一种基于粗糙集证据理论深度融合的局部冲突快速合成方法
2020-01-08倪龙强张丽华姚新涛胡高歌刘鹏辉
倪龙强,张丽华,姚新涛,胡高歌,刘鹏辉
(1.西北机电工程研究所,陕西 咸阳 712099;2.西北工业大学 自动化学院,陕西 西安710072)
0 引言
现代检测、认知、规划、决策与控制系统所面对的环境、任务越来越呈现出复杂系统的多样性、不确定性、不可预见性等特征。例如:在复杂环境态势感知中,需用到不同维度、不同模态的检测信息进行联合识别和跟踪,以提高态势感知信息的完备性、客观性和可理解性[1];在联合检测、识别中,气象、地理、电磁等因素可能会导致某些传感器对目标或目标的某一特性检测性能下降等[2]。因此对分布式检测与融合方法提出了新的更高要求。主要表现在以下两方面:1)如何基于大量传感器检测信息进行快速融合;2)如何在各检测数据源检测信息不完备、相互冲突条件下完成分布式探测信息的融合。
在经典贝叶斯框架下,证据理论将每个传感器量测信息看作一个证据体,每个传感器量测信息可能包含若干检测属性,该检测属性称为证据焦元,一条证据体包含若干证据焦元。传感器检测对每个属性的支持度称为焦元基本信度分配(BBA)函数,证据理论通过对证据体进行两两组合来更新BBA函数。由于证据推理过程只能对证据体进行两两合成,在证据体较多时计算量呈指数性增长,同时传统证据推理问题在两条证据体存在冲突时可能得到有悖常理的组合结果。因此,近年来领域专家对证据理论的合成规则进行了大量研究修改,以期获得更加客观、统一的决策信息[3-7]。
关于冲突证据合成问题的研究最早可以追溯到1986年,Zadeh在文献[8]中首次指出:当待合成证据体存在高度冲突时,Dempster-Shafer(D-S)组合规则会导致错误的融合结果。针对冲突证据合成问题,Smets[9]提出了基于闭世界和开世界假设的冲突证据合成修正方法。其中闭世界假设认为:冲突合成中产生错误结果的原因在于证据源受到干扰或合成规则的问题[10];开世界假设建立在证据体完全可靠的基础上,认为冲突的形成是由于辨识框架不完备所引起的,例如新模式、新方法的出现[11]。由于在实际应用中,很难满足证据源完全可靠的前提假设,同时新模式很难事先确定,因此对冲突证据合成的改进大多数基于闭世界假设。在闭世界假设中,对证据合成的修正主要表现为:1)对融合证据源进行修正;2)对证据组合规则进行修正[12-14]。
对融合证据源的修改认为:D-S融合规则本身没有问题,造成有悖常理的融合结果其主要原因在于证据体本身存在的冲突等因素,因此通过对待合成证据体进行预处理,再应用D-S组合规则进行证据合成[15-19];对证据规则的修正认为:证据合成规则应能够适应不同数据源,因此应当对证据合成规则进行修正[20-21]。
由于从冲突中不能直接给出正确或错误的结论,应将冲突按照一定的规则分配给待合成证据体,从而达到抑制冲突、增强一致的目的。假设传感器量测的不一致来源于对某一检测属性的不稳定量测,因此应从传感器量测信息中发现传感器探测稳定性;利用传感器量测差异来描述传感器量测冲突。粗糙集通常被用来进行知识系统分类,其与证据理论可以相互描述,同时具有很强的互补性[22]。由于无需任何先验知识就能够发现信息系统内存在的关联规则,近年来关于粗糙集与证据理论相结合的研究大都集中在刻画知识系统中的不确定性[23]、数据预处理[24-27]等方面。
为解决证据合成在规则提取方面存在的不足,本文应用粗糙集理论对分布式传感器获取的大量检测信息进行属性约简,从而降低待合成证据体的维度,同时计算出每条检测记录的支持度,并在证据合成规则中通过引入证据体支持度、焦元差异化等因素来刻画证据体之间的冲突,以期降低证据组合中的计算量,提升冲突证据合成的客观性和可理解性。
1 粗糙集属性约简及冲突证据合成
1.1 基于粗糙集的信息系统属性约简
在粗糙集中(U,A,F)表示一个信息系统,其中:U为对象集,
U={x1,x2,…,xn},
(1)
xi(i≤n)称为1个对象,n为对象总数;A为属性集,
A={a1,a2,…,am},
(2)
al(l≤m)称为1个属性,l为属性标号;F为U与A之间的关系集合,
F={fl:U→Vl(l≤m)},
(3)
Vl为al(l≤m)的值域。
对于任意的B⊆A,记
RB={(xi,xj)|fl(xi)=fl(xj)}(al∈B),
(4)
则RB是U上的等价关系;记
[x]B={xj|(xi,xj)∈RB},
(5)
则U/RB={[xi]B|xi∈U}是U上的划分。划分可以在特定关系下将信息系统分为若干类,关于粗糙集的其他性质可参考文献[8]。
1.2 D-S证据推理及冲突证据合成
令A为信息系统(U,A,F)中所有属性的集合,并且A中包含的所有元素互不相容,此时A为对象xi的识别框架。由于证据理论采用信任函数来度量对某一属性的未知程度,fl(xi)→[0,1],满足下列条件:
(6)
此时称fl(xi)为属性al的一个基本概率赋值,fl(xi)表示在对象xi(可表示某一传感器、某一探测源或某一故障模式)下对属性al的精确信任度,表示对属性al的直接支持程度。
设f1(·)和f2(·)分别是属性集合A上两个信任函数的基本概率指派,其焦元分别为ai和aj.定义
(7)
此时,D-S证据合成公式可以表示为(8)式所示的形式:
(8)
式中:K1有时也被称为冲突系数,如果K1≠1,则f(xk)可确定一个基本概率指派值;如果K1=1,则认为待合成证据体x1和x2冲突,此时不能应用D-S证据合成规则对基本概率指派进行组合。
2 粗糙集证据理论深度融合的冲突证据合成
2.1 证据冲突形成的原因分析
在假设多数(传感器总数的50%以上)传感器量测均为可靠量测的前提下,至少可以得到以下结论:1)多数传感器量测产生较一致的量测信息;2)个别证据体与其余证据体产生较大差异时,可能是由于该传感器的误检测或传感器性能下降等原因引起的;3)个别证据体某一焦元产生异常,可能是由于该检测传感器,在某一属性的检测上发生错误或其他原因(如遮挡、气象条件、电磁干扰等引起的对目标某一检测属性的检测性能下降)造成对该属性检测的异常。
基于以上假设,可以认为待合成证据体冲突主要来源于:1)待合成证据体相互之间支持度不一致引起的冲突;2)待合成证据体中同一焦元支持度在辨识空间中所占比例不同引起的冲突;3)不同证据体中同一焦元属性不一致引起的冲突。
因此可以认为:1)数据集中其他证据体对该证据体支持度高的证据体可信度大;2)在满足1的情况下,证据焦元在该证据体中占比较大,该焦元可信度高;3)不同证据体之间,相同焦元在待合成证据体中所占比例差异大的冲突高,因此一致性较低,可信度与一致性高的相比要低。
由以上分析可知粗糙集证据理论深度融合的数据挖掘方法如下:首先应用粗糙集对各传感器获得的证据体进行属性约简从而降低数据集维度,并计算证据体之间的相互支持度;其次计算证待合成证据体中同一焦元支持度在证据体中所占比例;再次计算不同证据体中同一焦元支持度的差异化程度;最后将以上计算结果通过冲突化因子的形式引入证据合成公式。具体过程如图1所示,其形象化描述如图2所示。图2中a1、a2、a3、a4为证据焦元属性,mi(*)为证据体i的焦元属性值,i=1,2,3,4.

图1 处理流程Fig.1 Procedure of fusion processing

图2 局部冲突计算过程示意图Fig.2 Schematic diagram of local conflict calculation
2.2 冲突因子的计算
假设对表1所示的两条证据体应用D-S证据合成规则进行合成。

表1 冲突证据Tab.1 Conflict evidences
此时尽管证据体x1和x2对事件a2的支持度都很低,计算得到冲突系数为K1=0.99,由D-S组合规则合成的结果如表2所示,该结果显然是不合理的。

表2 冲突证据合成结果Tab.2 Synthesis result of conflict evidences
仍然以表1的两条证据体为例,当收到第1条证据体时,直觉上第1条证据体x1完全支持属性a1,在接收到第2条证据体时,直觉上第1条证据体x2完全支持属性a2.显然造成证据合成结果的主要问题在于,两条证据体对同一属性的支持度产生了强烈冲突。接收到若干个证据体后的证据体如表3所示。

表3 包含多条证据体的冲突证据Tab.3 Evidence set including multiple conflict evidences
此时可以通过2.1节所述粗糙集理论对待合成证据体进行分类和属性约简,并计算信息系统对每条证据体的支持度,将证据体的重复因素纳入计算。如果将信息系统对某一条证据体的支持度表示为Supp,则通过属性约简后,待合成证据体如表4所示。

表4 通过属性约简的待合成证据体Tab.4 Evidences to be synthesized by attribute reduction
通过表4可以看出:约简后的证据体仍为冲突证据体。例如分布在不同区域的传感器可能受到某一频段干扰,有可能导致这种情况的产生。冲突的主要来源为:1)信息系统对每条证据体的支持程度不同,此时信息系统对第2条证据体的支持程度高于对第1条证据体的支持程度;2)同一证据体中,不同焦元在辨识空间上所占比例大小,直接影响证据合成中该焦元对合成证据焦元的贡献程度,所占比例大,则合成贡献大;3)两条证据体对同一属性焦元支持度的差异,如表4所示的两条证据体对属性a1和属性a3的支持度完全矛盾,差异越大说明冲突越大,即便是不同证据体对同一焦元属性支持度均相同,也要考虑焦元支持度在辨识空间上所占的比例,如表3和表4所示;不同证据体对属性a2的支持度完全一致,同时支持度都很低,此时有理由相信合成属性为a2的可能性较低。
造成以上结果的原因是多方面的,例如:通信传输误码率、传感器本身或特定环境下对于某一属性探测性能较低等。为讨论方便,将表4改写为表5所示的形式。
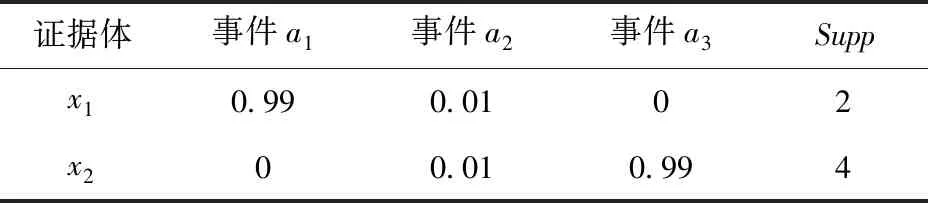
表5 对表4的简化描述Tab.5 Simplified description for Tab.4
通过以上讨论和分析,可以通过以下步骤对待合成证据体的冲突进行计算。
步骤1计算信息系统对证据体的支持度,
(9)
步骤2计算待合成证据空间对不同证据体相同焦元的支持度,
(10)
步骤3计算不同证据体之间同一焦元的差异化程度,
(11)
由(9)式可以看出:信息系统对证据体支持度高的证据体可信度高;由(10)式可以看出:相同焦元在待合成证据空间占比较高的属性获得的支持度较高;由(11)式可以看出:待合成证据体中,不同证据体之间同一焦元差异化程度大的焦元可信度低。
由于充分考虑了待合成证据体与信息系统、证据体与焦元、证据体相同焦元之间的支持度、比例以及一致性等因素,对冲突分配考虑得相对较全面,同时基于以上因素进行分配增强了冲突分配的客观性和合理性。
2.3 证据合成
通过以上讨论与分析可知,由于冲突中包含一些潜在有用信息,冲突中有些部分对待合成证据体及属性焦元起到支持作用、有些起到削弱作用,待合成证据体、焦元属性之间存在的冲突应该在引起冲突的证据体及焦元属性之间进行分配。因此证据合成公式可以表示为
(12)
式中:ci(x)为各局部冲突分配给焦元ai的部分,
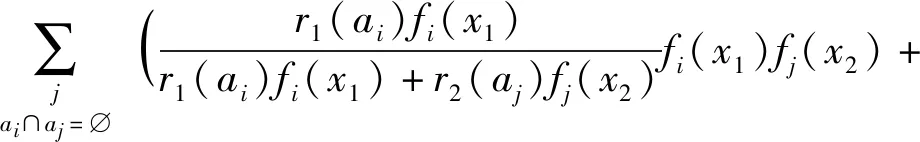
(13)
r1(ai)、r2(ai)分别表示待合成证据体1、2中证据焦元ai的可信度。由于(9)式~(11)式所示的证据体支持度、焦元支持度以及焦元差异化程度反映了证据体冲突程度,因此可以用(9)式~(11)所示的因子对焦元可信度进行描述。(10)式所示的焦元支持度满足归一化准则,可以直接用来进行冲突分配,对(11)式所示焦元差异化程度进行归一化处理,可得
(14)
此时可将冲突通过证据体支持度进行分配,例如在表5中由于信息系统对第2条证据体支持度高,在证据合成中应加大该证据体包含证据焦元的合成比例。假设对两条证据体进行合成,信息系统对证据体1的支持度为Supp1,对证据体2的支持度为Supp2,则证据体1中焦元在证据合成中的可信度如(15)式所示,证据体2中焦元在证据合成中的可信度如(16)式所示:
(15)
(16)
由于在证据合成之前通过粗糙集对信息系统进行了属性约简,消除了重复证据体参与证据合成计算带来的时间消耗,同时在冲突证据合成中充分考虑了信息系统对证据体的支持度、待合成证据体焦元在辨识空间中所占的比例以及待合成证据体对同一证据焦元之间存在的冲突等因素,因此可有效降低待合成证据数量,同时对冲突分配相对客观。
3 算法验证
3.1 测试数据说明
为了验证本文所提算法的有效性,采用表6所示的测试数据集,测试数据包括5条证据体,每条证据体包含3个属性。同时有3条证据体完全相同,有1条证据体与其余4条证据体完全冲突,具体测试数据见表6.

表6 测试数据Tab.6 Test data set
在进行证据融合之前,先通过粗糙集对表6所示的测试数据集信息系统进行分类约简,经过分类约简的证据体数据集信息系统如表7所示。
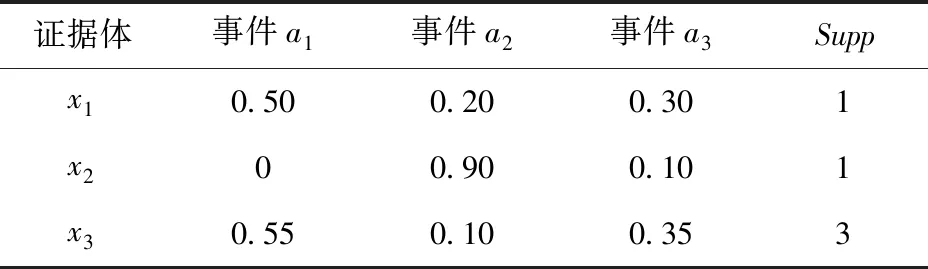
表7 约简后的测试数据集Tab.7 Test data set based on rough sets reduction
3.2 算法测试结果
应用不同融合规则对表6、表7所示的测试数据进行证据组合,结果如表8所示。应用D-S合成规则的合成结果如图3所示,应用本文合成方法合成的结果如图4所示。
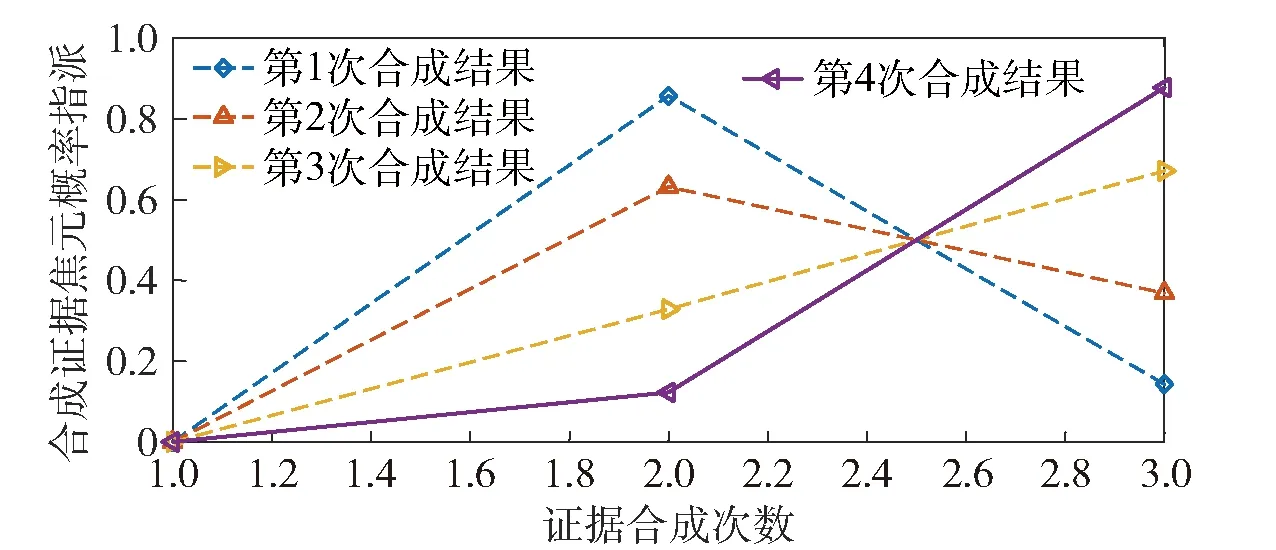
图3 D-S方法合成结果Fig.3 Synthetized results of D-S

图4 本文方法合成结果Fig.4 Synthetized results of proposed combination rule
3.3 计算复杂度比较
假设有100个传感器对目标进行检测,融合中心接受到的证据体重复率分别为0%,10%~90%(在实际应用中,传感器量测往往会存在微小差异,此时可以对传感器量测设置一定的门限值,并进行数据整定。如:传感器量测差异在某个范围内就可认为证据体完全相同)。分别应用D-S证据理论和基于粗糙集证据理论相融合的合成规则对以上证据体进行组合,并对合成计算时间消耗进行统计。由于粗糙集证据理论相融合的合成规则先进行粗糙集约减,再进行证据合成(包含冲突分配),因此不同证据重复率条件下的计算时间会存在差异。不同重复率条件下,经过仿真计算,得到应用D-S证据理论和应用粗糙集证据理论相融合的合成规则其计算时间消耗如图5~图14所示。
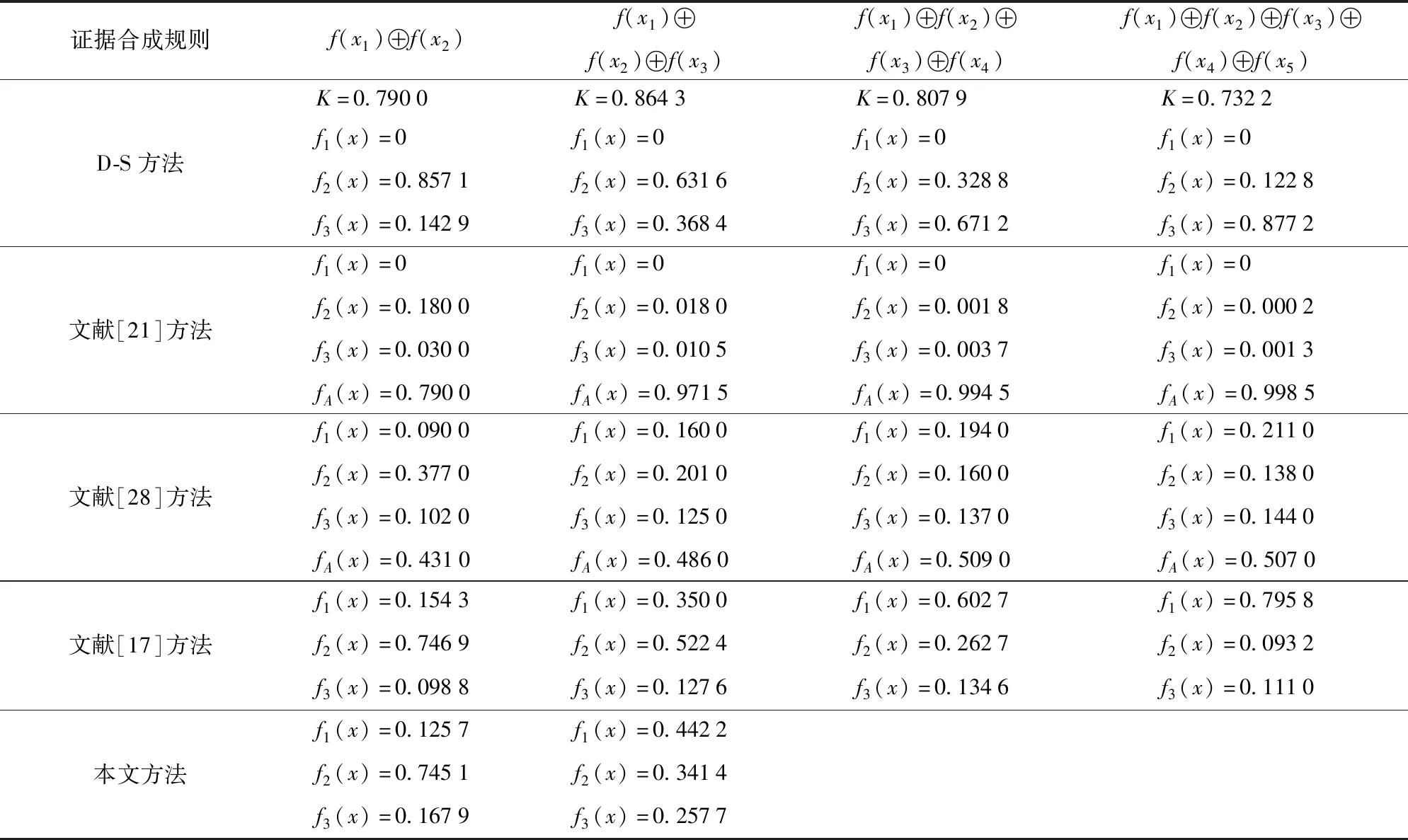
表8 合成结果比较Tab.8 Comparison of combined evidences of popular synthesis rules
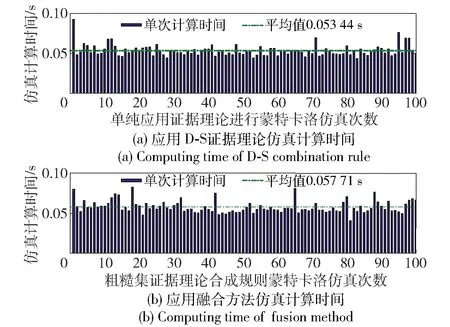
图5 重复率为0的证据体合成计算时间对比Fig.5 Computing time of evidence synthesis with repetition rate of 0

图6 具有10%重复率的证据体合成计算时间对比Fig.6 Computing time of evidence synthesis with repetition rate of 10%
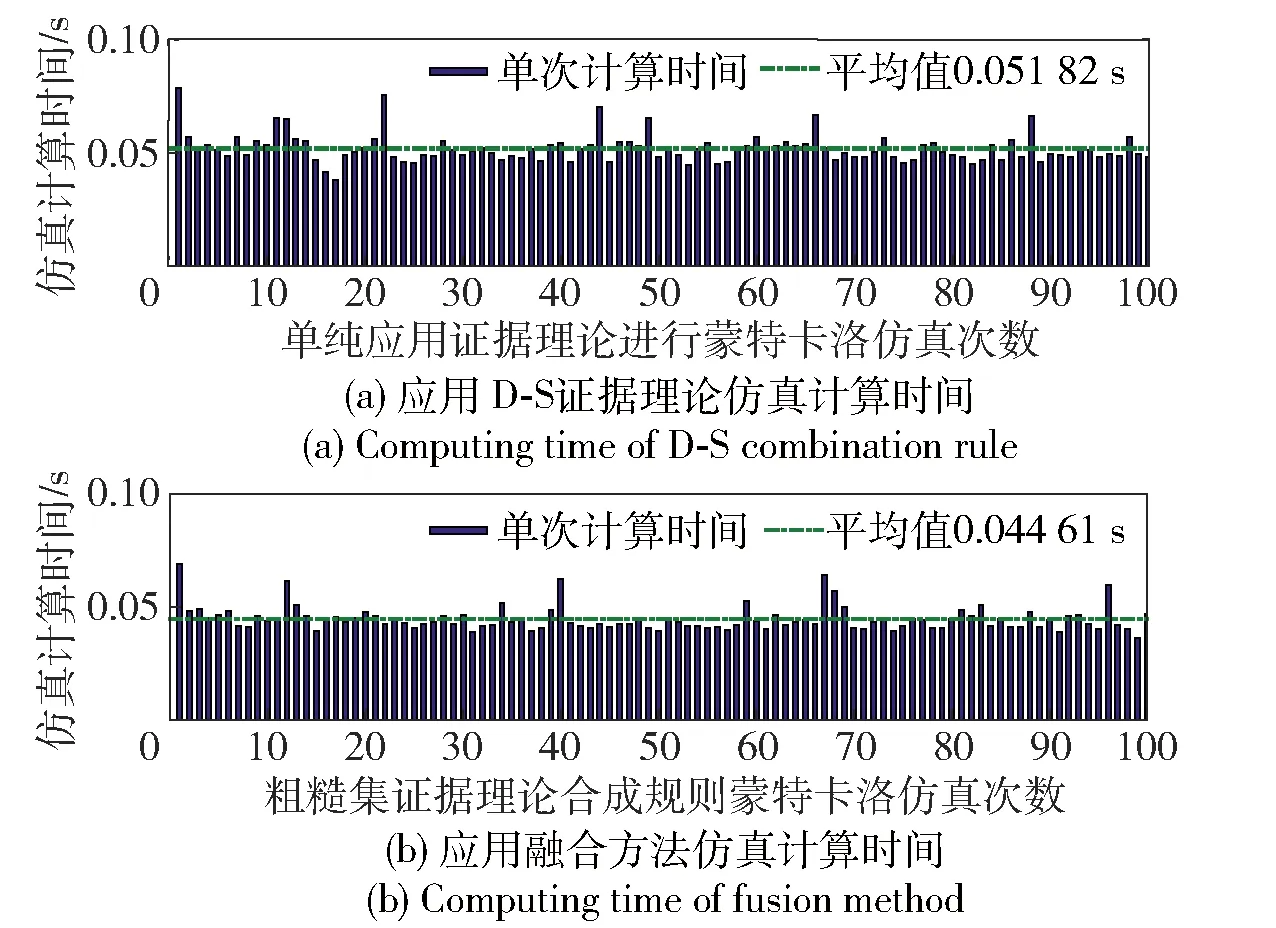
图7 具有20%重复率的证据体合成计算时间对比Fig.7 Computing time of evidence synthesis with repetition rate of 20%

图8 具有30%重复率的证据体合成计算时间对比Fig.8 Computing time of evidence synthesis with repetition rate of 30%

图9 具有40%重复率的证据体合成计算时间对比Fig.9 Computing time comparison of evidence synthesis with repetition rate of 40%

图10 具有50%重复率的证据体合成计算时间对比Fig.10 Computing time of evidence synthesis with repetition rate of 50%
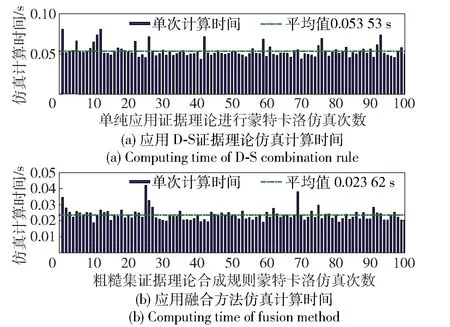
图11 具有60%重复率的证据体合成计算时间对比Fig.11 Computing time of evidence synthesis with repetition rate of 60%

图12 具有70%重复率的证据体合成计算时间对比Fig.12 Computing time of evidence synthesis with repetition rate of 70%
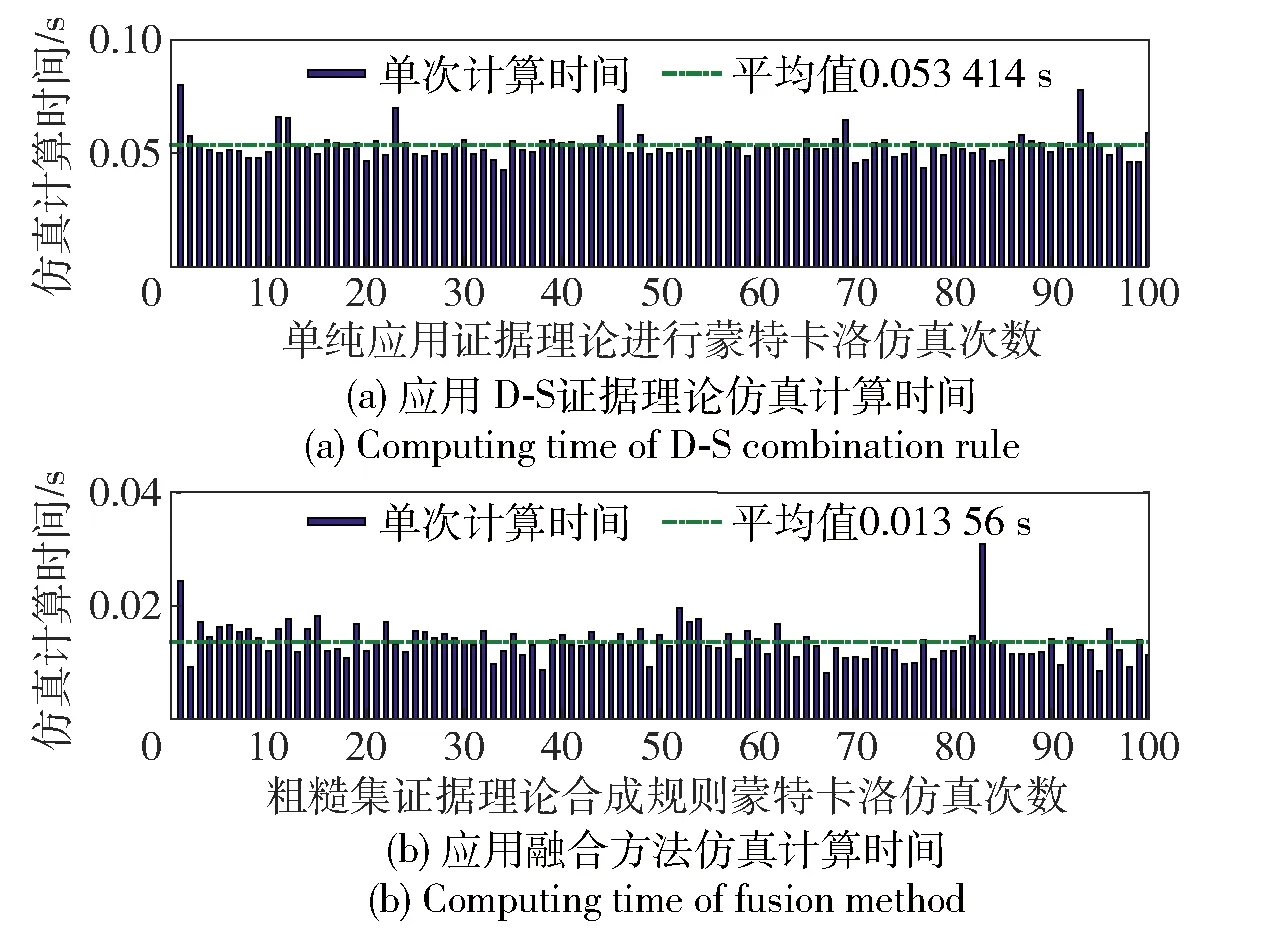
图13 具有80%重复率的证据体合成计算时间对比Fig.13 Computing time of evidence synthesis with repetition rate of 80%

图14 具有90%重复率的证据体合成计算时间对比Fig.14 Computing time of evidence synthesis with repetition rate of 90%
在不同证据体重复率下,单独应用证据理论进行合成与应用本文方法合成的平均计算时间消耗对比如表9和图15所示。

图15 两种方法在不同重复率条件下的时间消耗对比Fig.15 Computing-time consumption of two methods
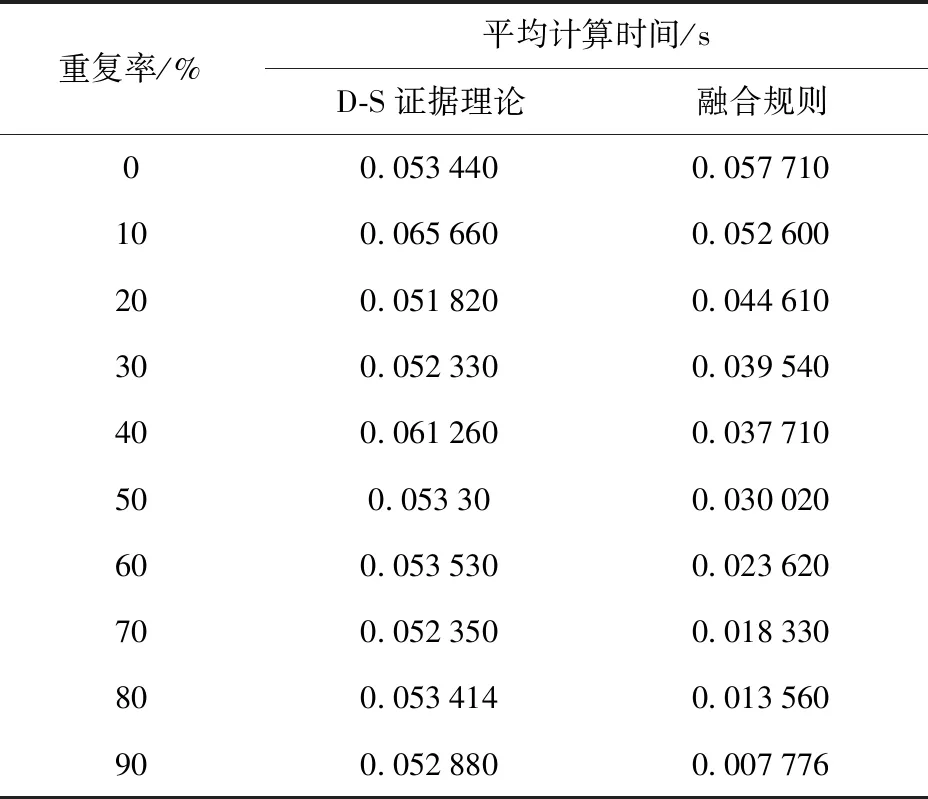
表9 不同重复率条件下两种方法的仿真计算时间对比Tab.9 Computing times of two methods at different repetition rates
3.4 测试计算结果分析
算例1对D-S组合规则、Yagerr组合规则、文献[17]、文献[21]和文献[28]给出的组合规则以及本文给出的融合规则进行了对比,并应用一组典型数据对各融合规则计算结果进行了测试对比,由对比结果可以看出:本文给出的融合结果在第2次融合结束后就可分辨出可信度较高的焦元属性值,并与直观接近。这主要是因为待合成证据体中有3条重复,经过粗糙集约简后证据体由5条简化为3条;同时在证据合成中考虑了证据体的支持度和焦元可信度等因素,支持度高的证据体以及可信度高的证据焦元在证据合成中所占比重相应增大,因此只需要2次合成就能够得到合成结果。
算例2对本文给出的合成规则与D-S证据合成规则计算时间进行了比较,由仿真结果可以看出,当待合成证据体中无重复时要进行额外的粗糙集约简过程,造成时间的额外损耗,此时应用粗糙集和证据理论性融合的规则比单独应用证据合成规则时间消耗大。当待合成证据体中有90%不重复时,两种方法计算时间相当,但是当待合成证据体重复率增大时,本文给出的方法计算量明显降低。实际应用中可能会存在各级情报中心对分布式感知源获取的信息进行融合,而传送到融合中心的数据一般会存在大量重复,因此适合应用该方法进行融合处理。
4 结论
在应用证据理论进行多传感器属性融合过程中,证据体及证据属性过多时容易引起组合爆炸,同时当分布式传感器检测具有冲突时,可能会存在一票否决等问题。本文通过在证据体合成过程中引入信息系统及粗糙集理论概念,采用信息系统属性约简的方法对待合成证据体进行约简,从而将问题转化为较低维度的融合问题,同时在证据体合成中综合考虑了证据体之间的支持度、焦元属性之间的支持度和差异度等因素,基于此给出了冲突证据合成公式,并进行了仿真验证。
结果表明:经过属性约减,证据合成时间得到有效降低,特别是当待合成证据体重复率较高的情况下,计算复杂度降低效果明显;同时,通过对冲突的重新定义和分配,合成结果相对客观。
