融合原始样本和虚拟样本的人脸识别算法
2016-10-17项晓丽武和雷
项晓丽,武 圣,龙 伟,武和雷
(1.南昌大学 信息工程学院,江西 南昌 330031;2.山东大学 软件学院, 山东 济南 250100)
融合原始样本和虚拟样本的人脸识别算法
项晓丽1,武圣2,龙伟1,武和雷1
(1.南昌大学 信息工程学院,江西 南昌330031;2.山东大学 软件学院, 山东 济南250100)
由于有限的存储容量和捕获图片的时间,实际的人脸识别系统往往只能获得少量的训练样本,但是,在小训练样本情况下大多数人脸识别算法都会遇到困难。因此,为了提高人脸识别的分类正确率,提出了一种融合原始样本和虚拟样本的人脸识别方法。该方法先利用人脸的对称性来构造虚拟训练样本;然后,利用协同表示方法分别对原始训练样本和虚拟训练样本进行分析,并且分别得到每一类训练样本的重建误差;最后,将原始训练样本和虚拟训练样本的同一类重建误差进行加权融合并得到最终的分类结果。大量的实验结果比较分析表明,该方法可以获得更好的识别效果。
人脸识别;小训练样本;协同表示方法;虚拟样本;加权融合;重建误差
人脸识别是模式识别和图像处理中的一项关键技术[1],广泛应用于刑侦破案、视频监控、证件核对、姿态识别等方面[2]。在过去的几十年里,研究者们已经提出了许多人脸识别算法[3]。其中,比较经典的是主成分分析(Principal Component Analysis,PCA)[4]方法和线性鉴别分析(Linear Discriminant Analysis,LDA)[5]方法。这两种方法都是通过投影变换获得原始图像的低维特征,从而达到降维的目的。在获取人脸特征以后,结合分类器即可完成识别分类。目前,应用较广泛的是最近邻分类器(NNC)[6]。最近邻分类器根据离测试样本最近的一个训练样本来进行样本的识别分类,但NNC的分类结果易受噪声或异常样本影响。
2009年,Wright等人将稀疏表示引入人脸识别问题中[7],提出了稀疏表示分类器(Sparse Representation based Classification,SRC),该方法的基本思想是首先将测试样本表示为所有训练样本的一个稀疏的线性组合,这里“稀疏”的意思指:在将测试样本表示为所有训练样本的一个线性组合时,一些训练样本所对应的系数的值为零或接近于零;然后SRC利用范数最小化技巧来获得最稀疏的解;最后,根据每一类训练样本对测试样本的重建误差做出分类决策。实验证明SRC可以获得令人满意的结果,且SRC对光照、噪声、遮挡具有较强的鲁棒性。随后,人们对基于稀疏的人脸识别方法进行了大量研究。尽管SRC可以在人脸识别中取得非常好的分类结果,但人们依然不清楚它的潜在理论基础,因此,相关研究提出基于SRC的人脸识别中协同性比稀疏性更重要,例如,Shi等人提出基于范数的算法可以媲美于基于范数的算法[8];Zhang等人提出了一种协同表示分类器(Collaborative representation based classification,CRC)[9],CRC采用了正则化范数最小化技巧,实验证明CRC与SRC可以获得相当的分类结果,但CRC具有更高的运算效率。
目前,大多数人脸识别算法非常依赖于训练样本,这些算法进行分类识别的前提之一就是假设有足够多的训练样本。如果没有足够多的训练样本,那么这些算法的性能会受到严重影响,甚至无法进行识别。然而,在实际的人脸识别系统中,由于有限的存储容量和捕获图片的时间,往往只能获得少量的训练样本,即实际中的人脸识别更有可能是一个小样本问题[10]。为了获得更好的人脸识别结果,研究人员提出了合成虚拟样本来扩充训练样本集,如Thian等人利用简单的几何变换来构造虚拟样本[11];Tang等人通过在原始训练样本上增加噪声来构造虚拟样本[12];Xu等人利用人脸的对称性来构造虚拟样本[13],这也是第一次在人脸识别中提出对称脸的概念。
为了有效地解决小样本情况下的人脸识别分类问题,本文提出一种融合原始样本和虚拟样本的人脸识别方法(Fusion of Original Sample and Virtual Sample Method,FOSVSM)。该方法先利用人脸的对称性来构造虚拟样本;然后利用协同表示方法分别对原始训练样本和虚拟训练样本进行分析,并且分别得到每一类训练样本的重建误差;最后,将原始训练样本和虚拟训练样本的同一类重建误差进行加权融合并得到最终的分类结果。人脸具有对称结构,不仅面部结构是对称的,而且面部表情也是对称的,因此,根据人脸的对称性所构造的虚拟样本能够反映某些情况下的可能的人脸变化,这也就是说,本文所提的方法能够有效地解决小样本问题。
1 融合原始样本和虚拟样本的方法(FOSVSM)
假设存在L个不同的模式类别,且每一类包含n个训练样本,x1,x2,…,xN代表所有的N个训练样本(N=n×L),若某个训练样本来自第i类,则它的类标签是i。FOSVSM主要包含三个阶段。FOSVSM的第一阶段是构造原始训练样本的左、右对称脸并产生虚拟训练样本集;FOSVSM的第二阶段是利用协同表示方法分别对原始训练样本和虚拟训练样本进行分析,并且分别得到每一类训练样本的重建误差;FOSVSM的第三阶段是将原始训练样本和虚拟训练样本的同一类重建误差进行加权融合并得到最终的分类结果。
1.1构造虚拟训练样本
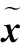
(1)
(2)

1.2协同表示分类器(CRC)
FOSVSM的第二阶段是利用协同表示方法分别对原始训练样本和虚拟训练样本进行分析,并且分别得到每一类训练样本的重建误差。FOSVSM需要利用协同表示方法分别对原始训练样本集和虚拟训练样本集进行分析,但为了方便介绍,这里只描述CRC在原始训练样本集上的分析过程。
根据1.1节内容,训练样本集为X,现在给定某个测试样本y,CRC首先假设存在下面的等式
y=Xα
(3)
然后,CRC利用正则化最小二乘方法对式(3)进行求解,可以得到式(3)的解为α=(XTX+λI)-1XTy。其中,λ是一个很小的正数;I是一个单位矩阵。
在获得系数解α之后,即可求得第i类训练样本对测试样本y的重建误差
(4)
其中,Xi=[x(i-1)×n+1,…,xi×n]表示第i类原始训练样本;αi表示第i类原始训练样本对应的解向量。
同样地,可以按上述过程对虚拟训练样本集进行分析,则将虚拟训练样本集的第i类训练样本对测试样本的重建误差表示如
(5)

1.3加权融合
FOSVSM的第三阶段是将原始训练样本和虚拟训练样本的同一类重建误差进行加权融合并得到最终的分类结果。根据第1.2节的内容可知,原始训练样本和虚拟训练样本的第i类训练样本的重建误差分别为ri和vi,将它们进行加权融合并作为第i类训练样本对测试样本的最终的重建误差,表示为freci,则有
freci=w1ri+w2vi,i=1,2,…,L
(6)
其中,w1和w2表示进行加权融合时的权值,且有w1+w2=1。
最后,根据每一类训练样本对测试样本的最终的重建误差,将测试样本分类给具有最小重建误差的那类,即若frecl=minfreci,则测试样本被分类识别为第l类。
总的来说,FOSVSM方法的主要算法步骤可表示如下:
1)由式(1)和(2)构造原始训练样本的左、右对称脸并组成一个虚拟的训练样本集;
2)根据式(4)和(5)分别计算原始训练样本集和虚拟训练样本集对测试样本的第i类重建误差;
3)将原始训练样本和虚拟训练样本的同一类重建误差进行加权融合,即根据式(6)计算第i类训练样本对测试样本的最终的重建误差;
4)根据每一类训练样本对测试样本的最终的重建误差,将测试样本分类给具有最小重建误差的那类,即若frecl=minfreci,则测试样本被分类识别为第l类。
2 实验结果及分析
为了测试本文算法的性能,利用ORL和AR人脸数据库进行人脸识别实验。ORL数据库总共有400幅人脸图像,分别来自40个人,即每一个人包含10幅图像。这些人脸图像分别是在不同的时期、不同表情(如笑与不笑)和不同细节(如戴眼镜和不戴眼镜)等条件下获取的,图1表示来自于ORL数据库的一些人脸图像及其对应的左、右对称脸。AR数据库包含126个人共4 000多幅彩色图像,其中有70名男性和56名女性。这些人脸图像是分两个批次采集完成的,包含不同的表情、不同的光照和遮挡物。本文选取AR数据库的一部分图像进行实验,包括120个人,每人26幅图像,共3 120幅图像,且所有的图像在实验前均被转化成灰度图像,图2表示来自于AR数据库的一些人脸图像及其对应的左、右对称脸。

图1 来自ORL数据库的一些人脸图像及其对应的左、右对称脸

图2 来自AR数据库的一些人脸图像及其对应的左、右对称脸
2.1ORL数据库实验
对于ORL数据库,本文分别选取每人的前1,2,3幅图像作为训练样本,剩余的图像作为测试样本,因此,训练样本总数分别为40,80,120,相应的测试样本总数分别为360,320,280。在实验前利用下采样方法[14]将所有的图像裁剪为56×46大小。为了验证FOSVSM算法的有效性,本文将FOSVSM算法的实验结果分别与CRC_OR,CRC_VI,SRC等方法的实验结果进行对比,其中,CRC_OR表示协同表示方法在原始训练样本集上进行实验分析;CRC_VI表示协同表示方法在虚拟训练样本集上进行实验分析。对比结果如表1所示。
表1在ORL数据库上的算法的识别率
%

算法每一类的训练样本数123FOSVSM(w2=0.8)69.1783.1287.50FOSVSM(w2=0.7)69.4484.0686.79CRC_OR68.0683.4486.07CRC_VI65.8376.2580.00SRC69.5677.8183.93
从表1可以看出,FOSVSM算法总能获得更高的识别率。例如,当每一类的训练样本数为2时,FOSVSM(w1=0.7)的识别率比CRC_OR,CRC_VI和SRC分别高了0.62%,7.81%和6.25%。比较CRC_OR和SRC的结果可知,CRC_OR能够获得与SRC相当的识别率,甚至更高的识别率,但CRC算法的运算效率更高,这证明FOSVSM算法中利用CRC方法进行实验分析能在一定程度上提高运算效率。从表1可以得知:当每一类的训练样本数由1到3变化时,FOSVSM算法的识别率总是高于CRC_OR的识别率,这说明增加训练样本数确实能够提高分类识别率;同样地,在不同的权值条件下,FOSVSM算法的识别率总是高于CRC_OR和CRC_VI的识别率,这说明FOSVSM算法将原始训练样本和虚拟训练样本的同一类重建误差进行加权融合确实能够提高识别率。
2.2AR数据库实验
对于AR数据库,本文分别选取每人的前13,14,15幅图像作为训练样本,剩余的图像作为测试样本,因此,训练样本总数分别为1 560,1 680,1 800,相应的测试样本总数分别为1 560,1 440,1 320。同样地,在实验前利用下采样方法[14]将所有的图像裁剪为50×40大小。实验结果如表2所示。
从表2可以看出,FOSVSM算法往往能获得更高的识别率。例如,当每一类的训练样本数为13时,FOSVSM(w1=0.7)的识别率比CRC_OR、CRC_VI和SRC
表2在AR数据库上的算法的识别率 %

算法每一类的训练样本数131415FOSVSM(w2=0.8)71.9985.2188.41FOSVSM(w2=0.7)71.6785.0788.11CRC_OR71.0385.1488.18CRC_VI64.1772.8577.42SRC67.6383.2683.18
分别高了0.64%,7.50%和4.40%。从表2可知,CRC_OR的识别率总是高于SRC的识别率,这再次证明了FOSVSM算法中利用CRC方法进行实验分析能在一定程度上提高运算效率。同样地,表2中的结果也再次证明了增加训练样本数且对原始训练样本和虚拟训练样本的同一类重建误差进行加权融合确实能提高人脸识别率。
3 结束语
本文提出了一种融合原始样本和虚拟样本的人脸识别方法,该方法包含三个阶段。第一阶段通过构造原始训练样本的左、右对称脸来产生虚拟训练样本集;从图1和图2可以看出,对称脸确实反映了某些情况下的可能的人脸变化,从表1和表2的结果可知,增加训练样本数确实能提高算法的识别率。第二阶段利用协同表示方法分别对原始训练样本和虚拟训练样本进行分析,并且分别得到每一类训练样本的重建误差;从表1和表2的结果可知,CRC_OR总能获得与SRC相当的识别率,甚至更高的识别率,但CRC算法具有更高的运算效率,这就证明FOSVSM算法能在一定程度上提高运算效率。第三阶段是将原始训练样本和虚拟训练样本的同一类重建误差进行加权融合并得到最终的分类结果;从表1和表2的结果可知,FOSVSM算法将原始训练样本和虚拟训练样本的同一类重建误差进行加权融合确实能够提高识别率。上述实验结果表明,FOSVSM算法能有效地解决小样本问题,且能获得较好的识别结果。
[1]ZHUNB,LIST.Akernel-basedsparserepresentationmethodforfacerecognition[J].Neuralcomput&applic,2014(24):845-852.
[2]朱明旱,李数涛,叶华. 稀疏表示分类中遮挡字典构造方法的改进[J].计算机辅助设计与图形学学报,2014,26(11):2064-2069
[3]周激流,张晔. 人脸识别理论研究进展[J].计算机辅助设计与图形学学报,1998,11(2):180-184.
[4]TURKM,PENTLENDA.Eigenfacesforrecognition[J].Cognitiveneuroscience,1991,3(1):7l-86.
[5]BELHUMEURPN,HESPANHAJP,KRIEGMANDJ.Eigenfacesvs.fisherfaces:recognitionusingclassspecificlinearprojection[J].IEEEtransactionsonpatternanalysis&machineintelligence,1997, 19(7):711-720.
[6]COVERT,HARTP.Nearestneighborpatterclassification[J].IEEEtransactionsoninformationtheory,1967,13(1):21-27.
[7]WRIGHTJ,YANGAY,GANESHA,etal.Robustfacerecognitionviasparserepresentation[J].IEEEtransactionsonpatternanalysis&machineintelligence,2008, 31(2):210-227.
[8]SHIQ,ERIKSSONA,HENGELAVD,etal.IsfacerecognitionreallyaCompressiveSensingproblem?[C]//IEEEConferenceonComputerVision&PatternRecognition. [S.l.]:IEEE,2011:553-560.
[9]ZHANGL,YANGM,FENGX.Sparserepresentationorcollaborativerepresentation:Whichhelpsfacerecognition[C]//Proc.IEEEInt.Conf.Comput.Vision. [S.l.]:IEEE,2011:471-478.
[10]QIAOL,CHENS,TANX.Sparsitypreservingdiscriminantanalysisforsingletrainingimagefacerecognition[J].Patternrecognit.lett.,2010,31 (5) :422-429.
[11]THIANNPH,MARCELS,BENGIOS.Improvingfaceauthenticationusingvirtualsamples[C]//Proc.IEEEInternationalConferenceonAcoustics,Speech,andSignalProcessing. [S.l.]:IEEE,2003:6-10.
[12]TANGDY,ZHUNB,FUY,etal.Anovelsparserepresentationmethodbasedonvirtualsamplesforfacerecognition[J].Neuralcomputing&applications, 2014, 24(3):513-519.
[13]XUY,ZHUX,LIZ,etal.Usingtheoriginaland‘symmetricalface’trainingsamplestoperformrepresentationbasedtwo-stepfacerecognition[J].Patternrecognition,2013,46 (4) :1151-1158.
[14]XUY,JINZ.Down-samplingfaceimagesandlow-resolutionfacerecognition[C]//Proc.InternationalConferenceonInnovativeComputingInformationandControl. [S.l.]:IEEE,2008:392-392.
项晓丽(1988— ),女,硕士生,主研模式识别、图像处理;
武圣(1996— ),本科生,主研模式识别与智能系统、信息安全技术;
龙伟(1952— ),教授,主要研究方向为模式识别与智能系统;
武和雷(1965— ),教授,主要研究方向为模式识别与图像处理、智能机器人。
责任编辑:闫雯雯
Face recognition based on the fusion of original sample and virtual sample
XIANG Xiaoli1,WU Sheng2,LONG Wei1,WU Helei1
(1.SchoolofInformationEngineering,NanchangUniversity,Nanchang330031,China;2.SoftwareCollege,ShandongUniversity,Jinan250100,China)
A real face recognition system often can obtain only a small number of training samples because of the limited storage space and the limited time of capturing images. However, most face recognition algorithms will encounter difficulties in the case of small training samples. Therefore,a new face recognition method based on the fusion of original sample and virtual sample is proposed to improve the classification accuracy of face recognition. First, the proposed method exploit the symmetry of the face to generate virtual samples. Then, it use the collaborative representation method to perform the original and virtual training samples classification, respectively and it will obtain reconstruction error of every class. Finally, it combines the reconstruction error of the same class obtained by the original and virtual training samples to conduct weighted fusion and gets the ultimate classification result. A large number of experimental results show that the proposed method can obtain better recognition effect.
face recognition; small training samples; collaborative representation method; virtual samples; weighted fusion; reconstruction error
TP391
A
10.16280/j.videoe.2016.09.024
国家自然科学基金项目(61261011)
2015-11-21
文献引用格式:项晓丽,武圣,龙伟,等. 融合原始样本和虚拟样本的人脸识别算法[J].电视技术,2016,40(9):117-121.
XIANG X L,WU S,LONG W,et al. Face recognition based on the fusion of original sample and virtual sample[J]. Video engineering,2016,40(9):117-121.
