一种基于分布式架构的隐私保护协同过滤算法
2020-09-16崔炜荣徐龙华
崔炜荣,徐龙华,李 宝
(1.安康学院 电子与信息工程学院,陕西 安康 725000;2.安康学院 数学与统计学院,陕西 安康 725000)
1 引言
在信息过载的当今社会,“推荐系统”已无处不在。它隐藏在各大新闻、视频、购物平台之后,悄无声息地收集着人们的浏览记录,及时将用户感兴趣的信息展现在用户眼前。由于需要利用用户的历史行为信息,甚至其人口统计属性信息,推荐系统在给用户带来便利的同时也面临着严峻的隐私安全问题[1]。其主要的隐私风险在于,一方面平台可以直接利用用户所提交的数据获得用户的个人身份、兴趣爱好等敏感信息;另一方面基于推荐系统所收集数据的稀疏特性,攻击者可利用推荐系统发布的聚合数据,有效推测出用户的敏感信息[2]。在个人隐私安全备受瞩目的当今社会,如何在保证可用性的前提下提供可靠的隐私保障成了推荐系统研究的热点问题。
矩阵分解协同过滤(Matrix Factorization Collaborative Filtering,MFCF)是构建推荐系统的主流算法之一[3]。本文基于常用的MFCF算法,设计了一种可有效保护用户隐私的协同过滤算法,称之为DSAMF(Distributed Secure Aggregation Matrix Factorization)。该算法采用了分布式架构,并且基于同态加密技术实现了模型计算过程中梯度更新信息的安全聚合,从而在保证推荐准确性的同时,有效保护了用户隐私。
2 相关工作
混淆和扰动是推荐系统中实现隐私保护的基本思路。该方式通过在用户数据中增加伪造值(加扰)以达到向服务器隐藏用户真实数据的目的[4-5]。然而,伪造值的引入牺牲了推荐系统的准确性,而且其安全性没有得到严格的证明。
差分隐私保护的原理在于通过在计算中引入特定分布的噪声来降低用户输入的可分辨性。与简单的混淆和扰动不同,差分隐私保护能够提供可度量和可证明的隐私保障。在推荐系统中引入差分隐私保护机制,同样需要在安全性和准确性之间做出权衡[6-10]。
同态加密技术能够使用户通过直接对密文运算以达到预期的明文计算效果,被广泛应用于各类隐私保护场景中。使用同态加密技术避免了加扰技术对推荐准确性的影响,但又带来了效率和能耗方面的较大开销[11-13]。
本文所设计的算法DSAMF是基于同态加密技术以及分布式计算架构来实现MFCF过程中的用户隐私保护。与现有算法区别在于,DSAMF除了能实现用户数据的保护外,还可以实现模型的保护以及用户评分“存在性”的保护。
3 同态加密技术
同态加密(Homomorphic Encryption)被广泛应用于安全计算领域。使用同态加密机制,可以将针对明文的特定代数运算转变为针对密文的特定代数运算。本文使用了Pailliers同态加密体系,与其他同态加密方法相比,Pailliers同态加密体系更加简单高效,因此被广泛使用。
3.1 Pailliers同态加密体系
Pailliers同态加密体系由三个原语组成。
(1)密钥生成:给定安全参数k,选择两个素数p和q(|p|=|q|),计算λ=lcm(p-1,q-1)。定义函数L(u)=(u-1)/n,其中n=pq。选择一个循环群生成元g,计算μ=(L(g2mod n2))-1mod n。所生成的公钥为(n,g),相应的私钥为(λ,μ)。

(3)解密:给定密文C,私钥(λ,μ),明文mod n。
3.2 Pailliers加密体系的同态性质
Pailliers加密体系的同态性质为:
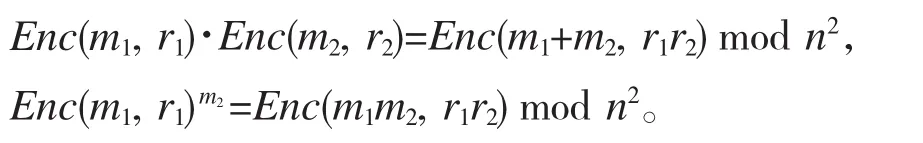
以上同态性质可简化为:

4 系统模型构建及隐私保护目标设计
4.1 系统模型及假设
整个推荐系统由多个用户和一个服务器组成。令用户集合为U={u1,u2,...,um},物品集合为V={v1,v2,...,vm},服务器为S。用户对物品的评分矩阵为R∈R|U|×|V|,rij∈R 为 ui对 vj的评分。系统的输入为用户评分矩阵R,输出为预测模型M=(W,H)。其中,W为用户隐藏因子矩阵,H为物品隐藏因子矩阵。R=WHT为评分预测矩阵,其应具有较好的拟合和泛化能力。对于上述模型,我们假设:(1)用户评分只保存在对应的客户端;(2)用户之间可以通过额外的安全信道进行点对点通信。
4.2 隐私保护目标
本文所设计的算法应满足如下隐私保护需求:
(1)模型保护:任意用户和服务器都无法获知完整的M,也无法通过所持有的部分信息推断出M的完整内容。
(2)评分保护:在模型的训练过程中,服务器无法获知用户的评分记录。每一个用户也无法获知其他用户的评分记录。
(3)存在性保护:在模型的训练过程中,服务器无法获知用户是否对某一物品进行了评分。每一个用户也无法获知其他用户是否对某一物品进行了评价。
5 算法设计
5.1 总体设计
为了实现上述隐私保护目标,本算法采用了分布式架构,即用户和服务器通过多轮迭代,共同参与了矩阵分解,如图1所示。
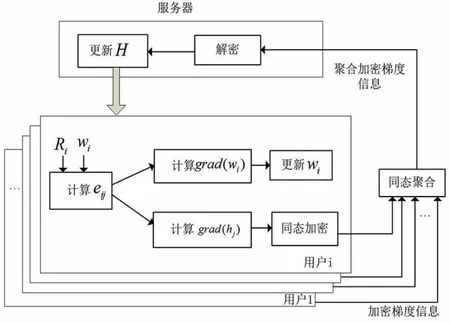
图1 总体设计
在初始化过程中,由服务器生成同态加密密钥对,并将加密公钥广播给每个用户。每轮迭代分为三个阶段。第一阶段:各个客户端ui从服务器下载更新过的H,之后利用保存在本机上的Ri和wi基于SGD算法计算wi的更新梯度grad(wi)以及其评价过的每一个物品所对应hj的更新梯度。接着,ui使用grad(wi)更新wi,并用同态加密密钥对每一个grad(hj)进行加密。第二阶段:用户间随机选举一位作为安全聚合端,由其完成针对各个hi的加密梯度更新信息聚合,并上传至服务器。第三阶段:服务器对聚合信息进行解密并更新H,至此进入下一轮迭代。
5.2 系统初始化
在初始化阶段,各个用户生成随机用户隐藏因子向量wi,服务器生成随机物品隐藏因子矩阵H。此外,服务器需要生成同态加密密钥对(ck,pk),并将pk广播给各个用户。
5.3 梯度更新信息计算
对于所求的目标模型M=(W,H),矩阵分解的目的在于基于给定的维度k找到最优的W∈R|U|×k和H∈R|V|×k,使得HWT≈R。也就是说,找到使损失函数L(W,H)值最小的W和H:

上式中,λ为归一化参数,用于防止过拟合。在本文中,使用随机梯度下降(Stochastic Gradient Descent,SGD)算法求解上式,其每轮迭代的更新规则为:
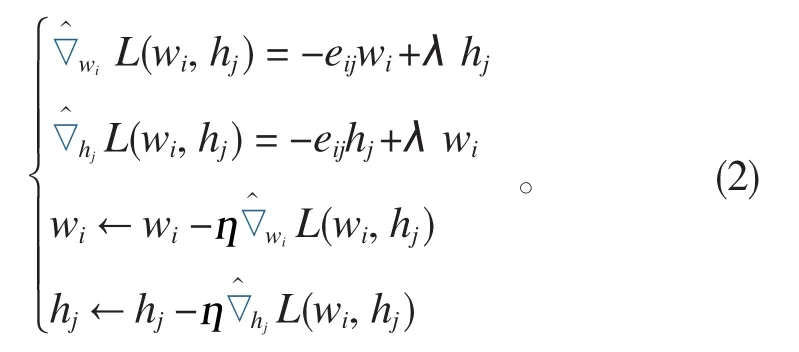
根据式(2),每轮迭代,用户ui首先需从服务器端下载H。假设用户评分过的物品集合为T={vj1,vj2,...,vjl},对于每一个hjk∈H,客户端进行如下计算:
(1)计算 eijk,
(2)计算grad(wi)jk和grad(hjk)。
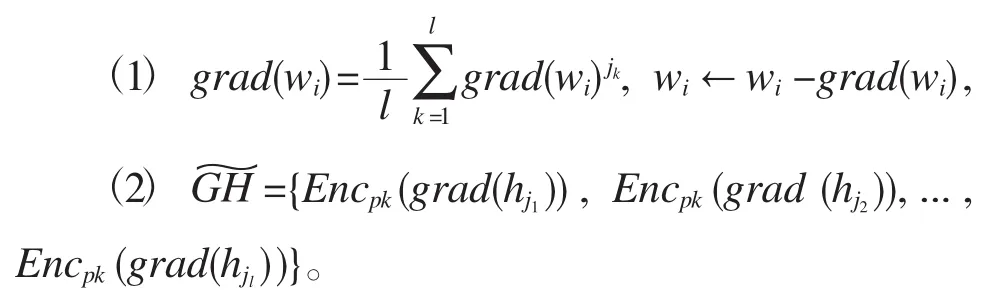
上述步骤中,Encpk(grad(hjk))表示用服务器生成的同态加密公钥pk对梯度更新值grad(hjk)进行加密运算。
5.4 安全聚合
每轮迭代中,为了避免服务器通过用户端上传的梯度更新信息推测出用户评价过哪些物品,客户端会对求平均值后,再将聚合结果上传至服务器。具体步骤为:
(1)混淆值加入:假设对于任意用户ui,其未评价的物品集合为在此步骤中,用户ui从中随机选取个物品,生成对应的s个Encpk(0),加入到中。
(2)聚合器选举:用户之间通过分布式选举程序从U={u1,u2,...,um}中选举出某一用户作为聚合节点。考虑到效率和安全性的权衡,选举可以每y轮迭代进行一次。
(3)安全聚合:假设聚合节点为ua,其他用户ui将发送给ua。为了区别起见,令用户ui生成的加密梯度更新值集合为,集合中针对某一物品vj的加密梯度更新信息为。聚合节点ua进行如下运算:
算法1同态聚合

聚合节点完成上述计算后,将结果上传至服务器,由服务器解密并更新H。
5.5 更新H
6 安全性分析
本文所设计的算法兼顾了预测模型、用户评分和用户评分存在性三方面的隐私保护需求。
6.1 模型保护
算法采取了分布式架构,对于模型M=(W,H)而言,W中的每一个行向量wi都保存在对应的用户ui端。对于服务器而言,在整个迭代过程中,其仅仅能够获知针对hj的更新信息。此外,由于该信息是多个用户针对同一hj的聚合,因此服务器无法从中推测出具体的用户隐藏因子向量。对于每个用户ui而言,虽然其能够获得H,但由于其无法得知其他用户的wi'(i≠i′)因此无法获知完整的W。根据上述分析,无论是服务器还是用户,都无法获知W,因此能够实现对M的保护。
6.2 用户评分保护
用户评分透露了用户的喜好,是推荐系统所涉及的重要隐私数据。本算法中,评分矩阵R没有集中存放,其每一行Ri∈R由对应的用户ui保存。在每轮迭代过程中,Ri只参与计算预测误差eij。因此,服务器在这个模型计算过程中,无法获知用户的评分矩阵,每个用户也无法获知其他用户的评分向量,用户评分得以保护。
6.3 存在性保护
在本算法中,安全聚合步骤是实现存在性保护的关键。举例而言,如果省略安全聚合步骤,客户端ui将梯度更新信息grad(hj)直接发放服务器,则服务器至少可以知道ui对hj进行了评分。而通过安全聚合步骤,服务器接收到的是来自多个用户针对同一hj的梯度更新值聚合,因此实现了针对服务器端的用户评分存在性保护。此外,在安全聚合步骤中,通过在用户加密梯度更新值集合中加入随机0值以及随机选取聚合节点两个操作,避免了评分存在性在用户之间的泄露。
7 实验结果与分析
基于所描述的算法设计,我们使用Python3.6+TensorFlow2.0开发了系统原型,测试了模型计算的收敛效率并与有关学者提出的SDMF方法[14]进行了比较。实验方法和结果如下。
7.1 数据集及实验方法
实验数据集为:MovieLens数据集ML-100K和ML-1M,Netflix数据子集(包含10000个用户和5000个物品)。我们将每一个数据集随机划分为占比80%和训练集和占比20%的测试集。具体的超参数设置为:K=50,学习速率分别为5×10-6(ML-100K),5×10-7(Netflix)。对于 SDMF,我们选取了作为两组差分隐私配置参数。
7.2 结果与分析
实验结果如图2所示。SDMF算法主要应用了差分隐私保护的思想,通过在训练过程中加入总体可控的噪声来实现对个体数据的保护。该算法的参数表示所要达到的差分隐私保护强度。越小,则差分隐私保障越强,相应的预测准确度就越低。图2中的实验数据说明了这一点。同时,图2也清晰地表明,DSAMF的预测准确度和收敛速度远远高于SDMF。这是因为针对同样的隐私保护目标,DSAMF采用了同态加密的思路。由于没有在系统中引入干扰噪声,所以能够在保护隐私的同时最大限度地保障推荐准确度。
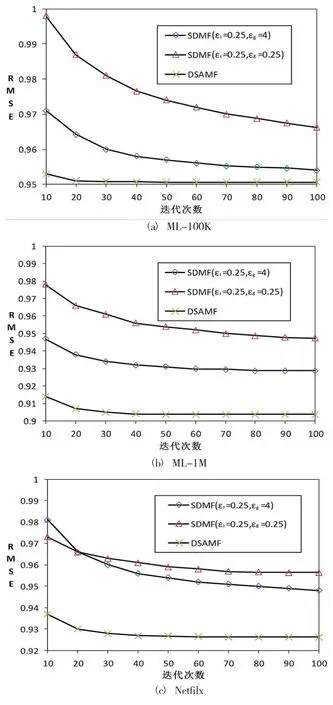
图2 实验结果
8 结语
针对协同过滤推荐系统中的隐私保护问题,本文设计了DSAMF算法。在DSAMF中,矩阵分解由各个客户端和服务器协作完成。整个模型训练过程中,服务器仅仅获得针对物品隐藏因子向量的聚合梯度更新,而每个用户仅能获知更新后的物品隐藏因子向量和来自其他用户的加密梯度更新值。因此DSAMF算法能够有效地实现模型、用户评分记录、用户评分存在性的保护。今后还需要针对如何进一步提高模型的准确度和生成效率展开研究,以期在安全性和效率两方面达到更优的权衡。
