一种在复杂环境中支持容错的高性能规约框架
2018-10-30李超赵长海晏海华刘超文佳敏王增波
李超, 赵长海, 晏海华,*, 刘超, 文佳敏, 王增波
(1. 北京航空航天大学 计算机学院, 北京 100083;2. 中国石油集团东方地球物理勘探有限责任公司 物探技术研究中心, 北京 100088)
在高性能计算和并行计算领域中,规约是最常用的集合通信原语之一。规约的目标是将各进程上的数据按某种操作,如求和或求积,计算为最终结果,并将该结果存放在指定的进程上。存放结果的进程称为根进程。目前,最广泛使用的规约实现为MPI_Reduce[1]。Rabenseifner等[2]统计发现,在基于MPI实现的并行应用中,耗费在MPI_Reduce和MPI_Allreduce上的时间占所有MPI函数执行时间的40%以上,而MPI_Allreduce又可分解为MPI_Reduce加MPI_Bcast。因此,规约的性能及可靠性对并行应用具有重要的意义。
在规约的性能优化研究中,早期研究主要集中于在理想计算环境中达到最优性能的规约算法。理想计算环境是指集群中每个计算节点配置均为一致,任意两节点间的网络延迟均相同,且并行应用在规约过程中独占集群资源。文献[3]提出了基于最小生成树(MST)的规约算法,MPICH早期版本[4]的规约实现也采用该算法。文献[5]提出了3种规约算法:向量对分和距离加倍(vector halving and distance doubling)、二元块(binary blocks)以及环形(ring)算法。目前主流MPI版本,包括Open MPI、MPICH、MVAPICH等,所采用的规约算法是二项树算法和Rabenseifner算法[5]。MST和二项树算法的时间复杂度如式(1)中的T1所示,Rabenseifner算法的时间复杂度如式(1)中的T2所示。
(1)
式中:a为两节点间的网络通信延迟;β为传输一个字节所耗费的时间;n为消息长度;γ为对一个字节进行规约计算时所耗费的时间;p为进程总数。
实际环境中,各节点间的网络延迟受网络拓扑结构影响,不同节点间的网络延迟可能不同。针对该问题,出现了一系列基于网络拓扑感知的规约性能优化研究。文献[6]给出了一种网络拓扑发现方法,该方法根据各节点间网络延迟大小,构建了一个多级网络拓扑结构,再根据该拓扑构建性能更优的二项树结构。基于相同研究思路的还有文献[7-11]。文献[12]提出了一种在广域网上优化规约性能的方法,其核心思路是尽量将计算和通信局限在局域网内部,以最大程度地降低需要通过广域网传输的数据量。
以上研究均建立在静态计算资源模型之上,即假定在规约执行过程中,各计算节点的CPU性能、内存性能以及任意两节点间网络延迟皆固定不变。然而,在真实环境中,该假设在多数情况下难以成立,具体表现在以下几方面:
1) 在基于商用集群搭建的高性能计算环境中,为提高集群的资源利用率,多个并行应用通常会被调度至同一集群上。由于受其他应用干扰,导致规约在执行过程中所依赖的计算资源的性能是动态变化的。
2) 对于非阻塞规约,由于应用的主体计算部分可以和规约同时执行,主体计算引起的计算资源动态变化也会影响规约的执行,且此种干扰无法避免。
3) 同时执行多个规约时,即并发规约,各规约之间会产生相互干扰。
静态计算资源模型假设的特殊性,导致传统的规约性能优化方法不能较好地适用于真实环境。除了动态变化的计算资源性能外,在真实计算环境中还需要考虑节点故障问题。随着集群规模的不断增大,集群的平均无故障时间(Mean Time Between Failures, MTBF)不断下降,根据文献[13-14]的统计数据,当集群规模达到数百节点时,集群的MTBF将降到6~7 h,这导致规约在运行过程中遇到节点故障的概率亦随之增加。节点故障会直接导致该节点上的进程无法参与计算。传统的基于检查点/重启[15-16]的容错方法越来越不适用于大规模集群环境,这是因为检查点/重启需要应用进行停止、重新启动、映像加载、状态回滚等一系列操作,这些操作均会带来较大开销,严重影响应用的性能。FT-MPI[17]和MPI 3.0标准提供了一种为应用返回集合通信接口执行状态的机制,但并未尝试如何在应用不退出的前提下,恢复遭遇节点故障的规约操作。而基于算法容错的相关研究[18-20],目前只能解决一些简单的集合通信接口的容错问题以及与矩阵计算相关的容错问题,也未能解决规约的容错问题。当规约过程中遇到节点故障时,如何在应用不退出的前提下,保证规约可以继续进行,是一个亟待研究的重要问题。目前该问题尚未得到良好解决。
本文复杂环境是指,节点的计算资源性能是不断动态变化的,且会出现节点故障。当前的规约算法和实现无法较好适应该类环境,无法实时地根据节点计算资源的性能对计算进行动态调整,也无法有效处理节点故障。本文以在动态复杂环境中提供高性能、高可靠的规约算法为目标,提出了一种基于任务并行的高性能分布式规约框架,实验结果显示,在复杂环境中,其具备更高的性能及更高的可靠性。
1 分布式规约框架
图1为分布式规约框架的架构示意图,框架采用Master/Worker结构组织所有进程,0号进程为Master。在分布式规约框架中,每个规约实例均被分解为一系列可并行执行的独立计算任务。Master节点上的规约调度器负责调度规约计算任务,Worker节点上的规约执行器则负责执行规约计算任务。在规约执行过程中,由数据可靠性模块负责保证原始规约数据的可靠性;容错模块负责故障节点的检测、通知以及故障恢复;性能计数器实时统计各节点的性能状态;调度器根据性能计数器和容错模块提供的信息,将计算任务实时调度到性能更高的无故障节点上。
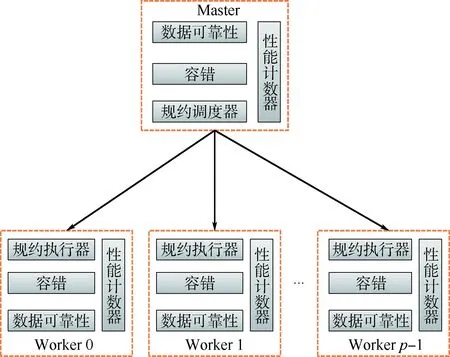
图1 分布式规约框架的架构Fig.1 Architecture of distributed reduction framework
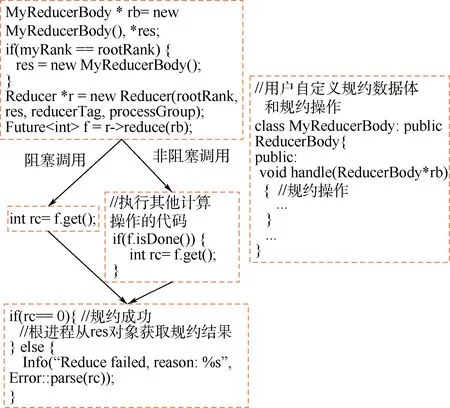
图2 分布式规约接口Fig.2 Distributed reduction interface
图2为分布式规约框架的规约接口示意图,应用可通过继承ReducerBody自定义规约数据及具体的规约操作;使用规约接口时,可指定根进程、存储规约结果的对象res、规约标识符以及参与规约的进程组;规约接口支持阻塞调用和非阻塞调用2种方式。规约接口调用后,会返回一个Future对象f。f将规约的阻塞模式和非阻塞模式统一为一个接口。应用可调用f的get接口进入阻塞模式,也可以在规约调用后安排其它计算操作,等计算完毕后再调用isDone查询规约是否结束。最后,应用可根据返回值判断规约操作是否成功。
2 基于任务并行的计算模式
传统的基于二项树算法实现的MPI规约有2个缺点。第一,进程间通信依赖关系是根据算法静态确定的,无法适应动态的复杂环境。当某节点繁忙时,依赖于该节点的其他节点不得不等待,导致规约效率下降。第二,需要Send/Recv匹配[21],如果不能匹配,则无法继续计算。在分布式规约框架中,所有点对点通信均采用支持异步的单边通信接口,可避免MPI中的Send/Recv配对问题。每个规约实例均被分解为一系列可并行执行的独立计算任务,由任务调度器动态的将计算任务调度到各节点上进行计算,从而动态地建立起规约树。在整个过程中,根据各节点的实时性能,不断调整规约树的构建过程,从而有效适应复杂环境。分布式规约框架对容错的支持亦建立在基于任务并行的基础上。
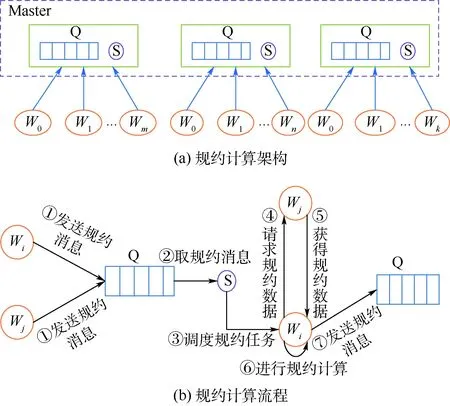
图3 基于任务的规约计算模式Fig.3 Task-based reduction computation pattern
在分布式规约框架中,记Wi为第i个Worker节点。图3(a)为规约框架执行规约计算的架构示意图。对于每一个规约实例,Master端均对应存在一个规约队列Q和规约调度器S。图3(b)为规约计算流程的示意图。为方便说明,作如下几个定义:
定义1原始数据,记为Oi,指Wi上的原始规约数据。
定义2中间数据,记为Di,指在规约过程中,Wi上的中间规约结果。
定义3规约数据,Oi或Di,指Wi上的原始数据或中间结果。
定义4规约消息,指Wi上规约数据准备就绪时,向S发送的消息。消息包含当前进程号Wi以及规约路径Pi。
定义5规约路径,记为Pi,和规约数据一一对应,由进程号构成的集合。规约路径Pi和Di的关系如式(2)所示,即通过对Pi中每个进程号对应的原始规约数据进行规约后可得到当前的中间数据Di。
(2)
式中:m为集合Pi中进程的数量;Pij为Pi进程集合中的第j个元素;∑通指具体的规约操作。
定义6规约任务,包含Wi、Pi、Wj和Pj4类信息,目的是将Wi和Wj上的规约数据进行规约。
基于任务并行的分布式规约算法的具体步骤如下:
步骤1Worker端,Wi调用reduce接口,向Master发送规约消息,规约消息中的进程号为Wi,Pi={Wi}。
步骤2Master端,所有的规约消息放置在队列Q中。
步骤3Master端,S从Q中连续取出2条规约消息,如果取出的第1条规约消息中的规约路径长度等于p,则广播通知所有规约进程规约结束,跳转步骤6。否则,进入步骤4。
步骤4Master端,设S得到的2条规约消息对应的进程号分别为Wi和Wj。根据这2条规约消息,生成规约任务。如果Wi和Wj中某个进程为根进程,则将任务调度给根进程;否则,根据性能计数器采集的每个进程最近一次完成规约任务的耗时,对比Wi和Wj的性能,将规约任务调度给耗时更低的进程,这里假设为Wi。
步骤5Worker端,Wi获得规约任务后,向Wj请求规约数据。得到数据后,根据用户自定义的规约操作进行规约计算。最后,向Master发送规约消息,其中,进程号为Wi,规约路径Pi=Pi∪Pj。发送完成后,跳转回步骤2。
步骤6规约结束。
从以上步骤中可以看出,Master根据Wi和Wj的规约消息,生成规约任务,并将规约任务调度给Wi和Wj中的某个进程执行,从而将规约拆分为多个独立的计算任务,且这些任务是可并行执行的。结合图4进行详细说明,在图4中,共有4个进程进行规约,进程号分别为0,1,2,3。其中,规约的根进程为1。开始规约后,这4个进程分别向Master的队列发送规约消息,队列中消息达到的顺序为0,3,1,2。Master首先从队首取出0和3对应的规约消息,根据0和3的规约消息生成规约任务1,根据性能调度策略,将任务1调度给进程3。然后继续从队列中取出1和2对应的规约消息,根据1和2的规约消息生成规约任务2,由于根进程为进程1,所以将任务2调度给进程1。进程1和进程3上的任务执行完毕后,分别向队列发送规约消息,Master根据1和3的规约消息生成规约任务3,又由于根进程为进程1,将任务3调度给进程1,由进程1完成最后的规约,并将规约结果保存在进程1上。在这个过程中,任务1和任务2是独立的,而且是并行执行的。因此,整个过程将规约拆分为一系列独立且可并行执行的计算任务。每个计算任务的具体执行过程参照上述步骤5。
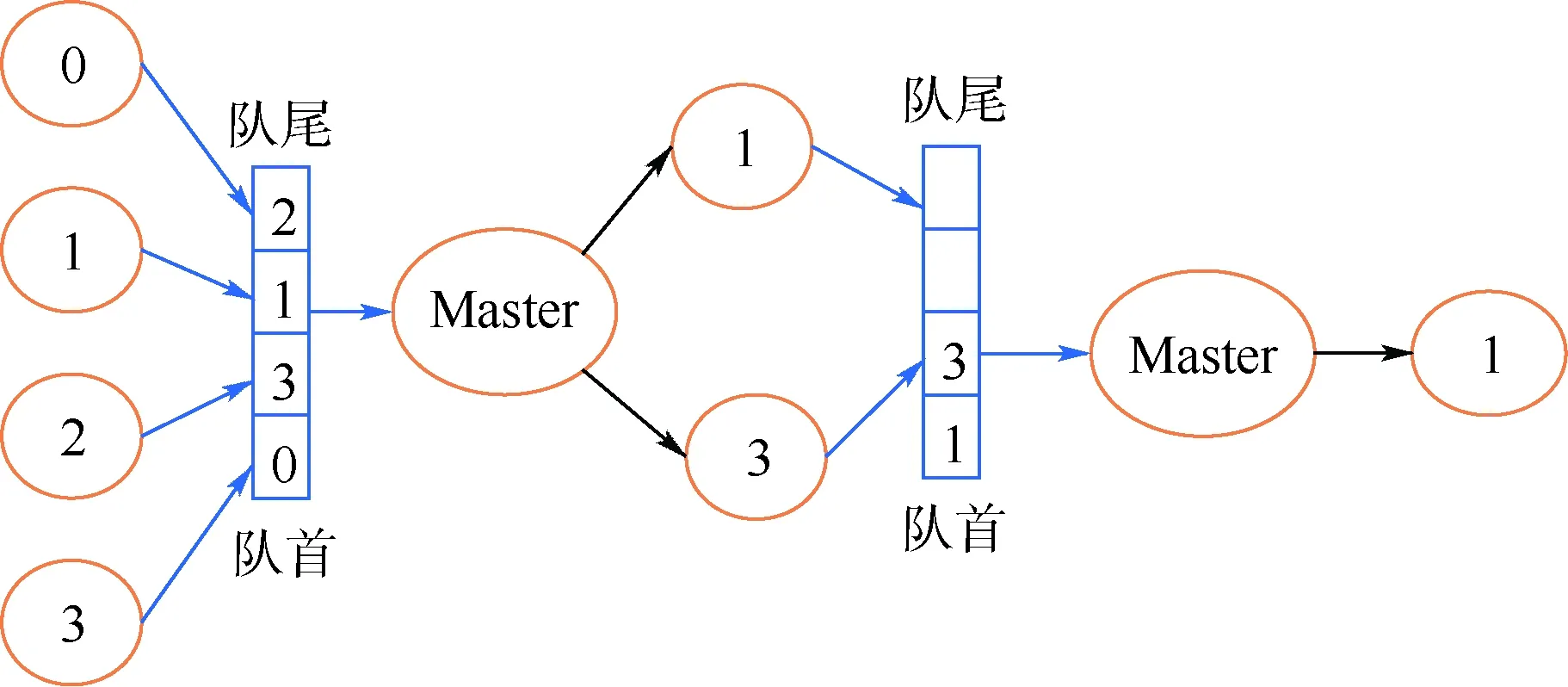
图4 任务分解示例Fig.4 Example of task decomposition
分布式规约的时间复杂度T包含2部分,一部分为完成规约耗费的时间,另一部分为广播规约结束信息所耗费的时间。该广播信息包含2部分,一部分为规约标识符,另一部分为规约接口返回值,共4字节。分布式规约的时间复杂度如式(3)所示:
T=(a+nβ+nγ+2θ+2λ)lbp+(a+4β)lbp
(3)
式中:θ为发送一条规约消息或一个规约任务的时间;λ为每条规约消息的平均排队和处理时间。和式(1)相比,分布式规约算法由于引入了额外的通信,所以在理想环境中,其性能低于二项树算法以及Rabenseifner算法。但分布式规约算法可以适应复杂环境,具体表现在如下2个方面:
1) 基于任务的计算机制,可以确保优先进入就绪状态的规约数据优先进行规约计算。和预先确定了进程间依赖关系的二项树算法不同的是,在分布式规约框架中,进程间的依赖关系是根据到达队列的先后顺序动态确定的,从而降低了慢节点对整体性能的影响。这是因为,其余节点不需要等待慢节点,可优先与已就绪节点进行计算。
2) 在调度任务时,总是将任务调度给性能更高的节点,可进一步提高规约计算对复杂环境的适应能力。
3 运行时容错
若在规约过程中遭遇节点故障,分布式规约框架将尝试在并行应用不退出的前提下修复故障。容错是基于故障侦听和数据可靠性存储实现的。故障侦听的实现原理是,Master周期性地向所有进程发送Ping消息,若某进程Wi在超过一定时间阈值后仍未反馈信息,则认为Wi故障,并将进程Wi广播给所有其他进程[22]。
为恢复出故障进程丢失的中间数据,分布式规约框架对原始数据进行了可靠性存储。Wi调用规约后,其原始数据将以双副本的形式存储在2个不同的计算节点的本地盘上。其中,一个节点为当前节点,即为Wi;另一个节点记为Wj,i和j的关系如式(4)所示:
j=(i+1)%p
(4)
在出现故障节点后,数据可靠性模块会将故障节点上的数据副本在其他无故障节点上进行恢复。为降低容错带来的性能开销,原始数据的可靠性存储和规约计算是异步同时进行的。
由于采用基于任务并行的计算模式,从容错处理的角度看,规约过程中各进程间的动态依赖关系可等价为S、Wi和Wj三者间的依赖关系。因此,容错处理可在S、Wi和Wj构成的模型上进行描述,如图5所示,Wi为获得任务的进程,Wj提供数据给Wi进行规约。
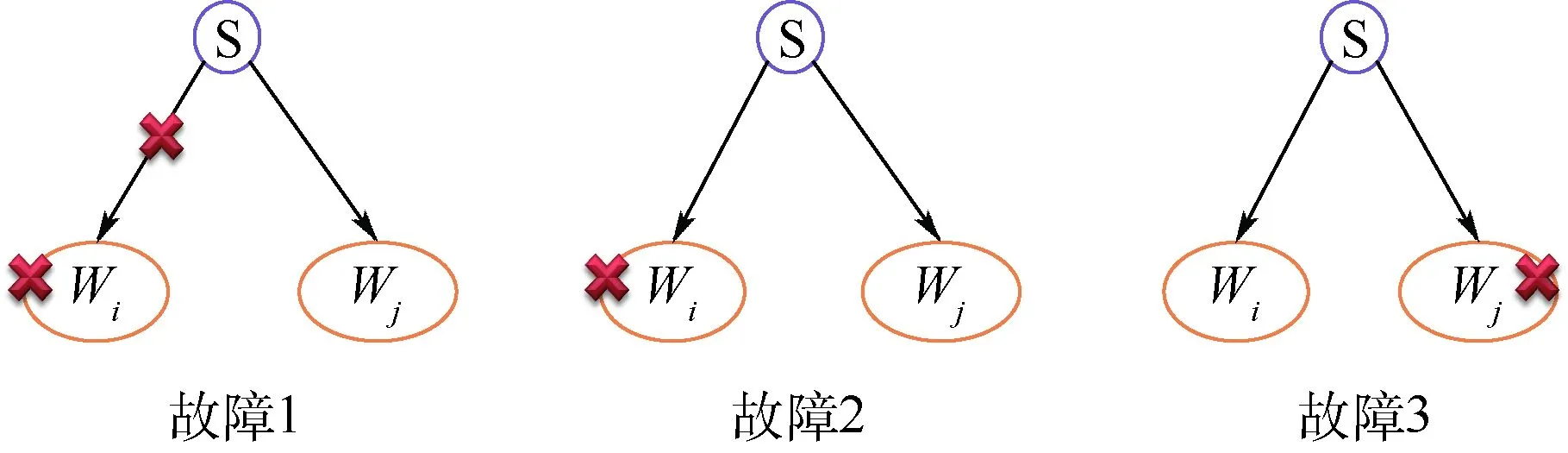
图5 故障位置说明Fig.5 Demonstration of fault location
在规约过程中,影响规约结果的故障位置共有3处:第1处是S在发送任务给Wi时,发现Wi故障;第2处是Wi在执行任务的过程中,Wi出现故障;第3处是Wi在执行任务的过程中,正在从Wj上获取数据时,Wj出现故障。记Mi为在故障发生前Wi向S发送的最新规约消息,Mj为在故障发生前Wj向S发送的最新规约消息。Pi为Mi对应的规约路径,Pj为Mj对应的规约路径。下面给出容错处理算法的详细步骤:
步骤1Master端,Master得到某节点故障通知后,判断故障类型。如果属于故障1或故障2,令M=Mj,P=Pi。如果属于故障3,令M=Mi,P=Pj。
步骤2Master端,Master将M重新放回到消息队列Q中。
步骤3Master端,记m为集合P的元素数量。将P拆解为m条独立的规约消息,第k条规约消息的进程号为Pk,规约路径为{Pk}。其中,Pk表示集合P中的第k个元素值。对于每条规约消息,需要设置容错标志。最后,将这m条规约消息放入到Q中等待被S调度。
步骤4Master端,调度器S在调度任务时,从Q中取出2条规约消息,仍记这2条规约消息对应的源进程分别为Wi和Wj。如果其中有一个为故障进程,则将任务调度给非故障进程。如果Wi和Wj都不是故障进程,但其中一个设置了容错标志(假设为Wi),则将任务调度给Wi。否则,按性能最优的调度策略调度。
步骤5Worker端,对于设置了容错标识的进程号,向数据可靠性模块请求其对应的原始数据。数据可靠性模块总是优先从当前节点的本地盘上直接为规约提供原始数据。
这里对规约的可靠性进行分析,若Wi在将数据存储到远程节点之前发生故障,则故障无法恢复。规约的可靠性δ表达式为
δ=1-
(5)
从式(5)可以看出,进程数量p越大,规约的可靠性越高。这是由于规约时间和lbp成正比,而Oi的远程副本存储时间是常量,和进程数量无关。
4 实验与分析
分布式规约的实验是在集群C1和集群C2上进行的,其中集群C1为测试集群,集群C2为生产集群。C1和C2均包含200个节点,C1和C2的每个节点配置为:128 GB内存,1块1 TB SAS本地盘,2颗CPU,每颗CPU有8个物理核;其中C1的CPU型号为Intel Xeon E5-2667 3.2 GHz CPU,C2的为Intel Xeon E5-2670 2.6 GHz CPU。集群C1和C2均采用的是万兆以太网。对比的MPI版本为MVAPICH,版本号为3.1.4。MVAPICH是高性能计算环境中最常用的MPI版本。所有的规约测试都是在C1或者C2的200个节点上运行的,每个规约性能结果都是重复运行9次后取平均值得到的。
4.1 理想环境中性能对比
理想环境是指,规约在运行过程中独占集群计算资源,不受其他应用干扰,理想环境实验采用的集群为C1,结果如图6所示(DR表示分布式规约,DCR表示分布式并发规约)。
图6(a)给出了理想环境中分布式规约和MPI规约的性能对比结果,其中测试数据的规模从128 KB(217B)以2倍递增到128 MB(227B),进行规约的进程数量为200。从图6(a)可以看出,在理想环境中,MPI规约的性能优于分布式规约的性能,但随着数据量的增加,分布式规约和MPI规约的耗时比呈缩小趋势。
图6(b)给出了理想环境中分布式并发规约和MPI并发规约的性能对比图,测试数据规模为8 MB,并发规约的数量从4递增到28。从图6(b)可以看出,在理想环境中,分布式并发规约的性能优于MPI并发规约的性能。
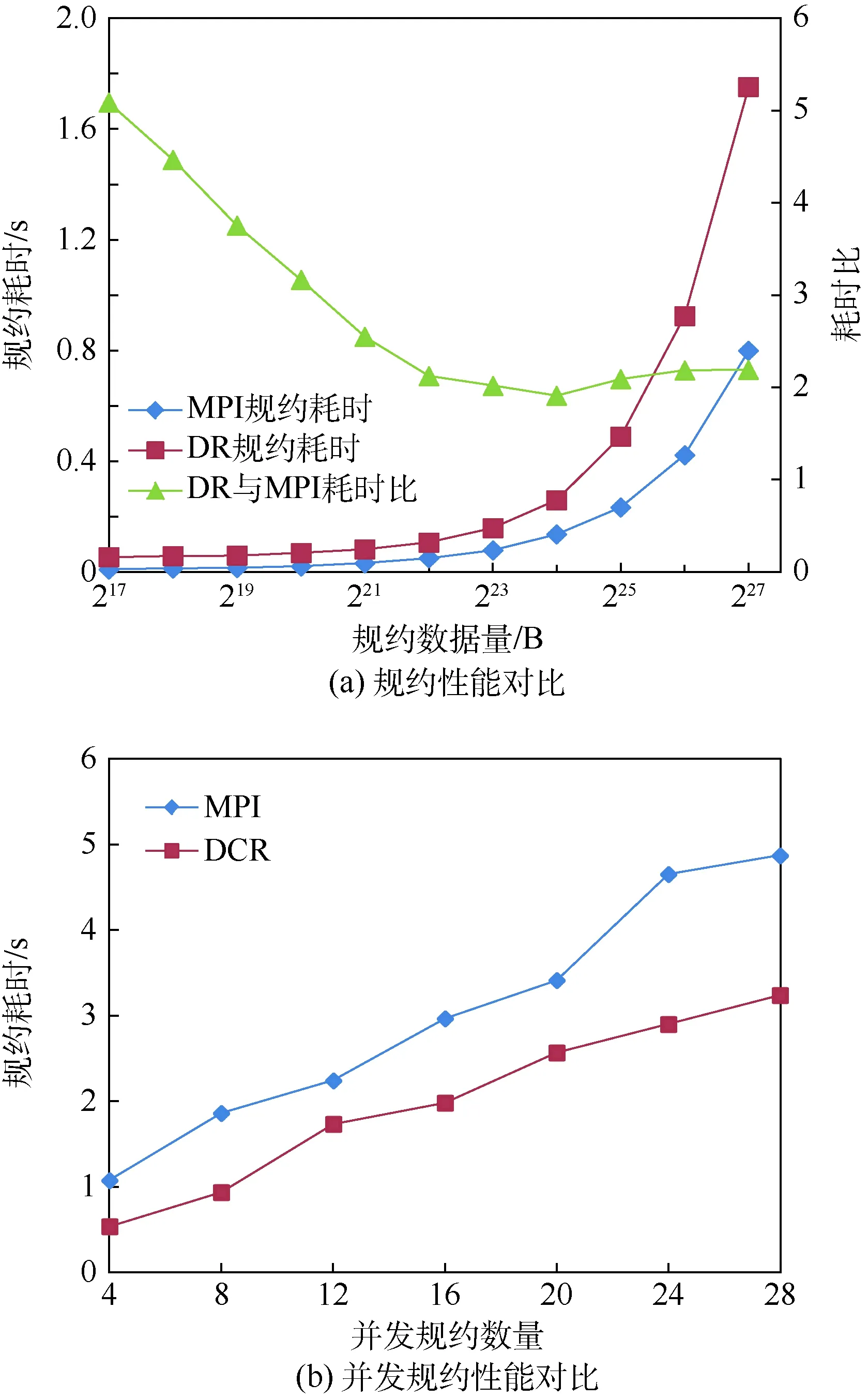
图6 理想环境中规约性能及并发规约性能对比Fig.6 Comparison of reduction performance and concurrent reduction performance in ideal environment
4.2 受控复杂环境中性能对比
受控复杂环境是指,在理想环境中人为引入干扰。首先在C1上运行大规模并行应用积分法叠前深度偏移(PreStack Depth Migration, PSDM),PSDM在运行过程中,会对集群的CPU、网络、内存产生较大的负载压力[23]。在该应用运行过程中,进行规约性能实验,进行规约的进程数量为200。
图7分别给出了使用节点数为50、100、150和200运行PSDM时,MPI规约和分布式规约的性能对比结果。可以看出,在数据规模较小时,MPI规约依然具有性能优势,这是由于数据规模较小时,规约耗时中网络启动时间占主要因素,干扰对规约数据的网络传输和计算造成的影响不是很显著。
当数据规模增加到4 MB以上时,分布式规约的性能明显优于MPI规约的性能。在这4种情况下,分布式规约的性能最高分别提升了5.59、2.09、3和5.15倍。
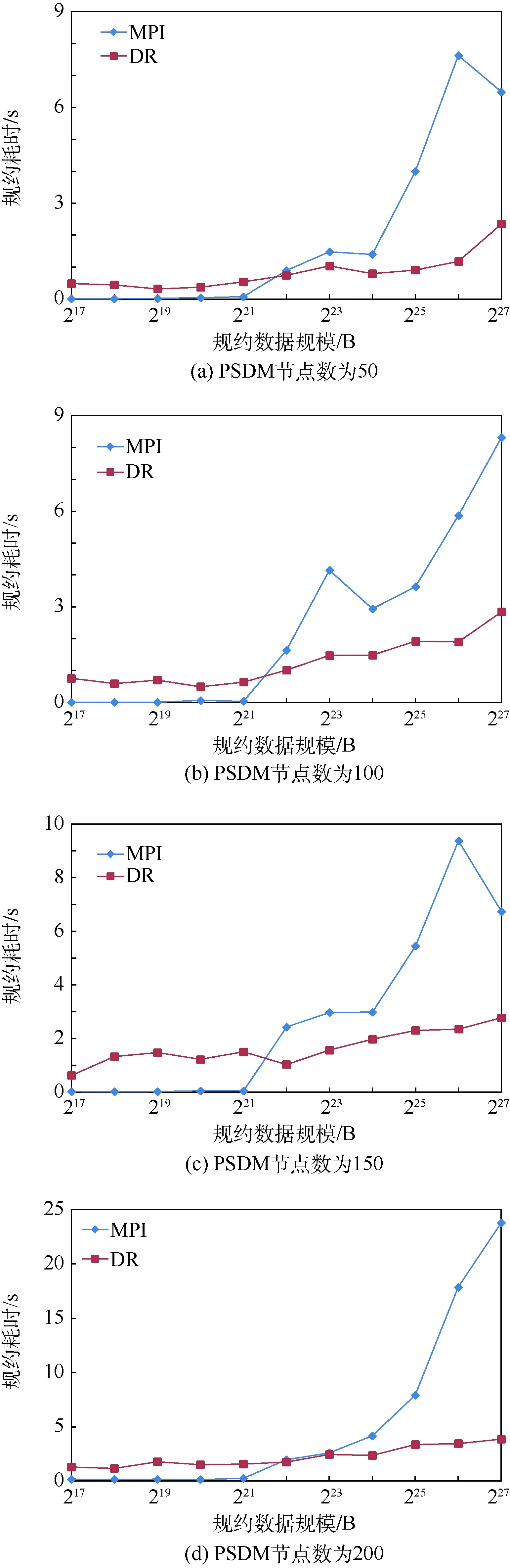
图7 受控复杂环境中规约性能对比Fig.7 Comparison of reduction performance in controlled complex environment
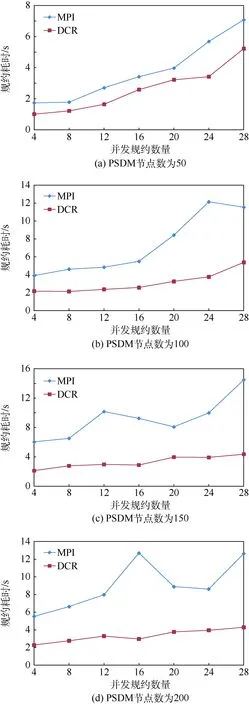
图8 受控复杂环境中并发规约性能对比Fig.8 Comparison of concurrent reduction performance in controlled complex environment
在受控复杂环境中,对比分布式并发规约和MPI并发规约的性能,规约数据量为8 MB,并发规约数量从4递增到28,进行规约的进程数量为200。图8分别给出了使用节点数为50、100、150和200运行PSDM时,MPI并发规约和分布式并发规约的性能对比结果。可以看出,在这4种情况下,分布式并发规约的性能均优于MPI并发规约的性能,分布式并发规约性能最高分别提升了0.72、2.21、2.41和3.28倍。
4.3 真实复杂环境中性能对比
真实复杂环境是指,集群C2上的真实生产环境,C2上长期运行着多个并行应用的生产作业,集群整体负载较高,较为繁忙。在真实复杂环境中,分别对比规约和并发规约的性能。实验中,测试数据的规模为32 MB,进行规约的进程数量为200。在该集群上分别对规约和并发规约进行了连续7 d的对比测试。
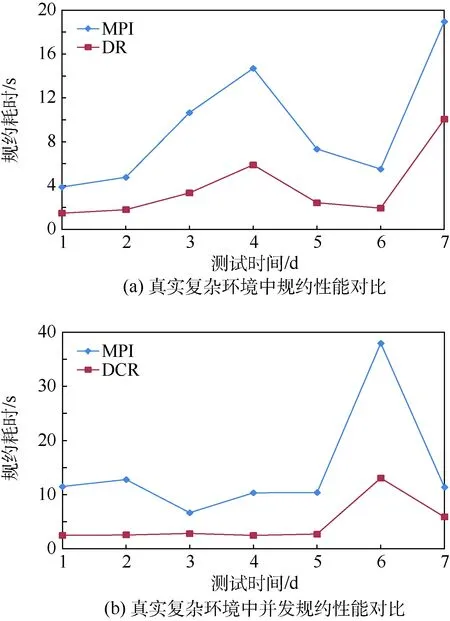
图9 真实复杂环境中规约性能及并发规约性能对比Fig.9 Comparison of reduction performance and concurrent reduction performance in real complex environment
图9(a)给出了真实复杂环境中,MPI规约和分布式规约的性能对比结果。图9(b)给出了该环境中,MPI并发规约和分布式并发规约的性能对比结果。从图9可以看出,在连续7 d的时间内,分布式规约的性能均优于MPI规约的性能,分布式并发规约的性能也都优于MPI并发规约的性能。规约性能最高提升了2.2倍,平均提升了1.67倍。并发规约性能最高提升了4倍,平均提升了2.55倍。
4.4 Master端负载测试
在C1集群上进行Master端的负载测试,以分析大规模节点数量下,频繁的Master与Worker间通信对Master端的影响。实验中,节点数为200,规约的数据规模从128 KB(217B)以2倍递增到128 MB(227B)。C1集群中每个节点接收消息的最大峰值为79 365次/s,发送消息的最大峰值为106 383次/s,网络接收数据的最大带宽为812.7 MB/s,网络发送数据的最大带宽为812.7 MB/s。表1记录了在规约过程中,Master端的接收消息数量,发送消息数量,接收数据量带宽,发送数据量带宽的平均值。表1中每行的4个值分别是用Master端在规约过程中的接收消息总量、发送消息总量、接收数据总量、发送数据总量除以规约时间得到的。
从表1可以看出,规约过程中,Master的接收消息数量、发送消息数量、接收带宽、发送带宽都远低于Master作为单个节点时各项指标对应的峰值数据。因此,规约过程中,Master端受到的负载在可承受的范围内。这主要是因为在规约过程中,各个Worker节点和Master之间的通信内容主要为规约信息和任务信息,而规约数据是在Worker节点之间进行通信的,不会经过Master节点,所以对Master造成的开销比较小。
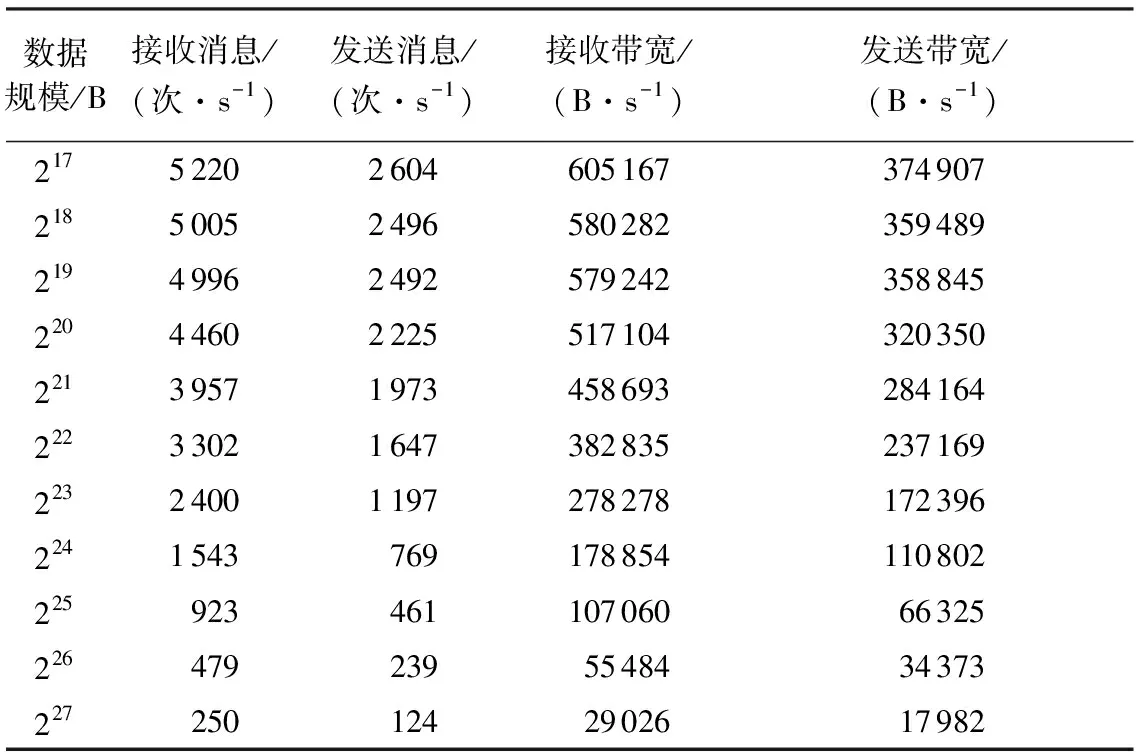
表1 规约过程中各项指标的平均值
4.5 容错实验
在真实复杂环境中,对分布式规约的容错进行实验,测试数据规模为32 MB,进行规约的进程数量为200。每轮测试中,首先进行9次测试取得平均规约时间t,然后进行100次规约。选择进程号为1的进程,每次规约时,在[0,t]内随机生成一个时间点,在该时间点上强制退出1号进程以模拟节点故障。每天进行一轮容错实验,连续进行7 d。表2给出了7 d的容错实验结果,在100次的容错测试中,无法恢复的故障数量为0~3个,规约的容错可靠性为98.43%。

表2 分布式规约的容错实验结果
5 结 论
规约是并行计算领域最常用的集合通信原语之一。传统的规约实现在性能优化方面没有考虑真实环境中的干扰因素,也没有解决规约过程中出现的节点故障问题。本文针对真实复杂环境,提出了一种基于任务并行的可适用于复杂环境且支持容错的分布式高性能规约框架,结合实验得出以下结论:
1) 基于任务并行的设计可有效解决干扰问题和容错问题。以任务为粒度进行调度,可优先执行已就绪的任务,慢任务可稍晚执行,但不会影响其他任务的执行。以任务为粒度进行容错,降低了容错实现的复杂性。
2) 在受控复杂环境中,当数据量在4 MB以上时,分布式规约性能优于MPI规约的性能。在4种干扰情况下,分布式规约的性能最高分别提升了5.59、2.09、3和5.15倍;分布式并发规约的性能最高分别提升了0.72、2.21、2.41和3.28倍。
3) 在真实复杂环境下连续7 d的测试中,分布式规约性能均优于MPI规约性能,分布式并发规约性能也均优于MPI并发规约性能。前者性能平均提升了1.67倍,后者性能平均提升了2.55倍。
4) 在真实复杂环境中,根据连续7 d的容错测试结果可知,分布式规约的容错可靠性可达到98%以上。
