基于集成学习模型预测重症患者再入重症监护病房的风险
2021-06-22吴静依胡永华孔桂兰1
林 瑜,吴静依,蔺 轲,胡永华,孔桂兰1,△
(1.北京大学健康医疗大数据国家研究院,北京 100191;2.北京大学公共卫生学院流行病与卫生统计系,北京 100191;3.北京大学信息技术高等研究院,杭州 311215;4.北京大学医学信息学中心,北京 100191)
重症监护病房(intensive care unit,ICU)的住院费用是国家医疗卫生预算中最高昂的花费之一,美国的一项研究显示,ICU中的住院花费占据了总体住院费用的13.4%[1]。住院期间,患者再入ICU的比例为4%~10%[2-3],无计划的反复进入ICU的患者往往意味着更高的死亡风险、更长的住院时间和更高昂的花费。再入ICU的患者中,接近40%的患者由于原发基础疾病没有妥善解决导致病情反复而多次进入ICU[4-5]。因此,了解重症患者再入ICU的影响因素,建立重症患者再入ICU的风险预测模型可以了解患者是否有再入ICU的可能性,避免患者过早离开ICU而导致病情反复。
目前已建立的再入ICU预测模型大多基于Logistic回归[6]或使用ICU病情严重度评分[7],预测性能有限。随着机器学习和人工智能技术的发展,在临床研究中使用更全面的方法建立预测模型,与ICU病情严重度评分相比可以得到更好的预测效果。Fialho等[8]使用模糊模型预测患者是否再入ICU,得到受试者工作特征曲线下面积(area under the receiver operating characteristic curve,AUROC)为 0.720,高于ICU常用的急性生理和慢性健康评分(acute physiology and chronic health evaluation,APACHE)的预测效果。Desautels等[9]基于英国Addenbrooke医院的ICU患者数据,使用基于自适应提升算法(adaptive boosting,AdaBoost)的迁移学习预测患者再入ICU风险,模型的AUROC为0.710,高于病情严重度评分,即转运的稳定与负担指数评分(stability and workload index for transfer score,SWIFT)。以往文献中预测重症患者再入ICU模型的区分度较为一般,性能有待提高。
临床风险预测模型的建立往往基于结构化数据,集成学习是对结构化数据拟合效果最好的算法之一,随机森林、AdaBoost和梯度提升决策树(gra-dient boosting decision tree,GBDT)被广泛运用在Kaggle等数据科学竞赛中[10],其中,GBDT具有参数设置简单、针对数据异常值性能亦较为稳健的特性,在临床建模中表现较为突出[11],相对于其他机器学习方法,如神经网络、支持向量机、集成学习算法等,在结构化数据上表现较好,而且可以给出特征的重要性排序,计算花费也低于神经网络和支持向量机。本研究基于随机森林、AdaBoost、GBDT三种集成学习算法,建立重症患者再入ICU的风险预测模型,并将集成学习模型的预测效果与Logistic回归模型进行对比。
1 资料与方法
1.1 资料来源
数据来源于美国重症医学数据库(medical information mart for intensive care,MIMIC)-Ⅲ[12],该数据库包含了2001—2012年Beth Israel Deaconess医疗中心ICU患者的个人数据和临床数据,数据中变量丰富,包含人口学特征、生命体征、实验室检查、手术情况、影像学检查和死亡情况等。
将住院期间进入ICU治疗的患者分成单次进入和重复进入两组,患者排除标准包括:(1)死亡患者,(2)新生儿ICU患者,(3)入住ICU时长小于24 h的患者,(4)年龄小于18或大于90岁的患者。
一次住院中患者有可能多次再入ICU,只选择第一次的再入ICU记录,确保每次住院只有一条记录纳入数据集。本研究筛选出的再入ICU记录为2 053条,未发生再入ICU的记录为33 656条。尽可能纳入较多的预测变量以获得更好的预测效果,所选择的进行预测建模的变量在原始数据集中的缺失率不高于20%。此外,对于单个患者缺失变量较多的情况,排除变量缺失率在30%以上的患者,最终用于建模的再入ICU记录为1 983条,未发生再入ICU的记录为32 179条。选择患者出ICU前最后24 h的记录作为模型的预测变量赋值。
1.2 指标类型
1.2.1个体特征 包括年龄、性别、ICU入住时长、住院类型。
1.2.2生命体征 包括呼吸、心率、收缩压、舒张压、平均动脉压、血氧饱和度、体温、血糖。
1.2.3实验室检查 包括阴离子间隙、碳酸氢盐、肌酐、氯离子、血红蛋白、血细胞比容、血小板、钾离子、钠离子、血尿素氮、白细胞。
1.2.4格拉斯哥昏迷评分(Glasgow coma scale,GCS) 包括GCS总评分、GCS运动、GCS语言、GCS睁眼。
1.2.5合并症 包括Elixhauser合并症评分[13]中的所有合并症:心力衰竭、心律失常、瓣膜疾病、肺循环疾病、周围血管病、高血压、瘫痪、其他神经疾病、慢性肺病、没有合并症的糖尿病、有合并症的糖尿病、甲状腺功能减低、肾衰竭、肝病、溃疡、艾滋病、淋巴瘤、转移癌、未转移肿瘤、类风湿性关节炎、凝血病、肥胖、体质量下降、电解质紊乱、失血性贫血、缺铁性贫血、酒精滥用、药物滥用、精神病、抑郁。所有的合并症均通过MIMIC-Ⅲ数据库中的国际疾病分类(international classification of diseases,ICD)-9诊断编码来提取。
1.2.6其他指标 包括尿量、是否有气管插管等。
本研究纳入的变量同时重叠了APACHE评分[7]和SWIFT评分[14]中大部分指标,因患者的生命体征在24 h内经多次测量,为反映患者生命体征在24 h内的变化情况,生命体征的最大值、最小值也作为预测模型的输入变量入选,本研究总计纳入67个变量。
1.3 数据预处理
MIMIC-Ⅲ作为真实世界的数据库,同样存在数据缺失情况,有相关研究比较了均值填补法和线性插值法处理缺失值的效果,发现线性插值法对数据缺失值的拟合效果更好[15],因此,本研究也根据线性插值法填补缺失值。在ICU住院患者中,发生再入ICU的只占总数据的5.7%,发生再入ICU和未发生再入ICU的数据比例极为不平衡。在未发生再入ICU的样本占绝大多数的情况下,分类器将所有样本预测为多数类样本,也可以得到很高的准确率,但这样的预测就失去了意义。大多数标准的机器学习算法是针对平衡数据设计的算法,过度不平衡的数据会严重影响算法的预测能力。目前解决数据不平衡的方法主要有采样、数据合成和加权等方法,本文采用两种采样方法处理不平衡数据,即随机下采样和NearMiss方法[16]。随机采样是在多数类样本中随机选择一部分样本,使多数类和少数类样本数量平衡。NearMiss方法主要是基于K近邻(K-nearest neighbor)的思想来达到下采样的目的。NearMiss是寻找每个多数类样本最近的3个少数类样本,计算其平均距离,选择平均距离最小的多数类样本组成新的样本子集。本研究将原始数据集分成80%的训练集和20%的测试集,用于评估经过随机下采样方法和NearMiss方法处理后的数据对模型性能的影响。使用预处理后的数据训练预测模型,根据模型在测试集上的准确率来评估不平衡数据处理方法的优劣。从随机下采样和NearMiss方法的准确率可以看出,NearMiss方法可以较大程度地提升分类器的性能(表1)。因此,本研究使用NearMiss方法来处理不平衡数据,再进行建模预测。
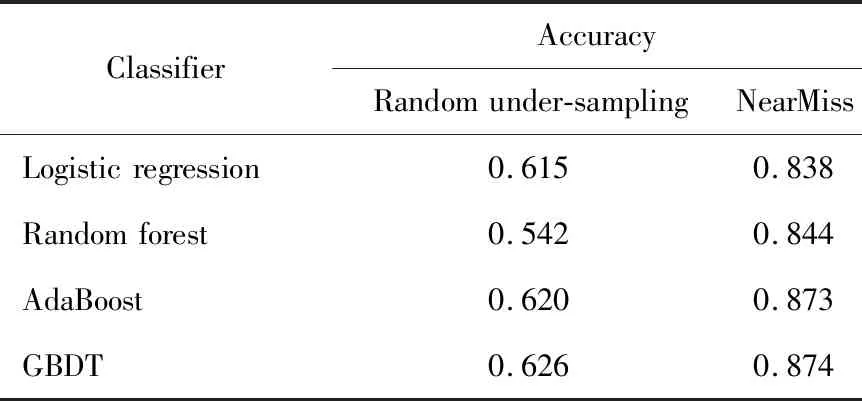
表1 随机下采样和NearMiss方法处理不平衡数据的性能Table 1 Performance comparison between random under-sampling and NearMiss methods
在建模之前,本研究进行了特征选择,使用基于Logistic回归的递归特征消除法寻找最佳的预测变量的组合。递归特征消除结果显示,在特征不断增加的同时,模型的预测性能也在不断上升(图1)。因此,基于Logistic回归的递归特征消除法提示本研究纳入的所有特征均对模型的预测效果有贡献,如果只选取部分特征,可能导致模型预测性能的下降,故本研究纳入所有特征,不对特征进行选择,以确保最佳的预测性能。

RFE,recursive feature elimination;LR,Logistic regression.图1 基于Logistic回归的递归特征消除法Figure 1 Recursive feature elimination based on Logistic regression
1.4 预测模型
Logistic回归中因变量是二分类变量,无需事先假设数据分布,将样本落入某一类的后验概率建模为Logit函数(图2)。使用Logit函数可以将自变量的线性组合转化为0~1之间的预测值,得到发生某一类别事件的概率,并根据概率大小来判定结局的类别,因可解释性强而使用广泛。

图2 Logit函数示意图Figure 2 Logit function
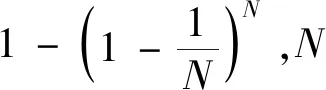
AdaBoost[18]是集成学习提升法(boosting)的代表算法,使用基础分类器单层决策树进行串行训练而获得更强的分类器。每一轮训练,根据当前基础分类器的误差率em(m为迭代次数,m=1,2,…,M)来确定本轮基础分类器权重am,同时更新样本权重,并根据新的样本权重训练下一个基础分类器Gm+1(x),最终AdaBoost的输出是所有基础分类器的加权组合。
首先计算基础分类器在训练集上的分类误差率:
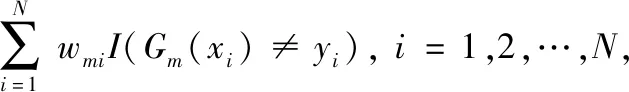
(1)
其中,N为样本总数,wmi是第m轮迭代中第i个样本的权重,I代表结果为0或1的指示函数,在训练第一个基础分类器G1时,为N个训练样本分配相等的权重。分类器的误差率越大,其在最终模型中所占的比重就越小,根据分类器的误差率确定每个分类器的权重am:
(2)
同时,更新训练样本的权重,为分类错误的样本分配更高的权重:

(3)
其中,Zm为规范化因子,计算公式为:
(4)
接下来进行下一个基础分类器Gm+1(x)(m+1≤M)的训练,每次迭代中生成新的基础分类器可以最佳地拟合当前加权样本。AdaBoost的输出是各基础分类器结果的加权组合,公式为:
(5)
对f(x)输出的概率进行判别,得到最终的分类结果。
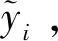
L(y,F(x))=ln(1+exp(-2yF(x))),y∈{-1,1},
(6)
其中,F(x)为:
(7)
GBDT模型的最终目标是找到使损失函数(7)最小的F(x),进而计算样本的预测概率,得到样本分类的结果。建立二分类的GBDT模型,首先根据公式(8)初始化GBDT模型:
(8)
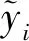

(9)

(10)
获得新的基础分类器的输出后,将CART的输出结果与上一轮模型Fm-1(x)串联后就可以得到GBDT的当前模型Fm(x):
(11)
最终模型预测概率值为:
(12)
1.5 建立模型
使用PostgreSQL在MIMIC-Ⅲ数据库中进行数据筛选,描述研究人群的基本特征,根据数据分布选择卡方检验或秩和检验比较组间差异。基于Logistic回归、随机森林、AdaBoost和GBDT四种方法预测建模,使用五折交叉验证来训练和验证模型的判别能力。基于灵敏度、阳性预测值、阴性预测值、假阳性率、假阴性率、AUROC、Brier评分来评价模型的预测能力,其中,前5项是临床建模较为常用的指标,Brier评分衡量了模型总体概率预测的准确性,AUROC衡量了模型总体判别患者是否再入ICU的区分度。在建立预测模型的同时,利用预测效果最好的模型给出重要性排序前10位的预测变量,变量的全局重要性通过五折交叉验证的重要性均值得到。使用R 3.5.1和Python 3.6软件进行分析。
2 结果
2.1 数据基本情况
本研究纳入ICU住院记录34 162条,其中发生再入ICU的住院记录1 983条,患者在住院期间再入ICU率为5.7%,仅使用无缺失值的数据进行描述性统计分析。与未发生再入ICU的患者相比,发生再入ICU的患者平均年龄更大,ICU住院时间更长,GCS的总分和各项GCS评分更低,因非择期手术而入院的患者比例更高(表2)。

表2 有无再入ICU的重症患者基本情况比较Table 2 The characteristics of critically ill patients with and without ICU readmission
2.2 预测模型性能
基于Logistic回归、随机森林、AdaBoost和GBDT算法建立预测模型,4个模型的五折交叉验证后的结果见表3,其中,GBDT的区分度最好,平均AUROC达到0.858,AdaBoost (AUROC=0.851)的区分度略差于GBDT,随机森林(AUROC=0.827)的预测效果第三,Logistic回归(AUROC=0.810)的预测效果最差。

表3 Logistic回归、随机森林、AdaBoost和GBDT模型预测再入ICU的性能Table 3 The prediction performance of Logistic regression,random forest,AdaBoost,and GBDT

a,b,c,d,represent the threshold of feature value in node splitting.图3 决策树示意图Figure 3 Decision tree
从预测模型的灵敏度、阳性预测值、阴性预测值、假阳性率、假阴性率和Brier评分的结果可以看出,GBDT的灵敏度略差于AdaBoost,阴性预测值与AdaBoost相当,阳性预测值、假阳性率、假阴性率和Brier评分的表现都是4个模型中最好的。在集成学习模型的总体预测效果中,GBDT的预测效果优于随机森林,略好于AdaBoost。对比集成学习和Logistic回归的预测效果,集成学习算法与Logistic回归相比均有较大的提升,能够提供更为精确的再入ICU风险预测。
再入ICU的预测模型中,预测性能最佳的GBDT算法给出的预测变量的重要性排序见表4,排序靠前的变量为血小板、血糖、尿量、血压、心率和血肌酐等,以实验室检查和生命体征变量为主。由表4可见,心血管功能方面,发生再入ICU患者的平均动脉压、收缩压、舒张压和心率比未发生再入ICU的患者更高;肾功能方面,再入ICU的患者尿量更少、血肌酐更高。总体来说,再入ICU的患者心血管功能和肾功能比未发生再入ICU的患者更差。

表4 基于GBDT模型重要性排序前10位的变量及分布Table 4 Top 10 variables identified by feature importance based on GBDT model and their distributions
3 讨论
本研究使用美国MIMIC-Ⅲ数据库,基于集成学习算法建立重症患者再入ICU的风险预测模型,其中,GBDT算法预测效果最好,平均AUROC达到0.858,高于随机森林(AUROC=0.827)、AdaBoost (AUROC=0.851)和Logistic回归(AUROC=0.810)。
集成学习算法是目前对结构化数据拟合效果最好的算法之一,本研究主要基于集成学习算法建立患者再入ICU的风险预测模型,对比了多种模型的预测效果,与生物医学领域运用广泛的Logistic回归相比,集成学习模型具有更好的预测性能。与已报道的再入ICU风险预测模型相比,本研究中预测模型的区分度更高,能够更好地预测患者再入ICU风险。早期识别高风险的患者,有助于临床医生进行更好的医疗决策。
本研究采用了两种数据平衡算法进行数据预处理,与随机下采样相比,NearMiss方法较好地提升了模型的性能。随机下采样在处理样本的过程中,丢失了大量多数类样本的信息,存在样本代表性不足的问题。NearMiss方法通过K近邻算法,选择了离少数类样本距离最近的多数类样本,较好地保留了原始样本的决策边界[20],因此比随机下采样的样本代表性更好,对模型的提升更为显著。
医学领域预测患者再入ICU的研究中,一般采用ICU中常用的疾病严重程度评分(如APACHE评分和SWIFT评分)来评估患者再入ICU的风险[7,14]。APACHE的评分项目中包含了生命体征和实验室检查等生理指标,年龄、入院类型等个体特征,GCS评分,肝脏、心血管、肺部疾病等合并症;SWIFT评分包括患者入院类型,ICU住院时长,还有部分生理指标(PaCO2和FiO2)。本研究纳入的变量同时重叠了APACHE评分和SWIFT评分中的大部分指标,尽可能全面地反映患者疾病的严重程度。GBDT的再入ICU风险预测模型中,重要性排序靠前的变量包括了血小板、血糖、尿量、血压、心率和血肌酐,实验室检查和生命体征的相关变量排序靠前。Fialho等[8]基于MIMIC-Ⅱ数据中的生理学指标预测患者再入ICU风险,选出了最具有预测作用的6个变量,分别为心率、体温、血小板、血压、氧分压和乳酸。患者在ICU出院前24 h的血小板、血压和心率在不同研究中都具有较强的预测作用,表明在临床工作中可以对ICU患者的这些指标进行常规监测,及时发现并干预指标表现较差的患者。Fialho等[8]的预测模型包含的变量只有实验室检查和生命体征指标,本研究纳入了更为丰富的预测变量,涵盖了人口统计学指标、合并症、GCS评分、实验室检查和生命体征等多个维度的信息,更能全面反映患者疾病的状况,且MIMIC-Ⅲ数据库记录有横跨10年的患者样本,相对而言提升了本文模型的代表性。
本研究也存在一定的不足之处,集成学习模型虽然预测效果更好,但对变量特征的解释性不强,Logistic回归尽管有较好的可解释性,然而模型性能表现不佳。未来研究应注重于开发预测能力高、可解释性好的模型,在提供临床决策支持方面更易于医生理解和接受。
总体而言,基于集成学习算法的再入ICU风险预测模型能够较好地辅助医生识别再入ICU风险高的患者,对这部分患者采取干预措施,可以预防可能发生的再入ICU,提高ICU救治的医疗质量,改善患者的预后,同时也节省了大量的医保费用。
