基于注意力机制的多通道CNN和BiGRU的文本情感倾向性分析
2021-01-05尧磊波张光河唐天伟项国雄陈豪迈
程 艳 尧磊波 张光河 唐天伟 项国雄 陈豪迈 冯 悦 蔡 壮
1(江西师范大学计算机信息工程学院 南昌 330022)
2(江西师范大学管理决策评价研究中心 南昌 330022)
3(江西师范大学新闻与传播学院 南昌 330022)
4(豫章师范学院数学与计算机学院 南昌 330022)
情感分析,也称为观点挖掘,是指人们对服务、产品、组织、个人、问题、事件、话题及其属性的情感、观点、评价、态度和情绪[1].在自然语言处理领域,情感倾向性分析是一项基础性任务,近年来已经吸引了国内外学者的广泛关注.随着互联网和移动网络的快速发展,用户在网上发表的观点和评论也越来越多,从这些内容中挖掘出重要的情感信息也值得探索.情感分析主要分为主客观情感识别和情感分类这2类,主客观情感识别是将给定文本分成主观性或客观性文本,情感分类则是把主观性文本分类为正面、负面或者中性[2].情感分析方法主要有基于机器学习和基于情感词典的这2类方法,随着神经网络研究的再次复苏,基于深度学习的方法被广泛应用到文本情感分析任务中.基于情感词典的方法最先被用于情感分析领域,它首先需要构建一个情感词典,然后对情感词典进行手工极性和强度标注,最后实现对文本的情感分类.这种方法虽然能够对文本进行情感分类,但是分类的效率并不高,因为它需要人工构建情感词典并进行手工标注.20世纪90年代,机器学习方法开始在文本情感分析中崭露头角[3-4].机器学习方法模型的函数虽然简单,但通常需要复杂的特征工程,而特征的好坏能够直接影响后面的分类效果,此外,机器学习方法的泛化能力比较低.近年来兴起的深度学习方法很好地弥补了基于机器学习和基于情感词典2种方法的缺陷,并被成功地应用于自然语言处理任务中,尤其是被应用在情感分析任务中,如卷积神经网络[5-7](convolution neural network, CNN)、长短期记忆(long-short term memory, LSTM)网络[8-9].循环神经网络(recurrent neural network, RNN)和CNN是目前深度学习领域比较热门的2种模型.但这2种模型也都存在一定的缺陷,CNN不能考虑到上下文语义信息,从而忽视了句子之间的相互联系;RNN模型缺乏对文本特征提取的能力,不能很好地提取句子的局部特征.针对2种模型存在的缺陷问题,本文利用CNN、双向门控循环单元(bidirectional gated recurrent unit, BiGRU)网络模型和注意力机制,结合word2vec词向量[10]表示模型,提出一种基于注意力机制的多通道CNN和BiGRU网络的模型来解决文本情感分类问题.模型使用3个CNN进行信息抽取,利用不同大小的卷积窗口进行粒度不同的情感特征提取,从而可以提取到更丰富的文本情感特征.BiGRU网络能够考虑文本上下文信息和保持句子间单词时序,因此能够更加充分地利用整个文本中的特征信息,有效识别文本情感极性.同时在CNN通道和BiGRU网络通道都引入注意力机制,能够更加关注句子中对分类重要的单词信息,以此来进一步提升分类准确率.
本文的主要贡献有3个方面:
1) 利用双向GRU(BiGRU)代替单向GRU和传统的RNN模型,使模型既能够考虑到文本上下文语义信息,又能够解决梯度消失问题.
2) 提出一种结合CNN和BiGRU的网络模型.该模型既能够利用不同大小的卷积核在CNN不同通道内提取文本中粒度不同的特征信息,又能够使用BiGRU网络充分考虑到句子上下文语义信息,弥补了各自的缺陷,增强了模型的文本特征提取能力,提高了分类准确率.
3) 将注意力机制引入到本文模型中,它能够提取影响情感极性分类的关键文本特征,使模型能够关注到句子中对文本分类贡献大的词语,以此来提升CNN和BiGRU网络的特征提取效果.
1 相关工作
情感分析是研究人们对实体的看法、态度和情感的.情感倾向性分析一直都是自然语言处理领域的研究热点.早些年,主要使用基于情感词典和传统的机器学习的方法进行情感倾向性分析.基于情感词典的方法是使用情感词典中已经人工标注好的词条和句子中分好词的每个词语进行匹配,再用相关公式对每个句子进行计算并打分,最后整个句子得分大于0的分为正类,小于0的分为负类,以此进行文本情感倾向性分析.对于英文词典,Kamps等人[11]使用WordNet英文情感词典判断英文文本的情感倾向性.与英文情感词典相比,规范的中文情感词典相对缺乏,最早也是最普遍使用的是由董振东等人[12]标注的大型情感分析词语库HowNet.基于情感词典进行分类的方法虽然操作简单,但是情感词典的构建耗时耗力,且扩充范围有限,具有领域局限性.而传统的基于机器学习的情感分类方法通常被看作是一类有监督学习问题.Pang等人[13]在2004年利用最大熵、朴素贝叶斯和支持向量机(support vector machine, SVM)在文本情感分析中进行了实验比较,发现使用SVM进行文本情感分类能够达到最优效果.Lee等人[14]将最大熵分类应用于给定电子产品评论的极性评估.这些机器学习方法虽然能够进行文本情感分类,但是在分类的过程中需要复杂的特征选择,这个过程同样需要人工设计,同样会导致其扩展性差,很难适应不同的领域和应用需求.
近些年来,深度学习方法逐渐成为了情感分析的主流方法.它不需要人工进行干预,是一种端到端的方法,可以实现对特征进行自动选择,因此效率会比基于词典和机器学习的方法更高,且领域适用性更强.Collobert等人[15]于2011年首先提出使用CNN解决词性标注等自然语言处理(natural language processing, NLP)领域的问题.在2014年,Kim[6]提出将CNN应用于英文文本情感分类任务中,并取得了当时不错的分类结果.Kalchbrenner等人[5]提出了一种宽卷积模型,并且用k-max池化代替了传统CNN的最大池化,这样做可以保留更多的特征信息.这种模型不需要任何的先验信息输入,也不需要构造非常复杂的人工特征.Yin等人[16]使用多通道不同尺寸的卷积神经网络进行句子分类.陈珂等人[17]提出一种多通道卷积神经网络模型,使用多个卷积神经网络提取句子的多方面特征,在中文微博情感分析任务上取得了不错的效果.然而,基于CNN的文本情感分类存在不能考虑句子上下文语义信息问题.
相较于CNN,RNN引入了记忆单元使得网络具备了一定的记忆性,能够捕捉到文本间的长距离依赖关系.但是它也存在一定的弊端,即在训练的过程中会出现梯度消失问题.而LSTM和门控循环单元(gated recurrent unit, GRU)网络在传统的RNN基础上引入了门机制,较好地克服了RNN中梯度消失的弊端.基于LSTM和GRU模型,很多人在它们基础上进行改进,并取得了不错的分类效果.Tang等人[18]首先使用CNN或LSTM实现单句表示,然后再用gated RNN编码句子间的内在关系和语义联系,最后再实现篇章级文本的编码,通过此方法可以较好地捕获句子间的语义信息.Lai等人[19]提出了一种RCNN模型,首先利用双向循环网络模型得到单词的上下文信息,然后再通过CNN的卷积池化过程进行文本分类,在ZONews,Fudan,ACL,SST这4个测试集上取得了最好的效果.Zhou等人[20]提出了一种C-LSTM模型,首先利用卷积神经网络提取文本特征,然后再用LSTM网络代替最大池化层得到最终分类结果.Ruder等人[21]使用一种层次化的双向LSTM模型进行方面级别的文本情感分类.Rao等人[22]使用2层LSTM进行文档级别的情感分类.Sachin等人[23]使用LSTM、GRU、双向GRU和双向LSTM方法进行亚马逊评论情感分析,并取得了不错的效果.虽然LSTM和GRU模型能够提取到上下文语义信息和考虑到单词间时序问题,但是它们并不能像CNN那样很好地提取句子的局部特征.
为了能够充分发挥CNN和RNN的各自优势,越来越多的研究者将CNN与RNN进行结合以此来进行文本情感倾向性分析.Wang等人[24]使用一层CNN和一层RNN构成一个融合模型,进行短文本情感分析,实验证明效果优于单纯使用CNN和RNN模型.Zhou等人[25]提出一种结合双向LSTM和CNN的模型,并在池化层使用2维最大池化代替传统的最大池化得到最终分类结果.Zhang等人[26]提出一种CNN-LSTM模型,用于预测Twitter文本的情感强度.Zhang等人[27]提出一种多通道CNN-LSTM模型,用于Twitter文本情感分类任务.Alayba等人[28]提出一种结合CNN和LSTM模型,用于阿拉伯语情感分析,并取得了不错的分类效果.Zhang等人[29]使用基于Convolution-GRU模型对Twitter仇恨评论文本进行情感极性判别.
近几年来,注意力机制被广泛应用于文本分类任务中,因为注意力机制能够让模型从大量信息中有选择性地筛选出重要信息,同时忽略一些不重要的信息,能够让模型注意到句子中对情感分类重要的词语,例如Yang等人[30]结合了双向RNN与注意力机制,构建了注意力模型应用在篇章级文本分类任务中,取得了当时文本分类任务的最佳结果;Wang等人[31]将多层注意力机制和CNN结合用于句子关系分类任务中,模型在多个数据集上的实验结果表明,使用注意力机制的模型比未使用的模型有更高的分类精度.Yang等人[32]提出2种不同的基于注意力机制的双向LSTM模型用于目标相关的情感分类,在当时达到了最好的分类效果.Wu等人[33]使用基于注意力机制的CNN-LSTM网络模型进行Twitter文本情感强度分析,并取得了不错的效果.程艳等人[34]提出一种融合卷积神经网络与层次化注意力网络的模型,先利用CNN学习词语特征,然后再将其输入到基于注意力机制的双向GRU网络中得到句子的情感倾向.吴小华等人[35]提出一种结合双向LSTM和自注意力机制的模型,先使用双向LSTM得到文本的上下文语义特征,然后通过自注意力机制自动调整特征权重,在短文本情感分类任务上取得了不错的效果.袁和金等人[36]提出一种提出了一种基于多通道卷积与双向GRU网络的情感分析模型,并在双向GRU网络上引入注意力机制来自动关注对情感极性影响较强的特征.鉴于融合注意力机制的神经网络模型的出色表现,本文在对文本情感倾向性分析任务中也引入了注意力机制,使网络模型能够更多地注意到对文本情感极性贡献大的词语.
基于CNN,RNN和注意力机制各自的优点,本文提出一种基于注意力机制的多通道CNN和BiGRU网络模型,该模型利用3通道CNN提取文本不同粒度的局部特征信息,并且使用BiGRU网络模型代替传统的RNN模型,提取文本上下文语义信息,然后在每一个通道上都引入注意力机制,最后将它们进行拼接,得到一种新的基于注意力机制的多通道神经网络模型.本文综合利用CNN,BiGRU网络和注意力机制这3种深度学习方法的优点,既考虑了文本的局部信息又考虑到了上下文语义信息,避免了文本信息的丢失,还能通过注意力机制关注到句子中对情感分类贡献较大的词语,提高了模型对文本情感分类性能.
2 模 型
2.1 卷积神经网络

oi=W·Si:i+h-1,
(1)
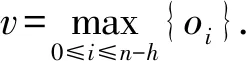

Fig. 1 The structure of the CNN图1 CNN结构
我们在2.1节已经详细描述了用一个过滤器提取一个特征的过程.图1中模型利用了几个不同大小的过滤器(具有不同窗口大小)来提取不同的特征,接下来把每一个过滤器提取的特征进行max-pooling操作,以此来得到多个不同的最重要特征,然后把这些特征进行拼接,最后再传递给全连接的Softmax层,其输出是标签上的概率分布.
2.2 门控循环单元络和双向门控循环单元网络
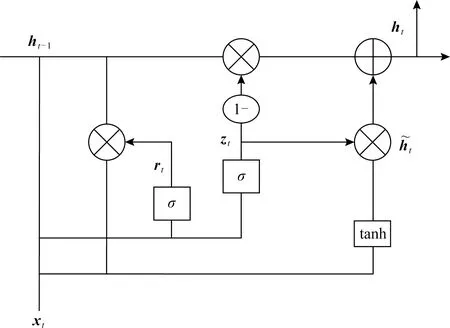
Fig. 2 The structure of the GRU图2 GRU结构
Cho等人[38]在2014年最初提出了一种GRU网络模型,以使每个循环单元能够自适应地捕获不同时间尺度的依赖性,有关GRU的结构说明如图2所示:
相比于LSTM,GRU的模型更为简单,仅由更新门z和重置门r构成,比LSTM少了一个门,所以在训练的时候参数更少,收敛时间更快.可以通过式(2)~(5)更新参数:
rt=σ(Wrxt+Urht-1),
(2)
zt=σ(Wzxt+Uzht-1),
(3)
(4)
(5)
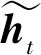
单向GRU的状态是从前往后单向传输的,也就是忽略了后文单词对整体状态的影响;BiGRU是GRU的一个变体,它的输出取决于前向状态和后向状态的双重影响,解决了单向GRU存在的问题,使得最后的输出结果更加准确.BiGRU的模型结构如图3所示:

Fig. 3 The structure of the BiGRU图3 双向GRU结构
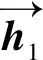
2.3 注意力机制
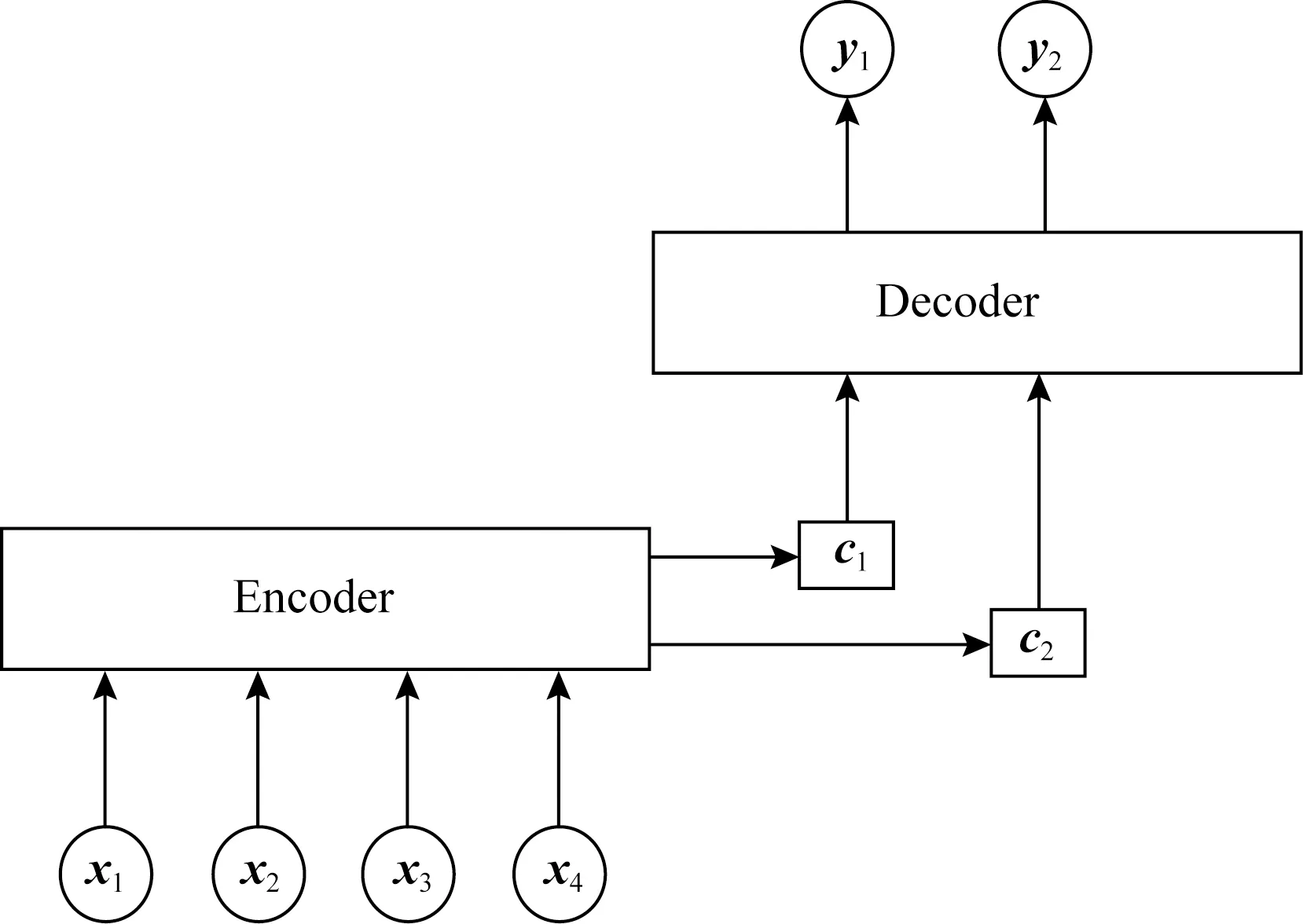
Fig. 4 The structure of attention mechanism图4 注意力机制结构
注意力机制早在2014年便被应用在机器翻译任务上[39],并取得了当时最好的效果.2016年,Yang等人[30]把注意力机制应用于文本篇章级别的情感分类任务中,取得了不错的分类效果.因为对于每个句子而言,每个词的重要程度不同,所以本文引入注意力机制来提取句子中重要单词的语义信息.注意力机制可以抽象为由Encoder和Decoder这2个模块组成.Encoder一般为编码器,对输入数据做一定的变换得到语义向量;Decoder一般为解码器,同样经过一定的变换后得到输出数据.注意力机制结构如图4所示.
主要公式如式(6)~(8)所示:
ui=tanh(Wihi+bi),
(6)
(7)
(8)
其中,uw为随机初始化的上下文向量,在训练的过程中更新;ui为隐藏层向量hi经过一个全连接运算得到的结果;Wi和bi分别为注意力计算的权值矩阵和偏置项;αi为句子中第i个单词的注意力分数,L为句子的长度.
2.4 模型整体结构
本文在上述基础模型上提出一种基于注意力机制的多通道CNN和BiGRU网络的文本情感分析模型.该模型由卷积神经网络、双向门控循环网络和注意力机制组成,模型结构如图5所示.
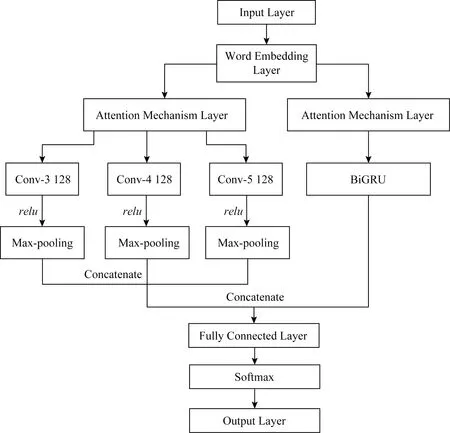
Fig. 5 The overall structure of model图5 模型整体结构
本文的总体模型是由多个通道组成,主体是3个拼接的CNN模型通道和一个BiGRU模型通道,3个CNN通道主要是用来提取句子间词语的不同的局部特征,而BiGRU通道是用来得到句子上下文语义信息.CNN通道的输入是每个句子经过分词操作得到的词语.第1层是嵌入层,作用是把输入的每个词语映射成一个向量表示;第2层是注意力机制层,主要是为了提取句子间重要单词信息;第3层是卷积层,主要用来提取词语间的局部特征,本文词向量维度选取300维,选择的3种过滤器大小分别为3×300,4×300,5×300,每一种过滤器各128个,步长stride=1,padding=valid(不需要进行补零操作),经过卷积操作之后就能得到句子的局部特征;第4层为池化层,主要是把卷积层得到的局部特征进行最大池化操作,提取句子间最重要的特征,丢弃部分不相关和无用特征,以此生成固定维度的特征向量,再将3个经过最大池化操作输出的特征进行拼接,作为全连接层输入的一部分,经过3种不同过滤器得到的3种不同的特征经过拼接后可以为后面句子情感分类提供更丰富的特征信息.
BiGRU通道的第1层亦为词嵌入层,词向量的维度也设置为300维,第2层同样是一个注意力机制层,和用于CNN模型的注意力机制一样,均用来提取句子中重要的单词信息;BiGRU的第3层和第4层分别为前向GRU和后向GRU结构,它们的隐藏层大小都设置为128,因为当前时刻的输入单词和前后序列单词都有一定的关系,所以将输入序列分别从前后2个方向输入GRU模型中,如图3所示,然后通过隐藏层来保存前后方向文本的信息,最后将这2个隐藏层的输出进行拼接,得到BiGRU最后输出,BiGRU输出代码如下:BiGru_output=keras.layers.Bidirectional(gru(hidden_dim,return_sequences=True))(inputs).
利用BiGRU模型主要是用来提取句子中词的上下文语义信息,以此来提取文本中词语的全局特征,然后我们将CNN通道中经过池化操作拼接起来的特征和BiGRU的输出进行融合,融合的代码为:output=keras.layers.merge.concatenate([cnn_output,BiGru_output]).
将融合的特征作为全连接层的输入,全连接层中的激活函数都是使用relu,在全连接层之后加入dropout机制,每次训练的时候都让一部分神经元不工作,这样做的目的是为了防止过拟合,最后再把它输入到Softmax分类器中得到最后的分类结果,本文Softmax分类器将x分类为类别j的概率如式(9)所示:
(9)
其中,θ为训练中的所有参数,k=2,本文均为二分类任务.
3 实验分析
3.1 实验环境
本文实验环境如下:操作系统为Windows10,CPU是Intel Core i7-6700U,GPU为GeForce GTX 1080,内存大小为DDR3 8 GB,开发环境为Keras 2.1.0,开发工具使用的是PyCharm.
3.2 实验数据集
本文实验部分在2个公开数据集上进行:
1) 谭松波酒店评论数据集.用户在国内不同酒店上的评论数据集,然后经过谭松波教授的整理,用于情感倾向性分析.
2) IMDB[40]数据集.国外用户在网站上对电影的评论数据,评论包括正向和负向的情感,用于情感倾向性分析.
数据集中的每条评论已经被人为地设置了情感标签,这2个数据集具体信息如表1所示,部分评论数据如表2所示,为了减少训练过程中带来的随机性影响,我们分别在这2个数据集上进行10折交叉验证实验.本文句子的长度我们用词语个数来衡量.
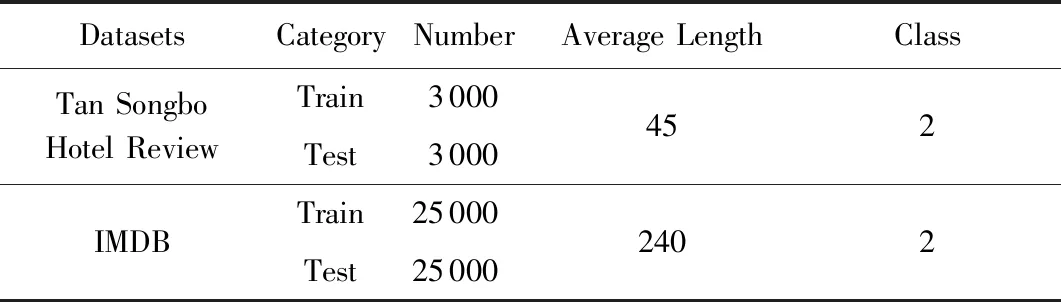
Table1 Specific Information of Two Datasets表1 2个数据集具体信息

Table 2 Part of Review Data表2 部分评论数据
3.3 实验预处理与模型超参数设置
词向量在自然语言处理中起着至关重要的作用,结合词向量进行预训练有助于提高模型的准确率[41].对于中文数据集,本文使用大规模中文Wikipedia百科数据集来预训练CBOW模型,以此来得到中文词向量,经过训练之后,每个语义相近的中文词语被映射到向量空间中相近的位置上,在训练过程中,我们设置词向量的维度大小为300.首先用Jieba分词工具对输入的句子进行分词操作,之后去除停用词,然后使用词向量训练工具把这些词语转换为向量形式后作为神经网络的输入.对于英文数据集,本文使用大规模英文Wikipedia数据集来训练CBOW模型,以此来得到英文词向量,在训练过程中我们同样设置词向量维度为300.然后通过空格把每个句子分成一个个单词,再去除停用词,本文中我们把句子最大长度设置为200,小于该长度时,对句子进行补零操作,大于该值时进行截断操作.本文实验基于Keras深度学习框架,模型的优化函数采用Adam[42]函数,因为它能为不同的参数设计独立的自适应性学习率,并且能够加快网络收敛速度.
在本文实验中,为了得到更加丰富的情感特征信息,将多通道CNN所选取的卷积核窗口大小分别为3,4,5,每个卷积核的数量都为128.为了防止过拟合现象,我们使用了L2正则化和dropout机制.本文模型的详细超参数设置如表3所示:
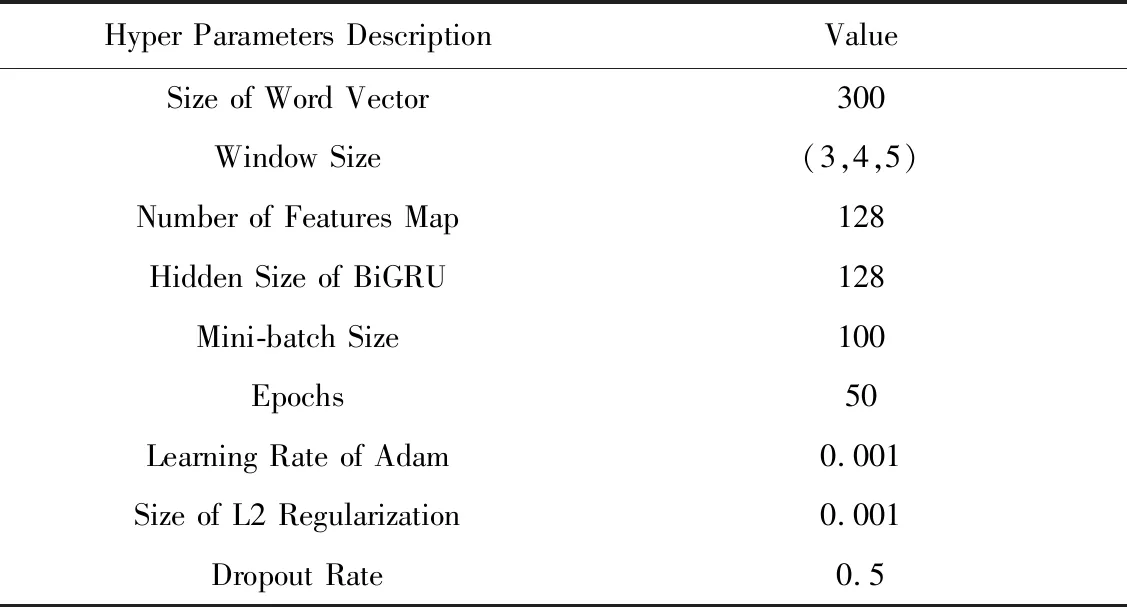
Table 3 Hyper Parameters of Experiment表3 模型超参数设置
3.4 实验对比
为了验证本文提出的模型的分类性能,我们使用准确率作为评估指标,将本文基于注意力机制的多通道CNN和BiGRU模型(MC-AttCNN-AttBiGRU)分别与13种模型方法在2个数据集上进行实验对比.
1) SVM.相较于其他机器学习方法,SVM在情感分类上面的效果较好[13],本文先把句子中的每个单词用词向量表示,然后再把这些单词向量进行加权平均作为SVM的输入进行分类.
2) Fasttext[43].Fasttext是Facebook开源的文本分类工具.在本实验中,将模型学习率设为0.01,词向量的维度设置为300.
3) CNN[6].普通的单通道CNN分类,把句子中每个词语经过词嵌入之后得到的词向量作为CNN的输入,然后经过卷积层、池化层、全连接层和最后的Softmax输出层进行分类.
4) MC-CNN.这是卷积核窗口大小分别为3,4,5的3个卷积层通道的拼接,即3通道CNN情感分类模型,过程和单个CNN分类一样,只是最后把3个经过池化层得到的最大特征进行了拼接,以此来获得更丰富、不同粒度的特征信息.
5) RCNN[19].这是一个单通道的CNN-RNN模型,该模型使用CNN和RNN进行文本分类,在训练的过程中对输入词向量进行微调.
6) C-LSTM[20].这是一个单通道CNN-LSTM模型,首先把句子中每个词语经过词嵌入之后得到的词向量作为CNN的输入,然后把抽取到的特征作为LSTM的输入,最后再经过全连接和Softmax层得到最终分类结果.
7) Convolution-GRU[29].这是一种结合CNN和GRU的复合模型,首先把句子中每个词语经过词嵌入之后得到的词向量作为CNN的输入,然后把抽取到的特征作为GRU的输入,最后再经过全连接和Softmax层得到最终分类结果.
8) MC-CNN-LSTM[27].这是一种多通道的CNN-LSTM模型,该模型由2部分组成:一部分是多通道CNN模型;另一部分是LSTM模型.首先使用多通道CNN抽取不同的n-gram特征,然后把得到的特征作为LSTM的输入,最后再经过全连接和Softmax层得到最终分类结果.
9) BiGRU.使用经过词嵌入之后的单词向量作为输入经过BiGRU网络模型进行句子情感分类.
10) ATT-MCNN-BGRUM[36].该模型是一种单通道的CNN-BiGRU模型,首先使用多通道的CNN模型提取到文本的不同的n-gram特征,然后将其输入到基于注意力机制的BiGRU模型中,最后使用Maxout神经元得到最后的分类结果.
11) MC-CNN-BiGRU.这是3个CNN通道和BiGRU通道的拼接,3个CNN通道和BiGRU通道的输入都是经过词嵌入之后单词的词向量,但3个CNN通道和BiGRU通道都不加入注意力机制.
12) MC-AttCNN-BiGRU.这是3个CNN通道和BiGRU通道的拼接,并且在3个CNN通道上都加入注意力机制,而BiGRU通道不加入注意力机制,其他参数设置和MC-CNN-BiGRU一致.
13) MC-CNN-AttBiGRU.这是3个CNN通道和BiGRU通道的拼接,并且在BiGRU通道上加入注意力机制,而3个CNN通道不加入注意机制,其他参数设置和MC-CNN-BiGRU一致.
14) MC-AttCNN-AttBiGRU.这是本文提出的最终模型,3个CNN通道和BiGRU通道的拼接,并且在BiGRU通道和3个CNN通道上都加入注意力机制,以经过词嵌入之后得到的词向量作为输入,分别通过CNN通道和BiGRU通道提取特征,最后将提取到的2种特征融合进行最后的情感分类.
3.5 实验结果分析
本文用所提出的MC-AttCNN-AttBiGRU与3.4节其他13种神经网络模型方法在谭松波酒店评论数据集和IMDB上进行实验对比,实验结果如表4所示:

Table 4 Accuracy Comparison of the Proposed Model and Other Baseline Models on Two Public Datasets表4 本文模型和其他基线模型在2种公开数据集上的准确率对比 %
从表4可以看出,本文提出的MC-AttCNN-AttBiGRU模型方法在2个数据集上都取得了比其他模型更好的分类效果,在谭松波酒店评论数据集上准确率达到了92.28%,在IMDB数据集上准确率达到了91.70%,说明了本文所提模型的优越性.
由表4可知,基于神经网络模型方法(CNN,RCNN等)在分类效果上还是显著优于传统机器学习模型方法SVM的,因为SVM模型只是简单地对句子中所有单词向量进行加权平均,并没有考虑到句子间的上下文语义和一些更深层次的信息,所以分类效果不好,基于神经网络模型方法准确率大概比基于传统机器学习方法SVM高10%左右,说明了深度学习方法在文本情感分类任务上更有效果;此外,Fasttext模型分类准确率(83.96%,81.69%)优于SVM模型(80.16%,79.86%),证明Fasttext模型在文本情感分析中的优良性能,因为其模型简单,运算速度快,因此本文把它作为基线模型;在谭松波酒店评论数据集上,CNN和BiGRU的分类准确率相近,因为它们都能提取到一定的语义信息,但CNN的准确率要比BiGRU的稍微高一点,这是因为谭松波酒店评论数据集较小并且评论文本较短,CNN可以很好地提取句子整体特征,而BiGRU却无法在短文本上充分发挥其优势;在IMDB数据集上,BiGRU的分类准确率要比CNN准确率要稍微高一点,这是因为IMDB数据集的每条评论都很长,BiGRU可以充分发挥其长距离记忆的优势;通过MC-CNN和单通道CNN,C-LSTM和MC-CNN-LSTM,ATT-MCNN-BGRUM和MC-AttCNN-AttBiGRU这3组对比实验可以看出,多通道模型相对于单通道模型能够提取到更丰富的情感特征信息,有助于提高情感分类性能;通过对比C-LSTM和Convolution-GRU可以看出,Convolution-GRU模型在本文数据集上的分类效果要优于C-LSTM模型;通过对比MC-CNN-BiGRU,MC-CNN-LSTM和RCNN,C-LSTM,Convolution-GRU可以看出多通道的CNN-RNN模型还是优于单通道CNN-RNN模型;通过MC-CNN-BiGRU和CNN,BiGRU进行对比可以看出融合了CNN和BiGRU的多通道模型还是比单独的CNN,BiGRU分类效果要好得多,这是因为MC-CNN-BiGRU结合了CNN和BiGRU各自的优点,既能提取到句子间连续单词的局部信息又能够获得句子上下文语义信息,从而得到更高的分类准确率.通过MC-AttCNN-BiGRU,MC-CNN-AttBiGRU和MC-CNN-BiGRU对比发现,加入注意力机制的多通道模型可以更好地提高分类准确率,因为它能让模型更加注意到句子中那些对情感分类贡献较大的单词;通过MC-AttCNN-AttBiGRU和MC-AttCNN-BiGRU,MC-CNN-AttBiGRU对比发现,在CNN通道和BiGRU通道同时引入注意力机制还能再进一步提升文本分类准确率.
本文提出的MC-AttCNN-AttBiGRU模型方法不仅能够提取到句子中连续单词的局部特征信息,还能够捕获句子上下文语义信息,充分发挥了CNN和BiGRU各自的优势,并且引入注意力机制能够让模型在特征提取的过程中更加关注句子中比较重要的情感词语信息,减少那些对分类不重要的词语的影响,所以本文提出的模型相较于其他几种基线模型能够获得最好的效果.
3.6 注意力可视化
为了更加直观有效地展示模型效果,本文在实验部分使用seaborn库和matplotlib库进行句子中单词注意力权重分配的可视化展示,本文选取正面和负面评论各一段进行可视化展示实验.
文本1:总体感觉还不错.房间很干净、简洁、舒适.
文本2:酒店前台小女孩子服务太次, 态度很差.
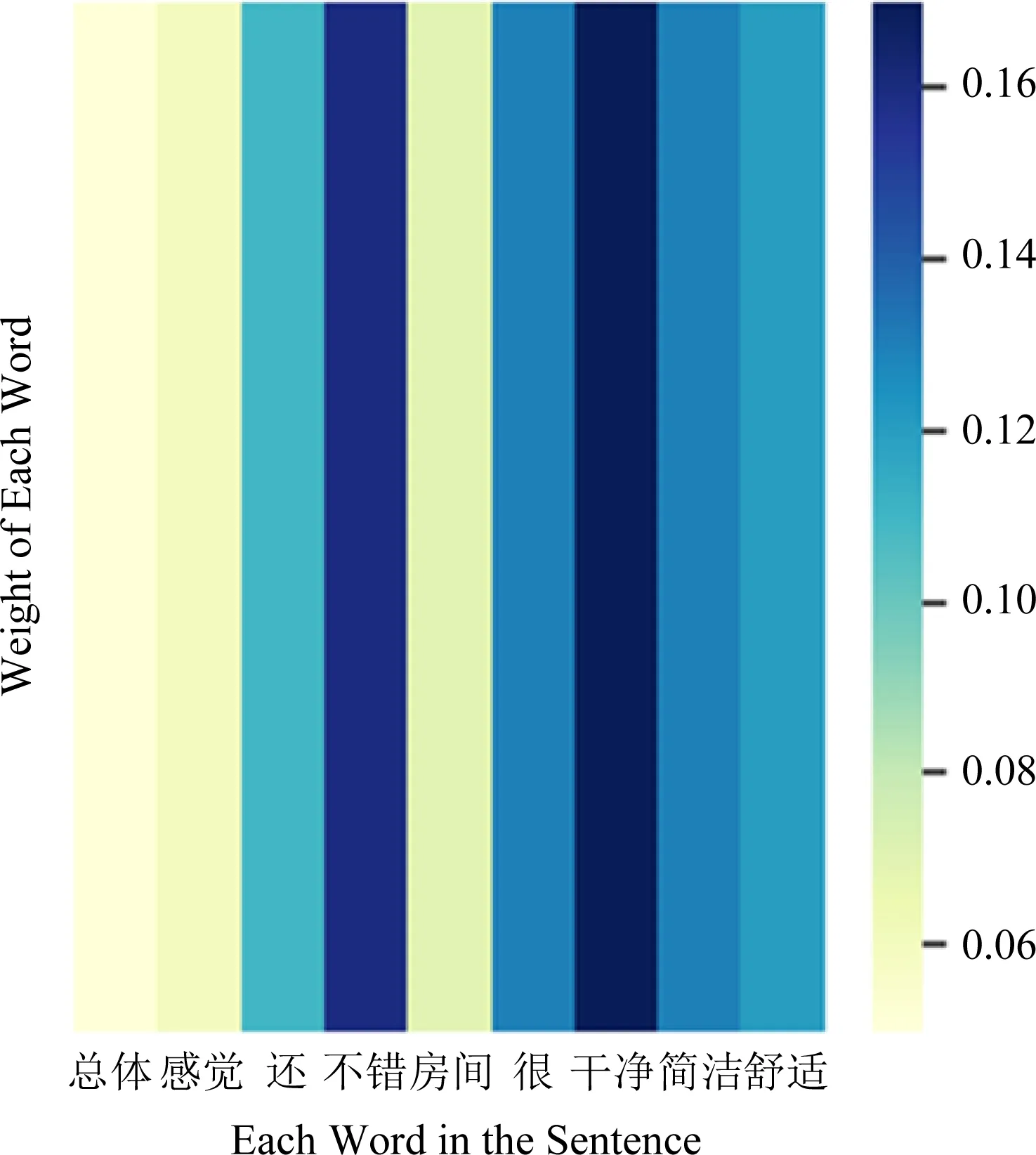
Fig. 6 Text one word attention weight heatmap图6 文本1单词注意力权重热力图
对于文本1和文本2,我们首先使用Jieba分词工具对句子进行分词,然后再去除标点符号和停用词,得到“总体 感觉 还 不错 房间 很 干净 简洁 舒适”和“酒店 前台 小 女孩子 服务 太 次 态度 很差”这些单词,然后再分别绘制单词级别的注意力权重热力图如图6、图7所示.图中颜色越深即灰度值越大,表示分配给单词的权重越高,说明该单词对后续情感分类的重要性更高.
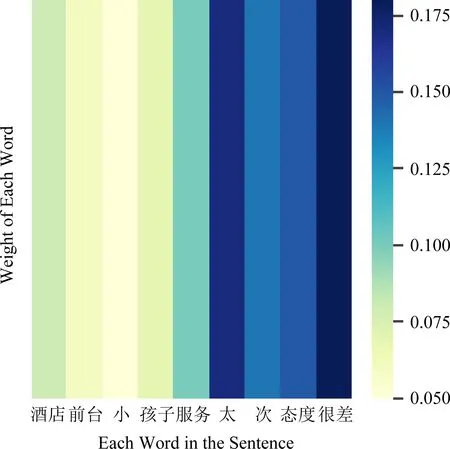
Fig. 7 Text two word attention weight heatmap图7 文本2单词注意力权重热力图
文本1中经过Jieba分词和去除停用词和标点之后包含9个单词,从图6中可以看出模型对“还”、“不错”、“很”、“干净”、“简洁”、“舒适”这几个单词分配了较高的权重,这些都是有关正面评论的词语;文本2经过Jieba分词和去除停用词之后也包含9个单词,从图7可以看出模型对“太”、“次”、“很差”这几个单词分配了较高的权重,这些都是有关负面评论的词语.
通过在这2段正负评论文本上进行注意力权重可视化实验,结果表明:本文使用注意力机制可以很好地找出句子中对情感分析结果影响较大的单词,证明了注意力机制确实能够关注句子中比较重要的情感词语.
4 总结和展望
本文提出了一种基于注意力机制的多通道CNN和BiGRU的网络模型用于文本情感倾向性分析,该模型既能够利用CNN有效地提取到文本间相邻词语的局部特征,又能够利用BiGRU捕获句子上下文全局语义信息,而且引入注意力机制还能更好的注意到句子中对情感分类贡献大的词语.在中英文数据集上多个实验结果充分证明了本文提出模型的有效性,这种多通道混合模型比单一的CNN和BiGRU网络提取的特征效果更好,且本文提出的模型较其他几种基线模型在2个公认的数据集上都取得了最好的分类效果.
虽然本文模型可以通过CNN提取局部特征和BiGRU网络提取一定的上下文语义结构信息,但是这对于文本情感分类任务还是不够的.传统的文本情感分类方法一般加入了一些句法结构特征,而本文提出的模型没有使用任何句法结构特征,因此下一步工作我将探讨如何让深度学习方法与传统的方法结合,并考虑引入更多文本特征进一步来提高分类准确率.
