基于改进LightGBM模型的汽车故障预测方法研究*
2020-06-29颜诗旋
颜诗旋,朱 平,刘 钊
(1.上海交通大学,机械系统与振动国家重点实验室,上海 200240; 2.上海市复杂薄板结构数字化制造重点实验室,上海 200240;3.上海交通大学设计学院,上海 200240)
前言
机器学习、大数据等人工智能技术与汽车行业的联系日益紧密,一个典型的应用场景[1]是对采集的汽车故障数据集建立机器学习模型,以数据驱动的方式,预测汽车是否发生故障,从而及时对发生故障的车辆进行维修。使用机器学习模型预测汽车故障的发生,对于降低安全事故风险、保障生命财产安全等具有重要意义。
随着汽车故障数据的采集与存储能力的提升,汽车故障数据集逐步向大样本、高维度发展,XGBoost、LightGBM等最新的机器学习模型开始应用于故障预测中。李卫星等[2]使用XGBoost模型,对4种工况下柴油机失火故障的平均预测准确率达90%以上。杨正森[3]使用 XGBoost和LightGBM模型对包含100多万个样本的工业产品数据集进行故障预测,结果优于经典的随机森林模型。Ke等[4]基于多个案例测试的结果,推荐在大规模数据集上使用训练速度快、预测能力好的LightGBM模型。然而,实际收集到的汽车故障数据普遍存在类别不平衡[5]的特点:无故障的样本数量多于有故障的样本数量,前者所能提供的信息量更多,使模型偏向于预测新的样本为无故障,导致故障查全率较低。针对类别不平衡的特点,Costa等[6]在模型损失函数中加入类别权重,将故障样本的类别权重设置为不平衡比(无故障样本数与有故障样本数的比值),降低了类别不平衡对故障查全率的影响,但其人为指定了类别权重,并未考虑其他可能的取值。Biteus等[7]将采用机器学习模型进行预测时的分类阈值降低至0.062,提高了对汽车故障样本的预测能力,但其选用的随机森林模型训练时间长达80 min,有必要使用更为高效的模型以提升效率。
LightGBM模型在大样本、高维度的故障预测任务中呈现出训练速度快的优势,但现有研究在使用LightGBM模型时未考虑类别不平衡对故障查全率的影响。虽然有研究通过设置类别权重来提高对类别不平衡数据集的预测能力,但类别权重的设定多依赖于人工经验直接指定,未考虑如何使用优化的方法进行设定。
为增强对大规模、类别不平衡的汽车故障数据集的预测能力,本文中提出一种基于改进LightGBM模型的汽车故障预测方法:设置类别权重和L1正则化项修正模型的损失函数,并通过贝叶斯优化得到修正项参数的取值;降低模型预测时的分类阈值,提高样本被分为故障样本的概率。通过在斯堪尼亚货车故障数据集上的实验,验证了本文方法的有效性。
1 LightGBM模型
LightGBM(light gradient boosting machine)模型由Ke等人在2017年提出[4],是一种以决策树为基学习器的集成学习模型,相比于 GBM[8]和 XGBoost[9]等模型,通过使用直方图算法、带深度限制的按叶生长策略等改进,显著提高了模型训练速度,在面对大样本、高维度的数据集时具备训练速度快的优势。
1.1 直方图算法
决策树在寻找最佳分裂结点时,对每个特征需要遍历所有的样本点来计算信息增益,即便有XGBoost等模型使用了预排序算法优化此过程,在面对大规模数据时仍极其耗时。
LightGBM模型使用了直方图算法寻找最佳分裂结点,其原理如图1所示。直方图算法的流程为:首先,对每个特征的取值用分桶的方法离散化,将在某个范围内的取值划分到某一段(bin)中,例如将[0,1.5)范围的取值变为 0,[1.5,3.0)范围内的取值变为1等,从而实现将取值离散化为k个整数;然后,构建一个宽度为k的直方图,实现用直方图代替原有的数据;最后,将借助于构建的直方图遍历数据,计算每个bin中样本的梯度、样本数量等以寻找最优分裂结点,无需再逐个遍历所有的数据,从而显著减少了计算量,提高了训练速度。
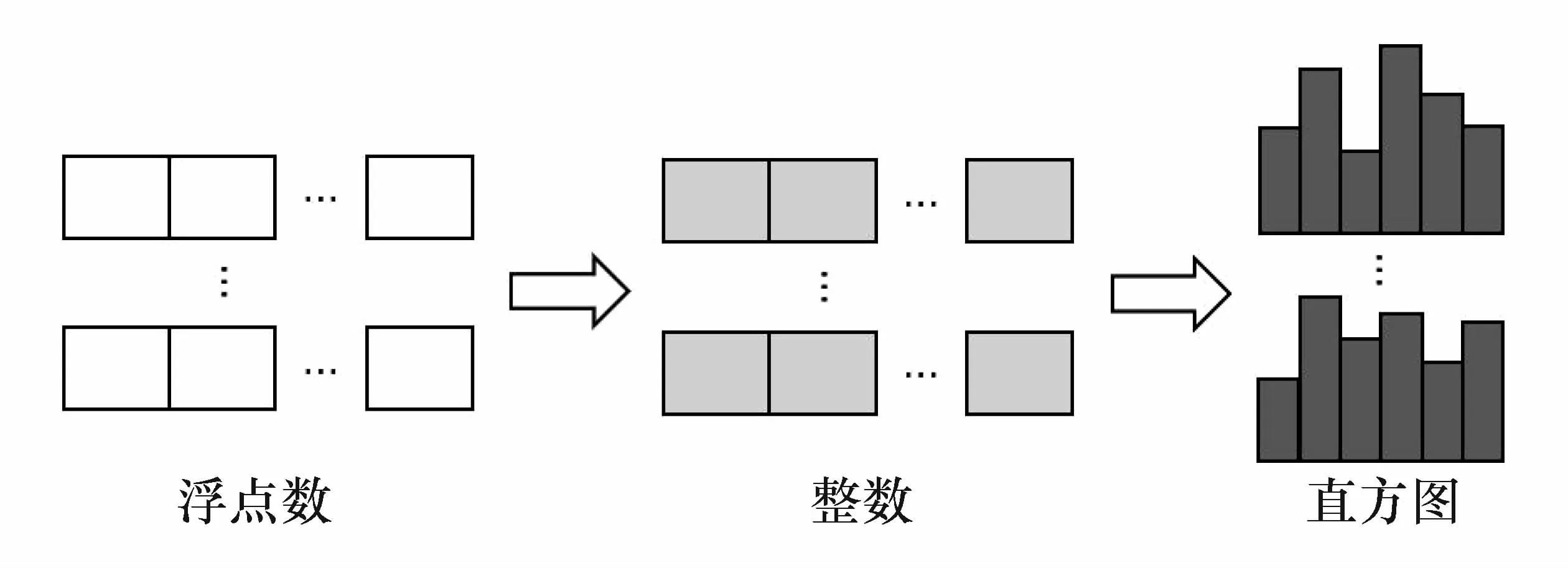
图1 直方图算法示意图
此外,LightGBM模型使用基于梯度的单边采样(gradient-based one-side sampling,GOSS)进行数据采样,使用互斥特征捆绑(exclusive feature bundling,EFB)进行特征采样,在进一步加快模型训练效率的同时,对数据和特征进行采样也增加了学习器的多样性,从而潜在地提升了模型的泛化能力[10]。
1.2 带深度限制的按叶生长策略
决策树在生长时,大多采用按层生长的策略,如图2所示。按层生长遍历全部数据计算各结点的增益,进而对同一层的叶子全部进行分裂。这一方法并行性很好,但效率较低:很多叶子的增益已经足够小,不再有必要进行分裂,而那些增益大的结点才是应进行分裂的结点。

图2 按层生长策略示意图
LightGBM模型使用按叶生长策略,如图3所示。在计算各结点的增益后,仅对增益最大的一个叶子继续进行分裂,而其他结点不再分裂。在一样的分裂次数下,按叶生长策略更加快速高效。但这样可能会生长出非常深的决策树,导致过拟合,即对训练集进行了过度的学习,影响在测试集上的泛化能力。因此,在LightGBM模型中设置树的最大深度(max_depth)这一参数,以限制决策树的深度,即决策树的层数,以控制模型的复杂度,降低过拟合的风险。

图3 按叶生长策略示意图
2 改进LightGBM模型
考虑到真实场景下的汽车故障数据集常具有类别不平衡的特点:无故障的样本数量占多数,导致模型对故障样本的查全率较低。为增强机器学习模型对汽车故障的预测能力,对LightGBM模型进行两方面的改进:在模型训练时,修正模型损失函数,引入类别权重和L1正则化项,并通过贝叶斯优化,获得修正项参数的最优取值,从而加强对故障样本的学习;在模型预测时,降低分类阈值,以提高测试样本被分为故障样本的概率。具体改进如下。
(1)修正损失函数
损失函数反映了模型训练过程中模型的预测类别与真实类别之间的差异。模型训练的过程,即是损失函数最小化的过程,损失函数的度量关乎模型训练的好坏[11]。对一个数据集 D=(x1,x2,x3,…,xm),共有m个样本,其中第i个样本xi的类别为yi,yi=0为无故障,yi=1为有故障,标准 LightGBM模型的损失函数为

由于样本数量的差异,有故障样本所累积的损失小于无故障样本所累积的损失,使无故障样本所累积的损失在LightGBM模型的损失函数中占据主导地位,导致模型对无故障样本的学习更为充分:模型总是在学习如何正确地预测出无故障样本。这偏离了使用机器学习技术预测有故障样本的初衷。此外,考虑到收集的数据仅是真实场景下的部分数据,不可能囊括所有可能的工况,须防止模型对收集到的训练集进行过度的学习,降低过拟合风险。
本文中对LightGBM模型的损失函数进行如下修正:引入类别权重,为有故障样本设置更大的权重,从而在损失函数中放大有故障样本的损失;同时引入L1正则化项来控制模型的复杂度,以降低过拟合风险。正则化手段主要有L1正则化和L2正则化两种,本文中使用L1正则化的原因是:L1正则化比L2正则化更易得到稀疏解,从而使模型参数ω=0的数量更多,以便更显著地控制模型复杂度,降低过拟合风险[12]。经修正后的损失函数为
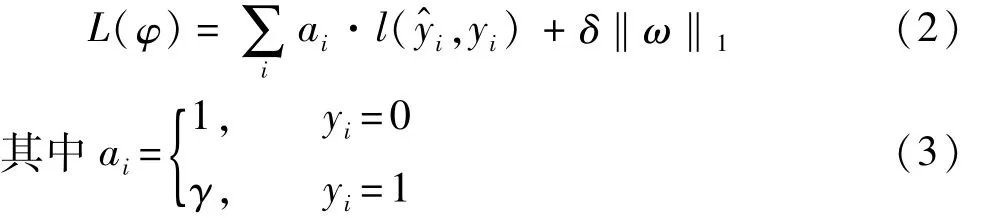
式中:δ‖ω‖1为L1正则化项;ω为该树的参数,可由决策树自动获得;δ为L1正则化系数;ai为类别权重系数;γ为少数类权重系数,出于放大少数类损失的目的,γ应设置为一个大于1的整数。
对于少数类的权重系数γ和L1正则化系数δ,本文中通过贝叶斯优化获得其取值。贝叶斯优化方法[13]假设待优化的参数与目标函数(即模型的损失函数)之间符合某种先验分布,然后通过采集函数不断地加入新的参数样本点,更新拟合出分布形状,找出使分布函数取最小值的参数,它在效率上优于网格搜索,与随机搜索相比,较不容易陷入局部最优。由Bergstra等[14]提出的TPE算法比高斯过程等传统的贝叶斯优化方法可更加高效地找到最优参数,因而本文中使用TPE算法搜索出γ、δ两个参数的最优取值。
(2)降低分类阈值
使用机器学习模型进行预测时,对于每个样本类别的预测结果ypredk为0(无故障)或1(有故障)。实际上,模型对每一个测试样本的预测结果ypredk,是与分类阈值T进行比较后得出的:模型先计算出样本的预测值youtk,它是一个[0,1]区间内的实数值;然后将它与分类阈值T进行比较,若小于阈值则分类为0,否则为1。通常情况下,分类阈值T设置为0.5,因此,标准LightGBM模型的预测结果为

对于式(4),可以理解为:youtk实际上表达了样本为1的可能性;而分类阈值T设置为0.5,意味着模型认为该样本为无故障和有故障的机率相等。然而当数据集中不同类别的样本数量不同时,将阈值设置为0.5显然忽视了数据集类别不平衡的特点。因而,使用“阈值移动”的方法[11],将分类阈值T降至0.5以下,使预测结果尽可能地被分为1,即模型倾向于认为新样本更可能是有故障。本文中将分类阈值T降低至0.01,改进后的LightGBM模型的预测结果为

3 改进LightGBM模型的验证
3.1 汽车故障数据集
本文中所使用的汽车故障数据集由斯堪尼亚货车公司发布[15],包括60 000个训练集样本和16 000个测试集样本,记录了汽车行驶过程中的速度和行驶里程等170个特征,体现出大样本、高维度的特点。样本的类别为有故障和无故障两类,其中有故障样本占少数,例如,训练集中只有1 000个有故障样本,仅占训练集的1/60,所提供的信息量远少于59 000个无故障样本,给汽车故障样本的预测带来很大难度。训练集中的部分数据如表1所示。

表1 训练集中的部分数据
3.2 实验流程
在斯堪尼亚货车故障数据集上进行实验,实验流程如图4所示。改进后的LightGBM模型称为cLightGBM模型,另使用 LightGBM、XGBoost、GBM机器学习模型作为对比。各模型的参数,除设置决策树的个数(n_estimaotrs)为100外,模型的其他参数均使用默认值。运算设备使用3.40 GHz主频、i7中央处理器和8 GK内存的计算机,编程语言为Python。
本实验具体流程如下。
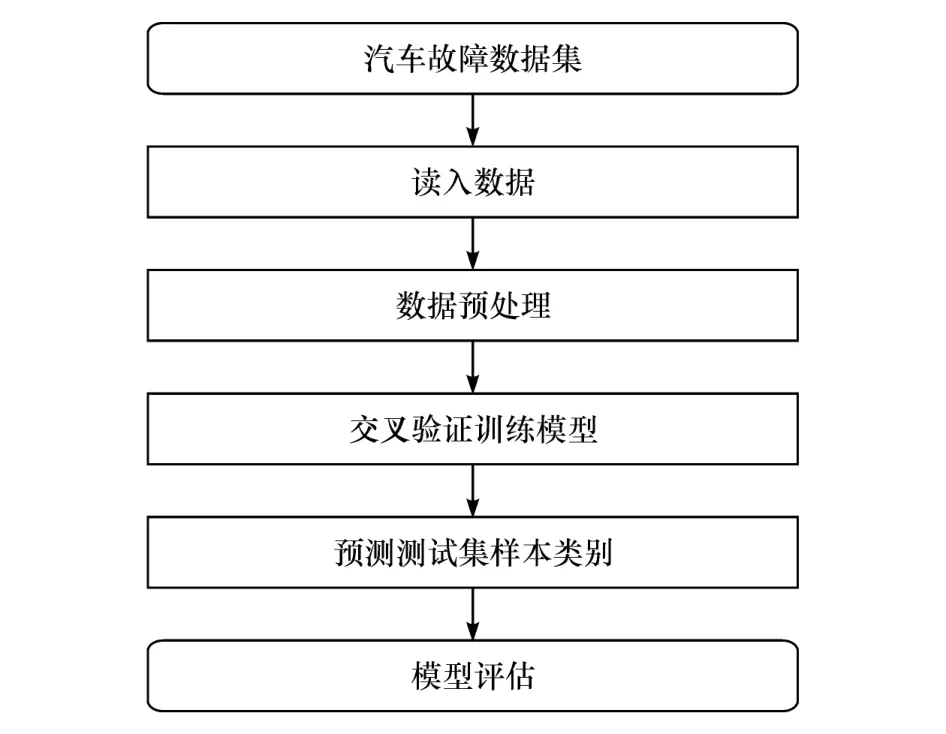
图4 实验流程图
步骤1:读入数据。读取已经划分好的训练集60 000个样本和测试集16 000个样本,检查数据格式。
步骤2:数据预处理。首先进行类别编码,将无故障的样本的类别编码为0,将有故障的样本的类别编码为1。其次处理数据缺失项,删除数据缺失的比例大于70%的7个特征,对于数据缺失比例低于70%的特征,对GBM模型所用数据使用中位数补全,对cLightGBM、LightGBM、XGBoost模型使用缺省方法。
步骤3:交叉验证训练模型。对于训练集的60 000个样本,按照5折交叉验证,分别训练cLight-GBM、LightGBM、XGBoost、GBM模型,并记录训练时长Time。其中,cLightGBM模型少数类权重系数γ、L1正则化系数δ经TPE算法调参后分别设置为57和0.001。
步骤4:预测测试集样本类别。在测试集上,使用训练好的机器学习模型,预测16 000个测试集样本的类别。
完成上述4个步骤后,使用查全率Recall、总体代价Cost作为评价指标,评估预测类别与实际类别之间的差异,验证汽车故障预测模型的有效性。
3.3 评价指标
评价指标通过表2的混淆矩阵[12]定义。混淆矩阵中:TP是被正确分类为有故障的样本数,即有故障的样本被成功预测为有故障;FP是被错误分类为有故障的样本数,即无故障的样本被误认为有故障;TN是被正确分类为无故障的样本数,即无故障的样本被成功预测为无故障;FN是被错误分类为无故障的样本数,即有故障的样本被误认为无故障。可见,TP、TN是被成功预测的样本数,FN、FP是被错误预测的样本数。

表2 混淆矩阵

总体代价Cost度量了被错误预测的样本FN、FP所造成的后果[12]。无故障的样本被误认为有故障,将带来不必要的检修,其分类代价较小,斯堪尼亚货车公司根据其商业经验[7],将FP的分类代价定义为10;有故障的样本被误认为无故障,导致故障车辆继续行驶,其分类代价很大,将FN的代价定义为500。总体代价综合考虑了FN、FP两种错误所造成的后果,总体代价越小,越有助于降低企业运营成本,发挥工程价值。

3.4 实验结果与分析
在测试集上,本文中提出的cLightGBM模型的预测结果如表3所示。测试集的16 000个样本中,共有375个实际有故障的样本,最理想的状态是将375个实际有故障样本全部预测为有故障,即故障查全率Recall为1。使用cLightGBM模型,预测出了370个故障样本的存在,故障查全率 Recall为0.987,接近于理想值。按照式(7),cLightGBM模型的总体代价 Cost为9 030,亦是一个比较理想的数值。
查全率Recall又称之为召回率[12],是实际有故障的样本被机器学习模型预测到的概率,反映了模型对汽车故障样本的预测能力。查全率的取值区间为[0,1],查全率越大,说明模型对汽车故障的预测能力越强。

表3 cLightGBM模型的混淆矩阵
cLightGBM模型与 LightGBM、XGBoost、GBM模型的预测结果对比如表4所示。从查全率Recall来看,cLightGBM模型最高,相比标准型LightGBM模型高出0.235,明显优于其他的机器学习模型,实现了对汽车故障的有效预测。从总体代价的角度,cLightGBM将工程实践中的总体代价降低至9 030,在4种模型中总体代价最小,有助于降低企业的实际运营成本,发挥工程实践价值。此外,从模型训练所需时间可看出,cLightGBM、LightGBM、XGBoost模型在面向大样本、高维度数据时的训练速度比传统的GBM模型均有显著的优势,尤其是cLightGBM、LightGBM模型,两者可在不到15 s内完成对具备170个特征的60 000个样本的训练,体现出很高的训练效率。

表4 不同模型预测结果对比
4 结论
本文中针对汽车故障数据集规模大、类别不平衡引起的模型训练速度慢、故障查全率低的问题,提出一种基于改进LightGBM模型的汽车故障预测方法,得出结论如下。
(1)从模型训练和模型预测两个层面对Light-GBM模型进行改进:通过设置类别权重和引入L1正则化项修正模型损失函数,并使用TPE算法得到修正项系数的取值;在模型预测时,使用阈值移动技术,将分类阈值调整为0.01,提高样本被分为故障样本的概率。
(2)在斯堪尼亚货车故障数据集上进行实验,结果表明,本文中提出的改进LightGBM模型故障查全率达0.987,总体代价为9 030,实现了对汽车故障的有效预测,具备工程应用价值。
(3)与 LightGBM、XGBoost、GBM等模型相比,本文中提出的改进LightGBM模型的故障查全率高,总体代价小,且具备LightGBM模型训练快的优势,展现出一定的先进性。
