基于AutoML的保护区物种识别①
2019-09-24刘耀,罗泽
刘 耀,罗 泽
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院大学,北京 100049)
近年来,红外相机技术因为其不受环境限制,全天不间断的特点,在各级保护区得到了广泛应用[1-3].目前有大量的照片数据,如何充分利用这些数据,从中挖掘有效的信息,成为了人们研究的重点.其中物种识别技术是很多工作的前提,比如物种行为分析、物种多样性检测等,都得先从图片中识别出物种.
深度学习技术的出现给各领域都带来了革命性的变化.在图像领域中,以卷积神经网络(Convolutional Neural Network,CNN)为代表的深度学习网络结构,在图像识别[4]、目标检测[5]、图像分割[6]等各项工作中,都以绝对的优势战胜了传统方法,带来了显著的提升.传统方法利用手工提取特征,包括纹理、颜色、灰度、梯度等特征,然后将这些手工提取的浅层特征输入到分类器中,进行识别.深度学习可以学习深层特征,而且理论上来讲,网络越深,学习到的特征越高级,是低阶特征的组合,同时,深度学习还是端到端的,特征提取与分类一起进行.但是网络结构并不是越深越好,随着网络结构的加深,会出现梯度爆炸、梯度消失[7]、过拟合等问题,虽然现在有一些技术,比如加BN[8](Batch Normalization)、ReLU[9](Rectified Linear Units)、Dropout[10]、Data Augmentation[11]等,可以在一定程度上缓和这些由网络结构加深带来的问题,但是也只是缓和,并不能从根本解决.所以卷积神经网络在发展的过程就是朝着越来越深的方向发展,同时会有一些新的结构单元出现,比如VGG[12]、Inception[13]、ResNet[14]、DenseNet[15]等.在实际应用中,人们往往不会自己设计一个网络结构,而是使用一些已经证明有效的网络结构,比如VGG16、VGG19、ResNet50 等.没有一个网络结构可以保证在任何数据集上都优于其它网络结构,对于一个特定的数据集,我们需要进行实验,根据实验结果选择一个性能最好的网络结构.所以,当拿到一个新的数据集的时候,我们需要重新进行实验选择.
这两年自动机器学习(Auto Machine Learning,AutoML)技术正在兴起,虽然刚刚起步,但已经取得了不错的成绩.AutoML 技术就是一种让机器学习怎么学习的算法,在传统机器学习就主要表现在自动调参[16-18],在深度学习上就主要表现在网络架构搜索[19-22](Neural Architecture Search,NAS),因为在深度学习最重要的参数就是网络结构的层数,每层神经元的个数等.
因此,本文将基于AutoML 的图像识别技术应用到保护区的红外相机物种识别上,对于不同保护区的物种图片数据,自动设计适合该数据集的网络结构,而不需要自己手动选择网络结构,在保证准确率的前提下,节省了人力.
1 相关理论
1.1 贝叶斯优化
贝叶斯优化是AutoML 中的常用的方法[23-25],它是一种典型的黑盒优化算法,就是只能观察到输入和输出,无法知道输入和输出之间的关系以及梯度信息,贝叶斯优化通常用高斯过程模型来捕捉输入和输出之间的关系[26-27].
高斯过程是假设你的输入之间服从高斯分布,通过已知的输入和输出 (x1,y1),(x2,y2),···,(xn,yn)来拟合高斯分布模型,当你给出一个新的输入x时,高斯过程模型能给出输出y的概率分布,因为假设输出y是服从高斯分布的,也就是能给出输出的均值 μ和方差 σ.得到均值和方差后,通常还需要一个采集函数(Acquisition Function,AC),以该采集函数的值作为准则来判断这个输入x的好坏.
在AutoML 中,贝叶斯优化通常被用来捕捉参数和模型性能之间的关系,通过贝叶斯优化器给出下一个最有“潜力”的参数组合,训练完后返回模型性能用来优化高斯过程模型,反复迭代,快速找到最优的参数组合.
使用高斯过程模型来捕捉输入和输出关系的贝叶斯优化算法过程:
(1)假设输入之间服从高斯分布模型M.
(2)从M 中选择下一个采集函数值较高的输入x.
(3)观察输入x的输出y,如果y满足要求,那么结束算法;否则,返回 (x,y)修正高斯分布模型M,返回第(2)步.
1.2 模拟退火
模拟退火算法是一种常见的搜索算法,常用来在一定时间内在一个很大的搜索空间中寻找近似最优解[28].
模拟退火算法的思想借鉴了固体的退火原理,当固体的温度很高的时候,内能比较大,固体的内部粒子处于快速无序运动,当温度慢慢降低的过程中,固体的内能减小,粒子的慢慢趋于有序,最终,当固体处于常温时,内能达到最小,此时,粒子最为稳定.模拟退火算法便是基于这样的原理设计而成.模拟退火算法从某一较高的温度出发,这个温度称为初始温度,伴随着温度参数的不断下降,算法中的解趋于稳定,但是,可能这样的稳定解是一个局部最优解,此时,模拟退火算法中会以一定的概率跳出这样的局部最优解,以寻找目标函数的全局最优解.这个概率就与温度参数的大小有关,温度参数越大,概率越大,反之则越小.
模拟退火的算法过程:
(1) 初始化:初始温度T(充分大),初始解状态S(是算法迭代的起点),每个T值的迭代次数L.
(2) 对k=1,2,···,L做第(3)至第(6)步.
(3) 产生新解S′.
(4) 计算增量 ΔT=C(S′)-C(S),其中C(S)为评价函数.
(5) 若 ΔT<0,则接受S′作为新的当前解,否则以概率接受S′作为新的当前解.
(6) 如果满足终止条件则输出当前解作为最优解,结束程序.
终止条件通常取为连续若干个新解都没有被接受时终止算法.
(7)T逐渐减少,且T←0,然后转第2 步.
2 本文方法
本文使用的基于AutoML 的图像识别技术,能够针对特定的数据集自动设计网络结构,不需要人工干预,主要思想如图1所示.
贝叶斯优化器模块主要负责的是网络结构的自动构建与搜索任务,从旧的网络结构构建出新的网络结构,然后搜索出下一个网络结构用于训练,得到的性能用来修正这个优化器.模型训练模块主要负责训练,给定一个网络结构,返回在验证集合上的准确率.
2.1 经典的网络结构组件
经典的网络结构组件主要有3 种:CNN (Convolutional Neural Network)、MLP (Multi-Layer Perceptron)、ResNet (Residual Network),这是构成网络结构的基本组成部分,比如VGG、Inception、ResNet、DenseNet等网络结构都是由这3 种基本组件组成,只是组件个数与组成方式不同而已.
2.2 自动构建网络结构
网络结构的构建是从小到大的过程,所以网络结构会越来越大.初始的网络结构有3 个,分别由CNN、MLP、ResNet 基本组件组成,然后由这3 个网络结构开始扩增.有一个候选队列Q,里面是候选的网络结构,从队列头取出网络结构G,对G进行扩增,扩增的方法如图2所示,主要有4 种:1)deep(G,u),加深网络结构,随机选择一层u,在层u处加入新的层使网络结构变深;2)wide(G,u),扩宽网络结构,随机选择一层u,在层u处加入新的节点使网络结构变宽,这里的加入新的节点指的是卷 积层中的卷积核,也就是增加卷积层u中卷积核的个数;3)add(G,u,v),随机选择一层u和v,增加跳跃连接,给层u和层v增加一条跳跃连接,使用ResNet 的思想;4)concat(G,u,v),随机选择一层u和v,将层u和层v合并;
主要步骤为:
(1)从候选队列头取出网络结构G.
(2)将G进行上述4 种扩展操作,得到4 个新的网络结构,将新的网络添加到候选队列中.
2.3 搜索网络结构
对于自动构建的网络结构,并不是每个新网络结构都训练,而是挑选最有“潜力”的网络结构,也就是最有可能获得最好性能的网络.这里的网络结构可以看作输入,而模型性能可以看作输出,这是一种典型的黑盒优化问题.关于黑盒优化算法,典型的有网格搜索、随机搜索、贝叶斯优化.网格搜索就是遍历所有的输入,观察每个相应的输出,最后选取最好输出对应的输入作为问题的解.随机搜索就是随机选择一个输入,观察相应的输出,最后选取最好输出对应的输入作为问题的解.可以看到网格搜索相对耗时,但可以得到问题的最优解,而随机搜索虽然不耗时,但具有随机性,解的方差较大.贝叶斯优化既不用遍历所有输入,又可以获得有一定置信度的解.
将贝叶斯优化应用到网络结构的搜索,也就是在训练了n个网络后,观察到了这n个网络结构的性能,就可以更新贝叶斯优化控制器.当给定一个新的网络f,可以得到新的网络结构性能的均值 μ(f)和方差σ (f).μ(f) 越大,说明网络结构f性能均值越好,也就是期望越高,α (f)越 大,说明网络结构f的性能方差越大,但说明不确定性也越大.

图2 自动构建网络结构
选择网络结构时,我们要平衡探索与利用,探索指的是倾向于选择那些不确定性大的网络结构,利用指的是倾向于选择那些性能期望高的网络结构,最终网络结构f性能的采集函数是
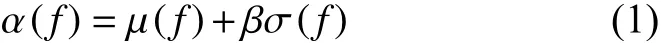
β是一个平衡因子,来平衡探索与利用.得到每个网络结构的 α值之后,通过模拟退火算法来选取下一个网络结构作为备训练的网络结构.
搜索算法的算法过程:
(1)初始化模拟退火的温度衰减率r,温度参数T以及最低温度阈值Tlow,最高历史模型性能值cmax,最优网络结构fmax,优先级搜索队列Q.
(2)取出队列头网络结构f,对该网络结构做上述四种操作进行扩增,得到四个新的网络结构,对于每个新网络结构f′,如果将该网络加入到优先级搜索队列中,否则不加入队列.如果cmax<α(f′),那 么cmax←α(f′),fmax←f′.同时 衰减 温 度T←T×r.
(3)如果队列不为空,并且T>Tlow,返回第二步;否则,返回最优网络结构fmax.
2.4 算法流程
算法流程图如图3所示.
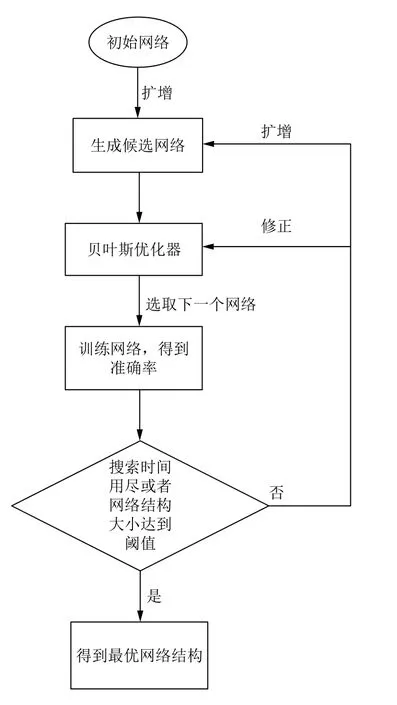
图3 算法流程图
3 实验分析
3.1 数据集
本文在保护区的红外照片数据集上验证了基于AutoML 的图像识别方法.本文从两个保护区的数据图片中制作了四个数据集,为了使不同数据集的之间具有可比性,尽量保持不同数据集之间相似性,比如1) 数据图片都是鸟类图片,不同类别是不同的鸟类;2)每个数据集类别数相同,都是十类;3)样本数量相差不大,每个类别大概900 张左右;4)使用相同的方式划分训练数据和测试数据,测试数据是从训练数据的每类中随机抽取20 张得到的,测试数据一共200 张,可以保证测试数据中不会因为类别的不均衡导致某些类别测试样本过少.
数据处理方面主要有两点:1)数据归一化,图片像素值的范围是[0,255],将数据乘以 1 / 255.0 缩放到[0,1];2)数据增强,为了增强数据以得到更好的性能,本文通过将数据水平翻转、缩放、随机裁剪、增加噪声等技术对数据进行增强.
3.2 模型训练
对于自动构建的网络结构和经典的网络结构VGG16、VGG19、ResNet50,都使用相同的训练参数,来验证自动构建网络的有效性,训练参数如表所示.训练过程都使用了一些深度学习的训练技巧,比如在Dense 层加入Batch Normalization 来防止过拟合,同时防止梯度消失,使得训练更深的网络成为可能.
在使用经典网络时,人们往往都会使用finetune 的方式,fine-tune 的一般步骤为:1) 使用公开的权重来初始化参数,先固定卷积层和池化层,保持它们的参数不更新,只更新全连接层的参数;2) 在训练一定的轮次后,不再固定卷积层和池化层的参数,调小学习率,再训练整个网络.当你的数据量不足时,这样做往往能取得不错的效果.对于经典的网络结构,公开的权重是别人使用大量的数据训练得到的,这样的权重提取到的特征对于大部分任务来说,往往是有效的,如果使用公开的权重来初始化,可以省去你的时间.相当于使用公共的卷积核来提取低级特征,因为很多数据集的低级特征类似,比如一些边缘特征、纹理特征等,训练全连接层,也就是组合低级特征,不同的数据集组合方式可能不同,所以第一步中要固定卷积层和池化层.第二步再更新整个网络,调小学习率,针对这个数据集来进行微调.在本文中,经典网络使用fine-tune 的方式,而自动构建的网络没有使用这种方式,因为经典网络结构是固定的,参数个数与网络形状相同,可以使用公开的权重来初始化,而自动构建的网络可能从来都没有见过,自然也就没有公开的权重来初始化.
关于训练停止的策略,都是用EarlyStopping 策略,也就是网络的验证性能在n个Epoch 后没有提升就停止训练,验证使用的是验证数据集,保留验证性能最高的Epoch 的权重,将测试性能记作该网络结构的最终性能指标.在基于AutoML 的方法中,选择性能指标最高的网络结构作为最终的网络结构.
3.3 实验结果
在相同的4 组数据集上,本文做了一组对比实验.训练集和测试集相同,图像增强技术只作用于训练数据.
表格中AutoML 后的2 h、12 h、36 h 指的是网络结构搜索的小时数为2 小时、12 小时、36 小时,本文做实验的机器配置:CPU 为双核4 线程,显卡内存为16 GB,所以这里的搜索时间与机器配置也有关系.对于AutoML 技术来说,主要是网络结构搜索消耗时间,所以AutoML 技术的整个流程消耗时间基本上为2 小时、12 小时、36 小时;对于经典的网络结构来说,由于有训练过程、调优过程以及反复的试错过程,消耗时间均为为3 小时左右,其中调优过程最为耗时.由表1可知,对于经典网络结构来说,没有一个网络结构在所有数据集上性能比其他网络结构好,这就是我们每次给定一个数据集需要选择网络结构的原因.而对于AutoML 技术来说,只要有足够的时间来搜索网络结构,一定会获得较好的性能,而且在一定的时间范围内,搜索时间越长,搜索到的网络性能越好.

表1 AutoML 技术与经典网络结构的精度对比(%)
4 结论与展望
本文将基于AutoML 的图像识别技术应用到保护区的物种识别上,解决了目前对于不同数据集需要重新训练和选择网络的问题.通过实验结果的分析,可以看出基于AutoML 的方法能够自动构建网络结构,同时保证了与人工选择的经典网络相持的准确率.然而在性能上还有待提高,从实验结果来看,可能还需要12 小时的网络结构搜索时间,才能达到不错的准确率,可以考虑在训练模型的时候,采用适当的方法来减少模型训练时间,比如提前终止训练,都训练50 步,因为我们不需要知道最终的性能,只需要知道相对性能,如果一个网络在50 步的性能比另一个网络高,那么证明这个网络比另一个网络有“潜力”.此外,AutoML 是近年兴起的热门研究领域,基于AutoML 的图像识别方法有望设计出更好的网络结构,在准确率上大幅超过原始的经典网络.
