基于深度网络的多模态视频场景分割算法
2020-07-21苏筱涵丰洪才吴诗尧
苏筱涵,丰洪才,吴诗尧
(1.武汉轻工大学 数学与计算机学院,湖北 武汉 430023;2.武汉轻工大学 网络与信息中心,湖北 武汉 430023)
视频场景分割是基于内容的视频检索中的一个重要环节,以镜头为研究对象,根据镜头内容的相关性和时间上的邻近性把语义相似的镜头划分到同一个场景中,将一段完整的视频分割成若干个有意义的逻辑故事单元[1]。国内外学者已对视频场景分割进行了大量研究,主流的视频场景分割方法包括基于规则的方法、基于图的方法和基于多特征融合的方法。其中,基于规则的方法是利用视频制作人员使用的视频规则作为计算镜头相似度的指导从而识别视频场景。CHASANIS等[2]以关键帧表示镜头,用谱聚类和低层颜色特征聚类并根据所属聚类进行标记,使用Needleman-Wunsch算法从符号序列的对齐分数中检测场景边界。但在不严格遵守编辑规则的视频中,或当两个相邻的场景相似且遵循相同规则时,该算法往往会造成场景分割错误。在基于图的方法中,镜头转换图(shot transition graph,STG)[3]模型以节点表示镜头或镜头簇,边缘表示连接节点之间的相似性或时间接近度,应用图形分割算法构造的图形被分成子图,每个子图表示场景。SU等[4]使用颜色和运动特征来表示镜头相似度,通过应用归一化的切分将STG划分为子图。SIDIROPOULOS等[5]引入STG近似的方法,利用视觉和听觉通道的特征。但该方法在对视觉特征和听觉特征相近似的镜头进行聚类时,没有考虑到上下文,从而不利于对生成子图的分析和分割有意义的场景。基于多特征融合的方法运用了多特征融合技术,可以避免提取到的场景图像特征单一的问题,是一种解决场景分类的新思路。贾澎涛等[6]通过多特征融合技术获取场景视频的综合特征,再设定阈值对场景进行分类。虽充分考虑了场景的区域位置属性,减小了信息冗余,但未从多角度对视频特征进行融合,同时相对于部分传统分类器来说,阈值判定分类器不需要进行训练集训练,分类过程易于实现。
针对使用低层颜色特征聚类、引入STG近似计算镜头相似度及多特征融合的问题,笔者提出了基于深度网络的多模态视频场景分割算法,整体框架如图1所示。该方法的创新之处在于提出了一种从视频视觉内容及文本中提取语义概念特征的策略,该策略结合了视频镜头的底层特征,通过三重深度网络学习多模态语义嵌入空间,利用这些特性实现多模态视频场景分割。
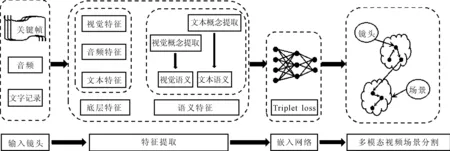
图1 整体框架图
1 镜头检测及特征提取
笔者采用多模态深度网络方法,将视频场景分割任务作为一个有监督的时间约束聚类问题来处理。首先,从每个镜头中提取丰富的底层特征和语义特征;其次,为了获得镜头特征之间的相似性度量,在欧氏空间中嵌入这些特征;最后,通过最小化时间段内距离的平方和来检测最优的场景边界,并使用一个惩罚项来自动选择场景的数量,解决了视频检索时场景结构的自动提取问题,实现了多模态视频场景分割。
1.1 镜头边界检测
为了进行镜头检测,使用文献[7]提出的将视频快速分割成镜头的方法。该算法使用HSV直方图和SURF描述符来表示视频帧的视觉内容,并通过量化和比较帧对之间的不相似性与预定阈值来检测突变和渐变的转换。细化步骤消除了由于物体、相机移动和闪光灯引起的异常值,进一步提高了检测精度。
1.2 视频底层特征
视频的多模态特征是由视频中图像、音频、文本3种媒体数据对应的底层特征构成的,不同模态的选择、融合与协作对于缩减视频底层特征与高层语义之间的“语义鸿沟”起着重要作用[8]。笔者提出了一组基于视觉图像、听觉、文本的底层特征,又提出了两种语义特征,它们依赖于对视觉内容和文本的联合概念分析,并解释了无法通过纯粹的底层线索识别的场景变化。
1.2.1 视觉特征
视频中的镜头从视觉内容的角度来看往往是统一的,因此依靠关键帧来描述视觉外观是合理的。同时,使用单一的关键帧可能会导致短镜头和长镜头的描述都很差,原因在于视觉质量可能不令人满意,或者其内容可能不足以描述镜头的时间演化。因此,笔者提出了一种解决方案,该方案保留了卷积神经网络提取高层特征的能力,同时考虑了镜头的时间演化。即构建了一个时间池化全卷积神经网络,可以将多个关键帧的可视外观编码为一个固定大小的描述符。该网络是完全卷积的,只包含卷积和池化阶段,不包含完全连接的层。此外,网络的最后一个阶段执行时间池化操作,从而将可变数量的关键帧减少到固定的维度。网络架构遵循VGG[9]的16层模型,保持全卷积架构,去掉最后的全连接层,添加时间池化层,通过对ILSVRC2016数据集[10]进行预训练,初始化网络参数。
给定一组尺寸为l×l的关键帧{I1,I2…,It},每个关键帧都由网络的卷积和空间池化层独立处理,从而每帧Ip将获得一个形状为|l/f|×|l/f|×k的三维张量CNN(Ip), 其中f为网络空间池化层调整输入图像大小的因子,k为最后一层卷积过滤器数量。在这k个激活图中,每个激活图都包含特定高级特征检测器在输入图像上的空间响应。
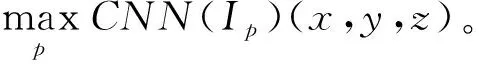
1.2.2 音频特征
视频音频是检测场景边界的另一种有意义的线索,因为音频效果和音轨通常用于专业视频制作,以强调场景内容的发展,而音轨的变化通常强调内容的变化。因此笔者采用基于短时功率谱的标准音频描述符[11],在10 ms窗口内提取了MFCCs(mel frequency cepstral coefficients)描述符[12]。
1.2.3 文本特征
视频人物话语中的停顿也可识别场景的变化,因此通过视频字幕构建一个文本特征,计算一个镜头中的词汇量。但当视频制作者没有直接提供视频字幕文本时,可通过现有的语音识别技术[13]获得。对于每个镜头,词汇量被定义为该镜头中出现的字数,并对在完整视频的镜头中找到的最大字数进行标准化。
1.3 视频语义特征
从视频文本中提取概念并将其投射到语义空间中,然后通过镜头的视觉内容来验证每个概念。为了收集候选概念,对文本中句子进行解析,并使用Stanford CoreNLP[14]词性标记器收集标注为名词、专有名词和外来词的字母组合。所选字母组合包含可能存在于视频中的术语,并且可能有助于利用视觉概念检测场景主题的变化。有些术语没有具体的视觉概念,但仍可从文本中推断出主题的变化。因此笔者将描述两个特性来解释这两种情况。
1.3.1 视觉概念特征
将视频文本中的每个概念映射到外部语料库后,可以构建分类器来检测一个镜头中的视觉概念是否存在。由于从文本数据中挖掘的术语数量很大,因此分类器需要高效。来自外部语料库的图像使用预先训练的深度卷积神经网络的特征激活来表示[15]。利用随机采样的负训练数据对每个概念进行线性SVM训练[16],再将每个分类器的概率输出作为镜头中一个概念是否存在的指示符。使用VGG的16层模型在ILSVRC-2016数据集上进行预训练,并使用来自fc6层的激活。
由于产生的术语集可能存在冗余且包含大量同义词,因此根据术语的成对相似性对其进行聚类,以获得一组语义上不相关的聚类。将每个词都映射到一个1 000维的特征向量,两个词的语义相似度定义为嵌入学习之间的余弦相似度。并将得到的相似矩阵与谱聚类方法[17]结合使用,将挖掘到的词汇聚类成K个概念组。
建立一个特征向量来编码每个概念组对镜头的影响。考虑到视频的时间连贯性,一个视觉概念不太可能出现在远离概念发现点的镜头中,同时文字记录中所表达的概念不仅与其出现的单个镜头有关,还与其邻域有关。因此,根据时间距离对每一项应用归一化高斯加权,则镜头s中出现u项的概率为:
(1)
式中:Q为到外部语料库的映射函数;fQ(u)(s)为基于概念Q(u)训练的SVM分类器在镜头s上测试得到的概率;tu和ts分别为术语u和镜头s的时间戳。
根据P(s,u)的定义,可知镜头的视觉概念特征为K维向量,其定义式为:
(2)
式中:T为视频中所有术语的集合;K为挖掘到的词汇所聚类的概念组的数量;δu,q∈{0,1},用于判断术语u是否属于第q个概念组。
1.3.2 文本概念特征
文本概念对于检测场景的变化同样重要,且检测到的概念组为描述文本中的主题变化提供了一种理想的方法。因此,构建文本概念特征向量t(s),将其作为视觉概念特征向量v(s)的文本对应项,从而得到每个概念组在一个镜头的文字记录及其邻近区域中出现数量的表示。
(3)
最后,将镜头s的整体特征向量X作为所有底层特征和语义概念特征的串联。对于每一个镜头,其整体特征向量X都是三重深度网络的输入,三重深度网络再进行嵌入学习。基于多模态的方法主要是为了提高分析视频语义内容的可靠性和效率。
2 深度网络结构嵌入
2.1 嵌入网络
考虑到视频流中同一场景内的镜头通常具有统一的内容,因此场景分割问题也被视为将相邻镜头分组在一起的问题,目的是最大化相似镜头的语义一致性。为了反映了语义相似性,需要计算镜头特征向量X之间的距离,因此构建了一个嵌入函数φ(X),可将一个镜头的特征向量映射到欧几里得距离具有所需语义属性的空间。成对的距离矩阵为:
[‖φ(Xi)-φ(Xj)‖2]=[1-αi,j]
(4)
其中,αi,j是一个二元函数,表示镜头Xi和镜头Xj是否属于同一个场景,i,j=1,2,…,N。

(5)
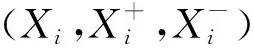
(6)
式中:w为网络权重;θ为偏差。N个三元组的总体损失由每个三元组的平均损失加上网络权重的L2正则项所给出,以减少过度补偿。N个三元组总体损失的定义式为:
(7)
2.2 深度网络嵌入空间学习
在学习过程中,进行小批量随机梯度下降。在每次迭代中,随机抽取N个训练三元组作为样本。对于每一个三元组,计算其分量上的梯度并根据式(7)进行反向传播。
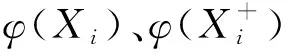
3 多模态视频场景分割
因为场景需要在时间上连续,所以具有相似语义内容但在时间上距离较远的镜头是应该可以被区分的。将视频场景分割任务作为一个有监督的时间约束聚类问题来处理,首先从每个镜头中提取丰富的底层特征和语义特征;其次为了获得镜头特征之间的相似性度量,在欧氏空间中嵌入这些特征;最后通过最小化时间段(候选场景)内距离的平方和来检测最优的场景边界,并使用一个惩罚项来自动选择场景的数量。
为了获得视频的场景分段,要求镜头在语义上尽可能一致。受K-Means的启发,聚类同质性可以用聚类元素与其质心之间的平方距离之和来描述,称为组内平方和(within-cells sum of squares,WSS)。因此,合理的目标是最小化组内平方和,即所有聚类的WSS。与K-Means不同,笔者希望找到视频镜头的数量,附加的约束是时间上连续的间隔。仅最小化组内平方和,将导致每个序列中只有一个镜头的琐碎解决方案,因此需要添加惩罚项以避免过度分割,则需要解决的问题是:
(8)
式中:M为输入视频被分割的变化点的数量;tm为第m个变化点的位置(t0和tM+1分别为视频的开始和结束);WSSm,tm+1为嵌入空间中第m个分段的组内平方和;g(M,N)=M(ln(N/M)+1)为贝叶斯信息标准惩罚[19],用视频中的片段数M和镜头数N进行参数化,其目的是减少过度分割效应;参数C是用于调节惩罚的相对重要性,较高的惩罚值C会造成太多的分段,因而C值的选择依赖于视频,使用0.001的步长调整C值,直到集群的数量小于视频中的镜头数量。
一组点与其平均值之间的平方距离之和可以表示为单独点之间的成对平方距离的函数。因此,组内的平方和可以表示为:
(9)
其中,μm为每个场景镜头特征的平均值:
(10)
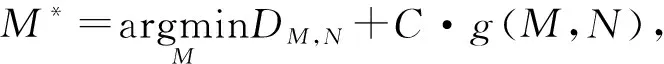
(11)
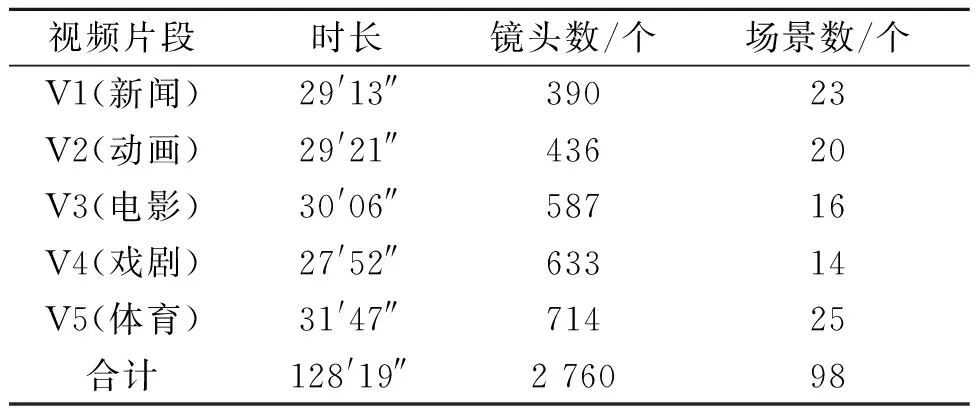
视频场景分割的算法中,输入为场景视频流,其中视频镜头总数为N、镜头整体特征向量为X。输出为场景边界(镜头编号Si)。具体算法步骤为:
(1)利用文献[7]的镜头检测器对输入的视频流进行镜头分割,通过计算所有镜头内帧的平均距离,找出镜头内帧的距离大于平均值倍数的帧作为该镜头的关键帧。对所有分割后的镜头和关键帧进行编号,即Si、Sf。
(2)利用CNN提取高层特征的能力并考虑镜头的时间演化,对视频底层特征中的视觉特征进行提取。采用MFCCs描述符对其音频特征进行提取。根据视频直接提供视频字幕文本并结合现有的语音识别技术对其文本特征进行提取。
(3)根据式(1)和式(2)分别对镜头的视觉概念特征向量v(s)和文本概念特征向量t(s)进行提取。然后将其所有特征进行串联得到其整体特征向量X。
(4)利用深度网络学习一个嵌入函数φ(X),通过在欧式空间中嵌入视频镜头特征,并根据式(4)~式(7)计算镜头间的成对距离矩阵,获得镜头特征之间的相似性度量值,从而得到视频镜头间语义相似度。
(5)针对每个段起始点r和段持续时间d利用式(9)计算WSSr,r+d。
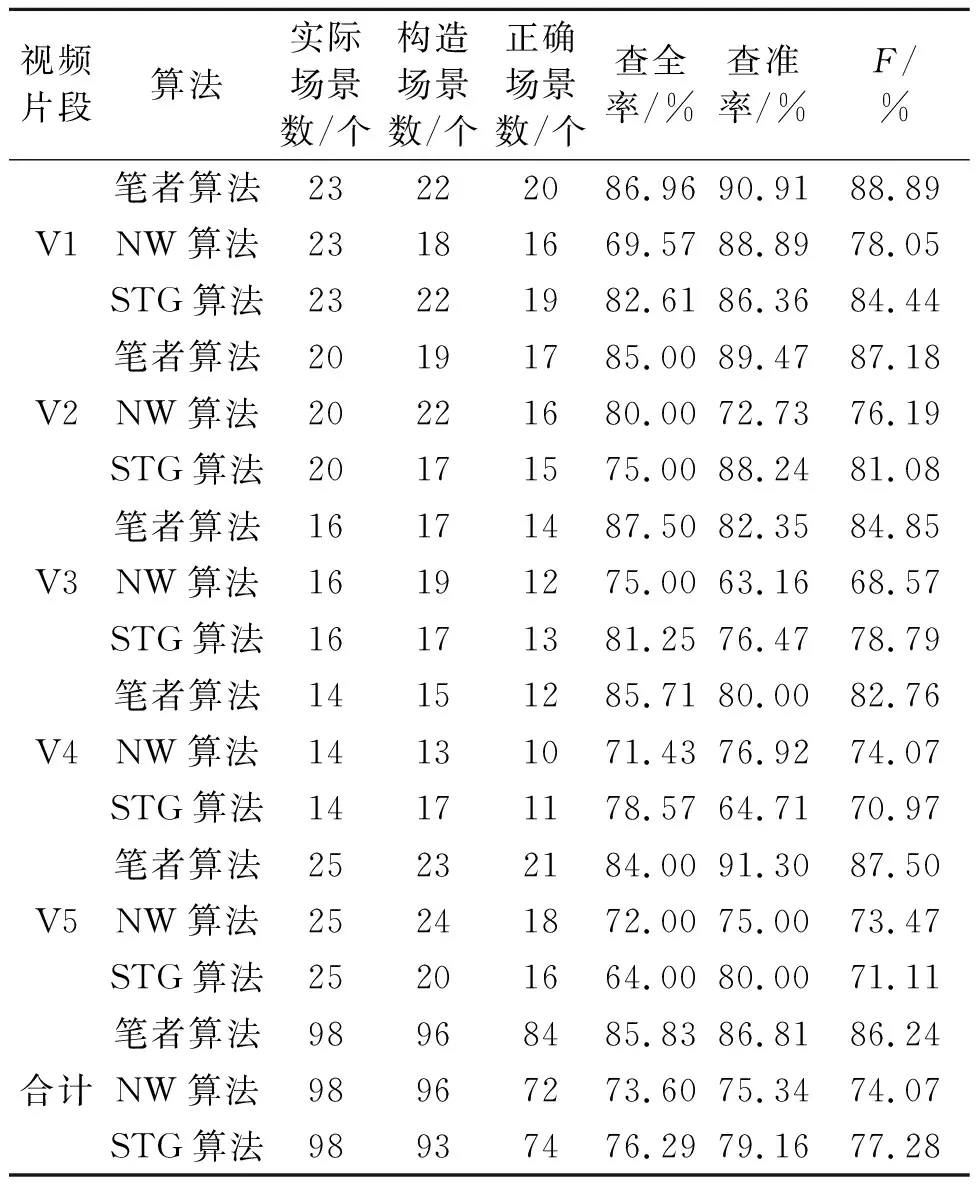
(6)令j∈[1,N]、M∈[0,N-1],通过式(11)计算一个包含j个镜头和M个变化点的最佳目标值来最小化目标DM,j。若r (7)通过计算选择最佳变化点数量M*,并根据分割点位置输出对应场景边界的镜头编号Si,最终得到视频场景分割结果。 为了验证所设计算法对视频场景分割的有效性,选择了具有代表性的5种不同类型和风格的视频片段进行实验,分别为新闻、动画、电影、戏剧和体育视频。实验素材涵盖了不同类型的场景,视频总时长为128′19″,共2 760个镜头,98个场景,实验详细信息如表1所示。 表1 视频片段详细信息 采用信息检索领域广泛使用的查全率(Recall)、查准率(Precision)及对两者进行综合度量的指标F,对算法的性能进行评测。 (12) (13) (14) 式中:nc为检测出正确的场景总数;nm为未检测出的场景总数;nf为错误检测出的场景总数;na为实际场景总数;nd为检测到的场景总数。 将笔者算法与文献[2]中利用底层颜色特征与NW(needleman-wunsch)算法相结合的方式、文献[5]中利用镜头转换图(STG)中融合各种视觉和音频特性所实现的视频场景分割方法进行比较,进而说明笔者算法的优劣。实验结果如表2所示。 表2 不同算法的实验结果 由表2可以看出,与文献[2]及文献[5]的算法相比,笔者算法的查全率、查准率及F值均有较大提高。这主要因为文献[2]仅仅考虑了视频底层颜色特征与NW算法相结合,文献[5]也仅在STG中融合了各种视觉和音频特性,都未全面考虑视频数据中多种模态之间的时序关联共生的特性。笔者则提出了一个深度学习框架,从视频中分别提取不同的底层特征并结合语义概念特征,通过三重深度网络学习多模态语义嵌入空间,用于对镜头分组并将视频分割成连贯的场景,有效缩小了视频底层特征与高层语义之间的“鸿沟”。由此可见,笔者算法所实现的场景分割效果更好,且该算法对于不用类型视频的通用性也更强。 (1)笔者提出基于深度网络的多模态视频场景分割算法,从每个镜头中提取丰富的底层特征和语义概念特征,将镜头整体特征向量作为三重深度网络的输入并进行嵌入空间学习,通过计算两个镜头整体特征向量之间的距离得到语义相似性的度量值,然后最小化时间段内距离的平方和来对镜头进行聚类处理,实现了对视频场景的快速分割,并取得了较好的实验结果。 (2)视频的多模态特征融合对缩减视频底层特征与高层语义之间“语义鸿沟”的作用不容小觑,利用深度网络学习一个嵌入函数并通过在欧式空间中嵌入视频镜头特征,使得视频场景分割准确度更高、通用性更强。4 实验结果分析
5 结论
