一种基于HashGraph的NoSQL型分布式存储因果一致性模型
2021-01-05田俊峰王彦骉
田俊峰 王彦骉
(河北大学网络空间安全与计算机学院 河北保定 071002)
(河北省高可信信息系统重点实验室(河北大学) 河北保定 071002)
分布式云存储是新一代数字时代发展的重要基石,公有云服务商的数据中心部署在不同的地方,为用户提供可扩展的计算、存储等服务[1].然而在提供高速、便捷服务的同时,保障分布式副本之间的数据一致性、因果一致性就成了比较严峻的问题.在理想的环境中下,副本中所有元数据的即时更新在其他节点中都立即可见,这种模型称为强一致性.但在分布式存储环境下,不牺牲一定的可用性和性能几乎无法实现;即使在没有对数据进行分区、分块存储,强一致性的实现也有着极高的性能成本.例如Guerraoui等人[2]基于增量更新提出的ICG(incremental con-sistency guarantees for replicated objects)方案,在牺牲通信开销和查询正确度的前提下提高了强一致性的操作延迟.
因此,许多系统使用最终一致性来保障用户数据安全,例如亚马逊的Dynamo[3]存储平台.该平台对用户数据可用性做出的唯一保障就是要求用户更新最终实现一致;为了确保多个副本都收敛到相同的数据状态,最终一致性的系统通常使用某种规则在多个差异的副本状态中选择一个作为最终稳定状态[4].
在Twitter、微博等社交软件或大型网站应用中,最终一致性是最常见的数据一致性约束,其次便是因果一致性,如MongoDB数据库就是典型的因果一致性数据存储产品.因果一致性是一种中间一致性模型,该模型只在系统要求可见的因果依赖性时,才要求保障记录用户事件的元数据的因果序.因果序就是前后2个用户事件之间一种有依赖性要求的发生顺序,有2个来源,一个是同一客户端中有前后顺序的更新,另一个是不同客户端中对同一个值的2次更新[5].为了实现数据因果一致性约束,分布式云存储模型需要提供验证因果一致性依赖关系的数据存取规则.具体来说,若用户要求某些元数据的因果依赖性不可见,那么系统中须保留一个对用户透明的变量.对于由多台机器组成的多节点数据分区来说,对因果依赖关系的校验就成了较难的问题.
1 相关工作和主要工作
1.1 相关工作
因果一致性可以在客户端与服务端分别实现,例如Zawirski等人[6]提出的客户端一致性方案.现有的工作中,在服务端实现因果一致性的解决方案都有较大性能开销,例如Lloyd等人[7]在2011年提出的COPS(clusters of order-preserving servers)模型,Du等人[8]在2013年提出的Orbe模型是较早的因果一致性数据存储模型.该类模型会对用户当前读取的值保持跟踪,当客户端写入某个新的键值时,系统中对客户端正在写入的新值因果依赖关系定义为:该客户端读取过的所有值.在分区同步消息中,这种明确的因果依赖关系校验机制要求极高的消息复杂度,导致分区间通信开销很大.
1) 近年来多数的成熟研究方案采用物理时钟方法对元数据和分区状态进行同步,如GentleRain是Du等人[9]在2014年提出的方案,依赖物理时钟的紧密同步、分区之间定期地进行通信来保障用户数据的因果序、正确性和系统性能.但该模型依赖于同步单调的物理时钟,若底层协议如网络时钟协议(network time protocol, NTP)出现异常(例如时钟偏移),就会导致GentleRain对PUT(用户向服务端写入新的数据)操作进行延迟等待.
2016年Tomsic等人[10]提出的PhysiCS-NMSI是一种使用了物理时钟,但对时钟的稳定性没有要求的数据因果一致性模型.该模型也使用一个单向的标量对数据依赖关系进行检查,并且提供数据因果一致性快照,保障用户写入事件操作的原子性,从而避免PUT等待、操作冲突等问题.
2) 混合逻辑时钟 (hybrid logical clocks, HLC)是Kulkarni等人[11]在2014年提出的一种基于物理时钟和逻辑时钟的时钟同步方法,用于在分布式存储系统中检查因果依赖关系.该方法在物理时钟基础上,用1组向量来表示用户数据条目的时间戳,优化了传统的物理时钟方法造成的PUT等待等缺陷.Okapi是Didona等人[12]在2017年提出的一种使用了混合逻辑时钟和全局稳定向量(global stable vector, GSV)的因果一致性模型,类似于文献[9]中的全局稳定时间(global stable time, GST),该模型设定一个状态值来校验和追踪当前分区最新条目、及其时间戳,时间戳不小于该状态值的元数据条目才被允许写入到分区内.该系统要求用户的查询操作须约束在所有节点都同步完用户更新之后,因此这个约束会大量增加Okapi的更新可见性延迟,甚至超过GentleRain.
Roohitavaf等人[13]在2017年提出了Causal-Spartan模型,基于混合逻辑时钟(HLC)和数据中心稳定向量(data center stable vectors, DSV)保障用户元数据的数据因果一致性,可提升在分区之间存在时钟偏移、查询放大的情况下的性能表现.而且提出了分区稳定向量的概念,若副本分区中单个查询被放大成大量内部查询,不仅提升了写入和查询服务的可靠性,还降低了客户端操作更新等待时间.但由于副本分区稳定向量包含数据中心所有条目,大大增加了分区之间同步数据的通信成本.此外,在服务器收到用户请求的更新后,子节点之间、父节点之间、以及父节点和子节点之间对数据、状态和时钟进行同步,以期满足因果依赖性约束的过程也会耗费较长时间.
1.2 主要工作
为解决时钟偏移和查询放大造成的用户PUT等待时间过长的问题,本文在混合逻辑时钟和数据中心稳定向量的基础上,结合HashGraph的原理,提出了一种使用部分稳定向量和依赖集签名的因果一致性模型Causal-Pdh(causal consistency using partDSVand Hash of dependency series),如图1所示,主要贡献有3个方面:
1) 写入操作中,服务端在发给客户端的PUT响应消息中,根据本地最新依赖集计算服务端依赖集签名(Hash of dependency series,HDS),然后发送给客户端,客户端根据响应消息更新本地依赖集后,也在本地计算客户端HDS,然后与收到的服务端HDS进行验证,为写入数据的过程提供完整性约束.

Fig. 1 Entity flow diagram model of Causal-Pdh图1 Causal-Pdh协议的实体流图模型
2) 查询操作中,服务端在收到客户端查询请求后,计算本地DSV对应的HDS,然后将客户端请求对应的partDSV,serverHDS发送给客户端,客户端更新本地依赖集后计算HDS,并与收到的服务端HDS验证.证明在分区存在时钟偏移与用户查询放大的情况下,请求响应时间有明显减少.
3)借鉴HashGraph的思想,数据中心之间随机同步本地最新稳定向量与对应的HDS,分区之间对数据中心最新状态、时钟进行同步共享,各副本、分区同时验证收到的HDS签名与本地最新数据、状态对应的HDS签名.用户更新后,所有数据中心间、副本间同步数据达成数据因果一致性共识所需的时间明显降低.
2 分布式系统因果一致性原理
随着数据量的爆发式增长以及应用负载的快速增加,传统数据库所采用的单一服务器模式,越来越难以应对当今应用对数据存储的需求[4].分布式云存储服务提供商通常利用一定的通信技术,将文件分布到物理位置独立的服务器中,最终提供相应的接口给用户端上传、下载或更新[14],从而降低响应来自不同地理位置的用户请求所需的时间.实际应用中,分布式存储模型的拓扑结构通常设定为双层结构,即对数据进行分区存储,如图2所示:数据中心为父节点,副本节点中的分区为子节点.例如CausalSpartan模型将用户元数据保存在M个数据中心,每个数据中心分为N个分区,该类方案中通常约束每个客户端只从当前所连接的分区读写数据.
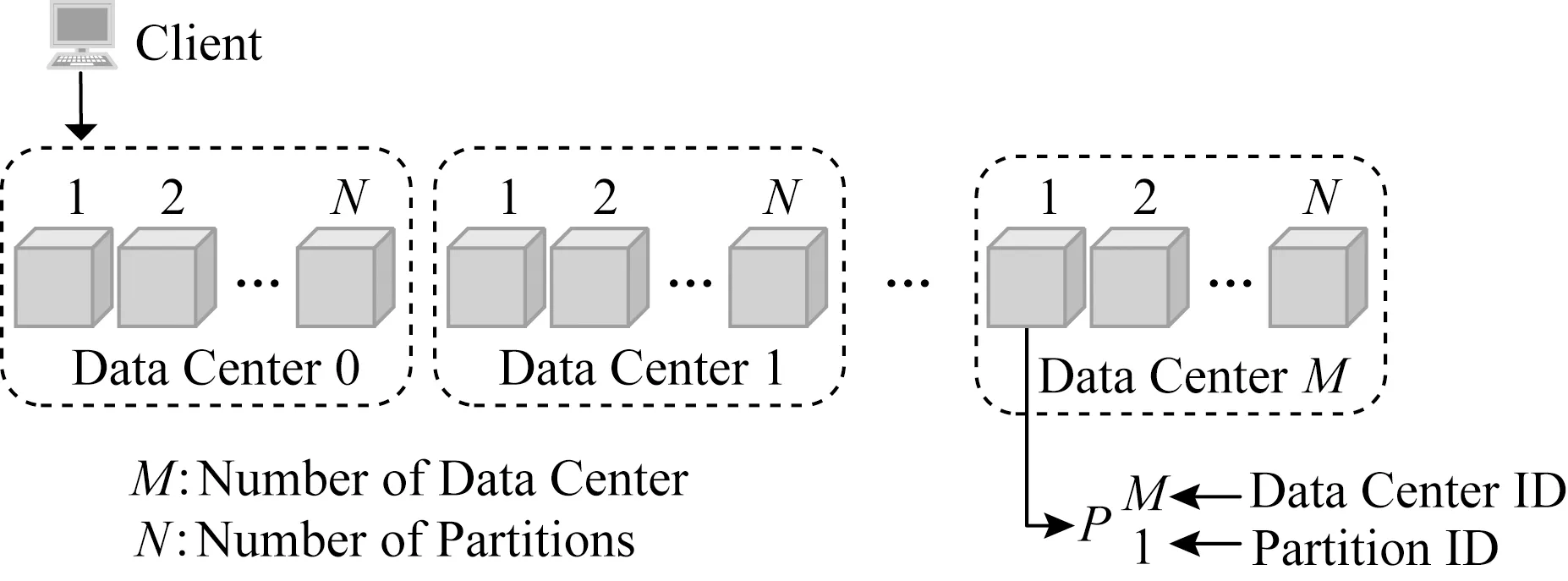
Fig. 2 Topology scheme of M data centers (N partitions)图2 有M个数据中心(N个分区)的节点分布方案
由于数据中心中存在网络分区,导致分区间可能由于通信故障造成分区间同步延迟等问题,但Causal-Pdh模型是在数据中心内部,即分区间无网络故障的前提下提出的.因此,数据中心内的分区可以相互保持网络传输、时间和数据同步.对于每个键,均使用键值存储服务存储多个版本信息.每个键值条目均可进行有2个基本操作:PUT(k,v)和GET(k).其中PUT(k,v)写入新版本信息,值为v,GET(k)则读取一条包含键k的条目数据.
2.1 因果关系
数据因果一致性的定义来自于事件之间happens-before关系.该关系的定义如定义1~定义3所示:
定义1.happens-before.a和b定义为2个事件,若以下条件成立:1)a和b为2个事件,且a在b之前发生;2)a是PUT(k,v)操作,b是GET(k)操作,b获取a写入的值;3)存在中间事件c使得a在c之前发生,并且c在b之前发生;则a与b的关系可表示为a→b,也就是ahappens-beforeb.
定义2.v1,v2分别是键k1,k2对应的值,v1与v2可表示为因果关系,当且仅当PUT(k2,v2)→PUT(k1,v1)成立时,即表示为“v1depv2”.
定义3.可见性.如果客户端Client的GET(k)操作返回的是v′,并且v′满足v′=v或者(vdepv′),那么键k的值v对客户端Client是可见的.
2.2 因果一致性
定义4.因果一致性.令k1和k2是数据中心的2个任意的键.令v1是键k1的值,v2是键k2的值,2个键满足v1depv2.若客户端Client读取的v1和v2对客户端Client是非透明的,那么该数据存储模型满足“因果一致性”约束.
键值存储数据库中对同一个键执行写入操作时,若不同客户端进行2次写操作,就通常会发生冲突,导致数据存储模型失去因果一致性约束.冲突的定义为:
定义5.冲突.v1和v2是键k的2个值,当且仅当(v1depv2)和(v2depv1)同时成立时,v1和v2是冲突的(即2个值不互相依赖于彼此).
2个值间存在冲突,就需要云存储模型解决或缓解冲突,因此,冲突解决函数定义为f(v1,v2) .该函数依据当前协议中的依赖项判别机制解决用户操作因果关系冲突,并且返回v1或v2中的一个作为最终值.若v1和v2不存在冲突关系,f返回的结果为v1和v2的最新值,即:如果v1depv2则f(v1,v2)=v1.
3 HashGraph
区块链是一种去中心数据存储技术,包含了2种创新技术:分布式账本和共识机制,降低了了交易和数据的风险.在分布式存储模型中,用户每次执行写入和查询操作都作为一次事件,这些事件执行的历史信息在就是下次发生事件的因果一致性依赖集.如果将区块链应用在分布式存储中,各个矿区可比作分布式存储中各个副本,各个副本中的事件依赖集数据就类似于矿区中存储的交易记录;最后共识链同步完毕后,所有矿区都达成了共识,就像各个存储副本同步完成,满足了数据一致性约束;因此可以用区块链相关技术来改进分布式存储模型中副本间的数据一致性机制.
HashGraph是区块链技术的一种改进,其包含2种特殊技术:八卦闲聊(Gossip about Gossip)和虚拟投票(virtual voting),是一种提供分布式账本和共识机制的数据结构和一致性算法,而且比区块链更快速、公平、安全.
3.1 八卦闲聊
八卦闲聊指各个事件节点定期向相邻节点随机地同步数据,即发送八卦消息:例如图3中,Alice会和Bob同步她所发生的的所有事件.同样Bob也会把他所发生的都同步给Alice.然后,Alice等节点均对不同的随机邻居事件重复此操作,所有其他成员也会这样做.因此,如果单个成员接收到新的信息,它将以指数级的速度在整个社区传播,直到每个成员都收到这一事件.
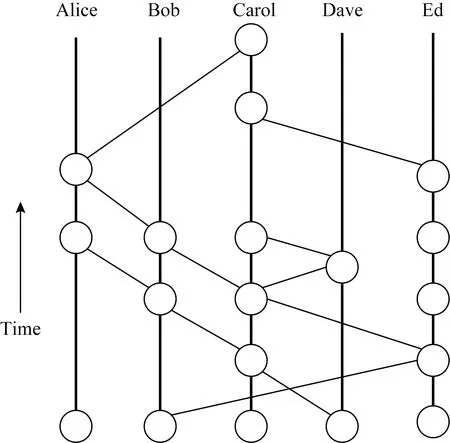
Fig. 3 Gossip about gossip between adjacent events图3 相邻事件之间的八卦闲聊
此外,Alice不仅会知道该事件,她还会确切地知道Bob什么时候知道了这个事件,也就会知道Carol知道Bob收到这个事件的时间.当所有成员都有HashGraph的副本时,共识的实现就成为可能.当HashGraph图中事件线随时间向上发展时,不同的成员在上部分可能会发生不同的新事件,但它们很快就会收敛到较低的位置,最后所有的节点都存储相同的共识数据、事件历史.
卦闲聊中同步的消息内容是:收到的上个事件对应的哈希签名、当前要发送的事件和当前事件对应的哈希签名.所有节点在收到事件同步消息后都将历史记录存储,在发送下一个事件时,当前事件就会变成事件历史中的上一个事件.所有节点都保存当前HashGraph中其他副本发生过的事件历史,为HashGraph提供了快速、可靠的溯源性.Causal-Pdh模型借鉴了HashGraph中节点进行八卦闲聊的消息格式,添加了HDS作为消息签名,供客户端在进行隐式依赖关系检查时进行验证.
3.2 虚拟投票
所有节点都收到Alice发送的消息后,记录事件历史的账单就完成了同步.这是因为HashGraph所有节点都达成共识后,任意副本就知道了“其他所有副本都完成了同步”,同时其他所有节点也都知道“Bob已经完成同步”,最后达成的共识链可延伸到全网共识.所有副本同步完成后的结果就是:大家并没有在同一位置对事件历史进行表决,也能公认数据同步完成这一事件,从而达成共识.
在分布式数据存储中,模拟HashGraph中完成虚拟投票的结果,就是所有节点都同步了用户存储的数据,并得到当前已写入最新条目的时间戳,用户可以在查询操作中检查数据的因果一致性,并检查相关数据的依赖性.
4 物理时钟与混合逻辑时钟
传统的单点存储系统或网络存储系统等都无法同时满足大数据存储在性能、可扩展性和经济成本等方面的要求[15].而构建于大量廉价商用硬件之上的分布式存储系统,不仅可以通过并行访问提供极高的数据存取性能,也可以通过增加存储节点增大规模和降低成本.因此,分布式存储系统在大数据的存储管理中得到了极为广泛的应用[16].云存储服务商通常为用户提供服务的数据中心分布在世界各地,以满足不同地点用户的需求.当各个数据中心之间使用NTP协议同步本地物理时钟时,便面临着一个严峻的问题:时钟异常.
时钟异常指的是不同副本在同步时钟状态时,由于距离差异,节点通信过程中会产生一定的通信时延,从而造成发送请求到收到回复所用的响应时间也有所不同,造成各个中心时间无法同步、NTP漂移等问题.
4.1 GentleRain与物理时钟
GentleRain模型除了通过NTP服务器更新物理时钟,还定义了一个单向的状态向量,即全局稳定时间,来满足因果一致性模型中对事件因果序的约束.该模型在写入数据时,依据本地时钟为每个值分配一个时间戳数据,同步存储到条目元数据中.当副本处理新的用户操作时,依据当前副本的物理时钟为该操作分配一个时间戳t,而且当副本的物理时钟为T值时,用户就可查询到当前副本中存储的所有时间戳小于等于T的数据条目.但该模型在客户端读取/写入一个时间戳t的键时,接下来客户端调用的任意PUT操作都必须具有高于t的时间戳,因此会在某些操作中需要等待.
混合逻辑时钟基于物理时钟,依据当前服务器本地时间分配事件的时间戳,同时结合逻辑时钟能为系统提供检验依赖关系的因果序,Causal-Pdh模型使用了改进后的混合逻辑时钟,从而避免了出现物理时钟造成的PUT延迟等问题.
4.2 混合逻辑时钟
混合逻辑时钟[11]结合了逻辑时钟和物理时钟,充分发挥了两者的优势.事件e的HLC时间戳表示为hlc.e,这是一个元组l.e,c.e.第1个分量l.e是e发生时本地服务器网络时间信息.c.e是一个有界计数器,可捕捉事件之间的因果关系.若时钟偏移造成2个事件时间戳相同时,仅用l.e无法判别2个事件之间的因果关系.
具体而言,如果2个事件e和f,使得e在f之前发生(定义1),并且l.e=l.f,为了捕获e和f之间的因果关系,将c.e设置为高于c.f的值,虽然c在递增,如文献[11]中,c的理论最大值是O(n),其中n是进程的数量.而实际上,这个值仍然很小.除HLC时间戳之外,每个进程还维护一个HLC时钟l.a,c.a.
算法1.HLC[11].
输入:事件a、当前物理时间;
输出:时间戳l.a,c.a.
① 在收到进程a发送的消息时:
②l′.a=l.a;
③l.a=max(l′.a;pt.a); /*追踪最新事件,pt.a是a的物理时间*/
④ if(l.a=l′.a)
c.a=c.a+1; /*追踪因果序*/
⑤ elsec.a=0;
⑥ end if
⑦ 使用l.a,c.a作为事件的时间戳.
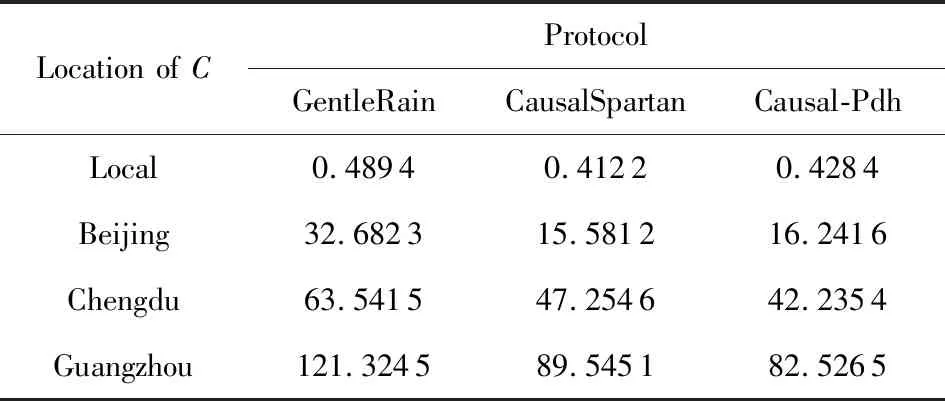
HLC不仅包含逻辑时钟的优点,而且可以追踪2个事件之间的因果关系.具体来说,如果e发生在f之前,那么hlc.e Causal-Pdh协议是一种可以稳定运行在分布式云存储中的通信协议,在满足因果一致性存储需求的基础上,为用户提供安全快速的写入、查询和存储服务[17].如图4(a)所示,下划线内容为Causal-Pdh在用户写入操作中引入了服务端HDS作为消息签名,即在服务端计算应发送数据条目依赖集的Hash校验值.服务端在回应用户请求中对应的的依赖集时,将签名附加在消息签名部分,客户端在收到响应消息后,首先同步依赖集数据,然后与收到的服务端HDS签名进行校验. Fig. 4 PUT and GET operations in Causal-Pdh图4 Causal-Pdh模型中的PUT和GET操作 其次在图4(b)中,服务器收到用户查询操作请求后,首先在本地计算HDS签名,然后将partDSV数据和服务端HDS签名一起封装到响应消息中.部分依赖集向量partDSV是当前服务端所有依赖项的某个子集,同步到客户端后供其更新查询到的条目依赖集,客户端更新本地稳定向量(DSVC)后计算HDS与签名进行验证. 分布式存储系统不同于物理机,而是多个节点基于不同位置,协同更新数据提供计算或存储服务的平台;因此服务器在收到用户写入数据的请求后,要在系统中执行分配存储空间、写入数据、同步各数据中心数据和状态等一系列操作. Causal-Pdh协议中最后一步的过程如图5所示,各分区将本地已写入的最新消息与其父节点同步,并附加HDS作为签名,父节点将本地最新DSV随机与其他数据中心同步,并且验证HDS签名.借鉴HashGraph中的Gossip about Gossip思想,系统中的DSV消息是随机发送到其他节点的,最近的更新数据在系统中呈指数级扩散,因此完成虚拟投票的速度得到了极大提升. Fig. 5 Synchronization among data centers in Causal-Pdh图5 Causal-Pdh模型中各数据中心间的同步 DSV是一个多维集合,包括当前数据中心的时钟信息,及其存储的所有数据条目,标记当前存储副本的最新稳定状态.Causal-Pdh在数据中心稳定向量的基础之上,将GET操作中DSV的内容进行了精简,只发送partDSV和依赖集更新完之后对应的摘要值,partDSV即当前数据中心DSV的依赖子集;在PUT操作中则附加一个摘要值HDS作为签名,使得客户端能在更新本地键值链后与服务端的依赖关系进行验证.DSV允许数据存储模型在多个客户端中存在一些慢副本[18]的情况时提供高效、准确的存取服务,同时降低更新可见性延迟.数据副本内部分区之间更新状态使用的是与数据中心稳定向量类似的VV消息(versions vector),而且是数据中心更新DSV的依据之一,因为副本进行存取操作都会在收到请求之后,详见5.2节. 客户端Client与服务端均同步更新1组数据中心ID和HLC时间戳,该组数据称为依赖关系集,用DS(dependency series)表示,为了区分客户端和服务端间的差别,用DSC标识客户端依赖关系集.对于每个数据中心i,发送的的依赖集DSC中最多只有1个条目i,h,其中h指的是客户端Client可查询到的最新值的时间戳信息,而这些值是客户端曾经写入到数据中心i中的. 算法2是客户端PUT和GET操作的算法.在GET操作中,客户端的请求信息包括请求的键及其DSVC.Causal-Pdh协议结合HashGraph中的共识机制gossip about gossip,在响应消息中附加一个消息的摘要值作为消息签名,服务器将所请求键的值、返回值的DS、服务器中的依赖关系列表partDSV及其签名HDS一起发送至客户端.客户端收到服务器回应后,首先更新其稳定状态信息DSV,然后调用updateDS函数来更新DSC:对于每个DS的子集i,h,如果在DSC中存在某条目i,h′,则选取h和h′中的最大值作为h′,若不存在则直接将i,h添加到DSC中,最后在客户端生成依赖集的校验值,并与收到的签名信息进行验证并保存. 对于PUT操作,客户端将想要写入的密钥与期望值及其DSC一起发送到服务器.服务器在发送响应消息时,将此更新使用的时间戳、数据中心的ID与依赖集对应的摘要值HDS等信息统一封装进响应数据中.客户端可调用updateDS函数更新其PUT操作的DSC,最后在更新完成后计算本地依赖集的校验签名进行验证并保存. 算法2.客户端Client中的操作. 1)GET(k)过程. 输入:键k; 输出:v,DS,partDSV,HDS. ③DSVC←max(DSVC,DSV); /*根据数据中心最新稳定状态更新客户端状态*/ ⑤DSC←updateDS(i,h,DSC); /*更新依赖集*/ ⑥ end for; ⑦ ifHash(DSC)==HDSreturnv; /*验证HDS签名*/ ⑧ elseGET(keyk); ⑨ end if 2)PUT(k,v)过程. 输入:键k、值v; 输出:ut,sr,HDS. ③DSC←updateDS(sr,ut,DSC); /*收到写入完成的响应后更新本地依赖集*/ ④ ifHash(DSC)==HDSreturnv; /*验证响应消息中的HDS签名*/ ⑤ elsePUT(k); ⑥ end if 存储在服务端的每条元数据,除了键值对之外,还包括其他信息,包括该条目存储的物理地址,键值创建的HLC时间戳信息ut,原来所在的副本信息sr,以及数据条目的1组依赖关系DS. 算法3是服务端中的PUT和GET算法.服务端在收到GET请求后,首先使用其中的DSVC值更新其状态信息DSV,然后根据请求中键在本地检索最新值,或该键在本地数据中心可查询到的所有依赖关系.检索到信息后,服务端对比该键的DS与数据中心的DSV信息,从而保障准确性.服务端一般使用冲突解决函数last_writer_wins解决中心的IDs之间的冲突,来检索最新状态的值,最后参照HashGraph共识机制中事件之间八卦闲聊的核心机制,服务端统一封装该键、值、及其依赖关系集、partDSV和HDS校验信息到查询响应消息中,并向客户端发送. 1)GET(k)过程. 输入:键k、dsv; ③ 获取键值链中k的最新条目d; ④DS←updateDS(d.sr,d.ut,d.DS); /*根据条目d更新依赖集*/ 2)PUT(k)过程. 输入:键k、值v、DS; 输出:d.ut,m. ②dt←maximum value inDS; ③updateHLC(dt); ④ create new itemd; /*为新的条目分配空间*/ ⑥ insertdto key chain ofk; /*将新条目插入到k的版本链中*/ ⑩ end for 算法4是更新DSV的算法.数据中心内的分区会定期对状态信息DSV进行更新,每过θ时间间隔,分区与分区之间分别共享其VV状态信息,并在每次心跳机制更新完后请求状态信息DSV作为最新VV状态.基于HashGraph共识机制,每个父节点在接收到其子节点的VV状态信息及其vvHDS签名时,都计算最新的VV条目及其校验签名信息发送到其他子节点.然后数据中心统一封装最后更新的DSV和签名校验信息dsvHDS签名为DSV消息,随机发送给其他对等节点,从而将最新的状态信息和数据更新到整体拓扑网络中.其余每个节点在收到DSV时更新其DSV并验证dsvHDS签名.算法4包含了心跳机制的算法,基于心跳机制定时发送心跳消息(heartbeat message)的目的是更新其他父节点的分区中相对等的状态和数据信息,如果数据中心在某固定的Δ时间段(心跳机制的时间间隔)内未发送任何数据更新的复制消息(replicate message),数据中心就会向相邻的其他节点发送心跳消息(heartbeat message),保持时钟同步的同时提供数据更新依据. 输出:DSV,dsvHDS. ① 每过θ时间间隔,do ③ 每过Δ时间间隔无replicate message,do /*按照心跳机制同步最新状态*/ ④updateHCL(); k≠mdo ⑨ checkvvHDS; ⑩ end for Causal-Pdh模型基于Java语言,采用键值数据库Berkeley DB存储和检索元数据信息.该数据库可支持关系型数据库中最常用的的完整ACID事务语义,也提供NoSQL中简单的数据库编程接口[19].实验在DKVF平台[20]的基础上布置和管理分布式副本,作为一个分布式键值存储管理框架,DKVF平台使用Berkeley db作为数据存储模块,集成了Google开发的数据结构化协议Protocol Buffer和Yahoo的性能测试工具YCSB,此外,DKVF平台还实现了COPS,GentleRain,CausalSpartan等协议.为了模拟实际环境中不稳定的用户请求情况,并对不同模型处理高并发请求的性能进行测试与统计,实验每次收集的数据均是在客户端和服务端存取1 000个键值信息,并在同样环境下进行3次重复并取得的平均结果. 实验中本地服务器和云服务器规格为:本地服务器运行Windows10 x64,Intel Core i7-6700,3.4 GHz,8 GB内存,256 GB固态磁盘存储.云服务器为运行Windows Server 2012的Aliyun ecs.n4.small实例和Tencent cvm实例,1个vCPU,Intel Xeon E5-2622,2.5 GHz,2 GB内存,40 GB存储. 为了准确研究时钟偏移对响应时间的影响,须对两副本之间的时钟状态进行人工管控.但实际环境中服务器一般使用NTP协议进行更新,其时钟偏差取决于人为控制之外的许多因素.因此为了使结果更加精确和权威,实验在1台物理机中设置了2个分布式服务端,并参照图5的拓扑结构,为每台个服务端分配一个数据分区,不同的是,2个服务器运行的Causal-Pdh数据服务之间存在一个可变的人为时钟偏差.实验还配置了不同的客户端分别以循环方式向服务器发送PUT请求,依据不同情况下的时钟偏差,对PUT操作平均响应时间的进行统计. Fig. 6 PUT response time in the same physical machine and different physical machines图6 同一物理机和不同物理机中的PUT响应时间 图6(a)显示,随着时钟偏差数值的递增,Gentle-Rain中PUT操作的平均响应时间呈递增趋势,而Causal-Pdh和CausalSpartan中的平均响应时间无明显变化趋势,与时钟偏差未表现出明显函数关系.由于Causal-Pdh协议提出部分稳定状态的概念partDSV,并使用HDS状态信息签名验证依赖集消息的完整性,若系统中产生高并发的读写操作,操作的响应时间比CausalSpartan协议的平均降低了20.85%,验证了1.2节主要工作1)中提出的完整性约束,可见Causal-Pdh模型较适合应用于存在时钟漂移,或网络时钟同步易出现风险的的分布式存储环境中. Fig. 7 Impact of clock offset between partitions on request response time图7 分区之间的时钟偏移对请求响应时间造成的影响 图6(b)是在2台不同的机器上进行的测试,结果表明如果不对时钟信息引入人为设置的时钟偏差,仅使用NTP来同步物理时钟,PUT等待延迟的影响也是可见的.实验为每个副本内分配2个数据存储分区,客户端以循环方式向这些服务器发送随机数据的PUT请求.CausalSpartan和Causal-Pdh在无时钟偏移情况下的响应时间都明显低于Gentle-Rain,这是由于父节点之间同步数据和状态时,发送的依赖集信息DS是一段长度有限的消息,而Hash-Graph中同步所有用户事件历史,完成虚拟投票达成共识所需的时间极短,尤其是系统中只有50~100个节点时,耗费时间可以忽略不计,所以计算消息的摘要作为校验值不仅没有造成更大的性能开销和计算延迟,反而提升了系统性能和响应速度.但由于两者均使用了混合逻辑时钟HLC作为因果一致性判断依据,为用户时间分配的时间戳信息类似,CausalSpartan与Causal-Pdh协议的PUT响应时间没有表现出明显的差异. 单个最终用户请求在服务器中可能会转化为许多因果关系的内部查询,这种现象被称为查询放大[21],尤其在数据存取服务商为成千上万个用户同时提供高并发服务时,查询放大会更加严重.实验将单个请求在内部造成复杂查询的数量定义为查询放大因子.为了研究实际环境中的影响,本节实验在同一物理机中安装了2个数据副本,避免网络通信造成时钟同步偏移的问题同时分别设置递增的人为时钟偏移,目的是针对查询放大情况对操作响应时间的影响进行精准的定量分析,图6即为实验结果.实验规定服务器以循环方式向分区PUT随机数据,是为了模拟实际应用中大量用户向Web应用服务器发送读写请求的场景. 图7实验是在数据副本之间设置了人为时钟偏移,且每个最终请求都包含了几百个甚至更多的内部查询,实验结果显示,查询放大情况越严重,请求响应延迟越明显.且表格中曲线的增长速度可看作该协议受查询放大情况的影响程度,随着查询放大情况变得越来越明显,GentleRain的增长速度明显高于其余两者,而CausalSpartan和Causal-Pdh的增长速度明显较慢.例如,在2个数据中心之间存在2 ms时钟偏差时,GentleRain中查询放大因子为100时的请求的响应时间比CausalSpartan高3倍,比Causal-Pdh高3.5倍.在实际分布式存储环境中,时钟偏移完全可能更大[22].例如,当底层通信网络受到不对称链路的影响或服务商遭受网络恶意攻击影响通信延迟时,时钟偏差可达100 ms或者更高.在这种情况下,当查询放大因子达到100时,GentleRain的响应时间比CausalSpartan和Causal-Pdh高35倍. 由于GentleRain模型容易受到时钟偏移等异常情况的影响,为了使结果更加直观,图7(b)(c)都只将查询放大因子小于200时GentleRain的平均响应时间放入结果中.同样条件下Causal-Pdh模型与CausalSpartan相比,请求响应时间平均降低了23.27%.例如时钟偏移为4 ms,查询放大因子为200时Causal-Pdh比CausalSpartan的响应时间降低了23.37%,而时钟偏移为8 ms且查询放大因子为500时则降低了22.02%.由实验数据可见,Causal-Pdh模型借鉴HashGraph中八卦同步机制,随机与对等节点同步节点间更新的数据和状态,简化GET操作回应消息格式,并且计算校验值作为消息签名校验数据完整性,相比于CausalSpartan方案,在降低用户请求响应时间方面是可行的、有效的,同时表明Causal-Pdh模型在查询放大、时钟偏差较严重或网络环境较差的环境中会有更优秀的表现. 图8(a)是6个数据中心8个分区均使用使用NTP协议同步,且分区间不存在人工时钟偏差时,放大因子对请求响应时间的影响.结果表明了查询放大对请求响应的影响规律:单个客户端造成的查询放大情况越明显,即查询放大因子越大,服务器处理请求所需的响应时间就越长.在同样的实验环境中,Causal-Pdh模型的请求响应延迟比Causal-Spartan平均降低了37.85%.例如,对于查询放大因子200,GentleRain的请求响应时间比Causal-Spartan高1.64倍,比Causal-Pdh高4.74倍. 吞吐量是客户端在单位时间内更新键值的数目,即客户端更新键值的速度.图8(b)中结果显示,在查询放大情况越来越严重时,不同数据一致性存储模型中客户端请求的吞吐量在逐渐降低,这是因为服务端处理查询请求时,单个客户端的查询造成内部查询的次数越多,服务端响应时间越长,同时客户端收到更新的速度越慢,吞吐量越低. Fig. 8 Effect of amplification factor on client request response time图8 放大因子对客户端请求响应时间的影响 评价分布式数据一致性存储模型的重要指标之一是更新可见性延迟,指的是从客户端发送数据和状态更新请求,到在远程副本中同步完成,可供其余客户端查询的时间延迟.其单位一般在ms级别,但即使短短几毫秒,对许多用户和数据存取服务提供商来说也十分重要,因为某单一用户的查询可能造成大量不同位置的数据查询;服务商也同时为数十万甚至上百万个终端用户提供并发的数据存取服务,许多用户的更新可见性延迟最后累计在一起,就会造成很明显的查询等待情况,甚至也给服务器带来非常大的负载. 实验基于Casual-Pdh协议设计了一个分布式数据存储系统,包含不同位置的3个数据中心,将其中2个位置固定不变,通过改变第3个数据中心C的地理位置,并收集C到其余数据中心A/B的网络通信往返时间,从而得到表1中不同模型在分区间存在较不同的通信时延时的性能表现.系统设定2个客户端分别对键k的值进行循环读取,并在数据副本C位置发生改变时,分别读取到奇数与偶数时对该键实施递增操作.数据中心A和B的位置固定在河北省保定市,第3个分区则根据到保定市的距离不断递增的规则,分别租用云服务器在北京市,四川省成都市和广东省广州市提供服务.由表1结果可得知,同步不同地理位置的数据副本中的数据时,往返时间递增的趋势主要原因是彼此之间越来越远的距离. Table1 RoundtripTime from the Third Replica to the Rest at Different Locations表1 第3个副本在不同位置时的往返时间 ms 更新可见性延迟是从客户写入新的更新,到另一客户端读取到更新之间的时间间隔.由于在不同地理位置的数据中心之间必然存在一定的时钟偏移,实验所得结果是实际更新可见性延迟的一个接近值. 实验中慢副本指的是某个因为距离过远造成通信往返时间很长,或者网络分区故障导致与其他节点通信被延迟的数据中心.图9(a)表明了Causal-Spartan和Causal-Pdh中的更新可见性延迟低于GentleRain.此外,随着3个数据副本间网络通信延迟的增加,GentleRain中的更新可见性延迟也在逐渐增加,表明GentleRain在网络环境差、网络通信延迟高的环境中性能会受到一定的影响.但CausalSpartan和Causal-Pdh并未受到影响,这是因为两者使用DSV指明本地最新的键值条目,在通信时延较高、或复杂网络环境中提升了数据中心与慢副本、客户端与服务端之间存在造成的更新响应速度. Fig. 9 Impact of update visibility latency and throughput when data center C is in different locations图9 C在不同位置时对更新可见性延迟和吞吐量的影响 图9(b)是数据中心C在不同地理位置时客户端请求的吞吐量变化趋势.由于CausalSpartan和Causal-Pdh都基于HLC使用了DSV标识分区最新状态,客户端的一些PUT/GET请求可能会在服务端造成更多的内部查询来判别操作的因果序,所以两者吞吐量相比GentleRain明显增加. Causal-Pdh和CausalSpartan都基于混合逻辑时钟方法分区中的用户事件分配时间戳信息,并且均设置数据中心状态向量标识最新数据时间,为了直观地研究两者各自的影响,实验在本地环境中完成,使用DKVF框架管理2个数据中心2个分区,在Casual-Pdh模型中分别单独使用HLC和DSV的时候,测试了处理收到的不相关的PUT/GET操作的吞吐量. 图10表明,如果仅使用数据中心稳定向量表明在分布式数据存储管理副本的状态,基于物理时钟同步时钟信息,而且将PUT和GET设置为相互独立的操作时,CausalSpartan和Causal-Pdh模型在服务端中的吞吐量比GentleRain低5%,然而Causal-Pdh和CausalSpartan的吞吐量并无差异,因为两者均使用DSV标识数据副本最新状态. 时钟信息的同步只会影响PUT,GET等原子操作的处理时间,因为每个操作均需依据时钟数据判别因果关系,因此仅使用物理时钟作为分区时间,无分区稳定向量的情况下,CausalSpartan,GentleRain和Causal-Pdh的吞吐量并无明显差别. Fig. 10 Throughput of GET/PUT operations in three models图10 3个模型中GET/PUT操作的吞吐量 现有的数据因果一致性研究成果在分区间存在网络时差的环境中,一般采用物理时钟同步时钟信息容易产生PUT延迟影响性能,而且在慢副本较多的环境中更新可见性延迟也会明显提高,影响用户的实际体验.在现有成果基础上,Causal-Pdh降低了CausalSpartan中PUT/GET操作消息的复杂度,明显提升了系统在用户短时间产生大量并发请求时的响应速度.本文引入了HashGraph相关技术,重新设计数据中心之间同步最新条目的消息格式,将dsvHDS作为消息签名,用于验证同步过程的完整性,此改进有效降低了存在查询放大和分区之间发生时钟偏移时的PUT操作等待时间.此外,Causal-Pdh借鉴HashGraph中Gossip about Gossip的思想,将数据中心之间发送稳定状态同步消息的方式改为随机地向其他节点同步,有效降低了各个副本同步数据和状态信息、进行虚拟投票,满足数据因果一致性约束并达成最终共识过程所耗费的时间,并在实验结果中验证了此结论.5 Causal-Pdh协议

5.1 客户端
5.2 服务端
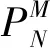





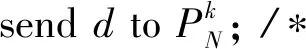





6 实验测试与分析
6.1 时钟偏移对PUT等待时间的影响


6.2 查询放大对响应时间的影响

6.3 通信时延对更新可见性延迟的影响

6.4 DSV对客户端吞吐量的影响

7 总 结
