基于文本挖掘的道路运输安全风险源辨识模型
2021-02-01罗文慧蔡凤田吴初娜夏鸿文孟兴凯
罗文慧 ,蔡凤田 ,吴初娜 ,夏鸿文 ,孟兴凯
(交通运输部公路科学研究院,北京 100088)
安全风险是指不确定性对安全的负面影响,是通过事故表现出来的[1]. 风险源是可能单独或共同引发风险的内在要素[1],由此,道路运输安全险源是指道路运输安全风险事件发生的根源,即通常所说的可能导致道路运输事故发生的不安全因素,或称道路运输事故原因因素. 实现有效的“事前”道路运输安全风险防控是实现交通安全生产的重要组成部分,道路运输安全风险源是“事前”道路运输安全风险防控的前提和基础.
目前,道路运输安全风险源辨识方法主要有基于故障树模型、失效模型、层次模型等专家经验判别方法,缺少基于数据的方法,主要是因为道路运输过程是涉及“人、车、路、环境、管理”等要素风险源耦合的复杂过程,缺少综合感应设备提取全部的结构化数据. 相比而言,较为完善的数据为道路运输事故报告等非结构化数据. 目前对道路运输安全事故报告等文本数据的风险源辨识基本为人工识别,工作量较大. 近年来,随着大数据技术的发展,自然语言处理技术(natural language processing,NLP)逐渐成熟,并应用到航空、铁路、船舶运输. 2018年,Li等[2]针对中国城市轨道交通安全风险源结构化数据缺失的问题提出应用文本挖掘的方法进行风险源辨识,应用词频分析和聚类的方法从156份事故报告中挖掘出包含管理、参与人和直接安全因素的15个安全风险源因子. 同年,Shi等[3]对航空事故报告数据进行了安全风险因子挖掘,先用主题模型对文进行挖掘,将挖掘结果输入到分类模型中,并与朴素贝叶斯、霍夫丁树分类模型的结果进行了比较,发现构建的模型表现最佳. Williams等[4]对铁路事故报告进行了文本挖掘,对比了潜在语义分析(latent semantic analysis,LSA)和潜在狄利克雷分布(latent Dirichlet allocation,LDA)模型在铁路事故报告上的主题挖掘效果,实验结果表明两种模型都能挖掘到最频繁发生的事故类型,但是对于非频繁事故达不到预期的效果. Andrzejczak等[5]基于航空事故报告对航空风险源因素进行挖掘,首先将文本向量化表示,然后应用扩散图模型进行降维操作,最后进行无监督分类,实验结果证明了模型的有效性. Tanguy等[6]利用TF-IDF (term frequency-inverse document frequency)对经过预处理的航空事故报告中的风险源相对权重进行度量,帮助专家在短时间内对报告中的重点风险实现快速辨识. Zhang等[7]提出一种基于文本挖掘的航空事故预测模型,该模型首先对航空事故报告进行人工标注,标注为高风险源、中等风险源、低风险源3个层次,然后应用支持向量机进行文本主题和结果之间的挖掘,同时构建深度神经网络,进行模拟事件上下文特征和事件结果之间的复杂关联.
以上模型可以总结为对文本关键词、主题的挖掘,然后通过分类模型进行大范围的风险源辨识,识别的风险源有限. 道路运输安全事故报告文本(简称事故报告)主要是对事故发生过程、运输参与方进行描述,一般只叙述事实,直接利用LDA或LSA主题挖掘模型、TF-IDF关键词挖掘模型效果不理想,需要对文本进行特征加强操作,然后再进行风险源的辨识. 目前,特征加强多数是对文本进行提前处理. An等[8]抽取文本中的因果句,并进行句法分析,利用三元法进行因果标注,构建相似度模型进行因果关系抽取,实现病例风险源的辨识. 在实体关系识别上多数应用深度学习模型来实现,Zeng等[9]、袁飞等[10]证明了卷积神经网络(convolutional neural networks,CNN)在抽取句子实体关系上的优越性.
本文借鉴以上方法,按照所建立的因果句抽取规则提取事故报告中的因果句子,对抽取的因果句进行词向量化、位置向量化等特征构造,最后将特征构造的结果输入到CNN中进行风险源或导致事故状态实体的抽取,从而实现风险源辨识. 本文通过对道路运输安全事故历史文本数据的风险源自动挖掘,为实现“事前”的道路运输安全风险源(简称风险源)防控打好基础.
1 模型构建
风险源辨识模型包含因果句抽取、因果句预先处理、CNN风险源辨识3个环节,如图1所示.

图1 风险源辨识步骤示意Fig. 1 Schematic diagram of risk-source identification process
1.1 因果句抽取
1.1.1 因果提示词构建
因果提示词来源于事故报告和北京大学中国语言学研究中心(CCL)的现代汉语语料库,借鉴裘江南[11]2012年提出的因果词,本文提取安全风险源提示词共115个,列举如表1所示.

表1 因果提示词清单列举Tab. 1 Causality cue words
1.1.2 因果句结构
事故报告的因果关系可总结为由因到果、由果到因和分开式3种形式:由因到果分为一因一果、多因一果、一因多果;由果到因分为一果一因、多果一因、一果多因;分开式分为因果分开式和果因分开式. 构建因果抽取规则如表2所示.

表2 因果句子结构列举Tab. 2 Causality sentence structures
1.1.3 因果句抽取
结合因果提示词构建因果句结构,事故报告因果句抽取算法的伪代码为:
l= [ ] //l为列表
foriin sentence: //i为迭代变量
if (句子中有一个提示词):
a= 提示词前后两句
l.append(a)
if (句子中有两个或两个以上提示词):
b= 取提示词所在的句子和前后两句
l.append(b)
returnl
1.2 因果句预先处理
按照NLP文本处理的基础步骤和本文特征抽取的需求,风险源因果句预先处理过程包括加载风险源自定义字典、加载因果句、去停用词和分词4个环节,如图2所示. 为了保障文本处理质量,构建了748个专业词汇,包括597个风险源词汇和151个运输专业术语,形成自定义字典. 在哈工大停用词表的基础上,形成自定义停用词表. 本文利用Python的Jieba进行文本分词操作.

图2 因果句预先处理流程Fig. 2 Preprocessing process of causality sentences
1.3 CNN风险源辨识模型
CNN风险源辨识模型如图3所示. 首先,对提取的风险源因果句进行模型输入特征构造. 本文通过借鉴He等[12]融合词向量和位置向量的特征构造方法实现模型输入特征构造. 其次,将构造的特征输入到CNN中进行模型训练,包含2个卷积层和2个池化层. 在池化层之后,构造全连接层实现池化层提取特征的向量化表示. 最后,将特征向量输入到Softmax中实现风险源或事故状态的分类.

图3 基于CNN的安全风险源辨识模型Fig. 3 Risk-source identification model base on CNN
1.3.1 特征构造
假设抽取的因果句长度为n,那么句子可以表示为x=(x1,x2,···,xi,···,xn).
1) 词向量化

1.3.2 CNN构造
1) 卷积层

2) 池化层
本文在池化层的构造中选择最大值池化操作,在输入数据上移动池化窗口,池化窗口大小为,提取窗口中的最大值. 最大池化层在位置(i,j) 的输出为
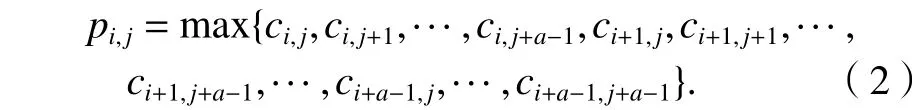
3) 输出层

2 网络训练
采用随机梯度算法(stochastic gradient descent,SGD)进行网络训练,本文为多分类问题,选用多分类交叉熵损失函数作为目标函数.
二分类交叉熵损失函数为

式中:N为训练数据的总数;为样本的标签,正例为1,负例为0;为样本k分类为正例的概率.
多分类交叉熵损失函数为

式中:ykc为样本k的标签,类别c相同则为1,不同则为0;pkc为样本k属于类别c的分类概率.
3 实验
3.1 数据描述
本文收集了2012年—2019年安全管理网站的600份道路运输安全事故报告,道路交通事故由“人、车、路、环境、管理”单一原因或其组合致因导致,共获取因果句1 554个. 在词向量化环节,由于CNN的输入为固定大小矩阵,将词向量处理为12 × 12大小,不足用0补齐. 在句子因果词标注环节,分成两组对句子进行因果关系标注,结果一致认为标记正确,不一致则由专家组进行讨论确定. 为了方便模型训练,需要辨识的风险源词汇依次用1,2,3,4,··· 标注,风险源造成的结果用 11,12,13,··· 标注,其他词汇用0标注,标注结果如表3所示,由于风险源词汇在句子中的占比较少,本文利用过采样(synthetic minority oversampling technique,SMOT)算法进行样本补齐操作,补齐后得到的数据共计53 200条,按照5∶1的比例分配训练数据42 560条,测试数据10 640条.

表3 因果句子标注列举Tab. 3 Causality sentence annotations
3.2 实验环境
实验平台为 2.5 GHz,4核,Inter(R) Core(TM)i7-6500U,16 GB内存,在 Python的 IDE PyCharm中实施. 操作系统为ubuntu16.04,64位,实验程序基于开源软件库Tensorflow 2.0.0和keras,采用Python环境下的Gensim包对词向量进行训练.
3.3 评估方法
3.3.1 评估参数
采用准确率P、召回率R以及准确率和召回率的调和平均值F来评估模型性能,如式(7)~(9)所示.

式中:a为被正确识别的某类风险源或导致结果的个数;b为被识别为其他类的识别风险源或导致结果的个数;e为应该识别的风险源或导致结果的样本总数目.
3.3.2 多分类 ROC (receiver operating characteristic)曲线
为了更加直观地评估模型的有效性,利用多分类ROC曲线进行模型效能的评估,ROC是以假正率和真正率为轴的曲线,ROC曲线和坐标轴围城的面积值越大,模型性能越好.
3.4 参数设置
相关参数设置见表4所示.

表4 参数设置Tab. 4 Parameters setting
3.5 结果与分析
在风险源辨识过程中,要在给定的数据中辨识到更多的风险源,因此,保证召回率理想的情况下最大程度地提升准确率. 利用交通事故报告对建立的安全风险源辨识模型进行实验,得到的准确率、召回率、以及准确率和召回率的调和平均值结果如表5所示. 由表5可知:类别11的召回率最高,依次为类别0、12等;从模型整体来看,模型分类的效果与样本的数量成正比;总体准确率为77.321%,说明了模型的有效性.

表5 准确率、召回率以及准确率和召回率的调和平均值Tab. 5 Tested results of precision,recall,and their F-score values %
建立的安全风险源辨识模型ROC曲线和坐标轴围城面积如图4. 由图4可以看出,非风险源词汇(0 类)和风险源类别 1、2、3、4、5、6、7 的识别准确率较高,风险源类别8、9识别准确率较低,类别10为空,因为数据样本量的大小依次排序为类别0、1、2、3、4、5、6、7、8、9,其中词汇类别 8、9占比不到 5%,类别10不存在. 类别11、12事故状态识别准确率都较高,类别13不存在,因为类别11、12事故状态样本占比较高. 整体的平均ROC与坐标轴围城的面积为 0.94,贴近左上角点(0,1.0),从模型效果来看,模型风险源识别的效果有效,模型辨识效果与样本量的大小有着较高的依赖程度.

图4 安全风险源辨识模型多分类ROC曲线评估Fig. 4 Multi-class ROC curves of risk-source identity model
4 结束语
1) 基于文本挖掘的道路运输安全风险源辨识模型分为文本因果句预先抽取和因果句文本挖掘两个阶段. 在因果句文本挖掘阶段,首先进行适应于CNN输入的、包含词信息和位置信息的特征构造,其次构建CNN道路运输安全风险源辨识模型,最后将构造的特征输入到CNN中进行风险源辨识. 实验结果表示,模型辨识准确率约为77.321%.表明本文提出的模型是一种有效的辨识模型.
2) 本文构建的模型结果的优劣和文本预处理的关联性较大:与在因果句抽取精准性有较大的关联性,若抽取的句子不含风险源或导致结果的信息较多,则削弱模型识别效果;在因果句预处理阶段较依赖于自定义字典和专业术语的完整程度,若自定义字典和专业术语较欠缺,则影响分词效果,进而影响辨识效果;从模型辨识的结果来看,建立的模型依赖样本的数量的程度较高,样本量小的风险源明显识别召回率较低. 因此,在后期的研究中一方面要进一步加大自定义字典和专业术语的完善、文本数据的积累等基础工作的力度;另一方面要进一步研究因果句提取的精准性,提高模型的识别效果.
致谢:感谢交通运输部公路科学研究所(院)科技创新专项资金项目(2019-C507)、中央级公益性科研院所基本科研业务费专项资金项目(2019-0049)的支持.
