基于改进MobileNet网络的人脸表情识别
2020-04-18王韦祥何小海卿粼波王正勇
王韦祥 周 欣,2 何小海* 卿粼波 王正勇
1(四川大学电子信息学院 四川 成都 610065)2(中国信息安全测评中心 北京 100085)
0 引 言
人脸表情识别是计算机视觉领域一大热点[1]。人脸表情作为人类情绪的直接表达,是非语言交际的一种形式[2]。人脸表情识别技术目前主要的应用领域包括人机交互(HCI)、安保、机器人制造、医疗、通信、汽车等。在人机交互、在线远程教育、互动游戏、智能交通等新兴应用中,自动面部表情识别系统是必要的[3]。
人脸表情识别的重点在于人脸表情特征的提取。对于人脸表情的提取,目前已出现两类特征提取方法。一种是基于传统人工设计的表情特征提取方法,如局部二值模式(Local Binary Pattern,LBP)[4]、定向梯度直方图(Histogram of Oriented Gradients,HOG)[5]、尺度不变特征变换(Scale Invariant Feature Transform,SIFT)[6]等,这些方法不仅设计困难,并且难以提取图像的高阶统计特征。另一种是基于深度学习的表情特征提取方法,目前深度神经网络已广泛应用在图像、语音、自然语言处理等各个领域。为了适应不同的应用场景,越来越多的深度神经网络模型被提出,例如AlexNet[7]、VGG[8]、GoogleNet[9]和ResNet[10],这些网络模型被广泛应用于各个领域,在人脸表情特征提取及分类上,也取得了不错的效果。
但随着深度神经网络模型的不断发展,其缺点也逐渐显现。网络模型的复杂化、模型参数的大量化等缺点,使得这些模型只能在一些特定的场合应用,移动端和嵌入式设备难以满足其需要的硬件要求。复杂网络模型对于硬件的高要求限制了其应用场景。基于此,Howard等[11]在2017年4月提出了一个可以应用于移动端和嵌入式设备的MobileNet轻量化网络模型。文中提出的深度可分离卷积层,在保证精度损失不大的情况下,大大减少了网络的计算量,从而为计算设备“减负”。但是这个版本的MobileNet模型在深度卷积层后引入非线性激活函数ReLU,而深度卷积没有改变通道数的能力,其提取的特征是单通道的,且ReLU激活函数在通道数较少的卷积层输出进行操作时,可能导致信息丢失。为了解决MobileNet第一版的问题,2018年1月Sandler等[12]提出第二版的MobileNet,即MobileNetV2。MobileNetV2使用了倒转的残差结构,即在采用当时流行的残差结构的同时,在进入深度卷积前先将输入送入1×1的点卷积,把特征图的通道数“压”下来,再经过深度卷积,最后经过一个1×1的点卷积层,将特征图通道数再“扩张”回去。即先“压缩”,最后“扩张”回去。前两步的输出都采用ReLU激活函数处理,最后一步采用线性输出,可在一定程度上减少信息的丢失。然而此模型应用于实际人脸表情识别中识别效果依然不佳,且参数量和运算量很大,在安卓手机上测试时,实时性表现也不佳。除此之外,MobileNet网络模型的最小输入尺寸为96×96,而人脸表情识别允许更小的输入尺寸,因此MobileNet难以满足实际人脸表情识别的需要。
针对MobileNet的上述缺点,本文设计了一个基于输入尺寸为48×48×1的单通道灰度图片的改进MobileNet模型——M-MobileNet,不仅大大减小了网络模型的参数量和运算量,使其更切合人脸表情识别的特点,还提升了其在人脸表情识别的实时性,除此之外,在CK+及KDEF人脸表情数据集上也取得了较高的识别率。由于MobileNetV2中采用“点卷积-深度卷积-点卷积”结构,其运算量和参数量较直接采用“深度卷积-点卷积”方式更多,MobileNetV2使用的残差网络结构也较直接使用顺序级联方式更复杂,且在实验部分其在人脸表情识别率较其他优秀模型更低。因此为了更好地保留深度卷积后输出的特征,不同于MobileNetV2中“先压缩再扩张”的思想,M-MobileNet在深度卷积层输出后,去掉用于提取非线性特征的激活层,采用线性输出,同时为了提高模型的非线性表达,依然在点卷积后采用ReLU激活函数,在各卷积层之间依然采用顺序级联方式,不使用残差连接方式,即采用本文提出的改进的深度可分离卷积层。另一方面,由于MobileNetV1和MobileNetV2使用Softmax分类器来进行分类,而由于人脸表情特征的特点,表情的类间区分本身就不高,所以Softmax在表情识别领域并不是很合适[13]。而SVM分类器作为一种具有较强泛化能力的通用学习算法,且对大数据高维特征的分类支持较好[14],其中L2-SVM[15]具有较好的可微可导性,故本文网络使用L2-SVM代替MobileNet中Softmax分类器,训练深度神经网络进行分类。实验验证了M-MobileNet网络相比MobileNet网络可以有效提高人脸表情识别的准确率;同时为了验证使用SVM分类器的有效性,还增加了与“M-MobileNet+Softmax”网络模型的对比实验。
1 改进的深度可分离卷积层
传统标准卷积既过滤输入又将过滤后的输出进行组合,最终形成一组新的输出[11],如图1(a)所示。假设输入特征图大小为M×M,通道数为C,标准卷积的卷积核大小为N×N,个数为K,并且假设输出与输入尺寸一致,则经过标准卷积后输出尺寸为M×M,输出通道数为K。传统标准卷积过程,实际上包含了两步:特征过滤和将过滤后的结果组合,图1(b)显示了输入特征图与第i(1≤i≤K)个卷积核进行标准卷积的过程。在这个过程中,首先输入特征图中的每个通道与对应的卷积核的每个通道进行卷积,卷积的结果是形成了C个M×M的单通道特征图,然后将这C个结果合并,最终形成一个M×M×1的单特征图。由于有K个卷积核,因此输入特征图与所有K个卷积核进行标准卷积后,共有K个M×M×1结果,最终结果为M×M×K的输出特征图,如图1(a)所示。标准卷积的计算量为:
M×M×N×N×C×K
(1)

(a) 标准卷积

(b) 输入与第i(1≤i≤K)个卷积核标准卷积过程示意图

(c) 深度卷积

(d) 点卷积图1 标准卷积、深度卷积、点卷积过程示意图
深度可分离卷积则是将标准卷积分解为一个深度卷积和一个点卷积[11],深度卷积过程实际上是将输入的每个通道各自与其对应的卷积核进行卷积,最后将得到的各个通道对应的卷积结果作为最终的深度卷积结果。实际上,深度卷积的过程完成了输入特征图的过滤,深度卷积过程如图1(c)所示,其计算量为:
M×M×N×N×C
(2)
这里的点卷积则是将深度卷积的结果作为输入,卷积核大小为1×1,通道数与输入一致。点卷积过程类似标准卷积,实际上是对每个像素点在不同的通道上进行线性组合(信息整合),且保留了图片的原有平面结构、调控深度。相比于深度卷积,点卷积具有改变通道数的能力,可以完成升维或降维的功能。点卷积过程如图1(d)所示,其计算量为:
M×M×1×1×C×K=M×M×C×K
(3)
因此深度可分离卷积总的计算量为:
M×M×N×N×C+M×M×C×K
(4)
深度可分离卷积与传统标准卷积计算量相比:
(5)
从式(5)可以看出,深度可分离卷积可有效减少计算量,若网络使用卷积核大小为3×3,则深度可分离卷积可减少8至9倍计算量。相比传统标准卷积,这种分解在有效提取特征的同时,精度损失也较小[11]。
在MobileNet网络中,为了更好地表现网络的非线性建模能力,同时为了防止梯度消失,减少了参数之间的依存关系,缓解过拟合发生,深度可分离卷积在深度卷积和点卷积后都使用了ReLU激活函数。同时,为了防止梯度爆炸,加快模型的收敛速度,提高模型精度,在ReLU激活函数前加入BN层,如图2(a)所示。

(a) MobileNet中深度可分离卷积层 (b) 改进的深度可分离卷积层图2 MobileNet及本文深度可分离卷积模型
ReLU定义如下:

(6)
式中:x表示输出,f(x)表示输出。
然而ReLU也有缺陷,它可能会使神经网络的一部分处于”死亡”的状态。假设网络在前向传导过程中如果有一个很大的梯度使得神经网络的权重更新很大,导致这个神经元对于所有的输入都给出了一个负值,然而这个负值经过ReLU后输出变为0,这个时候流过这个神经元的梯度就永远会变成0形式,也就是说这个神经元不可逆转地“死去”了。神经元保持非激活状态,且在后向传导中“杀死”梯度。这样权重无法得到更新,网络无法学习,自然就丢失了信息。而在深度卷积的过程中,由于深度卷积没有改变通道数的能力,其提取的特征是单通道的。而ReLU激活函数在通道数较少的卷积层输出进行操作时,如果出现这种情况就可能导致信息的丢失,所以深度卷积后进行非线性是有害的,甚至可能影响网络的建模能力。为此,文献[12]使用了线性的反转残差网络,然而此网络应用于实际人脸表情识别中效果依然不佳,参数量和运算量依然很大,在安卓手机上测试时,实时性表现也不佳。除此之外,文献[12]中的网络模型允许的输入尺寸与实际人脸表情图像的输入尺寸也不一致,因此MobileNet难以满足实际人脸表情识别的需要。为了避免这些现象的发生,本文提出了一种改进的深度可分离卷积层,即在深度卷积后去掉中ReLU激活函数而采用线性输出,其余与MobileNet中深度可分离卷积层一致,如图2(b)所示。线性输出表达如下:
f(x)=Wx+b
(7)
式中:W表示权重,b表示偏置,x表示输入,f(x)表示输出。
改进后的深度可分离卷积层的计算量与改进前相同,即保留了MobileNet网络中深度可分离卷积可减少卷积计算量的优势。同时,改进后的深度可分离卷积层在深度卷积层后采用了线性输出,使得各通道的信息完全保留下来,从而为后续人脸表情识别提供可靠的人脸表情特征。为了验证使用改进后的深度可分离卷积层的有效性,本文在实验部分对使用未改进的深度可分离卷积层的模型进行了对比。
2 改进的MobileNet网络模型
本文受到MobileNet网络模型启发,结合人脸表情识别的特点,在尽可能在减小网络的计算量并且保持较高的识别率的原则下,设计了一个基于改进深度可分离卷积层输入尺寸为48×48×1的改进MobileNet网络模型M-MobileNet,其网络结构如表1所示。

表1 M-MobileNet网络结构

续表1

(8)
pi的计算公式为:
(9)
根据式(8)、式(9)求得所有7个可能概率,取最大概率对应的类别即为最终预测类别。由于人脸不同表情的类间区分度本身就不高,使用Softmax分类器很可能会产生误判,因此在人脸表情识别方面不宜采用Softmax分类器。针对此问题,M-MobileNet采用L2-SVM作为分类器。在L2-SVM中,对于给定训练数据(xn,yn),n=1,2,…,N,xn∈RD,tn∈{-1,1},带有约束性的支持向量机:
(10)
s.t.wTxntn≥1-ξn∀n
ξn≥0 ∀n
目标函数:
(11)
预测类别为:
(12)
式中:w表示最优超平面法向量,C表示用来调节错分样本的错误比重,ξn表示松弛因子。
由于L2-SVM挖掘不同类别数据点的最大边缘,具有较好的可微可导性,正则化项对错分数据惩罚力度更大[16],且具有较强的泛化能力以及其对大数据高维特征的分类支持较好[14],对于人脸表情特征区分较好,所以本文使用SVM分类器替代MobileNet网络模型中的Softmax分类器对目标进行分类。
改进后的网络模型参数及与MobileNetV1、MobileNetV2的参数对比如表2所示。

表2 本文模型与MobileNetV1、MobileNetV2参数量对比
可以看出,M-MobileNet网络模型参数较MobileNetV1减少90%左右,较MobileNetV2减少88%左右,大大缩减了MobileNet网络模型参数。
3 实 验
3.1 实验环境
本文在PC端上的实验以Keras深度学习框架为基础,以TensorFlow框架作为其后端,编程语言使用Python 3.5,在Windows 7 64位操作系统上进行实验。硬件平台为:Intel Core i5-7500 3.4 GHz CPU,8 GB内存。数据集使用CK+数据集(extended Cohn Kanade dataset)[17]和KDEF数据集(The Karolinska Directed Emotional Faces dataset)[18]。实验中采用Adam优化器优化损失,epoch为100,batch_size为32。
本文的移动端的实时性实验在小米8手机上进行,CPU为骁龙710,内存6 GB,操作系统为Andriod 9.0。编程语言为Java。
3.2 数据集选取
本文在CK+数据集上分别进行6分类和7分类实验,在KDEF数据集上进行7分类实验。
CK+数据集包括123名年龄在18~30岁之间的593个表情序列。其中,带标签的表情序列有327个,为了避免引起误会,余下不确定的表情序列不带标签。标签总共有7类,包括:“快乐”,“悲伤”, “愤怒”,“惊讶”,“恐惧”,“厌恶”和“蔑视”。每个带标签的表情序列仅有一个标签。每个表情序列都是以中性表情开始,以对应峰值表情结束。在7分类实验中,为了比较本文模型和目前国际上在CK+数据集上识别率处于领先地位的模型的准确率,在本实验中,采用国际上比较通用的数据集选取和结果验证方式,即选用所有带标签的表情序列中的最后三帧,总共得到了981幅图像的实验数据集,其表情选取数量分布如表3所示。然后将数据集进行交叉验证,国际上常见的交叉验证策略包括8折交叉验证、10折交叉验证等,本文采用10折交叉验证策略。同理,在6分类实验中,除了数据集选取不同外(6分类实验中舍弃了蔑视表情),其他步骤与7分类实验一致。

表3 CK+数据集7分类实验样本选取数量分布
KDEF数据集包括了20~30岁年龄段的70位业余演员(35位女性和35位男性)的7类表情图像,共有4 900幅,拍摄角度包括正负90度、正负45度以及正面角度。本文选用正面角度图像进行实验,其数量分布如表4所示。同样采用10折交叉验证策略。

表4 KDEF数据集实验样本选取数量分布
3.3 人脸表情图像预处理
原始数据集的原始图像中包含了大量与人脸表情特征无关的冗余信息,且图像较大,因此不适合直接用于网络训练。因此在训练之前,对输入图片进行预处理是必要的。图3显示了图像预处理前和处理后的人脸表情图像示例。

图3 预处理前后的人脸表情图像示例
预处理过程如图4所示,首先根据输入图片类型判断是否转换成单通道灰度图,若图片已经是单通道灰度图,则直接转到一下步,反之则进行转换。然后对上一步的输出图像进行人脸检测,确定人脸区域。最后根据人脸区域对图像进行裁剪,将其裁剪至大小为48×48的单通道灰度图。

图4 图像预处理流程图
3.4 实验结果及分析
3.4.1CK+数据集7分类
本文按照表1所设计的网络模型进行训练,将预处理后的图片输入网络,采用10折交叉验证策略对网络性能进行评估。表5显示了本文模型与其他国际上在CK+数据集(7分类)准确率上取得领先水平的算法模型的对比结果,同时也对比了M-MobileNet+Softmax、MobileNet+Softmax、MobileNet+SVM、MobileNetV2四种网络模型的准确率。

表5 不同算法模型在CK+数据集(7类)上的准确率对比
可以看出,使用本文网络M-MobileNet提取特征后,无论是使用Softmax分类器还是SVM分类器,其准确率都高于其他模型,说明M-MobileNet网络具有良好的特征提取能力。而相比于传统未改进的MobileNet网络模型,M-MobileNet+Softmax网络模型高于未改进前0.93%,且本文最终模型M-MobileNet高于未改进前0.41%,说明改进的深度可分离卷积层相比未改进的深度可分离卷积层可以有效提高网络的识别率。从M-MobileNet、MobileNet+Softmax、MobileNetV2的准确率来看,M-MobileNet高于MobileNetV2网络1.13%,高于MobileNet+Softmax网络1.03%,说明M-MobileNet提高了MobileNet在人脸表情上的识别率。从M-MobileNet+Softmax网络及M-MobileNet网络的准确率来看,使用SVM分类器高于使用Softmax分类器0.1%,说明使用SVM分类器可以提高模型识别的准确率。
3.4.2CK+数据集6分类
本文比较了目前国际上对CK+数据集作6分类准确率较为领先的模型,同样采用10折交叉验证策略对网络性能进行评估。表6显示了本文模型与其他国际上在CK+数据集6分类准确率上取得领先水平的算法模型的对比结果,同时也对比了M-MobileNet+Softmax、MobileNet+Softmax、MobileNet+SVM、MobileNetV2四种网络模型的准确率。
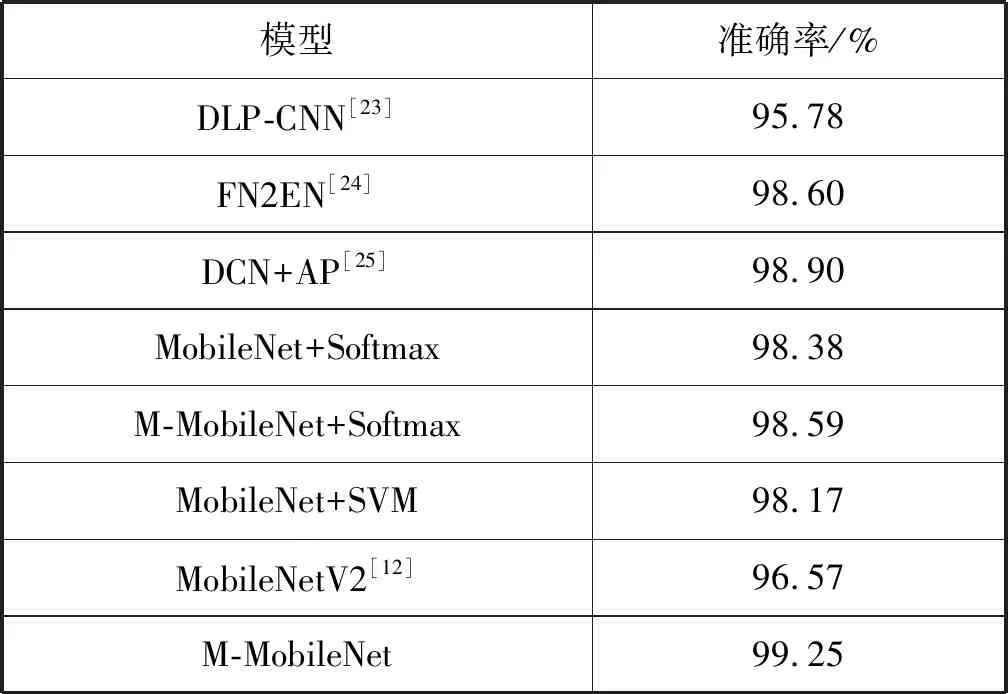
表6 不同算法模型在CK+数据集(6类)上的准确率对比
可以看出,无论是使用Softmax分类器还是使用SVM分类器,使用基于改进的深度可分离卷积的M-MobileNet网络的模型的准确率都高于使用未改进的深度可分离卷积的模型,再次证明模型中使用改进的深度可分离卷积层相比使用未改进的深度可分离卷积层的网络模型可以有效提高模型的识别率。从M-MobileNet、MobileNet+Softmax、MobileNetV2的准确率来看,M-MobileNet高于MobileNetV2网络2.68%,高于MobileNet+Softmax网络0.87%,进一步证明M-MobileNet提高了MobileNet在人脸表情上的识别率。而虽然在7分类实验中使用SVM分类器相比使用Softmax分类器模型识别的准确率仅提高0.1%,但是在6分类实验中M-MobileNet网络与M-MobileNet+Softmax网络相比,其准确率提高了0.66%,明显提高了模型识别的准确率,说明使用SVM分类器能提高网络模型对人脸表情的识别准确率。而本文最终网络模型M-MobileNet对表情分类的准确率高于表中其他模型。
3.4.3KDEF数据集
本文模型在KDEF数据集的实验结果及与其他算法模型对比如表7所示。

表7 不同算法模型在KDEF数据集上的准确率对比
可以看出,本文模型M-MobileNet准确率最高,高于表中所有其他模型,说明本文模型具有较好的识别性能。M-MobileNet网络模型准确率高于M-MobileNet+Softmax 0.73%,MobileNet+SVM高于MobileNet+Softmax 0.27%,说明使用SVM分类器相比Softmax分类器可以有效提高准确率;M-MobileNet网络模型的准确率高于MobileNet+SVM 1.03%,M-MobileNet+Softmax网络模型的准确率高于MobileNet+Softmax 0.58%,说明使用改进后的深度可分离卷积模型可以提高深度可分离卷积层的网络模型的准确率,进一步证明使用改进后的深度可分离卷积可以尽可能防止信息丢失。而M-MobileNet准确率高于MobileNetV2模型1.53%。
3.4.4移动端实时性
为了验证本文模型在移动端的实时性能,本文还在移动端上对比了M-MobileNet与MobileNetV1、MobileNetV2模型在小米8手机上的实时性表现,在CK+数据集上选取7种表情各一幅典型表情的图像进行预测,表8显示了各个模型预测1 000次后的结果。

表8 本文模型与MobileNetV1、MobileNetV2移动端表现对比
从表8可以看出,M-MobileNet网络无论是使用Softmax分类器还是SVM分类器,其实时性都比MobileNetV1、MobileNetV2好很多,说明本文模型相比MobileNetV1、MobileNetV2模型具有更好的实时性,结合表2可知,本文模型不仅减少了网络参数,同时还提高了实时性性能。同时从预测时间可以看出,M-MobileNet+Softmax及M-MobileNet二者预测时间都小于40 ms,可以看出二者都具有较好的实时性,考虑到二者预测时间相差不大,而在准确性实验中SVM分类器具有更好的准确率,因此本文最终采用SVM分类器。
4 结 语
本文提出了一种改进的MobileNet模型M-MobileNet用于人脸表情特征提取及分类。在M-MobileNet网络模型中,通过使用改进的深度可分离卷积层保证了网络的轻量级特性,解决了深度卷积的输出使用非线性激活函数而可能导致信息丢失的问题,提高了网络的特征提取能力。同时为了有效对表情进行分类,使用SVM分类器对人脸表情进行分类,提高了网络对于人脸表情的识别准确率。实验结果表明,本文模型不仅提高了模型的准确率,还实现与现有其他人脸表情识别模型更好的识别性能。在安卓手机上的实验证明,本文模型具有相较于改进前具有更好的实时性。与其他当前优秀算法模型的比较,也看出本文网络模型能够获得更好的识别率,说明其具有良好的应用价值。
