基于散度的网络流概念漂移分类方法
2021-01-05钱德鑫郭建伟史海滨赵玉宇
程 光 钱德鑫 郭建伟 史海滨 吴 桦 赵玉宇
1(东南大学网络空间安全学院 南京 211189)
2(教育部计算机网络和信息集成重点实验室(东南大学) 南京 211189)
3(江苏省计算机网络技术重点实验室(东南大学) 南京 211189)
4(华为技术有限公司西安研究所 西安 710075)
随着互联网的飞速发展,网络新应用、新协议层出不穷,网络应用程序越来越复杂;同时网络中的加密流量比例随着人们对于隐私的重视而不断扩大.这些问题使得传统的流量分类方法面临巨大的挑战,逐渐从基于端口和深度包检测技术(deep packet inspection, DPI)[1]的流量分类方法转向基于机器学习[2-3]的流量分类方法.基于机器学习的流量分类比较依赖于训练样本的环境.由于网络流量具有高度动态变化性、突发性、不可逆性等特点,因此流量的统计特征和分布会发生动态变化,导致基于流特征的机器学习方法产生概念漂移问题[4-5].网络流量概念漂移问题使得建立在原始数据集上的分类模型在新样本上适用性变差,造成分类器分类精度下降.
针对概念漂移问题国内外学者进行了大量的研究,并取得众多成果.然而这些方法还存在一些不足:1)当前大多数解决概念漂移的方法都是基于分类错误率[6]来检测概念漂移,带来的问题是获取样本标签需要耗费大量时间和资源,同时基于分类错误率的检测方法无法应对类不平衡[7]的网络流.2)当检测到概念漂移时,若只在新流量上训练分类器会导致历史知识的丢失[8],若将不同时期获得的所有流量重新训练分类器则会带来较大的性能问题[9].一个理想的网络流分类模型应该能增量地学习并适应多种网络流量类型的变化,因此设计出能应对概念漂移的网络流量分类方法具有重要的意义.
针对上述问题,本文提出了一种基于散度的网络流概念漂移分类方法(ensemble classification based on divergence detection, ECDD).该方法首先采用双层窗口机制跟踪概念漂移,借鉴信息论的思想,通过JS散度来度量新旧窗口之间数据分布的差异,从而有效地检测概念漂移.本文采用增量集成学习的方法,当检测到概念漂移时采用新样本重新训练分类器,接着通过分类器权值比较的方式保留性能较好的分类器,从而实现对于集成分类模型的有效更新.
1 相关研究
近年来,许多学者对于概念漂移问题提出了大量的算法与模型,目前概念漂移检测方法大体上分为2类:1)依据概念漂移造成的后果进行检测,例如依据分类准确率下降来检测概念漂移;2)依据概念漂移产生的原因进行检测,例如依据数据分布是否发生变化来检测概念漂移.
对于使用分类错误率来检测概念漂移,相关研究为:Gama等人[10]提出根据当前分类器的分类错误率来检测概念漂移的DDM算法,该方法持续监测分类器的分类错误率,对于突变式的概念漂移表现优越,但不能有效地检测到渐变式的概念漂移;Nishida等人[11]提出了基于伯努利分布检测概念漂移的算法EDDM,该方法同时依据模型的错误率变化与错误率之间的距离判断概念漂移,不仅对突变性的概念漂移检测良好,同时也提高了对渐变概念漂移的检测效果;Bifet等人[12]提出了自适应滑动窗口算法ADWIN,该算法用可变的滑动窗口来检测随时间变化的数据流,通过比较不同子窗口之间的分类错误率均值差异来判断是否发生概念漂移;Nishida等人[13]提出一种突变式概念漂移检测方法LID,依据当前模型的信息度和分类精度来检测概念漂移.
上述方法均基于分类准确率检测概念漂移,标记样本需要耗费大量时间和资源,因此很多学者基于概念漂移产生的原因,即数据分布的变化,取得了相应的研究成果:Borchani等人[14]基于半监督学习的方法提出基于距离的漂移检测,该方法使用滑动窗口将数据流划分为不同的子集,基于KL散度(Kullback-Leibler divergence,KLD)计算差异性来检测概念漂移,该方法使用的KL散度取值范围较大,并存在距离不对称等问题;Alippi等人[15]利用中心极限定理,设计了不依赖数据分布模型、不需要任何先验信息的概念漂移检测算法;Dries等人[16]基于统计学方法,使用对不同概念漂移类型设定不同阈值来检测漂移,克服了单一标准检测概念漂移的弊端,提高了对不同类型概念漂移的检测准确率;潘吴斌等人[17]基于概念漂移发生时属性信息熵会发生变化来检测概念漂移,该方法对于不同类型的概念漂移均可以有效检测并更新分类器,使得分类器具有良好的泛化性能.
由于网络流量的动态性,例如不同时间、地点、网络应用更新、新型网络应用出现等情况,使得网络业务分布发生变化,即会产生概念漂移问题,概念漂移使得分类模型的分类准确性下降,影响分类器的泛化性能.
将网络流量统计特征表示为A=(a1,a2,…,an),用B来表示网络流量所属类别,根据贝叶斯公式可得,分类器可以定义为期望函数f:A→B:
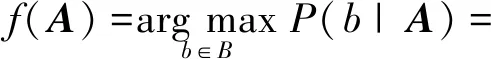
(1)
由式(1)可得,流统计特征ai的变化会影响类条件概率密度P(ai/b),从而影响到P(b/A);同时类别先验概率P(b)的变化也会影响到P(b/A),从而影响分类结果.
本文提出了一种基于散度的概念漂移流量分类方法ECDD,该方法基于双层窗口检测机制,依据特征属性的JS散度差异来判断数据分布的变化,从而检测概念漂移;检测到概念漂移时需要更新分类器,本文采用增量集成学习的方式引入漂移流量更新分类器,在保留之前分类器的基础上剔除性能下降的分类器,从而使得分类器得到有效地更新,有效地应对网络流量概念漂移问题.
2 基于散度的概念漂移分类方法
本节将首先介绍基于散度的网络流概念漂移检测算法,然后描述在概念漂移点采用增量集成学习的方式更新分类器的方法.
2.1 基于散度的概念漂移检测算法
概念漂移问题使得分类模型对新流量的适用性变差,难以保持稳定的识别准确性.仅依靠经验定期更新分类器会浪费大量的时间和人力,及时准确地检测到概念漂移,从而对分类器进行更新至关重要.基于分类错误率的概念漂移检测算法需要获得检测样本的真实标签,浪费大量人力资源,同时不能很好地适用于类不平衡的网络流.
本文提出了一种基于JS散度的概念漂移检测算法ECDD.在信息论中,相对熵(relative entropy)又称为KL散度,是衡量2个概率分布之间的差异性的指标,假设用X表示某随机变量,该随机变量上的2个概率分布为P(x)和Q(x),则它们的KLD(P‖Q)定义为
(2)
可以得出,KLD的取值范围为[0,+∞],当2个随机分布相同时,它们的相对熵为0,当2个随机分布的差别增大时,它们的相对熵也会增大.由于KLD取值范围为[0,+∞],对于2组随机分布数据,无法准确地用KLD来度量2组数据分布的差异,对相似度的判别较为粗略.
尽管KLD从直观上是一个度量或距离函数,但它并不是一个真正的度量或距离,因为它不具有对称性,即:
KLD(P‖Q)≠KLD(Q‖P),
(3)
KLD的非对称性对求解2组数据分布是否相似存在一定偏差.
JS散度是KL散度的一种变形,它解决了KL散度的不对称问题,对相似度的判别更确切,对于2个概率分布P(x)和Q(x),JSD(P‖Q)的计算公式为

(4)
由式(4)可得JSD是2个KLD的累加,将式(4)中KLD展开得:
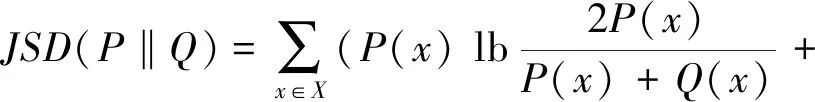
(5)
JSD的取值范围为[0,1],即对于2组随机分布变量,分布相同则是0,分布完全不同则为1.相较于KLD,JSD对相似性度量的判别更加确切.同时,JSD解决了KLD的非对称问题,即JSD满足对称性:
JSD(P‖Q)=JSD(Q‖P),
(6)
JSD的对称性使得在计算2组数据分布间差异时不会产生偏差.
基于JS散度的取值范围更准确以及其满足对称性,本文引入JS散度来度量特征分布的变化,从而检测概念漂移.
本文采用双层滑动窗口的方式,在概念漂移检测流程中一直维护2个滑动窗口,分别表示较旧概念的数据和新概念的数据.考虑到由于类不平衡会使得特征分布发生变化,从而对概念漂移检测结果产生影响,本文先对2个窗口内样本进行分类,依据分类结果计算2个窗口中样本特征分布之间的JS散度,根据JS散度判断概率分布是否发生变化,从而检测是否发生了概念漂移.
定义时刻ti,用Winold,i表示最近一次检测到概念漂移时的窗口,Winnew,i代表当前检测窗口,包含最新的样本实例.用JSD(Winold,i‖Winnew,i)表示2个窗口内数据分布的距离,定义漂移检测阈值τ,若存在某特征对应的2组数据分布的JSD(Winold,i‖Winnew,i)>τ,则判断发生概念漂移,称ti为概念漂移点.当新样本加入时,窗口Winnew,i向前滑动,每次更新,检测是否存在JSD(Winold,i‖Winnew,i)>τ,如果是,报告发生概念漂移,重复整个过程.算法1描述了概念漂移检测算法的流程:行①~⑦使用分类器对滑动窗口内样本进行分类,获得样本特征向量和分类结果;行⑧到结尾计算2个窗口内每类样本对应特征的JS散度,与漂移检测阈值τ比较,若大于阈值,则判断发生概念漂移,否则窗口向前滑动,重复整个流程直到数据流结尾.
算法1.概念漂移检测算法.
输入:分类器C、滑动窗口大小δ、特征向量Rd、漂移检测阈值τ;
输出:概念漂移检测结果.
①Winold,i表示在时刻ti的δ个样本;
②Winnew,i表示在Winold,i后的δ个样本;
③ 当滑动窗口未到达数据流尾部时
④ 用C对Winold,i,Winnew,i样本分类;
⑤Sold,i表示Winold,i的分类结果;
⑥Snew,i表示Winnew,i的分类结果;
⑦ 计算共有的类别yintersection,i;
⑧ 遍历yintersection,i
⑨ 遍历特征向量Rd
⑩ 若存在2组样本的JS散度大于τ
2.2 增量集成分类算法
本文借鉴集成学习里bagging[18]的思想构建集成学习初始分类器:假设集成分类器要构建k个基分类器,给定包含m个样本的原始训练样本集,通过k次随机采样,得到k个大小均为m的采样集S1,S2,…,Sk,对于这k个采样集,训练出k个基分类器,使用集成策略将这k个基分类器结合起来,形成最终的集成分类器.
借鉴自助采样法(bootstrap sampling)[19]来进行随机采样:给定包含m个样本的数据集,有放回地进行m次样本的随机抽取,经过m次随机采样操作,将得到含m个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现.重复上述操作k次,这样可以得到k个相互独立的样本集,从而使得集成中的个体学习器尽可能相互独立,获得泛化性能强的集成.
选取C4.5决策树作为集成学习的基分类器,C4.5决策树的分类模型易于理解,且具有较好的分类效果和效率[20-21].同时,C4.5决策树在模型构建过程中不依赖于网络流分布,具有较好的分类稳定性.
考虑到基分类器性能不同对于其分类结果应持有不同的信心,因此本文根据基分类器的分类性能赋予其权重.用Ci(1≤i≤k)表示基分类器,Wi(1≤i≤k)表示分类器Ci的权重,权重Wi与分类器Ci在其训练集Si上的分类准确率成正比,定义Acci为基分类器Ci在其训练集Si上的分类准确率,则该分类器对应的权重Wi计算为
Wi=α×Acci,
(7)
其中,α>0为正相关系数.算法2描述了集成学习分类器的构造方法.行①~⑧描述了初始集成分类器构造的整体流程,行②~④为获取每个基分类器的训练样本集并训练基分类器,行⑤~⑦为计算基分类器权重并将基分类器加入到集成分类器C中.
算法2.集成学习初始分类器构造算法.
输入:基分类器数目k、初始训练样本集S;
输出:k个带权重的基分类器集合C.
① 遍历基分类器集合
② 从S中随机采样得到训练集Si;
③ 根据Si训练基分类器Ci;
④ 计算Ci的分类准确率Acci;
⑤ 根据Acci计算Ci的权重Wi;
⑥ 将Ci加入到集成学习分类器中;
⑦ 完成加权集成分类器的构建;
⑧ 返回加权集成分类器.

Fig. 1 Capturing traffic at different locations图1 不同地点采集流量

(8)
本文采用增量集成学习的方法来进行分类器的更新,从而在检测到概念漂移时有效地更新分类器.检测到概念漂移时,对于新样本重新训练出新的分类器,在保留原先集成分类器的基础上,通过权值比较选取性能最优的分类器,从而提高集成分类器的泛化能力.
定义Snew为检测到的概念漂移样本集合,在Snew上学习出一个新的分类器Cnew,分类器Cnew的权重Wnew采用与式(7)相同的方法获得.对于每个基分类器Ci(1≤i≤k),根据其在Snew上的分类准确率更新各自的权重.对于Cnew和基分类器Ci(1≤i≤k),按照分类器权重排序选取前k个分类器构成新的集成分类器.算法3描述了增量集成学习算法流程.
算法3.增量集成学习算法.
输入:k个预先训练的基分类器集合C、概念漂移样本集S;
输出:更新权重的k个基分类器集合C.
① 在S上训练出新的分类器Cnew;
② 计算Cnew的权重Wnew;
③ 遍历预先的基分类器集合C
④ 计算基分类器Ci的分类准确率Acci;
⑤ 根据分类准确率计算各自的权重Wi;
⑥ 根据权重排序选取前k个分类器;
⑦ 返回更新后的加权集成分类器.
3 实验与分析
3.1 实验数据集
网络应用层出不穷,相同网络业务下的不同应用可能会存在特征方面的差异,即产生概念漂移问题,这对网络业务识别带来极大的挑战,造成网络业务识别准确率下降.
本文对常见的8种网络业务:视频(video)、音频(music)、网页浏览(Web)、发送接收图片语音(picture&voice)、上传下载大文件(file)、文本聊天(chat)、视频通话(video call over IP)、语音通话(voice call over IP)进行流量抓取,每种网络业务根据该业务下应用的下载量,选择3种不同的应用分别进行流量采集.
考虑到终端抓取的流量可能无法完全反映网络的真实情况,本文使用tcpdump在VPN服务器上进行流量的抓取,抓取到的流量更远离终端,也更能实际反映出业务过程中的网络情况.
同时,考虑到CDN对流量特征的影响,采集流量时通过部署不同地点的服务器共同采集,从而尽可能地使采集到每种应用的流量能较真实地反应该应用整体的流量特征.
样本采集示意图如图1所示,分别选取不同服务器地址进行流量采集,从而使采集到的样本较好地反映该类网络应用的特征情况.
样本集具体构成情况如表1所示,对于每类网络业务,各进行300次独立拨测,根据组流后的结果构造出300条网络流量样本.其中每类网络业务由3种网络应用组成,每种网络应用各独立拨测100次,从而对于每类网络应用均获得互相独立的100条网络流量样本.
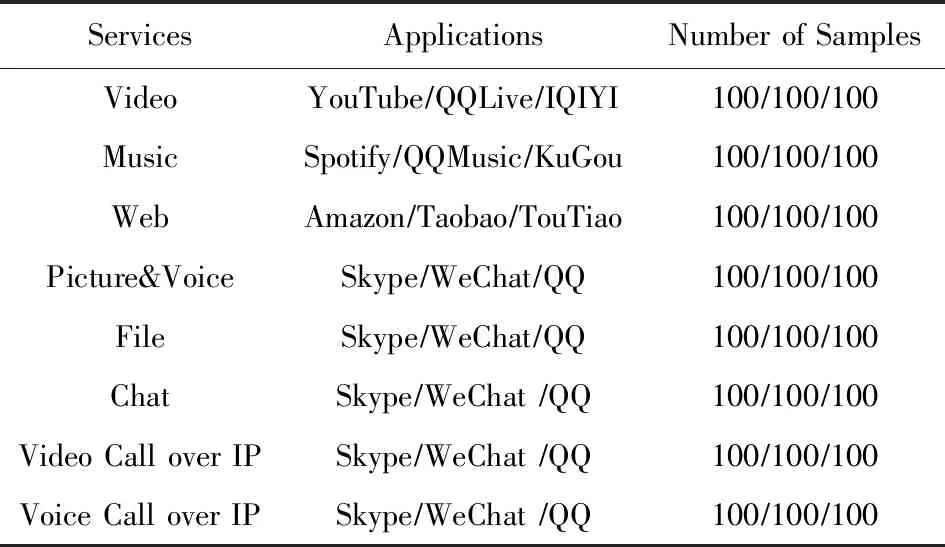
Table 1 Experimental Data Set Composition表1 实验数据集组成情况
本文实验平台为Windows 10,CPU为酷睿i5,内存为12 GB,开发环境为python 3.0.
3.2 特征选择
对于如表1所示数据经过组流、流统计特征处理后,每条样本均提取出81维特征.为了提高分类模型的分类性能和简化分类模型,需要进行特征选择,删除冗余、无效的特征.例如实际接收到的字节数等特征针对某些网络业务可能区分性不足,而平均码率、平均包大小等对不同的网络业务可能区分较明显.
本文结合常见的特征选择方法,充分考虑特征间的相关性、信息增益、信息增益率,综合各特征选择算法(InfoGain,GainRatio等)选取最优特征,最终选择出了11维特征,如表2所示:
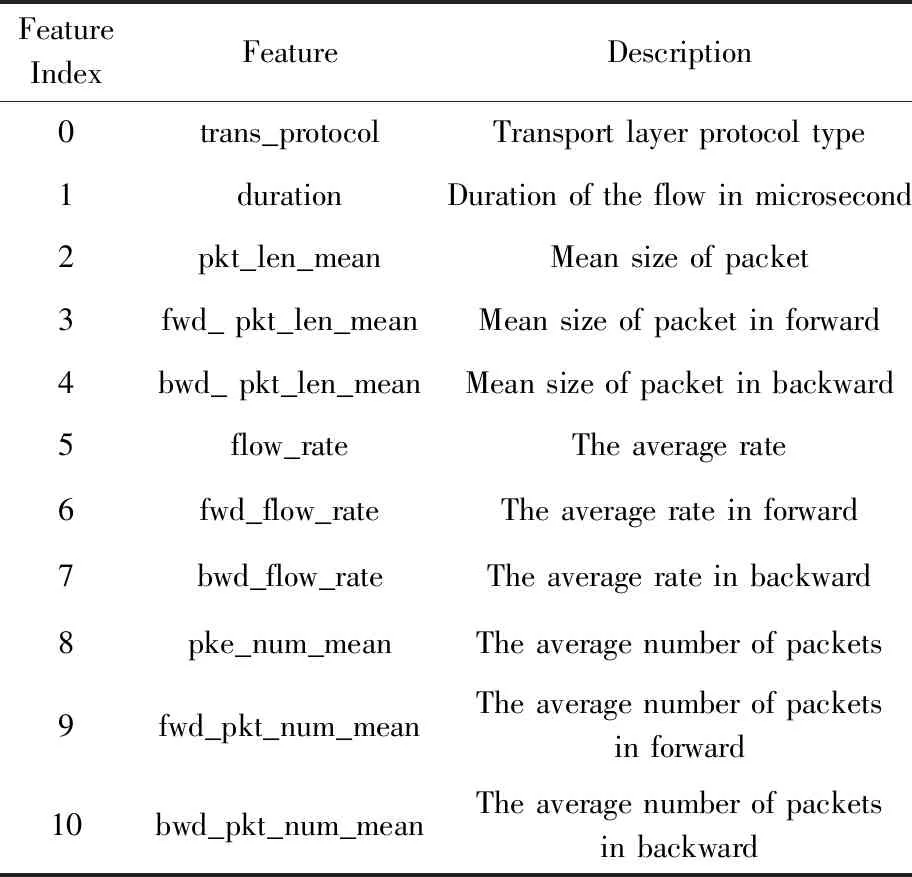
Table 2 Feature Selection Result表2 特征选择结果
3.3 评估指标
本文采用基于散度的方法解决流量识别中的概念漂移问题,在使用机器学习算法进行流量识别的过程中,准确率是算法性能评估常用的指标,真正例TP表示将正类正确预测为正类数,假正例FP表示将负类错误预测为正类数,假负例FN表示将正类错误预测为负类数,真负例TN表示将负类正确预测为负类数.根据这4个指标,可以得到准确率(Accuracy)、精确率(Precision)、召回率(Recall)和综合评价(F1_score)的计算方法:
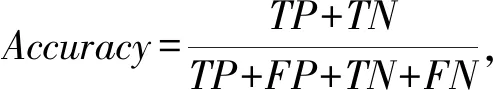
(9)
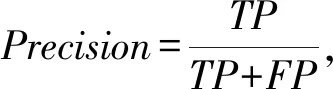
(10)

(11)

(12)
同时,为了评估概念漂移检测方法的准确性及有效性,本文采用误报率(FPR)和漏报率(FNR)来评估.误报率和漏报率越高,表示概念漂移检测性能越差,误报率、漏报率分别计算为
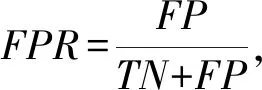
(13)

(14)
3.4 概念漂移检测结果
3.4.1 概念漂移样本集构造
对于网络业务识别,由于同类网络业务下可能会包含不同的网络应用,各应用间可能会存在特征分布上的差异,从而使得该业务产生概念漂移问题,导致对于网络业务的识别准确率下降.
对表1所示的网络流量进行特征分析,寻找同类业务不同应用之间是否存在特征分布的差异.如图2所示为视频业务中,爱奇艺视频IQIYI与腾讯视频QQLive在平均速率特征上的分布直方图.
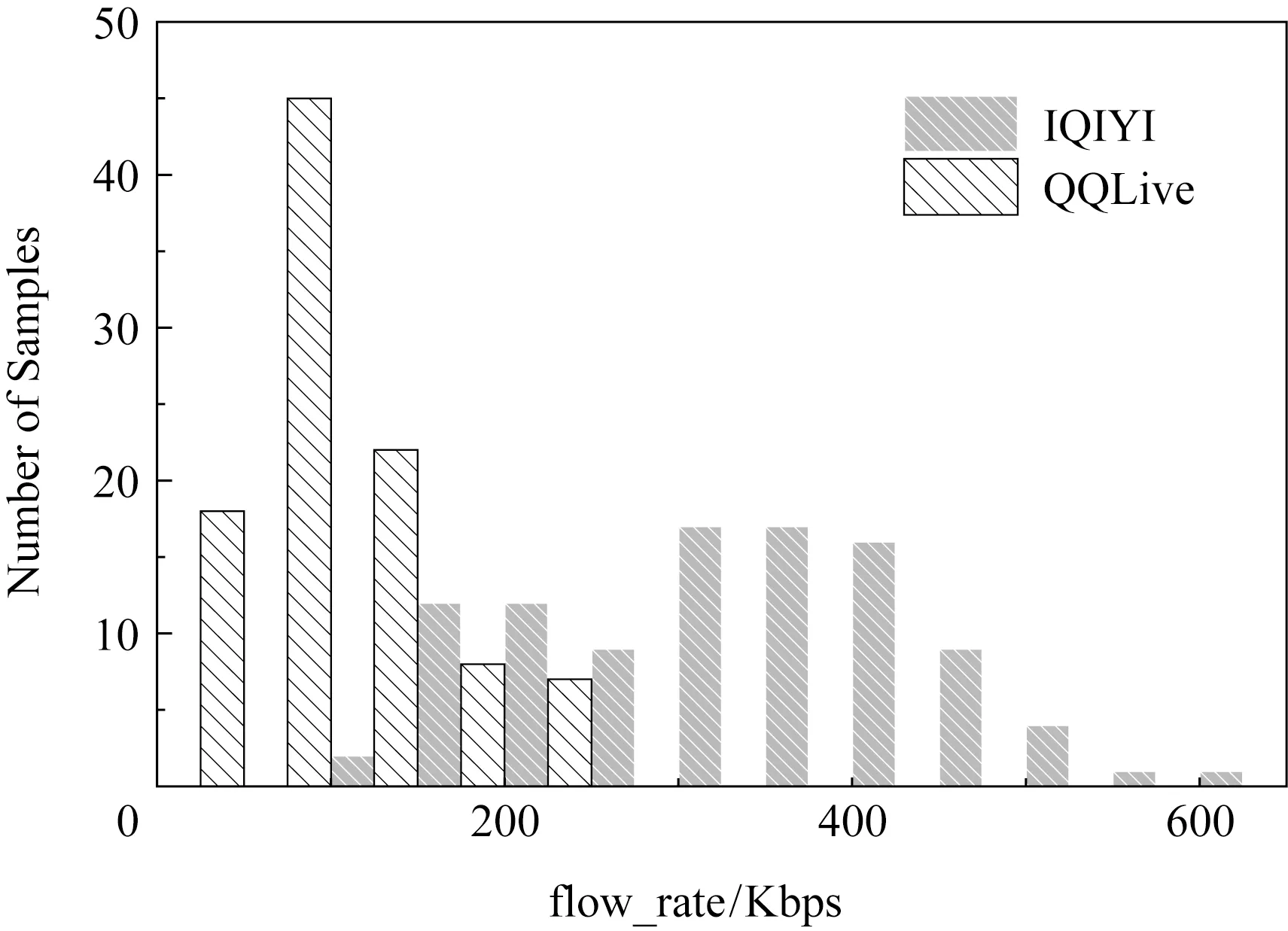
Fig. 2 Video app distribution differences in flow_rate图2 视频应用在平均速率上的分布差异
由图2可以看出爱奇艺视频与腾讯视频在平均速率这一特征上的分布差异.基于此方法,寻找表1所示网络业务不同应用间存在的特征分布差异,根据应用间特征的差异构造概念漂移数据集,表3所示为构造出的5种概念漂移数据集.

Table 3 Concept Drift Data Set表3 概念漂移数据集构成
如表3所示,通过更换某类网络业务下的应用构造出不同的概念漂移数据集,为了模拟真实网络环境中样本的情况,上述每个概念中的样本均随机打乱.
3.4.2 基于散度的概念漂移检测结果
本文依据2个窗口内数据的分类结果,使用JS散度度量特征间数据分布的差异,从而检测概念漂移.为了验证基于JS散度的概念漂移检测算法的有效性,本文做了2组对比实验.
以Concept_1样本集为例,将Concept_1样本集划分为大小相同的2个样本集,分别为Concept_1_a与Concept_1_b,2个样本集来自于同一个概念,依据分类结果对每个特征计算JS散度,结果如图3所示:

Fig. 3 JS divergence results for the same concept data set图3 相同概念数据集的JS散度计算结果
如图3所示,相同概念的样本集的特征计算出的JS散度值均较小(均小于0.2),表示2个样本集特征分布差异较小,即可以判断没有发生概念漂移.
对比实验为Concept_1数据集和Concept_2数据集,由表3可以得出Concept_1与Concept_2数据集视频类业务存在特征差异,对这2个不同概念的数据进行JS散度计算,结果如图4所示:

Fig. 4 JS divergence results for different concept data sets图4 不同概念数据集JS散度计算结果
如图4所示,Video样本计算出的JS散度值较大(图4中矩形标志的折线),表明Video类业务特征分布的差异较大,即可能发生了概念漂移.
上述实验窗口大小均取待检测数据集大小,并且没有定义漂移检测阈值,实验的目的是依据JS散度的检测结果与原始数据本身是否含有概念漂移进行比对,从而验证基于JS散度检测概念漂移的有效性.
3.4.3 检测窗口大小与检测阈值
本文采用滑动窗口的方式检测概念漂移,滑动窗口过大可能会造成概念漂移检测时漏报率增加,窗口过小可能会造成概念漂移检测时误报率增加,同时本文根据特征分布的JS散度衡量特征分布之间是否存在明显差异,从而判断是否发生概念漂移,JS散度的阈值大小也影响着检测算法的性能.
为了确定合适的窗口大小与检测阈值,采用误报率与漏报率来评估不同窗口大小与阈值的检测性能,设置窗口大小为100~250,阈值为0.4~0.6,在不同的窗口与阈值情况下测试误报率与漏报率,结果如表4所示.
如表4所示,当检测阈值不变时,随着检测窗口变大,误报率呈现降低的趋势,漏报率呈现增加的趋势;同时当检测窗口大小不变时,随着检测阈值增大时,误报率也呈现降低趋势,漏报率呈现增加趋势.
综合误报率与漏报率的综合表现,选择窗口大小为150,检测阈值为0.5,从而实现较低的误报率与漏报率.
3.4.4 检测方法比较
DDM和STEPT是2种常见的概念漂移检测方法[10].这里将这2种常见的概念漂移检测方法与ECDD方法进行对比,测试各算法的概念漂移检测性能.

Table 4 Detection Window and Threshold表4 检测窗口与检测阈值
DDM方法根据分类错误率检测概念漂移,根据默认配置设置其警告级别为2.0,漂移级别为3.0;STEPT方法采用统计检验来检测概念漂移,根据默认配置设置检测窗口大小为30,警告显著性水平为0.05,漂移显著性水平为0.03.ECDD方法则使用上述实验确定的滑动窗口大小为150,漂移检测阈值为0.5.
如表5所示为ECDD方法与DDM,STEPT方法在检测概念漂移的实验对比结果.

Table 5 Comparison of Detection Methods表5 检测方法比较
ECDD方法相比较DDM和STEPT方法可以较有效地检测到概念漂移,综合误报率和漏报率,ECDD在概念漂移检测性能上优于DDM和STEPT方法.
3.5 网络流分类结果
3.5.1 基分类器数目选择
对于给定的初始训练集,基分类器数目可能会对分类准确率产生影响.本文采用C4.5作为基分类器,以Concept_1为测试集,图5描述了在不同的基分类器数目下集成学习模型分类性能的变化情况.

Fig. 5 The effect of the number of base classifiers图5 基分类器数目对分类效果影响
由图5可见,当分类器数目为4时,分类器的准确率、精确率、召回率和综合评价均达到最高,分类效果最优.减小或增加分类器数目时,各项评价指标都会出现相应的下降,因此本文集成学习基分类器数目选择4,使分类模型性能最优.
3.5.2 分类准确率
本文根据准确率和综合评价评估算法的分类性能.在单分类器中决策树C4.5的分类效果较好,本文将同时与C4.5分类器进行对比,如图6所示为4种方法(ECDD,C4.5,DDM,STEPT)的分类准确率对比.
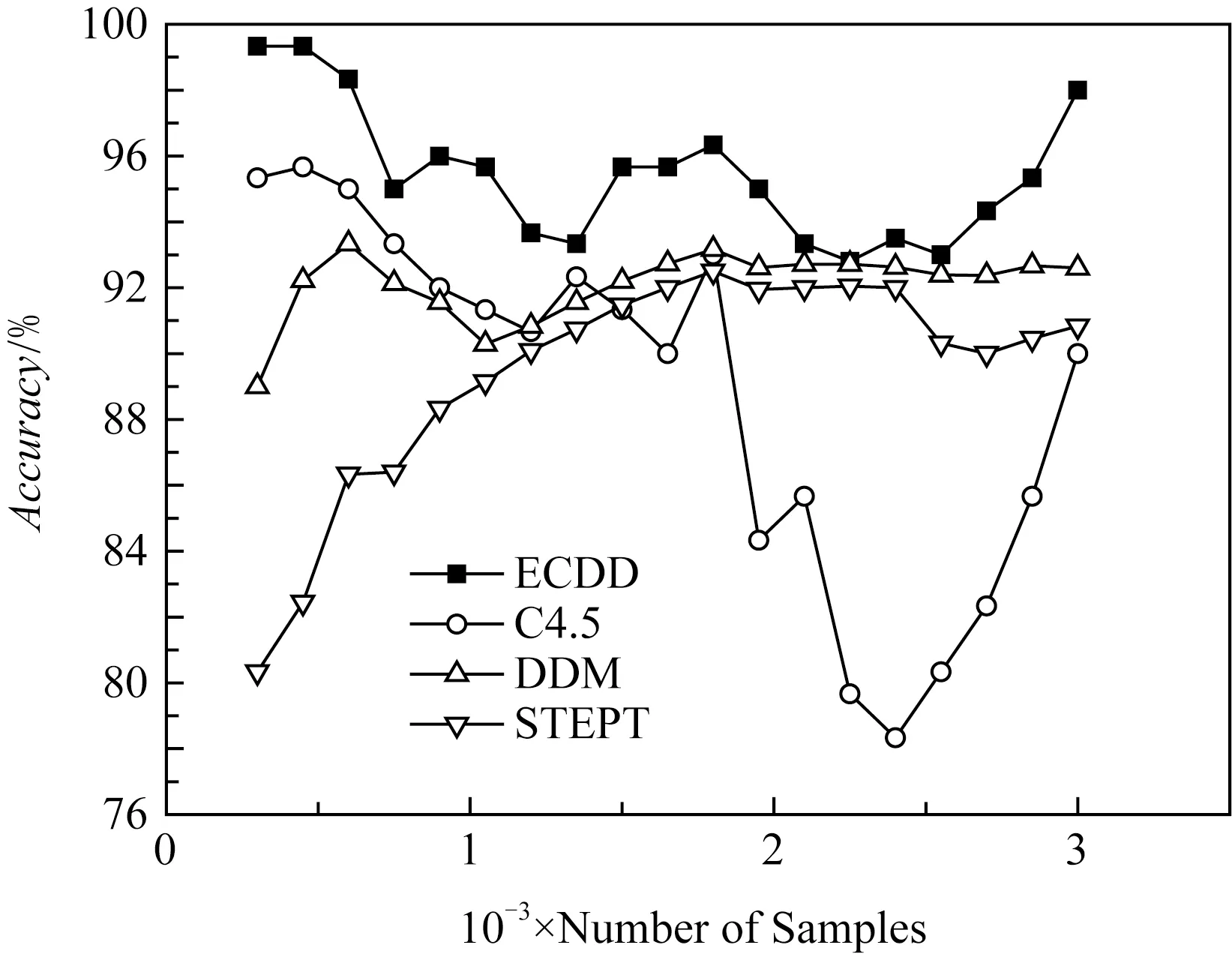
Fig. 6 Comparison of classification accuracy图6 4种方法分类准确率对比
如图6所示,在检测到概念漂移时,ECDD方法可以快速地更新分类器,根据检测到的概念漂移点引入新流量重新学习,更新分类器使分类精度回升.C4.5方法由于没有概念漂移检测机制,在发生概念漂移时无法引入新流量更新分类器.DDM与STEPT基于分类准确率判断概念漂移的产生,由于流量不同类别的识别率存在差异,因此对于总体的识别准确率有较大差异,导致这2种方法可能无法有效地检测概念漂移,最终影响分类准确率.
如图7所示为4种分类方法(ECDD,C4.5,DDM,STEPT)的综合评价对比.

Fig. 7 Comparison of F1_score图7 4种方法综合评价对比
由图7可见,ECDD方法在F1_score上总体优于C4.5,DDM,STEPT等方法.
综上,ECDD方法的分类效果明显好于C4.5,DDM,EDDM等方法,ECDD方法可以及时有效地更新分类模型,使得分类器保持良好的分类性能.
4 结 论
网络应用层出不穷,不同网络应用可能具有不同的特征分布,导致包含这些应用的网络业务流特征和分布随之发生改变,产生概念漂移问题,概念漂移导致分类模型分类精度降低,性能下降.本文提出一种基于散度的网络流概念漂移分类方法ECDD,该方法首先根据网络流量特征的JS散度变化检测概念漂移,在检测到概念漂移后根据增量集成学习策略引入新样本建立的分类器;接着根据权值比较替换性能下降的分类器;最后,将更新后的集成分类器用于之后的流量分类中.实验结果表明该方法可以有效地检测概念漂移,并在概念漂移点更新分类器,达到良好的分类性能.下一步工作将研究如何处理含噪声的概念漂移网络流.
