基于DeblurGAN和低秩分解的去运动模糊
2020-02-12孙季丰朱雅婷王恺
孙季丰 朱雅婷 王恺
(华南理工大学 电子与信息学院,广东 广州 510640)
图像去模糊技术在交通管理、目标检测、视频监控等方面起着极其重要的作用。生活中难免因为某些因素接收到模糊图像,给生活和研究带来不便。例如,车辆在行驶中由于车和路旁物体间的相对运动,且往往伴有抖动的情况,所摄图像存在运动模糊,这不利于司机判断路况。因此,对模糊图像进行去运动模糊处理,具有一定现实意义。
传统去运动模糊方法往往都基于对清晰图像的先验假设,从而估计出相应的运动模糊核,然后将其与清晰图像卷积,再叠加噪声,最终获得运动模糊图像。其模糊核估计过程很繁杂,且去模糊效果很大程度上依赖于对图像的先验假设,很难泛化到其它模糊类型。文献[1]试图通过对模糊源的简单假设来参数化模糊模型,他们认为模糊只是由3D相机运动引起的。然而,在动态场景中,模糊核估计更具挑战性,因为存在多个移动物体以及相机运动。文献[2]基于模糊核大小通常小于图像尺寸的先验知识,使用变分贝叶斯近似来对模糊核估计进行约束,从而恢复出真实图像,但其复原图像细节不够清晰。文献[3]引入相机抖动分类,利用重叠添加的空间变异过滤框架,介绍了一种适用于空间变化模糊的盲去卷积方法。
近年来,基于深度学习的图像去模糊方法也不断被提出。Sun等[4]使用卷积神经网络(Convolution Neural Network,CNN)来预测运动模糊的概率分布,并通过图像旋转设计和马尔可夫随机场模型来推断运动模糊场,实现了复杂的去运动模糊,但其去模糊处理过程耗时过长。随着对抗神经网络(Generative Adversarial Network,GAN)在图像生成及图像翻译领域中的兴起,许多文献利用GAN从事图像去模糊工作的研究。Nah等[5]结合多尺度CNN和GAN训练的方法实现了动态场景去模糊,去模糊效果良好,但处理时间较长。文献[6]提出了一种基于条件生成对抗网络(conditional GAN,cGAN)和感知损失的去模糊方法,获得较好的视觉效果及较高的峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity Index,SSIM)指标,但去模糊后的图像同样存在边缘模糊问题,且由于该方法没有使用像素空间上的L2损失,其复原图像的PSNR不是很高。
本研究对文献[6]的DeblurGAN网络进行修改,通过对文献[6]生成网络的标准卷积层进行低秩分解(即:将原来的3*3卷积改成瓶颈结构[7],并在瓶颈结构内进行低秩分解),从而减少网络参数量和计算量,加快网络收敛。同时在网络的卷积层和相应转置卷积层之间添加两个对称跳跃连接,充分融合网络浅层的图像信息,从而减少图像信息丢失,保证去模糊效果。此外,本研究为解决DeblurGAN复原图像边缘不清晰问题,向原网络损失函数加入互信息损失和梯度图像L1损失,使模糊图像的隐含特征能够更好地表征输入图像的信息,从而获得更清晰的去模糊图像,最后通过实验对文中算法的有效性进行了验证。
1 相关理论
1.1 基于cGAN的图像去运动模糊
1.1.1图像盲去模糊
图像的运动模糊模型可用式(1)表示:
IB=k(M)*IS+N
(1)
式中:*代表卷积操作,IB为模糊图像,k(M)表示运动模糊核,IS表示潜在的清晰图像,N为加性噪声。
图像去模糊就是从观察到的模糊图像中恢复出潜在清晰图像的过程。但现实中模糊核往往是未知的,因此,图像盲去模糊需同时估计潜在的清晰图像和模糊核。
1.1.2基于cGAN的图像盲去运动模糊模型
基于cGAN的图像去运动模糊网络能够学习模糊图像到清晰图像的映射关系,其基本框架如图1所示。含加性噪声的模糊图像B经由生成器G可获得生成图像G(B),然后将生成图像G(B)和对应的基准清晰图像S输入到判别器,判别器输出一个标量值,该值代表判别器将输入判为清晰图像S的概率。再用判别器的判断结果指导生成器不断学习模拟基准的清晰图像的分布,直到判别器难以辨别清晰图像S和生成图像G(B),即可认为网络已达最优状态。
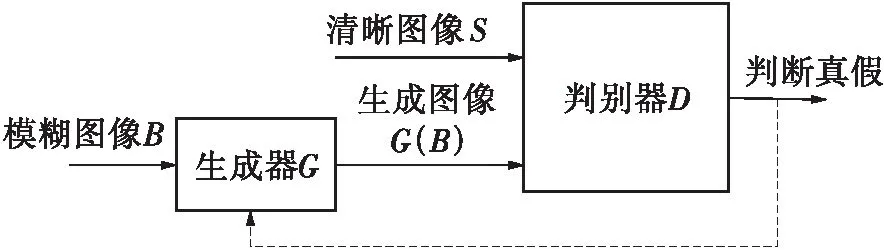
图1 基于cGAN的图像盲去运动模糊的基本框架
Fig.1Basic framework ofimage blind motion deblurring based on cGAN
本研究采用cGAN训练方式来进行图像去运动模糊实验,其中,生成器由多个卷积层构成,本研究将生成器的一部分卷积层改成瓶颈结构并对其进行低秩分解,同时在生成器网络中添加了全局对称跳跃连接[8],判别器由卷积识别网络组成。
2 本研究的去运动模糊网络模型
2.1 生成器
2.1.1生成器网络结构
本研究的生成器网络架构如图2所示,主要由两组3*1和1*3卷积块、9个LR_ResBlock和两组3*1和1*3转置卷积块构成,每个LR_ResBlock由1个1*1的卷积层、1个3*1卷积层、1个1*3卷积层和1个1*1卷积层构成,且将LR_ResBlock的输入和输出进行了残差连接。本研究将DeblurGAN首尾的3*3卷积进行了标准的低秩分解,而LR_ResBlock为本研究对DeblurGAN的残差模块(ResBlock)进行修改后所采用的结构,所作修改如下:在维持与DeblurGAN感受野相同的情况下,将原来ResBlock的3*3标准卷积改成瓶颈结构,且瓶颈结构中采用了3*1和1*3的卷积低秩分解,从而有效减少网络的参数量和计算量,如图3所示,图中X为LR_ResBlock的输入,D表示低秩分解的卷积核个数,卷积核大小d=3。
由于对网络进行压缩和加速可能会导致PSNR和SSIM指标的下降,为获得较高的图像保真度,本研究在网络前端的卷积块和其对应的转置卷积块之间添加了两个对称跳跃连接(图2的红线部分),从而充分地利用网络浅层的图像信息,以便获得更好的去模糊效果。
LR_ResBlock的输入特征图首先经过第一个1*1的卷积操作后,通道数降为m1,这样有利于减少网络的计算量,而网络更深层的LR_ResBlock的输入通道更多,其降维效果更明显。接着通过3*1和1*3的卷积低秩分解操作,进一步减少计算量,再经实例规一化和ReLU[9]激活,然后通过1*1的逐点卷积操作将上层的m2个通道的特征信息进行融合,并在其后采用Dropout[10]技术,从而有效加入高斯噪声,模拟抖动分布,防止GAN崩溃,最后将LR_ResBlock的输入和Dropout的输出进行残差连接求和作为整个LR_ResBlock的输出。

图2 生成器网络架构
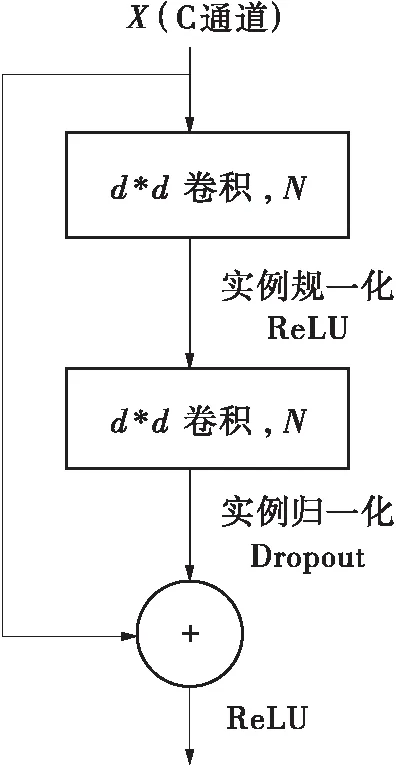
(a)DeblurGAN使用标准卷积的ResBlock
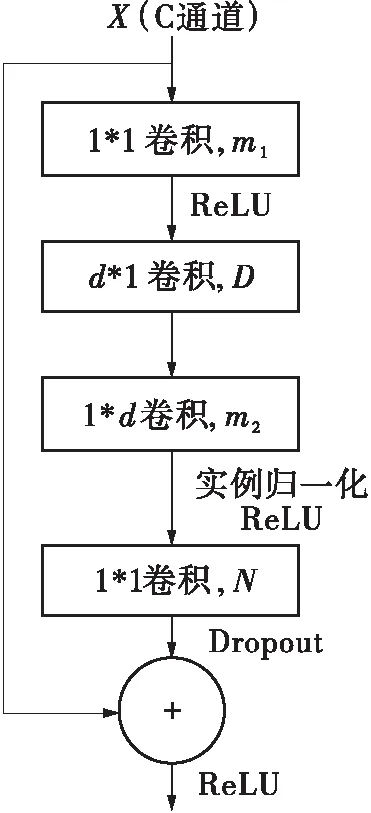
(b)文中使用低秩分解的LR_ResBlock
2.1.2生成器网络参数量和计算量
标准卷积的低秩分解如图4所示。图中,*表示卷积运算;C、W、H分别为输入的通道数、宽和高;d为分解前的卷积核大小;N、W0和H0分别为输出的通道数、宽和高;D为低秩分解的卷积核个数。通过计算得到标准卷积低秩分解的计算量压缩比表达式为
(2)
当确定好C、N、d、W和W0的值时,分解个数D越小,计算量压缩比R越大。
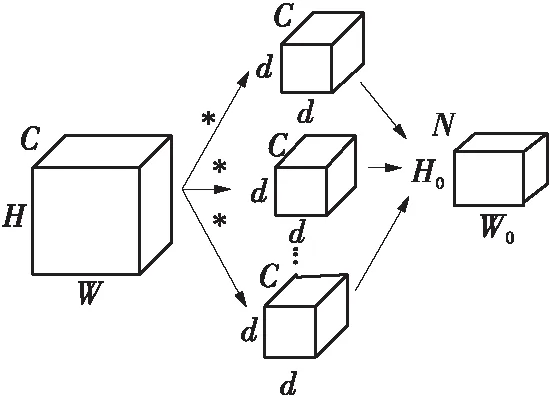
(a)标准卷积

(b)低秩分解
文中LR_ResBlock并非简单地对DeblurGAN中ResBlock的两个3*3标准卷积直接采用图4常规低秩分解来得到多个级联的3*1和1*3低秩卷积层,再进行堆叠,这样确实会带来一定压缩加速效果,但会因过多低秩分解且没有足够的通道间的信息交流而导致网络更深层提取的信息不足,使生成网所恢复的图像质量欠佳。文中LR_ResBlock是将标准卷积转换成瓶颈结构,并在瓶颈结构中使用低秩分解,从而进一步减少计算量和参数量,同时LR_ResBlock结构中最后的1*1逐点卷积还可将各通道的信息进行融合,以获得更佳的图像质量,充分考虑了速度和质量两方面因素。
将DeblurGAN中ResBlock的两个3*3卷积的输出特征图大小均记为DF×DF,文中LR_ResBlock的每一步输出大小也为DF×DF。将DeblurGAN1个ResBlock和文中1个LR_ResBlock的参数量和计算量分别记为para1、Computation1,para2和Computation2,得:
para1=C×d×d×N+N×d×d×N=
(C+N)d2N
(3)
(4)
para2=C×m1+m1×d×1×D+D×1×d×
m2+m2×N
(5)
Computation2=(C×m1+m1×d×1×D+
D×1×d×m2+m2×N)×DF×DF
(6)
将文中1个LR_ResBlock对DeblurGAN中ResBlock的参数压缩比和计算量压缩比分别记为rp和rc,因为C=N,故:

D+D×1×d×m2+m2×N)=
(7)
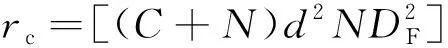
D×d(m1+m2)×DF×DF]=rp
(8)
DeblurGAN中,C=N=256、d=3、DF=64。文中C、N、d、DF的取值均和DeblurGAN相同,m1=m2=64,则有:
(9)
考虑图2的整个生成器网络,则本研究引入图3所示的采用低秩分解的LR_ResBlock之后,整个生成器网络的计算量和参数量如表1所示。DeblurGAN网络的相应信息如表2所示。表中,CV、CT、P1和P2分别表示卷积层和转置卷积层、DeblurGAN的生成网络和本研究生成网络的总参数量;C1表示DeblurGAN的生成网络的总计算量,C2为本研究的生成网络的总计算量。将本研究生成网络对DeblurGAN生成网络的总参数量压缩比和总计算量压缩比分别记为Rp和Rc。由表中数据可知,文中方法的参数量和计算量相对DeblurGAN分别压缩至约3.25%和约5.32%,可由以下两个式子算出:
(10)
(11)
表1文中方法的生成器网络各层参数量和计算量
Table1Parameters and calculation for each layer of the generator network of the methods in the paper
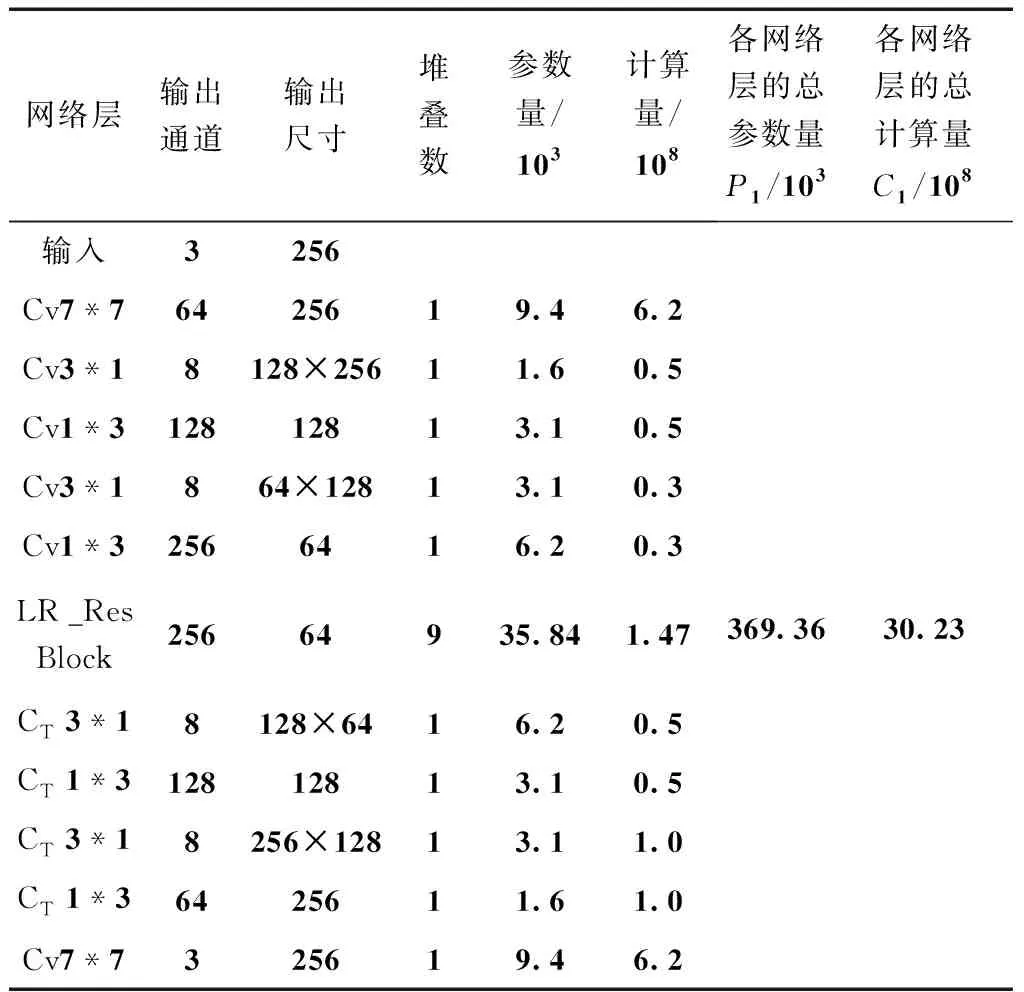
网络层输出通道输出尺寸堆叠数参数量/103计算量/108各网络层的总参数量P1/103各网络层的总计算量C1/108输入3256Cv7*76425619.46.2Cv3*18128×25611.60.5Cv1*312812813.10.5Cv3*1864×12813.10.3Cv1*32566416.20.3LR_ResBlock25664935.841.47CT 3*18128×6416.20.5CT 1*312812813.10.5CT 3*18256×12813.11.0CT 1*36425611.61.0Cv7*7325619.46.2369.3630.23
表2DeblurGAN的生成器网络各层参数量和计算量
Table2Parameters and calculation for each layer of the generator network of the DeblurGAN
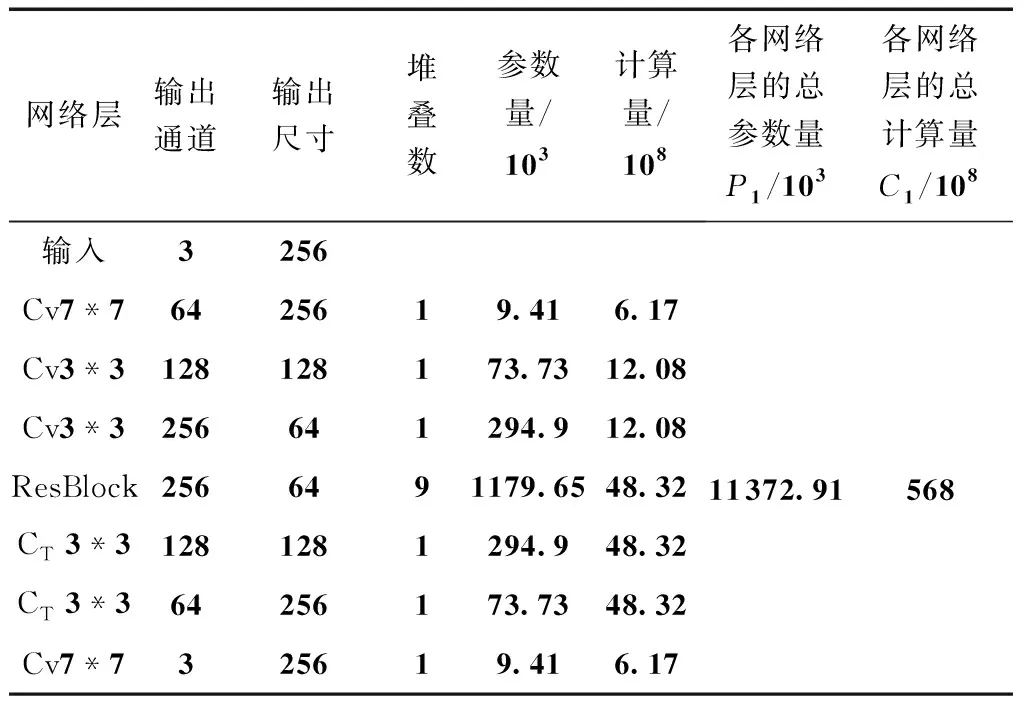
网络层输出通道输出尺寸堆叠数参数量/103计算量/108各网络层的总参数量P1/103各网络层的总计算量C1/108输入3256Cv7*76425619.416.17Cv3*3128128173.7312.08Cv3*3256641294.912.08ResBlock256649 1179.6548.32CT 3*31281281294.948.32CT 3*364256173.7348.32Cv7*7325619.416.1711372.91568
2.2 判别器网络
判别器网络用来判别其输入图像是否清晰,文中的判别器网络是一个使用梯度惩罚机制的具有5个卷积层的马尔科夫片判别器(Markovian Patch Discriminator[11]),并将其记为PatchGAN,如图5所示。在把图像输入进判别器之前,首先将整张图像随机裁剪成多个F×F的局部图像块(patch),判别器只在patch的尺度上加入惩罚结构,用来鉴别图像中一个F×F的局部块是否清晰。用判别器对整张图像进行卷积,并对所有patch的判断结果取平均值作为对整张图像的最终判断结果。当判别器输出的概率值大于0.5时,即可认为输入图像为清晰图像,否则判为模糊图像。其中,F可以比整张图像的尺寸小得多,也仍能产生高质量的结果。这是因为更小的PatchGAN有着更少的参数,跑得更快,并且能够应用到任意大小的图像中。经多次迭代实验后,文中取F=256。
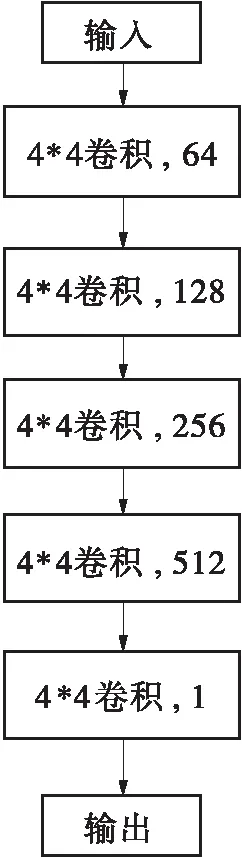
图5 判别器网络
2.3 损失函数
2.3.1对抗训练损失
(1)对抗损失
文中采用具有梯度惩罚项的WGAN-GP[12]作为对抗损失函数,加入梯度惩罚可防止GAN崩溃,WGAN-GP可通过式(12)计算:
(12)
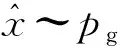
(2) 条件损失
一个成功的清晰图像生成器,必须能够成功欺骗判别器,让判别器无法区分所输入的图像是否清晰,文中的条件损失函数可用式(13)求出,其训练目标是最大化判别器将生成图像判为真实清晰图像的概率。
《议定书》推动中国—东盟自由贸易区升级发展。但是,《议定书》并未涉足TPP开创和引领的多个“边境后”规则,并未改变中国—东盟自由贸易区以边境规则为主,属于传统关税治理协议范畴的属性。事实上,我国建立中国(上海)自由贸易试验区的初衷之一,就是顺势利用全球经贸规则新高地TPP带来的倒逼改革效应,在国内建设能够对标TPP高标准、高要求的新开放高地。而且,中国—东盟自由贸易区在关税领域的改进空间非常有限,升级版建设应该以更高的开放水平为目标,尝试性、试验性、渐进性推动更大领域的双边市场开放与管制对接。
(13)
式中,B表示输入的模糊图像。该损失函数帮助生成器在给定输入的模糊图像情况下,在其输入和输出之间保持高度统计一致性,从而使生成器G保持输出对输入的模糊图像的依赖性,以适应不同种类和数量的抖动模糊,并防止它在“欺骗”鉴别器的过程中摇摆太远,从而成功模拟出真实清晰图像集的分布。
所以本研究的对抗训练损失为
LGAN=Ladv+Lcondition
(14)
2.3.2内容损失
为维持图像的内容保真度,本研究在网络的内容损失函数上继续沿用文献[6]的感知损失。同时本研究希望生成器的编码过程提取尽量多的专属于原始输入图像的重要特征,进而通过该特征指导后续解码出清晰图像。考虑到互信息可用来考察两个变量间的相关性,因此本研究引入互信息损失,通过最大化模糊图像和其隐含特征之间的互信息,即最大化它们之间的相关性,使模型提取出较好的隐含特征用于复原图像。此外,为使恢复图像有更好的边缘特征,本研究引入生成图像和真实清晰图像间的梯度图像L1损失。故本研究的内容损失函数为
Lcontent=Lperceptual+a1Linf+a2Lgrad
(15)
其中:Lperceptual、Linf和Lgrad分别代表感知损失、互信息损失和梯度图像L1损失,系数a1=0.5、a2=0.5。
(1)感知损失
感知损失是真实的清晰图像和生成器所得的去模糊图像经深卷积层激活后所得的特征图之间的欧几里得距离,本研究采用的深卷积层为在ImageNet上的VGG19[13]预训练网络模型的卷积层。感知损失的计算公式如下:
Φi,j(G(B))x,y]2
(16)
其中,Φi,j是输入图像向前传递到VGG19网络的第j个卷积层(在第i个最大池化层之前)再经ReLU激活后输出的特征图,Wi,j和Hi,j分别为该特征图的宽和高,S和G(B)分别表示真实清晰图像和生成器所得的去模糊图像,x和y分别为特征图上的像素点的x坐标和y坐标,本研究采用Φ3,3特征图来计算感知损失。
(2)互信息损失
本研究只考虑最后一个LR_ResBlock的输出特征图这个隐含特征。用X表示输入的模糊图像的集合,x∈X代表输入的某个模糊图像,Z为隐含特征的集合,z∈Z表示其中某个隐含特征,p(z|x)为x经生成器所提取的隐含特征的分布,则可通过互信息来衡量X和Z的相关性,本研究计算互信息时采用的对数底数为自然常数e,表示互信息的单位是奈特,其表达式如式(17)所示:
(17)
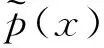
要获得好的隐含特征,则应最大化该特征与输入之间的互信息:
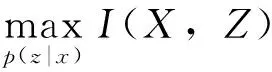
(18)
将式(17)稍作变换,则互信息可表示为
(19)
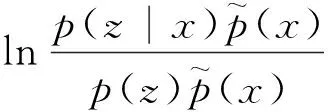
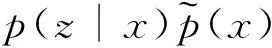
(20)
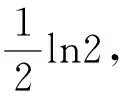
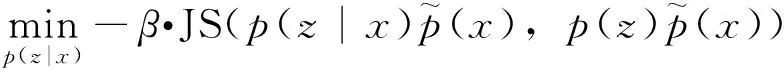
(21)
式中的JS散度可参照文献[14],通过式(22)计算:
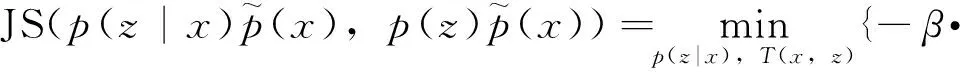
[ln(1-σ(T(x,z)))])}
(22)
式(22)的含义就是负采样估计[15],其中σ(T(x,z))是由4个全连接层构成的判别网络,模糊图像x及其对应的隐含特征z作为一个正样本对,而x及随机抽取的z则为负样本对,式(22)最大化似然函数,就等价于最小化交叉熵。
(3)梯度图像L1损失
由于清晰图像具有显著的边缘特征,而模糊图像的边缘特征比较杂乱,故本研究在文献[6]的损失函数基础上,还引入了梯度图像的L1距离,将其作为图像去模糊的正则约束,有助于获得具有清晰边缘特征的生成图像。本研究采用的梯度算子为Sobel算子,梯度图像的计算公式如下:
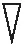
(23)
文中的梯度图像L1损失的计算公式为
(24)
2.3.3总体损失函数
网络总体损失函数为对抗训练损失和内容损失的线性组合,表达式如下:
L=LGAN+λ*Lcontent
(25)
实验证明对抗训练损失和内容损失相差100倍左右,故式中选λ=100。
3 实验结果与分析
使用GOPRO[5]数据集进行网络训练和验证。GOPRO数据集由模糊-清晰图像对组成,其中训练集2103对、验证集1111对。文中将训练所得模型对GOPRO验证集的复原结果与同类方法进行了比较;然后对自制的200张车载模糊图像测试集进行去模糊,并使用SSD[16]检测框架对去模糊前后的图像进行检测,比较准确率的变化,从而证明方法的有效性。
3.1 实验数据集预处理
文中对训练的图像数据进行随机裁剪和缩放、水平翻转和随机角度旋转等数据增强处理,以增强网络泛化能力,并最终将清晰图像和模糊图像的像素值归一化为[0,1]的范围,且将图像数据封装成二进制格式再送入网络进行训练,以加快网络的数据读取速度,加快网络训练。
3.2 实验网络参数设置及实现细节
文中在Ubuntu系统下用Pytorch深度学习框架进行实验,GPU为英伟达1080Ti。实验采用自适应矩阵估计(Adaptive Moment Estimation,Adam)作为优化器,每对判别器进行5次梯度下降优化更新后,再对生成器进行1次更新,网络迭代训练250轮后收敛。生成器和判别器网络初始学习率均设为10-4,经150次迭代训练后,在接下来100轮训练中线性衰减学习率为零,采用Dropout策略和实例归一化进行训练,batch size=4。此外,本研究借鉴文献[17]的全局监督低秩分解重构策略,以网络输入的标签信息(即基准清晰图像标签)作为监督信息来逐层训练低秩分解层,从而有效减少传统低秩分解的重构过程中因拟合原始网络层输出而忽视网络输入的标签信息所带来的累积误差。最终本研究网络训练时长为4d。
3.3 实验结果分析
为验证文中所提去模糊网络的有效性,分别使用文中方法、Sun等的方法、Nah等的方法及DeblurGAN方法,对GOPRO验证集进行去模糊处理,并将处理结果进行主观视觉效果比较,同时还进行了PSNR及SSIM两项图像质量全参考客观评价指标的定量对比分析,并统计各方法的测试运行时间;接着,对真实场景下的200张模糊车载图像测试集进行去模糊,并用信息熵[18]和平均梯度2个图像质量无参考客观指标来比较不同方法的去模糊效果;最后用SSD检测框架对去模糊前后的图像进行检测,进一步比较不同方法的去模糊效果。
3.3.1复原图像的主观效果对比
对GOPRO验证集进行了去模糊处理,并将处理结果进行局部放大来对比主观视觉效果,图6所示为其中3幅模糊图像的实验结果。
比较图6所示实验结果可看出,Sun等的方法去运动模糊后的图像存在一定失真,且边缘较模糊;DeblurGAN方法的去模糊结果图像边缘特征也不明显;Nah等的方法处理结果最好;文中方法的复原图像的保真度也较高,同时不存在伪影现象,边缘特征显著,这是因为本研究的损失函数不仅考虑了有助于图像保真的感知损失和互信息损失,还考虑了有助于恢复边缘特征的梯度图像L1损失,从而获得较好的去运动模糊效果。图6(a)中,文中方法和Nah等的方法所复原的车牌字符边缘更清晰;图6(b)中,Sun等的方法所得复原图像的窗户纹理不够清晰,而文中方法及其他两种方法的结果更清晰;图6(c)中,Sun等的方法所复原的墙壁仍有伪影,而文中方法没有伪影,且砖块线条比DeblurGAN清晰,光线色彩度更饱满。
3.3.2全参考图像质量客观评价及运行时间
不同去模糊方法在GOPRO验证集的PSNR、SSIM和运行时间的实验结果如表3所示。
表3不同方法在GOPRO验证集上的全参考图像质量客观评价及运行时间
Table3Objective evaluation of full-reference image quality and running time of different methods on the GOPRO validation dataset
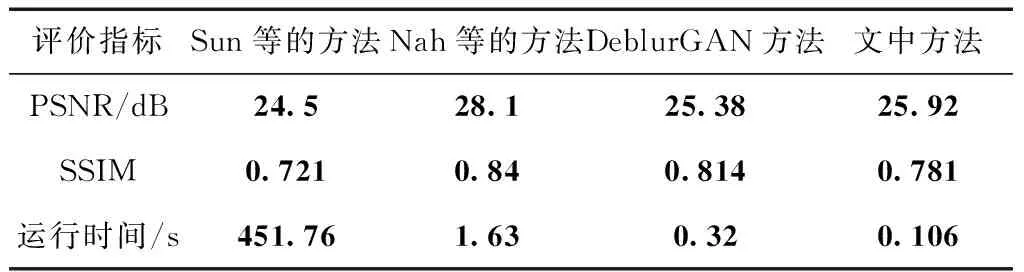
评价指标Sun等的方法Nah等的方法DeblurGAN方法文中方法PSNR/dB24.528.125.3825.92SSIM0.7210.840.8140.781运行时间/s451.761.630.320.106
表3中所示的每个评价指标数据均为整个GOPRO验证集上的平均值。由表3可见,文中方法获得的PSNR值比DeblurGAN高,这得益于本研究采用的互信息损失和梯度图像L1损失;Nah等的方法的处理效果最好,但运行时间较长;而文中方法运行时间最快,平均每张图像的处理速度分别是DeblurGAN方法的3倍、Sun等的方法的4261倍、Nah等的方法的15倍,这得益于本研究采用的瓶颈结构和其中的张量低秩分解技术。
3.3.3无参考图像质量客观评价
用上述4种方法对200张现实场景的模糊车载图像进行去模糊,并统计图像平均信息熵和平均梯度,结果见表4。由表4可见,4种方法所得复原图像的信息熵和梯度都比原图高,但文中算法所复原图像的平均信息熵高于DeblurGAN和Sun等的方法,仅次于耗时较长的Nah等的方法,表明所恢复图像包含更多的信息;此外文中方法复原图像的平均梯度也较高,仅次于Nah等的方法,说明文中方法相比于Sun等和DeblurGAN两种方法,复原图像的细节纹理更清晰,色彩更丰富。
表4不同方法的无参考图像质量客观评价
Table4Objective evaluation of no-reference image quality of different methods
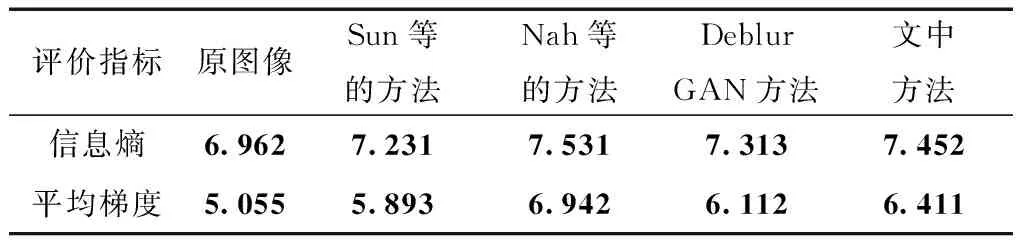
评价指标原图像Sun等的方法Nah等的方法DeblurGAN方法文中方法信息熵6.9627.2317.5317.3137.452平均梯度5.0555.8936.9426.1126.411
3.3.4去模糊前后的目标检测结果对比
最后,文中研究了图像去模糊对目标检测准确率的影响。用文中方法对200张模糊车载图像测试集进行去模糊,并用SSD检测框架分别对去模糊前后图像进行检测,置信度阈值设置为0.5。经实验验证,文中方法所得复原图像的检测效果优于DeblurGAN和Sun等的方法,准确效果和Nah等的方法相当,去模糊前的检测准确率为71%,文中方法复原图像的检测准确率达82.7%。图7所示为部分检测结果。由图7可见,去模糊前未检测到的小目标和模糊物体经文中方法去模糊之后被成功检测到,同时置信度有所提高。如原模糊图像1和Sun等的方法所复原的图像1均只检测到两辆轿车,而文中方法和其余2种方法所复原的图像1均被检测到4辆汽车,且文中方法置信度比DeblurGAN方法高;原模糊图像2只被检测到2辆轿车,而经4种去模糊方法分别处理后,前方3辆轿车被成功检测到,且文中方法和Nah等的方法还检测到后方的卡车。

(a)图像1

(b)图像2

(c)图像3

图像1

图像2(a)原模糊图像

复原图像1

复原图像2(b)Sun等的方法的处理结果

复原图像1

复原图像2(c)Nah等的方法的处理结果
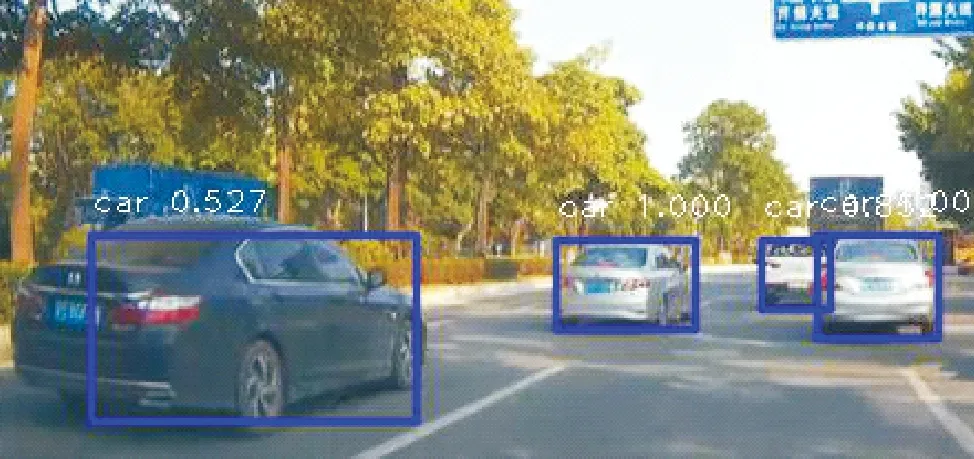
复原图像1

复原图像2(d)DeblurGAN方法的处理结果

复原图像1

复原图像2(e)文中方法的处理结果
Fig.7SSD object detection results before and after deblurring
4 结论
(1)文中提出的基于DeblurGAN和低秩分解的图像去运动模糊方法,经过分析DeblurGAN存在的不足,在其损失函数上加入互信息损失和梯度图像L1损失,同时将DeblurGAN中的3*3标准卷积改为瓶颈结构,并在瓶颈结构内进行低秩分解;此外,在预处理阶段将图像封装成二进制格式,加快数据读取速度,缩短了训练时长;经实验验证,该方法在保证PSNR略高于DeblurGAN、SSIM值基本相同的情况下,网络模型大小压缩至DeblurGAN的3.25%,平均每张图像处理速率提升3倍,使得对大量图像进行去模糊时,可节省很多时间,且计算量的减少降低了对硬件计算能力的要求。
(2)通过用不同方法对200张现实场景的车载模糊图像的去模糊处理,证明了文中方法所得图像的信息熵和平均梯度均高于Sun等的方法和DeblurGAN方法。
(3)通过SSD检测框架对去模糊前后的图像进行检测,结果表明,文中方法复原图像的检测效果优于Sun等的方法和DeblurGAN方法,检测准确率比去模糊前高11.7个百分点,这有助于车载图像快速有效去模糊和智能辅助驾驶,且对移植到数码照相机和手机等计算能力受限的系统进行照片去抖有一定现实意义。
