基于改进级联卷积神经网络的交通标志识别*
2020-10-09蔡英凤
王 海,王 宽,蔡英凤,刘 泽,陈 龙
(1.江苏大学汽车与交通工程学院,镇江 212000; 2.江苏大学汽车工程研究院,镇江 212000)
前言
交通标志的检测和识别在自动驾驶系统中十分重要,在自动驾驶过程中,迅速并正确识别出驾驶场景的交通标志对于交通安全意义重大。常用的交通标志检测主要有以下方法:基于颜色[1]、形状[2]的检测或者基于二者结合进行检测,再用模板进行匹配的方法[3-4];传统基于机器学习的检测方法[5]。其中基于标志颜色、形状的检测通常采用对图像进行颜色分割的方法,运算量小,实时性好,然而颜色特征受光照、天气的影响较大。基于标志形状的检测算法可以将交通标志从复杂背景中有效提取出来,通常采用霍夫变换进行直线和圆的检测,检测效果良好,然而受环境影响也较大。传统的基于机器学习方法通常在分类中应用了如支持向量机[6]、贝叶斯分类器[7]等,然而该方法需要针对不同检测任务设计不同特征,识别效果一般且不稳定。
基于深度学习的计算机视觉算法作为计算机视觉领域的后起之秀,随着近几年数据量的不断提升和硬件水平的突飞猛进,在各类计算机视觉任务中都取得了巨大的成功,例如目标分类、目标检测和语义分割等。其中,针对目标检测,目前已有大量效果出众且实时性良好的算法。这些算法根据是否使用了区域候选网络(RPN)进行一次正样本的检测框回归,分为单阶段和二阶段检测算法。单阶段目标检测算法有YOLOv3[8]、SSD[9]、Retinanet[10]等,双阶段检测算法有RCNN[11]、RFCN[12]、Faster-RCNN[13]和Cascade-RCNN[14]等。单阶段目标检测算法相比二阶段检测算法,减少了一次RPN的回归操作,有着更快的检测速度,但同时因为少了一次目标框的回归,有大量的简单负样本信息干扰单阶段检测算法最后的检测框回归操作,导致检测结果有较大的定位误差。而以Faster-RCNN为代表的一系列二阶段检测算法相比单阶段算法一方面存在着检测速度的劣势,另一方面二阶段检测算法的高查全率也会导致检测结果中有较多的假阳性目标。针对检测速度这一问题,考虑到二阶段算法中RoI pooling的插入,打破了原卷积网络的平移不变性,牺牲了训练和测试效率,RFCN检测算法提出了位置敏感积分图(position sensitive score map)这一概念,积分图包含位置信息,因此能够把RoI pooling层的输入直接连接全连接层用于分类和回归,大大提高了训练和检测的速度。针对假阳性问题,研究人员提出的Cascade-RCNN算法通过级联几个检测网络达到不断优化预测结果的目的,在进一步提高位置回归精度的同时也使得检测结果假阳性得到了一定的抑制。在目标检测领域中,交通标志检测是一个十分重要的方向,研究交通标志检测算法对于交通安全十分重要。
基于以上的研究基础,本文中提出了一种改进的卷积神经网络,基于Cascade-RCNN深度学习框架对交通标志进行检测和识别,算法在德国交通标志数据集(GTSDB)[15]上进行了验证,获得了较好的检测效果。
本文中的贡献包括以下内容:(1)对一些目前主流的深度学习目标检测算法在GTSDB数据集上进行横向比较研究,包括检测算法的精确度和实时性等,并对测试结果进行了分析和总结;(2)引入了特征图像金字塔FPN[16],针对交通标志这类小目标特殊任务,为更好地识别大小不同的物体,通过多尺度融合,将低层图像的位置信息与高层图像的特征语意信息融合,更好地表达图像信息;(3)通过引入文献[17]中提出的GIoU(generalized intersection over union)这一优化目标加快模型拟合预测框与真实框的位置关系,并提高交通标志识别回归框的准确率;(4)通过相关实验结果分析,本文所设计的目标检测模型在检测性能上相比其他目标检测模型有明显的提升。
1 基于Casacade-RCNN改进的交通标志检测算法框架
1.1 Cascade-RCNN算法框架
Cascade-RCNN是Faster-RCNN的 改 进 版,Faster-RCNN算法包含两个卷积神经网络,其结构如图1所示。Faster-RCNN由区域生成网络(RPN)和Fast-RCNN两部分构成,RPN用于生成目标可能存在的候选区域;Fast-RCNN实现对候选区域的分类,并进行边界回归。这两部分共享一个提取特征的卷积神经网络,使得目标候选区域的检测时间几乎为0,大幅提高了目标检测的速度。

图1 Faster-RCNN结构示意图
在目标检测算法中,IoU阈值常用于定义并生成正负样本,当使用低IoU阈值训练检测器时,会带来检测噪声(检测精度不高);如果仅仅提高IoU阈值,检测性能也同样下降,原因如下:(1)IoU阈值的提高,用于训练的正样本数量呈指数倍减少,会导致训练的过拟合;(2)预测阶段,输入与检测分支训练时采用的IoU阈值不一致,会导致性能下降。
双阶段检测网络会对提取的候选区域进行分类和回归。在分类过程中,每个候选区域中的正样本和负样本会根据初始设定的IoU阈值进行分类。在训练回归任务中,网络不断地向正样本的边界框回归。因此正确的IoU设定对于网络的训练和验证具有重大影响。
于是Cai等[14]在Fast-RCNN和Faster-RCNN的基础上提出改进的目标检测算法Cascade-RCNN。当设置一个阈值训练时,训练出的检测器效果有限,在级联RCNN中就采用了多阶段结构,每个阶段分别设置不同的IoU阈值。算法的主要思想是设置不同阈值,阈值越高,其网络对准确度较高的候选框的作用效果越好。通过级联的RCNN网络,每个级联的RCNN设置不同的IoU阈值,这样每个网络输出的准确度提升一点,用作下一个更高精度的网络的输入,逐步将网络输出的准确度进一步提高。对于交通标志检测识别,使用级联RCNN可使检测更加准确。
在交通标志识别中,为解决交通标志检测精度不高的问题,本文中采用级联RCNN网络结构(图2)。与图1所示的Faster-RCNN相比,将多个不同的检测器根据IoU的值串联起来。本文中设定IoU分别是0.3、0.4和0.5的3个级联检测器,每个检测器的输入源自上一层检测器边界框回归后的结果。这种设定的网络可使正样本的图像信息得到充分利用。首先初始化搭建的卷积神经网络模型参数,其中卷积层参数由利用ImageNet图像数据集预先训练的ResNet101[18]得到,其他层的参数都是采用随机方式初始化;为获得图像的多尺度特征表达,利用卷积神经网络提取层次特征,进而建立特征金字塔;然后根据RPN网络生成目标候选区域,在特征金字塔各个层级中找到对应的目标区域,从而提取出目标的多尺度特征;最后将池化后的特征进行特征融合。
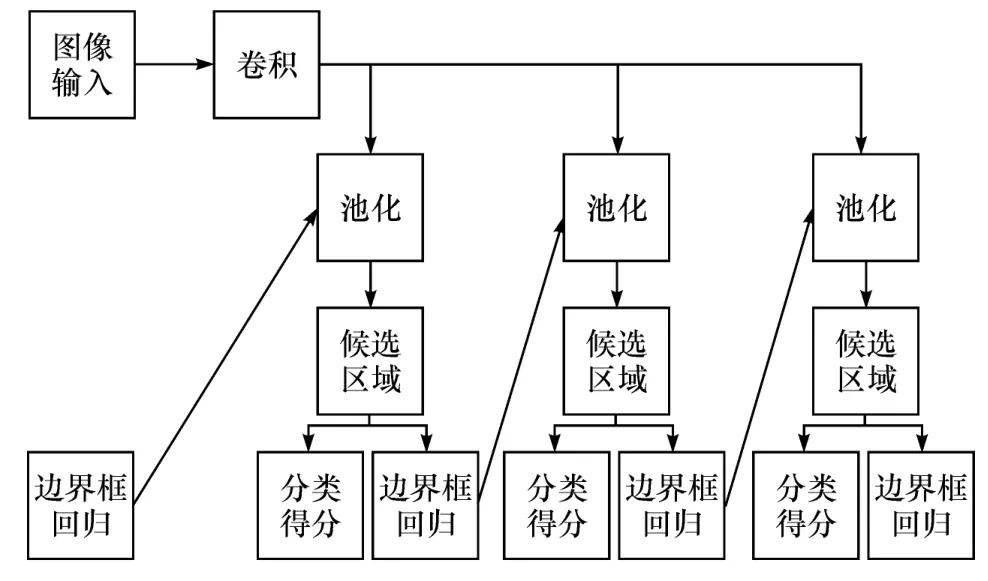
图2 级联RCNN网络结构
本文中采用的级联网络结构前传步骤详细如下:图片送入模型中,经过RPN网络,RPN网络从全部anchor中分配正样本和负样本,大于阈值0.7的为正样本,小于阈值0.3的为负样本,从全部的正样本和负样本中随机抽取200个样本进行loss训练,200个样本中正样本比例占0.5,接着RPN后处理。按照预测的分类概率进行排序,利用非极大值抑制筛选后得到2 000个候选区域,然后将2 000个候选区域选出512个送入第1个RCNN网络中,正样本比例为0.25,IoU大于0.3的为正样本,IoU小于0.3为负样本,接着再将上一步中的输出送入第2个RCNN网络中,正样本比例为0.25,IoU大于0.4的为正样本,小于0.4的为负样本,最后再将上一步中的输出送入第3个RCNN网络中,正样本比例为0.25,IoU大于0.5的为正样本,小于0.5的为负样本。这种设定在一定程度上减少了正样本的浪费和流失,使得检测网络适应各种目标的检测情况,提高网络的整体检测精度。
1.2 特征图像金字塔
通过本文中采用的级联RCNN网络结构,可提高网络整体的检测精度,但是针对交通标志这类小目标特殊任务,检测效果提升不明显,通常为了更好地识别大小不同的物体,特征图像金字塔[19]是一个常见方法。常见的特征图像金字塔将图像化成不同大小尺寸,对每一个尺寸的图像生成各自的特征并进行预测。虽然可保证特征提取的完备性,但是时间成本太大。通过该方式,网络速度快,内存占用小。但是由于忽略了低层网络的细节信息,网络精度有待提高。
基于上述原因,本文中创新性地引用FPN(feature pyramid network)的思想,在图像融合前,分别对两者生成特征图,由于图像底层的特征语义信息比较少,不能直接分类,但目标信息准确;高层特征语义信息比较丰富,但目标位置不准确,本文中采用如图3所示的特征金字塔网络FPN,其网络结构为自底向上和自顶向下的特征映射的构建模块。将自底向上和自顶向下的路径进行横向信息融合,通过对高层特征上采样和底层信息进行3×3卷积操作融合,可充分还原最低层特征图的语义信息,并得到有丰富的特征信息和高分辨率的特征图,对小目标有很好的检测率,且生成的特征图满足后续的处理。
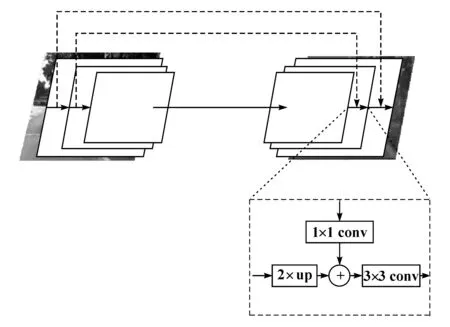
图3 FPN网络结构示意图
首先,通过设定空间分辨率采样为2像素,来完成较为粗糙的分辨率特征映射。其次,通过逐个元素叠加的方法将上采样的映射与对应的自下而上的映射(其经历1×1卷积层以减少信道维度)合并。迭代此过程,直到生成最佳分辨率的映射,然后添加一个1×1卷积层来生成最粗糙分辨率映射以开始迭代。最后,由于要减少上采样的混叠效应,在每个合并的映射上添加一个3×3卷积来生成最终的特征映射,即特征图。
整个算法大致分为3个部分:自底向上、横向连接和自顶向下。自底向上就是普通的卷积神经网络前馈过程,如果同一阶段的不同层产生相同大小的输出映射,则选择每个阶段最后一层的输出作为待处理特征图;自顶向下过程就是将自底向上过程得到的特征图进行上采样,该目的是使上采样后的特征图和相邻低层的特征图大小相同,可进行特征图相加;横向连接就是将上采样的结果和自下而上生成的特征图进行融合。这种做法只是在基础网络上增加了跨层连接,优点是不会增加网络额外的时间和计算量。
1.3 针对目标定位损失函数的优化
本文中将GIoU作为一种新的评价指标损失函数替代原有评价指标IoU引入到了级联RCNN中,由Loss-GIoU计算公式可知,Loss-GIoU能保证损失函数目标检测框回归具有尺度不变性,同时使检测框的优化目标和损失函数保持一致。在交通标志识别中,由于正样本和负样本之间存在显著的不平衡,这使得训练边界框得分更加困难,使用GIoU可有进一步改进的机会。在很多目标检测算法中,定位损失函数都使用预测框与真实框角点坐标距离的1-范数Loss或者2-范数Loss。目标检测领域IoU是对象检测基准中最常使用的评估指标,在最终评价模型性能时使用预测框与真实框的交并比来判断是否进行了正确的检测。IoU作为定位回归的损失函数主要有以下问题:(1)对于不重叠的两个对象,IoU值将为0,并不能反映两个形状之间的距离,在非重叠对象的情况下,如果使用IoU直接作为损失,则梯度为0无法进行优化;(2)IoU对于不同的对齐方式也无法进行区分。
如图4所示,图中右上角在圆心的矩形框为真实框,右上角在圆上的矩形框为预测框。可以看出预测框与真实框的2-范数Loss都是相等的,但是第3个的IoU明显高于前两个。在1-范数与2-范数取到相同值时,实际上检测效果却差异巨大,直接表现就是预测和真实检测框的IoU值变化较大,这说明1-范数和2-范数不能很好地反映检测效果,模型对这两者的优化不是等价的,所以检测结果也优于前两者。更精确地说,对于两个具有相同交点水平的不同方向重叠对象,IoU将完全相等。因此,IoU函数值并不能反映两个对象是如何重叠的。所以基于此问题,本文中提出了一种新的度量预测框与真实框拟合程度的方法,将GIoU作为一种损失函数引入到2D目标检测中。
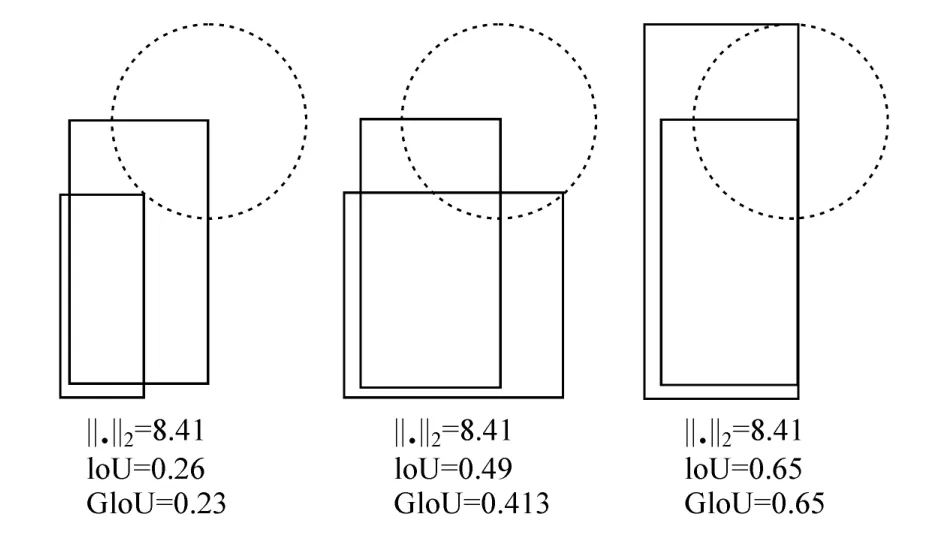
图4 相同2-范数Loss不同IoU
IoU和GIoU的计算公式为

式中:A为预测框;B为真实框;C为两者的最小闭包(包含A、B的最小包围框)
GIoU的详细计算方法如下所示。
输入:
输出:LossIoU和LossGIoU
(6)IoU=I/U,其中U=Areap+Areag-I,GIoU=IoU-(AreaC-U)/AreaC
综上损失函数为
LossIoU=1-IoU,LossGIoU=1-GIoU
2 实验与结果
2.1 数据准备
本文中使用了世界知名的公开交通标志数据集—德国交通标志检测数据集GTSDB,目标图像大小为1 360×800,本文中所采用的数据集包括不同的交通标志图像共900张,其中训练数据为600张,测试数据为300张。其中,图像中交通标志的数量在0到6个不等。每张图片均为RGB三通道的彩色图像。图像分为4类:禁止(prohibitory)、警告(danger)、指示(mandatory)与其它(other)。交通标志示例如图5所示。实验平台为Intel酷睿i7 8700K处理器,64GB内存,操作系统为Ubuntu18.04,编程软件为Pycharm,使用的运算显卡为GTX1080Ti。

图5 交通标志示例
2.2 实验步骤和实施细节
本文中选择4种目前主流的深度学习目标检测算法以及本文中改进的级联RCNN算法共5种算法进行横向比较研究,其中包含了两类单阶段检测模型YOLOv3和RetinaNet,两类二阶段检测模型Faster-RCNN和原版Cascade-RCNN,以及本文中改进的算法。训练和测试平台是一台搭载了GTX1080-TI GPU的工作站,在GTSDB数据集上评估这4种目标检测模型。对比实验统一将输入检测模型的图片尺寸定为1 360×800,考虑到显卡内存的限制batchsize选择为4,训练时选择的优化器都是SGD算法[20],初始学习率设置为0.001。除了YOLOv3使用Darknet-53作为基础特征提取之外,其余4类目标检测模型,本文中均使用在Imagenet上进行预训练的ResNet101网络作为基础特征提取网络。
2.3 实验结果
本文中算法采用的评价指标为平均精度均值(mean average precision),实际上就是4类交通标志平均精度(AP)的平均值。每一个类别检测结果指标为精确率(Precision),即被正确检测出来的交通标志占全部检出区域的百分比,其计算方式如式(3)所示;召回率(Recall),即被正确检测出来的交通标志占全部交通标志的百分比,其计算方式如式(4)所示。根据每一个类别检测结果的精确率和召回率绘制一条曲线,曲线下的面积就是平均精度,其计算如式(5)所示。5种算法的实验结果如表1所示。

式中:PR为精确率;RE为召回率;AP为平均精度;TP为正确检测出来的交通标志数量;FP为背景被检测为交通标志的数量;FN为交通标志被检测为背景的数量;p为纵轴精确率;r为横轴召回率。

表1 不同算法的检测精度对比
2.4 结果分析
表1清晰地显示了不同目标检测算法对于不同交通标志类别目标的检测精度,同时也反映了各算法对检测样本的查全和查准的能力。
两类单阶段模型YOLOv3、Retinanet在检测GTSDB的检测精度较低,相比于双阶段检测算法Faster-RCNN、Cascade-RCNN以及本文中的算法mAP较低,检测较不精确。
相比于改进前的Cascade-RCNN,当使用本文中改进的方法后,其中禁止类标志牌AP提高了1个百分点,警告类标志牌AP提高了2.2个百分点,指示类标志牌AP提高了3.5个百分点,其他类标志牌AP提高了1.6个百分点,平均准确率mAP提高了2个百分点。

图6 本文算法检测效果
实验中,本文中算法得到的部分检测结果如图6所示,所提出的方法可以很好地检测不同尺寸、角度和位置的交通标志。在图6中,包围框区域代表交通标志牌的位置,数字表示置信度,由图可以看出,对于较小的交通标志,本文中使用的模型能够很好地将交通标志检测出来,较好地解决了对交通标志这样的小目标漏检的问题。
改进后算法与YOLOv3算法检测效果对比如图7所示,可知改进后算法的车牌检测效果相较于YOLOv3的算法定位更加准确。由图8可知,原版Cascade-RCNN算法中较小的交通标志被漏检,改进后的检测效果较好,改进后的检测效果准确率和召回率都更高。同时本文中改进后的Cascade-RCNN算法相比于原版算法在检测速度上几乎一样,改进后不产生明显的时间代价。

图7 本文算法与YOLOv3算法检测效果对比

图8 本文算法与原版Cascade-RCNN检测效果对比
通过上述实验结果表明,测试的总体识别率达到98.8%,对于不同光照下和不同场景以及不同距离都有着良好的检测效果,本文中提出的算法准确率高于其他算法,对于现实场景下的交通标志有着良好的检测效果,有着很高的准确性。
3 结论
本文中针对交通标志的识别采用了基于级联Cascade-RCNN改进优化方法,在原有网络基础上引入FPN模块,将深层特征信息融合进浅层特征层,同时引入了更加接近检测任务的评价标准GIoULoss作为代价函数以提高模型的定位能力。该方法能识别出交通标志,既可提高网络在各个候选区域的检测精度,又可重点解决小目标检测问题,使网络的整体检测精度有了较大的提升。经过多次合理的模型参数优化后,检测准确率高达98.8%。但由于基础特征网络ResNet101的层数较深,单帧图像的检测时间较长,实时性还有待提高,下一步可考虑减少模型体积压缩模型来完成交通标志的实时检测与识别。
