基于XGBoost算法对新疆女性臀部体型判别及原型修正
2021-01-05刘婷婷梅馨元刘一心肖爱民
刘婷婷,徐 红,梅馨元,刘一心,肖爱民
(新疆大学 纺织与服装学院,新疆 乌鲁木齐 830046)
人体体型根据时间、生活环境、地理位置等客观因素的影响而变化。对新疆地区青年女性裙装合体性进行问卷调查发现,臀部的不合体比例较高。为了使服装更加合体,应对地区性体型进行细分研究。近几年国内外有通过新方法建立体型分类与判别的模型,来提高服装合体度。而针对体型分类的研究方法较多:如尹玲等[1]选择有序样本最优分割法从整体、局部、躯干轮廓层面对女性体型分类,最终把体型划分为3类;Maja Mahnic Naglic等[2]把K-means聚类法应用到人体姿势体型分类中,此分类函数可基于判别函数及其因子负载来定义;王军等[3]利用两步聚类法作为臀部分类方法,选取5个指标后对臀部进行细分;石小强等[4]使用DIANA分裂聚类将江浙地区青年女性臀部分为5类。体型判别上的创新有:尹玲等[5]采用随机森林算法建立可靠的判别模型,提升了体型判别精准度;景晓宁等[6]把女童数据库合理利用起来,运用朴素贝叶斯算法对女童体型进行了判别分析。
极端梯度提升(XGBoost)是一种基于梯度提升决策树的集中学习模型,该方法不仅解决了梯度提升[7]的过拟合问题,还提升了预测的精准度,是目前计算机领域中的一个研究热点。该算法属于提升方法,在分类和预测领域中应用广泛,其优点是模型计算运行速度快,精准度高,运行方式简单[8]。本文采用XGBoost算法建立了判别模型,对新疆地区青年女性臀部进行判别,得到了极高的精准度。该模型可运用到数据系统内,为服装定制厂商提供参考依据,并提高服装的合体性。
1 数据收集及预处理
1.1 测量对象及样本量
本文采用马丁测量仪、卷尺、角度仪等作为测量工具;对新疆地区18~25岁的青年女性进行人体数据采集。参照GB/T 1335.2—2008《服装号型 女子》中人体部位尺寸的标准差与最大允许误差,其中样本量的计算公式为
式中:N为样本量;t为标准正态分布在置信度α为5%时的概率,查表可知t为1.96;δ为标准差;A为允许误差。
程朋朋等[9]指出,以腰围为基础的样本量为最小值,腰围的允许误差为1 cm,总体标准差为6.7 cm,代入计算公式后最终可得样本量为173。考虑到奇异值的筛选,最终选择测量人数为220。
1.2 测量部位确定
本文选择臀部作为体型细致研究部位,参照王军等对臀部分类的指标[2-4],及张文斌描述的前臀长、侧臀长、后臀长与人体腰臀部位、裙装原型的关系[10],使用公因子方差分析后,确认符合要求的17个指标:体重、臀围、腰围、中腰围、大腿根围、腰厚、腹厚、臀厚、身高、臀高、腰高、膝盖中点高、前臀长、后臀长、侧臀长、臀突上角、腰侧角[11]。
图1示出臀长与角度的测量方法。本文中所有测量部位误差不超过允许误差。

图1 臀长与角度测量示意图Fig.1 Hip length and angle measurement schematic. (a) Face of hip body;(b) Side of hip body
通过这些指标可计算出需要的间接变量:身体质量指数(BMI值)、臀腰差、臀腰比、腰围身高比、臀围身高比、后臀长腰围比、后臀长臀围比、后臀长身高比。
1.3 数据预处理
使用SPSS软件对指标进行描述性统计分析,用QQ概率图与直方图对数据进行正态性检验,所有指标均服从正态分布。运用XGBoost算法处理缺失值,通过箱型图与茎叶图查找异常值,对原始数据进行校正。确定有效样本量为200个。
2 腰臀部体型分类
2.1 主成分因子分析
对17项指标进行主成分贡献率分析,不同主成分方差贡献率如表1所示。提取特征根大于1的前4个主要成分,4个主要成分的累积贡献率为77.11%,说明前4个主要成分能表述臀部体型的绝大部分信息。

表1 主成分贡献率分析Tab.1 Analysis of contribution rate of main component
旋转后的成分矩阵如表2所示。旋转后的载荷数的绝对值>0.5时即可被定为指标因子。由表2可知,第1主要指标因子是围度相关指标因子;第2主要指标因子是高度相关指标因子;第3主要指标因子是臀长相关指标因子;第4主要指标因子是角度相关指标因子。
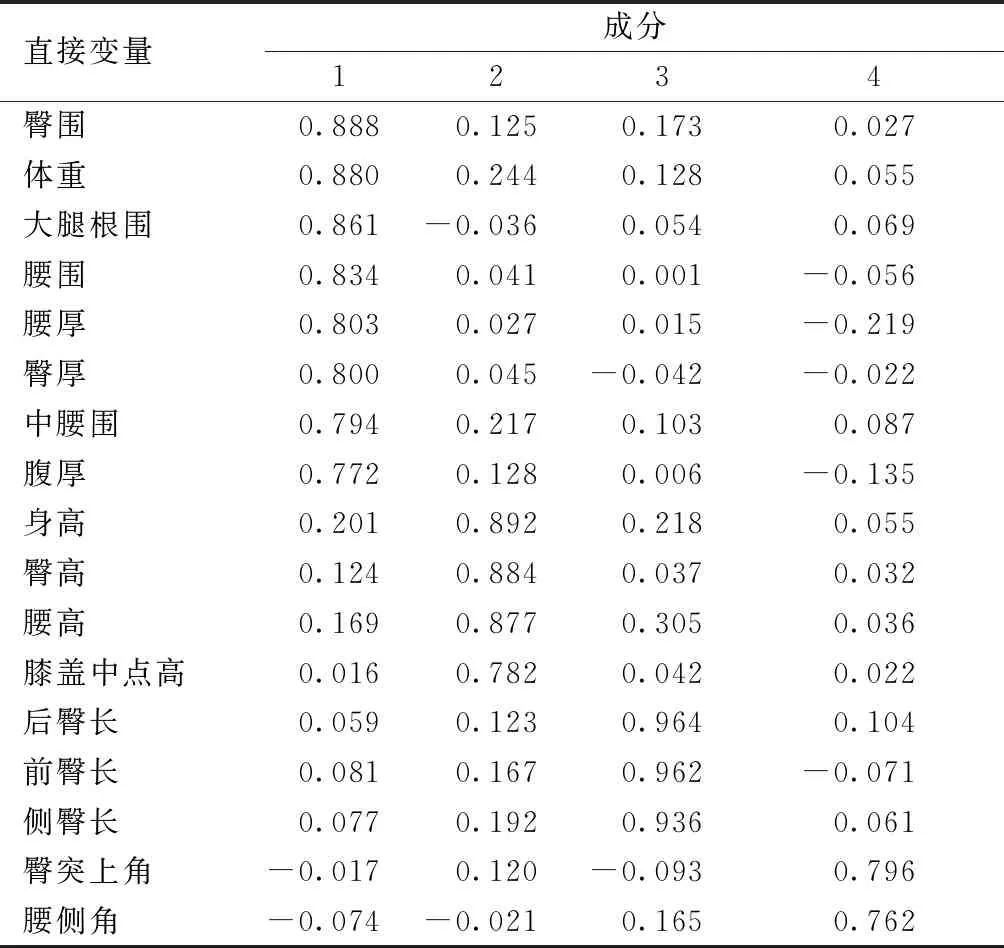
表2 旋转后的成分矩阵Tab.2 Rotating composition matrix

表4 测量部位的间接变量与臀部体型关键部位的单因素方差分析Tab.4 One-way ANOVA between each derived variable and key part of hip body
相关指数与变异系数如表3所示。可以用相关指数与变异系数来决定影响臀部的主要指标。指标的相关指数与变异系数越大,越具有代表性。由表3可知:围度因子的重要指标为体重、臀围、腰围;高度因子的重要指标为身高;由于后臀长的相关指数比其他指标大,与臀角、臀突均存在相关关系,因此臀长因子重要指标为后臀长;角度因子的相关指数值较小,表1中的前3个主要成分的累积贡献率为69.311%,也可代表所有数据的主要信息,因此可省略角度因子。最终确定体重、腰围、臀围、身高、后臀长作为主要影响指标。
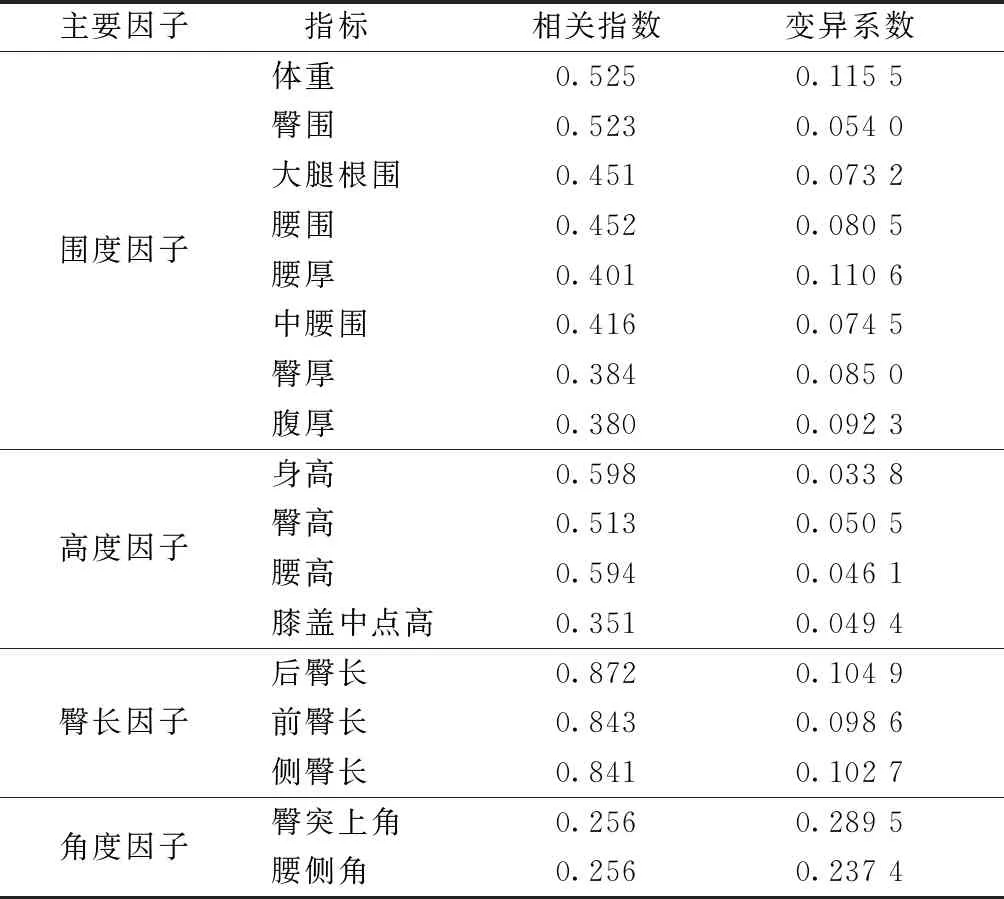
表3 相关指数与变异系数Tab.3 Correlation coefficients and coefficients of variation
2.2 臀部体型分类
国内外最常使用的体型分类方法为K-means聚类方法。本文使用K-means聚类方法对臀部进行分类,参照黄灿艺对福建地区上体下体分类时选择聚类指标的方法,采用单因素方差分析确定最终的聚类指标[12],并以此为依据进行聚类分析。使用长度与围度比、围度差,体重与身高计算得出的BMI值作为间接变量[13]。
表4给出了测量部位间接变量与臀部指标的F值与P值。P值代表显著水平,当P<0.05时,其显著性就越强;而表中只有后臀长腰围比与后臀长臀围显著性效果更好,因此定义其为聚类指标。聚类指标与主要指标的三维散点图如图2所示,2个聚类指标与腰围、臀围、身高、后臀长这4个主要指标均存在线性正相关的关系,且2个变量符合K-means聚类的要求[14],最终确定以这2个间接变量作为聚类指标。
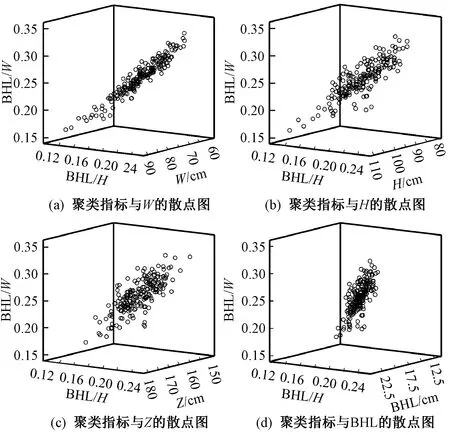
注:BHL为后臀长;W为腰围;H为臀围;Z为身高。 图2 聚类指标与主要指标的散点图Fig.2 Scatter plot of clustering indicators and major variables. (a) A scatterplot of clustering indicators and W; (b) A scatterplot of clustering indicators and H; (c) A scatterplot of clustering indicators and Z; (d) A scatterplot of clustering indicators and BHL
通过体型占比分布与迭代次数来选择[15]K-means聚类中的聚类数,为了给企业提供参考,不应有太多类别。在进行3次分类时的体型占比较为合理,初始聚类数据与最终聚类数据变化较大,迭代次数为12,因此确定将新疆青年女性臀部分为3类。
3种体型用于分类的聚类指标平均值及占比见表5。第1类体型聚类指标的数值最大,描述分析中得知各臀长数值也最大,臀角最小;第2类体型聚类指标的数值适中,身高、腰臀围与厚度、角度适中,且占比最大,可定义为中间体;第3类的聚类指标的数值最小,腰臀围、角度最大。3种体型的示意图如图3所示,参照文献[11]中的臀部体型名称,最终定义为平臀体、中间臀体、翘臀体。
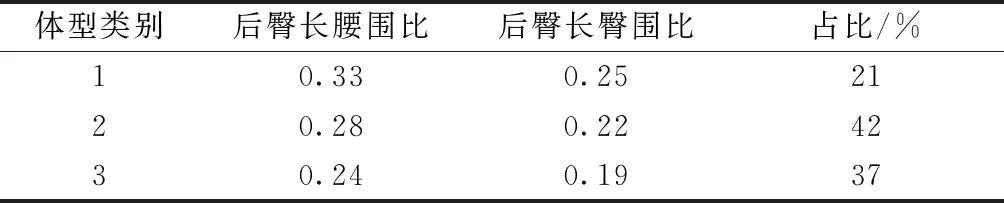
表5 3种体型主要指标平均值及占比Tab.5 Average and proportion of main indicators of three body types

图3 3种臀型示意图Fig.3 Three hip body shape diagram. (a)Face of hip body; (b)Side of hip body
2.3 不同地区臀部基本指标对比分析
表6示出不同地区与时间的女性臀部数据均值比较。由表可知,新疆[16]、上海[17]、东北[3]3个地区的臀部基本指标会随着时间的变化而增长。由此可证明体型的变化与时间也有关系,因此,对新疆青年女性臀部进行体型判别分析,并及时修正原型,设计数据系统是有实用价值的。

表6 不同地区与时间的女性臀部数据均值比较Tab.6 Comparison of waist and hip data mean in different regions cm
3 体型判别
3.1 XGBoost原理
XGBoost算法是一种集中学习模型,把多个分类准确率较低的决策树组合起来,多次迭代并拟合最终值。它具有良好的推理性,可通过较少的决策树得到更高的精度。该算法与传统的梯度树相比,有较好的权衡偏差和方差[18]。其目的在于对原有目标函数进行改写和优化,同时进行泰勒展开,使算法收敛得更快,最终得到最优解,并以此来提升判别精度。
XGBoost算法的目标函数为

式中:γ为复杂度参数;T为叶子节点的个数;λ为正则项惩罚系数;ω为叶子上的权值。
定义一个近似目标函数,设第t次的损失函数为目标函数,用二阶泰勒展开得到的公式为
损失函数的一阶导数gi与二阶导数hi分别为:
定义函数叶子节点一阶与二阶导数之和:
Gj=∑i∈Ijgi,Hj=∑i∈Ijhi
式中,叶子节点样本集合为Ij={i|q(xi=j)},化解得:
对ωi求导,令导数为0,得:
代入ωj,求得最优解目标函数
3.2 样本集确定及超参数调优
本文使用Python软件建立了XGBoost预测模型,用来判别未知的女性臀部体型。XGBoost模型体型判别流程如图4所示,训练与测试的流程相同,在多维特征训练后先让训练集进行机器训练,再通过测试集了解其精准度,最终得出判别结果。

图4 XGBoost模型体型判别流程图Fig.4 XGBoost model body size difference flow chart
模型机器学习的训练集和测试集所占比例为7∶3。XGBoost模型的参数可进行网络调参Xgboost=XGBOSTclassifier(n_estimater=100,learning_rate=0.05)。
3.3 XGBoost模型与其他模型精度比较
将XGBoost算法与支持向量机(SVM)算法、临近算法(KNN)进行精度比较: XGBoost、KNN、SVM训练集的精准度分别为97.8%、97.1%、75.7%,测试集的精准度分别为98.4%、96.8%、74.6%。结果显示,XGBoost算法训练集与测试集的精准度最高。
4 裙装原型修正及实践应用
4.1 中间体裙装原型修正及比较分析
在对人台进行修正后,使用立裁与平面结构方法对版型数据进行调整[19],标准裙装原型与修正裙装原型比较见图5。由图可知,B与B1分别是修正裙装原型和标准裙装原型的后臀长,2种裙装原型的后臀长之差为2.4 cm,证明新疆地区的臀部较翘;地区性的裙装原型前后臀长差值较大,后臀长B比前臀长A长了1.4 cm;标准裙装原型的侧缝线处弧度C比修正裙装原型大,说明角度不同会影响弧度的变化。

图5 标准裙装原型与修正裙装原型的比较Fig.5 Comparison of revised skirt prototype and standard skirt prototype
将不同裙装原型[20]前后片差值进行比较分析发现,新疆、英式、美式裙装原型前后片差值均大于或等于0,国内标准裙装原型前后片差值为-1。这可能是由于人口迁徙相互融合、地域等原因导致新疆地区与国内其他地区青年女性臀部差异较大,本研究可为新疆本地与线上服装生产企业提供参考依据。
4.2 数据系统的应用
新的算法可用于实践研究,可应用到数据系统内,提升体型判别的效率,增加其实用性。本文设计的数据系统有体型判别的功能,先选择XGBoost算法,再输入后臀长腰围比与后臀长臀围比,即可快速获得新疆地区青年女性的臀部体型类别。
5 结 论
1)本文利用主成分因子分析与相关指数、变异系数分析及单因素方差分析确定了2个聚类指标:后臀长腰围比、后臀长臀围比;通过K-means聚类分析法将女性臀部体型分为3类:平臀体、中间臀体、翘臀体。
2)运用XGBoost算法对新疆青年女性臀部体型进行了判别分析,与SVM、KNN算法进行精度比较,结果表明,该算法的训练集与测试集的精准度均在97%以上。
3)利用标准裙装原型与新疆地区青年女性修正裙装原型结构比较发现,修正原型的后臀长比前臀长多1.4 cm,说明新疆地区青年女性臀部与其他地区臀部差异较大。
4)将XGBoost算法模型应用到数据系统中,可提高效率,增加实用价值。
