基于蚁群优化的特征基因选择算法
2020-01-14侯远韶
侯远韶
(河南工业贸易职业学院 机电工程系,河南 郑州 451191)
特征选择方法是影响机器学习分类速度和分类精度的重要一环。为了提高分类精度,减少数据计算的复杂度,从原始数据集中提取出一组最能表达原始图像信息的子集,即为特征选择方法。特征选择方法是一个NP问题,具体可以分为三大类即封装式(Wrapper)、过滤式(Filter)和嵌入式(Embedded)[1]。Wrapper方法首先利用特定的学习模型大致确定特征子集,通过学习模型的准确性带动特征搜索过程,将学习算法的优劣定性为评估特征选择的标准,进而得到最优子集。该方法需要对分类器进行多次训练才能对每一个子集进行评价,虽然精确度有所提高,但数据冗余计算量大,对数据集较大的模型并不适用。Filter特征选择方法利用数据自身的统计特性作为基因评价准则,通过判断特征子集与目标函数的相似度得到最优子集。该方法分类速度快,但准确率不高。Embedded特征选择方法为了得到最优特征子集,通过对原始数据进行学习模型训练,在训练过程中得到基因的最终表达形式。该方法虽然能够与学习模型互相影响,但时效性并不高[2]。蚊群算法作为一种解决组合优化问题的经典算法,可以很好地改善上述算法的不足,快速精确地提取到特征基因,进而实现提升机器学习分类的精度和速度。
1 蚁群算法
1.1 蚁群算法思想
蚁群算法(ACO)又称蚂蚁算法,是意大利人Marco Dorigo在1992年提出的基于模拟蚁群觅食行为寻找优化路径的一种自然估算算法[3]。本质上特征选择问题可以转化为求解离散组合的优化,蚁群算法可以通过选择机制、协调机制和更新机制进行优化。通过分析蚁群的遍历,得到起点和终点之间所有路径中最优的一条[4]。每个特征可以理解为蚁群觅食时经过的结点,通过0或1来表示蚂蚁选择的路径,0表示该基因没有被选中,1则表示该基因被选中。假设路径为{1,1,0,1,0}则表示第1,2,4个基因被作为特征基因进行下一步分类,而第3和第5个基因则作为冗余数据没有被选中。每只蚂蚁经过一次完整的起点到食物的过程称为遍历,即一个子集,则m只蚂蚁可以得到m个基因子集。蚂蚁之间通过每个特征结点的信息素表达最优的路径,蚂蚁之间在某一路径传达的信息素浓度越高,就意味着此路径的选择概率越大。特征子集(即蚁群觅食路径)的优劣可以通过适应度函数来得到,特征子集越好适应度函数越大[5]。基于蚁群的特征选择如图1所示。

图1 基于蚁群的特征选择
1.2 蚁群算法数学模型

(1)
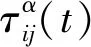

τij(t+1)=(1-ρ)τij(t)+Δτij
(2)
式(2)中:ρ∈[0,1]为信息素减弱程度;Δτij为信息素增量,即
(3)
2 特征选择
2.1 特征选择理论
为了降低数据维数,避免维数灾难的发生,需要从高维数据集中选择具有代表性的特征子集来表示原始的特征集,这一过程即为特征选择[6]。特征选择的数学描述为:假设一个原始数据集中有n个特征分别为X1,X2,X3,…Xn,可以分为Y类,通过有监督训练学习算法,得到能表示整个特征集的特征子集XOPT,即特征子集XOPT根据相应的评价准则确定为整个特征集的最优特征子集。特征选择具体流程如图2所示。
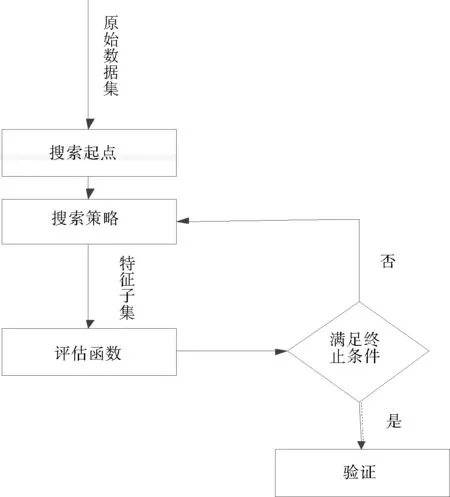
图2 特征选择流程
2.2 特征选择标准
特征选择主要有3个步骤:首先,利用数学方法将图像数据转化为矩阵形式,通过函数来表示图像特征即为特征的形成;其次,通过对原始图像数据集进行映射或者压缩感知等变换,将高维数据低维化,利用低维数据表示图像原始信息,即为特征提取;最后,依据相应的评价准则,从提取到的特征集中选择最优的、全面的、必需的特征子集,去除冗余的子集,即为特征选择。评价特征选择方法的优劣主要从鲁棒性、相异性、单独性(即相关性)和少量性等方面进行评判[7]。
不同特征子集可以分类是由于其属于特征空间中不同的区域,这些区域的选择标准主要有距离度量、信息度量、相关性度量和一致性度量[8]。当特征子集中不同样本类别距离尽可能大,同类别样本的距离尽可能小时,特征子集才是最优特征子集[9]。距离度量的数学表示为:存在样本集S中有n个特征分别为X1,X2,X3,…Xn,可以分为C个聚类,K1,K2,…KC(i=1,2,…C),每个样本维数为T,距离度量Fd的表达式为
(4)
式(4)中wi为类中心向量。其中
y=(y1,y2,…yT)
(5)
(6)
(7)
只有当取Fd最小值时,表明选择的子集为最优特征子集。
3 基于蚁群优化的特征基因选择
蚁群算法将路径结点作为特征,边缘作为下一特征选择,通过每只蚂蚁对整个路径的遍历,得到满足停止条件的最小数量的特征和结点[10]。但蚁群算法容易在局部循环,同时收敛速度慢,即蚂蚁会对同一路径重复搜索,导致算法停滞、计算数据量加大。同时算法对参数的要求比较高,参数的设置决定了算法的质量[11]。因此,需要对蚁群算法进行优化和改进。以往主要从以下几个方面进行算法的优化和改进。
a.增强概率的自适应性。蚁群算法将路径结点作为特征,边缘作为下一特征选择,因此对选择下一结点概率算法进行优化。
b.蚁群通过每个特征结点的信息素表达最优的路径,蚂蚁之间在某一路径传达的信息素浓度越高就意味着此路径的选择概率越大。因此,为了使信息素分配更加合理,对信息素更新规则进行优化。
c.将蚁群算法与其他智能优化算法相结合,如与粗糙集等相结合。
本文采用基于蚁群算法与粗糙集的特征基因选择算法。粗糙集作为研究不确定性方法,利用已知知识刻画不确定知识,可以解释不精确数据间的关系。定义信息系统可以由S=〈U,A,V,f〉表示,A表示非空有限条件属性集合,V表示属性的值域,U为非空有限条件对象集合,f则为V的映射即信息函数。其中∀a∈A,x∈U,f(x,a)∈U,f(x,a)∈Va,A=C∩D且C∩D=Φ。具体算法流程如图3所示。
输入:信息系统S=〈U,A,V,f〉。
输出:特征子集CS的最优解(Characters-Set)。
(1)将原始数据信息进行重置初始化。
a.最大重复反馈次数max=n,蚂蚁数目m,候选特征子集;
b.选择初始特征子集S,设定初始值为零,属性集的分类个数初始值为NULL;
c.将蚂蚁置于初始结点,设置初始值各特征结点信息素浓度为τi(0)=τ0。
(2)生成特征解和评价结点重要性函数。
a.构造解:在起始点随机放入m只蚂蚁,进行属性集遍历;
b.评价解:所有蚂蚁遍历后,选择最好的蚂蚁作为迭代的最优结果,通过评价结点重要性函数来得到特征子集的是否为最优子集。
(3)验证算法的终止条件。假如得到了特征子集且最大重复反馈次数已经到达了最大值,则进行步骤6,否则进行步骤4。
(4)环境信息素更新。将信息素的挥发和蚂蚁自身信息素的混合对结点信息素浓度的影响考虑进去,对属性结点的信息素浓度进行更新。
(5)每次完成遍历性后,生成新的蚂蚁。把每只蚂蚁的最后一个结点作为下一次迭代的开始,重复步骤2。
(6)输出最优特征子集CS。

图3 蚁群优化的特征基因选择算法流程
4 实验仿真
实验采用Matlab实验平台,电脑Windows XP操作系统,配置CPU为Intel I7处理器,16G内存。在进行实验前需要对样本数据集进行归一化处理,使得每个样本特征属性列的数据都属于[0,1][12]。为了验证算法的有效性和实用性,采用的样本数据为UCI数据库的3组数据和Internet上选定的2组数据,这些数据具有广泛的代表性。实验数据描述如表1所示。

表1 实验数据说明
为了验证算法的优劣,将本文算法与基于贪婪法的特征选择算法在实验数据集上进行测试,实验结果如表2所示。

表2 本文算法与基于贪婪法的特征选择实验性能
由实验结果可知,基于蚁群优化的特征基因选择算法和传统特征提取算法相比,不管是在准确率上还是在运行速度上都有一定的优势,可以大大提高分类效果,具有一定的应用价值。
5 总结展望
分析了蚁群算法的模型以及现有算法在进行特征选择时存在的不足之处。为了提高蚁群算法的准确性,利用特征对不同数据集的敏感度,寻找最优基因,滤除无关基因,同时引入粗糙集的属性重要度和依赖度,改进蚁群算法的参数选择方法,有效地提高了蚁群搜索的效率。实验结果表明,该算法具有一定的实用性和应用价值。
