基于时段-时长耦合LDA的用户收视行为挖掘
2020-04-18顾军华李晓雪
顾军华 李晓雪 杨 亮
1(河北工业大学人工智能与数据科学学院 天津 300401)2(河北省大数据计算重点实验室 天津 300401)3(河北工业大学电子信息工程学院 天津 300401)
0 引 言
IPTV[1]是随着互联网发展出现的一种崭新技术。IPTV利用宽带网将多媒体信息传递给用户,为用户提供包括数字电视在内的多种交互式服务。它在传统电视的基础上,加入点播、回看等交互功能,使得电视观众与电视服务提供商之间有了更好的互动。为了给用户提供更好的收视服务,电视服务提供商可以通过大数据分析用户行为,为用户建模。IPTV用户行为建模可以通过分析用户行为来优化网络规划,进而提升IPTV系统的性能[2-3];可以通过挖掘用户收视兴趣,给IPTV用户提供诸如个性化电子菜单、节目推荐[4-5]、个性化情景广告[6]等服务,以此提升用户收视体验。
现有的用户收视行为建模方法大致可以分为两类。一类是通过适当抽象节目类别信息,将收看节目归纳为不同类型,从而建立用户兴趣模型[7]。其中,AIMED模型[8]是一种利用人工神经网络技术结合用户的活动、兴趣和心情等属性构建的推荐模型,该模型可以预测用户对电视节目的偏好。另一类方法是基于主题模型LDA[9]算法的改进。例如,隐式反馈LDA模型[10]结合IPTV用户收视过程中的点播、收藏和浏览等行为,采用LDA联合建模为用户做推荐。TMUD模型[11]将两个LDA模型通过主题连接成为一个统一的模型,用于相似用户群分组和电视节目推荐。考虑到一个IPTV用户对应一个家庭,不同的家庭成员会在不同时段观看节目,张娅等[12]提出基于时间耦合主题模型(cLDA)的IPTV用户建模方法,该模型通过对用户收视节目与收视时间点的联合建模,挖掘IPTV用户在每个时段的收视兴趣主题。
以上基于LDA模型的改进算法在用户行为建模方面取得了良好的效果,但这些方法忽略了对节目观看时长的利用,而节目的观看时长在很大程度上反映用户对节目的喜爱程度。基于此,本文提出一个新的时段-时长耦合LDA(Time-Duratioan Coupled LDA)模型。TDC-LDA模型是一个概率生成模型,其中用户兴趣主题和收视时段隐变量可同时生成收视记录中的所看节目、观看时间点与时长。每一个IPTV用户可以用一个时段-兴趣主题的联合分布来表示,称之为用户行为模式。
1 LDA模型
LDA是Blei等学者于2003年提出的一种基于概率模型的文本主题建模方法,可以识别庞大文档集或语料库中的隐藏主题信息,被广泛应用于信息检索、自然语言处理等领域[13~15]。LDA的图模型如图1所示,该模型假设文章是由多个主题以不同比例混合而成,每个主题可以用多个词的概率分布表示,文章中的每一个词都是由一个潜在主题生成。

图1 LDA概率图模型
用LDA模型挖掘用户收视兴趣的原理如下:
将一个IPTV用户的观看记录当成一篇文档,IPTV用户观看的电视节目当成文档中的词。假设IPTV用户在观看节目时有多个收视兴趣主题,兴趣主题可以表示为一些电视节目的分布,那么用户m从大量IPTV数据中选择观看节目的生成过程可以描述如下:


(3) 对于第m个用户中的任意一个收视纪录n,其中n∈{1,2,…,Nm}:
① 根据兴趣主题的多项式分布,选择一个主题zm,n~Multinomial(θm);
② 根据选择出的主题对应的电视节目多项式分布,生成电视节目wm,n~Multinomial(φzm,n)。


表1 论文中用到的符号

续表1
LDA模型能捕捉到IPTV用户的收视兴趣分布,但是用于IPTV用户行为模式挖掘有较多的缺陷。第一,一个IPTV用户对应一个家庭,一个家庭由不同的成员组成。LDA模型只能挖掘到一个家庭的收视兴趣,但无法挖掘到每个家庭成员的兴趣。第二,家庭成员可能选择在不同的时段观看电视,因此一个IPTV用户在不同时段的兴趣爱好可能会不相同。比如:儿童在放学后喜欢观看动画片,爷爷奶奶喜欢在下午观看戏曲类节目,年轻人喜欢在晚上观看各类娱乐节目。LDA模型无法挖掘到用户在不同时段的收视兴趣。第三,用户在观看电视节目时,对每个节目的观看时长不尽相同,而观看时长是体现用户收视兴趣的重要因素,LDA无法刻画收视兴趣主题随观看时长的变化。
2 TDC-LDA模型
为了更好地挖掘用户行为模式,对IPTV电视节目每周的收视周期性展开研究。本文使用的IPTV数据由天津电视台IPTV运营商提供,用户收视历史数据由服务器端收集用户的操作记录形成。图2展示了一部动画节目、一部爱情剧和一档综艺节目在两周内的收视曲线,其中横坐标记录了每周周一的起始时间,观看次数以四小时为间隔进行统计,纵坐标记录了每个节目一小时的播放次数。该曲线有较强的周期性,其周期为一周。假设同一类节目会在固定的时段被收看,不同家庭成员看电视的时段不同,在同一时段用户倾向于观看同一类型的节目,用户对节目的观看时长体现了他对节目的喜爱程度。基于上述假设,IPTV用户观看行为有如下几个特点:
(1) 一个IPTV用户有一个或多个成员;
(2) 每个成员有多种不同的收视兴趣;
(3) 每个成员倾向于在每周的特定时段看电视;
(4) 用户对某个节目的观看时长越长,则对这个节目的喜爱程度越高。
基于上述分析,本文将LDA模型中的兴趣主题分布θm扩展为表示用户收视兴趣、时段与时长的行为模式分布,建立TDC-LDA模型。表2是LDA模型推广到TDC-LDA模型后θm的变化。在LDA模型中,每个IPTV用户的兴趣主题分布不区分时段。而TDC-LDA模型中,每个IPTV用户会因时段的不同而有不同的兴趣主题分布,且兴趣主题分布受观看时长影响。

表2 主题分布向量θm
值得说明的是,本文中的时间点服从多项式分布而不是连续分布。在基于时间的主题模型TOT[16]中,时间为连续分布,它可以在很长的非周期性时间跨度内生成单峰时间分布,但很难描述如图2所示的具有周期性和多峰的分布。多项式分布可以轻松地将时间点聚合在一起,生成时段,如“工作日早晨”、“周末午夜”等。因此,时段对应的时间点由多项式分布生成。
2.1 模型生成
TDC-LDA模型是一个概率生成模型,它是对LDA模型的拓展,模型如图3所示。假设有K个兴趣主题,Vm个不同的电视节目,兴趣主题对应的电视节目多项式分布描述成K×Vm维的矩阵Φ,φk,vw是节目vm属于主题k的概率。同样,假设有L个时段(时段指一些特定的时间区间,例如,工作日17:00-19:00),Vt个不同的时间点。时段对应的时间点多项式分布描述成L×Vt的矩阵Ψ,ψl,vt是时间点vt属于时段l的概率。

图3 TDC-LDA概率图模型
每一个IPTV用户对应一个描述兴趣主题、时段与观看时长的多项式分布,用户收看的节目、观看时间点以及观看时长为该用户的行为模式。具体来讲,行为模式是指用户选择在哪个时段收看哪种类型的节目以及其收看时长,其中用户对节目的观看时长体现了他对这个节目的喜爱程度。把K×L维的行为模式矩阵分解成KL维的向量θm。θm中第z项代表一个IPTV用户在zm,n,1时段选择兴趣主题zm,n,2这个行为并且观看时长为dm,n的概率。其中zm,n,1、zm,n,2的计算公式如下:
(1)
对于用户m,用TDC-LDA模型选择观看时间点、观看节目与观看时长的过程如下所示:
(2) 根据Dirichlet分布选择时段的时间点分布ψl~Dir(γ),其中l∈{1,2,…,L}:
(4) 对于m用户中每一个收视纪录n,其中n∈{1,2,…,Nm}:
① 根据该用户的行为模式多项式分布,选择一个行为模式zm,n~Multinomial(θm);
② 根据选择的行为模式对应的时段找到这个时段生成时间点的多项式分布,然后根据时段对应的时间点分布生成时间点tm,n~Multinomial(ψzm,n,1);
③ 根据选择的行为模式对应的兴趣主题找到这个主题生成电视节目的多项式分布,然后根据主题对应的电视节目分布生成电视节目wm,n~Multinomial(φzm,n,2);
(2)
2.2 模型拟合

(3)
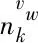

(4)
同理,对兴趣主题-电视节目分布矩阵Φ和时段-时间点分布矩阵Ψ有如下公式:
p(φk|z,w,β)=Dirichlet(φk|nk+β)
(5)
p(ψl|z,t,γ)=Dirichlet(ψl|nl+γ)
(6)
通过对上述Dirichlet分布的期望求解,得到:
(7)
(8)
(9)
TDC-LDA模型的Gibbs采样过程如算法1所示。
算法1TDC-LDA算法
输入:用户收视数据、K(兴趣主题数)、L(时段数)、α、β、γ、Niter(迭代次数)
输出:用户-行为模式分布矩阵Θ、兴趣主题-电视节目分布矩阵Φ和时段-时间点分布矩阵Ψ
00:%初始化
02:for 每一个用户m∈{1,2,…,M} do
03: for 用户m中每一个观看行为n∈{1,2,…,Nm} do
05: 根据采样的zm,n用式(1)求得兴趣主题索引k和时段主题索引l
07: end for
08: end for
09: %Gibbs采样
10: foriter=1 toNiterdo
11: for每一个用户m∈{1,2,…,M} do
12: for用户m中每一个观看行为n∈{1,2,…,Nm} do
13: %对于当前行为模式zm,n=i
18: end for
19: end for
21: end for
22: 根据式(7)-式(9)计算Θ、Φ、Ψ
3 实 验
本节主要介绍实验中使用的数据集并分析TDC-LDA模型的实验结果。实验中,α、β、γ设置为0.1。首先,对比TDC-LDA、cLDA与LDA模型在挖掘兴趣主题与时段方面的不同,验证TDC-LDA模型的优势。然后,对同一节目不同观看时长的用户群体的兴趣主题分布求平均,通过对比不同用户群体的兴趣主题分布展现了TDC-LDA模型挖掘到的兴趣主题随观看时长增加而递增的特性。通过分析一个儿童与主妇主导型家庭的观看数据与实验结果的吻合度来证实该模型的有效性。最后,分别用LDA、cLDA与TDC-LDA模型为用户推荐节目,通过计算困惑度,证明TDC-LDA在执行推荐任务上有更高的准确度。
3.1 实验数据集
实验中使用的IPTV数据由天津电视台IPTV运营商提供。服务器端收集用户的操作记录形成IPTV用户收视历史数据。整个数据集包含2 480个用户,7 857个电视节目,同一个电视节目中的不同集数视为同一个节目。本文仅提取用户的观看节目名称、观看时间点、观看时长等信息。表3展示了一些用户的观看记录样例,每一条记录包含用户ID、节目的开始时间点、节目名称和观看时长。本文将时间点改成“星期-时”的形式,不同的时间点Vt总共是7×24个。只保留观看时长超过3分钟的观看记录(节目的平均观看时长是35分钟)。换句话说,如果用户相邻观看记录之间的时间间隔小于三分钟,则删除上一个观看记录。通过对数据的处理,最终得到2 447个用户从2014年12月到2015年2月在5 925个节目上的106 599 085条观看记录。
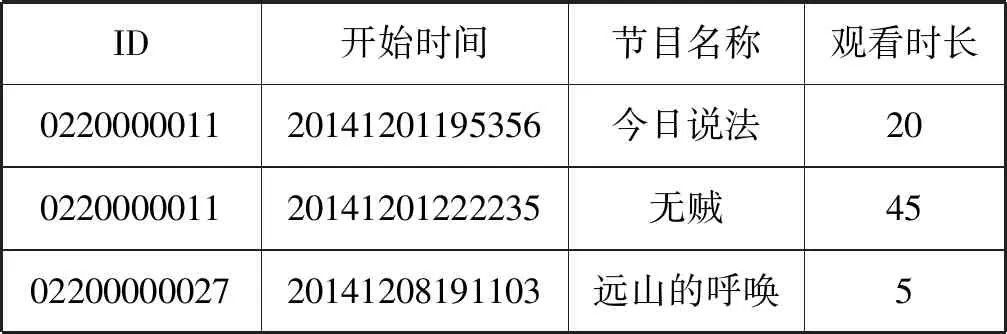
表3 IPTV用户观看行为记录样例
3.2 兴趣主题与时段挖掘
本节根据LDA、cLDA、TDC-LDA模型在实验数据集上运行的结果,分析三个不同模型在兴趣主题发现与时段挖掘上的异同。实验中根据经验将每一个模型的兴趣主题K设为50,cLDA与TDC-LDA的时段L设为8。
3.2.1兴趣主题挖掘
三种模型得到的兴趣主题基本都是由一些相关性比较强的节目以不同比例混合而成,如表4所示。但是不同模型中相同主题的电视节目分布不同。由于LDA与cLDA模型得到的结果基本一致,所以只分析TDC-LDA模型与cLDA模型的不同。
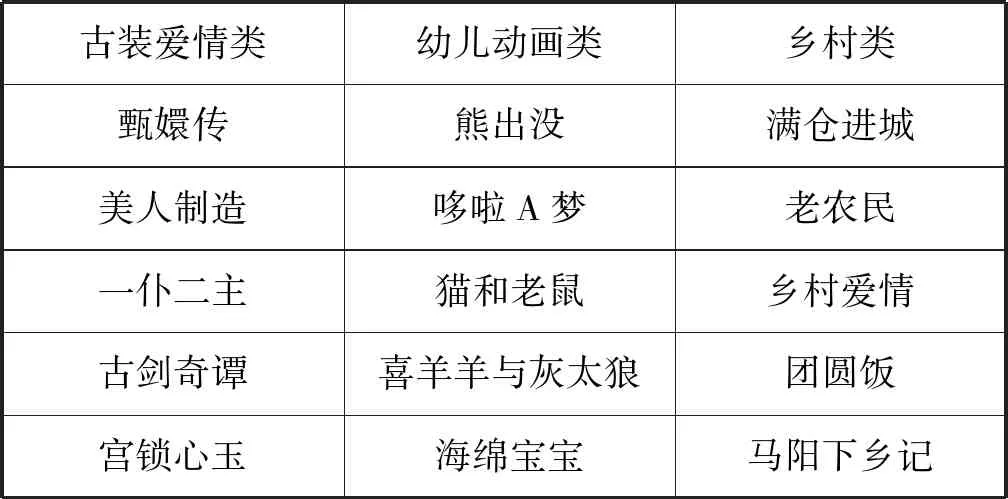
表4 兴趣主题对应的节目
为了证明TDC-LDA模型加入观看时长后挖掘到的兴趣主题分布与真实情况更加接近,先对IPTV数据中所有电视节目的观看总时长与观看总次数做统计。然后通过古装爱情这一兴趣主题的节目分布来对比两种模型挖掘到的兴趣主题的不同。表5是一些古装爱情类电视节目的观看总次数与观看总时长的统计数据,表6列出了两个模型挖掘到的古装爱情主题的电视节目分布。

表5 电视节目的观看总次数与观看总时长

表6 两种模型中古装爱情主题的电视节目分布
由表6可以看出,两个模型在古装爱情这一兴趣主题里包含的主导电视节目基本一致,但每个节目所占的比率不同。通过表5中电视节目的观看次数与观看时长可以看出,“甄嬛传”“美人制造”“一仆二主”等节目更受欢迎,在该主题下应有更高的概率,这与TDC-LDA模型得出的结果基本一致。而cLDA模型本身不考虑观看时长,兴趣主题的节目分布与实际情况有出入。此外,cLDA模型在该主题下还出现一些不相关的节目,如“频道包装”,且占有较高的概率。
3.2.2时段的挖掘
由TDC-LDA和cLDA产生的时间点信息如图4所示。图中将一周的时间点总共分为8个时段,用序号“0-7”来标记,相同时段的时间点用同种填充图案标记。

(a) TDC-LDA时段行为模式

(b) cLDA时段行为模式图4 TDC-LDA与cLDA的时段行为模式
从图4中可以清楚地看出,一周的时间点被划分为上午、下午、晚上等时段。时段的划分完全由TDC-LDA与cLDA模型根据用户收视记录挖掘得到,没有加入任何先验信息。工作日的18时被单独划分出来,是因为通常学生在18时放学到家,开始看电视。LDA中没有时间点因素,在此不作比较。cLDA和TDC-LDA都可以将一周中的时间点划分为不同时段且基本合理,但是根据对IPTV数据的统计分析可以证明,TDC-LDA模型挖掘到的时段信息与实际情况更贴近一些。第一,经过统计发现,早上6时至8时之间是新闻类节目的收视高峰期,并且在周末的时候人们倾向于晚起;第二,18时是动画类节目的收视高峰期;第三,19时也是一个看电视的高峰期,这时候用户倾向于观看一些新闻类的节目。
分析图4可知,TDC-LDA对于早上新闻类节目收视高峰期的时段挖掘是准确的,而且可以将18时与19时两个时段成功分开。cLDA对于这三个时段的挖掘并不准确,且时段2与时段1和时段3有交叉错乱之处。
3.3 兴趣主题随观看时长的变化
本节通过比较观看时长不同的用户群体的平均兴趣主题分布,分析TDC-LDA与cLDA模型的兴趣主题分布与观看时长的关系。将每个电视节目的观看用户分为4类,分别为观看该节目时长3~10分钟、10~17分钟、17~30分钟以及观看时长30分钟以上的用户,时长类别简记为短、次短、中、长。用实验得出的θm来描述每个用户,通过对每类用户的θm求平均,并用图5所示的方式展现出来(图中为电视节目“海绵宝宝”所对应的4类用户的平均兴趣主题分布,TDC-LDA中的θm消除时段的影响,从400维折合到50维,即50个兴趣主题上。兴趣主题15与兴趣主题21用黑色圆点进行标记)。

(a) LDA

(b) TDC-LDA图5 两种模型中不同用户群体的平均兴趣主题分布
实验中,仅保留满足以下两个条件的节目:第一,通过用户对该节目观看时长的不同,使用上面的分类方式将用户分为4类群体;第二,该节目至少被20个以上的用户收看。通过前面条件的过滤,得到899个节目中不同用户群体的兴趣主题分布。从一些节目中可以比较明显地看出,TDC-LDA拟合效果与实际更相符。
根据图5分析,随着用户对节目观看时长的增加,其兴趣主题分布的变化。假设用户观看某个节目的时长越长,则对这个节目的喜好程度越高,那么第四组用户的平均兴趣主题分布和真实数据应该最接近。
表7列出了兴趣主题15和兴趣主题21的一部分电视节目分布,由表可知,“海绵宝宝”属于兴趣主题21,是一部动画类节目。从图5可以看出,在LDA模型中,4类用户在主题21上有着大小不一的概率,每一类用户对某个兴趣主题的喜爱程度没有一个确切的规律。而在TDC-LDA模型中,随着用户观看时长的增加,兴趣主题21的概率逐渐增长,尤其是第4类用户,观看兴趣比较明显,偏向于兴趣主题15与兴趣主题21。兴趣主题21是动画类主题,其中“海绵宝宝”在该主题下概率最高,兴趣主题15是动画片与娱乐类主题。通过分析可知,TDC-LDA可以准确地挖掘到兴趣主题分布随观看时长的变化,这与实际情况相符。

表7 两个动画类主题的电视节目分布
3.4 案例分析
前面已经对TDC-LDA在挖掘兴趣主题与时段方面的优势做了详细论述。本节通过一个具体用户(记为M)的观看数据与模型实验结果,对比TDC-LDA与cLDA模型在挖掘用户行为模式上的优劣。表8列出了用户M用TDC-LDA模型生成的用户行为模式,表中的时段与图3(a)中标注的时段相同,只列出了三种概率最高的行为模式。表9分别列出了用TDC-LDA与cLDA模型挖掘到的三个概率最高的兴趣主题概率分布(为方便进行比较,对每个兴趣主题上不同时段的概率值进行加和,得到用户的兴趣主题概率分布)。图6展示了用户M平时观看最多的5个节目以及每个节目的观看次数和观看时长(其中时长按十分钟一个单位统计)。
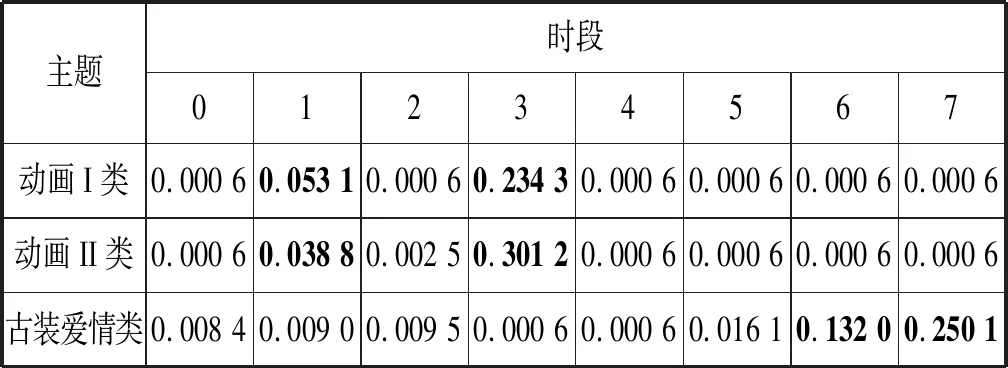
表8 TDC-LDA生成的行为模式
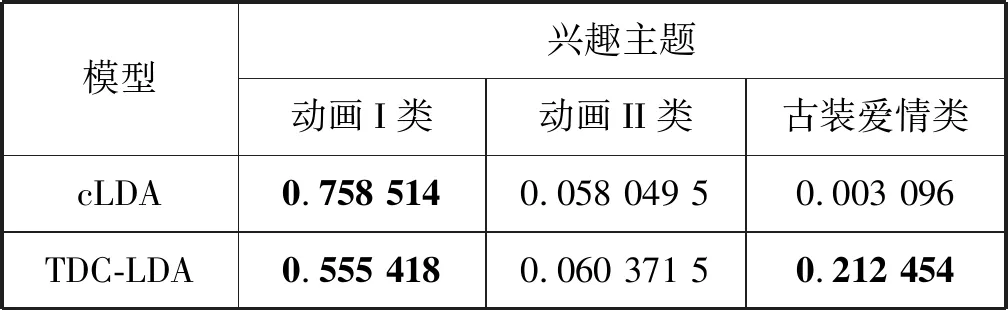
表9 用户M的兴趣主题概率分布

图6 用户M观看最多的5个节目的观看次数与时长
分析图6可知用户M是一个以儿童与家庭主妇主导收视兴趣的混合型家庭,观看的主要节目是动画类节目与古装爱情类节目,其中动画类节目为主,古装爱情类节目为辅。由表8可知,该用户倾向于在16时至17时收看动画类节目,在20时至23时收看古装爱情类节目。由表9可知,cLDA只挖掘到用户M的动画I类兴趣主题,并且该主题占有很高的概率,成为绝对主导主题。TDC-LDA模型中,用户的收视兴趣在动画I类与古装爱情类主题上都占有较高的概率。由图6用户观看节目的统计数据可知,“甄嬛传”这个节目有较高的收视时长,但是观看的次数相对少一些,可能导致cLDA模型无法准确地挖掘到用户对这一类节目主题的喜好。图7按照观看频次与观看时长分别对用户观看兴趣分布进行研究,然后给出两个模型的用户兴趣主题分布实验结果。图7(b)是通过统计得到的用户真实的兴趣主题分布,可以明显地看出,TDC-LDA挖掘到的用户兴趣主题更接近实际情况。

(a) 观看频次结果 (b) 观看时长结果

(c) cLDA模型结果 (d) TDC-LDA模型结果图7 四种方式得到的用户兴趣主题分布
现实生活中,儿童的观看行为与成年人不太相同。第一,儿童观看的节目类型时长普遍较短,而成年人观看的节目时长较长,尤其一些纪录片、综艺类节目。第二,儿童不太容易集中注意力去有始有终地观看一个节目,成年人一般有自己固定的收视规律与喜好,每次观看时长较长。根据这些分析,cLDA中单单考虑观看次数来衡量用户对某个兴趣主题的喜好是不太准确的。由此可见,TDC-LDA模型中引入观看时长这一项是非常必要和有效的。
3.5 困惑度分析
本节用时段-时长耦合LDA模型在数据集上执行推荐任务,并计算LDA、cLDA、TDC-LDA模型的预测困惑度(predictive-perplexity)。推荐任务的目标是预测IPTV用户在特定的时段打开电视时会收看什么节目。实验中,将IPTV用户分为训练集和测试集。训练集包括每个用户除最后一个收视行为记录外的所有记录。测试集由每个用户的最后一个收视行为记录构成。推荐任务要完成的是通过每一个用户最后一个收视行为记录的时间点来预测用户收看的节目。预测困惑度指标定义如下:
predictive-perplexity(Dtest)=
(10)
式中:Mtest是测试集中用户数目。困惑度越低表示模型泛化性能越好,推荐更准确。实验中,令cLDA与TDC-LDA的时段L=8,通过将兴趣主题K设置为不同的值来比较不同模型的困惑度,如表10所示。由表可知,TDC-LDA、cLDA、LDA模型的推荐效果依次降低。这说明,在挖掘用户不同时段的收视兴趣时加入用户观看时长信息是非常有必要的。

表10 预测困惑度
4 结 语
本文提出了一种全新的TDC-LDA模型。该模型的观看节目与观看时间点由Dirichlet分布生成,观看时长由指数分布生成,通过Gibbs采样对隐变量进行推断进而得到用户的兴趣主题与收视时段分布,进而可以挖掘到用户在不同时段的收视兴趣。最后,在天津电视台IPTV用户数据集上进行验证,实验结果表明,TDC-LDA模型可以更加精确地挖掘到用户的观看兴趣主题与收视时段信息,在IPTV节目推荐任务中,TDC-LDA模型也明显优于cLDA模型。
虽然TDC-LDA模型考虑了用户的观看节目、观看时间点、观看时长等信息,但是IPTV用户收视过程中还有很多其他信息,比如收藏、浏览、回看等。之后,我们将考虑通过融入各类用户互动信息进一步提升模型的鲁棒性和灵活性。
