基于分组卷积的密集连接网络研究
2020-03-30康一帅
康一帅,王 敏
(江苏科技大学 电子信息学院,镇江 212003)
近年来,深度学习特别是卷积神经网络(convolutional neural networks, CNNs)凭借其强大的特征提取能力,无论是在视觉识别[1-4](如图像分类)还是在目标检测、语音识别[5]等领域都得到了广泛应用.最近研究[6-7]表明卷积神经网络中存在大量冗余,逐层连接的模式使得网络中的每一层仅仅依赖于它上一层的特征.文献[8]提出的密集连接的卷积网络(DenseNet),通过任何两层之间的直接连接加强特征的传递,同时更有效地利用了特征.尽管DenseNet的优势很明显,但是当假设后面的层不需要前面层的特征时,密集连接仍会引入冗余.
为了降低计算复杂度和模型复杂度,文中提出一种分组卷积的密集连接网络(GDenseNet),通过将每个3×3卷积层的filter(滤波器,也称为卷积核)拆分成几个组来减少模型复杂度,然后引入一个更加细致和高效的网络模型体系结构来降低计算复杂度.
1 相关工作
1.1 高效的网络结构
目前有许多卷积网络可以实现端到端(end-to-end)的训练,如MobileNet[9]和ShuffleNet[10],都是可以部署在移动设备上的高效的网络,并且都使用了深度可分离卷积(depth-wise separable convolutions),大大减少了模型复杂度而使精度仅有微小损失.但是,它们的一个不足之处是在大多数深度学习平台上还无法很好地支持深度可分离卷积.相比之下,GDenseNet使用支持良好的分组卷积[11]操作,从而提高计算的效率.
1.2 高效的优化方法
知识精炼[12](knowledge distillation)方法先训练出一个“教师”网络,然后通过迁移学习的方式把其迁移到一个较小的“学生”网络上,从而“学生”网络能够具备与“教师”网络相似的性能效果,同时很大程度上节省计算资源.动态推断[13-14]方法使推断适应每个特定的测试样例,跳过一些单元甚至是整个层以减少计算.
1.3 密集连接卷积网络
DenseNet[8]由数个密集块(dense blocks)组成,而每个密集块又由多个层构成.每一层的输入是同一密集块中所有之前层生成的特征图的串联,而输出是k个特征图,这里的k被称为网络的增长率(growth rate),即第l层的输入是(l-1)*k个特征图.如图1(a),每一层都有一系列的变换操作.
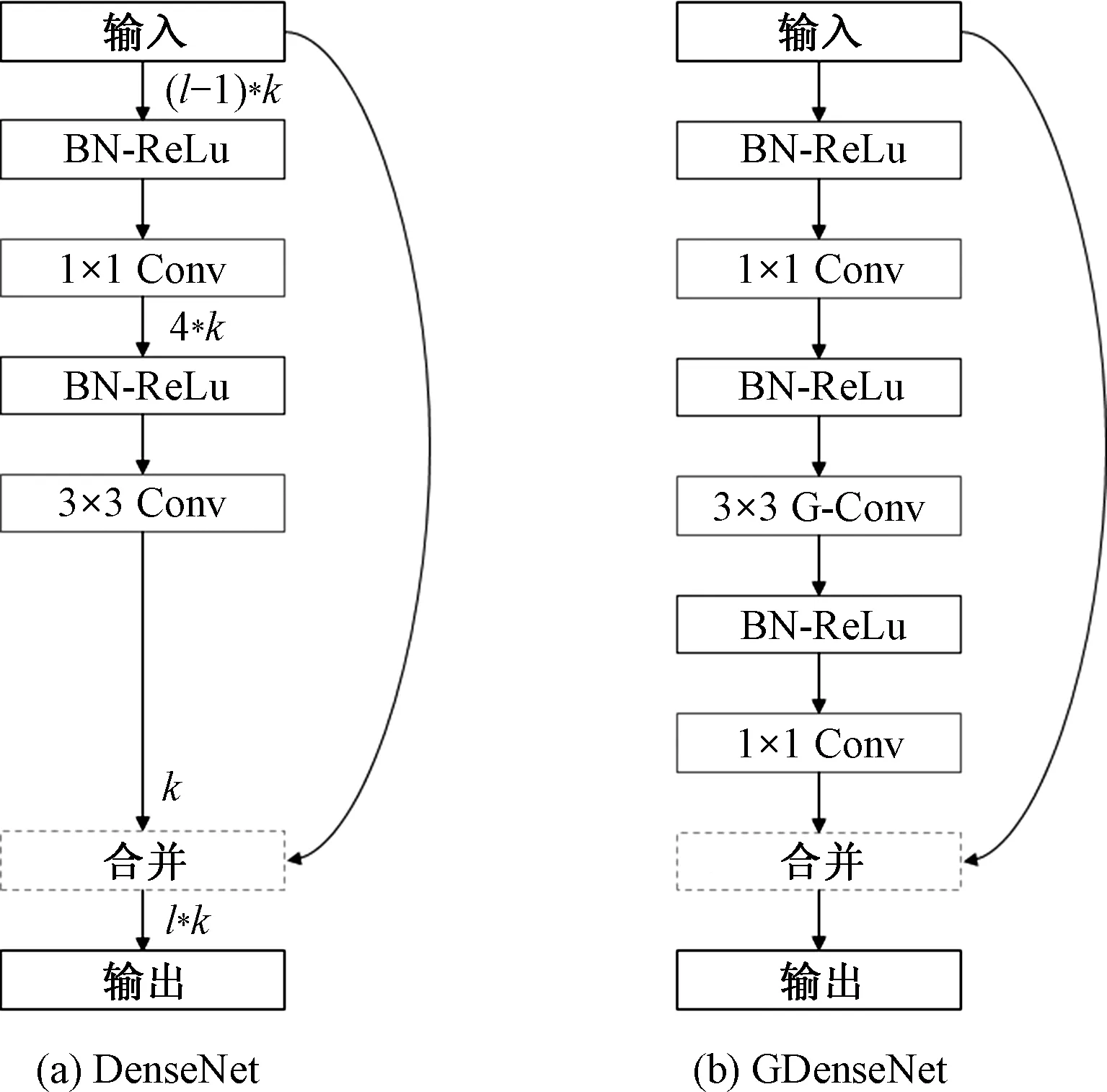
图1 密集块Fig.1 Dense block
第一个变换(BN-ReLU)由批标准化[15](batch normalization)和线性整流函数[16](rectified linear unit, ReLU)构成,接下来是一个的卷积把特征图的数量从(l-1)*k降至4*k,然后再经过一个BN-ReLU变换后,输入到3×3的卷积,最后输出的k个特征图与输入该层的(l-1)*k个特征图经过通道合并(concatenate)后输出.
DenseNet的密集连接过程,公式如下:
xl=Hl([x0,x1,…,xl-1])
(1)
式中:[x0,x1,…,xl-1]为前l-1层的输出,即第l层的输入;Tl为上述第l层的变换操作.
2 基于分组卷积的密集连接卷积网络
2.1 分组卷积
分组卷积在AlexNet[11]中首次提出,是为了将模型分布在两个GPU上以解决单GPU显存不足的问题,随后在ResNeXt[17]中再次使用分组卷积将ResNet进一步进行了优化.
如图2,在分组卷积中,若把输入的C1个特征图分为G个组,则有:
(2)
(3)
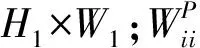
图2 分组卷积Fig.2 Group convolution
分组卷积可以有效提高参数效率.如果上述分组卷积的输入和输出特征图相等,即C1=C2=C,那么参数数量TGC为:
(4)
而对于一个输入输出和卷积核大小与分组卷积相同的普通卷积的参数数量TRC为:
TRC=C·h·w·C=h·w·C2
(5)
比较TGC和TRC可以明显地看出参数效率的提升程度完全取决于分组数G,当G越大时,参数效率越高,即参数复杂度越低,反之亦然.
2.2 模型结构设计
在GDenseNet中,为了更好地使用分组卷积,每一层中使用两个1×1卷积和一个3×3的分组卷积,如图1(b).由实验可知,若不对密集块进行改进,直接在其基础上引入分组卷积不仅会导致错误率的大幅提高,而且分组数会受到增长率的限制,无法充分发挥分组卷积的优势.其次,增加的1×1卷积还能够起到降维和通道间特征融合的作用.除了使用分组卷积外,文中还在DenseNet的基础上对增长率进行更改,从而进一步简化体系结构,并提高其计算效率.
增长率呈指数增长.最初的DenseNet设计为每层增加k个特征图,其中k是一个被称为增长率的常量.正如文献[8]中提到的,DenseNet中越深的层往往越依赖一些高级的特征而非低级的特征,这就需要加强近程连接以改善网络.通过实验发现,增长率随着深度的增加而增加可以使得较深的层拥有更多的高级特征,而较浅的层拥有相对较少的低级特征.文中增长率设置为k=2m-1k0,其中k0为基础增长率,m为密集块的索引.这样设置的好处是没有引入任何额外的超参数(hyperparameters),而且大大提高了计算效率,但是这也使得模型中较深的层拥有较大的参数比例.
由于计算资源有限,文中设计一个较小的模型与DenseNet中相似的模型进行比较,如表1.其中的一些超参数是根据经验来设置的,而不是使用网格搜索(grid search)来调优超参数,如分组数G和增长率k.
模型复杂度通过计算神经网络中全部权重(可学习参数)来测量.从表1给出的两个模型的结果可以看出,GDenseNet-121的参数比DenseNet-100少了12%.
通过计算每秒浮点运算次数(floating-point operations,FLOPs)测量计算复杂度,其中输入图像大小是32×32.表1给出了理论的计算成本.虽然实际的时间成本可能受到其他因素的影响,如GPU带宽和编码质量等,但是从结果可以看出GDenseNet-121的FLOPs比DenseNet-100少了36%,其中d为卷积核个数.

表1 DenseNet和GDenseNet针对CIFAR设计的结构
3 仿真实验分析
3.1 数据集
实验将在CIFAR-10和CIFAR-100这两个图像分类数据集上对GDenseNet进行评估.CIFAR-10与CIFAR-100都是由60 000张大小为32×32的三通道彩色图像组成,其中50 000张专门用于训练模型,剩下的则是用于测试.二者不同的是,CIFAR-10被分为10类,每类有6 000张图像,而CIFAR-100被分为100个小类,每个小类包含600张图像.实验采用标准的数据增强[7-8]方法,如把图像的每一侧进行4像素的零填充后进行随机裁剪产生32×32大小的图像,以0.5的概率对图像进行水平翻转.
3.2 实验细节
GDenseNet的网络结构如表1,除非有特别说明,否则下面所有实验均使用该网络配置.根据之前的分析,实验将3个密集块的增长率k分别设置为{8,16,32},分组数G设置为16,每个组有4个卷积核.
训练采用带动量(momentum)的随即梯度下降(stochastic gradient descent, SGD)来更新权重.具体来说,是采用Nesterov动量,并设置为0.9;权重衰减设置为10-4;小批次规模(mini-batch size)设置为64,一共迭代300次;初始学习率设置为0.1,且在总的迭代次数为50%和75%时让学习率除以10来降低学习率.
3.3 实验结果与分析
图3为GDenseNet与DenseNet的计算复杂度与模型复杂度的比较.可以明显地看到,对于计算复杂度GDenseNet要更低一些,尤其对于小模型来说,而对于模型复杂度GDenseNet的表现还不太好,有待进一步改善.

图3 DenseNet与GDenseNet在CIFAR上的计算复杂度和模型复杂度对比Fig.3 Comparison of the DenseNets and GDenseNetsTop-1 error rates on the CIFAR
图4是GDenseNet与DenseNet在训练集和验证集上错误率随迭代次数下降的曲线图.

图4 DenseNet与GDenseNet训练和测试的曲线图Fig.4 Training and testing curves ofDenseNet-100 with GDenseNet-121
从图4中看出,当计算复杂度和模型复杂度都降低以后,GDenseNet的错误率仅有不明显的很小的损失.从表2可以看出,在两个数据集上,GDenseNet都只需较少的参数和计算资源就能够达到和DenseNet类似的错误率.且对于同样使用了分组卷积的ResNeXt和DPN来说,前者在两个数据集上都有很好的表现,后者仅在CIFAR-100上的表现较好,但它们都具有较高的参数和计算复杂度.
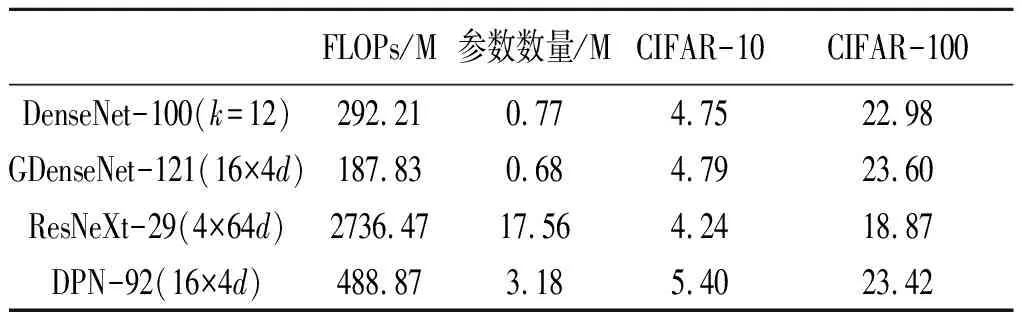
表2 CIFAR上的错误率、Flops和模型大小
从表3可以看出,与ResNet和DenseNet一样,GDenseNet同样是随着深度的增加,错误率随之下降,而不会像AlexNet和VGGNet那样受到梯度消失的影响无法搭建更深的网络.

表3 增加深度GDenseNet的变化
从表4可以看出,采用与DenseNet相同的密集块将会限制分组卷积的分组数,从而无法充分利用分组卷积达到降低参数复杂度的目的.采用固定增长率,在降低参数复杂度方面表现更好,但在降低计算复杂度和错误率方面的表现不佳.

表4 在CIFAR-10数据集上对不同密集块
4 结论
在DenseNet的基础上,文中提出一种高效的卷积网络GDenseNet,首先通过对密集块的设计将分组卷积与DenseNet很好地结合在一起,并充分发挥出分组卷积的优势,有效地降低了模型复杂度;其次通过呈指数增长的增长率来使得计算复杂度降低,同时准确率仅有不明显地损失.实验结果表明:在准确率基本相同的情况下,使用文中分组卷积的密集连接网络在计算效率和所需的参数数量方面要优于传统的DenseNet卷积网络,证实了文中方法的优越性.
