FC-CNN:基于卷积神经网络的水果图像分类算法
2021-01-29简钦张雨墨简献忠
简钦,张雨墨,简献忠
(1.200093 上海市 上海理工大学 机械工程学院;2.200093 上海市 上海理工大学 光电信息与计算机工程学院)
0 引言
1994 年以来,我国水果总产量稳居世界第1 位[1]。国家统计局数据显示,2000~2016 年我国水果总产量持续增加,从6 225.15 万t 增至28 351.1 万t。虽然我国水果产量巨大,但多以鲜果销售为主,食用加工比例低下,且损耗率较高,水果加工产业严重落后于欧美发达国家。提高水果产业的工业化、智能化水平成为一个亟待解决的问题。
20 世纪,科研人员着手于水果分类技术的研究,已经开发了一些依赖于形状、颜色和纹理特征的方法用于水果分类。Bolle[2]等人利用最邻近技术,将水果图像的直方图与预先训练好的带有标签的直方图进行对比,再根据直方图的相似度对水果图像进行分类;陶华伟[3]等人利用颜色完全局部二值模式(color completed local binary pattern,CCLBP) 提取果蔬图像的纹理特征,利用HSV 颜色直方图和BIC 颜色直方图提取果蔬图像的颜色特征,采用融合算法将颜色和纹理特征相融合实现果蔬分类。
近年来,许多机器学习技术已经应用在水果分类领域。Peng H[4]等人利用形状不变矩合成水果的颜色和形状特征,再应用SVM 分类器根据提取的特征向量对水果图像进行分类;Erwin[5]等人使用模糊颜色直方图(FCH)方法进行颜色提取,用矩不变量(MI)方法进行形状提取,K-均值聚类算法进行聚类,KNN 方法用来对水果图像分类;Zhang Y[6]等人提出了BBO-FNN 方法,该方法首先提取图像的颜色、形状和纹理特征,然后使用主成分分析(PCA)来去除过多的特征,最后使用一种基于生物地理学优化(BBO)和前馈神经网络(FNN)的方法对水果图像分类。
上述方法虽然取得了一些成果,但是需要对水果图像进行复杂的预处理,提取水果图像的颜色、纹理和形状等特征,且识别水果种类少,分类精度相对不高。
卷积神经网络(Convolutional Neural Networks,CNN)是一种众所周知的深度学习架构,其灵感来自于生物的自然视觉感知机制[7]。随着近年来计算机性能的提升以及成本的下降,CNN 获得了长足的发展,并且在多个领域得到了广泛的应用。现在CNN 能够处理众多复杂的任务,例如图像分类、目标跟踪、姿态估计、文本检测、视觉显著性检测、行为识别、场景标注、自然语言处理等,与其他方法相比,CNN 可以在大规模数据集上实现更好的分类精度,因为它具有联合特征和分类器学习的能力。
最近,CNN 也被应用到水果分类领域,相对其他方法取得了比较好的效果。曾维亮[8]等人设计了一个3 层CNN,使用ReLU 替代传统的Sigmoid 作为激活函数,并引入Dropout,降低网络对某一局部特征的过拟合。实验在15 个类别的水果图像上进行,达到了83.4%的准确率。Lu 等人设计了一个6 层CNN,由卷积层、池化层和全连接层组成[9]。实验在9 个类别的果蔬图像上进行,达到了91.44%的准确率;曾平平[10]等人参照经典的LeNet-5 结构,设计了一个4 层CNN。实验在5 个类别的水果和蔬菜图像上进行,达到了98.44%的准确率。
已有基于深度学习水果图像分类算法均采用池化层进行网络结构设计,训练过程会丢失部分特征,导致分类精度有待提高。在现有工作的基础上,本文设计了一个6 层卷积神经网络作为分类器,使用卷积加步长替代池化层,添加了批量规范化层,并对损失函数和训练算法进行优化,获得了更好的分类效果。
1 FC-CNN 水果图像分类算法
1.1 池化层分析
CNN 一般由卷积层、池化层和全连接层构成。卷积层(Convolutional layer,Conv)对输入的图像进行卷积运算,提取图像特征。池化层(Pooling layer)用于减少卷积层之间的连接数来降低计算负担同时减少特征维度。全连接层(Fully connected layer,FC)将二维图像连接成一个一维向量,用于结果的输出。
最大池化(max Pooling)是最常用的池化方法,其采用滑动窗口分割图像,在每个滑窗内取最大值作为输出。图1 展示了窗口大小为2 的最大池化操作。
由图1 可知,池化操作虽然减少了计算参数、提高了运算速度,但同时也会导致部分特征丢失。本文的FC-CNN 算法使用卷积加步长替代池化层,可以自主选择特征,提高分类精度。

图1 最大池化Fig.1 Max pooling
1.2 批量规范化
在训练神经网络时经常会遇到的问题就是过拟合(Overfitting),即模型过度接近训练的数据,使模型的泛化能力差,表现为模型在训练集上测试的准确率很高,但是在测试集上测试的准确率却很低。过拟合的模型不是理想的模型,需要对模型进行优化,从而提高其泛化能力。
批量规范化(Batch Normalization,BN)可以提高训练速度、加快收敛,防止过拟合,降低网络对初始化权重的依赖,允许使用较大的学习率[11],对于减少过拟合,它比Dropout 更有效。在提出BN 之前,广泛采用Dropout 来克服过拟合,但是添加Dropout 会影响训练速度[12]。BN 是一种更先进、更适用于该问题的方法,通过归一化操作,避免了梯度消失或爆炸的问题。后文将会对比BN 和Dropout 对网络性能的影响。
批量规范化可以看作是训练过程中对每一层输入数据的标准化处理,从而保证输入数据保持相同的分布。
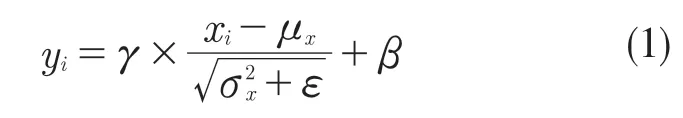
式中:μx——输入xi的平均值;σx2——xi的方差;γ,β——保证输出满足标准高斯分布的正则项,平均值为0,方差值为1。
1.3 FC-CNN 网络结构设计
FC-CNN 的网络结构如图2 所示,由卷积层(Convolutional layer,Conv)、批量规范化层(Batch Normalization layer,BN)、全连接层(Fully connected layer,FC)、Softmax 层和激活函数(ReLU)构成。
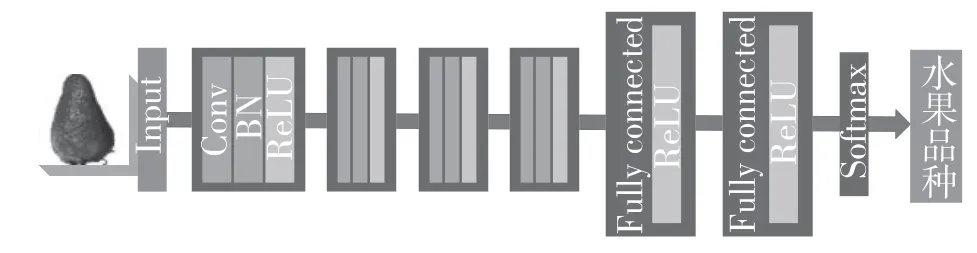
图2 FC-CNN 网络结构Fig.2 FC-CNN network structure
输入图片大小为100×100,通道数为4。第1 层卷积Conv1 使用大小为5×5 的卷积核进行卷积,步长为2;Conv2 的卷积核大小为3×3,步长为2;Conv3 的卷积核大小为5×5,步长为2;Conv4 的卷积核大小为3×3,步长为2。并且所有卷积层都加入了批量规范化层(BN),使用激活函数(ReLU)进行激活。全连接层FC1 和FC2 分别有1 024 和256 个神经元,并使用激活函数(ReLU)。FC-CNN 的具体结构参数如表1所示。
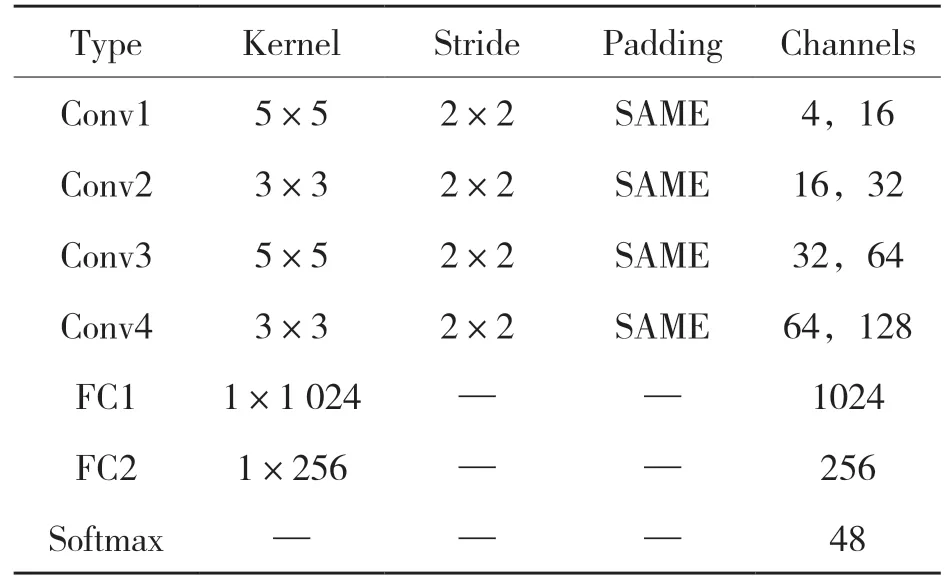
表1 FC-CNN 结构参数Tab.1 FC-CNN structural parameters
1.4 损失函数设计
在模型训练阶段,需要构建损失函数用于评估网络输出结果与实际值的差异。Softmax loss 是一种常用的损失函数,它本质上是多项Logistic loss 和Softmax 的组合。Softmax 将预测转化为非负值,并将其标准化,从而得到类别的概率分布。这种概率预测用于计算多项Logistic loss,即:

为了防止训练过程中发生过拟合现象,本文又在损失函数中加入了L2 正则化(L2 regularization),它通过降低网络中一些神经元的权值抑制过拟合,公式为
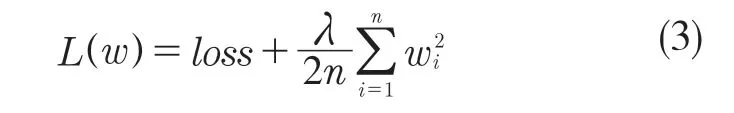
L2 正则项即对所有参数求平方和再除以样本大小,λ是正则项系数,在本文中λ=0.000 5。
本文所使用的损失函数为Softmax loss 和L2正则化的组合,即:
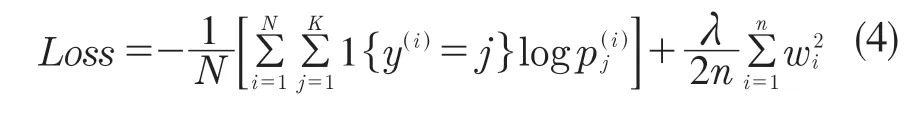
1.5 优化器选择
在设定好损失函数后,需要选择合适的优化器,使损失函数最小。现有的水果分类模型使用的是批量随机梯度下降法 (Mini-batch Stochastic Gradient Descend,Minibatch SGD),其每一次迭代计算Mini-batch 的梯度,然后对参数进行更新。Minibatch SGD 虽然取得了一些成果,但也存在一些需要解决的问题。它选择合适的学习率比较困难,对所有的参数更新使用同样的学习率;同时,它容易收敛到局部最优,并且在某些情况下可能被困在鞍点。
为解决上述问题,本文使用Adam(adaptive moment estimate)优化算法计算梯度并更新权重[13]。该算法结合AdaGrad 和RMSProp 两种优化算法的优点。对梯度的一阶矩估计和二阶矩估计进行综合考虑,计算出更新步长。它是一种自适应的优化算法,能计算每个参数的自适应学习率,参数的更新不受梯度的伸缩变换影响,收敛速度快,学习效率高,其公式为
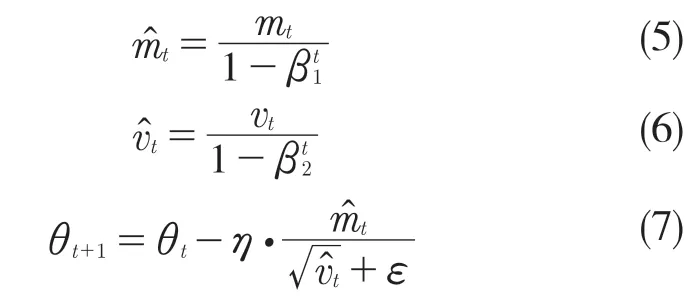
2 实验结果与分析
本实验基于Windows10 操作系统,使用开源的深度学习框架TensorFlow,配置有3.20 GHz主频、16 GB 内存的Intel(R) Core(TM) i7-8700 CPU,和12 GB 显存的NVIDIA GeForce GTX 1080Ti GPU。
2.1 数据集
实验所用数据集为Fruits-360[14],该数据集将水果安装在低速电机的轴上,水果后面放置白纸作为背景(见图3 左侧),启动电机并拍摄20 s 的短片,从中截取图片。对图片进行处理,使其背景被白色像素填充,并将图片缩放到100×100 像素(见图3 右侧)。

图3 Fruits-360 数据集示例Fig.3 Fruits-360 dataset example
从Fruits-360 数据集中选取了48 种中国常见的水果(如图4 所示),其中训练集22 806 张,测试集7 665 张。

图4 部分水果图像Fig.4 Some fruit images
2.2 实验方法
本文对数据集进行了预处理,将输入的RGB图像进行随机的色调和饱和度变化。为了对数据集增广,随机地水平和垂直翻转它们。然后将它们转换为HSV 图片和灰度图片,最后将其合并为4 通道图片。
使用Adam 优化器对损失函数进行优化,学习率为0.001,动量参数β1=0.9,β2=0.99。从训练集中随机选择64 幅图像作为一个批次,对算法进行45 000 次迭代训练,每100 次计算一次准确率。
2.3 实验结果对比与分析
为了验证本文算法网络结构的合理性,在数据集上进行了多次测试,包括有无批量规范化层(Batch normalization layer)、池化层(Pooling layer)和Dropout 的对比。多种网络结构的测试结果见图5、图6、图7。
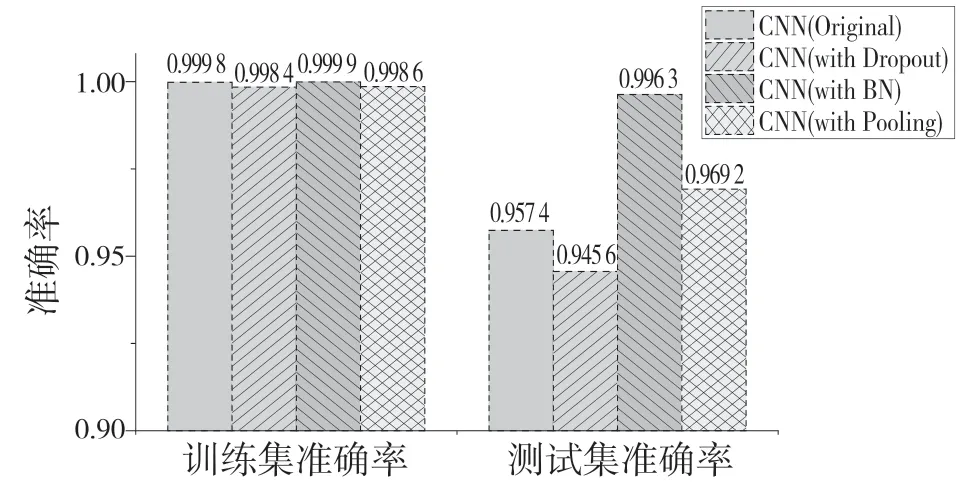
图5 多种网络结构准确率Fig.5 Multiple network structure accuracy

图6 损失函数Fig.6 Loss function
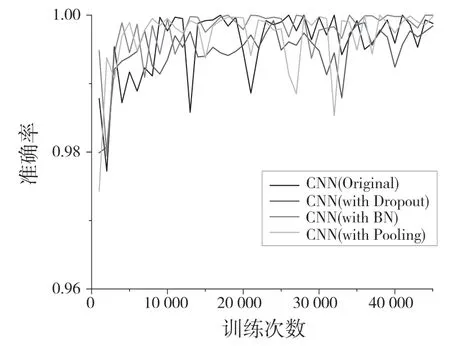
图7 训练集准确率Fig.7 Accuracy on training set
图5—图7 展示了同一数据集下不同网络结构的实验结果,可以看出CNN(with BN)在训练集和测试集上的准确率都是最高的,同时相比于其他结构CNN(with BN)的收敛速度更快,因此验证了FC-CNN 算法网络结构的合理性。
为了验证本文提出的FC-CNN 算法与其他分类算法在水果图像的分类效果上是否具有优势,实验选取了文献[8-10]中的算法在Fruits-360 数据集上进行对比。表2 给出了FC-CNN 算法与其他3 种算法的分类效果对比。
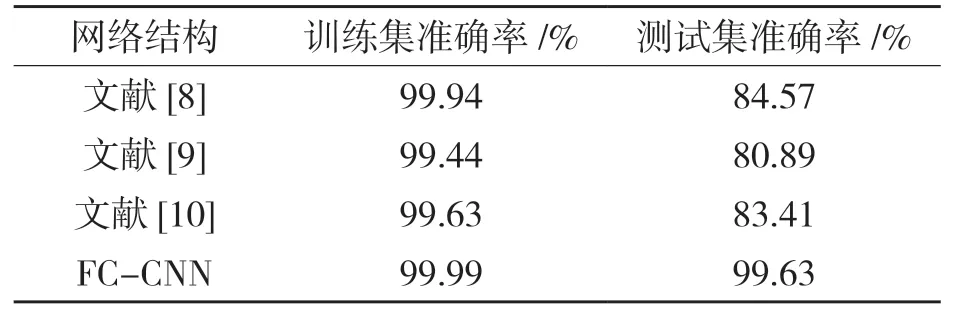
表2 多种分类算法测试结果Tab.2 Various classification algorithms test results
从表2 得出,FC-CNN 模型相比文献[8-10]中的模型的准确率分别高出15.06%、18.74%和16.22%,表明FC-CNN 分类算法优势明显。
3 结论
为了提高现有基于深度学习的水果图像分类算法精度不高、识别种类少的问题,本文完成了一种基于深度神经网络的FC-CNN 水果图像分类算法。由于采用卷积加步长替代现有算法中的池化层,提高了分类精度;同时加入批量规范化层,加快了收敛速度,解决了水果图像分类算法训练过程中过拟合的问题。经实验验证,相较于现有方法分类精度更高,识别水果种类更多,为多类型水果分类提供了一种新的思路。课题组下一步工作将基于提出的算法,采用嵌入式设备进行硬件系统实现。
