基于数据隐私保护的(L,K,d)算法
2020-10-23康茜晏慧雷建云
康茜,晏慧,雷建云
(中南民族大学 计算机科学学院,武汉 430074)
目前数据共享时最需要解决的问题是保护个体的数据隐私.一方面,如果在发布共享时没有对数据进行加密保护,这将会对个体造成隐私困扰;另一方面,如果不对数据进行发布共享,这将不利于社会研究发展.如何在发布共享数据的同时对数据进行隐私保护成为众多研究者关注的问题.在发布数据时需要以牺牲数据精度为代价,给科研者提供较高的数据研究价值的同时,最大程度地保护个体的数据隐私.K-匿名算法[1]是一种早期提出的有效保护数据隐私的方法:将准标识属性进行泛化等处理,使得在划分的同一等价组内至少有K条不可区分的准标识属性.当攻击者想要通过已获得的数据表进行数据关联来获取个体隐私时,攻击者至少要排除掉K-1个元组.K-匿名算法的提出有效地抵御了来自攻击者的关联攻击,很大程度上保护了个体的隐私安全.但是,当同一等价组中的敏感属性值大部分相同时,攻击者即使无法确定具体元组也能知晓被攻击者的敏感信息,这就造成了个体的隐私泄露.L-匿名算法[2]的提出在一定程度上解决了同质攻击的问题:在满足K-匿名算法的同时,L-匿名算法规定同一等价组中至少有L个不同的敏感属性值.这在一定程度上抵御了同质攻击带来的隐私问题.然而,即使对数据进行了来自关联攻击和同质攻击的保护,攻击者也可能因为同一等价组中的某些敏感属性值具体语义相同而推理出个体在某个较小范围内的隐私.如:胃溃疡,胃胀气,胃结石等在具体语义上都属于胃病,攻击者即使不知道患者的具体病情也可以通过关联获知该患者患有胃病,在一定程度上个体隐私没有得到较好的保护.针对这种相似性攻击,已有研究者提出了(P,K,d)匿名算法[3]:在满足K-匿名算法的同时,该算法规定同一等价组中至少有p个满足d-相异程度的敏感属性值.(P,K,d)匿名算法的提出有效抵御了敏感属性值相似性问题,阻碍了攻击者获取被攻击者某一小范围隐私的途径.在这些算法的基础上本文做了一些改进,使数据达到更高的使用价值的同时对数据实施更有效的隐私保护,解决数据有效性和数据隐私保护两者的矛盾.个体的隐私不仅仅只有一个,针对多维敏感属性[4]的出现,本文改进了算法使之适用于多维敏感属性,从而保障了多维敏感属性的隐私安全.
1 相关概念
以表1为例进行相关概念的描述.
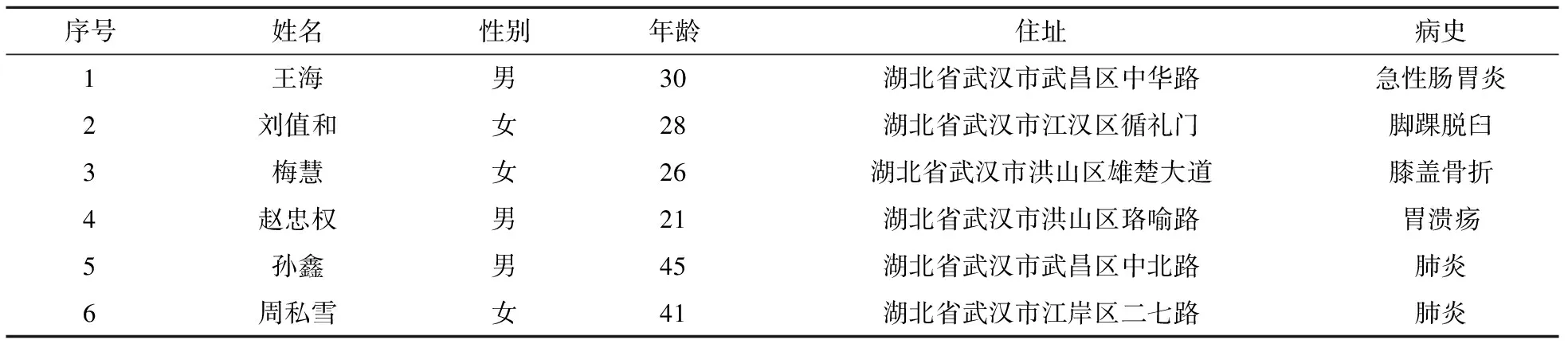
表1 原始数据表
定义1元组(tuple):数据表中的每一行即为一个元组.
定义2属性(property):数据表中的每一列都属于同一个属性.如{姓名},{性别}等.
定义3准标识符集(quasi-identifier attribute set):准标识符集是在一定程度上可以公布的、能够与外部的数据表进行联接来识别个体的最小属性集合.如表2中的属性集{性别,年龄,住址}即为一个准标识符集.

表2 删除标识符后的数据表
定义4敏感属性:数据表中的有些属性是个体本身比较在意的信息,不愿被暴露在公众视野之下,这些属性即为敏感属性,数据在被发布之前必须将这些信息保护起来以防隐私泄露.如表2 中的{病史}属性即为敏感属性,但是该敏感属性在某些研究领域是具有研究价值的,倘若在发布之前直接删除会导致数据的可用性大大降低.
表3为一张登记信息表,倘若攻击者从某些途径获取到该数据表,并将其与表2进行关联来获取被攻击者的个体信息[5],将会导致严重的隐私泄露.
定义5泛化:泛化是一种匿名化方法,它主要针对准标识符集进行操作,通过将准标识符集的具体值泛化为某一不确定具体值的值域,来达到防止攻击者通过准标识符集进行数据关联以保护被攻击者个体隐私的目的.表4是对表3进行泛化后的数据表.

表3 登记信息表

表4 泛化后的数据表
为了阻止关联攻击以防隐私泄露,要求在同一个等价组中的所有准标识属性都不可区分地相同.例如在对表4进行2-匿名处理后的数据表5中,记录1与记录2组成了同一等价组,该等价组中性别、年龄、住址是不可区分的.假若每个等价组中都至少有K条记录的准标识属性不可区分,则称该表满足K-匿名数据表.可知,如若每个等价组中的记录都只有一条,那么该表必然会遭受到关联攻击.

表5 K-匿名数据表(K=2)
定义6同质性攻击[6]:假若在同一等价组中的敏感属性值全部或者大多数都相同,在此种情况下,即使攻击者无法关联到具体元组也能获取被攻击者的隐私情况.例如序号5与序号6的敏感属性病史值都为肺炎,那么攻击者进行数据关联后将得知个体孙鑫和周私雪两人患过肺炎,这就造成了主体的隐私泄露.信息的有用程度不应以泄露个体的隐私为代价,应该以牺牲数据的最低使用价值为代价来保护数据的隐私安全.L-匿名算法要求同一等价组中的敏感属性都至少有L个不同的值,该算法的提出有效地解决了同质攻击带来的隐私保护问题.表6是对表5进行2-匿名处理后的数据表.

表6 L-匿名数据表(L=2)
定义7相似性攻击[7]:相似性攻击的攻击对象为同一等价组中语义相似的准标识属性值,如果数据保护者没有考虑到准标识属性的语义相似性问题,攻击者将会攻击到某一小范围的隐私.例如表6中的第一组等价组中的脚踝脱臼和膝盖骨折都属于骨科疾病,即使攻击者无法获知具体的疾病史也能了解到个体曾有过与骨骼相关的疾病史.后文有改进的算法来抵御相似性攻击.
在众多数据攻击中,背景知识攻击[8]是最难解决的,因为数据保护者无法得知攻击者已经掌握了哪些背景知识,无法有效解决隐私泄露问题.例如表5中的第一组等价组,假若攻击者通过数据关联来查询王海的隐私情况,又得知王海喜欢打篮球中间却有段时间没打篮球,那么就可以得知王海曾有过脚踝脱臼的病史.此种背景知识攻击是很难抵御的.
2 算法及改进
2.1 泛化层次树
如图1中的泛化层次树,采用泛化的思维来实施K-匿名算法,目的是以牺牲最低的数据真实度为代价来抵御关联攻击,通过泛化准标识属性值使之成为同一等价组.泛化会导致生成的准标识属性值与原始的标准属性值存在差异,从而使数据失真.数据泛化程度越高,失真度越大.为了使数据泛化时失真度尽可能小(即尽可能地保护数据的真实性和有用性),准标识属性值泛化为同一等价组时要求元组泛化后的距离[9]尽可能的小,即保障数据因泛化导致的失真尽可能的小.
两个准标识属性值(V1,V2)之间的相异程度(Distance)可以由它们距离其最小公共祖先结点Vm的距离的最小值来表示.即Distance(V1,V2)=min{level(V1)-level(Vm),level(V2)-level(Vm)},其中level表示准标识属性所在的泛化层次树中的层次数[10].例如:在图1的泛化层次树中,叶子结点(第4层为叶子结点)中的两个属性风湿病和关节炎其最小公共祖先结点为骨骼病变(第3层),那么这两个属性值之间的相异程度Distance=min(4-3,4-3)=1,两者属于同一类型疾病,相异程度很小,共同泛化后失真代价小;但是图1中的咽喉炎和关节炎的最小公共祖先结点为病史(第一层),两个属性值之间的相异程度Distance=min(4-1,4-1)=3,两者的相异程度极大,共同泛化后将导致巨大的数据失真,严重影响数据的研究价值.由此可见,如果准标识属性值离其最小公共结点越远,则属性值之间的相异程度越大,越不适合作为等价组来进行泛化.
2.2 元组之间的泛化距离
(1)在泛化层次树中并非每层的泛化程度都是一样的,层次树越高则泛化程度越大,数据失真度越高.故本文引入权重W来衡量准标识属性的泛化程度:假设某个准标识属性Vj从p层泛化到了q层(1≥p>q≥h,h为泛化层次树的高度),则W(p,q)=1/q.q值越小,泛化程度越高,权重越大,数据失真度越高[11].定义加权层次距离(Weighted Hierarchical Distance)如下:
(1)
例如属性风湿病从4层泛化到2层,j=3,则:
WHD(4,2)=(1/2+1/3)/(1+1/2+1/3)=0.45.
(2)所有准标识属性泛化后的加权层次距离之和即为元组t泛化后的距离:
(2)
(3)有些准标识属性在一定意义上是个体不愿意过度暴露的隐私,在保障数据的可用价值的同时,数据在发布时理应对其进行高度泛化处理来解决个体的隐私隐患.例如有以下元组:元组1住址为湖北省武汉市洪山区关山大道金地太阳城15号楼10-311.若元组1的住址属性只在相邻泛化层次树之间进行泛化(即p=q+1),则元组1的住址将会泛化为武汉市洪山区关山大道金地太阳城15号楼,此种程度的泛化结果是个体不愿意看到的,因为住址属性过于具体,很有可能给个体带来骚扰甚至安全隐患.针对此种情况,专门提出了一种新的元组泛化后的距离算法:
(3)
其中,当Vj为需要高度保护的准标识属性时(例如住址),则要求p>q+1(即该属性必须在泛化层次树上满足两层以上的泛化距离).
意义:新的元组泛化距离对某些准标识属性更有针对性,在加强了用户隐私安全保护的同时,又最大程度减少了数据泛化的失真度.
2.3 多维敏感属性d-相异度
相异程度(Distance)用来描述两个属性之间的相似程度.为了抵御由于敏感值属性相似造成的同质攻击和背景知识攻击,早期的(P,K,d)匿名算法已经很好地解决了这些安全问题,(P,K,d)匿名算法要求在满足K-匿名的条件下,同一等价组内至少有P个满足d-相异度的敏感属性值(此处的d一般大于1即可,即敏感属性值不属于同一层语义树即可)[12].但是此算法只适用于解决单维敏感属性相似性问题,而现实数据中往往会存在多维敏感属性相似性攻击问题,例如{职业,疾病,工资}会组成三维敏感属性,发布者必须同时保护这3种属性的隐私安全.在实际情况中各个维度的敏感属性隐私保护程度不同,需要加以区分.故此提出了多维敏感属性d-相异度的概念:在多维敏感属性中,由于不同维度的敏感属性所需要的隐私保护程度存在差异性,故需要根据实际情况取不同的d值,以此来约束各个维度敏感属性的泛化程度,从而满足不同维度敏感属性的隐私保护程度.d值越大,泛化程度越高,该敏感属性保护程度越高;反之敏感属性保护度越低.例如在三维敏感属性{职业,疾病,工资}中,工资和职业为一般保护的隐私,只需满足一般的d-相异度即可.而疾病涉及到个体的人身安全问题,个体最不希望将自己的病史公之于众,疾病这一敏感属性对于另外两维敏感属性来说更需要隐私保护.故取不同的d值来满足不同维度敏感属性的隐私保护度,d(职业,工资)=1,d(疾病)=2,故将d设置为2以此来提高敏感属性值间的相异程度,从而更好地防止多维敏感属性数据遭受攻击.
2.4 (L,K,d)多样化匿名算法
(L,K,d)多样化匿名算法要求在满足K-匿名算法的同时,在同一等价组中所有维度的敏感属性值至少都有L条不同的记录满足d-相异度.既保证了数据不受到关联攻击,又保障了不同维度的敏感属性不受到同质性攻击和背景知识攻击.
算法(L,K,d)多样化匿名算法
输入原始数据集S,等价类中不同属性值个数L,d-相异度
输出匿名表S′,S′中的每个等价组中至少有K个元组的准标识属性值不可区分,且同一等价组中所有维度的敏感属性都至少有L个值满足d-相异度
步骤
(1)由数据集S中生成初始等价组;
(2)循环,直至不存在元组个数小于K的等价组:
1)随机选择一个小于K的等价组C;
2)计算C与其他所有等价组的泛化距离:
3)找出距离C最近的等价组C′;
4)将C与C′泛化合并为同一等价组;
循环结束,得到K-匿名表T;
(3)循环,直至同一等价组中所有维度的敏感属性d-相异度个数都不少于L:
1)随机选择一个多维敏感属性d-相异度个数少于L的等价组A;
2)找出距离A最近的等价组A′;
3)将A与A′合并为同一等价组;
循环结束;
(4)返回匿名表S′.
3 实验
选取的实验数据集为UCI中的Adult标准数据集,该数据集中含有48842条有效数据,选取其中的5个属性进行实验:sex(性别)、age(年龄)、native-country(出生地)、marital-status(婚姻状况)、occupation(职业),具体属性情况如表7所示.实验将从信息损失数、隐私泄露概率两方面来比较已有的(P,K,d)算法和提出的(L,K,d)多样化匿名算法,并从信息损失度的大小和隐私泄露率的高低两方面来评估(L,K,d)多样化匿名算法.
如图2所示,横轴为K的不同取值,纵轴为信息损失数量.可以看出,当取相同的K值时,两种算法的信息损失度几乎相同.只是原有的(P,K,d)算法信息损失度相对较低,而提出的(L,K,d)多样化匿名算法信息损失度相对较高.这是因为(L,K,d)多样化匿名算法对某些重要的准标识属性增强了泛化程度来保护隐私属性(如表7中的属性3是个体希望加强保护的隐私属性),故使得信息损失度稍微增加.另外,随着K值的增加两种算法的信息损失度相继增加,这是因为K值增加使得同一等价组中的泛化元组变多,泛化次数越多则信息损失度越高.

图2 信息损失比较
如图3所示,横轴为属性,纵轴为隐私泄露概率.取3种属性来分别检测两种算法的隐私泄漏概率:native-country为准标识属性中的隐私属性,是个体在意的需要保护的属性;marital-status为敏感属性,且易受背景知识攻击;occupation为敏感属性,相对于marital-status个体更为在意,因此更需要隐私保护.对于第1种属性native-country:(L,K,d)多样化匿名算法相对于(P,K,d)匿名算法有很明显的隐私保护度,这是因为改进的(L,K,d)多样化匿名算法对该隐私属性进行了更强的泛化,更好地保护了该属性的隐私;对于第2种属性marital-status:两种算法的隐私保护度相差甚小,但该属性容易受到背景知识攻击,故隐私泄漏概率比occupation要高一些;对于第3种属性occupation:改进的(L,K,d)多样化匿名算法具有较高的隐私保护度,这是因为新算法对d-相异度做了改进,对于更需保护的敏感属性d-相异度取更大的值,故明显降低了该敏感属性被泄漏的概率.

图3 隐私泄露比较
从实验结果可以看出,(L,K,d)多样化匿名算法相对于传统的(P,K,d)算法而言,对数据具有更灵活的处理能力.首先,(L,K,d)多样化匿名算法将数据中的准标识属性进行了不同程度的泛化处理,以此提高了个别准标识属性的隐私保护程度,但在一定程度上降低了数据的可用性;其次,(L,K,d)多样化匿名算法提出的多维敏感属性d-相异度对不同维度的敏感属性进行了不同程度的约束,更加灵活地保证了数据的隐私保护程度的同时,又维持了数据的可用性.
4 结语
本文首先对已有的K-匿名算法进行了改进,通过控制泛化的程度来控制不同的准标识属性公开度,满足了个人对敏感准标识属性的隐私保护,以此来提高病人的隐私保护程度;其次对(P,K,d)匿名算法进行了改进,通过控制不同的d-相异度来保证个别重要敏感属性的隐私保护,改进后的算法不仅适用于抵抗单维敏感属性中的同质性攻击和背景知识攻击,同时也适用于多维敏感属性表;最后,综合K-匿名算法和(P,K,d)匿名算法,提出了一种新的(L,K,d)多样化匿名算法,使同一等价组中所有维度的敏感属性至少有L条不同的记录满足d-相异度条件,在提高数据的隐私保护度的同时,也保障了数据的有用性.
