感知相似的图像分类对抗样本生成模型
2020-11-15李俊杰
李俊杰,王 茜
重庆大学 计算机学院,重庆 400044
1 引言
随着计算能力与数据量的提升,深度神经网络在各个领域都得到了广泛应用[1-3],如图像分类、文本分析、语音处理等。在一些安全敏感的领域,深度神经网络同样被广泛使用,比如自动驾驶、智能医疗、人脸识别等。然而,近年来的研究工作发现:在输入数据上增加微小的修改与扰动,可以轻松造成主流深度神经网络模型的误判,这些造成深度神经网络模型误判的样本称为对抗样本。对抗样本的出现,显示出深度神经网络抵御攻击的脆弱性,这为深度神经网络在安全敏感领域的应用带来不确定性,比如经过修改的交通标志对抗样本会被自动驾驶系统中的分类模型错误识别,继而做出错误驾驶判断,造成严重后果[4]。因此,需要通过研究对抗样本来进一步认识现有主流深度神经网络模型的脆弱性,进而提高模型对对抗样本的鲁棒性。
近年来,出现了越来越多生成对抗样本的方法。其中一类方法是迭代修改输入图像的像素值,直到输入图像被分类器错误分类。这种基于迭代修改原图来生成对抗样本的方法,虽然可以最大程度限制修改的像素数量与像素幅度值,从而生成人眼观察难与原图做分辨的对抗样本,但是每一次迭代都需要大量的计算,如梯度计算、雅各比矩阵计算等,这些庞大的计算量极大地增加了生成一个对抗样本的时间,如Carlini 和Wagner 在文献[5]中提出的生成对抗样本的方法,可以成功攻击具有防御能力的深度神经网络模型,并且其生成的对抗样本与原图相比难以被人眼察觉,但是该方法生成一个对抗样本需要数分钟的时间,这在时间要求较高的应用场景中是不可用的。
基于生成器来生成对抗样本的方法有效减少了生成对抗样本的时间,其只需训练生成器生成一个扰动,然后将生成的扰动叠加到输入图像上,就可以得到一个对抗样本。虽然训练需要一定时间,但是当模型训练完成后,利用模型生成对抗样本的时间仅为几毫秒。该类方法通过Lp范数来限制生成器生成的扰动的幅度,以使生成的扰动叠加在原图之上人眼不易识别。虽然限制Lp范数为很小的距离可以降低对抗样本与原图的差异,但同时也会降低攻击成功率;而减小对Lp范数限制以保持攻击成功率,则会使生成的扰动具有明显的纹理特征,当这些扰动被叠加到原图上时,这些纹理会极易被人眼观察到。
现有的基于生成器生成的对抗样本易被人眼察觉的原因有两点:首先,对抗样本是在原图上叠加一个生成器生成的扰动,也就是原图加上纹理,分类器通过这个纹理的特征做出错误分类,而叠加的纹理易被人眼观察到。实际上,除了叠加扰动,对原图的变换、旋转、颜色改变等都可以使分类器分类失误[6-7]。其次,基于Lp范数来评价对抗样本与原图的相似性与人眼观察上两张图像的相似性有相当的区别。使用Lp范数来限制生成扰动只是限制了像素内容上的差异和距离,但在多数情况下,这并不能有效避免生成的扰动易被人眼察觉的问题。
本文在图像分类领域的对抗样本生成任务中,主要做出以下创新与改进来提高生成对抗样本的效率,并在保持对抗样本攻击成功率的基础上,有效提升对抗样本与原图之间人眼观察的相似性。
(1)提出了一个基于深度神经网络(deep neural networks,DNN)生成器生成对抗样本的模型GPAE
(generative perceptual adversarial example)。GPAE模型以原图作为输入,生成器直接生成可以攻击分类模型的对抗样本。相比于其他基于生成器的对抗样本生成模型,GPAE 模型将对抗样本生成看作是对原图进行图像增强操作,而不再看作是对原图叠加扰动的操作,这使得GPAE 尽可能将对原图的改动分布在图像结构边缘等人眼不易察觉的区域,因此在保持对抗攻击成功率的基础上,GPAE 有效提升了对抗样本与原图的结构相似性指标(structural similarity index,SSIM),使人眼观察不易察觉出区别。同时GPAE引入生成对抗网络(generative adversarial networks,GAN),保证了生成对抗样本图像的真实性。
(2)为进一步提高对抗样本与原图之间人眼观察相似性,GPAE 模型引入感知损失,并进行了改进。使用激活函数之前的数据作为特征图,并使用多个特征图的均方误差构成最终的感知内容损失,这让感知损失同时表征了内容空间与特征空间中对抗样本与原图的相似性,以此为优化目标减少了训练生成的对抗样本与原图之间视觉观察上的差异,提升了SSIM 值。
(3)集成多个分类模型的分类损失为GPAE 模型训练时的损失函数中的一部分,实现了模型生成的一例对抗样本可以攻击多个深度神经网络分类器,有效提升了攻击效率。
2 相关工作
本章主要介绍对抗攻击与对抗样本在图像分类领域的相关概念,对近几年主要的生成对抗样本的方法进行简要介绍,并阐述其优劣。针对文献[8]提出的基于生成模型生成对抗样本的方法GAP(generative adversarial perturbations)进行具体介绍。最后,对判断对抗样本与原图相似性的评价指标进行相关阐述。
2.1 对抗样本
使神经网络产生错误输出的输入样本称为对抗样本(adversarial examples)。文献[9]首次提出图像分类模型中的对抗样本,Szegedy 等人在图像上生成细小扰动(perturbations),使添加扰动的图像在常规的基于深度神经网络的图像分类模型上被错误分类,并在错误分类上取得较高置信度。这些扰动很小,往往人眼难以察觉,但是这些添加了扰动的对抗样本却可以造成分类器分类结果错误,从而得到不正确的类别标签。
设分类器为f,x为输入的原始图像,基于x生成的对抗样本为x′,对抗攻击的形式化描述如式(1)。

其中,l与l′分别表示输入图像x与对抗样本x′的分类结果,||∙||代表对抗样本与原始图像之间的差异距离,x′-x则是加在原始图像上的扰动。
生成对抗样本并攻击分类模型称为对抗攻击(adversarial attack),对抗攻击根据对抗样本的分类结果l′是否被限制为具体的类别,分为有目标攻击(targeted attacks)与无目标攻击(non-targeted attacks)。有目标攻击生成的对抗样本被错误分类为指定类别,无目标攻击则仅要求对抗样本被错误分类。在测试集上,对抗样本能实现对抗攻击的样本占测试集总样本的比例为攻击成功率(fooling ratio)。本文主要研究已知攻击模型(即白盒攻击)下的无目标攻击。
2.2 生成对抗样本模型与GAP
通过多次迭代修改原始图像像素值来生成对抗样本的方法被广泛用于生成对抗样本。Papernot等人在文献[10]中提出的JSMA(Jacobian-based saliency map attack)基于雅克比矩阵,每次迭代仅修改少量最影响分类结果的像素,减少了需要修改的像素数量。Moosavi-Dezfooli 等人提出DeepFool[11],通过迭代将深度神经网络分类模型每次迭代近似为线性模型,克服了分类器非线性的问题,每次迭代将输入样本推至分类器分类超平面边缘,直至分类器分类错误,进一步减少修改量。Carlini 和Wagner 提出的生成对抗样本的方法[5],可以有效攻击具有防御能力的模型,并减少对原图像素的修改,从而使人眼难以察觉对抗样本与原图的区别。
基于迭代方式生成对抗样本的每次迭代都需要大量的计算,导致生成对抗样本需要大量的时间,如Carlini 和Wagner 提出的方法生成一个对抗样本需要数分钟。在对对抗攻击时间要求较高的情况下,如要求在短时间内生成大量对抗样本,基于迭代生成对抗样本的方式是不可用的。
Goodfellow 等人在文献[12]中提出的FGSM(fast gradient sign method)仅通过迭代一次来生成对抗样本,极大减少了生成对抗样本的时间,但其在原图上增加了明显扰动,人眼易察觉,并且攻击成功率低。近年来,一些文献提出基于生成模型来生成对抗样本[8,13],一旦训练好生成模型,在产生对抗样本的阶段只需要很短的时间。
Zhao 等人提出基于DNN 生成器直接生成对抗样本[13],在训练生成器的同时训练一个Inverter,将原图映射到特征编码空间(latent space),使用经原图对应的特征编码修改得到的噪声向量生成的图像作为对抗样本。然而生成器直接生成的对抗样本与原图差异很大,且受限于生成器的结构,生成的图像并不真实,无法应用于实际攻击。其结构如图1。

Fig.1 Structure of directly generating adversarial examples by DNN generator图1 基于DNN 生成器直接生成对抗样本的模型结构图
Poursaeed 等人提出一系列基于深度神经网络生成器的生成对抗样本的模型GAP[8],生成的对抗样本可用于图像分类任务与自然图像语义分割任务的对抗攻击,其中生成器生成扰动,叠加在原始图像上合成为一个对抗样本。GAP 中的模型支持有目标攻击与无目标攻击,且除了根据输入的原始图像生成对抗扰动,GAP 还可以生成可叠加在任意输入图像实现对抗攻击的通用对抗扰动,一旦生成器训练完成,只需要很短的时间就可以生成大量对抗样本,甚至通用扰动,提高了对抗攻击的效率。这里仅讨论GAP中基于输入图像的无目标攻击模型,其结构如图2 所示。
输入的原始图像x经过深度神经网络生成器f生成的扰动,并不能直接叠加在原始图像之上,为了控制生成的扰动的大小,使其不至过大,需通过L∞来限制,即将生成器生成的扰动缩放至L∞限制的范围之间,然后叠加到原图上,之后将所有非法像素值截断到合法范围,最后生成一个对抗样本。GAP 模型使用对抗样本与原图在待攻击的图像分类模型中分类结果的交叉熵损失作为损失函数来训练生成器模型。
尽管GAP 通过缩放扰动至限制范围来减少对抗样本与原图的区别,然而其生成的扰动具有明显纹理,人眼易分辨,失去了对抗攻击的意义。如图3 所示是限制L∞为10 的对抗样本,人眼可在短时间内轻易观察到明显的纹理。
尽管GAP 生成的对抗样本在人眼感知上与原图相比有明显纹理,但是其基于DNN 生成器生成图像分类任务对抗样本的思路,完全区别于之前基于迭代修改原图的方法,并且有效提升了生成对抗样本的效率,因此本文将主要与GAP 模型进行对比。
2.3 对抗样本与原图相似性评价指标
在对抗攻击中,要求对抗样本与原图的差别尽可能小,以达到人眼观察难以察觉的目的。大多数的研究都采用了Lp范数来评价对抗样本与原始图像的区别,Lp范数表示为式(2)。
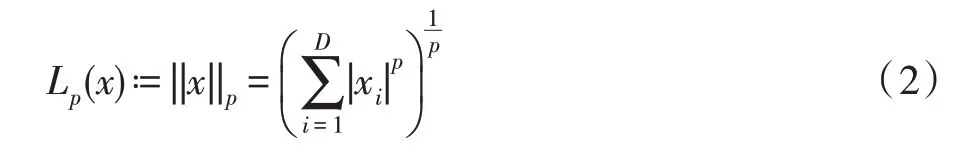
其中,D为数据x的维度。L0、L2和L∞是三种最常用的Lp范数。L0用于评价对抗样本对原始图像修改的像素的数量。根据式(2)可知均方误差(mean squared error,MSE)与L2是正相关的,因此欧式距离、MSE 与L2常被视为相同意义的评价指标,MSE 也常用于判断图像间的相似性。L∞则表征对抗样本像素值的最大改变幅度。
在评价对抗样本与输入图像的相似性上,Lp范数并不是完美的评价指标。Wang 等人在文献[14]中指出使用Lp范数来评价两张图像的相似性与人眼观察有很大不同。文献[14]的研究表明,人眼观察对结构模式的改变更加敏感,基于此,Wang 等人提出了SSIM 评价指标,从亮度、对比度与结构信息三方面来评价两张图像之间的相似性,以更接近人眼观察的效果。图4 来自于Wang 等人的实验,其清楚表明在同样的MSE 下,不同SSIM 的图像与原图的差异不同。
具体的,图像x与图像y之间的SSIM 值计算如式(3):
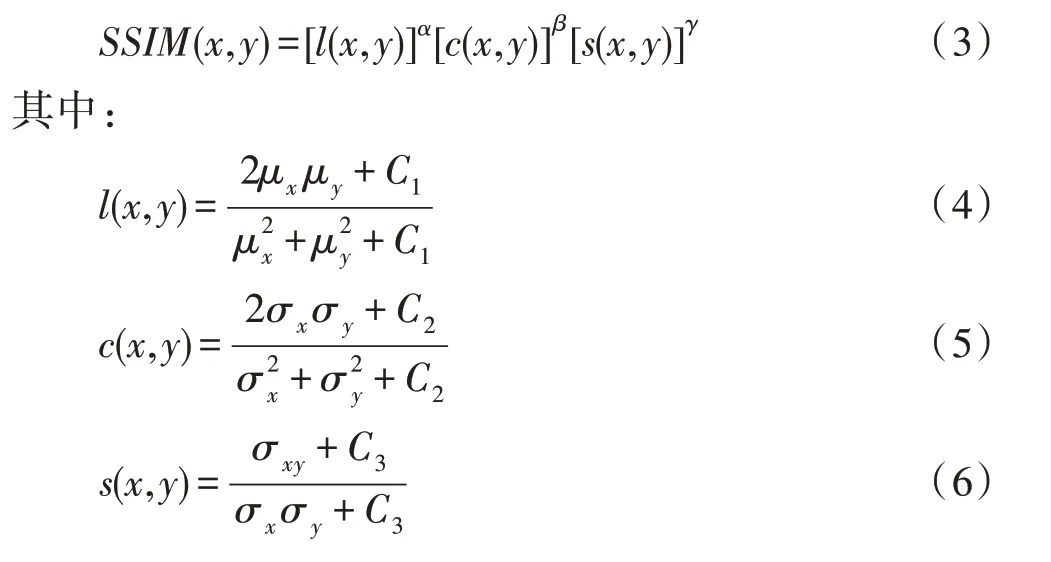

Fig.2 GAP structure图2 GAP 结构图

Fig.3 Adversarial examples generated by GAP图3 GAP 模型生成的对抗样本

Fig.4 Comparison between images with different SSIM but the same MSE图4 相同MSE 值下不同SSIM 的图像对比
式(4)、式(5)、式(6)分别比较图像x与y之间的亮度、对比度与结构信息。其中,μx及μy、σx及σy分别为图像x、y的平均值和标准差,σxy为协方差。α>0,β>0,γ>0 分别为调整l(x,y)、c(x,y)、s(x,y)的相对重要性参数;C1、C2、C3为常数,用以维持l(x,y)、c(x,y)、s(x,y)的稳定,实际使用时,将参数设置为α=β=γ=1,同时C3=C2/2,从而得到式(7):

其中,C1=(k1L)2,C2=(k2L)2,L是像数值的动态范围,k1=0.01,k2=0.03。
3 GPAE 模型
基于迭代的模型生成一例对抗样本需要多次迭代进行模型的反向梯度计算与前向分类结果计算,基于生成器的GPAE 模型仅进行一次前向计算即可快速生成一例对抗样本;并且,GPAE 模型中多分类器损失函数的引入,使其生成的一例对抗样本可以攻击多个分类器,提高了攻击效率。
为了解决现有基于生成器的模型产生的对抗样本与原图在人眼观察上区别明显的问题,GPAE 模型不再使用扰动叠加的方式,而是将对抗样本生成作为生成器对原图进行图像增强的操作,采用残差网络结构让生成器G直接根据原图生成对抗样本,这使得对原图的修改尽可能被隐藏在原图的边缘等人眼不易察觉的区域;GPAE 模型还使用了生成对抗网络损失函数与改进的感知损失函数作为模型训练的优化目标,以确保生成的对抗样本是真实的自然图像,并且与原图在人眼观察上更加相似。
3.1 问题定义
设(x,y)是数据集中的数据样本,其中x∈X,X是所有输入图像数据样本组成的集合,并且x~Pnature是符合自然图像数据分布的图像;y∈Y表示输入图像样本对应的在分类器中的真实分类类别标签。被攻击的深度神经网络分类器f:X→Y通过训练,能够根据输入的图像得到其对应的类别标签。设一个输入的原始图像x∈X,对抗攻击的目的是生成一个对抗样本x′,使得f(x)≠f(x′)(无目标攻击),或者使得f(x′)≠t,t为任意指定的目标类别(有目标攻击),生成的x′与x在人眼观察上应尽可能相近,即SSIM(x,x′)尽可能高,做到人眼不易察觉。
3.2 模型结构
图5 给出了GPAE 的总体结构,其主要由四部分组成:生成对抗样本的生成器G、判别真实样本与对抗样本的判别器D、被攻击的目标分类器f(其用来计算分类损失Lclf)以及一个用来计算对抗样本与输入原图之间的感知损失Lperceptual的结构。

Fig.5 GPAE structure图5 GPAE 总体结构
与GAP 模型采用扰动叠加的方式不同,在GPAE模型中,生成器G将原始图像x作为模型的输入,直接生成对抗样本。这样生成的对抗样本在亮度、颜色、形变等方面进行了细微的变换,相比于GAP 模型生成的对抗样本,显著提高了SSIM 指标,从而有效提升了人眼感知的相似性。
从图5 可以看到,GPAE 模型与其他基于生成器的模型,如GAP 模型相比,未采用扰动叠加策略来生成对抗样本,而是直接使用生成器生成对抗样本图像,这在运算效率上仅减少了扰动叠加至原图的时间。生成器生成对抗样本的时间不取决于输入数据的规模,是固定次数的浮点运算,因此GPAE 模型与GAP 模型等运算效率相当。因为GPAE 与GAP 模型等均基于生成器,相比于基于迭代的模型,可以有效降低对抗样本生成的时间。
一旦GPAE 模型的生成器G训练完成,在对抗样本生成阶段,每次只需要将原图输入生成器进行一次前向计算就可以生成一例对抗样本。基于迭代的对抗样本生成模型每次迭代修改原图后,都需要将修改的图像输入分类器进行一次前向计算以判断当前攻击是否成功,并且不同的模型每次迭代还需要对梯度、分类超平面等进行计算。以梯度计算为例,每次迭代就需要一次分类器的反向计算。因此基于迭代修改的对抗样本构造模型与基于生成器的GPAE相比,在对抗样本生成时间复杂度上,前者始终是后者的n倍(n指迭代次数)。
生成器G生成的对抗样本x′=G(x)被输入至判别器D,通过训练判别器D,使其能够尽可能地将真实样本与对抗样本分辨出来;同时训练生成器G,尽可能生成让判别器D无法正确判别的生成图像,其损失函数如式(8)。

式(8)中E代表期望,x~Pr表示输入的原始图像。在优化Lgan时,通过对抗的方式同时训练G与D的生成对抗网络结构,使生成器G生成的对抗样本符合输入图像的分布,以使对抗样本与输入的原始图像具有相同分布,进而生成自然图像。
为了提高对抗样本与原图在人眼观察上的相似性,GPAE 将均方误差MSE 与改进的感知内容损失集成为训练生成器G的损失函数的一部分,即感知损失Lperceptual。通过训练模型降低感知损失,从而使经过训练的生成器G生成的对抗样本在人眼观察上高度接近原图。
对抗样本x′=G(x)输入到被攻击的分类模型f,将对抗样本在DNN 分类器中的分类结果与指定的分类目标之间的交叉熵作为分类损失Lclf,并作为训练G的损失函数的一部分。形式化描述分类损失为式(9)。

其中,H为交叉熵函数。通过优化分类损失使对抗样本能成功攻击目标模型,同时GPAE 集成多个分类损失,以生成能攻击多个DNN 分类器的对抗样本,进而提高攻击效率。
最终训练GPAE 中生成器的损失函数由上述各部分组成,如式(10)。
其中,a、b、c为实数,用来调整各部分损失的权重。通过优化损失函数来训练生成器G,从而得到可以生成与原图在视觉上极为相似的对抗样本,并具备同时攻击多个分类模型的能力。
3.3 生成器G 与判别器D
GPAE 基于生成对抗网络GAN 结构[15],同时训练生成器G与判别器D,进而利用G直接生成对抗样本。与直接使用GAN 根据输入的噪声向量生成一个自然图像不同,GPAE 的对抗样本生成是一个图像增强的过程,G对输入的原始图像进行增强从而得到对抗样本,这非常符合残差网络(residual networks,ResNets)[16]的设计,因此GPAE 采用残差网络来构造生成器G,其结构如图6。其中每一个残差块(residual block)的结构如图7。
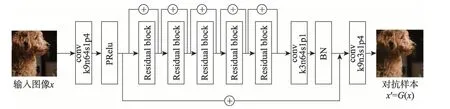
Fig.6 Structure of GPAE generator图6 GPAE 生成器结构
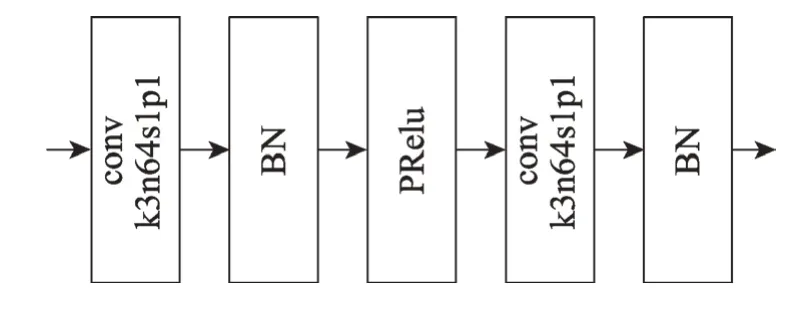
Fig.7 Structure of Residual Block图7 Residual Block 的结构
在图6与图7中,k代表卷积核大小(kernel size),n代表输出的特征图(feature map)的层数,s代表卷积步长(stride),p代表填充的大小(padding);PRelu表示带参数的线性整流函数(parametric rectified linear unit);BN 表示批归一化(batch normalization);⊕操作表示按位叠加。
判别器D用来判别其输入是对抗样本还是原始图像,在GPAE 中D被设计为一个最常见的卷积神经网络,通过sigmoid 函数输出一个0 至1 的值,其值越小,D越倾向于将样本判别为对抗样本;反之,其值越大D越倾向于将样本判别为原始图像。其结构如图8 所示。
其中各参数的含义与上述生成器一致。每个灰色块表示的是由卷积块、BN 层与激活函数层组成的块。本文使用的Leaky Relu 激活函数中的非零斜率为0.2。
3.4 感知损失
为了提高对抗样本与原图之间视觉上的相似性(perceptual similarity),GPAE 设计了改进的感知损失函数Lperceptual以同时优化对抗样本与原图在内容空间与特征空间的相似性,并将其作为训练G的损失函数的一部分。Lperceptual由均方误差MSE和文献[17]中SRGAN(super resolution generative adversarial network)的感知损失函数组成,并对SRGAN 中的感知损失进行了优化改进,Lperceptual的结构如图9 所示。
感知损失主要由均方误差MSE 与VGG 损失两部分构成,并根据不同权重组合为Lperceptual,如式(11)。

其中,MSE 主要用来描述对抗样本与原图之间像素值内容(pixel-wise)上的相似性,MSE 越低就越相似。并且,MSE 越低,对抗样本与原图之间的峰值信噪比(peak signal-to-noise ratio,PSNR)就越高,从而确保两者之间的内容空间上的相似性。单通道图像的MSE 均方误差如式(12)。

其中,x′为对抗样本,x为原图,n、m分别用来指定图像中像素的坐标。

Fig.8 Structure of discriminator图8 判别器的结构
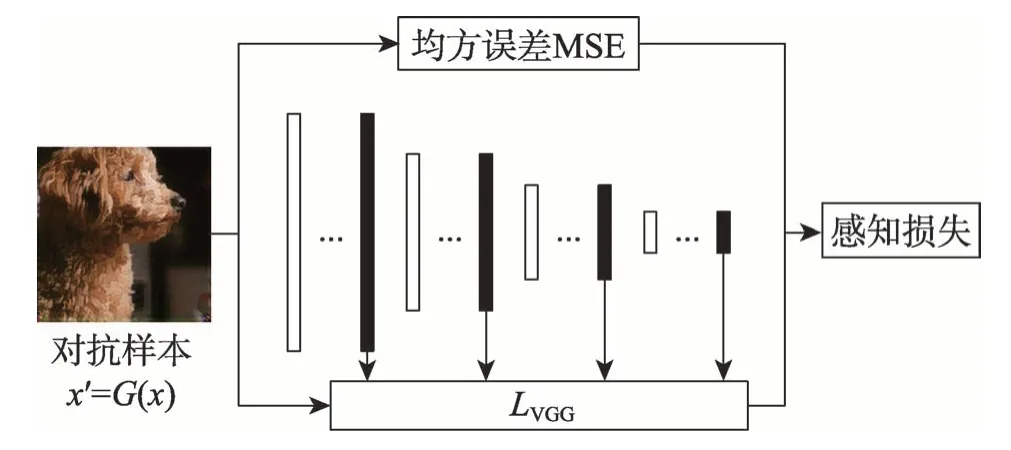
Fig.9 Perceptual loss composition图9 感知损失构成
MSE 仅表征了对抗样本与原图在图像空间上内容的相似性,优化MSE 值可以有效提高PSNR 指标,但是PSNR 指标高不完全表示对抗样本与原图在人眼观察上的相似性就高。在训练模型时,MSE 会对幅度改变大的像素有更强的惩罚,而对于幅度改变小的像素惩罚较低,最终使生成的对抗样本与原图之间像素值改变小,范围改变较大,这样的改变会影响图像局部的结构信息、亮度与颜色等,实际上人眼对图像无纹理区域的结构、颜色、亮度等改变更为敏感,这些改变会降低SSIM 指标。而在特征空间中包含了对图像提取的结构特征信息与纹理特征信息,因此GPAE 增加了在特征空间中的计算相似性的损失函数,从而进一步提升对抗样本与原图的相似性:GPAE 基于VGG16 模型,使用原图与对抗样本在同一个预训练的VGG16 模型上的特征图(feature map)上的相似性作为损失函数,为了方便表述,称该损失函数为VGG 损失LVGG。
文献[18]通过比较输入激活函数之前与之后的特征的类激活映射图(activation map),发现输入激活函数之前的特征图与经过激活函数之后的特征图相比拥有更多影响分类结果的像素。这说明随着VGG模型深度加深,绝大多数经过激活函数之后的特征变得非活跃,且激活函数之前输出的特征相比激活函数之后输出的特征具有更多信息。这些代表特征空间中的特征信息,包含了结构信息、纹理信息,而特征图经过激活函数后会减少特征信息的输出,因此计算激活函数之前的特征图之间的相似性要比计算特征图之后的相似性更加全面准确。基于此,GPAE使用线性整流函数(rectified linear unit,ReLU)之前的特征图来计算误差。因为不同层的卷积层提取的特征信息不同,为了让损失函数包含更多特征空间中的相似性损失,进而更好地训练生成器生成与原图在结构信息、纹理信息上更相似的对抗样本,本文使用多个卷积层的输出特征图进行损失函数计算,具体在GPAE 模型中选择了不同通道(channel)数的三个卷积层计算对抗样本与原图在特征空间中的相似性,加权求和得到VGG 损失,结构如图10 所示。
将原图与对抗样本同时输入预训练好的VGG16模型中,在图中灰色卷积层中,其在激活函数之前输出的特征图之间的均方误差分别为MSE128、MSE256、MSE512。最终的VGG 损失为上述三项的加权求和,如式(13)所示。

其中,i、j、k分别为不同项的权重。不同卷积层输出的特征图信息都不尽相同,通过文献[19]提出的Network Inversion以及文献[20]提出的Network Dissection等卷积神经网络可视化技术对卷积层输出特征图的研究可知,较浅层的卷积层会更偏向于提取位置与颜色信息,而较深层的卷积层则偏向于提取类别纹理、目标等更加影响人眼感知的信息,因此为了提升生成的对抗样本与原图在人眼观察与感知上的相似性,较深层的卷积层输出的特征图相似性应该具有更高的权重。此外,随着深度的增加,卷积层输出的特征图也更加抽象,而较浅层卷积层输出的特征图包含更多输入图像的内容信息,由于GPAE 模型已经在感知损失函数中使用了MSE 来保证对抗样本与原图内容上的相似性,因此在VGG 损失中,越深的特征图相似性损失项应该具有更高的权重,即上述三个权重参数i、j、k应该是逐渐增加的。根据上述分析,如果要求对抗样本与原图在颜色等信息上更相近,可增加浅层卷积层输出特征图的相似性损失项权重。
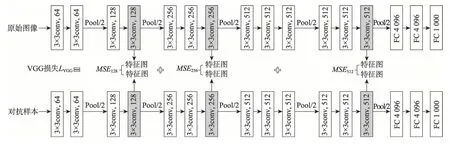
Fig.10 VGG loss composition图10 VGG 损失构成
3.5 生成可攻击多个模型的对抗样本
GPAE模型通过将多个分类模型的分类损失集成为最终训练生成器G的分类损失函数,以支持生成器G生成能攻击多个分类模型的对抗样本。形式化描述为:设被攻击的分类模型为f1,f2,…,fm,通过GPAE生成的对抗样本x′=G(x)可以同时使这些分类器分类错误,以无目标攻击为例,即f1(G(x))≠f1(x),f2(G(x))≠f2(x),…,fm(G(x))≠fm(x)。实现攻击多个分类模型的结构如图11 所示。
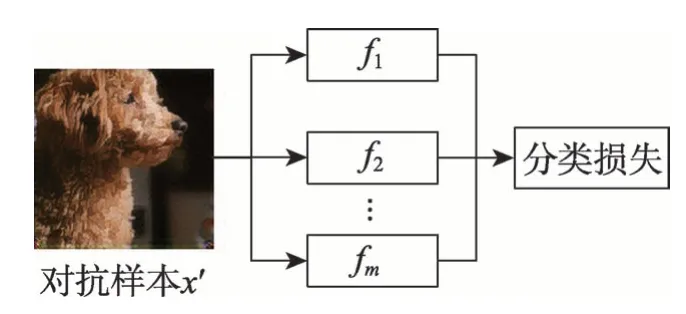
Fig.11 Attack multiple classifiers图11 攻击多个分类器
生成器G生成的对抗样本x′被输入多个预训练好的分类器f1,f2,…,fm。最终的分类损失是各个分类模型的损失函数的线性组合,如式(14)。

其中,{λ1,λ2,…,λm}⊂R 是不同分类器的权值,该权值依赖于被攻击的模型的复杂度,越复杂的模型其权重越高,结构越简单的模型权重越低。在本文中,同时攻击预训练好的VGG16、VGG19 两个DNN 分类器。
3.6 GPAE 参数规模与收敛性
尽管从结构上看GPAE 模型除了生成器与判别器包含DNN 网络结构,在损失函数中,分类损失函数与改进的感知损失函数也具有DNN 网络结构,但实际上因为损失函数中的DNN 结构都是预训练好的模型,因此在参数训练过程中,GPAE 模型仅需要训练生成器G与判别器D的参数。与其他基于生成器的对抗样本生成模型相比,GPAE 模型增加的参数量实际仅为判别器的参数。判别器参数的训练方式与GAN 中训练方式一致,不会影响导致的收敛。
与生成器仅生成叠加在原图的扰动不同,GPAE模型中的生成器G需要直接根据输入的原图生成对抗样本,这就需要G的结构具备更高的复杂度来完成图像生成任务。因此,GPAE 模型需要增加生成器G的深度,在深度神经网络模型训练时,通过反向传播的方式来计算损失函数对每层神经网络中各参数的梯度,进而更新模型参数。如文献[21]所述,根据链式求导规则计算损失函数对模型中某层网络的参数的梯度,实际上是计算该层网络之后的每层网络的输出对输入的偏导数的连乘结果,因此,当模型深度加深时,模型中浅层梯度就会通过更多项偏导数的连乘计算得到,当偏导数小于1 时,连乘结果就会变得很小,导致反向传播时浅层网络中参数的梯度很小,进而浅层参数更新缓慢,以致模型难以收敛,出现梯度消失问题[21];当偏导数大于1 时,连乘的结果就会很大,导致浅层梯度大,进而浅层参数更新幅度大,模型训练不稳定,出现梯度爆炸问题[22]。换句话说,模型深度的加深会加剧连乘效应,导致浅层梯度过小或过大,最终导致模型难以训练。
GPAE 模型中采用的残差网络块结构[16],通过跳连的方式将浅层的输出跳连至深层的输出,残差块仅输出残差,与输入相加后成为最终的输出。因此在反向传播时,损失函数的梯度通过跳连的结构直接传递到浅层网络,减少浅层梯度的计算受模型深度的影响,使得在训练时较浅层的梯度不会异常,有效避免了模型深度加深对收敛性的影响。
GPAE 模型中使用了Batch Normalization 操作,对输入卷积层的批数据进行归一化,使其均值与方差规范,从而有效避免在训练时产生的梯度爆炸与梯度消失问题,使模型训练可以更快收敛;因为对数据都进行了归一化操作,也减少了模型对输入的初始参数的依赖,使得模型更容易训练,更易收敛。
4 实验
分别对GPAE 生成器生成的对抗样本与输入原图的人眼感知相似性、GPAE 中改进的感知内容损失的有效性以及GPAE 同时攻击多个DNN 分类器的能力进行实验。
使用了ImageNet ILSVRC 2012 数据集[23]与Tiny ImageNet数据集[24],这两个数据集均为自然图像数据集。ImageNet ILSVRC 2012数据集的训练集一共包含128万张图像,验证集包含50 000张图像,测试集包含100 000 张图像。Tiny ImageNet 数据集与ImageNet ILSVRC 数据集相似,但数据量规模较小,其训练集包含100 000 张大小为64×64 的自然图像,每个分类有500 张图像用于训练、50 张图像用于验证、50 张图像用于测试。
经过多次实验,发现GPAE 各部分损失函数参数设置如图12 所示可以取得最好的实验效果。
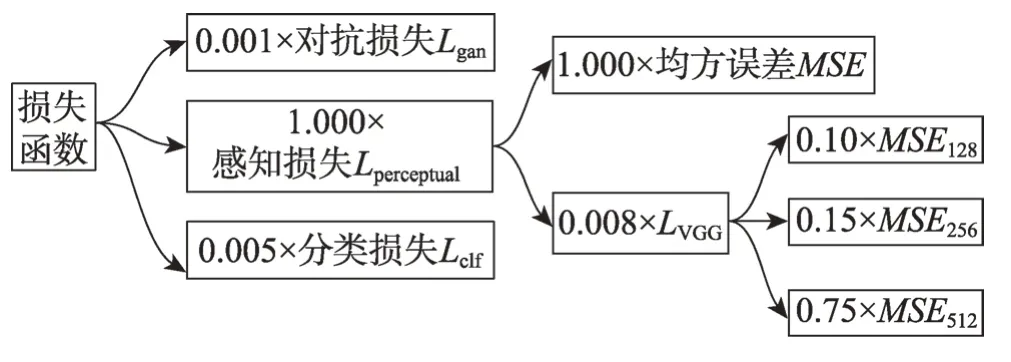
Fig.12 Settings and composition of loss function图12 损失函数参数设置与构成
根据图12,训练GPAE 生成器的损失函数如式(15)所示。

在GPAE 模型训练中,每一个mini-batch 的batchsize 为15,epoch 设置为30,同时设置在验证集上攻击成功率改变小于0.05 时停止训练。
实验在上述参数设置下进行。
4.1 GPAE 与GAP 生成的对抗样本对比实验
为了测试GPAE 模型对不同深度神经网络分类器的攻击效果,以及对抗样本与原图的人眼观察相似性,本实验每次仅攻击一个DNN 分类模型。使用ImageNet ILSVRC 2012 数据集,并将在ImageNet ILSVRC 2012 数据集上预训练的VGG16、VGG19 和Inception-V3模型作为需要攻击的DNN分类器。GPAE生成器生成的对抗样本将与GAP 模型生成的对抗样本进行对比,以验证GPAE 模型是否能在保持攻击成功率的基础上提高对抗样本与原图的SSIM 值,从而提高人眼观察相似性。其中,作为对比的GAP 模型生成的对抗样本与原图的差异L∞被设置为10。
在上述设置下训练GPAE 与GAP 模型生成器。将测试集的图像作为原图分别输入GPAE 与GAP 生成器,得到对抗样本,用生成的对抗样本攻击分类器。实验得到的对抗样本与原图的SSIM 值及对抗样本的攻击成功率如表1 所示。
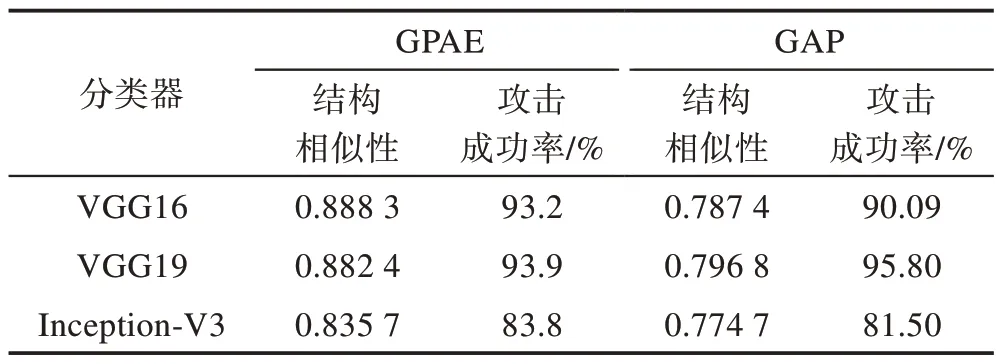
Table 1 Comparison of SSIM and fooling ratio表1 结构相似性与攻击成功率对比
为了展示人眼观察下实验结果对抗样本的差异,这里罗列出部分GPAE 和GAP 模型生成的对抗样本对比图,如图13 所示。进一步地,为了更清楚展现细节区别,局部放大对比图如图14 所示。

Fig.13 Comparison of adversarial examples generated by GPAE and GAP图13 GPAE 和GAP 模型生成的对抗样本对比图

Fig.14 Local enlarged comparison图14 局部放大对比图
由表1 可见,GPAE 模型生成的对抗样本,相比于GAP 模型生成的对抗样本,能够在保持攻击成功率的基础上,提升与原图的SSIM 值。观察GPAE 与GAP 生成的对抗样本发现:GPAE 生成的对抗样本相比GAP 生成的对抗样本,与原图在人眼视觉感知上更加相似,GAP 生成的对抗样本与原图相比,明显可见叠加了纹理;而GPAE 生成的对抗样本与原图的差异较小,人眼不易察觉出区别。观察GPAE 模型与GAP 模型生成的对抗样本与原图的差异可以发现,使用GPAE 模型生成的扰动会更加依赖原始图像,幅度较大的扰动信号主要分布在原始图像的一些结构边缘,这样生成的扰动减少了对原图结构信息的改变,而GAP 生成的扰动则是非常明显的纹理整体叠加在原图上。
4.2 改进的感知损失函数的有效性实验
为了验证GPAE模型中改进的感知内容损失LVGG能否有效提高对抗样本与原图的相似性,提高两者间的SSIM 值,分别对以下三种情况下的对抗样本的生成情况进行了实验:
(1)未使用感知内容损失。
(2)未改进的感知内容损失:即SRGAN 中使用的感知内容损失,仅使用VGG 模型的最后一层激活函数之后输出的特征图来计算感知内容损失。
(3)改进的感知内容损失。本部分实验在Tiny ImageNet 数据集上完成,攻击的分类模型为预训练的VGG16 分类模型,实验结果如表2 所示。
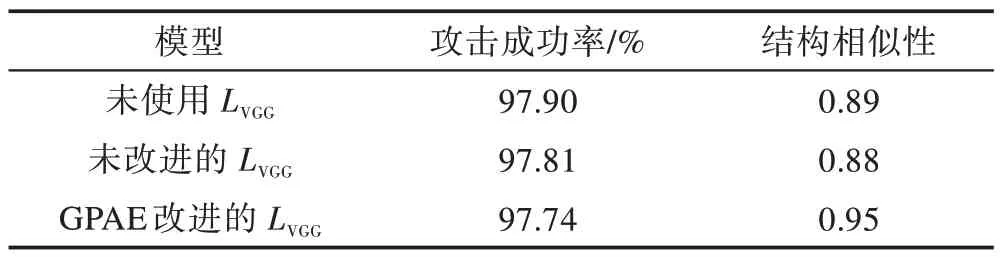
Table 2 Experimental results of different perceptual loss functions表2 不同的感知损失函数实验结果
为了验证表2 中的实验结果数据,图15 展示了三组生成的对抗样本与原图对比情况。

Fig.15 Adversarial examples comparison with different perceptual losses图15 不同感知损失的对抗样本对比
实验结果表明:使用改进的感知内容损失,能在保持攻击成功率的基础上,有效提升对抗样本与原图的SSIM 值。观察生成的对抗样本可见:使用改进的感知内容损失训练生成器,能增加对抗样本的细节,减少对原图的扰动,提升对抗样本与原图之间在人眼观察上的相似性,相比于未使用感知内容损失的模型,减少了对抗样本上的纹路,图像更加自然。未改进的感知内容损失对结构相似性指标SSIM 效果提升有限,相比于改进的感知内容损失,在与原图的对比中,仍然有较为明显的纹路扰动添加,人眼易察觉。
4.3 攻击多个DNN 分类器实验
本文通过集成多个分类器损失函数实现对多个分类模型的攻击。本部分对攻击多个模型的效果进行相关实验。使用ImageNet ILSVRC 2012 数据集作为训练、验证与测试数据集,实现对VGG16、VGG19模型的同时攻击。
使用LVGG16、LVGG19两个分类模型的分类损失函数构成总的分类损失函数Lclf,因为VGG19 模型相比VGG16 更加复杂,经过多次实验,将各部分的权值设置如式(16),取得最好的实验结果。

为了进行对比实验,首先分别单独使用LVGG16、LVGG19作为分类损失对GPAE 模型生成器进行训练,再使用LVGG16、LVGG19集成的分类损失对生成器进行训练。表3 分别对这三个生成器生成的对抗样本在不同分类器上的对抗攻击成功率进行展示。
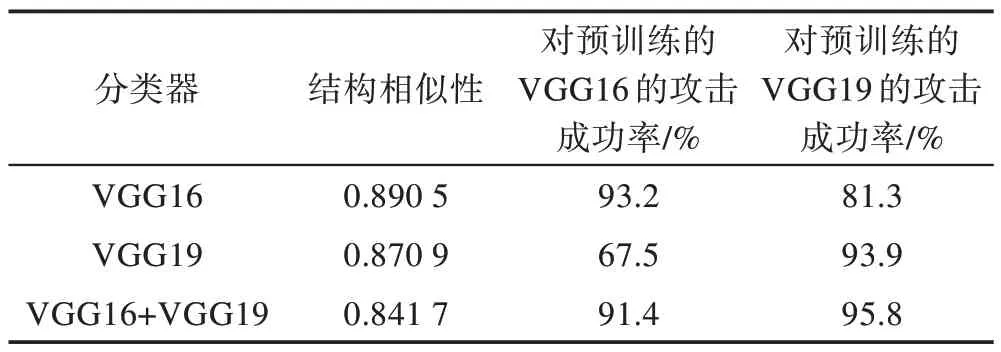
Table 3 Comparison of single and multiple attack表3 攻击单个与多个模型对比实验
从表3 可看出:当仅使用VGG16 或者VGG19 单个分类器的损失函数来训练生成器,其生成的对抗样本在攻击另一个预训练的分类器时,其攻击成功率都会大幅下降,而使用集成的分类损失函数训练生成器,其生成的对抗样本在两个分类器上都取得了较高的攻击成功率。实验结果表明:通过将多个DNN 分类器的分类损失函数集成为训练GPAE 生成器的损失函数,相比仅使用单个分类器损失函数进行训练的生成器,能有效提升生成的对抗样本在不同模型上的攻击成功率,验证了该结构生成的对抗样本能攻击多个DNN 分类器,有效提高生成对抗样本的效率。
5 结束语
本文提出了一种基于生成器生成对抗样本的模型,相比基于迭代的对抗攻击样本生成的方法,能够快速生成大量对抗样本。相比于其他基于生成器的对抗攻击模型,本文提出的模型在保持攻击成功率的前提下,有效提升了对抗样本与原图之间人眼观察的相似性,从生成对抗样本的时间与对抗样本与原图的相似性两方面保证了可用性。
本文的核心点主要有三个:
(1)使用GAN,并基于残差网络的结构设计了一个生成器模型,直接依据输入原图生成对抗样本,不采用叠加扰动来生成对抗样本的方式,避免了使用扰动叠加方式生成的对抗样本与原图具有明显不同的问题,GAN 同样让GPAE 生成的对抗样本图像更加真实。
(2)引入改进的感知损失,从图像内容空间与特征空间优化对抗样本与原图的相似性,不仅保证了像素值内容相似,也优化了纹理、结构信息等相似性,进一步提升了对抗样本从人眼观察上与原图的相似性。
(3)通过集成多个分类模型的损失函数,使生成的对抗样本能攻击多个主流深度神经网络分类模型,提高了对抗攻击的效率。
实验结果表明,相比于其他基于生成器的对抗攻击模型,本文提出的模型取得了较高的攻击成功率,并且有效提升了对抗样本与原图之间的相似性,更加不易被人眼察觉。
本文的后续工作可以在以下方面开展:
(1)修改模型中的分类损失函数,从而实现有目标攻击。
(2)改进残差网络块的结构,以生成更自然精细的图像。
