氧化石墨烯指数富集法筛选食品中的组胺适配体
2021-03-06朱勤超冯俊丽戴志远
朱勤超,冯俊丽,2*,戴志远,2,汪 艺
(1 浙江工商大学海洋食品研究院 杭州310012 2 浙江省水产品加工技术研究联合重点实验室 杭州310012)
组胺(histamine,HA)是在许多食物(例如葡萄酒、奶酪、蔬菜和鱼类等)中以各种水平存在的一种生物胺(biogenic amine,BA)。大部分由生物胺造成的食源性中毒事件都与组胺有一定联系[1]。低浓度组胺参与重要神经生理功能的调节,如机体运动、体温控制、胆固醇及胆汁酸代谢和免疫反应[2]。然而,食品和饮料中高浓度的组胺对人体具有毒性作用,会引起腹泻、恶心、呕吐、心悸、头疼、心肌缺血和急性肺水肿等症状[3]。在食品加工和储存期间,组胺通常由微生物对环境中游离的组氨酸进行脱羧反应而产生。反应中涉及的外源组氨酸脱羧酶由相关的微生物释放。这些微生物有些存在于活鱼的正常微生物菌群(主要是肠道细菌)中,然而大多数似乎来自渔船上、加工厂和运输系统的污染[4]。除了卫生条件外,食品加工方法的其它因素,如其储存温度和时间对组胺生成也有一定影响。
值得注意的是,食物中的组胺一旦形成通常不会被高温破坏[5]。食品中组胺的存在及含量非常重要,它通常作为食品变质的一个指标,也是食品生产加工、运输和储存过程中质量控制、监测的生物标志物之一[6]。
据文献报道,目前鉴定、定量组胺的分析方法有:毛细管电泳技术[7-9]、气相色谱[10-11]、薄层色谱[12]、高效液相色谱[13]、比色法和荧光法[14]等。这些方法成本高,耗时且需要复杂的设备,亟待构建一种操作简便、成本低廉、速度快、灵敏度高的组胺检测方法。
适配体是由寡核苷酸随机文库通过指数富集筛选而获得。适配体的体外选择过程涉及特异结合,分离和扩增[15-16]。适配体可以靶向多种分子结构,如金属离子、生物毒素、蛋白质、细菌和病毒等[17-19]。适配体折叠成不同的二级结构或三级结构,进而具有与抗体相当的亲和性和特异性,可识别相应目标物质[20]。此外,与抗体相比,适配体具有以下几个优点[21-23]:快速可重复的合成,简单可控的精确修饰,以满足不同分析、临床诊断和治疗。其稳定性好且可逆变性,至今未发现免疫原性,具有较长的保质期。作为抗体替代物,新出现的适配体成为检测特定靶标的理想识别元件,得到国内外科研人员的广泛研究[24]。
近年来,筛选用于分子质量较小的靶标检测的适配体方法主要包括磁珠法[25]、亲和柱层析法[26]和氧化石墨烯法[27]等。本试验中采用氧化石墨烯法作为ssDNA 筛选分离的指数富集方法,不需要改变组胺的化学结构,不需要活化组胺并将其固定于载体上,只需将氧化石墨烯加入反应体系中吸附去除未与组胺结合的游离ssDNA,从而实现对食品中组胺适配体的筛选[28]。
1 材料与方法
1.1 材料与试剂
组胺、氧化石墨烯(Graphene Oxide,GO)、L-组氨酸盐酸盐、血清素、5-羟色胺,上海生工生物技术有限公司;高保真PCR 酶、50 bp DNA 标准品、琼脂糖,大连宝生物工程(Takara)有限公司;其它试剂为国产分析纯级。
1.2 随机文库构建和引物合成
建立长度为81nt 的单链DNA 随机文库:5′AGT ATA CGT ATT ACC TGC AGC(N 40)CGA TAT CTC GGA GAT CTT GC 3′,两端为固定序列,中间N40 为含40 个碱基的随机序列。随机ssDNA 文库和引物均由上海生工生物工程有限公司合成。用TE 缓冲液配成浓度2 nmol/L 贮液,于-20 ℃保存备用。
1.3 聚合酶链式反应(PCR)与琼脂糖凝胶电泳
利用PCR 将每轮筛选获得的ssDNA 作为模板进行扩增。反应体系:模板DNA 2 μL,上游引物1 μL(20 mmol/L),下游引物1 μL(20 mmol/L),2× 预混液10 μL,灭菌超纯水6 μL,总体积为20 μL。PCR 扩增程序:94 ℃预变性5 min,95 ℃变性30 s,56 ℃退火30 s,72 ℃延伸30 s,循环25 次,最后72 ℃延伸2 min。利用琼脂糖凝胶电泳分离PCR 扩增产物,凝胶成像仪拍照分析,观察电泳条带是否单一,位置是否正确。
1.4 GO-SELEX 筛选方法
参考文献[29]的方法,将氧化石墨烯加入反应体系中吸附去除未与组胺结合的游离ssDNA。本试验中,将组胺溶于超纯水,配成2 nmol/L 的溶液。配制15 mg/mL GO,超声至均匀悬浮体系,使用前充分混匀。
在第1 轮筛选时,随机ssDNA 文库使用量为20 μL,组胺溶液用量为20 μL。首轮筛选体系为600 μL,在1 × 结合缓冲液(0.85% NaCl,10 mmol/L Tris-HCl,pH 8.0)中25 ℃反应2.5 h,加入100 μL 氧化石墨烯吸附30 min,然后,13 000 r/min 离心10 min,取其上清液,重复3 次,充分去除残留氧化石墨烯。将离心获得的上清液作为PCR 扩增的模板,PCR 扩增所得ssDNA 通过纯化、酶切、纯化及变性后作为第2 轮筛选所需文库。
为提高适配体筛选的特异性,每2 轮正筛后进行1 轮反筛,即分别在第3,6,9 轮用L-组氨酸盐酸盐、血清素及5-羟色胺进行反向筛选。反筛过程与正筛基本相同,在结合反应结束后,离心收集不与反筛物结合的上清液,直接作为模板进行不对称PCR 扩增。11 轮筛选所得ssDNA 经纯化,送至上海英骏生物技术有限公司序列分析。
1.5 适配体二级结构模拟
用DNAMAN 软件对测序获得的序列进行比对,并用在线程序Mfold(http://mfold.rna.albany.edu/?q=mfold)进行二级结构预测和模拟。
1.6 适配体结合特异性分析
氧化石墨烯不仅能强吸附游离的单链DNA,而且具有极好的荧光淬灭作用,能将吸附在其表面的荧光基团猝灭[29]。将测序所得序列通过分析挑选2 种代表性序列,在其5-端进行FAM 标记,分别与组胺、L-组氨酸盐酸盐、血清素及5-羟色胺在25 ℃摇床孵育2 h,加入GO 吸附并淬灭未结合的荧光标记ssDNA。反应结束后用F-7000 荧光光谱仪,在激发波长490 nm,发射波长520 nm,光电倍增电压800 V 的条件下检测孵育液的荧光强度(F)。共重复3 次试验,以不加适配体的为空白对照组,不加靶标物并不用氧化石墨烯吸附的为阳性对照组。

1.7 适配体亲和力测定
各适配体与HA 的亲和常数测定方法是:将HA 与不同浓度的适配体(0~80 nmol/L)结合2 h,然后按照1.6 节方法计算不同浓度时的亲和力,并以适配体浓度为横坐标,亲和力为纵坐标作图。利用Origin 8.0 软件拟合每条适配体的饱和曲线,计算其解离常数Kd值。
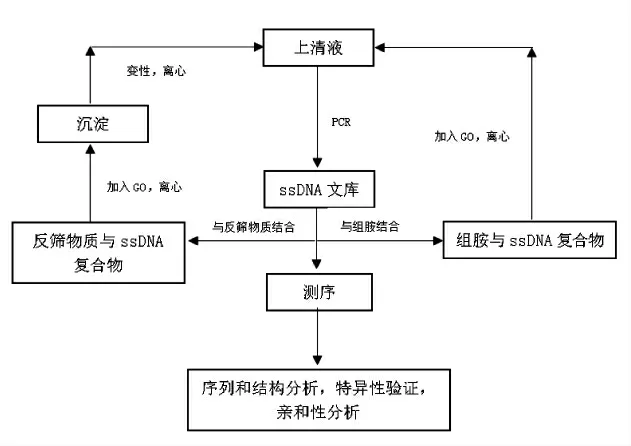
图1 基于氧化石墨烯的组胺的SELEX 筛选原理图Fig.1 SELEX of Histamine based on Graphene Oxide(GO)
2 结果与讨论
2.1 适配体筛选流程
第1 轮、第2 轮为正筛,以富集到更多的与组胺相结合的ssDNA。当富集的ssDNA 达到一定的数量,加入L-组氨酸盐酸盐、血清素及5-羟色胺进行反筛,以增强适配体的特异性。经11 轮SELEX 筛选,测序获得15 条候选适配体序列,见表1。其中有6 个适配子的序列(HAA-1、HAA-4、HAA-7、HAA-12、HAA-13 和HAA-14)在测序结果中出现5 次以上,是高频适配子。

表1 测序得到的15 条适配体序列Table 1 15 Aptamer sequences by test
2.2 适配体一级结构分析
使用DNAMAN 软件对15 条序列进行多序列比对和同源性分析,得到相应的同源树(图2)。依据该同源树将这15 条序列分成3 个家族(表2)。从表2 可看出,同源性较高的第1 家族集中了57.7%的适配体,大部分高频出现的适配体在这个家族。这表明GO-SELEX 筛选具有很好的富集作用。
2.3 候选适配体的二级结构分析
在测序结果中适配体出现的频率越高,意味着其在富集库中的占比越较高,对组胺的亲和力也越高。从3 家族中选择高频出现的适配体HAA-1、HAA-4、HAA-7、HAA-12、HAA-13 和HAA-14。利用在线程序Mfold 对这6 条高频适配体序列的二级结构进行预测和模拟。比较每个适配体的预测二级结构的自由能,适配体序列二级结构见图3。
基于ssDNA 折叠结构的稳定性主要通过自由能衡量,自由能越小,折叠结构越稳定[23]。对这6 条适配体的自由能进行比较,HAA-4 最小自由能为-6.87 kcal/mol,明显小于其它5 条适配体的自由能,表明相比其它适配体,其二级结构更加稳定。图3 可见HAA-4 为茎环结构,表现为1 个大环和2 个小环,而茎环结构正是适配体与靶标组胺结合的基础。

图2 组胺适配体同源树Fig.2 Homology tree of aptamers against Histamine
2.4 适配体特异性分析
所挑选的高频适配子对HA 的结合特异性分析见图4。HAA-4 和HAA-7 对HA 的亲和特异性较高。后续只选HAA-4 和HAA-7 适配子进行亲和常数的测定。

表2 基于同源树的组胺适配体分类Table 2 Classification of aptamers against histamine based on the homology tree
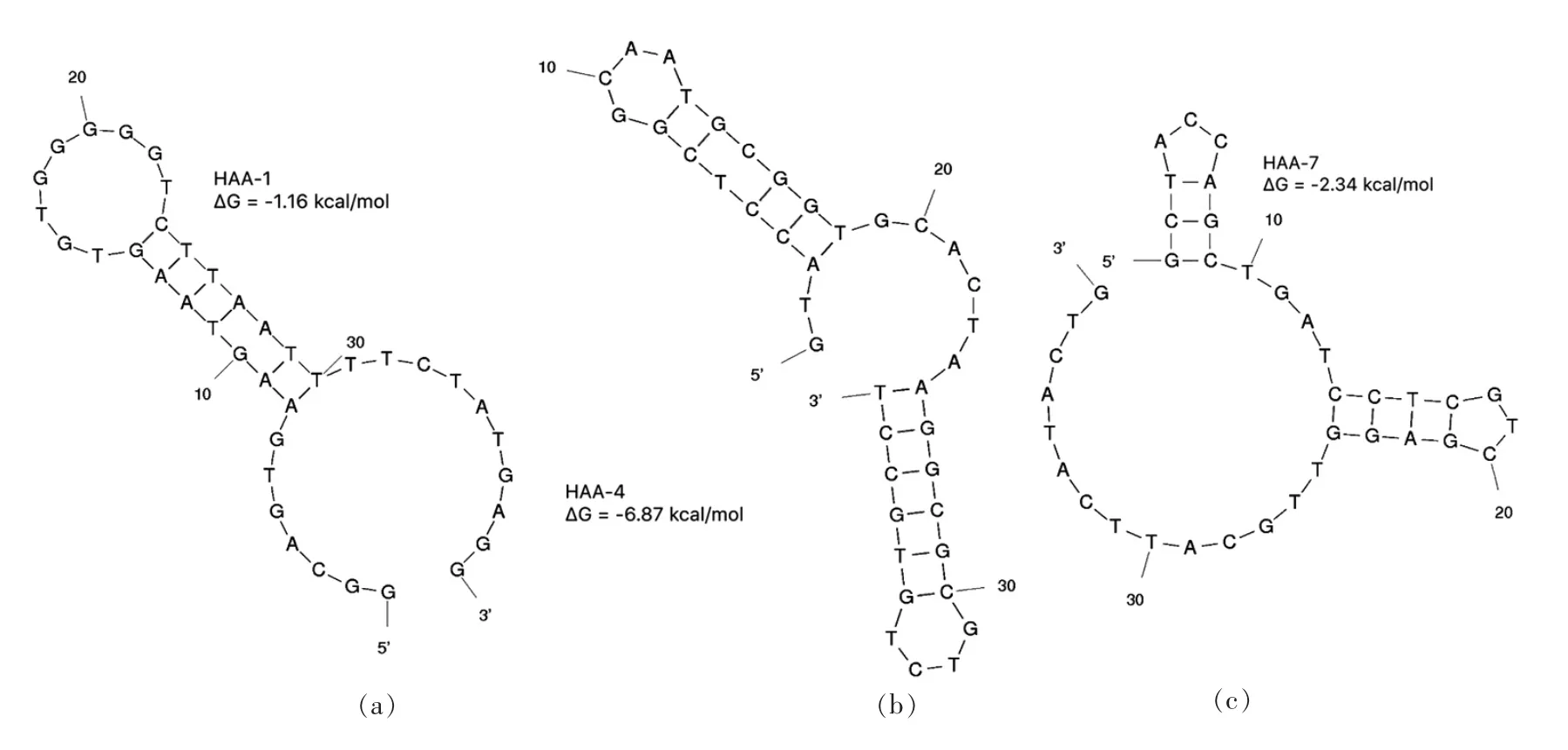

图3 预测的组胺适配体序列二级结构Fig.3 Predicted secondary structures of Histamine aptamer sequences

图4 4 种高频适配体特异性分析Fig.4 Analysis of specificities of the four high-frequency aptamers
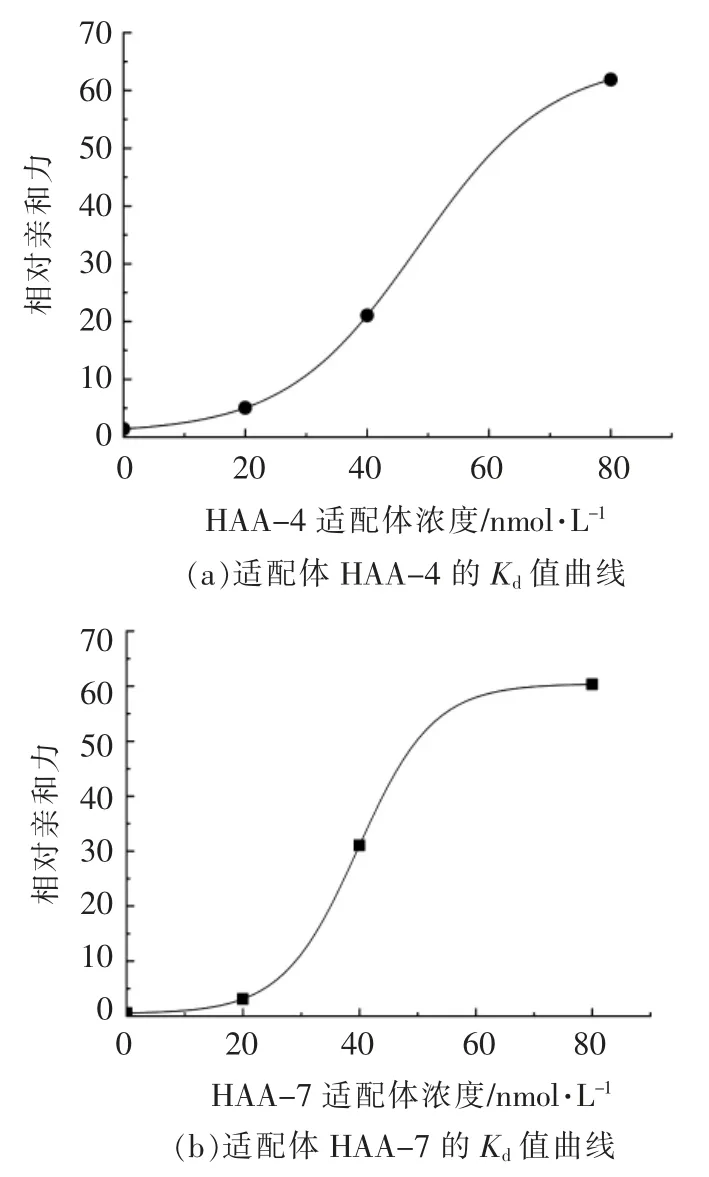
图5 组胺适配体的解离常数饱和曲线Fig.4 Saturation curves of dissociation constant(Kd)of Histamine aptamer
2.5 适配体亲和性分析
测定HAA-4 和HAA-7 适配子的亲和常数,其中适配子HAA-4 的亲和常数饱和曲线见图5,呈较好的拟合效果,适配子与菌体之间的亲和常数Kd=48.37 nmol/L。适配子HAA-7 的饱和曲线与图4 类似,亲和常数Kd=39.73 nmol/L。根据亲和常数越小,适配体与靶标的亲和力越大的原则,适配子HAA-7 对HA 的亲和力更大。
3 结论
本研究中,利用基于氧化石墨烯的SELEX 技术,对组胺进行11 轮的筛选,分别在第3,6,9 轮用L-组氨酸盐酸盐、血清素及5-羟色胺进行反向筛选,最终获得高度亲和性和特异性的15 条适配体序列。通过适配体二级结构、亲和性和特异性分析,最终HAA-4 和HAA-7 被确定为最佳候选适配体,有望用于食品中组胺的定性、定量分析。未来的工作是确定对组胺候选配体进行化学改性和修饰,开发基于对组胺精确识别的适配体的低成本、高灵敏的新型组胺检测方法。
