P2P网络借贷信用风险度量模型的对比研究
——以“Prosper”和“拍拍贷”为例
2020-01-16西南财经大学法学院邓春生
西南财经大学法学院 邓春生
1 引言
自2007年拍拍贷在上海成立以来,P2P网络借贷在我国取得了迅猛发展。与此同时,P2P平台在信用风险、技术风险、政策风险等因素的作用下,给P2P行业乃至整个金融行业的健康稳定发展带来了巨大的压力。为此,政府部门密集出台了一系列P2P行业相关的监管制度,意图让P2P行业的发展回归理性和健康。密集的监管制度出台必然会给行业发展带来一些波动,例如2018年全年我国P2P网贷行业的成交量达到17948.01亿元,相比2017年下降36.01%。
目前,国内外众多学者对P2P网络借贷借款人的信用风险度量进行了广泛且深入的研究。针对P2P网络借贷借款人信用风险度量模型,主要分为以下两种:(1)统计回归模型。Lin &Li et al(2016)应用二元逻辑斯回归方法建立了一个综合的信用风险评估模型,以便量化每笔贷款的违约风险。Serrano-Cinca &Gutiérrez-Nieto(2016)以预期盈利能力为着眼点,使用多元回归建立利润评分系统,进而选择最优的借款人。Lee &Lee(2012)首先分析了影响信用风险的相关变量,然后利用多项式逻辑市场份额模型对信用风险进行评估。(2)机器学习模型。涂艳等(2018)基于拍拍贷的交易数据,基于机器学习建立的借款人信用风险度量模型,其准确率要高于传统回归模型。Xia,Liu &Liu(2017)通过结合成本敏感学习和极端梯度增强方法,提出了一种新的成本敏感提升树模型,用以提高区分潜在违约借款人的能力。Ma&Sha et al(2018)针对Lending Club的数据,应用现代机器学习算法LightGBM和XGboost进行了信用风险度量风险。Ma,Zhao &Zhou(2018)针对信息不对称前提下的P2P平台贷款决策问题,通过借款人的手机/电话通讯数据,利用自适应增强算法(AdaBoost)建立了违约风险预测模型。Kim &Cho(2019)针对Lending Club中的无标签数据,结合Dempster-Shafer理论和转导支持向量机(TSVM)方法对违约风险进行了准确预测。Wang &Jiang et al(2017) 针对发生率分量,应用随机森林来预测是否违约;针对延时风量,应用随机生存林来预测何时违约。Malekipirbazari &Aksakalli(2015)针对Lending Club数据,提出了一种基于随机森林的分类方法用于预测借款人的信用风险状 态。
众多的学者已经利用各式各样的方法对P2P网络借贷的风险进行了度量分析。但是,没有免费的午餐定理指出,不存在某一个方法或模型在所有性能上都是最优的。在众多的信用评分模型中,不可能存在某一个模型在所有信用风险相关数据集上都适用,那么对决策者来说就存在最优决策问题。因此,如何选稳健的评价和选择鲁棒的分类方法就是一个非常重要的问题。为此,本文针对Prosper和拍拍贷两个数据集,应用了11种分类算法进行对比研究,以期得到对P2P网络借贷信用风险度量问题最合适的方法类型,也为以后开发综合性能更优以及对P2P网贷行业符合度更高的度量方法奠定研究基础。
2 信用风险度量模型简介
信用风险的评分模式主要是一些分类方法。分类,是有监督学习中的一种,以待分析的目标问题为背景,采用一部分样本数据建立一个关于类别属性划分的分类方法,并利用该方法对同类问题中类别标记未知的样本进行学习和判断的过程。现在,让我们对一些主流的分类算法进行简单介绍。
2.1 决策树类算法
决策树类算法是一种逼近离散函数值的典型分类方法。决策树算法通过构造决策树来发现数据中蕴涵的分类规则。(1)C4.5算法:由于C4.5算法生成的决策树能够被用于分类,所以C4.5模型通常被用于统计分类。2011年,Witten &Frank (2011)将C4.5模型描述为“一个具有里程碑意义的决策树算法,可能是迄今为止在实践中最广泛使用的机器学习方法”。(2)CART算法:CART(Classif cation and regression trees)算法是一种十分有效的非参数分类和回归方法。CART选择具有最小GINI系数值的属性作为分裂属性,并按照节点的分裂属性,采用二元递归分割的方式把每个内部节点分割成两个子节点,递归形成一棵结构简洁的二叉树。
2.2 函数类算法
(1)RBF(径向基)神经网络模型:RBF神经网络是使用径向基函数作为激活函数的人工神经网络,其中径向基函数表示其取值仅仅依赖于离原点距离,即满足特性的函数。RBF神经网络通常由三层组成:第一,输入层;第二,具有非线性RBF激活函数的隐藏层;第三,线性输出层。(2)MLP(多层感知)神经络模型:MLP是一类的前馈人工神经网络,可用于通过回归分析创建数学模型。由于分类是响应变量是分类时回归的特定情况,因此MLP也是良好的分类器算法。(3)SVM(支持向量机)算法:SVM(support vector machines)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。
2.3 贝叶斯算法
(1)NBC(朴素贝叶斯分类)算法:NBC(Native Bayes Classif er)是一种简单但是非常强大的线性分类器,而且它所需估计的参数很少,对缺失数据不太敏感,方法也比较简单。(2)BN(贝叶斯网络)算法:BN(Bayesian Network)也叫贝叶斯信念网络,借助有向环图来刻画属性之间的依赖关系,并使用条件概率表来描述属性的联合概率分布。(3) NBT(朴素贝叶斯决策树)算法:该算法主要有两个优点:第一,算法过程非常清晰、直观、可理解性很强;第二,在计算复杂度不高的前提下能保持较高的分类正确率,有利于在大型数据集中的利用。
2.4 K邻近(KNN)分类算法
K邻近分类算法的基本思想是:输入没有标签(标注数据的类别),即没有经过分类的新数据;首先,提取新数据的特征并与测试集中的每一个数据特征进行比较;其次,从测试集中提取K个最邻近(最相似)的数据特征标签,统计这K个最邻近数据中出现次数最多的分类,将其作为新的数据类别;类似于生活中的“物以类聚,人以群分”。
2.5 基于规则的算法
(1)CBA(基于关联规则的分类)算法:CBA(Classification base of A ssociation)算法,即基于关联规则进行分类的算法,利用了Apriori挖掘出的关联规则,然后做分类判断。在某种程度上说,CBA算法也可以说是一种集成挖掘算法。(2)CPAR(基于预测关联规则的分类)算法:CPAR(Classification Based on Predictive Association Rules)模型整合了关联规则分类算法和传统的基于规则分类算法的优点。CPAR算法为避免过度拟合,采用贪心算法生成规则,这一策略比产生所有候选项集的效率要高。
3 评价指标
信用风险度量模型的评价实质上就是对分类模型的评价。为方便说明,引入如下混淆矩阵(confusion matrix),如表1所示。
考虑到对分类方法评估的科学性、全面性和客观性,我们选用了八个经典的评价指标,定义如下。
(1)正确率(ACC):正确率是指测试集中被正确分类的百分率,是最广泛使用的分类评估指标之一,即:
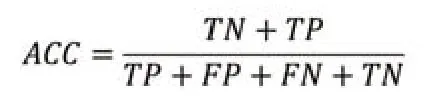
通常来说,ACC越高,分类器越好。
(2)真正率(TPR):指被正确划分的预测正样本数的百分率,即:
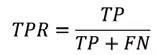
TPR也称为灵敏度指标,用于衡量分类器对正样本的识别能力。
(3)真负率(TNR):指被正确划分的预测负样本数的百分率,即:

表1 混淆矩阵示意图
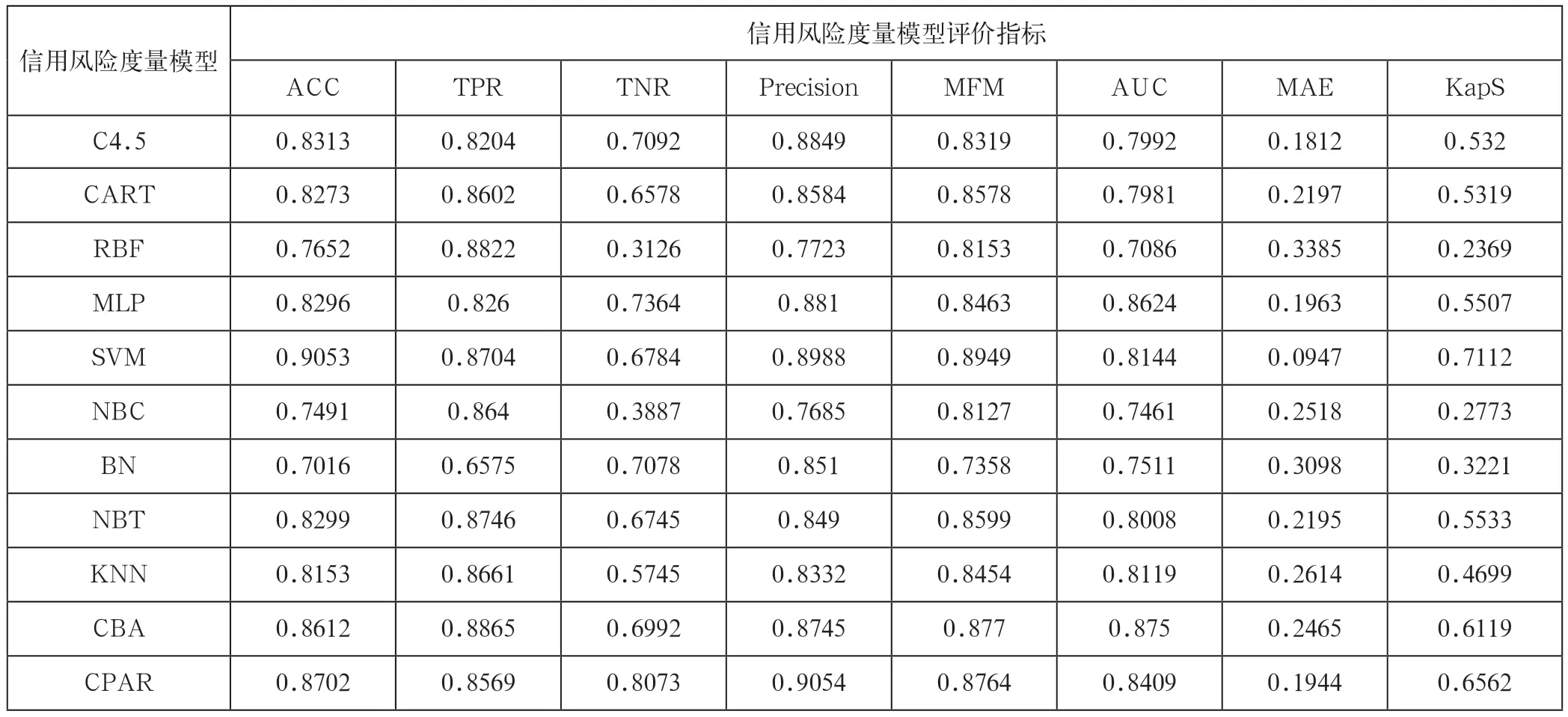
表2 针对Prosper数据集的信用风险度量模型的评价结果
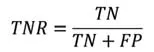
TNR也称为特异性指标,用于衡量分类器对负样本的识别能力。
(4)精度(Presision):指预测正样本中实际为正样本的百分率,是精确性的度量,即:
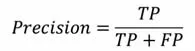
(5)F 1-measure(MFM,平均F测量)值:一个综合评价指标,指当精度与真正率矛盾时,对精度与真正率的综合考虑,即:

(6)AUC(Area under curve):是机器学习常用的二分类评测手段,直接含义是ROC曲线下的面积。曲线下面积越大,分类器就越好。
(7)平均绝对误差(MAE):指分类器的预测值和实际值之间的偏离程度,即:
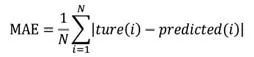
式中,ture(i)和predicted(i)分别表示第i个样本的真实值和预测值。
(8)Kappa 统计指标(KapS):一种用于衡量分类精度的统计指标,其计算基于混淆矩阵,即:

4 信用评分模型的 综合评价
针对Prosp er数据集和拍拍贷数据集的11个信用评分模型在8个评价指标下的评价结果分别列在表2和3中。注意,粗体数字表示在某一指标下最优的评价值。
观察表2和表3,我们有如下结论:(1)在不同的评价指标下,不同的信用评分模型有不同的评价值,且没有一种信用评分模型在所有的评价指标下都是最优的。主要原因是:不同的评价指标,其评价侧重点也不一样。另外,信用风险的度量主要是一个典型的分类学习问题,那么不同的分类模型其学习的侧重点也不一样,所以不可能存在某一分类模型在所有评价指标上都是最优的。
(2)针对Prosper数据集,以SVM方法构建的信用风险度量模型在ACC、MFM、MAE和KapS这四个指标下是最优的。针对拍拍贷数据集,SVM方法在ACC、Precision、MFM、MAE和KapS这5个指标下表现最优。由此可见,SVM方法具有很强的稳健性。
为了全面、综合的评价这位11个信用风险度量模型,我们引入排序均值的概念,并以排序均值的大小来对这11个模型综合排序。表4展示了Prosper数据集和拍拍贷数据集上的排序均值和综合排序。
从表4中可以得出:(1)性能优越的信用风险度量模型主要是SVM方法、CBA方法和CPAR方法。(2)信用风险度量模型性能次优的模型主要是CART方法、MLP方法、NBT方法和KNN方法。(3)信用评分性能出现较大差异的方法是RBF网络,该方法的波动较大;在Prosper数据集中,RBF网络在指标TPR下表现为最优,但是其综合排序却是第10名。

表3 针对拍拍贷数据集的信用评分模型的评价结果
5 结语
(1)不同的信用度量模型在同一个数据集中有不同的表现,同一个信用度量模型在不同的数据集中性能表现也不尽相同。为了让同一个信用度量模型对不同的数据集都能有一致的评级性能,需要让数据集足够的大,让信用度量模型有充足的训练数据来学习出最优的参数。为此,我们应建立P2P网络借贷行业统一的个人/企业信用信息共享系统,以便建立P2P网络借贷行业统一的信用信息数据集,为建立客观有效的信用度量模型奠定数据基础,克服单一平台进行信用评级存在的数据不全、评价不准等问题。
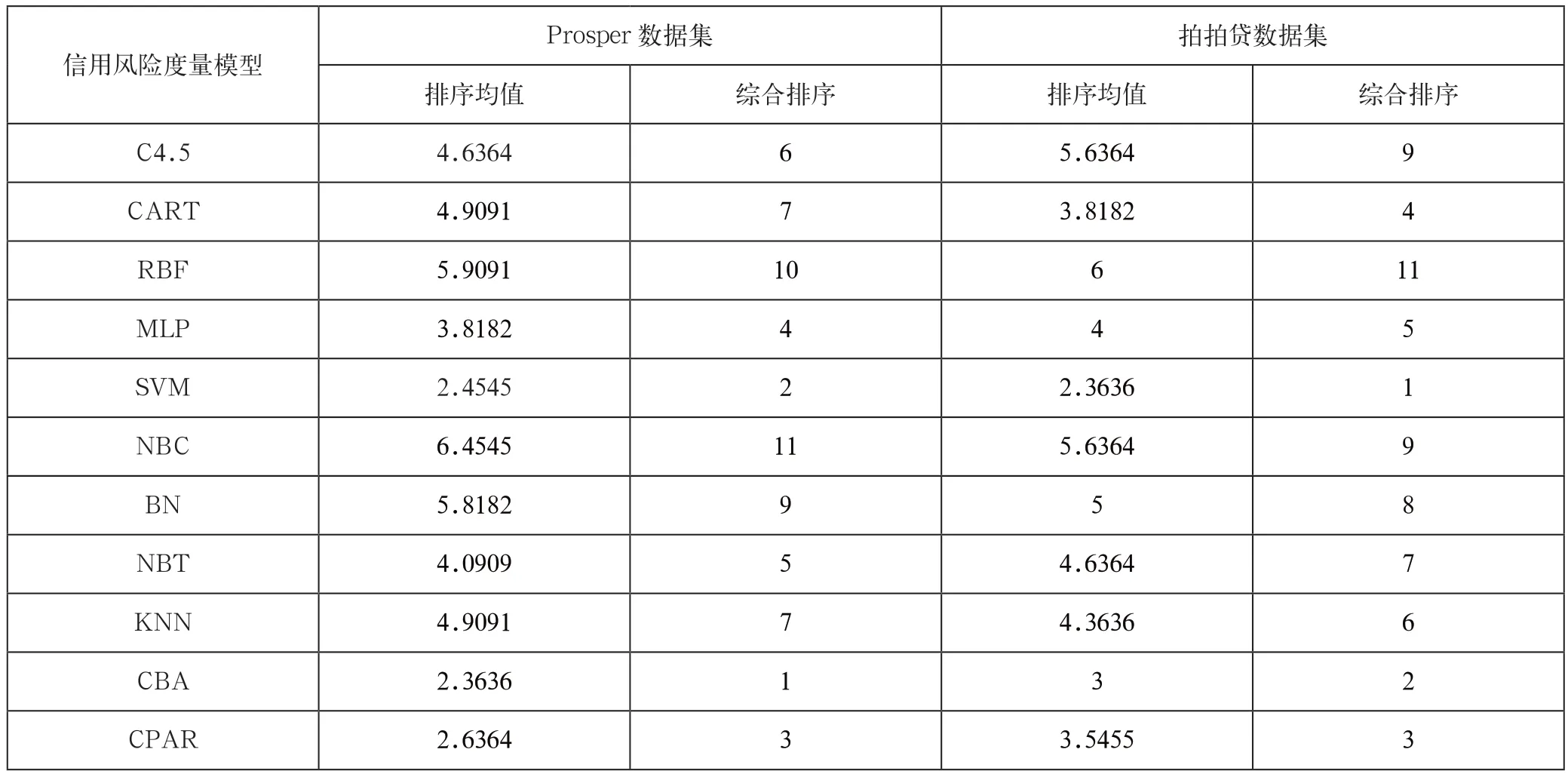
表4 信用风险度量模型综合评价
(2)根据我们的综合评估来说,针对所选择的数据集,在稳健性和鲁棒性上表现最优的三个信用度量模型分别是SVM方法、CBA方法和CPAR方法。另外,依据CART方法、MLP方法、NBT方法和KNN方法构建的信用评分模型也有不俗的表现。最后,出现波动比较大的方法是RBF网络方法。针对该结论,我们应建立P2P网络借贷行业统一的个人/企业信用评级系统,克服不同的平台使用不同的度量模型,对同一个借款人得出不同信用等级的问题。
