洗后织物外观视觉特征编码与折皱评级
2021-01-05徐平华冒海琳沈红影丁雪梅
徐平华, 冒海琳, 沈红影, 丁雪梅
(1. 浙江理工大学 服装学院, 浙江 杭州 310018; 2. 浙江省服装工程技术研究中心, 浙江 杭州 310018; 3. 江苏依海服饰有限公司, 江苏 南通 226007; 4. 东华大学 服装与艺术设计学院, 上海 200051)
织物外观平整度体现了面料经洗涤、烘干后的形状保持性,被广泛用于评价面料性能、整理效果、洗涤剂及洗护设备的护理性能等[1-2]。由于现有客观评级方法的主客观一致率偏低,当前检测机构仍采用AATCC 124—2018《织物经多次家庭洗涤后的外观平整度测定》规定的人工方式评估折皱等级,然而,人工评级存在如评级精度低、稳定性差、再现性弱等不足,极易引起贸易双方的质量纠纷[3-4];因此,亟需建立客观、准确、快捷的客观评级方法,以适应精确检测以及出入境快速通关的需求。
计算机视觉技术具有快速、无损、可重复等优势,在织物外观平整度客观评级方法研究中,研究人员利用计算机视觉技术,从织物折皱图像或空间形貌入手,对织物的折皱形态特征进行提取和分类[5-6]。在折皱信息提取方面,如空间域的局部或全局灰度波动信息[7-8]与起皱形态学信息、变换域的变异程度和统计信息以及空间形貌下折皱位置和高度信息等[9-10],研究人员对提炼的50余种特征进行尝试分类后,主客观一致率未能大幅度提升,无法满足平整度精确识别的检测需求,至今仍未出现有效的商用检测仪器[11-12]。其困难之处在于:折皱位置、尺度的不定性,标准样板的弱覆盖性,织物表面花型和色彩的干扰性等[5]。
本文针对面料整理效果、洗涤剂和洗护设备护理效果评价的现实需求,提出以纯色织物为测试样,在建立洗后织物折皱图像数据库的基础上,利用融合多尺度图像视觉编码和多分类支持向量机的分类方法,实现洗后织物外观平整度的自动评级,有效提升了主客观一致率。
1 实验样本处理与图像采集
1.1 样本选择与处理
本文旨在构建一种能够有效评价面料抗皱整理效果、洗涤剂和洗护设备护理效果的评价方法,面料材质、表面色彩和花型不作考虑。实验过程中,选择市场常用的衬衫面料(广东溢达纺织有限公司)作为本文实验的测试样本。面料成分为100%棉,组织结构为平纹,经密为567根/(10 cm),纬密为283根/(10 cm),经、纬向纱线线密度均为14.6 tex,面密度为(128±5) g/m2。面料处理工艺为烧毛、退浆、煮练(不丝光、不轧光、不上浆、不上蓝、不上增白剂)的半漂无抗皱整理白色织物,满足GBT 406—2018《棉本色布》优等品要求。表面均匀平整、纹路清晰、无油渍、黄斑和破损。
实验过程中,选择了海尔、小天鹅、松下等7家市面上常用的品牌洗衣机、烘干机和熨烫机。整个护理过程参照AATCC 124—2018及商家使用说明,除了采集标准提供的6块立体标准样板外,以实际洗涤、烘干或熨烫的织物折皱形态图像作为实验样本,最终设计形成涵盖9档(1~5级,半级为1档),共计650种不同折皱形态的织物试样。
1.2 织物折皱图像采集
为了构建统一、稳定的图像采集环境,本文实验自行设计了织物采集箱体。织物图像采集箱体见图1,包含了箱体结构框架、抽拉式载物台、工业相机等。
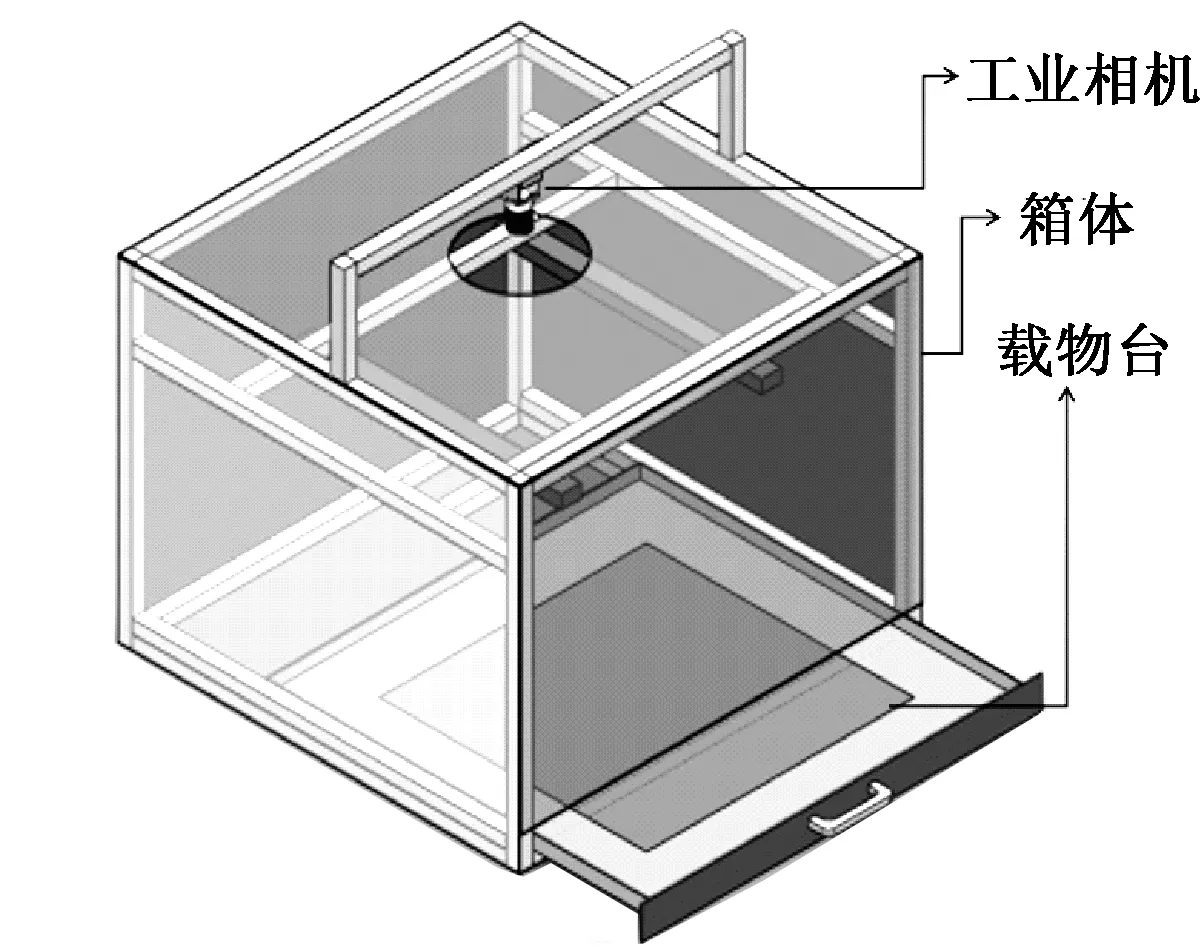
图1 织物图像采集箱体Fig.1 Hardware of image acquisition
其中,相机为TXG50型黑白CCD工业相机(德国BAUMER电气有限公司),其具有高速、高灵敏度、超低噪声和大视场等优势。利用该图像采集装置采集了650幅织物折皱图像,图像大小为2 448像素×2 050像素。载物台大小为50 cm×50 cm,载物台划线区域大小为38 cm×38 cm。箱体采用黑色亚克力板材,内壁为深灰涂层。内置光源为双排LED条形光源的OPPLE T5灯管(欧普照明股份有限公司)。
部分织物试样图像如图2所示。织物经图像采集后,对相机进行标定、图像矫正,将原始图像按照载物台划线区域大小分割处理形成类似图2的织物图像。

图2 部分织物试样图像Fig.2 Partial fabric sample images. (a) Grade 1; (b) Grade 1.5; (c) Grade 2 (d) Grade 2.5;(e) Grade 3; (f) Grade 3.5; (g) Grade 4; (h) Grade 4.5; (i) Grade 5
2 织物折皱特征编码
2.1 D-SIFT特征提取
为了模拟人眼在观测面料外观形态时由远及近的聚焦过程[13],本文利用图像尺度变换,可获得不同分辨率下的折皱图像。如假设原始图像尺度为m×m,分别缩小至原始尺寸的1/4、1/16大小,可形成三级尺度图像。
图像特征变换(dense scale invariant feature transform,D-SIFT)在目标分类和场景分类中有重要应用,能够对输入图像进行分块SIFT特征提取。所谓SIFT特征,是指对划定区域每个像素的SIFT特征[14]进行提取。D-SIFT根据可调的参数大小,来适当满足不同分类任务下对图像特征的表征能力;而传统的SIFT算法仅对整幅图像进行处理,得到一系列特征点。检测窗口数N可由式(1)算出。D-SIFT特征提取实现路径见图3,可分别提取同一样本3个不同尺度图像的D-SIFT特征。(图中右侧框型内每个小方块代指检测出的D-SIFT特征)
(1)
式中:m′为泛指任意一图像的尺寸,像素;p为采样窗口宽度,设定为16像素;v为步进大小,设定为6像素;⎣ 」表示向下取整。

注:m表示原图像尺寸;t表示图像移动的距离。图3 D-SIFT特征提取实现路径Fig.3 Pipeline of D-SIFT feature extraction
窗口以t个像素间隔滑动,在计算每个窗口内中心点的SIFT特征时,将窗口均分划分为16个矩形单元,每个单元梯度方向数为8,因此中心点形成128维度的特征向量。对于1幅大小为m′×m′的图像,经处理得到N个128维的特征向量,因此,如图3所示,同一样本的3个不同尺度图像,利用窗口滑动计算各自的D-SIFT特征序列;再将图3右侧3个框型内D-SIFT特征依次串联后,构建为有序D-SIFT阵列,用以表示该样本的底层特征。
2.2 特征编码
词袋模型(bag-of-words, BOW)[15]近年来在图像分类和识别领域被广泛应用。利用无序局部区域描述子集合,将图像表示成离散化的“视觉词汇”,继而统计每类图像“视觉词汇”频次,构建该类专属的“视觉字典”。对于织物折皱而言,AATCC 124—2018《织物经多次家庭洗涤后的外观平整度测定》划分出5级9档,利用D-SIFT可构建出9类专属“视觉字典”,但因BOW是基于无序“视觉词汇”构建的1幅图像,失去了特征空间关系这一重要信息[15],不利于描述对折皱形态描述。为弥补这一缺陷,在图像尺度变换实现窗口多尺度放缩的基础上,利用线性排列方式,将特征进行按序排列。
进一步地,需要对现有冗余特征进行降维,构建具有较强代表性的“视觉词典”。由式(2)~(4)可计算最优的稀疏U值以及该类别的视觉词汇W解。
∀g=1,2,…,G
(2)
X=[x1,x2,…,xi]∈RM×D
(3)
W=[w1,w2,…,wg]T
(4)
式中:U表示最优稀疏值;X为D-SIFT特征向量的集合;xi为X中的第i个特征;λ为调节系数;ui为第i维度的词汇系数;W为“视觉词典”;wg为第g个“视觉词汇”;G为词汇数量;‖·‖为L2范数,可约束结果至平凡解;M、D分别为二维特征向量的纵横向尺度,单位为像素。
通过对训练样本特征进行迭代训练,形成各级最优视觉词汇库和编码系数,作为该等级分类判定的依据。
3 外观平整度客观等级评定与验证
3.1 客观等级评定
首先,提取测试图像D-SIFT特征,获得稠密的SIFT点,其次,利用式(2)对其视觉词汇进行降维优化,形成该图像的视觉词汇包,利用最大值池化的方式[16-17],构建出该测试图像的稀疏融合特征,用以表征测试样本。
支持向量机是一种基于统计学习理论的机器学习方法,因其可以避免过拟合的优越性质现已广泛应用于人工智能的各个领域。假设训练集X的特征向量为xi,i=1,2,…,N,通过线性分类器在n维的数据空间中寻找1个超平面进行特征分类。在等级评定阶段,首先判定测试样本的初始等级,初始等级精度为0.5级。其次,利用多分类支持向量机,采用一对多的方式构建n×(n-1)/2个分类器,即通过36次分类计算实现9档的初始判定。核函数是一种特征空间的隐式映射,通过将数据映射到高维空间来解决在原始空间中线性不可分的问题。在设定支持向量机的核函数时,结合池化出来的特征,可构建可函数,形式见式(5)。
(5)
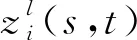
(6)

至此,当检测来样时,判定其外观平整度等级精度为0.5级。进一步依据线性距离关系,将各档之间划分为5个区域,控制精度为0.1级,依据距离落地位置,二次优化判定结果,形成精度为0.1级的平整度客观等级。
3.2 主客观一致率验证
依据GB/T 13769—2009 《纺织品 评定织物经洗涤后外观平整度的试验方法》,实验邀请3名行业内专家,对照标准样照,各自独立评定织物外观平整度等级,将专家评定结果算术平均后记为试样的主观评级等级。
文中提及的主客观一致率,指专家评定结果平均值与仪器评定结果的偏差绝对值小于或等于0.5级,记为“一致”;偏差绝对值大于0.5级,记为“不一致”。主客观一致率计算方法见式(7)。
(7)
式中:C为主客观一致率,%;n为“一致”数量,即统计的主客观等级偏差绝对值小于等于0.5的试样数量;A为测试样本总数。
4 实验结果
评级专家对650张洗后织物样本进行人工评级,同时利用设计的箱体对以上试样进行图像采集、图像切割处理,形成38 cm×38 cm的可视区域图像。
4.1 折皱等级视觉词汇库构建
利用上述稀疏编码算法,实现图像子库的视觉词汇提取。以各档样本量50幅训练图像为例,图4示出各档视觉词汇可视化结果,其中任意小方格为1个词汇,其维度为128,各维度在该子库下均有对应的投影系数。

图4 视觉特征编码词汇Fig.4 Visual feature coding vocabulary.(a) Grade 1;(b) Grade 1.5; (c) Grade 2; (d) Grade 2.5; (e) Grade 3;(f) Grade 3.5; (g) Grade 4; (h) Grade 4.5; (i) Grade 5
按照每档出现的频率高低分布,提取了前1 024个关键词汇(见图4(a))。视觉特征编码词汇图如图4(b)~(i)所示,分别为1.5~5级代表性视觉词汇可视化效果。
4.2 主客观一致率分析
稀疏编码算法所获得的“超完备”基向量可高效地表示样本数据,重建性能好,但如何确定每个级别的最小样本量,对于本文实验仍具有重要的意义。本文采用样本递增的方式,通过主客观一致率递进趋势明确最小样本量。
在数据训练和验证环节,将以上650幅折皱织物图像分为2大类。第1类共计450幅图像,按照人工评级的均值,在1~5级(0.5级为1档)之间每档筛选出50幅图像(允差控制为±0.2级)作为训练样本。余下的200幅图像作为第2类图像,即经过筛选后所剩的图像,作为验证样本。1~5级各档对应的测试样本数量分别为:30、30、30、30、30、20、10、10、10。
具体地,每档训练样本量分别设置为5、10、15、20、25、30、35、40、45、50。以等级2.5、训练样本量20为例,首先从该级的50幅图像子库中随机选取20幅图像。类似地,9档共计选取了180幅图像作为训练样本进行测试。按此方式,对于每类样本量,均作5次随机选取验证样本进行测试。当样本量上升至50次时,由于最大训练样本同为50,不再作随机抽取处理。
图5示出不同训练样本量下的主客观一致率。除训练样本量为450张外,每个样本量5个柱值对应于5次随机抽样下的主客观一致率。折线控制点为该样本量下的主客观一致率均值及标准误差量。由图可知,随着样本量的增长,主客观一致率逐步提升。当各档训练样本为45张,训练样本总量为405张时,主客观一致率为95.08%,均值标准误差最小,5次评级结果趋于稳定。当训练样本总量为450张时,主客观一致率为95.10%,主客观高度一致。

图5 主客观评价一致率验证结果Fig.5 Output of sub-obj rating consistency
此外,本文实验所用计算机CPU为2.9 GHz,RAM为8 G,实验样本对应的测试图像大小为1 750像素×1 750像素,单张验证样本检测时间均小于6 s。
5 结 论
织物折皱特征提取及评级算法的有效性,是决定主客观评价一致率的关键因素。本文在模拟人工评级过程中专家视觉聚焦机制的基础上,提出利用图像稀疏编码技术,对多尺度图像词汇特征进行筛选和优化。以可视化的特征视觉词汇再现了织物外观折皱形态;在此基础上,利用多分类支持向量机分类算法,实现了织物表观折皱的1至5级(0.5级为1档)的客观评级。在最低有效训练样本的确定中,采用递增训练样本量的方式,评估样本量对主客观一致率支撑作用。实验结果表明在各档最小样本量为50幅时,主客观一致率达到95.10%,一致率趋于稳定,单张样本检测速度小于6 s,满足当前织物外观平整度的商用检测需求。
