谱遥感影像中的一个非常重要的应用,不同材料的地物在特定波长上反射电磁波的方式不同,因此可以通过光谱特征识别不同的地物,分类是为了给存在于高光谱图像中的像元分配一个确定且唯一的地物类别标识。人们开发了各种高光谱图像分类技术,例如,基于神经网络[8-11]的分类方法、基于人工免疫系统[12]、支持向量机[13](support vector machines,SVM)、多项式逻辑回归[14-15]、稀疏表示[16-19]等新型分类器的分类方法。
近年来,关于稀疏表示在高光谱图像分类中的应用得到了广大学者的青睐。文献[20]将稀疏表示引入高光谱图像分类,一个测试像元可以由训练字典中少量的训练原子表示,利用稀疏性和重建精度约束的优化技术可以获得表征测试像元权值的稀疏向量,最后字典中原子的类别和用于恢复测试像元中原子对应的稀疏向量将直接决定测试像元的类别。文献[21]将核方法引入稀疏表示中,将样本投影到特征空间并核化稀疏表示,提高了各个像元间的可分性,得到的分类结果相较于线性稀疏更接近真实类别。若不考虑空间信息而只是采取光谱信息用于高光谱图像分类,往往会得到较差的分类效果。
为了利用空间信息提高分类性能,文献[22-25]提出了一些结合光谱-空间特征提取的稀疏表示方法。文献[16]提出一种联合稀疏模型用于结合空间信息,高光谱图像中的相邻像元通常拥有相近的光谱特征,极大可能是来自相同类的像元(即相邻像元的平滑性),联合稀疏模型的前提是相邻像元拥有相同的稀疏模式。文献[26]根据正交匹配追踪算法(orthogonal matching pursuit,OMP)和子空间追踪算法(subspace pursuit,SP)提出了联合OMP和联合SP算法求解受稀疏度和重建精度约束的优化问题,得到稀疏表示的稀疏系数和相应的训练原子索引,最后由最小类重建残差得到测试像元的类别标签。文献[27]提出了非局部加权联合稀疏表示分类方法,在联合稀疏模型中,根据测试中心像元和相邻像元的结构相似度决定邻域像元的权值大小。文献[27]中固定窗口的邻域不能真实反映空间信息,同一窗口内的像元可能来自不同类。文献[28]提出了基于形状自适应的联合稀疏表示方法。文献[29]提出了一种通过核函数计算邻域像元与待测像元间的相似度并进行邻域筛选形成自适应窗口,用于构建联合稀疏模型。
上述文献中将待测像元与其邻域像元组成的联合稀疏表示模型在一定程度上同时利用了空间信息和光谱信息进行分析,但是这种逐像元的组合方式使每个像元多次参与分类过程,计算成本高。因此,本文提出了基于空间预处理的联合稀疏表示高光谱图像分类(joint sparse representation of hyperspectral image classfication based on spatial preprocessing,SP-JSRC )方法,利用空间预处理策略将高光谱图像划分为相近大小且相互独立的子块,将包含多个像元的子块用于构造联合稀疏模型,以此极大减少了分类计算成本。考虑子块中每个像元对联合稀疏模型的贡献,对每个像元赋予相应的权重,最后充分利用训练样本的已知信息用于修正分类结果。
1 稀疏表示

(1)
式中:αc是一个Nc维的未知向量,其中的每个元素是相应训练样本在稀疏表示中的权重,αc向量中的元素只有少数非零项,称为稀疏系数。
一个未知的待测像元xn则可以通过字典D的稀疏表示建模为
xn=d1α1+d2α2+…+dCαC=
[d1d2…dC][α1α2…αC]T=Dα
(2)
式中:α是一个N维稀疏向量。理想情况下,如果待测像元xn属于第c类地物,稀疏向量存在αi=0,∀i=1,2,…,C,i≠c。
高光谱图像通常存在较大的均匀区域,同一区域内的相邻像元往往由相同类型的材料组成,因此如果相邻像元拥有近似的光谱特征,极大可能属于同一地物类别。联合稀疏模型在稀疏向量恢复过程中,除了对稀疏性和重建精度的约束外,还利用了高光谱图像相邻像元的空间平滑性。同一邻域内的像元可以由几个训练样本相同的稀疏表示近似组成,但是每个像元的稀疏系数可能不同,即同一邻域内的相邻像元共享同一个稀疏模式。
待测像元x1与其邻域像元组成集合X1=[x1x2,…,xT],通过联合稀疏模型可以将邻域集X1由字典稀疏表示为
X1=[x1x2,…,xT]=
[Dα1Dα2,…,DαT]=DS
(3)
式中:S表示只有少数非零行的N×T维稀疏矩阵。
若知道稀疏系数就可以通过稀疏表示重建待测像元,考虑了经验数据的近似误差,则联合稀疏表示模型中的稀疏矩阵可以通过以下优化问题求解:
(4)

(5)

2 本文提出的方法
联合稀疏表示在分类阶段的优化过程中利用相邻像元的空间信息对待测像元进行平滑约束,改善了高光谱图像的分类效果。逐像元的分类策略在采用联合稀疏表示模型时会对高光谱图像中的每个像元进行邻域选取,一个像元同时位于多个邻域当中便多次参与联合稀疏重构和分类过程。针对这个现象,本文考虑高光谱图像存在大量均匀同质区域,提出基于聚类空间预处理的方式,将空间信息融入联合稀疏表示的重构和分类过程中,同时充分利用训练样本的已知信息修正分类结果,纠正某些错分像元,从而进一步提高分类精度。这种空间预处理策略将高光谱图像划分为相互独立且大小相近的多个子块,将每个子块中包含的多个像元用于构建联合稀疏模型,结合SOMP[22]求解稀疏矩阵从而对子块中的像元进行稀疏重构并分类。本文提出的高光谱图像分类框架如图1所示。

图1 高光谱图像分类框架Fig.1 Classification framework of hyperspectral image
2.1 空间预处理
本文中的空间预处理方案采用结合空间信息和光谱信息的聚类准则[30],自然地平衡了空间信息和光谱信息,该聚类得到的子块同时包含空间相关性和光谱相似性。具体实施步骤如下。
步骤 1通过预置的聚类中心数量初始化聚类中心{Ck},k=1,2,…,K。
步骤 2根据Ck的位置确定搜索邻域的范围,以此降低计算复杂度并可以得到大小相近的聚类子块。

(6)
像元xi与聚类中心Ck之间的空间距离定义为
(7)
结合像元xi与聚类中心Ck间的空间距离和光谱距离用于聚类准则判断,定义为聚类中心Ck与像元xi间的距离:
Di,c=γDspa+(1-γ)Dspa
(8)
式中:γ是平衡空间信息与光谱信息的权重因子。
步骤 3对于每个聚类中心,采用新的的距离准则计算搜索范围内每个像元与Ck的距离并聚类,具体的距离计算方法如式(6)~式(8)所示。
步骤 4在每次迭代后实时更新聚类中心并进行下一次迭代,聚类中心更新如下:
(9)
式中:Gk表示第k个聚类区域;M表示该区域内的像元数量。
满足迭代条件则返回步骤2,否则输出聚类结果。
用于高光谱图像空间预处理的具体实现过程如算法1所示。

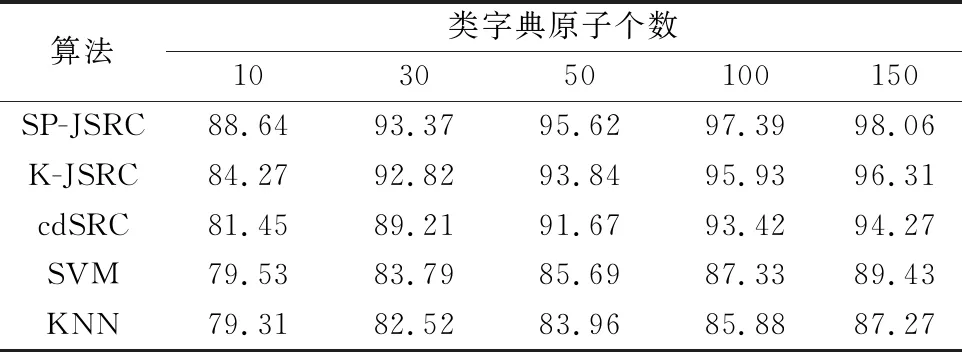
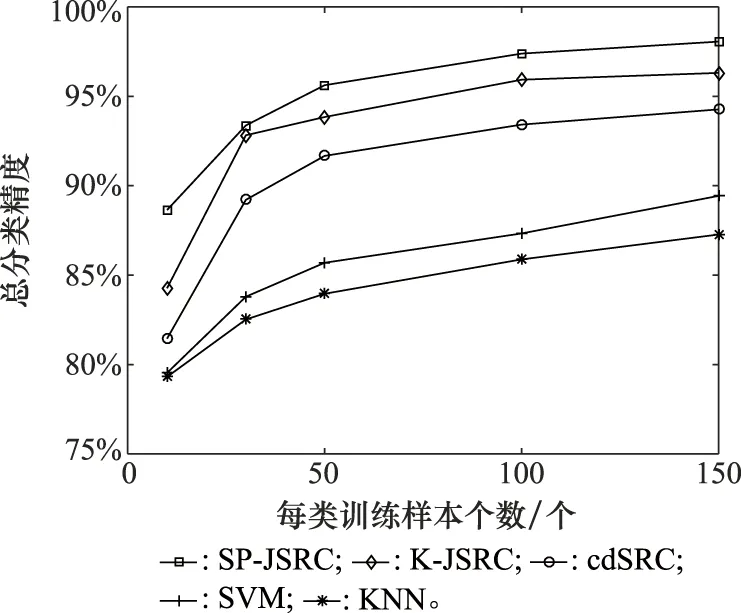
算法1 高光谱图像空间预处理输入:HSI数据集X,聚类数量K,两个像元间的光谱角距离和欧式距离的权重p,空间距离与光谱距离间的权重γ,聚类迭代次数S。初始化:根据K确定初始子块的尺度w×h,更新K,聚类中心{Ck},k=1,2,…K,像元聚类标签label(i)=-1,i=1,2,…,N,像元与聚类中心的距离d(i)=+∞,i=1,2,…,N。Fors=1:S For每个聚类中心Ck1.在聚类中心Ck的2w×2h搜索范围内的每个像元xi 根据公式(8)计算xi与Ck的距离di,k2.若di,k 联合稀疏表示模型中几个相邻像元共享同一个稀疏模式,经过空间预处理将高光谱数据集分成多个子块,每个子块中包含一定数量的像元,利用每个子块构造联合稀疏表示模型,将空间信息融入待测像元的稀疏重构过程中,主要分为以下4个步骤。 步骤 1结合空间预处理得到的聚类子块和原始高光谱数据集生成相应的邻域集。 步骤 2计算邻域集中每个像元与聚类中心的相似度并作为权重赋予每个像元形成新的邻域集,权重计算方法如下: (10) 式中:Ck为第k个子块的聚类中心;gi表示子块中的第i个像元;μs表示光谱标准差。 步骤 3将邻域集用于构建联合稀疏模型,采用SOMP求解稀疏矩阵。 步骤 4根据稀疏重构残差对每个子块进行分类判别。 由于同一子块中像元的光谱特征不是完全一致,所以相邻像元间的相似度大小也不同,两个像元来自于相同地物类别的可能性与像元间的光谱相似度大小呈正相关。在构建联合稀疏模型时应该考虑各个像元的贡献不同,根据子块中像元与相应聚类中心的相似度确定该像元在稀疏表示中的权重,权重的大小可由式(10)计算得到。 基于空间聚类的联合稀疏表示分类方案的具体流程如算法2。 算法2 基于空间聚类的联合稀疏表示分类方案输入:HSI数据集X,由算法1得到的聚类标签labels1,la-bels1相应的聚类中心{Ck},k=1,2,…,K初始化:稀疏度K0、测试样本集Test、训练样本组成字典D=[d1,d2,…,dT]、稀疏像元索引集Λ0=ϕ,迭代记数q=1步骤1 结合labels1和Test生成K个邻域集合G=[G1,G2,…,Gk,…,GK],k=1,2,…,K步骤2 For每个邻域Gk (1) 根据式(10)计算邻域中每个像元与该邻域聚类中心的距离作为像元的相似度因子,从而计算出新的邻域Gk=[w1g1,w2g2,…,wnLgnL],赋予残差R0=Gk (2) 对邻域Gk构建联合稀疏优化模型:^S=argminDS-GkFs.t.Srow,0≤K0 (3) Fork=1:K0 ①根据λq=argmaxRTq-1di2i=1,2,…,T找出最接近所 有残差的原子的索引,加入索引集使其得到 更新Λq=Λq-1∪{λq} ②计算Pq=(DTΛqDΛq)-1DTΛqGk ③计算残差Rq=Gk-DΛqPq,q=q+1 End (4) 根据(3)中的索引集Λq-1得到稀疏矩阵:^S=(DTΛq-1DΛq-1)-1DTΛq-1Gk计算类残差:rc(Gk)=Gk-Dc^ScF,c=1,2,…,C根据class(Gk)=argminc=1,2,…,Crc(Gk)得到分类结果 End输出:高光谱图像分类结果class(Test) 利用训练样本的已知信息修正分类结果,从而得到最终的分类,提高分类精度。首先,根据空间预处理得到的聚类标签labels2获取高光谱图像的多个子块。然后,统计各个子块内训练样本所属类别个数,此时存在3种情况:① 子块内不存在训练样本,则统计子块内像元最多的类别,将子块内所有像元归属于该类别;② 子块内只存在一种类别的训练样本,则将子块内像元判别为该类;③ 子块内存在两种及两种以上类别的训练样本则保持子块内像元原有类别不变。最后,得到修正后的分类结果。修正分类结果的决策融合方案如图2所示。 图2 决策融合方案Fig.2 Decision fusion scheme 本文在数据集Pavia University和AVIRIS Salinas上验证提出的基于空间预处理的联合稀疏表示分类方法的分类效果,并与SVM、邻近算法(k-nearestneighbor,KNN)、类相关稀疏分类(class-depentent sparse representation classifior,cdSRC )[31]、基于核函数的联合稀疏表示分类方法(kemel joint sparse representation classification,K-JSRC )[29]进行仿真对比。本次仿真实验条件如下:处理器为Inter(R)Core(TM)i5-8500、运行内存8 GB、主频3 GHz,仿真平台为MATLAB R2014a。仿真实验主要通过分类性能评价指标总体分类精度(overall accuracy,OA)来表现分类效果。 图3 聚类尺度对分类精度的影响Fig.3 Effect of clustering scale on classification accuracy Pavia University:该数据集是由反射光学系统成像光谱仪(ROSIS)传感器在意大利北部帕维亚大学获得的。包含610×340个像元,将受噪声影响的12个波段筛出,剩下103个光谱波段形成图像用于本次实验。其中包含9类地物,如沥青、草地、柏油屋顶等。 AVIRIS Salinas:该数据集由AVIRIS成像光谱仪于加利福尼亚州萨利纳斯山谷收集,包含512×217个像元。剔除不能被水反射的波段后,将剩余204个波段形成的图像用于本次实验,其中包括16类地物。 在Pavia University数据集的实验仿真过程中,每类选取数量相同的训练样本组成训练字典,用于仿真实验本文提出算法以及对比算法。选取了8种训练样本个数(10,30,50,70,90,110,130,150)分别进行实验仿真。该数据集除去背景像元后包含42 776个像元,用于组成训练字典和测试样本集,其中用于组成稀疏字典的训练样本是从数据集中随机选择的,将剩余未选中的像元作为测试样本集。本次仿真实验数据是10次实验结果的平均值,各个算法在不同字典原子个数情况下的实验结果如表1所示。 表1 Pavia University数据集总分类精度Table 1 Total classification accuracy of Pavia University dataset 为了观察分类结果,使用不同灰度值表示像元所属类别,生成假色图像,当字典原子个数为50时,各个算法的分类结果如图4所示。 图4 Pavia University数据集分类结果Fig.4 Pavia University dataset classification results 图5绘制了多种字典原子个数下各个分类算法的总分类精度折线图,可以直观地看出稀疏字典原子个数对各个分类算法效果的影响和各算法间的对比。从表1可以得到,当组成字典的每类训练样本个数为10时,SP-JSRSC算法的总分类精度分别比K-JSRC、cdSRC、SVM和KNN算法高出1.02%、5.52%、9.22%和10.79%,当训练样本个数增加到30时,SP-JSRC算法的分类精度达到91.27%,比SVM、KNN分别高出10.69%和15.08%,可见该算法对于少量训练样本也能达到较好的分类效果。在类训练样本个数为90时,SP-JSRC算法分类精度比K-JSRC算法高出4.02%,类训练样本个数为150时,SP-JSRC算法分类精度为97.30%,比cdSRC高出7.01%。参与实验的5种算法获得的分类精度均会随着字典原子的个数增加而提高,由图5可以看出,字典中每类原子个数添加到50后,cdSRC算法的OA趋近稳定状态,其他算法的总分类精度还在持续提升。 以选取字典类训练样本个数50为例,从图4可以看出各个对比算法对于光谱相似度高的别类分类效果不佳,而提出的SP-JSRC算法可以充分利用训练样本信息对分类结果进行修正,所以光谱相似度高的类别也能得到很好的区分,并且分类结果更接近真实地物标签。 图5 Pavia University数据集总分类精度Fig.5 Total classification accuracy of Pavia University dataset 在Salinas数据集实验仿真过程中,选取5种不同训练样本个数组成稀疏字典验证提出方法的分类效果,分别为10、30、50、100、150。该数据集除去背景像元后包含54 129个像元,用于组成字典和测试样本集,其中用于组成稀疏字典的训练样本是从数据集中随机选择的,将剩余未选中的像元作为测试样本集。本次仿真实验数据是10次实验结果的平均值,不同字典原子个数下各个算法的实验结果如表2所示。字典每类选取150个原子时,由各个算法的分类结果对应不同灰度值,生成的假色图像如图6所示。图7绘制了多种字典原子个数下各个分类算法的总分类精度的折线图,可以直观地看出稀疏字典原子个数对各个分类算法效果的影响和各算法间的对比。如表3所示,展示了各个分类算法在实验仿真时的运行时间。 表2 Salinas数据集总分类精度Table 2 Salinas dataset total classification accuracy 图6 Salinas数据集分类结果Fig.6 Salinas dataset classification results 图7 Salinas数据集总分类精度Fig.7 Salinas dataset total classification accuracy 表3 各算法分类运行时间Table 3 Classification running time of each algorithm s 由表2可知,在每类选取10个训练样本时,SP-JSRC算法的总分类精度分别比K-JSRC、cdSRC、SVM和KNN算法高出4.37%、7.19%、9.11%和9.33%;当每类训练样本个数为50时,SP-JSRC算法的总分类精度比KNN高出11.66%;每类训练样本个数增加到100时,SP-JSRC算法的总分类精度比SVM高出10.06%。从图7可以看出参与实验的5种算法得到的分类精度随训练样本个数的增加呈上升趋势,SP-JSRC算法的分类曲线呈现稳步增长的趋势,不同训练样本个数下,SP-JSRC算法的分类精度比其他方法均高。从图6中可以看出,其中有两个类别的错误率较高,这是由于这两个类别的光谱相似度较高,容易错分,而SP-JSRC能较好地修正这两个类的分类结果,使得分类效果更接近于真实地物标签,且能够完全正确分类的类别较其他算法多。根据表3可以看到,相较于K-JSRC算法,本文提出SP-JSRC算法采用空间预处理构建联合稀疏表示模型能够减少联合稀疏表示分类的运算量,仿真运行时间大大减少。 从Pavia University、AVIRIS Salinas 两个数据集的实验结果可以看出本文所提出的高光谱图像分类方法能使分类精度显著提高。本文采取空间预处理策略将空间信息融入联合稀疏表示的构建和分类过程,从图4和图6可以观察到SP-JSRC算法得到的分类结果能够极大程度上解决“椒盐现象”,在一定程度上也可以改善光谱相似度高的类别的错分现象。 本文提出的基于空间预处理的联合稀疏表示分类算法充分利用了光谱-空间信息。通过空间预处理结合空间信息构建联合稀疏表示模型,避免了每个像元重复参与联合稀疏表示模型的构建与计算,赋予邻域像元权重提高待测样本被稀疏重构的准确率,最后通过决策融合方式,利用训练样本的已知信息修正联合稀疏表示的分类结果。在Pavia University、AVIRIS Salinas 两个数据集上实验验证本文提出的算法,实验结果表明本文算法分类精度高于K-JSRC算法以及其他几种传统算法。本文的研究工作还有一些改善的空间,例如:空间预处理结果对分类结果影响较大,如何提高预处理的精确度值得被研究,如何优化字典的构建以降低现用随机选择一定数量的训练样本组成字典对分类结果的影响。2.2 结合空间预处理的联合稀疏表示

2.3 修正分类结果

3 实验分析
3.1 参数设置


3.2 实验数据集
3.3 实验结果及分析





4 结 论
