面向知识迁移的跨领域推荐算法研究进展*
2020-11-15刘柏嵩孙金杨
任 豪,刘柏嵩,孙金杨
宁波大学 信息科学与工程学院,浙江 宁波 315211
1 引言
随着网络信息化时代的到来,各类信息呈指数性增长,出现严重“信息过载”问题。如何从海量数据中按需高速获取有效信息成为亟需解决的问题,各类推荐算法应运而生。传统的推荐算法包括基于内容的推荐[1-3]、基于协同过滤的推荐[4-7]和基于混合方法的推荐[8-11]三种,其中基于协同过滤的推荐应用广泛,推动了电商领域的发展。
近几年推荐系统在学术界和工业界大热,推荐算法在不同的场景下发挥着重要作用。然而,数据稀疏问题和冷启动问题已然成为制约推荐系统进一步发展的重要瓶颈。迁移学习作为机器学习方法的补充和扩展,利用已有的来自不同领域的与当前任务相关的数据来帮助解决目标领域中标签数据稀少或者无标签数据问题,旨在从和目标域相似或相关的源域中迁移合适的领域知识,辅助解决目标域任务,已在图像处理、自然语言处理领域得到运用。近年来,迁移学习被用来解决推荐中的数据稀疏[12]和冷启动[13-14]问题,这类推荐算法统称为跨领域推荐算法(cross-domain recommendation)[15-16]。
2 跨域推荐概念及其技术
2.1 相关定义
不同任务中域的划分不尽相同,目前在推荐任务中域尚未有统一的划分标准。目前取得较为广泛认同的推荐中的域的定义为:具有某个特定推荐系统中所需的某些共享属性的项目集合构成一个域,其中共享属性可以是文本属性、评分、标签、类别等[17-18]。本文中的域遵从此定义。
跨领域推荐是将不同领域的知识和信息融合,通过发现并利用辅助数据域中的可迁移知识来提高目标域的推荐性能,从而做出更加综合全面的推荐。其中,跨领域推荐任务定义如下:
定义1(跨领域推荐任务)设UA和UB分别是域A和域B中的两个具有某种特征(用户偏好)的用户集合,IA和IB分别是域A和域B中的两个具有某种特征(商品属性)的项目集合,则两种不同的跨域推荐任务可以归纳如下:
(1)利用源域A中用户和项目信息提高目标域B中的项目的推荐质量;
(2)将来自两个不同域中的项目进行联合推荐。
文中跨领域推荐任务均指第一种情况。
2.2 迁移学习技术及其分类
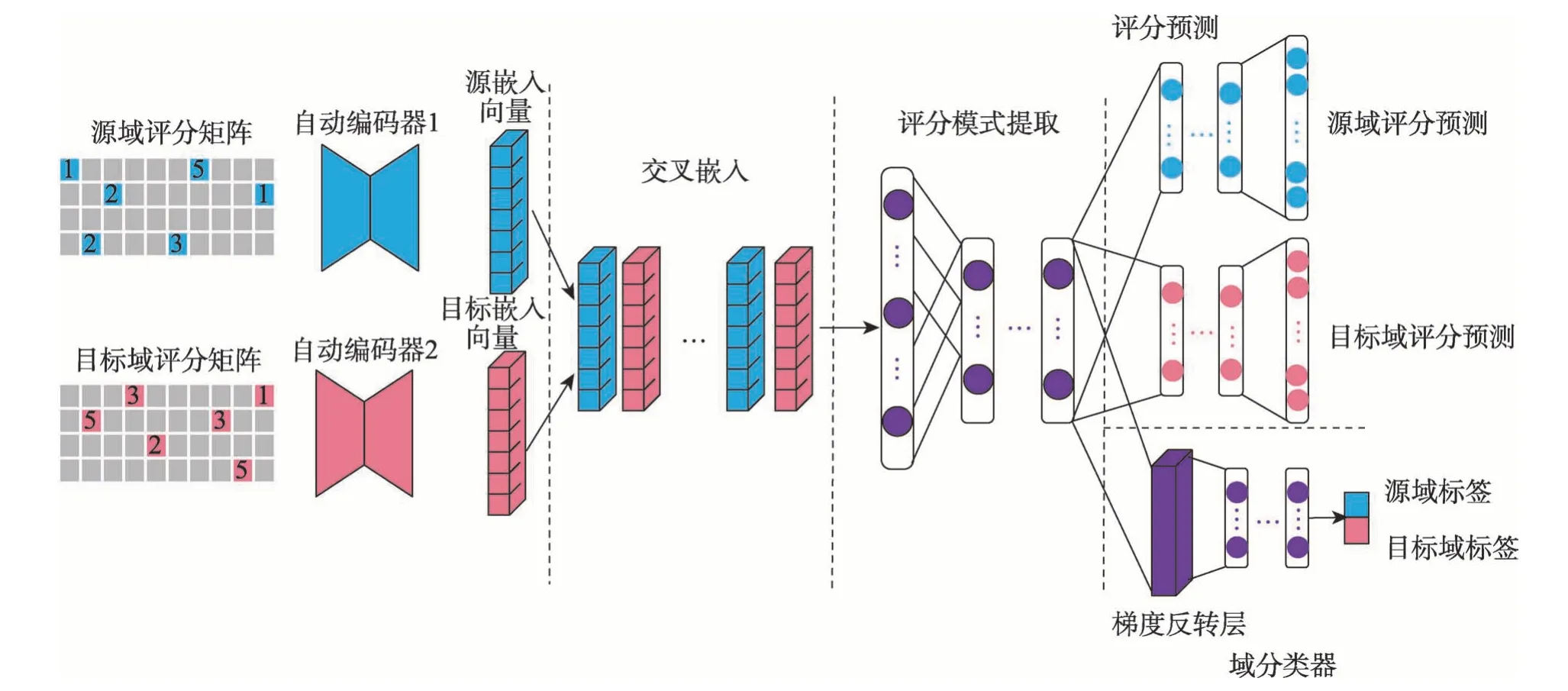
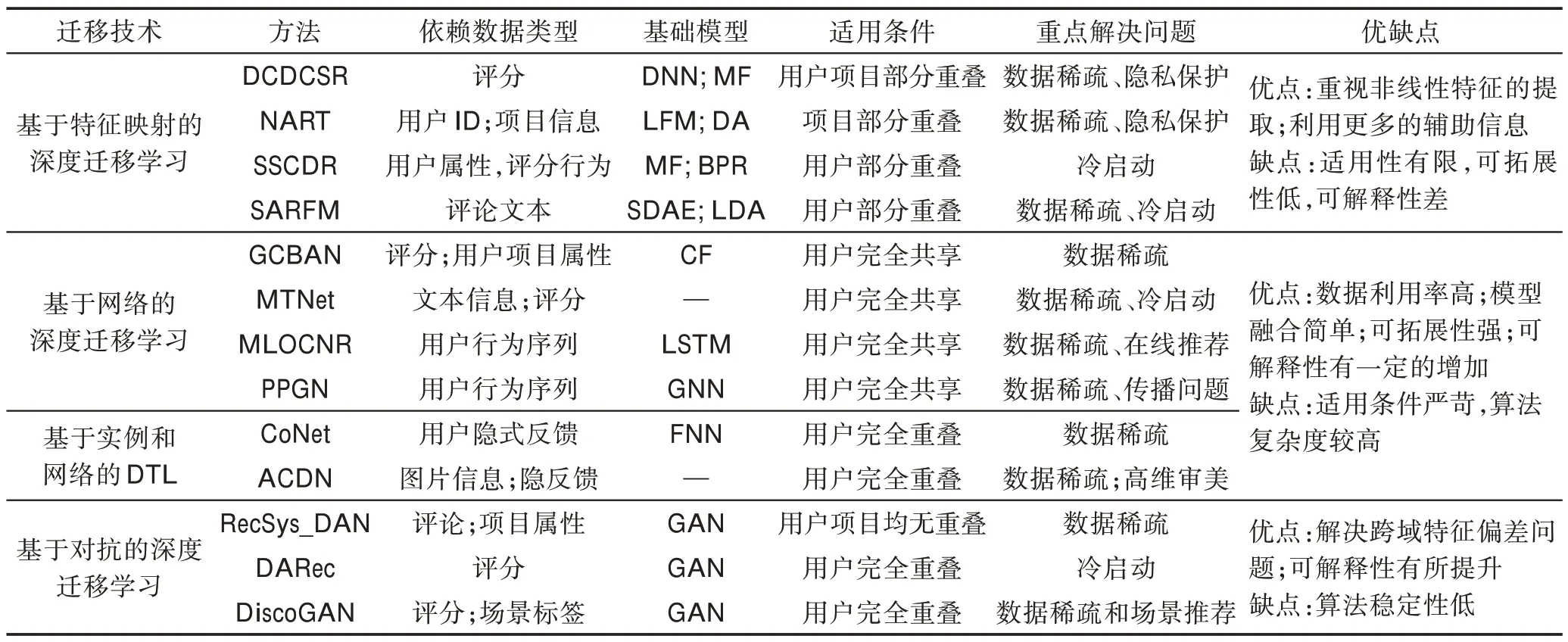
定义2(迁移学习(transfer learning))给定源域Ds以及源任务Ts,目标域Dt和目标任务Tt,当Ds≠Dt或者Ts≠Tt时,利用Ds和Ts中学习到的fs(∙)来提高目标预测函数ft(∙)的预测准确性,则迁移学习任务可表示为 合理应用迁移学习可作为传统机器学习算法的补充,解决其无法解决的问题,传统机器学习和迁移学习从域和任务两个角度的对比如表1 所示。但如何避免“负迁移”是应用迁移学习时不可避免的问题。有效避免“负迁移”需考虑两个问题:“迁移什么”以及“如何迁移”。从“迁移什么”层面上看,Pan等[19]将迁移学习分为四类,即基于实例的迁移学习、基于特征表示的迁移学习、基于参数的迁移学习和基于知识关系的迁移学习。而在“如何迁移”层面上,不同任务场景中有不同的迁移方法,接下来将以跨领域推荐场景为例重点阐述如何展开有效知识迁移。 Table 1 Comparisons between machine learning and transfer learning表1 传统的机器学习和迁移学习的比较 类似于迁移学习,深度迁移学习同样需要考虑“负迁移”问题。显然,在深度迁移学习中需要迁移的是那些含有更多有用信息的、可在不同域间共享的、有利于目标任务解决的非线性特征;而从“如何迁移”角度,文献[20]给出一种深度迁移学习的分类方法,其描述见表2,后文中关于深度跨域推荐算法的分类沿用此分类方法。 Table 2 Classification of deep transfer learning表2 深度迁移学习的分类方法 传统跨域推荐,即基于迁移学习的跨领域推荐算法,通过建立辅助域和目标域间知识迁移桥梁,借助矩阵分解、因子分解、张量分解等方法提取出合适的领域知识,将其迁移到目标域中辅助解决目标任务,提高目标任务的性能。不同推荐场景中,知识迁移方法不同,主要包括评分模式共享、隐含特征映射/转换和域关联三种。 评分模式,又称“密码本”,是由辅助域数据压缩而成的富含信息的聚类级的评分矩阵,常用于辅助域和目标域的用户项目不重叠时建模用户簇对于项目簇的隐含行为偏好,通过将用户-项目交互矩阵“共聚类”提取“密码本”,重构目标评分矩阵补全缺数数据,实现数据稀疏条件下的跨域推荐。如ACTL(adaptive codebook transfer learning)[21]以矩阵分解作为基本模型,动态调整提取密码本的规模以提高算法性能;LSCD(low-rank and sparse cross-domain)[22]加入低秩约束解决基于稀疏评分矩阵的跨域推荐问题;CD-MDTF(cross domain multi-dimension tensor factorization)[23]以多维度的张量分解替代矩阵分解,考虑用户-项目交互情况的同时考虑时间因子对推荐结果的影响。 以上方法均是从单个辅助域的评分数据中迁移领域知识,虽可初步解决推荐中数据稀疏问题,但是单个辅助域中的可迁移信息有限,易发生过拟合且无法保证知识的有效正迁移。近年来从多个辅助域中提取“密码本”的方式得到重视。MINDTL(multiple incomplete domains transfer learning)[24]从多个相关的非完全稠密域的评分中提取评分模式,并以此预测目标评分矩阵,其中评分矩阵的近似估计方法如下: 式中,Bn表示从第n个辅助域中提取的“密码本”,Utgt和Vtgt分别表示从目标域的评分矩阵分解得到的非负用户项目矩阵,W是掩码,用于控制待预测的评分矩阵的规模。该算法的不足在于要求引入的多个辅助域数据相互关联。Zhuang 等[25]放宽了引入辅助域时的数据相关性约束,提出TRACER(transfer collaborative filtering framework from multiple sources via consensus regularization),对多个辅助域评分数据联合因子分解,通过加入一致正则项实现各辅助域中“密码本”的相似性约束。该方法只强调了域间的共有特性而忽略了域间特有信息,导致推荐效果不理想。Jiang 等[26]考虑了域间特有信息的重要性,提出基于低秩系数分解的方法DLSCF(deep low-rank sparse collective factorization)。该方法分别从多个辅助域中提取共享评分模式和特有评分模式,再利用分层模型得到隐含因子和隐含子类之间的从属关系,通过域间隐含因子类间关系约束保证知识的正迁移以实现数据异构场景下的跨域推荐。 将单个辅助域拓展到多个辅助域增加可迁移信息能够提高算法性能,但仅利用辅助域的评分信息增大了数据引入的代价却未充分利用其他可用辅助信息,降低数据的利用率。于是,充分挖掘辅助域中知识关系成为了增加正迁移的另一种解决办法。王俊等[27]提出基于共享模式、隐含因子和连接图三元桥式的TRBT(triple-bridge transfer)模型,考虑域间特有信息以解决正迁移不足的问题,模型框架如图1 所示。其目标函数如下: 其中,Z是评分矩阵R的指示矩阵,当R中有评分缺失时Z的取值是0,反之则为1。V0、U0分别表示用户和项目的可迁移特征,S表示通过连接图挖掘的用户/项目的可迁移的兴趣模式信息,B是辅助域和目标域中的共享信息,B′则是域间特有信息,将跨域迁移信息分成[B,B′]可保留领域间共有信息,同时能够很好地反映领域的相关性。GU=tr(UTLUU),LU=DU-WU,其中LU是拉普拉斯矩阵,WU是用户i和用户j余弦相似度矩阵,DU是由WU的行元素之和生成的一个对角矩阵,GV的计算方法类似。GU和GV的引入,强调了共享评分对于项目或者用户的不同侧重,增加了模式迁移的多样性。SKP(sharing knowledge pattern)[28]则将用户属性信息加入推荐过程以解决跨域正迁移不足问题。引入其他可用的辅助信息增加可用的数据量可缓解数据稀疏带来的影响,但在辅助域数据和目标域数据存在不一致性或者没有明显关联的情况下,该类方法反而会加重“负迁移”。 Fig.1 Model of TRBT图1 TRBT 模型图 隐含因子(latent factor)是常用的域间用户行为和项目属性的稠密表示,用于实现用户偏好和项目属性之间匹配,在域间数据没有明确关联但共享隐含空间时作用效果极佳。基于隐含特征映射/转换的跨域推荐方法通过一定的特征映射/转换,将源域数据和目标域数据映射到相同的特征空间,从而建立域间关联并以此作为域间知识迁移的桥梁,解决不同领域的用户行为的异构问题。 Zhang 等将域间域内的实体对应关系加入矩阵分解过程中,提出基于核诱导的知识迁移的跨域推荐算法KerKT(kernel-induced knowledge transfer)[29]。利用领域自适应调整重叠实体的特征空间,基于扩散核补全法[30]将两个领域间的不重叠的实体进行关联,通过重叠实体实现知识有效转移,从而缓解数据稀疏性问题。实验表明,本算法在不同的场景下可将预测的精准性提高1.13%至20%不等,同时实验结果亦证明了即便在域间仅有较小重叠度的情况下,领域知识的跨域迁移也是可行的,但该方法仅适用域间实体有重叠的情况。SCT(semantic correlation in tagging systems)[31]则利用跨域标签间的语义关联跨域对齐用户和项目的特征表示,识别域间相似的用户和项目,实现数据稀疏条件下的跨域推荐。该方法放宽了需实体重叠的适用条件,但其能否准确识别领域间相似用户和相似项目直接影响推荐效果,适用范围受限。 文献[32]提出的CDLFM(cross domain collaborative filtering algorithm based on a linear decomposition model)考虑到用户在评分行为上的相似关系,将用户相似度融入到矩阵分解中,同时为了在稀疏域中全面刻画用户偏好,作者提出从用户不感兴趣点、评分差异性及评分行为相似性三个维度计算用户相似度。为实现跨领域的知识迁移,文中提出基于领域的梯度增强树(gradient Boosting trees,GBT)方法学习特定用户的高阶特征映射函数来对齐用户隐含特征。具体来说,每一个冷启动用户u∈UT都可以在源域中找到与之具有相似评分行为的链接用户v并以此为迁移桥梁,利用用户v在源域和目标域中的潜在特征对计算出域间的特征的映射关系,其中f(x)按式(3)完成第m次梯度增强: 根据用户u在源域中的潜在特征和特征映射函数按式(4)~式(6)得到项目的预测评分: 其中,hm(x;αm)为参数化函数,ηm为学习率,λ是防止过拟合的衰减参数,Vt是目标域中的项目的隐含特征表示。尽管文章中提出了三种不同的计算用户相似度的方法,但其算法性能受到单一跨域知识迁移模式约束。随后,吴彦文等[33]提出采用联合用户侧重和项目侧重的多元知识迁移模式预测目标域评分实现数据稀疏条件下的跨域推荐。更有一些学者借助隐含特征映射/转换基本思想创造性地将跨域推荐问题转化成分类问题[34]、回归问题[35-36]等,用常见的机器学习算法加以解决,为跨域推荐提供了新的求解思路。 域间关联是目前传统跨领域推荐算法中常见的另一个重要的方法。该类算法通过利用额外辅助域中除隐含特征和评分信息以外的其他外部信息建立域间知识迁移的桥梁,增加跨领域推荐的准确性和合理性,同时增加辅助域数据的利用率。常用的域间关联信息包括物品标签及其语义关系、用户社交信任关系、域间关联规则等。ITTCF(item-based tag transfer collaborative filtering)[37]摒弃了大部分跨域推荐算法中仅从用户评分模式中挖掘可迁移知识的单一辅助方式,将用户的行为反馈(即标签)和数值型的评分信息相结合,通过层次标签聚类、主题偏好迁移多种方式解决跨域推荐问题。Ma 等[38]则将评分数据与用户社会信任关系结合融入到推荐中来,提出了跨领域信任感知推荐模型TT-CDR(transitive trustaware cross-domain recommendation)。依据用户间的社交关系为每个领域单独建立一个基于上下文感知的信任关系传递网络,并在此基础上利用基于信任关系传递感知的概率分解模型挖掘用户间的社会信任,建模用户间的间接信任关系,最后利用非线性用户特征向量的映射连接不同领域的用户反馈,实现跨域项目预测。由于无法自动挖掘社交信任关系而需要给定先验的用户间信任关系,因此该方法不适用于关系动态变化的情况。UP-CDRSs(user profile as a bridge in cross-domain recommender systems)[39]则自动计算用户信任关系并以此作为域间关联桥梁,通过最大化后验概率学习用户和物品的隐含因子,将二者的点积结果对未评级物品做出评分预测以实现跨领域推荐。类似的方法还有CDIE-C(cross-domain item embedding method based on co-clustering)[40]、FAS-CF(fusion auxiliary similarity collaborative filtering)[41]等。 除了直接利用跨领域数据间的直接关联外,从领域数据中挖掘跨域间接关联也是解决跨域推荐问题的新的方法。考虑到用户社会关系和行为偏好间互惠关系,Shu 等提出了CrossFire(cross media joint friend and item recommendation)[42],利用平台间用户-用户相关性以及平台内用户-项目交互关系挖掘不同平台间的领域关联特征,融合跨媒体信息解决跨媒体推荐中两媒体不能直接链接问题。图2 是CrossFire 算法框架。通过基于项目的稀疏迁移学习、跨媒体的评分行为迁移学习和跨媒体的社交关系迁移学习三方面的计算提取跨域共享特征实现项目和朋友的联合推荐。在项目的稀疏迁移学习部分将给定的项目特征矩阵Xi近似分解为DVi,其中D是从源域和目标域中提取的共享特征矩阵,用于跨域知识迁移;同时为了满足项目特征的几何位置描述以及跨域项目特征的统一编码约束依GraphSC(graph regularized sparse coding)[43]和MMD(maximum mean discrepancy)[44]思想加入正则项,按式(7)方式得到项目的稀疏表示Vi,i=1,2,…,p: Fig.2 Frame of CrossFire图2 CrossFire 模型框架 再将项目的稀疏表示通过映射矩阵Q的作用得到项目的隐含特征表示,完成跨媒体的评分行为迁移学习。类似的,引入用户-项目共享交互矩阵P建模用户在不同社交媒体上的共享隐含特征,构建跨媒体用户关联,实现跨媒体朋友推荐。该算法较好地利用社交网络实现推荐问题,但由于领域间没有直接关联造成领域特征表示存在语义偏差,推荐的精准性有待提高。 获取可迁移特征的质量逐渐成为影响跨域推荐性能进一步提高的重要因素,加之可利用辅助数据的异构性,传统跨域推荐算法仅利用从评分数据中提取线性特征来实现推荐的局限性显现,推荐结果不能满足实际要求。于是,研究者们开始将目光转向深度迁移学习,试图用深度学习方法解决跨领域推荐问题。现有的深度跨域推荐算法按照深度迁移学习技术的不同可分为基于特征映射、基于网络/实例、基于对抗迁移三大类。 该类算法借助于深度学习方法将不同领域的特征向量映射到相同的特征空间,在新的特征空间中对齐不同域的用户/项目向量表示,消除因特征非对齐对推荐结果的影响,解决跨域推荐问题。Zhu 等[45]提出一种基于迁移学习的隐含因子跨域映射模型,在矩阵分解的基础上利用深度神经网络映射跨领域特征,同时将不同领域间用户和项目的评分稀疏度引入,作为一种网络训练的指示因子,提高评分数据的利用率。该算法保留了矩阵分解较好的解释性又注重非线性特征的提取,但未考虑域间数据特征不一致性的影响。为此,Gao 等[46]提出了仅需项目侧辅助信息的神经注意力跨域推荐算法NATR(neural attentive transfer recommendation),引入维度适应单元解决跨域数据不一致性问题,其网络结构如图3。其中,迁移增强嵌入层以隐因子模型(latent factor model,LFM)作为基准模型,将实值的用户与项目的稀疏向量分别映射成稠密向量,结合维度适应单元解决项目向量迁移过程中不同领域内向量表示的维数偏差问题;项目级注意力层和域级注意力层则充分利用注意力机制强区分性,分别在构建用户表示时区分不同项目的重要度和在跨域迁移过程中动态调整领域知识对推荐结果的影响因子;结果预测层将求得的用户偏好特征向量与项目特征向量进行点积操作计算预测评分以实现跨领域推荐。SARFM(sentimentaware review feature mapping framework)[47]通过用户评论中的情感感知实现不同领域的文本特征对齐,解决跨域情感偏差问题。SSCDR(CDR framework based on semi-supervised mapping)[48]则以重叠用户作为锚点,通过半监督学习、k近邻聚类等方法计算冷启动用户的偏好特征实现跨领域推荐。该方法虽能解决新用户的推荐问题,但由于其要求两个域有重叠的用户,固无法解决新系统的冷启动问题。 Fig.3 Model of NATR图3 NATR 模型 基于特征映射的深度跨域推荐算法主要依据的数据大部分依旧是评分数据,辅助数据的使用不多,算法性能受到数据稀疏性影响依旧明显。 不同于传统意义上的基于网络的迁移学习保留预训练网络中一部分结果或模型参数直接应用目标任务,在跨域推荐场景下的基于网络的深度迁移学习则是对已有网络进行整体改进,组合重构新的网络模型,常见的网络改进方法有两种:(1)保留原始网络基本结构,增加某些层或者改变某些层以构成新网络;(2)以固有的某些网络结构作为整体模型的一部分,经拼接重组组成新的网络。He等[49]利用第一种网络迁移方法改进MVDNN(multi-view deep neural network)[50]模型提出GCBAN(general cross-domain framework via Bayesian neural network),其网络模型如图4 所示。该算法考虑到域间用户和项目的协同关系在推荐中的作用,以用户向量和项目向量的交互结果替代MVDNN 网络中用户/项目的原始特征编码作为全连接层的输入;除此之外,考虑到以定值作为权重无法表示网络的不确定性,GCBAN 以贝叶斯后验概率替代点估计,有效避免数据稀疏时的“过拟合”问题。值得一提的是,本方法中除了利用评分信息以外,还引入用户和项目的属性信息提升推荐效果。而MTNet(memory&transfer network)[51]则采 用第二类模型改进方法将记忆网络和迁移网络两个网络拼接,以记忆网络提取最有用的特征,以迁移网络选择可迁移的知识,最后通过特征共享交互层耦合两个独立网络,实现基于非结构性文本信息的跨域推荐。要求源域和目标域的用户完全重叠限制了该算法模型的适用性。类似方法,文献[52]以LSTM(long short-term memory)作为基础模型进行多层堆叠共同建模用户行为,捕获高阶用户-项目交互关系,同时在模型中加入注意力机制以及时间感知因子实现跨网络的在线推荐问题;考虑到LSTM 只能从左到右或者从右到左单向建模,而图神经网络则可有效地建模信息间的复杂高阶关系,Zhao 等[53]提出以GNN(graph neural network)作为基础模型的PPGN(preference propagation graphnet),通过构建用户偏好传播图模型捕获跨领域特征偏好的高阶传播关系,实现跨域推荐。 基于实例的深度迁移跨域推荐算法将不同域的特征加权重构,动态调整不同特征在目标网络和辅助网络中的地位,同样采用现有网络整体改进或重组的方式实现,亦可看成是基于网络的深度跨域推荐的一部分。Hu 等[54]利用NCF(neural collaborative filtering)[55]对复杂用户-项目高维非线性交互关系的有效性提出CoNet(collaborative cross networks)。该模型以前馈神经网络作为基本网络架构,由三个隐含层和两个十字交叉单元共同组成,其中交叉连接单元是将CSN(cross-stitch networks)[56]中的实数权值用关系转移矩阵替代的一种改进,用于动态调整不同特征空间的可迁移特征的权重,实现特征的双向跨域迁移。该算法是目前关于深度跨域推荐算法模型性能比较中常见的基础模型。Liu 等[57]则在CoNet的基础上将事先由ILGNET[58]提取的项目的高级审美特征连同用户和项目的隐含向量一并作为CSN 的输入,提出新的跨域推荐算法ACDN(aesthetic preference cross-domain network),其网络结构如图5 所示。该模型中以图片信息作为辅助信息,从多模态数据中提取有用数据以增强跨域推荐的性能。由于CoNet和ACDN 都需要以相同用户作为跨域迁移的桥梁,而在实际中不同领域间完全共享用户的可能性极低,且易造成用户的隐私泄露问题,因此算法的适用性受限。 Fig.4 Model of GCBAN图4 GCBAN 模型 Fig.5 Model of ACDN图5 ACDN 模型 该类深度跨域推荐算法不再依赖于评分数据,更多地关注于从反馈信息如文本信息、用户行为序列信息中挖掘用户的偏好,结合深度学习技术破除跨域推荐的数据稀疏性影响;但是,大部分算法是从某个用户角度出发进行跨域推荐的,这对于冷启动问题的解决产生一定的限制。 Goodfellow 等提出的GAN(generative adversarial networks)是对抗学习的代表方法之一,其核心结构由生成器G 和判别器D 组成,G 用于生成最接近真实数据的虚假数据,D 则试图完美区分真实数据和“逼真”的虚假数据,通过D 和G 的博弈对抗达到两者都可学习到最理想的输出的效果。基于对抗的深度跨域推荐算法是将GAN 融入到跨领域推荐中解决跨域推荐中特征的领域适应问题。其中对抗学习的思想主要体现在三方面:(1)借鉴GAN 中最大-最小博弈的对抗式目标函数优化模型参数;(2)借鉴其生成模型-判别模型对抗式结构设计网络模型;(3)对抗式网络训练。 Wang 等[59]提出第一个基于判别对抗网络的跨域推荐算法RecSys-DAN(discriminative adversarial networks for CDR)以解决单模态和多模态下的数据稀疏和数据不平衡问题。不同于标准GAN 只有一组G和D,该算法在源域和目标域中分别设定一组生成器,在目标域中设定一个判别器D f,其中k∈{s,t} 代表{源域,目标域},i∈{u,v,f}代表{用户,项目,用户与项目的交互}。G 用于从已知的数据中完美地学习到各域内用户和项目的隐含特征表示,D 则要学习一个映射函数,使得尽可能多的目标域特征可由源域特征经过映射近似表示,实现域间的特征的跨域对齐,为此和D f的学习函数设定如下: 特别的,在本算法中用户和项目的交互即为用户对项目的评分Y,;由于源域中已知评分情况,故源域的生成器G 以监督学习方式得到相应的特征表示。Yuan 等[60]则将判别器-生成器结构作为基本框架提出一种基于深度域适应的跨领域推荐方法(deep domain adaptation cross-domain recommendation,DARec),模型结构如图6 所示。两个自动编码器分别从源域和目标域的稀疏评分矩阵中提取用户偏好特征,并以此作为交叉嵌入模块的输入,经交叉嵌入模块的作用将域间用户偏好特征充分混合后输入到对抗结构中,联合完成评分模式提取、评分预测以及域分类,最终实现跨域评分预测。考虑到推荐场景不同会影响推荐结果的精准性,DiscoGAN[61]将时间和所处场景作为考量维度之一融入到GAN 中,以对抗训练的方式学习场景特征向量,实现在不同时间场景下服装的智能化推荐。 Fig.6 Model of U-DARec图6 U-DARec 模型 基于对抗的深度跨领域推荐算法将对抗学习思想融入到了跨领域推荐中来,通过设定不同的生成器和判别器达到预测目标用户的评分情况,算法的可解释性有了一定的提升,但是由于GAN 固有局限性使得该类算法的稳定性有待进一步研究。 传统跨域推荐算法大都是采用两段式学习方法,而深度跨域推荐算法由于其采用不同的深度学习技术,因此大多数算法模型是“端到端”的,实时性相对较高。两大类算法解决问题的方法各有侧重,传统跨域推荐算法以矩阵分解或张量分解作为基准模型,可解释性相对较高,评分信息利用较为充分,评分的准确性以及稀疏性对推荐结果的影响较大,忽略了非线性特征的提取和利用;深度跨领域推荐则将各种有效的深度学习方法应用到跨域推荐中,相交于传统跨域推荐具有以下几点优势:(1)可学习更多层次的非线性特征,而这些特征往往是低维的;(2)无需通过复杂的计算提取特征,可以借助于DNN(deep neural networks)、注意力机制、图神经网络等方式实现;(3)部分算法更加关注于高阶复杂的用户行为关系的抽取,更全面地表述用户特征。 不同的知识迁移场景以及依赖数据类型会对算法的有效性产生影响。表3 和表4 从定性角度分别从迁移技术、依赖数据类型、基础模型、算法适用性及重点解决问题几个方面对传统跨域推荐算法和深度推荐算法进行总结,并指出各类算法的优缺点;同时,为增加算法间的宏观可比性,增加各算法的定量分析,总结如表5,同时本文中对当前主流的跨领域推荐算法的评价指标进一步的总结如表6。 从表3 和表4 各类算法模型的依赖的数据类型角度来看,传统跨域推荐算法以用户对项目的评分为主,辅以添加部分用户侧属性和项目侧属性信息,特别是基于评分模式和基于隐含特征映射两类跨域推荐算法大部分都是以评分数据为基础,利用矩阵分解或者张量分解为基本模型,目标域的数据的稀疏性对算法模型的性能影响较大;而深度跨域推荐算法则是重点从用户项目侧属性信息以及用户与项目的交互信息中挖掘用户的兴趣偏好,这也使得整个深度跨域推荐中领域间用户的依赖程度较高。 与模型依赖数据直接相关的便是各类算法模型对用户特征的描述能力。当前的跨域推荐算法主要通过以下几个方法完成数据用户特征的提取:(1)用户与项目的交互信息、用户间的社交关系等显示反馈信息;(2)用户侧属性信息和项目侧的属性信息等辅助显示信息;(3)用户的隐式反馈信息,如用户的浏览序列。由于用户显示反馈信息以评分信息为主,该类信息具有线性性,基于矩阵分解的算法对该类数据的利用率较高,但是由于其固有条件的约束,这类算法只能挖掘用户的线性特征,而实际情况下用户的非线性特征偏好往往包含更多的可用信息,这也是深度跨域推荐算法产生的原因。从表4 总结可以看出,无论是基于隐含特征映射、基于网络和实例的深度迁移还是基于对抗的深度迁移都主要依赖于隐式反馈信息提取用户的非线性偏好,为全面提取非线性特征同时增加数据的利用率,ACDN 从图片特征中提取用户的高维审美偏好作为整体偏好特征的补充,SARFM 从评论文本中提取用户的特征偏好。从整体上看,由于深度学习在非线性特征的学习上的优越性使得深度跨域推荐算法在用户特征的描述以及提取能力上明显高于传统的跨域推荐算法。 Table 3 Summary of traditional cross-domain recommendation algorithms表3 传统跨领域推荐算法总结 Table 4 Summary of cross-domain recommendation algorithms with deep transfer learning表4 深度跨域推荐算法小结 Table 5 Comparison of experimental results of cross-domain recommendation algorithms表5 跨领域推荐算法实验结果比较 Table 6 Summary on use of evaluation indices of main cross-domain recommendation algorithms表6 主要跨领域推荐算法评价指标使用总结 从模型的适用条件上看,传统跨域推荐对域间用户的重叠程度依赖性低,甚至可以在用户和项目都完全无交集的情况下完成推荐,对用户的隐私保护有一定的考虑,这使得传统跨域推荐算法在现实条件下适用的范围更广,可方便实现跨系统推荐,甚至是跨媒体推荐;而深度跨域推荐则大都从某用户的角度出发,用户信息的跨域共享成为了推荐的重要条件,但是当前的方法基本是一个ID 即为一个用户,而“一人多账号”和“多人共用一个账号”问题较为常见,如何准确定位用户问题有待进一步的研究。 从各类算法重点解决实际问题角度来看,传统跨域推荐着重于数据稀疏问题的解决,少部分算法通过添加标签关系、用户社会关系等辅助信息在冷启动的条件下发挥作用(如CD-MDTF、KerKT、CDLFM、CDIE-C 等);而深度跨域推荐算法除了数据稀疏和冷启动问题以外,考虑解决现实推荐场景下的隐私保护、在线推荐和跨域推荐中的行为异构问题,这是因为深度学习技术对其输入数据的约束性较小。 算法模型的可解释性一直是推荐领域需要重点攻克的问题,跨领域推荐算法中亦然。由于传统跨域推荐算法以矩阵分解为基础模型,故此类算法主要通过概率矩阵分解角度增加其可解释性(如UPCDRSs)、引入概率图模型(如TRBT)和引入外部知识库(如社交关系、标签等)等方式提高推荐结果的可解释性;深度跨领域推荐算法则依赖于各种不同的深度模型,总结如表4。类似于传统跨域推荐算法,该类算法可从概率估计(如SSCDR、GCBAN 等)角度增加结果的可解释性,部分算法通过注意力机制对不同的项目进行加权选择以提取更加准确的用户偏好,提高结果的可解释性。除此之外,MTNet 引入记忆网络提取用户偏好特征的同时增加模型的可解释性。但由于端到端模型中间结果的不可见性增加了结果可解释的难度,更加有效的可解释性方法需要进一步探究。 从表5 可以看出,同一模型在不同的跨域场景下表现出来较大的差异性,这是因为不同场景下数据稀疏性不同,加之可用的辅助信息利用程度不同,也对推荐结果产生影响。同时可以看出,在相同条件下,深度跨域推荐的性能相对较高;当可用的辅助信息较多的时候,性能会有所改善;从表6 中不同算法模型验证实验评价指标的对比可以看出,常用的评价指标可分为评分预测类(以MAE(mean absolute error)和RMSE(root mean squared error)为主)和排序加权类(NDCG(normalized discounted cumulative gain)、MRR(mean reciprocal rank)、HR(hit ratio)等)两大类,主要用于衡量推荐的准确性。其中传统跨域推荐算法更加倾向于使用评分预测类指标,这与其主要依赖的数据类型是评分有关,部分算法由于依赖数据的多样性,同时采用预测类指标和排序类指标,试图全面评价模型。但是不同场景下模型的有效性还有更多可以探索的方面,因此如何有效地全面地对各算法模型进行横向的评价仍有待深入研究。 目前跨领域推荐算法作为解决推荐中的数据稀疏和冷启动的有效解决方法得到学术界和工业界的足够重视,是当前推荐领域的重点和热点研究方向之一。综合上一章的对比分析可看出,现有的跨领域推荐算法存在以下几点不足:(1)算法的适用性有限;(2)推荐结果的可解释性不佳;(3)数据本身挖掘不足,导致成本增加;(4)算法的评价指标单一。为此,本文总结以下几点可能的研究方向: (1)新深度跨领域推荐算法 跨域推荐涉及不同的推荐对象以及推荐场景,无法建立统一的推荐模型,需要根据推荐对象、可用信息以及推荐场景考虑构建各有侧重的推荐模型;再者,辅助信息来之不易,应当充分利用已获得的辅助信息(如时序关系、地理位置等),但目前此类信息利用尚不充足,需要研究更多的新的深度跨域推荐算法解决上述问题。 (2)跨域推荐的可解释性问题 跨域推荐算法除直接展现推荐结果外,还应适当给出推荐的理由,提升用户对推荐结果的接受度。一直以来,推荐系统的可解释性问题都是业界研究的重点和难点,对于跨域推荐亦然。传统跨域推荐算法利用矩阵分解来增加可解释性,但其限制性较大,推荐结果不能满足实际要求;而在目前的深度跨域推荐中,已知的仅是输入数据和输出结果,其中间过程的不可见性降低结果的可解释性,同时引入辅助域的合理性与否的可解释性亦不足,需要考虑从更多方面入手提高跨域推荐的可解释性。 (3)序列推荐与跨领域推荐相结合 一般来说,用户的消费行为之间总是具有某种隐含的因果关联,用户行为序列可有效建模此类关系,序列推荐算法可充分利用用户行为序列信息。但是,单域序列推荐常常对历史物品中选择合适的物品给出下一项推荐候选而无法推荐全新的物品,跨领域推荐作为提高推荐多样性和新颖性的方法可以有效地对单域序列推荐存在的问题进行补充,实现智能化的精准推荐。当前尚无此类研究。 (4)丰富跨领域推荐的评价指标 现有的跨领域推荐算法的评价指标沿用了传统推荐中对评分预测正确率、准确率等指标,基本没有涉及到新颖性、全面性和多样性方面的评价,虽然可以初步达到衡量算法性能的目的,但是相较于传统的推荐,跨领域推荐面临的问题更复杂,解决问题更多样,使用的数据集也不同,简单的评价指标无法全面对跨域算法进行评价。因此,提出新的跨域推荐算法的评价指标是必然之势。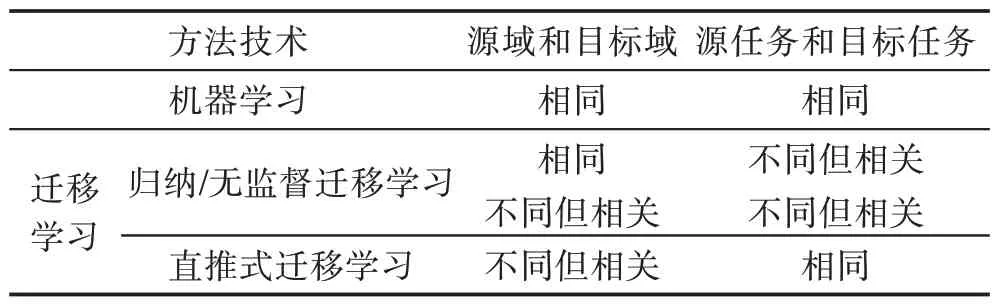

3 传统跨领域推荐算法
3.1 基于评分模式共享的跨域推荐算法



3.2 基于隐含特征映射/转换的跨域推荐算法
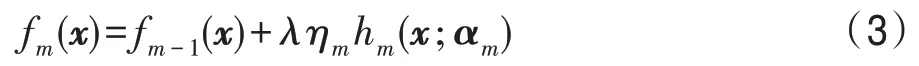

3.3 基于域关联的跨域推荐算法


4 深度跨域推荐算法
4.1 基于特征映射的深度跨域推荐算法

4.2 基于网络/实例的深度跨域推荐算法


4.3 基于对抗的深度跨领域推荐算法

5 跨域推荐算法模型比较分析



6 研究趋势与展望
