基于词向量的文本特征选择方法研究
2018-07-04陈磊,李俊
陈 磊,李 俊
(中国科学技术大学 信息科学技术学院 自动化系,合肥 230026)
1 引 言
随着互联网的发展,以文本为主的非结构数据急剧增长,文本分类[1]已成为一个重要的研究课题,在机器学习和信息检索等领域得到了广泛研究和应用.文本分类就是从训练集学习分类模型,使用该模型对未知文本进行分类[2].然而,文本高维度的特征会影响分类算法的效果.因此,进行特征选择,对提升分类的准确率和速度具有重要意义.
传统的文本特征选择大多基于统计的方法,通过计算特征词在语料中的词频或特征词与类别的关系,来评价每个词对分类的贡献度.常用的特征选择方法有以下几种:DF[3](Document Frequency,文档频率)特征选择,利用训练集中特征词出现的文档数进行特征选择.通过设置阈值,过滤文档频率较低的特征词.该方法会忽略掉一些文档频率过低但对分类影响较大的特征词.CHI[4](Chi-square test,卡方检验)评价类别与特征之间的关系.其缺点是对低频特征词的区分效果不佳.IG[5](Information Gain,信息增益)通过计算特征项出现与否信息熵的变化大小,进行特征选择.缺点是信息增益值低的词其对分类贡献度可能比较高.以上几种基于统计的选择方法,都没有考虑特征的语义,特征选择效果还有很大的改善空间.
本文提出基于词向量的特征选择方法,分别从主题和词语上下文关系得到每个词的词向量.然后根据相应的评价规则完成特征选择.基于主题的词向量构建,本文利用Blei等人提出的LDA[6](Latent Dirichlet Allocation,潜在狄利克雷分布),将特征词映射到一个维度为K(主题数目)的主题空间上,得到特征词在不同主题下的概率分布.由于LDA是一个3层贝叶斯模型,LDA词向量可以视作一种浅层的词向量.Word2vec词向量是利用深度学习方法获取词的分布表示,本文利用Tomas Mikolov 提出的CBOW模型[7](Continuous Bag-of-Words,连续词袋模型),得到每个特征的Word2vec词向量.语料经特征选择后,利用VSM[8](Vector Space Model,向量空间模型),进行文本分类,检验特征选择效果的好坏.
2 基于LDA词向量的特征选择方法
2.1 LDA模型
LDA是一种主题模型,每篇文章表示为多个主题的分布,每个主题表示为不同词的概率分布.模型如图1,M表示语料中的文章数,K为主题数;V代表词典大小;θ是M*K的矩阵,θi是文档di的主题分布;z是每个词的主题,φ是K*V的矩阵,φz是第z个主题的词分布.对于文档di中的第j个词wi,j,其生成过程如下:依据文档主题分布θi,所决定的多项式分布Multi(θi),选择一个主题z.依据该主题词分布φz,所决定的多项式分布Multi(φz)生成词wi,j.α、β分别是文档主题分布和主题词分布的先验分布(即Dirichlet分布)参数.LDA参数估计主要有三类方法:变分期望最大化算法,期望-扩散算法和吉普斯算法.由于吉普斯采样简单、快速,本文采用吉普斯采样[9],求解模型参数φ和θ.

图1 LDA模型Fig.1 LDA Model
2.2 基于LDA的词向量特征选择
LDA模型训练完成后,主要得到两个矩阵φ(主题-词矩阵)和θ(文档-主题矩阵).类比于topic rank[10],对LDA生成的主题重要性进行排序,提出LDA的词向量特征选择,对主题词重要性进行排序.主题-词矩阵中,并非所有词都能表达相应的主题,词典中包含一些垃圾词汇,这些词会影响文章的分类效果.因此,构建LDA词向量,进行词的重要性排序可以协助文本分类.
LDA词向量wc=[wc,0,wc,1,wc,2…,wc,K-1],其生成方式是,根据主题词矩阵φ,转置后归一化.其中wc表示当前词,词向量第k维的权重为江大鹏[11]按照公式(1)计算LDA词向量进行短文本分类.本文提出LDA词向量特征选择方法LDA-w.LDA-w根据LDA训练得到的主题-词矩阵,按公式(1),得到每个词的词向量.然后计算词向量与垃圾词向量wnoise=[1/K,1/K,…,1/K]的1-余弦距离,得到每个词向量与垃圾词向量的距离distance,计算公式为式(2).垃圾词向量的每一维服从均匀分布,其熵最大,这样的词对分类的贡献度最低.词wc在语料中出现的概率为P(wc).将每个词与垃圾词的距离distance,同其在语料中出现的概率P(wc)结合,得到词的排序值rank,进行特征选择.
(1)
(2)
(3)
rank(wc)=distance(wc)*P(wc)
(4)
其中tk表示主题k,P(tk)表示主题k出现的概率.
由于LDA输出的主题中,存在一些意义不明的垃圾主题,所以有必要进行垃圾主题过滤,再求解每个词的词向量,使得词向量映射在更加有意义的主题空间中.为此,本文结合topic rank方法,利用LDA词向量进行特征选择.对topic rank进行了如下的简化处理:
(5)
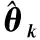
2)根据主题-词矩阵φ,计算当前主题的主题-词向量φk=[φk,1,φk,2,…,φk,V]与垃圾向量φnoise=[1/V,1/V,…,1/V]的1-余弦距离distancetopic->word.
3)当前主题与垃圾主题的距离定义为distance=a*distancetopic->doc+b*distancetopic->word.
其中a和b为可调系数.

与LDA-w和LDA-Rp特征选择不同,本文提出的Saliency特征选择方法,借鉴了LDA主题模型的可视化系统Termite[12].该系统提出定义特征词的Saliency,来衡量每个词对主题的重要性.对于一个给定的词wc,其distinctiveness定义为条件概率P(tk|wc)和P(tk)的Kullback-Leibler距离.
(6)
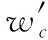
Saliency(wc)=P(wc)*distinctiveness(wc)
(7)
本文基于Saliency计算每个词的重要性,但是在计算Saliency时引入Laplace平滑.根据LDA训练得到的词-主题分配结果,计算P(tk|wc)和P(tk),定义如下
(8)
(9)
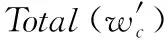
3 基于Word2vec词向量的特征选择方法
3.1 Word2vec
Word2vec是获得词向量的工具,它将每个词映射到一个特定维度的实数空间中,包含两种模型,CBOW和 Skip-gram[7](Continuous Skip-gram,连续阶跃文法模型).本文采用CBOW模型训练来获得词向量.这里介绍下CBOW模型,模型结构如图2所示.
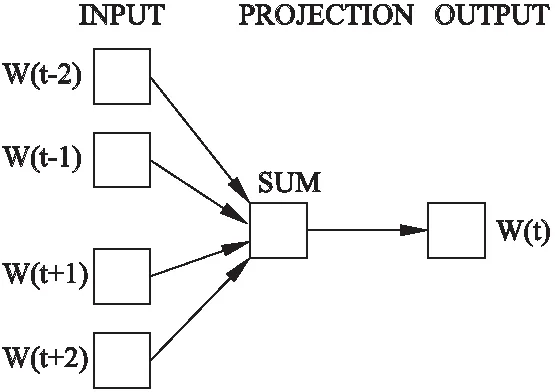
图2 CBOW模型Fig.2 CBOW Model
由图2可见,CBOW模型包含三层,输入层、投影层和输出层.CBOW是已知当前词w(t)的上下文词(前后各c个,这里c=2)w(t-2),w(t-1),w(t+1),w(t+1)预测当前词w(t).输入层是上下文中2c个词向量,投影层是这2c个词向量的累加和.输出层是语料中出现的词作为叶子节点,每个词出现次数作为权值的一棵Huffman树.利用随机梯度上升使L=∑w∈Clogp(w|Context(w))值最大化(Context(w)指词w上下文中的2c个词).模型训练完成,获得词的向量表示.Word2vec词向量可以表示词之间的关系,例如同义词,语义关系(中国-北京=美国-华盛顿)等.
3.2 基于Word2vec词向量的特征选择
Zengcai Su[13]在情感分析中,利用Word2vec词向量,计算与情感色彩强烈词的余弦相似度,保留相似度较高的词完成特征选择.Lei Zhu[14]使用Word2vec词向量改善信息增益.本文利用Word2vec词向量结合文档向量进行特征选择.Word2vec训练词向量完成后,提取出每篇文档的关键词.根据这些关键词的词向量,求和取平均得到每篇档文档的向量表示.
(10)
其中d表示采用的关键词个数,Cw表示关键词w的词向量.Chao Xing[15]采用了文档中所有特征词的词向量求和取平均得到文档的向量表示.这里选取关键词,考虑到一篇文档中大多数的词都是常用词,不能体现文档的中心思想.而关键词能够代表文档的主题,通过关键词求和取平均得到的向量,能够更加准确的代表文档.至于如何获取文档的关键词,文献[16]采用TF-IDF结合文章结构提取关键词.为了简化处理,本文使用TF-IDF方法,通过计算文档中每个词的TF-IDF权重,选取值最大的几个词作为文档的关键词.按公式(10)计算出训练集中每篇文档的向量表示形式.
基于Word2vec词向量的特征选择方法步骤如下:首先获得训练集中每个词的词向量以及根据关键词得到每篇文档的向量表示;接着,计算出训练集中每篇文档中的词与该文档向量的余弦相似度;最后,对文档中的词按与文档向量的相似度大小降序排列,通过设置阈值,保留相似度较大的特征词,进行特征选择.
4 实验结果与分析
4.1 数据集及评价指标
数据集采用复旦语料,实验前进行如下预处理:首先删除训练集和测试集中各自1500篇左右的重复文档;其次删除训练集中长度较短的文本;最后去除文章数较少的类别.最终训练集和测试集各9个类别,分别包含 7181和7872篇文档.对数据集,采用国内公认的中文分词系统ICTCLAS处理.经去停用词后,语料的词典包括60747个词.Word2vec词向量是在复旦语料和搜狗新闻语料上进行训练.
通过设置不同的特征选择比例,对语料进行特征选择.文本模型采用基于TF-IDF的向量空间模型,分类器采用SVM(Support Vector Machine,支持向量机),使用林智仁等开发设计的LibLinear软件包进行文本分类[17].
本文采用传统的文本分类标准.单个类别使用查全率R和查准率P来计算F1,对多类别分类使用宏平均MacroF1、微平均MicroF1,公式如下:
(11)
(12)
(13)
(14)
(15)
其中,Ti表示第i类分类正确的文档数,Ci表示分到第i类的文档数,Ni表示第i类实际包含的文档数,n表示类别数.
4.2 结果分析
为了验证本文提出的特征选择方法的有效性,共进行了7组实验,其中3组是传统的特征选择方法(DF,IG和CHI).LDA-w、LDA-Rp、Saliency和Word2vec(W2v)是本文提出的基于词向量的特征选择方法.LDA的主题数根据Blei等人采用的困惑度方法[6]确定为100,经过垃圾主题过滤后,LDA-Rp保留的主题数为95.通过设置不同的特征选择比例,分类效果如表1所示.
由表1可知,DF、IG和CHI特征选择的分类效果比较相近.四种词向量特征选择方法的分类效果均优于传统的特征选择方法.例如在特征选择比例为10%时,W2v的MicroF1比DF高0.7%左右.结合topic rank的LDA词向量特征选择LDA-Rp,分类效果相对于LDA-w方法,有一定的改善.Word2vec词向量特征选择方法,平均分类的效果最好.可能的原因是Word2vec获得的词向量比LDA获得的词向量更加合理、准确.Saliency特征选择分类MicroF1略低于LDA-w和LDA-Rp.以上几种特征选择方法随着特征选择比例增高,MicroF1变化波动趋于稳定.下面分析特征选择维度较低时,分类的MicroF1变化情况.由于DF、IG和CHI特征选择的分类效果相近,这里只考虑DF的分类效果作为对比.
图3为特征选择比例低于10%时,分类的MicroF1变化情况.图中显示了特征维度从500到5000时,W2v、lda-w、lda-Rp、Saliency和DF的分类MicroF1变化曲线.由图可知,四种

表1 分类微平均F1(%)Table 1 Micro average F1(%)
词向量的特征选择方法分类效果,在特征维度较低时,均优于DF.尤其是Saliency和lda-Rp的分类MicroF1明显优于DF.例如在特征维度为1000左右时,Saliency和lda-Rp的MicroF1高出DF将近1.5%.W2v的分类效果,在特征选择维度较低时比lda-w等LDA词向量特征选择方法低.原因是LDA词向量特征选择方法,不仅考虑了特征的语义信息,还加入了特征在语料中出现的概率.lda-w和lda-Rp方法计算了每个词与垃圾词的距离,再结合词在语料中出现的概率大小进行特征选择.Saliency特征选择也是先计算出每个词对主题的distinctiveness,最后再结合词出现的概率,完成特征选择.而W2v特征选择仅仅利用了词的上下文语义,没有考虑词频信息.在维度较低时,W2v选择部分语义丰富的低频词,导致语料中出现短文本.因此W2v分类效果在低特征维度时,没有LDA词向量特征选择效果好.DF在特征选择维度较低时分类效果最差,原因是DF仅仅考虑每个词的文档频率.而文档频率高的有些词,包含的语义不够丰富,其分类的贡献度比较低.

图3 Micro F1值Fig.3 Micro F1 Score
5 结束语
本文提出了几种基于词向量的特征选择方法,分类的效果相对于传统的特征选择方法,有一定的提升,尤其是在特征维度比较低时,分类效果改善明显.同时,传统的特征选择如IG和CHI,需要获得类别标注信息.然而在数据急剧增长的今天,获得有标注的数据越来越困难.基于词向量的特征选择,是一种无监督的方法,无需事先标注样本信息,因此具有更广泛的特征选择用途.未来的工作包括研究LDA和Word2vec结合的特征选择方法,词向量和传统特征选择结合的方法.
:
[1] Patel F N,Soni N R.Text mining:a brief survey[J].International Journal of Advanced Computer Research,2012,2(4):243-248.
[2] Tated R R,Ghonge M M.A survey on text mining-techniques and application[J].International Journal of Research in Advent Technology,2015,1:380-385.
[3] Azam N,Yao J T.Comparison of term frequency and document frequency based feature selection metrics in text categorization[J].Expert Systems with Applications,2012,39(5):4760-4768.
[4] Tran V T N,Phu V N,Tuoi P T.Learning more chi square feature selection to improve the fastest and most accurate sentiment classification[C].The Third Asian Conference on Information Systems (ACIS 2014),2014.
[6] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[7] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].arXiv Preprint arXiv:1301.3781,2013.
[8] Ababneh J,Almomani O,Hadi W,et al.Vector space models to classify Arabic text[J].International Journal of Computer Trends and Technology (IJCTT),2014,7(4):219-223.
[9] Darling W M.A theoretical and practical implementation tutorial on topic modeling and gibbs sampling[C].Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies,2011:642-647.
[10] AlSumait L,Barbará D,Gentle J,et al.Topic significance ranking of LDA generative models[C].Joint European Conference on Machine Learning and Knowledge Discovery in Databases,Springer Berlin Heidelberg,2009:67-82.
[11] Jiang Da-peng.Research on short text classification based on word distributed representation[D].Hangzhou:Zhejiang University,2015.
[12] Chuang J,Manning C D,Heer J.Termite:Visualization techniques for assessing textul topic models[C].Proceedings of the International Working Conference on Advanced Visual Interfaces,ACM,2012:74-77.
[13] Su Z,Xu H,Zhang D,et al.Chinese sentiment classification using a neural network tool—Word2vec[C].Multisensor Fusion and Information Integration for Intelligent Systems (MFI),2014 International Conference on.IEEE,2014:1-6.
[14] Zhu L,Wang G,Zou X.Improved information gain feature selection method for Chinese text classification based on word embedding[C].Proceedings of the 6th International Conference on Software and Computer Applications,ACM,2017:72-76.
[15] Xing C,Wang D,Zhang X,et al.Document classification with distributions of word vectors[C].Asia-Pacific Signal and Information Processing Association,2014 Annual Summit and Conference (APSIPA),IEEE,2014:1-5.
[16] You E S,Choi G H,Kim S H.Study on extraction of keywords using TF-IDF and text structure of novels[J].Journal of the Korea Society of Computer and Information,2015,20(2):121-129.
[17] Fan R E,Chang K W,Hsieh C J,et al.LIBLINEAR:a library for large linear classification[J].Journal of Machine Learning Research,2008,9:1871-1874.
附中文参考文献:
[11] 江大鹏.基于词向量的短文本分类方法研究[D].杭州:浙江大学,2015.
