线上多节点日志流量异常检测系统的研究*
2020-11-15王晓东赵一宁肖海力王小宁迟学斌
王晓东,赵一宁,肖海力,王小宁,迟学斌
1.中国科学院 计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
1 引言
中国国家高性能计算环境是由国内众多超算中心和高校的计算集群组成的国家级大型高性能计算环境,采用中国科学院计算机网络信息中心自主研发的网格环境中间件SCE[1]聚合了大量的通用计算资源,为全国众多高校和研究机构的用户提供了优质的计算服务。环境中Linux 系统的syslog 服务会产生大量日志,用于记录系统中发生的各类事件信息,这些信息包含各种潜在的异常情况,对其进行分析具有重要意义。由于环境中的每个节点都会产生大量的系统日志,这使得最终的日志文件变得极为庞大,直接采用人工观察的方法处理这些日志显然是一项不可能完成的任务,因此需要使用一些机器学习方法对环境中的日志进行检测分析。
基于机器学习的检测分析技术主要分为两大类:误用检测和异常检测[2]。误用检测属于机器学习中的有监督算法,建模时需要人工将所有训练样本标记为“正常”和“异常”后才能进行学习训练并更新模型参数。异常检测属于无监督学习算法。其主要思想是根据已知的大量数据建立模型基线,然后找到偏离模型基线的少量数据作为异常。大规模分布式环境中多节点产生的日志比较复杂,因为这些日志通常是开发人员为了开发方便而打印的一些原始想法,其中包括错误、跟踪和程序内部状态等信息,因此利用这些信息是非常困难的。同时这些信息都是非结构化的,不利于机器识别。此外,日志的数据量非常庞大,人工标注后再使用机器学习方法进行分析显然是难以完成的任务,因此使用无监督的异常检测方法较为合适。在先前的工作中已经初步实现了使用机器学习算法对环境中的日志流量进行检测,然后针对异常日志流量进行聚类。然而该方法属于离线算法,并且在异常结果分析时使用的聚类算法需要人工参与并设定聚类参数,而本文方法在建模时可以更加精细地自动化确定模型参数,并更进一步探索如何进行模型持久化以及如何进行线上检测。
系统的整体流程除了设定少量阈值以及流量模式的定义需要人工参与外,得到异常日志流量模式的过程全自动化进行,并且在线上检测时也能自动化得到异常结果并将其进行分类归纳,这样使得系统管理员对系统日志流量的监控变得简单。具体来说,本文有两个贡献点:
第一,实现了两阶段异常检测的方法,包括线下模型自动化建立和线上实时结果分析。在线下模型建立的过程中无须人工参与即可找到流量异常情景。在线上分析时,可将结果实时自动化展示。整个处理过程对操作者的要求不高,进行检测时不需要有机器学习的专业知识。
第二,在线下建模和线上预测时使用了国家高性能计算环境中产生的真实日志进行实验,实验结果证明了该方法显著降低了人工分析的工作量。
2 相关研究
本章简单讨论一下日志模式分类、数据挖掘相关的日志分析以及在线日志分析的相关研究。
2.1 日志模式分类方法的相关研究
Vaarandi[3]在对日志文件数据进行模式分类时使用了一个名叫SLCT(simple logfile clustering tool)的聚类算法,该聚类算法是基于Apriori 频繁项集的算法,因此需要使用者手动输入调整支持阈值。之后,他又在文献[4]中改进了日志的聚类算法,并取名为LogHound,该算法是一种基于广度优先搜索的频繁项集挖掘算法,可以从日志中挖掘频繁模式。该算法结合了广度优先和深度优先算法的特点,同时考虑了事件日志数据的特殊属性,因此比SLCT 更接近地反映Apriori 算法。在此基础上,Makanju 等人[5]引入了IPLoM(iterative partitioning log mining)算法,该算法是一种用于挖掘事件日志簇的新算法。与SLCT 不同,IPLoM 是一个层次聚类算法,它以整个事件日志作为分析起点,并在三个步骤中迭代分区。与SLCT 类似,IPLoM 将单行日志中的位置视为单词匹配点,因此对单词位置的移位操作敏感。基于层次聚类的特点,IPLoM 算法不需要提供支持阈值,而是需要其他一些参数(如分区值和簇优度值),这些参数对分区的划分进行细粒度的控制。IPLoM相对于SLCT 的一个优点是能够使用尾部通配符(例如Interface**)来检测日志的行模式。而本文在处理日志模式分类时,考虑线上分析的实时性,匹配时需要快速得出结果,因此这里采用基于字符匹配的分类算法,之后针对国家高性能计算环境的系统日志进行分类,代码压缩率和后续特征创建都显示出了不错的效果。
2.2 数据挖掘技术相关的日志分析研究
一些学者在分析日志并寻找异常消息的领域进行了研究,比如Xu 等人[6]通过源代码匹配日志的模式,找出相关变量,然后通过匹配日志模式,找到其中变量并使其作为主成分分析方法的输入数据,最后根据主成分分析的最大可分性检测异常的日志文件。Fronza 等人[7]使用随机索引为代表的日志序列,根据每条日志中的操作提取特征,然后使用支持向量机关联序列到故障或无故障的类别上,以此来预测系统故障。Weiss 等人[8]研究了从有标签特征的事件序列中预测稀少事件的问题,他们使用了基于遗传算法的机器学习系统,能够在预测稀有任务上达到比较好的结果。Yamanishi 和Maruyama[9]提出了一种新的动态系统日志挖掘方法,以更高的置信度检测系统故障,并发现计算机设备间的连续报警模式。Yuan 等人[10]提出了一个名为Sher-Log 的工具,它利用运行时日志提供的信息来分析源代码,以推断在失败的生产运行期间必须或可能发生的事情,它不需要重新执行程序,也不需要知道日志的语义即可推断关于执行失败的控制和数据值信息。Peng等人[11]应用文本挖掘技术将日志文件中的消息分类为常见情况,通过考虑日志消息的时间特性来提高分类准确性,并利用可视化工具来评估和验证用于系统管理有趣的时间模式。本文中使用Xu 等人[6]描述的异常检测方法,但是输入的日志类别是通过字符匹配得到的,同时研究对象为日志类型的有序排列,在得到未知的异常日志流量模式上更有优势。
2.3 在线日志分析的相关研究
典型的在线日志分析程序通常基于控制台日志或者安全审计日志等进行分析。比如文献[12-13]中进行的在线日志分析研究程序,它们通过手动输入如正则表达式这样的规则来匹配待分析日志中的对应字符串,通过这种方式就可以找到需要关注的日志条目。然而这种手动输入规则的方式,处于线上运行时,可能会经常更新软件或者模型基线,这样会使得每当需要更新的时候,都需要人工重新编辑规则匹配新出现的日志条目。而本文在日志分析处理的整个流程中,完全使用无监督的方法建立日志模式库和异常模式库,线上分析时采用间隔一段时间就自动更新模型的方式进行诊断,这样可以保证模型具有时效性。同样的,日志模式匹配时也不需要人工参与编写任何规则。
3 两阶段线上异常检测方法
3.1 线下数据处理
本节回顾了日志预处理的步骤并重点分析模型建立时需要持久化的数据,这些数据是线上分析时的基础。整个线下数据处理过程分为:预处理、异常检测模型的建立与异常流量序列聚类、日志流量模型的建立三部分,下面分别详细介绍。
3.1.1 日志数据预处理
Syslog 系统日志属于非结构化数据,为了后续使用各种机器学习方法进行分析,必须要将这些数据转换成可以进行处理的结构化数据,在实践中,需要将日志进行分类,即每一条日志都可以确定成唯一的一种类型,这就要求能得到一个日志仓库,里面存储所有已知的日志类型。生成日志仓库的核心是如何判定两条日志是否属于同一类型。判定日志类型时,为了使判定过程实时快速,Zhao 等人[14]提出了字符匹配法来确定两条日志的相似度,并且在文献[15]中改进了该算法。算法将日志中的每一个单词作为一个基本单元,然后对其进行匹配,并基于最长公共子序列得到匹配的单词数目,最后与两条日志的总单词数进行比较来计算相似度。具体来说,假设待匹配的两条日志分别为l′和l,其包含的单词数量分别为m和n,则两条日志的相似度的计算公式如下:

其中,|LCS(l,l′)|代表两条日志最长公共子序列匹配的单词数。比如以下三条日志:
l1:Received disconnect from IP1
l2:Received disconnect from IP2
l3:Accepted publickey for User1 from IP3
设阈值为0.5,其中l1 和l2 这两条日志的前三个字符相匹配,后一个字符不匹配,因此根据式(1),可以计算得到S()l1,l2=3×2/(4+4)=0.8 >0.5,说明l1、l2 为同一种类型的日志,同理可以计算出l1 和l3 这两条日志的相似度S(l1,l3)=0 <0.5,说明l1、l3 为不同类型的日志。
在实践中,遍历所有线下日志,然后和日志仓库中的每条日志进行相似度计算,如果得到的相似度大于给定阈值,则认为日志仓库中已存在该类型的日志并进行下一条日志的比较,否则将这条日志加入到日志类型仓库。为了进行线上模型预测,将这一步算法完成后得到的日志类型仓库保存下来,并记作Pattern。
得到日志类型仓库后,即可进行日志数据的预处理工作。实际操作时,将日志流量的监控确定在一个固定的时段内,因此输入到异常检测模型中的基本数据单元是以时间片进行切分的,将单个时间片内顺序出现的所有日志称作“日志流量序列”。将流量序列中的每条日志和日志仓库中的日志类型进行匹配,可以得到一条以日志类型为属性的向量,向量的每一个位置的数值代表该条流量序列中对应类型日志出现的次数。该日志流量序列向量组生成后即完成了预处理步骤。整个日志预处理流程如图1所示,图中右下角的表格即预处理步骤完成后输出的数据表。
3.1.2 线下异常检测模型的建立与异常流量序列聚类
主成分分析(principal component analysis,PCA)是一种常用的机器学习算法,该算法可以自动找到数据的比例中心,该中心代表数据的正常空间。在建模阶段,首先将3.1.1 小节得到的日志流量序列向量组作为输入数据,设输入数据组成的矩阵为P,则使用PCA 异常检测模型的目的是捕捉到转换矩阵PPT中的主导模式,该模式可以计算出所有流量数据中的异常流量序列,具体比较方式是计算出每一个流量序列到正常空间的距离,该距离越大,则代表这条流量序列更可能是一个异常。该距离的阈值使用文献[6]中提出的Qα,该阈值即表示1-Qα置信水平下的SPE残差函数公式。在建模阶段,需要得出线下数据的异常流量序列向量,因此需要计算每条日志流量序列到正常子空间Sd的距离,该距离通过ya=(1-PPT)y计算,如果SPE=|ya|2>Qα,则标记该条流量向量是异常的。为了进行线上模型预测,在这一步计算完成后将建立好的模型矩阵P以及异常判定分位点Qα保存下来。
根据历史数据建立完成异常检测模型后,可以初步筛选出异常的流量序列,但是这些序列直接进行人工识别仍然会存在问题,因为每条流量序列都包含多条日志以及各个节点的信息,这些日志流量代表的异常应该进一步聚类,以便人工分析。日志的流量实际上代表不同日志事件按顺序出现,因此继续使用最长公共子序列进行两条流量信息的相似度判定,只不过这次对比的最小单元是一种日志类型。这也符合实际的问题设置,因为不同日志按照顺序出现恰好是一种异常流量模式的体现。比如单独出现一次T4(认证失败)类型的日志,可能是由于用户不小心密码输入错误引起的。但是如果在一定的时间片内,同一个主机频繁出现T4(认证失败)类型日志、T10(密码错误)类型日志、T0(连接断开)类型日志,则说明该类型序列可能是一种暴力破解密码进行登录的尝试。
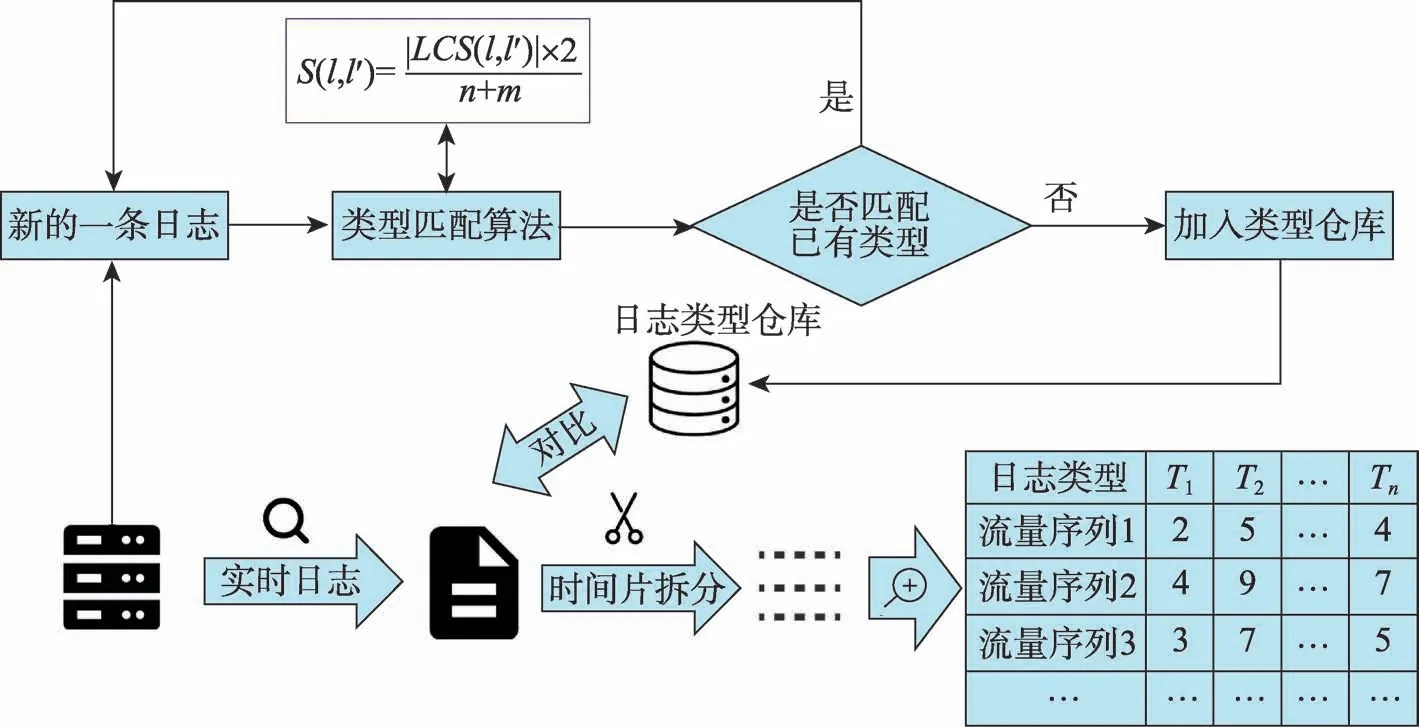
Fig.1 Flow chart of log preprocessing step图1 日志预处理流程图
基于以上考量,最终确定两条日志流量序列的相似度计算公式如下所示:

其中,|*|代表类型序列* 的长度,S1和S2分别代表两个待比较流量序列,S代表这两条流量序列的最长公共子序列,比如图2 所示的两个日志流量序列S1=[T7,T11,T3,T2],S2=[T7,T11,T5,T6,T2]。则可得|S1|=4,|S2|=5,|S|=3,最后根据式(2)可计算出两条日志流量序列的距离是d=3。
根据以上的距离计算公式,可以使用聚类算法对异常流量数据进行聚类,最终可以将所有异常序列分成几个小类,以便后续分析。
3.1.3 线下日志流量模型的建立
第3.1.2 小节介绍了如何将日志流量信息通过无监督机器学习方法进行异常筛选和聚类分析,最后将所有异常流量序列分成几个小类。然而在实践中,不可能将所有异常流量序列都保存下来,因此本小节需要对每一类异常流量序列进一步分析,并为其找到一个代表性流量序列,以便对该数据进行持久化从而可以在后续线上运行时进行异常流量序列的匹配。
在对每一类异常流量进行分析时,考虑到流量本身是一个序列性数据,为了能将单条流量数据映射到向量空间,需要将序列数据转换为数量数据。在实际操作中,直接使用每条流量数据中每种类型日志出现的次数作为其数量化的结果,然后将所有流量数据都抽象成其数量化的结果并做成表格,如图3 左上角所示,其中每一行代表一条流量数据,每一列代表该类型日志出现的数目,该表格整体代表上一小节中分好类的其中一类异常流量数据的总体。下一步首先计算出表格中各个日志类型的平均值,然后遍历该类型流量序列的所有数据,计算每一个流量序列与平均值序列的距离,此时的距离公式可以直接使用欧几里德距离。最后找到该距离最小的那条流量序列作为该类流量序列总体的代表。通过以上步骤得到的流量序列代表既满足数量上靠近平均流量值,又满足序列上的顺序对应,因此结果满足了问题设定,总体流程如图3 的上半部分所示。
在得到一类异常流量序列的代表后,按照上一小段介绍的方法循环所有异常流量序列类,最终就能为每一种异常流量序列类都对应地找到一条流量序列代表,整个流程图见图3 的下半部分。之后即可将这些代表作为待匹配流量序列模式并保存,为后续线上异常检测提供基础。最终,为了进行线上模型预测,这一步计算完成后需要保存的数据是所有异常流量的序列代表集合Moed。
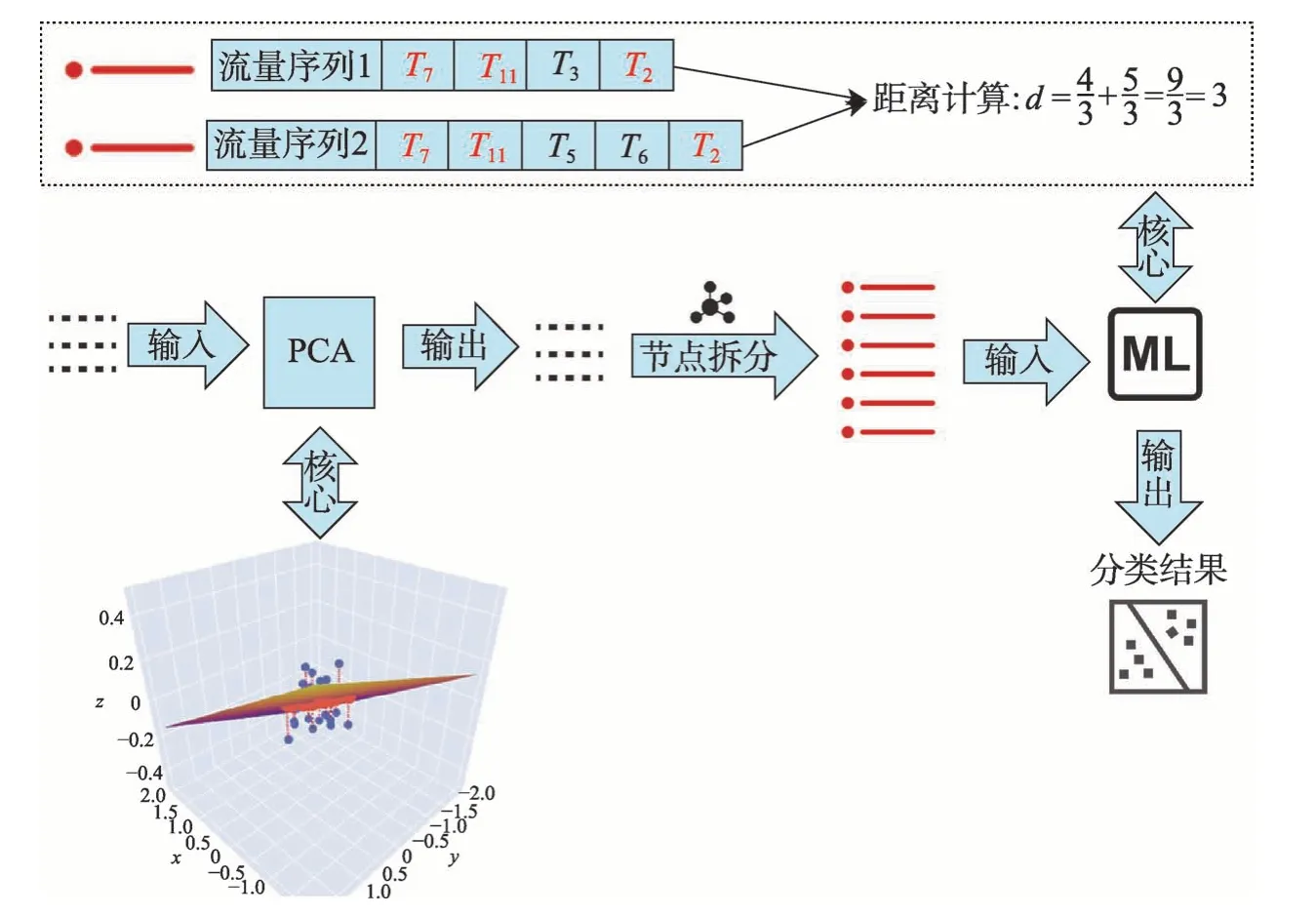
Fig.2 Flow chart of log flow anonymous detection and classification图2 日志流量异常检测与分类流程图
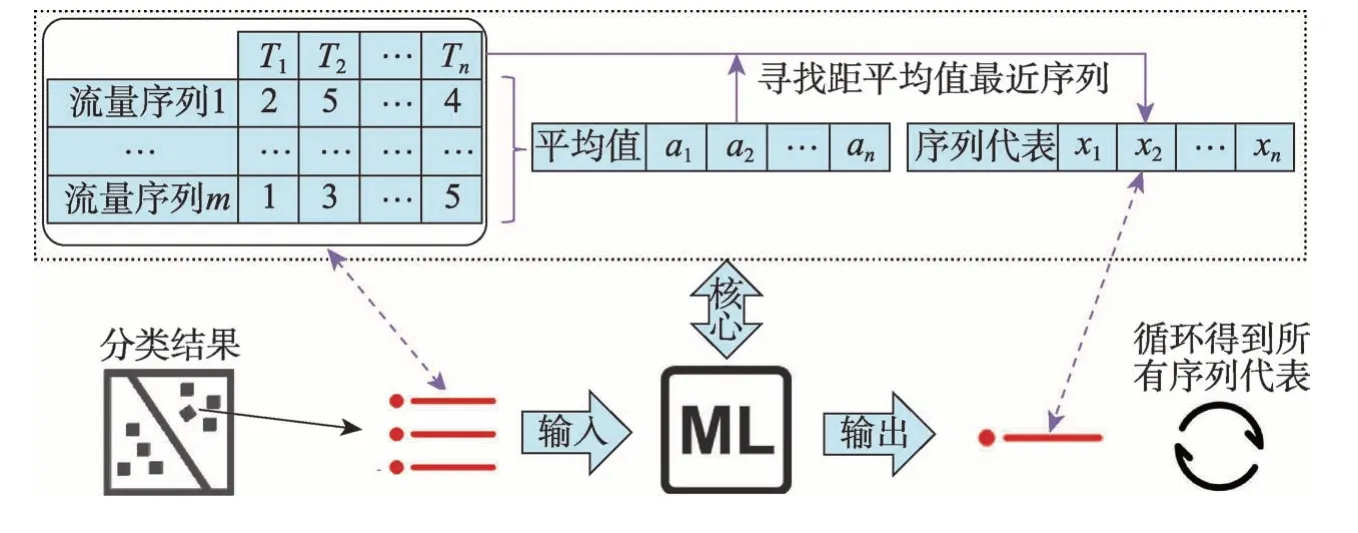
Fig.3 Flow chart of selecting logs for flow exceptions图3 流量异常代表日志挑选流程图
3.2 线上异常检测
第3.1节详细介绍了如何进行线下模型建模,表1展示了线下模型建立时得到的持久化数据。本节重点介绍如何进行线上实时预测并显示结果。在线上预测时可以分为两个阶段,预处理阶段和异常匹配阶段。

Table 1 Persistent data symbol,interpretation and corresponding sections表1 持久化数据符号、解释以及对应章节
3.2.1 预处理阶段
线上的流量检测是实时的,而在线下建立流量检测模型时用已经确定的时间片对日志进行分割,因此在线上流量检测时需要使用相同的时间间隔进行处理,这样才能保证线上检测时流量数据适合线下建立的模型。在这种情况下,按照3.1 节中建模时的时间间隔搜集日志数据并得到单个时间片内的所有日志后,还需要将其处理成适合模型的输入向量,该向量的每一个位置代表不同日志类型在该时间片内出现的次数,为了保证向量数据的一致性,日志类型的位置要与模型建立时日志类型的顺序一致。这里匹配单条日志的方法是将该单条日志与Pattern文件中的所有日志模式遍历并分别进行相似度的计算,计算公式见3.1.1 小节中的式(1),计算时如果相似度的结果大于阈值0.5,即将该日志作为此类型,并在向量的对应类型数据上加1,如果所有计算结果都不到0.5,则将计算得到的相似度最高结果对应的日志类型作为该条日志的实际类型。按照这样的处理方式,即可得到该时间片的日志流量向量,最后将预处理得到的向量设为V。
3.2.2 异常匹配阶段
在异常匹配阶段,首先读取线下建模时保存的矩阵P和阈值Qα,然后将3.2.1 小节得到的向量V与矩阵P进行异常分数的计算,即Score=(1-PPT)V。该异常分数和阈值进行比较即可得出此流量是否异常,即如果Score>Qα,则认为该流量时间片为异常。
另外,每一个流量序列还需要和实际的异常模式进行对比,来确定异常的种类。在实践中,先将该条流量序列的所有数据按照节点分开,然后将得到的每一个节点的流量序列数据分别和流量模式文件Moed中的每个流量序列模式进行匹配,匹配时使用式(1)进行计算并得到单个节点在该时间片的流量和每种异常流量的相似度,然后将结果保存。在进行异常评价时,使用其中相似度最大的结果并记作Score。
目前已经得到了线上诊断时一个流量时间片所需的所有数据:单个流量时间片的异常分数Score和阈值Qα,该流量时间片内所有主机对应的异常相似度列表以及其中最大的相似度Sim。最后需要将这些结果进行叠加并能够清晰地展示给相关运维人员,具体细节将在下一章的实验部分介绍。
4 实验结果与分析评价
本章将第3 章介绍的方法用于国家高性能计算环境系统在实际工作中产生的系统日志中。选取系统日志的secure 类别日志作为实验数据。在第一阶段使用了2018 年9 月的日志数据进行线下模型的建立,并得出异常基线以及异常流量模式数据,在第二阶段将2018 年10 月的日志作为线上测试数据,进行实际的流量分析诊断,下面详细介绍实验结果。
4.1 日志异常检测和筛选的分析评价
在使用日志数据进行线下模型建立时按照3.1节所描述的方法进行,首先计算出各个时间片的Q值,然后和模型的阈值Qα比较,如果大于阈值则认为该时间片是异常时间片。各个时间片的Q值和阈值Qα如图4 所示。

Fig.4 Q-value and threshold Qα of secure logs图4 secure类型日志的Q 值和阈值Qα
从图4 可以看出,异常类型时间片均匀地分布在整个日志周期的时间片内。得到所有正异常流量时间片后,还需要进一步过滤,具体的做法是首先统计出正常、异常时间片中不同类型日志出现数量的分布,计算出其对应正常、异常日志和出现数量的中位数来进行后续比较。根据比较的差值来得出正常、异常时间片主要差异的日志类型。通过该差异进行了过滤。最终统计得出了一共有8 134 个时间片段,挑出了908 个异常时间片段,时间片按照节点拆分后得到了16 240 条异常节点的类型序列,过滤后有676条异常节点的类型序列。
4.2 日志层次聚类和关键类型挑选的分析评价
在本节中,将4.1 节得到的大量异常日志流量序列按照3.1.2 小节的方法进行层次聚类的相关实验。在进行层次聚类时,需要根据聚类结果的好坏来调整聚类参数,因此这里首先要选择一种判别聚类方法性能的评价指标,由于应用的场景是高性能计算环境中的日志,数据量大并且模型每隔一段时间都需要更新重建,因此无法事先人工打好聚类标签,整个过程需要使用完全无监督的方式进行。考虑到上述因素,这里选择使用适合于无监督的聚类评价方式,轮廓系数(silhouette coefficient)法[16]。该方法结合内聚度和分离度两种因素,其中轮廓系数得分较高的模型具有较好的聚类性能。单个样本的轮廓系数计算公式如下:

其中,a代表样本与同类数据中所有其他点之间的平均距离。b代表样本与下一个最近聚类簇中所有其他点之间的平均距离。最终整体的轮廓系数是计算出所有样本的轮廓系数后取平均值得到的,因此轮廓系数得分越高,说明此时的聚类结果使得同一种类之间聚集得比较紧密,同时不同的类之间聚集得比较远,因此可以判定此时的聚类效果较好。
在使用层次聚类时有三个关键参数需要定义:(1)不同数据之间的距离度量方法;(2)不同簇之间的距离度量方法;(3)最终的聚类数目。不同数据之间距离定义按照3.1.2 小节的式(2)进行计算。不同簇间距离度量方法具有三种不同的选择,分别为:平均距离标准方法(average)、最小距离标准方法(single)和最大距离标准方法(complete)。在对聚类数目进行选择时,考虑到聚类的数目不能太多,因此就将实验区间定义为3 到30种聚类数目。按照上述描述的结果,分别对不同的情况进行聚类实验,并计算出对应聚类结果的轮廓系数。最终实验结果图如图5 所示。
如图5 所示,横坐标代表不同聚类数目,纵坐标代表轮廓系数值,3 条折线代表不同的簇间距离度量方法。根据实验结果,程序可以自动选择对应最佳的参数。例如实验中使用的线下数据最终的最佳参数是:聚类的簇间度量方法是最大距离标准方法(complete),聚类数目是3。根据上述参数,程序最终进行聚类后显示出3种异常情景:
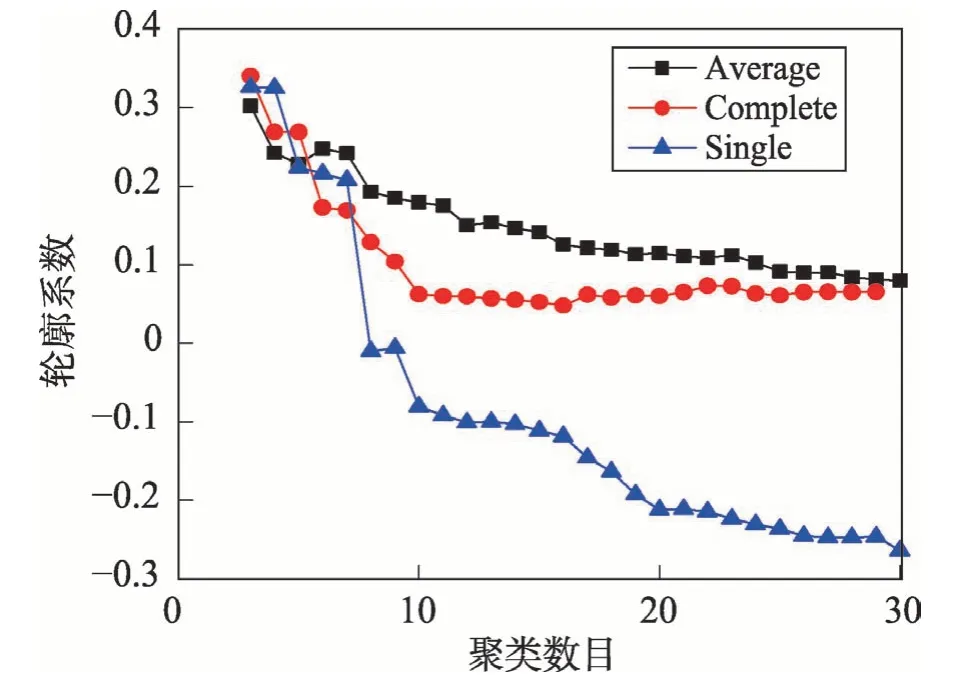
Fig.5 Silhouette coefficient for different parameters图5 不同参数对应的轮廓系数值
情景1 该情景下出现最多的日志类型是T10(failed password for invalid user User0 from X.X.X.X port XX ssh2)和T4(pam_unix(sshd:auth):authentication failure; logname=uid=0 euid=0 tty=ssh ruser=rhost=X.X.X.X)。该种异常日志流量模式表明此时间段内可能有人进行暴力入侵系统的行为。
情景2 该情景下出现最多的日志类型是T14(sshd*pam_unix(sshd:session):session opened for user User1 by (uid=0))和T13(sshd*Accepted publickey for User1 from X.X.X.X port XX ssh2)。该种异常日志流量模式表明此时间段内出现大量登录的行为,说明该段时间为用户访问高峰。
情景3 该情景下出现最多的日志类型是T39(sshd*error:no more sessions)和T0(sshd*Connection closed by::1)。该种异常日志流量模式表明该时间段内建立用户会话数量超过限制,可能需要人工干预。
分别将这些情景定义为非法用户攻击、用户访问高峰、会话数超限,并将这些模式结果保存。
4.3 线上异常检测实例对比分析
在实践中已经完成了线上异常检测程序的整体搭建与运行,整个流程分为两个阶段。
第一阶段目标是完成线上日志的类型解析,该阶段需要在程序中输入线下模型日志的路径和线上待分析日志的路径,然后才能进行解析,已经完成了该阶段的界面输入以及正确的日志解析结果,如图6所示。解析完成后就得到了待分析日志按时间片拆分后的日志类型序列。
第二阶段需要完成的工作是待分析日志的实时预警以及分析结果的可视化展示。在3.2.2 小节中,已经构建好了异常实时监测模型并计算出异常结果Score、Qα以及Sim,为了将这些异常结果利于可视化展示,需要将结果进行合并,其中异常流量的结果可能会超过异常值比较多的比率,因此在计算时使用比值的方式,即Score/Qα,而异常相似度的Sim本身的值在0 到1 之间,因此可以直接乘以流量的异常来表示在该流量异常的情况下节点的流量为对应异常模式的可能性。最终,确定的异常分数计算公式如下:
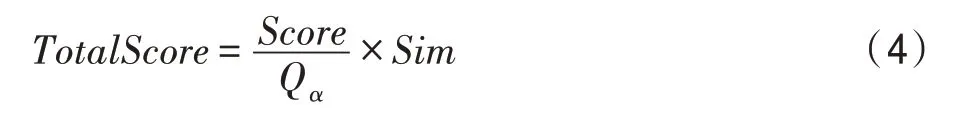
通过式(4)进行流量分数的计算并将该值的大小进行可视化展示,其中颜色越深代表该值越大。其中一个时间片内异常的分数如图7 所示。

Fig.6 Parsing of online code图6 线上代码解析
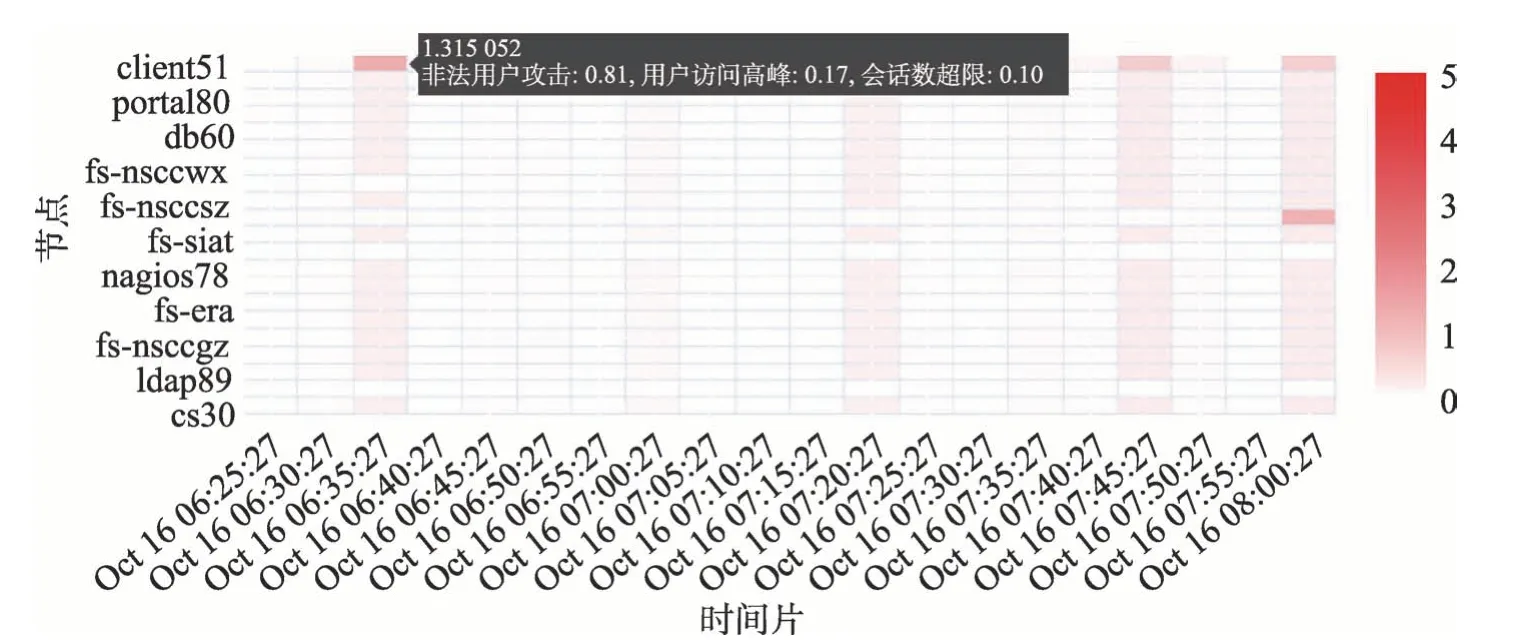
Fig.7 Anonymous score图7 异常分数
图7 的横坐标代表不同的时间片,纵坐标代表不同的节点。该图在实际运行时会根据时间流逝动态地向左运动,这里仅截取一小部分作为代表。如图7所示,线上检测时根据式(4)计算出的各个时间片的异常分数值可以明显地展示出来:如果该时间片的流量有异常,则整体都会显示出深色,其中和异常流量模式匹配的相似度最高的节点颜色最深。此时如果点击该节点的时间片,则可以显示出各种异常流量相似度的具体信息,如图7 中左上角的黑色框所示。然后系统运维人员还可以进一步调出该节点在该时间片内的所有日志,通过真实日志的跟踪显示给出进一步分析。该可视化的结果以及异常情景的自动化匹配大大减少了人工工作量。在实际工作中,由于模型是根据历史数据训练并构建的,在进行检测时可能出现新的异常流量模式,因此采用的策略是间隔一段时间使用新搜集的数据进行模型的迭代更新。
该系统已全部搭建完成,并已在网上(http://114.115.172.217/online)公布了示例程序。
5 结束语
本文介绍了一个无监督异常检测系统,该系统自动挖掘系统日志的异常日志流量模式。系统的整个流程可以自动找到系统日志的异常时间段,并得到时间段内不同节点的日志序列。该序列通过进一步聚类可以自动得到异常情景模式序列并保存,之后还可以在线上实时进行检测,最终检测的结果可以实时显示,使得系统运维人员可以方便地进行分析。
本文只是针对单一日志异常流量进行了一些前期探索工作,未来还有很多值得关注的研究点。今后的工作主要针对以下几个方面:不同种类的日志,通过不同种类日志的关联关系进行分析,以找到更全面的异常日志流量模式;基于日志类型序列的角度进行更多不同维度的日志分析方法研究,例如日志类型序列的关联性分析等。
