并行对称矩阵三对角化算法在GPU集群上的有效实现
2021-01-05刘世芳赵永华于天禹黄荣锋
刘世芳 赵永华 于天禹 黄荣锋
1(中国科学院计算机网络信息中心 北京 100190)
2(中国科学院大学 北京 100190)
稠密对称特征值问题存在于科学计算和工程模拟中的许多领域,例如计算材料和计算化学等科学计算应用[1-3].规约稠密对称矩阵为三对角形式是求解对称特征问题的关键一步,且占据了问题求解的大部分时间.因此对稠密对称矩阵三对角化算法进行加速计算是非常必要的.虽然在LAPACK(linear algebra package)[4],ScaLAPACK(scalable linear algebra package)[5]等一些传统的标准库中都可以获得对称矩阵三对角化算法,但硬件发展促使我们重新设计算法以更有效地使用底层硬件.本文基于GPU和CPU的混合架构重新设计了对称矩阵三对角化的并行算法的实现方法,使其可以有效地利用GPU的并行计算能力,降低特征值求解的计算时间.
稠密对称矩阵三对角化一般分为2种方法:1阶段法和2阶段法.标准的1阶段法是直接将稠密对称矩阵通过双边的Householder正交变换转化为三对角矩阵[4].而2阶段法[6-7]包括两步,第1步通过一系列的Householder变换将矩阵规约成一个带状(band)矩阵,这一步运用了许多BLAS(basic linear algebra subroutine)-3(矩阵-矩阵)操作,因此取得了较好的效果[7-9],第2步将带状矩阵转化为三对角矩阵[10].在2阶段法中,由于第1步使用了更多的BLAS-3操作,通常2阶段法要比1阶段法更快.然而,由于2阶段法中第2步的计算不能充分发挥GPU的性能,并且若要求解原始问题特征向量,2阶段法比1阶段法多需要1个额外的转化计算,因此在整体上所需的时间要比1阶段法更多[11].因此,在本文中,我们采用1阶段法.
在1阶段法的三对角化块算法中,主要分为2部分:条块内规约与条块外尾部矩阵的修正.主要的计算量主要集中在条块内规约时的对称矩阵向量积和条块外尾部矩阵的修正.已经有一些工作利用GPU对三对角化中这2部分加速计算[11-12],文献[11-12]采用了仅对尾部对称矩阵的上或下三角部分进行修正的方法,该方法降低了修正过程中的计算量,但使得修正后的矩阵失去了完整性,导致了条块内规约过程中对称矩阵向量积计算变为2个不规则的三角矩阵向量积计算,这种不规则的计算不能充分利用GPU的并行计算能力.针对GPU集群的架构特点,本文给出的算法改进包括4个方面:
1) 给出的三对角化算法是对整个矩阵进行操作,这避免了条块内规约过程中不规则矩阵向量乘运算,但这也带来了一些冗余计算:在条块内修正为规约部分时,不仅要修正列条块内为规约部分,也要修正行条块内未规约部分.但从整体上减少了算法的用时,增加了性能.
2) 增加计算密集度.在条块内规约中将2个小的长条矩阵-向量积合并成1个更大的矩阵-向量积.并且,在条块外尾部矩阵的修正中,将调用2次矩阵-矩阵乘的秩-b修正合并成1个调用1次矩阵-矩阵乘秩-2b修正.加大计算密集度能更加充分发挥GPU的计算能力,增加GPU的利用率,从而提升算法的性能.
3) 利用多个CUDA流同时启动多个CUDA内核,使得在三对角化算法中独立的CUDA操作可以在不同的CUDA流中并发执行.另外,在基于MPI+CUDA的并行算法中,利用了CPU与GPU之间的异步数据传输操作,使得在不同CUDA流中的数据传输操作与GPU内的核函数同时执行,隐藏了数据传输的时间,使得并行算法的性能进一步提高.
4) 采用完全并行的点-点数据通信方式.在并行算法中,由在处理器列上的向量获得对应的在处理器行上的向量操作,若使用全局通信,则需要将属于在处理器列上的各个列处理的部分向量进行全局求和操作,这是一个全局的非并行的通信操作.本文给出的处理器行列之间的向量转置算法是一个完全并行的点-点的并行通信形式:处理器列上的各个处理器并行地将属于本处理器的部分向量发送到对应的处理器行上的处理器,处理器行上的各个处理器并行地接收发送来的数据.这有效地改善了三对角化算法实现的通信性能.
本文三对角化算法的实现是在我们开发的PSEPS(parallel symmetric eigenproblem solver)特征求解器软件包的基础上完成的.我们从多个方面优化了三对角化算法实现,使其主要计算部分并行地在多个GPU上进行加速计算.计算部分通过调用NVIDIA的cuBLAS(CUDA basic linear algebra subroutine)库完成,从而有效地保证了多GPU实现的性能.在中国科学院超级计算机系统“元”上,使用Nvidia Tesla K20 GPGPU卡(峰值双精度浮点性能1.17 TFLOPS)测试了算法的实现性能,取得了较好的加速效果与可扩展性.在对30 000×30 000阶矩阵利用GPU进行加速计算时,文献[8]中利用4个NDIVIA Tesla C2050 GPUs(峰值双精度浮点性能515.2GFLOPS)加速时,性能约为115GFLOPS,约达到峰值性能的22.32%.我们利用4个Nvidia Tesla K20 GPUs时性能约为376.60 GFLOPS,约达到峰值性能的32.19%.
1 三对角化串行块算法

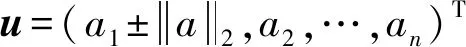
T=Hn-2…H2H1AH1H2…Hn-2
为三对角对称矩阵.
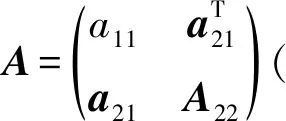
(I-βuuT)A(I-βuuT)=A-uwT-wuT,
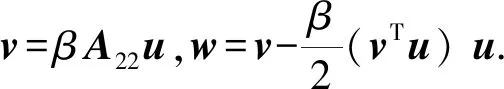
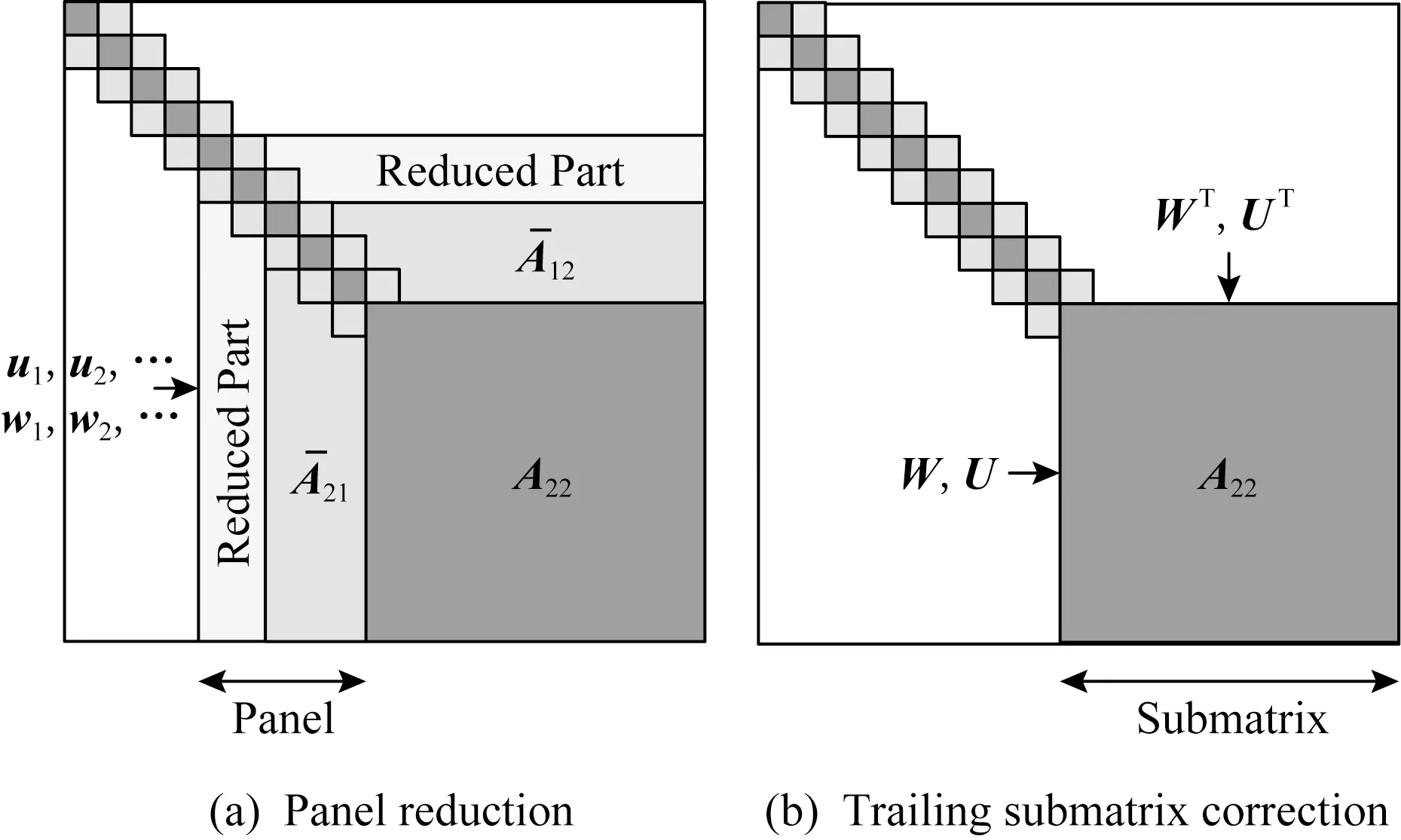
Fig. 1 Panel reduction and trailing submatrix correction图1 条块规约与尾部矩阵修正
块算法将尾部矩阵的秩-2修正聚合为秩-b修正.A22的延迟修正使向量v的生成变得复杂,因为存储在矩阵A22中的元素在条块规约过程中没有及时更新.因此,当求解w时,v的计算需要替换为
v=β(A22-UWT-WUT)u,
其中,UWTu与WUTu对应着尾部矩阵的修正.进一步:

同样,在尾部矩阵A22的修正中:
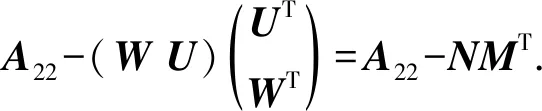
这将需要2次矩阵乘法的秩-b修正合并成了只需要1次矩阵乘法的秩-2b修正.在实现中,我们可以将向量w和u交叉存储在矩阵M和N中:
M=(u1,w1,u2,w2,…,ub,wb),
N=(w1,u1,w2,u2,…,wb,ub).
将这些运算合并成一个更大的计算,这使得计算更加密集,更适合GPU的架构.密集计算可以更加充分地利用GPU的计算能力,从而提升了三对角化算法的性能.

算法1.利用GPU加速计算的三对角化串行块算法.
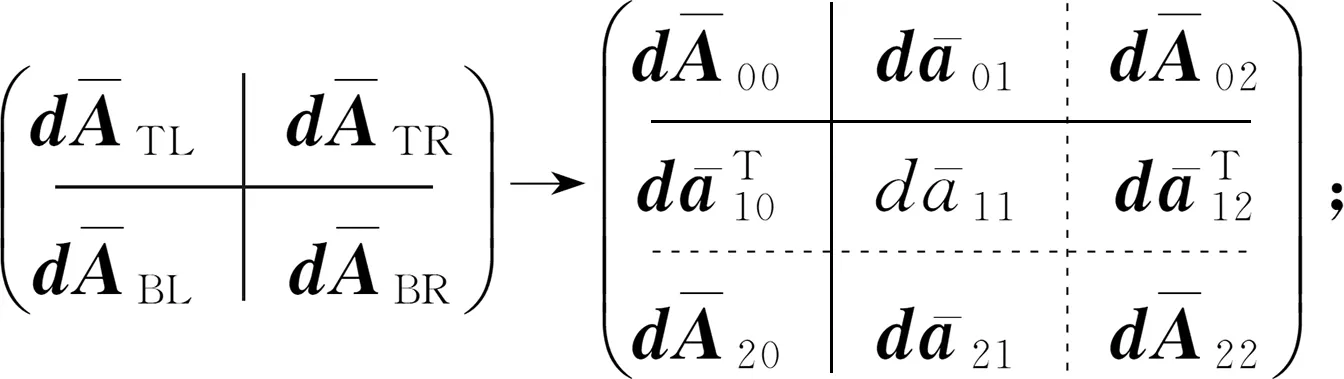
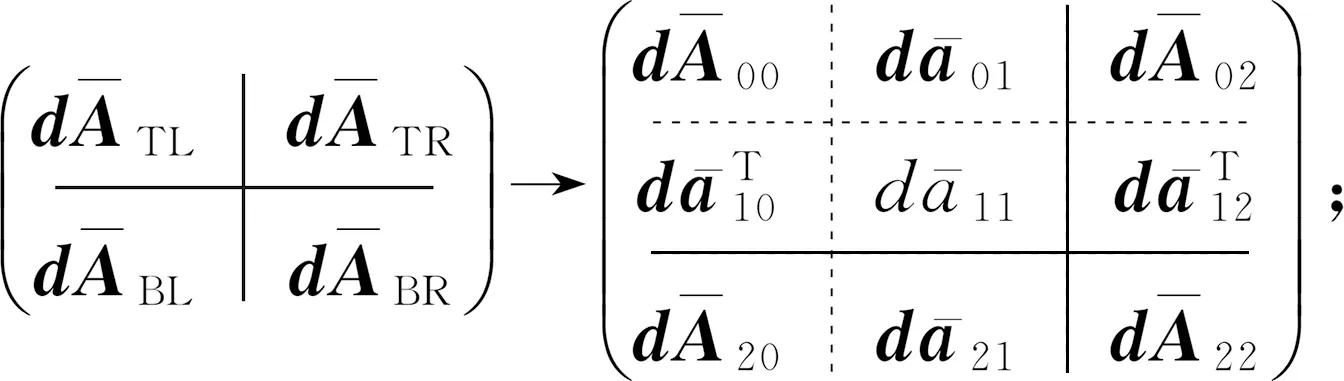
划分矩阵,其中dATL是0×0阶矩阵,置i=1;
do untildABR是0×0阶矩阵{
确定列条块的大小:bc=min{b,dABR的列宽};
重新划分矩阵,其中dA01,dA11,dA21的列数为bc:

/*条块内规约*/
/*将u从GPU传到CPU*/
Synchronize(stream1);
Step1. 计算(u,β,μ)=House(u):
β→φi;μ→zi;i=i+1;
(stream1)u→du;
/*将向量u传到GPU*/
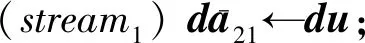
/*将du保存在dA中*/
Step2. 计算矩阵向量积:
Step3. 修正矩阵向量积:
Step3.1. (stream2)dvt=dNTdu;
Synchronize(stream1);
Step3.2. (stream2)dv=dv-βdMdvt;
Step4. 计算修正向量:
Synchronize(stream2);
Step5. 将du和dw交叉保存到矩阵dM和dN中:
Step5.1. (stream1)dM=[dM|du|*];
Step5.2. (stream2)dM=[dM|*|dw];
Step5.3. (stream3)dN=[dN|dw|*];
Step5.4. (stream4)dN=[dN|*|du];
Step6. 更新条块内未规约部分:
Step6.1. 更新列条块:
Step6.2. 更新行条块:
Synchronize(stream1&stream2&stream3
&stream4&stream5&stream6);
对下列矩阵形式继续上述过程:
}end while
Step7. 对尾部矩阵dA22执行秩-2b修正:
(stream1)dA22=dA22-dNdMT;
对下列矩阵形式继续上述过程:

}end do
在算法1内的条块内规约过程中,可以发现Step2和Step3.1以及Step5.1~Step5.4,Step6.1~Step6.2这些操作互不依赖,每个操作可以看成是1个独立的任务,这些任务可以并发执行.在利用GPU进行加速计算的三对角化算法中,可以将每一个CUDA流视为GPU上的1个任务,这样通过启动多个CUDA流,使得这些独立的任务在不同的CUDA流中并发执行,使时间进一步压缩,从而提升三对角化算法的性能.注意在利用多个CUDA流并发启动的三对角化算法中,在有数据依赖的位置需要进行同步操作,以保证算法的正确性,如图2所示:

Fig. 2 Parallel execution with multiple CUDA streams in the panel reduction图2 在条块规约内利用多个CUDA流并发执行
2 基于MPI+CUDA的三对角化并行块算法
2.1 数据在处理器上的分布方式
MPI并行算法的效率较大地依赖数据在处理器间的移动代价,这个代价又与数据在处理器上的初始映射(分布)和处理器间通信所使用的算法有关,并且数据在处理器的分布方式极大地影响着算法的负载平衡和通信特性.在稠密线性代数中,当前普遍使用的是2维块循环分布.2维块循环具有支持可拓展的高性能并行稠密线性代数编码的特性[14-16],并被HPF(high performance fortran handbook)[17],ScaLAPCK[5]和其他并行稠密线性代数库选为首要的数据分布.因此在基于MPI+CUDA的并行三对角化块算法中,我们采用了2维块循环的数据分布方法.将稠密对称矩阵A采用2维块循环方式分布到p=pr×pc处理器网格中,存储块的大小为b.这里,假设矩阵A的元素A(1,1)映射到处理器p(0,0)中的本地矩阵元素为Aloc(1,1),则全局元素A(i,j)映射到处理器
中的本地矩阵元素为Aloc(iloc,jloc),其中

2.2 MPI通信方式
在2维通信域中,处理器间的通信通常发生在处理器网格中同行处理器之间或同列处理器之间.在行、列映射方式下矩阵的整行或整列被播送.基于MPI+CUDA并行三对角化算法中的通信主要操作包括行播送、列播送、行聚集求和、转置操作.
1) 行播送.2维通信域中处理器行内某处理器将数据广播到该处理器所在行的所有处理器,在算法2中此操作用Rbroadcast表示.
2) 列播送.2维通信域中处理器列内某处理器将数据广播到该处理器所在列的所有处理器,在算法2中用Cbroadcast表示.
3) 行聚集求和.在处理器行上对数据进行聚集求和,在算法2中用Rsum表示.
4) 转置操作.将处理器行/列上的向量转置到对应的处理器列/行上的向量.在算法2中用Transpose表示.
2.3 基于MPI+CUDA的并行块算法
基于串行的利用GPU加速计算的的三对角化块算法1,算法2给出了基于MPI+CUDA的并行三对角化块算法在GPU集群上的实现.在算法2中,(GC-数字)表示数据从GPU传到CPU,(CG-数字)表示数据从CPU传到GPU.(CC-数字)表示CPU之间的通信操作.(G-数字)表示在GPU端的操作.算法2中的变量前边加“d”表示在GPU端对应的变量.
在基于MPI+CUDA的并行算法2中,除了将独立的CUDA操作在不同的CUDA流中进行运算,还利用了CPU与GPU之间的异步数据传输操作,使得在不同CUDA流中的数据传输操和GPU内的核函数同时执行: (G-3)GPU内的拷贝操作与(GC-3)数据传输操作,(CG-4)数据传输操作与(G-4) GPU内的计算操作.这可以隐藏CPU与GPU之间数据传输的时间,使得基于MPI+CUDA的并行算法的性能进一步提高.

算法2.基于MPI+CUDA的并行三对角化块算法.
/*算法中的dot表示向量的点乘运算,scal表示向量的数乘运算,copy表示向量的拷贝操作,gemv表示矩阵-向量乘运算,axpy表示向量的加法运算,ger表示矩阵的一阶修正运算,gemm表示矩阵-矩阵乘运算*/
for eachbt∈[1,bn]
as=bt×b;/*条块内第一列*/
ae=min(as+b-1,n-2);/*最后一列*/
for eachk∈[as,ae] /*条块内规约*/
Step1. 计算Householder向量及其范数:
ifk∈CSthenCS=CS(k) endif
ifk∈RSthen
Step1.1. (GC-1) (stream1)dA(k,CS)→uc;
Synchronize(stream1);
Step1.2. (CC-1)Cbroadcast(uc);
Step1.3. (CG-2) (stream1)uc→duc;
endif
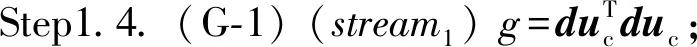
/*dot*/
Synchronize(stream1);
Step1.5. (CC-2)t=Rsum(g);
ifj+1∈CSthen /*行播送*/
Step1.6. (CC-3)Rbroadcast(u(k+1));
endif
Step1.7. 计算次对角元素μ和范数β
Step1.8. (G-2) (stream1)duc=βduc;
/*scal*/
ifk∈RSthen
Synchronize(stream1);
Step1.9. (G-3) (stream2)duc→dA(k,CS);
/*copy*/
endif
ifk∈RSthenRS=RS(k) endif
Step1.10. (GC-3) (stream1)duc→uc;
Synchronize(stream1);
Step1.11. (CC-4)ur=Transpose(uc);
ifk+1∈CSthen
Step1.12. (CC-5)Rbroadcast(ur);
Step1.13. (CG-4) (stream2)ur→dur;
endif
Step2.计算矩阵向量积(gemv):
(G-4) (stream1)dxr=βdA(RS,CS)duc;
Step3. 修正矩阵向量积:
Step3.1. (G-5) 计算部分向量dxr(gemv×2)
Synchronize(stream1&stream2);
(G-5.2) (stream0)dxr-=dMrdxt;
Step3.2. (GC-5) (stream0)dxr→xr;
Synchronize(stream0);
Step3.3. (CC-6)wr=Rsum(xr);
Step3.4. (CG-6) (stream2)wr→dwr;
Step3.5. (CC-7)wc=Transpose(wr);
ifk∈RSthen
Step3.6. (CC-8)Cbroadcast(wc);
Step3.7. (CG-7) (stream1)wc→dwc;
endif
Step4. 修正矩阵向量积:

/*dot*/
Synchronize(stream1);
Step4.2. (CC-9)σ=Rsum(s);
Step4.3. (G-7) 计算dwc,dwr(axpy×2);
Synchronize(stream1&stream2);
Step5.(G-8) 将向量dwr,dwc,dur,duc交叉保存到矩阵dMr,dNc的相应位置(copy×4):
(G-8.1) (stream1)dMr=[dMr|dur|*];
(G-8.2) (stream2)dMr=[dMr|*|dwr];
(G-8.3) (stream3)dNc=[dNc|dwc|*];
(G-8.4) (stream4)dNc=[dNc|*|duc];
Step6. (G-9)更新条块内未规约部分:
(G-9.1) (stream5) /*ger×2*/
(G-9.2) (stream6) /*ger×2*/
Synchronize(stream1&stream2&stream3&
stream4&stream5&stream6);
endfor
Step7. 对尾部矩阵执行秩-2b修正(gemm):
Synchronize(stream0);
endfor


Fig. 3 Operations of Algorithm 2图3 算法2的操作
图4描述了将处理器列上的向量vc转置到对应的处理器行上的向量vr的过程,每一个列处理器并行的将部分向量发送到对应的行处理器上,行处理器并行地接收部分向量:pse,0→pre,0,pse,1→pre,1,pse,2→pre,0,pse,3→pre,3.将处理器行上的向量转置到对应的处理器列上的操作类似,这里不再讨论.

Fig. 4 Transpose operation图4 转置操作
CPU+GPU的异构编程需要CPU与GPU之间的数据传输,要想利用GPU进行加速计算,需要将计算数据上传到GPU端.因为使用的多个GPU分布在多个节点上,则GPU间的通信需要在CPU中通过MPI进行,首先将要通信的数据从GPU端传回到CPU端,之后通过MPI通信,通信完成后,再将数据传回到相应GPU中.算法2中CPU与GPU的数据传输操作如图2所示,共有7次.
3 实验结果与分析
因为Frank矩阵
A=(aij),aij=n-max(i,j)-1,
i,j=1,2,…,n
具有解析特征值:
所以为了验证算法实现的准确性和测试算法的性能,我们使用了Frank矩阵作为测试数据.
我们在中国科学院计算机网络中心超级计算机系统“元”上实现了本文描述的算法,并在GPU队列上进行测试.每台GPGPU计算节点配置2块Nvidia Tesla K20 GPGPU卡(峰值双精度浮点性能(板卡)1.17 TFLOPS),2颗Intel E5-2680 V2(Ivy Bridge|10C|2.8 GHz)处理器.使用的cuBLAS版本是6.0.37,使用的MPI是openmpi-1.8.4.在测试时,为了使得多个GPU并行加速计算,每个节点申请2个进程,1个进程对应1个GPU.测试的数据类型是双精度浮点数.
3.1 基于MPI+CUDA的三对角化并行块算法性能分析
表1展示了20 000×20 000阶矩阵三对角化块算法在CPU调用上MKL(math kernel library) 2013的BLAS库和通过多个CUDA流并发调用GPU的cuBLAS库使用不同进程数(1,2,4,8,16,32)时的时间对比.从表1中可以看出,首先利用GPU进行加速计算的三对角化算法取得了明显的加速效果.其次,随着使用GPU数目的增多,加速倍数在不断减小,这是因为随着随着使用GPU数目的增多,在单个GPU上负载减小,并且随着进程数目的增多,通信时间、CPU与GPU之间的数据时间等开销占比增大,因此计算加速效果不如负载大的好.总的来说,利用GPU对三对角化算法进行加速取得了较好的加速效果(这里b=64).
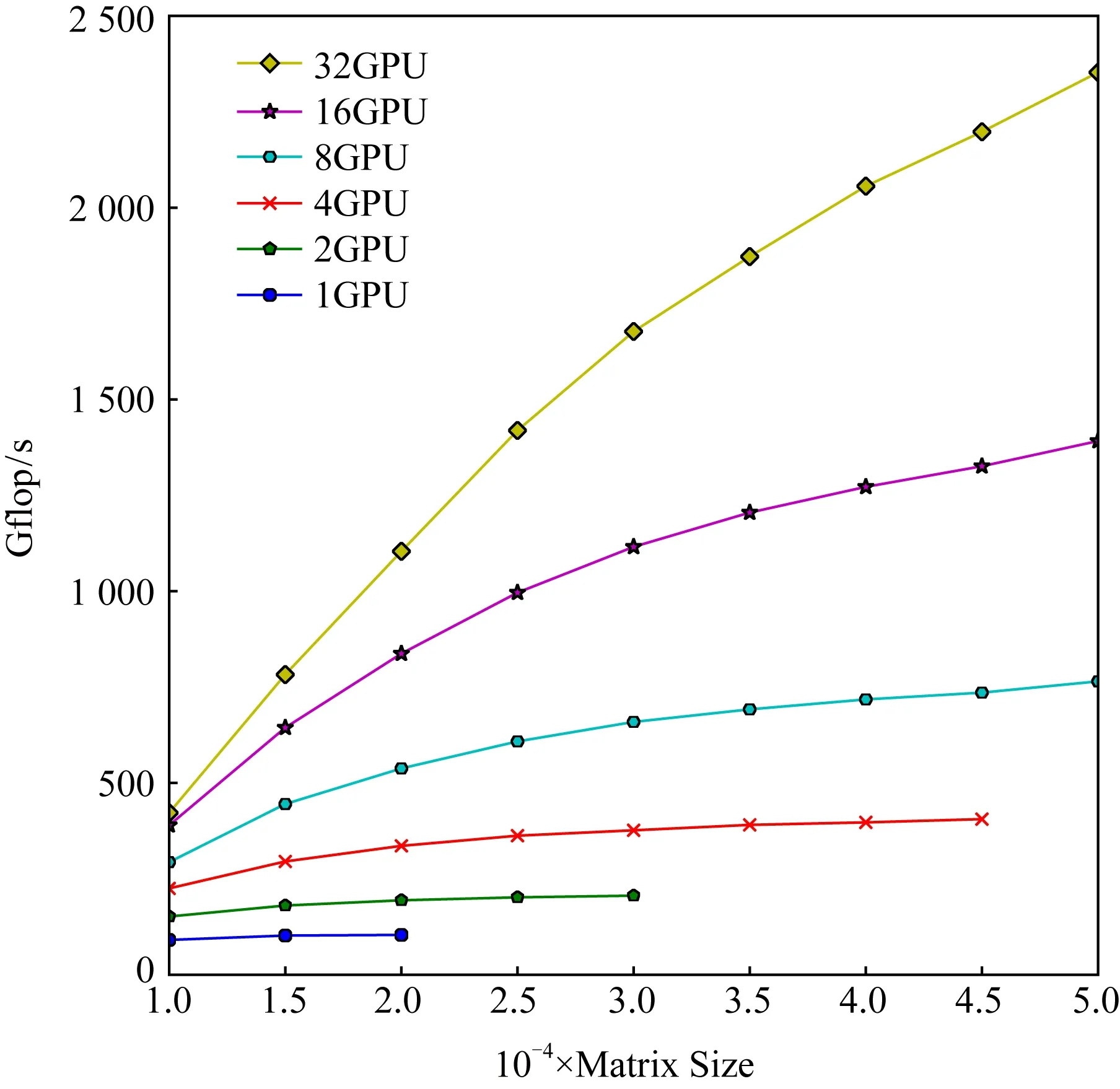
Fig. 5 Peak performance of tridiagonal parallel algorithm图5 并行三对角化算法的峰值性能
图5展示了当b=64时不同规模的矩阵使用不同GPU个数(1,2,4,8,16,32)时达到的性能.从图5中可以发现,在使用GPU的数目一样时,矩阵规模越大达到的性能越高,这是因为问题规模越小,GPU的负载越小,而GPU适合计算密集型任务,这样加速效果就不如规模大的好.并且规模越大,计算时间所占的比例越大,加速效果越明显,则达到的性能越高.从图5可以看出,基于MPI+CUDA的三对角化并行块算法取得了较好的性能.
图6展示了不同矩阵规模(10 000×10 000,15 000×10 000,20 000×20 000,25 000×25 000,30 000×30 000)使用不同个数的GPU进行加速计算时相对于使用1个进程/GPU时加速比曲线.
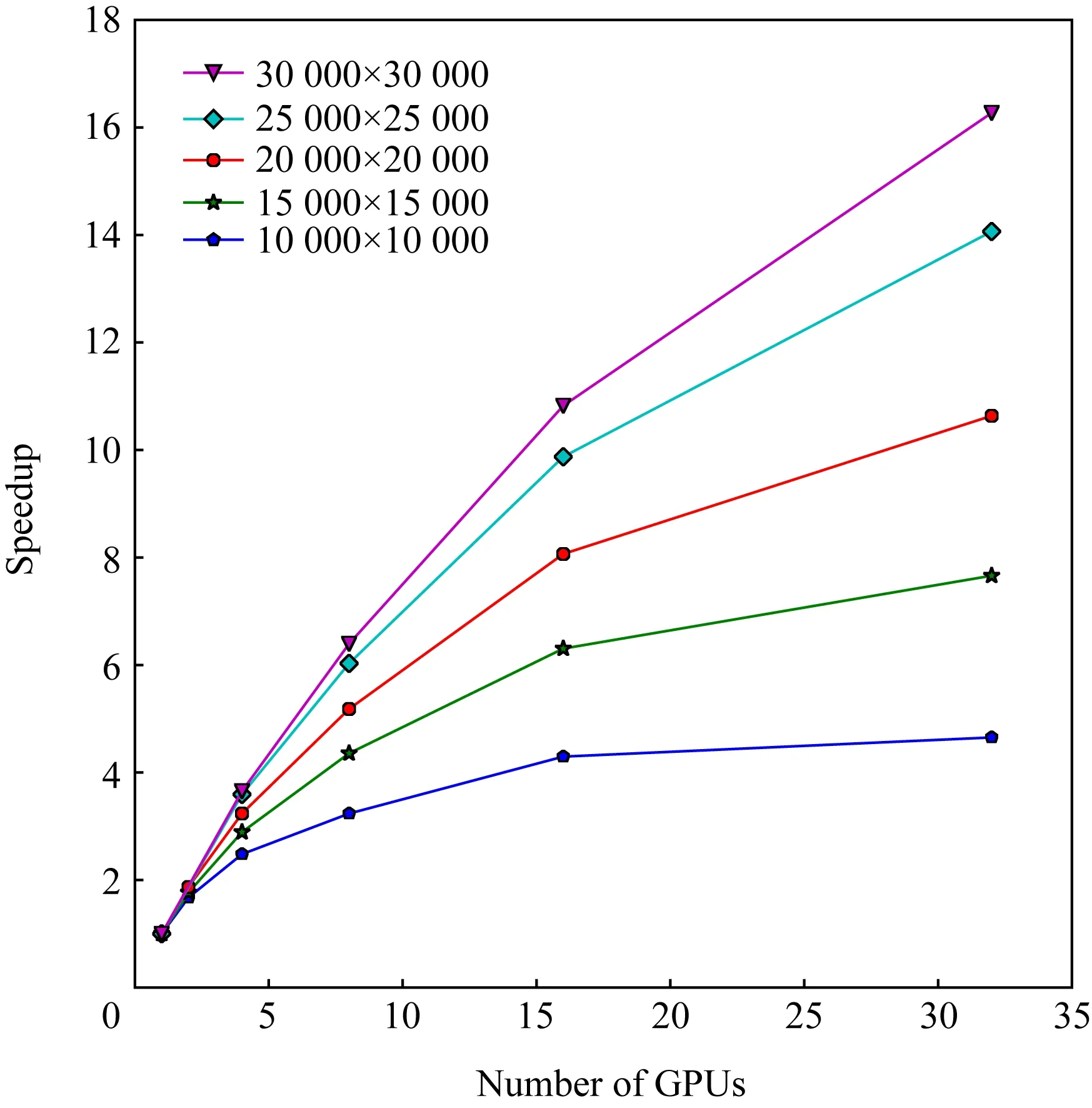
Fig. 6 Speedup curves for different matrix size图6 不同矩阵规模的加速比
从图6中可以看出当矩阵规模一定时,随着使用GPU数目增加,加速比增加的幅度在不断降低,这是由于随着使用GPU个数增加,GPU与CPU之间的数据传输、通信等开销所占的比例增加导致的.当使用的GPU的数目一样时,较大规模矩阵的加速比大于较小规模矩阵的加速比,加速比随着矩阵规模的增大而增大,这是因为大规模的矩阵在GPU上的负载较大,比小规模矩阵更能够充分地利用GPU的计算能力.并且,随着使用GPU数目的增多,较大规模的加速比与较小规模的加速比相差越来越大,这是因为在单个GPU上的负载越大,取得的性能越好.总的来说,基于MPI+CUDA的三对角化并行块算法具有良好的可扩展性.
3.2 加大计算密集度的算法性能分析
不同的条块(矩阵存储块)的大小会影响三对角化算法的性能,当三对角化算法只启动1个CUDA流时,分别测试了如表2所示的当b分别取值32,64,128时的不同规模的矩阵(10 000×10 000,20 000×20 000,30 000×30 000)利用不同GPU个数(2,4,8,16)加速时的用时.可以看出,当b=64时用时最短,因此在只启动1个CUDA流的三对角化算法的分析中,取b=64.
表3展示了在三对角化算法中启动1个CUDA流时20 000×20 000阶矩阵使用1个GPU加速时各个计算部分在GPU上的用时.其中,算法2中(G-4)gemv计算条块内规约的矩阵向量积v=Au的计算量约为4n3/3,占据了在GPU上计算总时间的约86.62%,因此,采用完整的矩阵进行运算提升这部分的性能,将会提升整个程序的性能.
表4展示20 000×20 000阶矩阵的使用不同GPU个数(4,8,16,32)时分别采用对上三角和下三角直接调用2次cublasDgemv与使用完整矩阵只调用1次cublasDgemv的时间对比,可以发现采用完整矩阵的方式这部分时间减少了约一半,又因为这部分占了三对角计算时间的大部分,这部分性能的提升将会大幅度提升整个算法的性能.但采用完整矩阵的方式将增加(G-9)ger的计算量,表5展示了增加前后的时间对比,虽然这部分的用时增加了,但是相对于(G-4)gemv时间的减少这部分的增加的时间非常少,因此整个程序的性能相对提升了.
对条块内第(G-5)gemv步进行优化,将原来需要4次矩阵向量积的运算合并成只需要2次矩阵向量积的运算.表6展示了20 000×20 000阶矩阵的使用不同GPU个数(1,2,4,8,16,32)时合并前后的时间对比,从表6中可以发现,将矩阵-向量运算合并后,这部分的时间减少了大约42%.这是因为将小规模的矩阵向量乘运算合并成较大规模的矩阵向量乘运算后,更加充分地利用了GPU的资源,因此程序的性能得到了进一步地提升.
(G-10)gemm条块外尾部矩阵的秩-2b修正计算量约为4n3/3,虽然这部分的计算量与(G-4)gemv的计算量一样,但占据的时间仅为7.27%(20 000×20 000阶矩阵使用1个GPU加速时),这2部分时间占比相差非常大是因为BLAS-2与BLAS-3对GPU的利用率不同导致的.在(G-10)gemm中我们将需要2次gemm的秩-b修正合并成调用1次gemm的秩-2b修正,表7展示了20 000×20 000阶矩阵使用不同GPU个数(1,2,4,8,16,32)时优化前后的时间对比,从表7可以发现,将秩-b修正合并为秩-2b修正后,此部分的时间约减少了23%.合并计算后使得计算更加密集,更加充分地利用了GPU的计算能力,提高了GPU的利用率,因此获得了更高的性能.
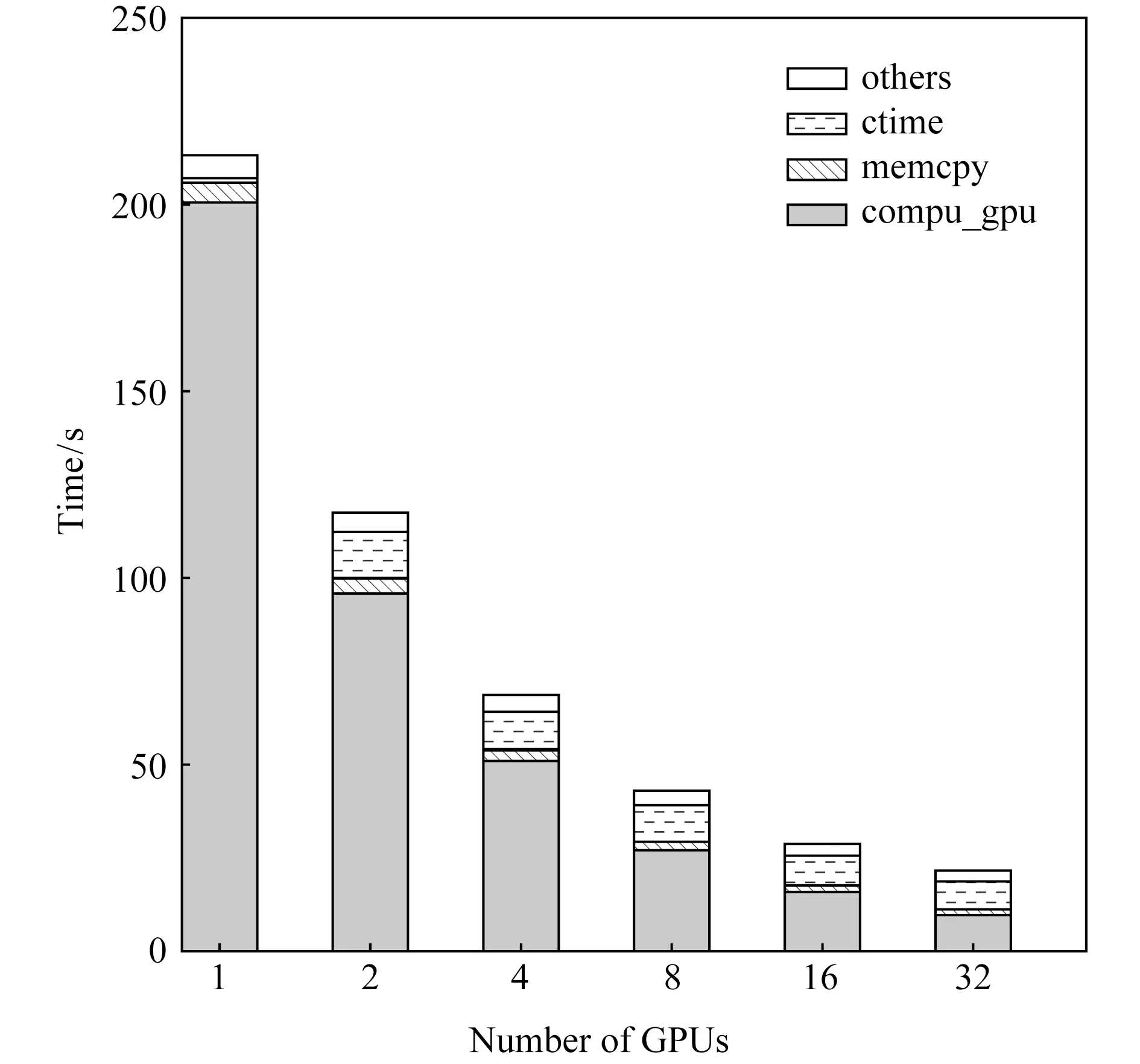
Fig. 7 The time of each part of tridiagonal parallel algorithm图7 并行三对角化算法各部分的时间
图7展示了在三对角化算法中启动1个CUDA流时20 000×20 000阶矩阵使用不同GPU数目(2,4,8,16,32)加速时三对角化算法各个部分所用占用的时间(compu_gpu表示在GPU上的计算时间;memcpy表示CPU与GPU之间的数据传输时间;ctime表示CPU之间的通信时间;others表示其他时间).从图7中可以看出,在整个三对角化的过程中,计算时间占据了大部分,因此利用GPU进行加速计算能够明显提升三对角化算法的性能.并且,随着GPU的数目增多,计算时间compu_gpu逐渐递减.同时,通信时间ctime随着处理器数目(从2个开始)的增加也在逐渐递减.总的来说,整个基于MPI+CUDA的三对角化算法的用时随着使用GPU数目的增多逐渐递减,整个算法表现出了良好的强扩展性.
3.2 利用多个CUDA流的算法性能分析
在通过多个CUDA流并发调用多个GPU内核的三对角化算法中,我们同样测试了条块(矩阵存储块)b取不同值(32,64,128)时对不同规模的矩阵(10 000×10 000,20 000×20 000,30 000×30 000)利用不同GPU个数(2,4,8,16)加速时的影响,如表8所示,当b=64时用时最短,因此在启动多个CUDA流的三对角化算法的分析中,取b=64.
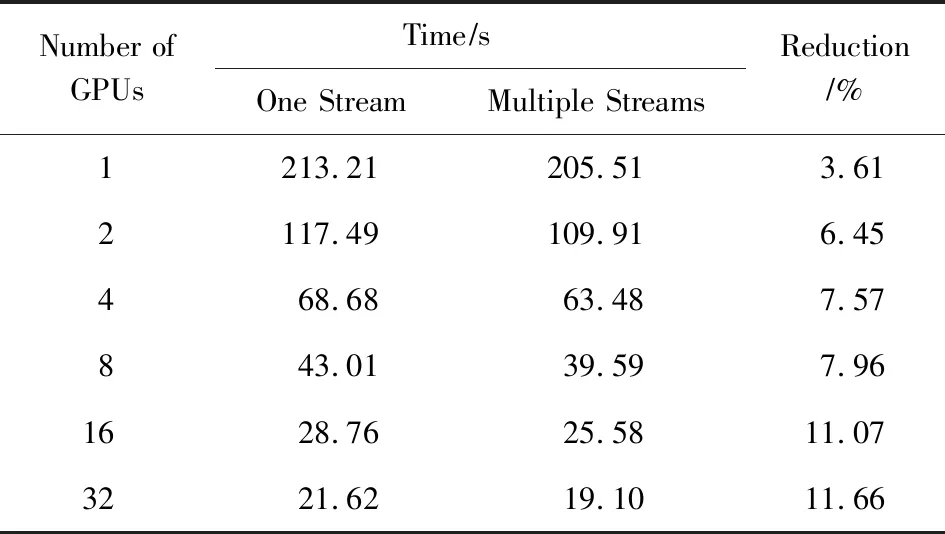
表9展示了在基于MPI+CUDA的并行三对角化块算法中启动1个CUDA流与启动多个CUDA流时,20 000×20 000阶矩阵使用不同进程数(1,2,4,8,16,32)时的时间对比,可以发现启动多个CUDA流相比于只启动1个CUDA流用时更短,取得了较好的加速效果.另外随着进程数目的增加,加速效果越来越好,这是因为随着进程数目的增加,在单个GPU上的负载不断减小,GPU中可用的SM(streaming multiprocessor)等资源越多,多个流并发执行的可能性越大,因此规模越小,加速效果越好.
Table 9 Time Comparison Between Starting a CUDA Stream
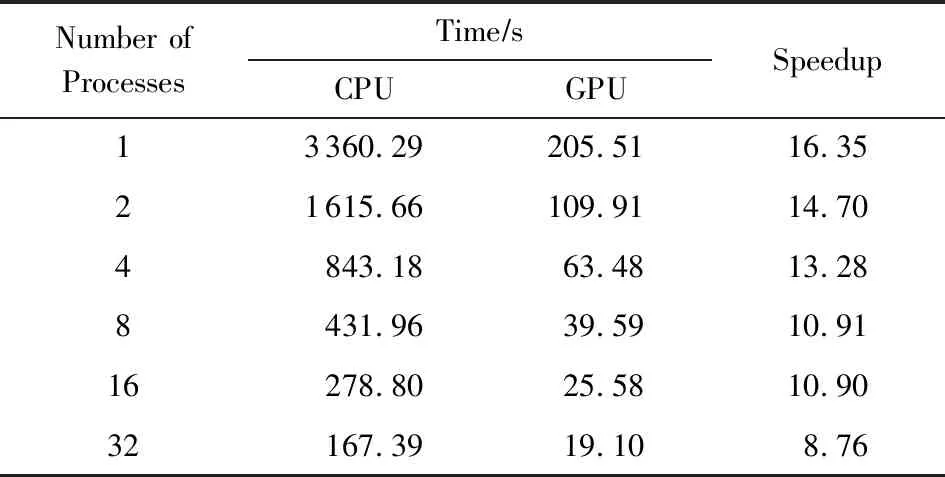
Table 1 Time Comparison of Using CPU or GPU表1 使用CPU或GPU的耗时比较

Table 2 Time Comparison for Different Matrix Size with b Taking Different Size表2 不同规模的矩阵当b取不同大小时的耗时比较 s

Table 3 Time and Proportion of Each Calculation Part表3 各个部分计算部分用时和占比

Table 4 Time Comparison of Calling cublasDgemv Twice and Once表4 调用2次cublasDgemv与1次cublasDgemv的 耗时比较 s

Table 5 Time Comparison of Before and After (G-9)ger Increase表5 (G-9)ger增加前后耗时比较 s
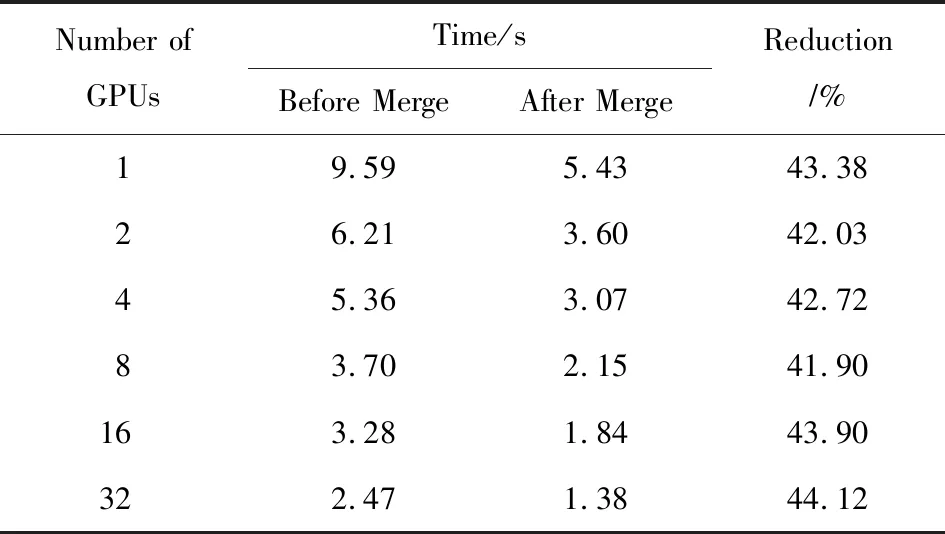
Table 6 Time Comparison Before and After Merge of the(G-5)gemv Within the Panel Reduction表6 条块内规约(G-5)gemv合并前后耗时比较

Table 8 Time Comparison for Different Matrix Size with b Taking Different Size表8 不同规模的矩阵当b取不同大小时时间对比 s

Table 10 Time Comparison Between Starting a CUDA Stream and Multiple CUDA Streams of Different Scale Matrices When Using 32 GPUs表10 不同规模的矩阵使用32个GPU加速时启动1个 CUDA流与多个CUDA流的时间比较
and Multiple Streams of 20 000×20 000 Order Matrix
表9 20 000×20 000阶矩阵启动1个CUDA流与多个CUDA流的时间比较
Number ofGPUsTime∕sOne StreamMultiple StreamsReduction∕%1213.21205.513.612117.49109.916.45468.6863.487.57843.0139.597.961628.7625.5811.073221.6219.1011.66
表10展示了不同规模的矩阵(10 000×10 000,20 000×20 000,30 000×30 000,40 000×40 000,50 000×50 000)利用32个GPU进行加速计算时启动1个CUDA流与启动多个CUDA流时的时间比较,可以发现随着矩阵规模的增大,加速效果不断减小.这是因为,虽然从软件的角度来看,CUDA操作在不同的流中并发运行;而从硬件上来看,不一定总是如此.根据每个SM资源的可用性,完成不同的CUDA流可能仍然需要互相等待.矩阵规模的越大,GPU上的负载越大,而GPU中SM资源是有限的,规模越大,需要的资源越多,因此多个内核同时并发执行的可能性就越小.并且,多个CUDA流并发执行,所用的总时间主要去取决于用时最多的那个任务,利用多个CUDA流并发调用多个内核,并没有减少用时最长的任务所用的时间,在三对角化算法中,主要是条块内规约中的矩阵向量积(G-4)gemv操作,矩阵规模越大,这部分的计算时间占的比例越多,因此对于整个三对角化算法,利用多个CUDA流并发调用多个内核,问题规模越大加速效果反而不如规模小的明显.总的来说,在单个GPU上的负载越小,利用多个CUDA流进行并发操作提升的性能越明显.
4 结束语
本文描述了基于MPI+CUDA的稠密对称矩阵三对角化并行块算法在GPU集群上实现,主要的计算部分由GPU完成,而通信部分在CPU上通过MPI来完成,从而充分发挥CPU+GPU的异构平台的优势.为了适应GPU架构,我们重构了算法,在条块内规约过程中的对称矩阵向量相乘时使用了完整的矩阵,虽然带来了额外的计算,但比直接分别对上三角和下三角矩阵进行2次矩阵-向量相乘时时间明显减少.同时,在条块内规约中合并了一些矩阵-向量积运算,这部分的时间减少了约42%.而且,在条块外尾部矩阵的修正过程中,将矩阵的秩-b修正合并为秩-2b修正,此部分的时间约减少了23%.本文提出的三对角化算法通过加大计算密集度来发挥GPU的计算能力,增加GPU的利用率,从而提升了算法的性能.另外,在三对角化算法中,对在GPU中互不依赖的操作,利用了多个CUDA流同时启动多个内核,使这些独立的CUDA操作可以在不同的流中并发执行,使得时间进一步压缩.并且,在基于MPI+CUDA的并行三对角化算法中,利用了CPU与GPU之间的异步数据传输,使得在不同流中的数据传输与核函数同时执行,隐藏了数据传输的时间,进一步提升了并行算法的性能.在三对角化并行算法中,块的大小将会影响通信次数、负载平衡以及利用GPU计算的性能,在使用时需要权衡.总的来说,本文中的异构三对角化算法取得了较好的性能与加速效果,并且具有良好的可扩展性.
