基于国际疾病分类的心血管疾病亚型的基因组学研究
2021-06-22郭子宁梁志生
郭子宁,梁志生,周 仪,张 娜,黄 捷
(北京大学公共卫生学院全球卫生学系,北京 100191)
心血管疾病(cardiovascular disease,CVD)是一组心脏和血管疾病的统称[1]。CVD是全球第一大死亡原因,2017年全球有将近两千万人死于CVD,这个数字远高于肆虐全球的新冠肺炎[2]。全球范围内,大约80%的CVD死亡发生在中低收入国家,因此CVD研究对我国的全球卫生与健康战略具有十分重要的意义[3]。
最近十余年,基因芯片的大量应用和基因数据的大量采集催生了全基因组关联研究(genome-wide association study,GWAS)[4],将传统流行病学带入了系统流行病学时代。GWAS方法不需要事先假设某个基因跟某个疾病有相关性,而是通过综合分析基于人群大队列的表型数据和基于高密度生物芯片检测出来的基因型数据来快速筛选潜在致病性的单核苷酸变异位点(single nucleotide variation,SNV)。早期的芯片主要检测次要等位基因频率(minor allele frequency,MAF)高于1%的SNV,这样的SNV也称为单核苷酸多态(single nucleotide polymorphism,SNP)。
由于CVD是全球第一大死亡原因,最近十多年来GWAS的研究很多,也发现了很多CVD相关的易感基因位点,并且对疾病的预测和预防产生了积极的影响[5]。但是传统的方法主要聚焦于临床的定义,一些听起来似乎比较简单的某种CVD(如冠心病或心肌梗死),可能有着非常复杂的临床和病生理标准。而本研究从公共卫生的角度出发,完全基于世界卫生组织(World Health Organization,WHO)颁布的国际疾病分类标准(International Classification of Diseases,ICD)对心血管疾病进行分类。目前常用的是第10次修订版本(ICD-10),该版本于1990年修订完成[6]。虽然从临床和卫生经济学的角度来说很有必要把疾病分门别类,但是ICD的分类标准是否有足够的分子生物学依据,这一点尚不很清楚。因此,本研究从分子生物学的角度特别是从基因组学的层面来探索同一疾病大类(如CVD)之下的疾病亚型之间的异同,通过甄别不同疾病亚型的基因学特点来更好地诠释基于临床的ICD分类。
1 资料与方法
1.1 研究对象
本研究以英国生物样本库(UK Biobank,UKB)人群为研究对象[7]。UKB于2006—2010年招募了50多万名当时年龄在40~69岁的志愿者。在基因数据方面,UKB所采用的基因芯片包含约80万个SNV,直接测定的这些数据通过基因数据“填补”(imputation)的方法得到大约9 600万个SNV[7]。英国生物库项目获得了英国国家研究伦理委员会North West-Haydock的批准(REC reference:11/NW/0382),获得了全部参与者的电子签名知情同意书。本研究所使用的UKB数据经过严格的申请和审批程序获得,不涉及任何生物样本的存储、转运和实验操作。
本研究排除了非白色人种族的样本,以及具有三代之内血缘关系的样本,研究的对照组是不具有任何CVD-10亚型的样本(不具有ICD-10代码或者ICD-10代码不以“I”字母开头),UKB的CVD患者根据ICD-10分类共分为10个亚型。本研究排除了样本量非常少的两个亚型和没有明确归类的两个亚型。为了提高CVD亚型患者的“纯净度”,本研究排除了那些被同时诊断为多个亚型的患者。鉴于CVD患者中具有高血压疾病亚型ICD-10代码的人数高达62.5%,本研究在定义CVD亚型的时候不排除高血压疾病,也就是说,当一个患者同时具有而且只有亚型X和高血压疾病的时候,该患者仍然被分类到亚型X,而不是被排除掉。按照这种分类方法,本研究分析的亚型有5个,不单独研究高血压亚型。这5个CVD亚型分别为(1)缺血性心脏病(ischaemic heart diseases,IHD),(2)肺源性心脏病和肺循环疾病(pulmonary heart disease and diseases of pulmonary circulation,PHD),(3)脑血管疾病(cerebrovascular diseases,CRB),(4)动脉、小动脉和毛细血管疾病(diseases of arteries,arterioles and capil-laries,AAC),(5)静脉、淋巴管和淋巴结疾病,不可归类在他处者(diseases of veins,lymphatic vessels and lymph nodes,not elsewhere classified,VLL)。
1.2 统计分析
本研究使用R软件从UKB数据库中提取出所有样本的ICD-10代码,以及样本的年龄、性别、吸烟情况(1=既往或当前吸烟,0=从不吸烟)、饮酒情况(1=既往或当前饮酒,0=从不饮酒)等基本特征表型指标。分类变量通过R软件做卡方检验计算。连续变量进行数据分布的正态性检验,如果符合正态分布,则进行t检验;如果不符合,则进行秩和检验。
根据UKB官方发布的流程下载经过填充后的基因数据,并根据以下3个标准排除符合其中任何一个标准的SNV:(1)基因填充的准确率<0.4;(2)哈迪-温伯格平衡(Hardy-Weinberg equilibrium,HWE)P<1×10-10;(3)最小等位基因频率 <1×10-4。经过上述筛选后得到大约2 100万个SNV,供本研究分析使用。
GWAS分析使用PLINK软件中的glm功能进行Logistic回归[8]。每一个疾病的亚型(0或1或NA)是因变量,每一个基因变异的值(0到2)是自变量,而年龄、性别、基因主成分(principal components,PC)作为混淆因素加以控制。使用国际上通用的P≤5×10-8作为标准衡量基因型是否与疾病亚型有统计显著性关联,并使用Locuszoom软件对每个GWAS得出的显著性位点进行描述[9]。
通过GWAS分析得到的与表型相关的SNV位点并不一定真实客观地描述遗传因素对表型的效应。除了真正的基因效应,还有群落分层和样本间隐藏的亲缘关系等混淆因素。尽管GWAS分析可以通过控制协变量来校正群落分层等因素,但仍然无法消除其他混淆因素。本研究采用了国际上通用的连锁不平衡得分回归(linkage disequilibrium score regression,LDSC)方法来计算混淆因素的占比。对于多个表型,LDSC可以根据对应的卡方统计量来计算表型间的遗传相似度[10]。无论是表型相关性还是基因相关性,都不代表因果关联。本研究采用基于汇总数据的广义孟德尔随机化法(generalized summary data-based Mendelian randomization,GSMR)来研究表型之间的因果关联。与传统的孟德尔随机化(Mendelian randomization,MR)方法相比,GSMR提供工具变量异质性检验的方法(heterogeneity in dependent instrument,HEIDI)来识别基因多效性,并将存在多效性的工具变量筛选出来后剔除[11]。
2 结果
2.1 五大CVD亚型的ICD-10分类特征
本研究的总样本量为380 083人,对照组为246 437人。跟对照组相比,五大亚型组的年龄显著偏高,P均<0.05,五大亚型组的性别比例与对照组有明显差距,P值<0.05(表1)。除了VLL组中女性比例高于对照组外,其他四大亚型组均为男性比例显著偏高。五大亚型组与对照组的体重指数(body mass index,BMI)也有显著差异,亚型组的BMI均高于对照组。所有亚型组和对照组相比,吸烟人数都显著偏高,而只有两个亚型组的饮酒量(PHD亚型、AAC亚型)与对照组相比差异有统计学意义。
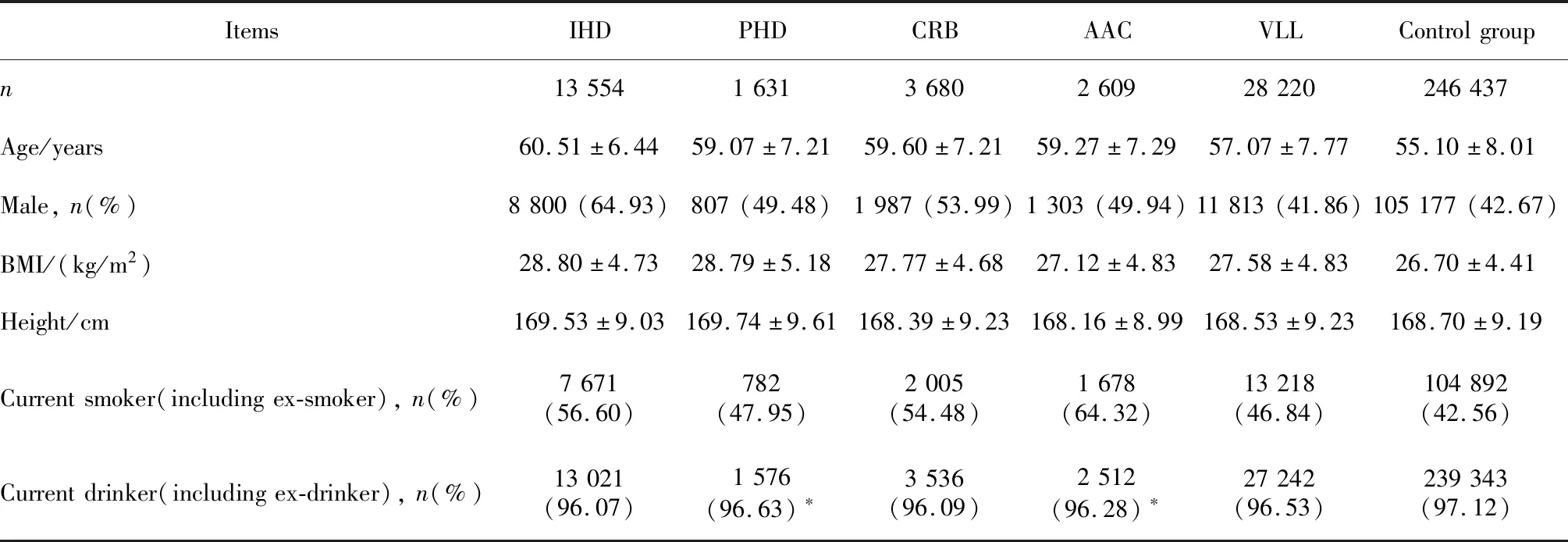
表1 CVD五大亚型组和对照组的基本特征Table 1 Characteristics of participants in five cardiovascular diseases (CVD) subtypes and in control group
2.2 全基因组关联分析
五个GWAS的曼哈顿图(图1)纵坐标表示每个SNP的-lgP值,横坐标表示SNP在染色体上的位置,红色的断续横线表示GWAS通用的显著性阈值P=5×10-8。与五大CVD亚型相关联的显著性基因位点见表2。

IHD,ischaemic heart diseases;PHD,pulmonary heart disease and diseases of pulmonary circulation;CRB,cerebrovascular diseases;AAC,diseases of arteries,arterioles and capillaries;VLL,diseases of veins,lymphatic vessels and lymph nodes,not elsewhere classified.图1 五大亚型GWAS的曼哈顿图Figure 1 Manhattan plots of five CVD subtypes
通过PLINK的聚集功能识别GWAS中相互独立的基因座。显著基因座(或统称“区域”)的定义是基因组上100万个碱基对区间(1Mb)其中有至少一个SNP的P≤5×10-8。表2的第1列为所有统计显著性的基因位点数量,第2列为相互独立的基因座数量。通过文献检索,本研究报道了28个新的基因座(表2第3列和表3),其中8个是罕见变异(MAF≤1%)。新发现的定义是本研究中发现的显著性SNP的1Mb范围内未见已经公开发表过的相关信号。

表2 与五大CVD亚型相关联的显著性基因位点Table 2 Significant loci associated with CVD subtypes
既往的GWAS经常忽略对X染色体的分析,因此本研究所发现的一个与CRB显著相关的X染色体基因区域值得关注。如图2所示,该区域最显著的SNV的位置为ChrX:63179140(基于GRCh37版本),没有rsID,表明此前对该SNV鲜有研究。虽然该SNV的P值仅为2.79×10-8,但由于MAF很低,在CRB病例组和对照组的频率相差很大(分别为0.2%和0.04%)。离该SNV最近的上下游基因分别为ARHGEF9和AMER1,其中AMER1基因的缺陷是导致头颅硬化的纹状体骨病变的原因[12]。此前文献报道过的该区域相关表型包括Wilms肿瘤和胃癌[13],但是未见与CVD相关联的报道。
2.3 五大亚型之间的基因水平关联强度分析
根据LDSC方法计算得到五大亚型的基因相关性(表4),五个亚型之间共进行了10次的两两比较,因此统计显著性P值设定为小于5.00×10-3,即0.05/10。根据这一阈值,表4前3个组合,IHD和VLL(P=2.52×10-7)、IHD和PHD(P=3.77×10-3)、IHD和AAC(P=4.90×10-3)之间具有显著的基因相关性,其中IHD和VLL之间的基因相关性的统计显著性最强,而IHD和AAC之间的基因相关性的相关系数最高(Rg=0.74)。
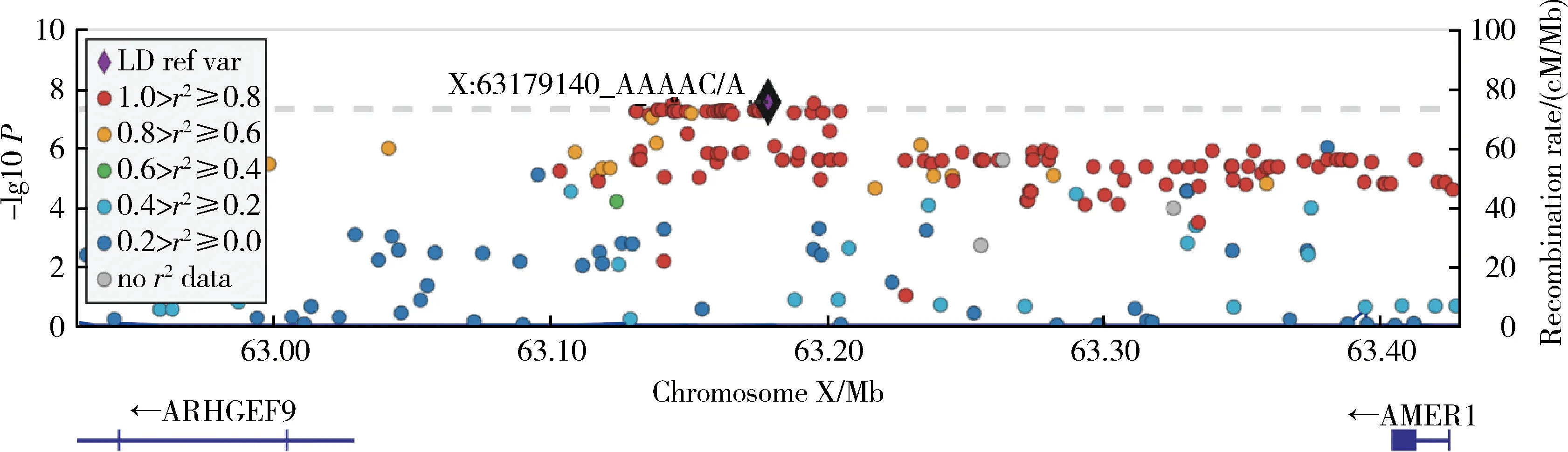
LD ref var,linkage disequilibrium reference variant.图2 与CRB相关的X染色体区域LocusZoom图Figure 2 LocusZoom plot of the chromosome X locus associated with CRB

表4 CVD五个亚型相互之间的基因相关性Table 4 Genetic correlations among five CVD subtypes
2.4 五大亚型之间的因果关系分析
根据GSMR方法计算得到的五大亚型之间的因果关联性结果(表5),上述的LDSC方法对每一对亚型的组合只需要分析一次,而GSMR需要对每一对亚型的组合分析两次,即正向因果关系和反向因果关系,因此,一共有20次计算,相应的将统计显著性阈值设定为P=2.50×10-3(即0.05/20)。根据该标准,表5前面4组亚型具有正向因果相关。有因果性的四对中,反向因果关系皆不成立,与上述的LDSC分析结果相吻合的是统计显著性最强的亚型组合是IHD和VLL。

表5 五个亚型相互之间的孟德尔随机化因果关系Table 5 Mendelian randomization based causal effects among CVD subtypes
3 讨论
我国CVD患病率持续上升,目前患病人数超过3亿,位居城乡居民总死亡原因首位,成为我国的重要疾病负担,因此防治CVD刻不容缓。国际权威的心血管队列研究——弗雷明翰研究(Framingham heart study,FHS) 表明,当双亲有一方有早发心血管疾病史,子女比无家族史个体患CVD的风险显著增加[14]。因此,深入系统地研究CVD的基因易感性非常必要。
本研究使用英国样本库50万人大型队列数据,根据ICD-10对CVD疾病亚型的分型,对IHD、PHD、CRB、AAC、VLL 5种常见CVD亚型进行了系统的研究。从表型的定义,到5个GWAS的分析,到采用国际上通用的统计学方法和软件(LDSC、GSMR),本研究具有一定的广度和深度。本研究围绕的关键问题是为世界卫生组织发布的ICD标准提供系统分子生物学依据。本研究新发现了多个基因位点,并做了进一步的基因相关性和因果性分析。
本研究采用了完全基于ICD代码的CVD亚型分类方法,目的是从分子生物学的角度为完全基于临床特征的ICD分类方法提供分子生物学依据。本研究的数据来自国际权威的大队列UKB,表型和基因型数据经过国际专业团队的提炼和质控,所采用的软件也是国际通用的,因此本研究所得出的结果可以被完全重复。
但是本研究仍存在一定局限性:(1)由于数据来源的限制,目前只研究了白种人的数据;(2)同样由于数据的限制,GWAS的结果没有进行验证;(3)虽然UKB队列的总体样本数很大,但是本研究包括的五大亚型的病例组样本数量相对很有限,因此GWAS得到的位点也很少,这在一定程度上会影响到后续的基因关联度和因果分析的准确性。
综上所述,本研究针对全球健康领域一个重要的问题,通过具有深度(GWAS、LDSC、GSMR)和广度(大队列的基因组数据和ICD-10 的临床数据)的系统分析,得到了一些新的发现,并为后续的类似研究提供了参考。期待将来有更多的研究来验证本研究新发现的基因位点,有更深层次的蛋白质组学和代谢组学研究来丰富ICD-10的研究,从而为国际通用的ICD-10以及即将到来的ICD-11提供更多的分子生物学依据。
