结合词相关性特征的《红楼梦》作者辨析
2020-03-14陈蔼瑞 吴士军 展浩宇
陈蔼瑞 吴士军 展浩宇






摘 要:自《红楼梦》成书以来存有多种版本,对其作者的辨析也在不断地进行,其本质是一个分类问题。本文以120回程高版本的《红楼梦》的每个回合作为样本,在人物频数、虚词频数为样本特征的基础上,提出了一种用词和词之间的相关性差异作为不同作者写作差异性度量,并用word2vec词向量方法来计算词与词之间的相关性作为特征,对比了线性模型和非线性模型下,采用SVM分类器对样本进行训练和判别,实验数据表明,结合词相关性特征后,采用高斯核的非线性SVM,得出前80回和后40回存在显著差异,从而可以合理地假设是两位不同的作者。
关键词:词相关性;频数;特征;词向量;支持向量机
一、引言
《红楼梦》是我国的明清四大名著之一,具有极高的艺术成就。自《红楼梦》成书以来,一直有学者对其内容不断进行研究探讨。但因为历史上流传不便等原因,现存的《红楼梦》具有多个版本,其作者也存在较大争议。目前较为公认的120回版本是指前80回由曹雪芹所创,后四十回由高鹗续写的版本。
在过去,大多数对《红楼梦》作者讨论的工作都是基于文学上感性的认识或者历史上文献文物的考证进行的。一些作者尝试采用多元统计分析和机器学习的方法探讨《红楼梦》作者。瑞典汉学家高本汉最早使用统计方法研究《红楼梦》,根据32中语法、词汇现象的统计结果得出前80回和后40回为同一作者的结论。李贤平、成大康、施建军等人的工作,都是以每回中文言虚词的频数作为训练样本的特征,结合方差分析、回归分析、SVM分类器、K近邻等方法进行分析,基本假设是每个作者使用虚词的习惯是不同的。采用文言虚词的频数作为学习模型中样本空间的特征值称为辨析《红楼梦》作者相关研究的主流。
这种特征选择方法在一定程度上是有效地,但也存在一些问题:首先,虚词频数的差异程度多大能够判决是不同的作者难以定义。其次这种特征选择抛弃了语言成分如词、語句的结构特性,事实上这种语言结构上的差异信息更能区分著者的不同写作习惯和风格。
本文从统计的角度出发,选择人物出场频数、虚词频数等多个特征,并且引入词向量分析提取词和词之间的关联程度作为特征选择,采用SVM分类器对120回程高版《红楼梦》的作者进行了分析。
本文假设《红楼梦》作者的分析问题可视为机器学习中经典的二类分类问题,整本《红楼梦》可视为含有120个样本点的样本集。
我们在实验中分别试验了线性近似可分SVM和非线性SVM的分类性能;尤其通过使用非线性SVM模型,取得了高置信度的分类结果,证明了在不同的回目上曹雪芹、高鹗两位作者存在“可分的”差异。
二、基于统计分析的文本分类方法
1.模型
令D={x1,x2,…,xm}表示具有m个样本(sample)的数据集(data set),每个样本xi=(xi1; xi2; …;xid)X是d维样本空间中的一个向量,xi1是xi在第i个特征(feature)的取值,d为样本xi的维数(dimensionality)。标有类标号(label)的样本成为样例(example),(xi,yi)表示第i个样例。
文本分类的基本流程如图1所示:
2.词向量
在文本分类中,词向量是用来表示词的特征向量,One-hot表示方法将每个词表示为只有一个维度取值为1、其余维度取值都为0的d维向量,d也是词表的大小。在深度学习中,采用一种低维的实值向量表示词向量。利用词向量之间定义的各种度量,可以表示词语之间的相似性程度。词向量可以通过基于神经网络语言模型经过训练而产生,目标函数可以采用对数似然函数:
三、基于人物出场频数、虚词频数和词向量的作者辨析
我们按照题意分别采取了几种不同的提取《红楼梦》语料中词语特征的方法。通过组合这些词的特征,我们构建了《红楼梦》每一回目的文本特征。我们将前40回文本样本作为正例、81~100回文本样本为反例,用以训练SVM模型,41~80回文本样本、101~120回文本样本作为测试样本,最终输出分类结果,以判别《红楼梦》前80回与后40回是否是同一作者。
下面我们按照题目顺序介绍几种特征提取的方法。
1.统计120回中每一回目主要人物名称出现的频数
首先我们将程高版《红楼梦》的txt文档按照120回目分开,储存为一个csv格式的文件,然后我们用python的pandas框架读取这个文件,并用python的jieba框架对文本进行了分词。在去掉中文的停用词之后,我们用python的nltk框架的FreqDist模块统计了分词后每个回目每个词的频数。
由于红楼梦的出场人物众多,造成了统计120回中每一回目主要人物名称出现的频数的以下3个困难:
a.人物众多,有名有姓者就有732人;
b.许多人物往往只在120回中出现了一次,造成了样本的稀疏性。
c.对于文本分词产生的指代性人称代词、别名、小名无法处理。
针对问题b,我们采用主成分分析PCA(Principal Component Analysis)进行降维,计算出主要人物。最终选取了15个人物每一回目的出场次数,作为每一回的文本特征,如图2所示:
2. 统计120回中每一回目常见文言虚词的频数
处理思路和方法与统计人物出场次数相同,但统计虚词作为文本特征相比于统计人物出场次数有两个优势。规定的文言虚词数量只有18个。除去2个120回都没有出现过的虚词外,其余的16个虚词出现频数都相对正常。
我们完整地统计了每一回目16个虚词出现的频数,如图3所示。
3.基于词与词之间相关性的特征提取
我们采用了一种word2vec的词向量方法来计算词与词之间的相关性。为了节约篇幅,我忽略了对自然语言处理从词的one-hot向量的特征形式到词向量的特征形式发展的介绍,简单来说可将one-hot视作对字典中的词一种非常稀疏的编码形式,且无法计算出词与词的相关性;词向量则是将某个词与上下文n个词之间的相关性用马尔科夫决策过程计算,用计算的数值来作为这个词的特征。而word2vec算法主要功能就是通过简单的单隐层神经网络来训练出表示词和词之间相关性的词向量。
word2vec算法的输入是one-hot向量,隐藏层没有非线性激活函数,也就是线性的单元。输出层维度跟输入层的维度一样,用的是softmax回归。我们要获取的词向量其实就是隐藏层的输出单元。
word2vec算法有两种结构,分别为CBOW和skip-gram,它们的结构分别如图4所示。
CBOW模式根据上下文n个词计算某个词的相关性,适合小语料;skip-gram模式根据某个词计算上下文n个词的相关性作为该词的特征,适合大型语料。
我们通过调用python的gensim框架中word2vec模块,采用skip-gram模式,设置计算一个词前后五十个词的相关性,对整本《红楼梦》进行了训练。训练的结果显示模型已经掌握了一些词与词之间结构的高级特征。图5、图-6给出了模型输出与“贾宝玉”加“林黛玉”和“贾宝玉”加“薛宝钗”最相关的词语。
我们将每一回目所有词的特征相加后求平均作为该回目的文本特征,从而进一步作为SVM的输入来训练模型。
4.基于tf-idf的特征提取
tf指词频,idf指逆文本频率指数,某一特定词语的idf,可以由总文本数目除以包含该词语的文件的数目,再将得到的商取对数得到。tf-idf算法的内容就是将一个词的tf和idf相乘得到这个词的权重或者特征。这样做的好处在于能将那些真正对文本分类重要的词作为文本的特征,而将那些虽然出现很多但毫不重要的词例如“的”“了”给过滤掉,这正是乘积中idf项起到的作用。
我们用python的tensorflow框架实现了用tf-idf作为特征提取来对《红楼梦》每一回的文本提取特征。
四、实验和數据分析。
我们分别用几种不同的特征提取方法提取了《红楼梦》每一回的文档特征,并分别连接了线性SVM和非线性SVM用来产生分类的结果。
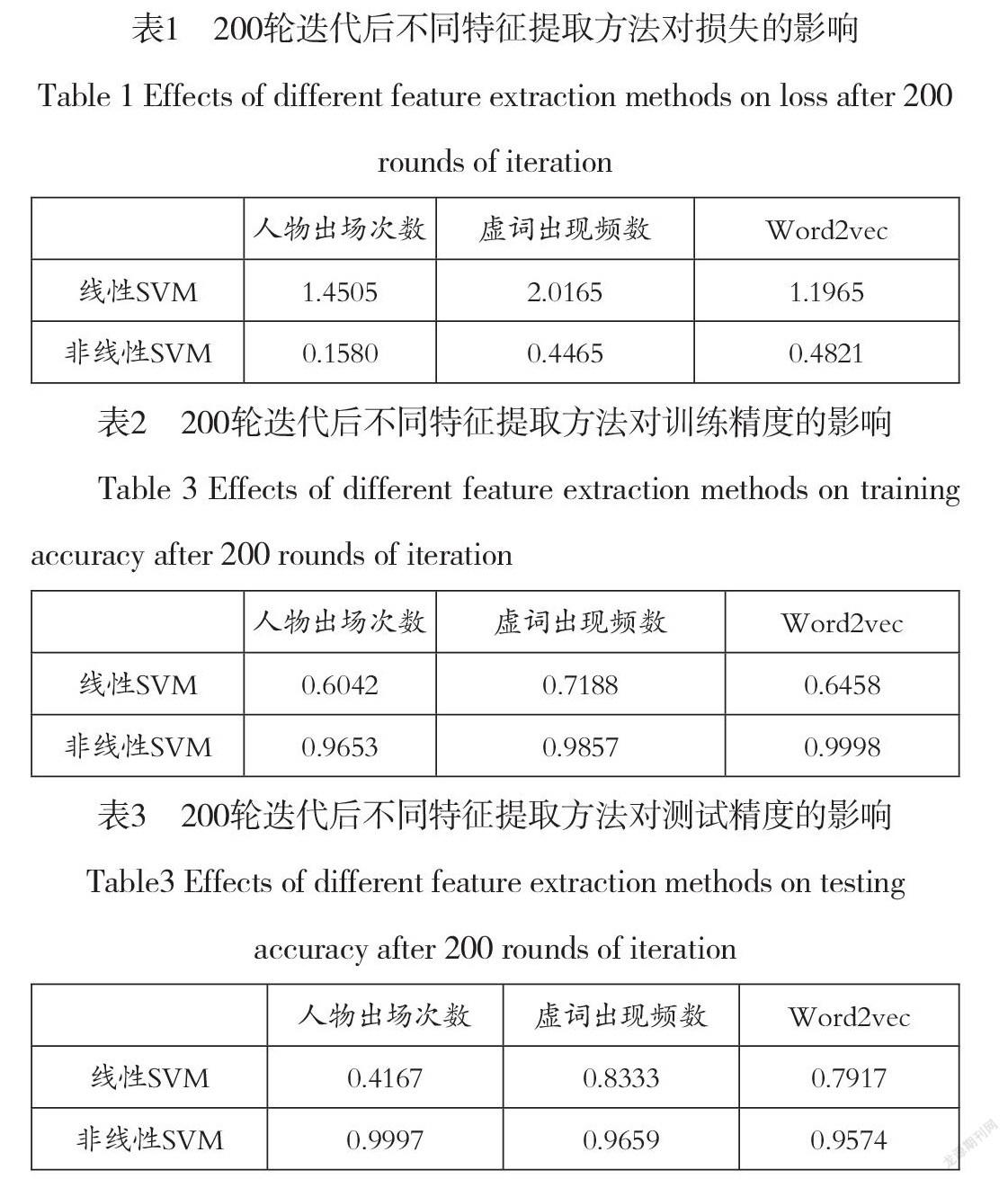
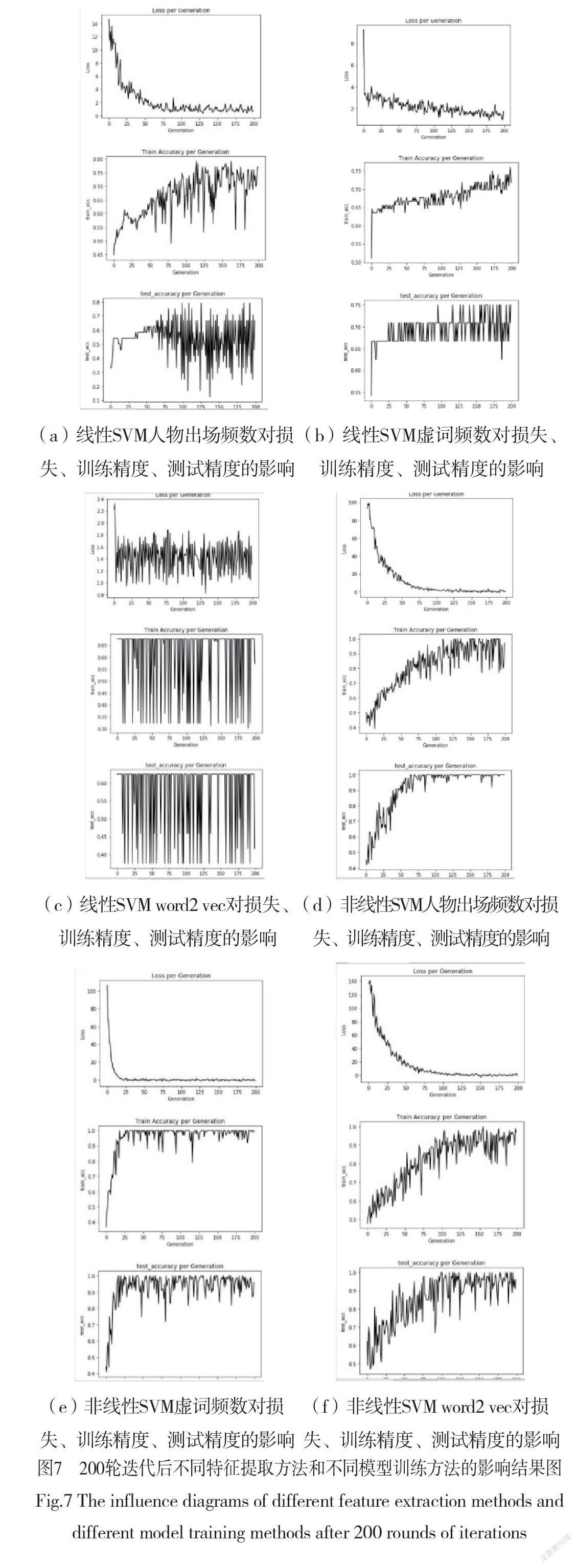
对比表1,表2,表3,我们可以看出在200轮迭代后不同特征提取方法连接的非线性SVM分类器对于测试数据都已接近1的置信度成功分类,说明了《红楼梦》每个回目的特征空间在映射的高维空间上是线性可分的,证明了在不同的回目上曹雪芹、高鹗两位作者存在“可分的”差异。
我们也通过图7可以看出,使用线性SVM作为分类器时训练精度和测试精度不能收敛,存在震荡,说明我们原先假设回目的特征空间线性近似可分是错误地。
我们还发现当迭代到100轮时,非线性SVM的损失已经收敛到0,然而训练精度和测试精度还未达到最高。这也许会对那些优先考虑算法速度的任务很有帮助。
此外还有曲线平滑度的问题,在超参数相同的情况下,用主要人物出现频数提取特征的测试曲线最为光滑,用虚词出现频数提取特征的测试曲线光滑度次之,用word2vec提取特征的曲线,光滑度最差。猜测在超参数相同的情况下,测试曲线的光滑可能与特征的维数有关,维数越高,越不光滑。
结束语
本文基于几种不同的特征提取方法和两种SVM分类器对现存公认的《红楼梦》120回目版本的文本建立了模型。通过迭代训练,非线性SVM分类器能够以接近1的置信度将每一回目的作者成功分类,证明了在不同的回目上曹雪芹、高鹗两位作者存在“可分的”差异。
进一步地工作包括以下两个方面:
(1)在通过word2vec训练词向量时,实际上将模型的训练分成了两块:用于提取特征的单隐层网络和用来分类的SVM。这样使得后端更新的参数不能反馈到前端去更新单隐层网络,不利于损失函数的收敛。假如能够构造出一种能够实现end-to-end的网络结构,既能用来提取词向量特征,又能用来文本分类,这样参数可以用BP算法从后端更新到前端。有利于提升损失函数的收敛速度和测试的精度。
(2)对于《红楼梦》这样的特定语料,我们无法判断样本是否基于独立同分布产生的。同时也存在类别不平衡的问题。进一步地工作将围绕这两个问题展开对模型的修正。
参考文献:
[1]刘钧杰.《红楼梦》前八十回与后四十回言语差异考察[J].语言研究,1986,1(2):172-181.
[2]蒋绍愚.近代汉语研究概率[M].北京:北京大学出版社,2005.
[3]李贤平.《红楼梦》成书新说[J].复旦学报 (社会科学版),2005,5(8):3-16.
[4]陈大康.从数理语言学看后四十回的作者——与陈炳藻先生商榷[J].红楼梦学刊, 1987,1(2):293-318.
[5]施建军.基于支持向量机技术的《红楼梦》作者研究[J]. 红楼梦学刊,2011,9(14):35-52.
[6]周志华.机器学习[M].北京:清华大学出版社,2016:2-3.
[7]Hinton, Geoffrey E. Learning distributed representation of concepts[C]. Pro-ceedings of the eighth annual conference of the cognitive science socith.1986
[8]N Cristianini, J Shawe-Taylor, An Introduction to Support Vector Machines[M] Cambridge Univer-sity Press, Cambridge, UK, 2000.
本文受江苏省政策引导类计划(产学研合作)-前瞻性联合研究项目资助,项目编号:BY2016065-5。
作者简介:吴士军(1967-),男,本科,讲师,主要研究方向为大数据分析。
