人口普查多报及重报估计
2019-09-20胡桂华廖金盆
胡桂华,吴 婷,廖金盆,余 鲁
(重庆工商大学 数学与统计学院,重庆 400067)
一、引言
2020年,中国、美国和其他许多国家将进行每隔10年1次的全国人口普查。按照惯例,也将组织质量评估抽样调查。人口普查质量评估的核心任务是估计人口普查覆盖误差[1]。覆盖误差进一步分为普查净误差及普查多报与漏报[2]。普查净误差定义为普查登记人口数与目标人口总体实际人口数之差。普查多报指普查员在普查中登记了不应登记的人,使普查登记人口总数大于实际人口总数,普查重报是普查多报中的一种,指某人在普查中被登记一次以上。普查漏报指普查员在普查中未登记应该登记的人口,使普查人口总数低于总体实际人口总数。关于净误差估计的研究成果较多,而普查多报的研究成果较少,尤其是很少见到国内外学者发表普查多报的学术性论文。本研究将起到一种示范效应,吸引更多学者研究普查多报,为政府统计部门制订普查多报方案提供决策建议和理论依据。
在人口普查质量评估的历史上,世界各国最早只是估计净误差。这项工作的关键是构造目标总体实际人口数的一个估计量[3],用普查登记人口数与之相减来求得净误差。由于净误差提供的人口普查登记质量信息有限,为了了解人口普查工作更多、更细致的信息,人口普查多报与漏报估计问题逐渐被重视。美国普查局在2010年的人口普查质量评估工作中,在净误差估计之外,增加了普查多报与漏报估计这两个目标[4]。联合国统计司也对各国提出了这样的建议[5]。
但是,国内一些学者认为研究普查多报或重报无太大意义,人口普查的多报与重报问题并不突出,相反人口普查中的漏报问题更值得研究[6]。然而事实并非如此。近10年来,拥有两套甚至多套住房的中国人越来越多,而在不同地点有住房是重报的主要原因。另外中国养宠物的也人越来越多,其中有些人视宠物为亲人,在普查表中登记宠物,造成普查多报。美国2010年普查多报10 042千人,其中重报8 522千人,其他多报1 520千人;普查漏报15 999千人,其中估算的普查人口数为5 993千人,其他漏报人口数为10 006千人[7]。这表明,普查多报和漏报都很严重,在剔除估算的普查人口数外,普查多报人口数比漏报人口数还要多。所谓估算的普查登记人口数是指对拒绝接受普查的家庭根据其邻居提供的信息所估计的这类家庭的人口数。严格意义上来讲,估算的普查人口数并不能当作普查漏报,因为它已经包括在最终公布的普查登记人口数中。普查漏报应该是指既未被普查员登记又未被估算的那部分人口。除美国外,中国和其他国家的普查登记人口数中没有包括估算的普查登记人数[8]。
在普查多报估计中,有些国家(如乌干达、南非)只构造覆盖全部多报的普查多报估计量(联合国统计司人口普查质量评估指南并未提及普查重报)[9-10],也有些国家(如中国和加拿大)只构造重报估计量[11-12]。中国在重报估计做法上尚有若干缺陷,例如,把样本当作总体、把样本重报率当作总体重报率、在统计重报人数时计数对象不明确,等等。
为了全面反映普查多报,除了估计重报外,还要估计其他普查多报,即使其他多报人口数为零,也要将其纳入多报估计范围,在研究报告中明示其他多报人口为零。
联合国统计司及所有国家的政府统计部门把普查多报认定为普查员登记了普查目标总体之外的人。实际上,这样表述不够严密。应该说,普查多报包括对普查目标总体之外的人所做的登记,以及对普查目标总体的人所做的重复登记这两个部分。也就是说,不应把对普查目标总体的人所做的重复登记叫做目标总体之外的登记。
关于普查多报估计,还涉及到一个位置登记错误的问题[13]。许多国家在普查多报估计中,要求一个人登记在所属的普查小区内,否则认定位置登记不正确,作为普查多报处理。这种处理办法会导致普查多报数目虚增。是否把位置登记错误视作普查多报,要看登记位置是否在研究范围内。如果研究范围是全国,那么登记在全国任何一个地方都不应记为多报。如果研究范围是重庆市,那么应该在重庆市登记的某人登记在该市任何区域都不应记为多报,但如果该人登记在四川省,则应记为重庆市的漏报;如果研究范围是重庆市和四川省,这个人不应记为多报。在2010年普查多报估计中,美国规定,一个人只要登记在质量评估调查研究范围内,即认定为位置登记正确,在没有其他登记错误的情况下,认定其为普查正确登记。这一规定避免了登记位置问题导致的多报估计错误。
本文的创新主要有以下三个方面:第一,给出了普查多报及其中的普查重报的明确定义。解决了目前多报、重报统计中由于定义不明、界限不清导致的错误。第二,明确规定了普查重报的两种估计对象。解决了目前重报统计结果含义不明确的问题。第三,采用泰勒扩张抽样方差估计量,近似计算多报或重报估计量的抽样方差,从而规范了普查多报及重报估计量的抽样方差计算。
二、普查多报重报统计一般问题
(一)普查多报与普查重报的内涵与外延
普查多报包含两个部分:第一部分,属于普查目标人口总体的人员进行了两次或更多次普查登记,将他们进行普查登记的次数减1所得结果记作重复性普查多报(简称普查重报);第二部分,不属于普查目标人口总体的个体(例如,普查标准时点之前死亡的人口、普查标准时点之后出生的人口、虚构的人口,等等)进行了普查登记,将他们进行普查登记的次数记做其他普查多报。这里特别要注意,如果一个不属于普查目标总体的个体进行了不止一次普查登记,须将其进行普查登记的次数全部计为其他普查多报,而不应计为普查重报。
(二)普查重报的估计对象
对普查重报估计问题,有两种估计对象。一是估计重复性普查重报人数。二是估计发生普查重报人数。对前者,将属于普查目标总体的某个人在普查中登记的总次数减1,作为其重复性普查重报人数。对后者,只要某人在普查中登记一次以上,就将其作为发生普查重报人口,重报次数计为1,而不考虑其实际登记的次数。目前加拿大在普查重报估计中采用第一种估计对象,其目的是为了修正普查登记总人数。
三、普查多报及重报的抽样估计理论
人口普查多报、重报估计理论包括下列四项内容:抽样设计、样本数据采集、普查多报估计方法、估计量构造及估计量方差的估计[14-16]。
(一)抽取样本
在人口普查质量评估抽样调查中,各国政府统计部门采取的抽样方法通常是分层整群抽样、分层多阶段抽样、分层多重抽样。用于分层的标志通常是城乡或抽样单位的规模。以中国为代表的发展中国家主要采用分层整群抽样,为更好地服务于中国政府的需要,本文采用分层整群抽样方法抽取以普查小区为抽样单位的样本。
(二)获取样本小区普查多报或重报人口数据
在抽取样本普查小区后,收集每个样本小区的普查人口登记名单,进行入户现场调查编制质量评估调查人口登记名单。识别样本小区普查多报或重报人口的方法有4种。第一,检查样本小区的普查人口登记名单,看是否存在普查日后出生的人、普查日前死亡的人、狗和其他宠物以及重复登记的人。第二,在进行入户现场调查编制质量评估调查人口登记名单时查明是否存在同一人同时在两个地点进行普查登记的情形。第三,对本小区普查人口登记名单中的每一个人,在全国普查人口登记名单进行搜索,看能否找到与其相同的人,即重报人口。第四,比对样本小区的普查人口登记名单和质量评估调查人口登记名单,包括在本小区内部及外部比对这两份名单。比对的内容是姓名、性别、年龄、文化程度、婚姻状况等。如果某人在这两份名单的姓名及这些特征相同或绝大部分相同,就判断为匹配,即普查正确登记人口。如果比对结果是普查人口登记名单的某人为未匹配人口,即未在质量评估调查人口登记名单中找到与其相同的人,就组织个人后续调查收集新信息再次比对[17]。如果利用新信息再次比对的结果仍然是普查人口登记名单的某人为未匹配人口,并且现场核实该人实际上并不存在,就判断该人为普查多报。如果在个人后续调查期间,确认普查人口登记名单的某人是虚构的人,即普查日后出生的人、普查日前死亡的人,就判断某人为多报人口。如果普查人口登记名单中的某人在比对后为未匹配,并且个人后续调查未收集到任何用于再次比对的信息,就判断该人为普查多报人口。为便于对比对结果做出判断,在人口普查质量评估中,通常假设质量评估调查人口登记名单不存在非抽样误差。
(三)普查多报估计方法
采用何种方法构造普查多报估计量要考虑两个因素。第一个因素是样本普查小区的普查多报人口的数目。第二个因素是普查登记分类的详细程度。发展中国家和绝大多数发达国家通常将普查登记分为普查正确登记和普查多报登记。美国普查局将普查登记分为普查正确登记、普查多报登记、位置错误的普查登记、不足比对信息的普查登记及未数据定义人口(最多只登记姓名及一个普查项目)的普查登记。基于上述因素,选择构造普查多报估计量的方法。如果样本普查小区多报人口较多,就直接依据样本小区多报人口及其抽样权数构造总体普查多报估计量,即样本多报人口的加权和。中国在2010年人口普查多报估计中采用这种方法估计常住人口多报率、现有人口多报率和户籍人口多报率。美国和其他一些国家也是采用这种方法估计普查多报。如果样本多报人口很少甚至为零,此时虽然可以算出平均每个样本小区的普查多报人口数,但这个数往往是一个很小的数,用其推断总体普查多报人口数可能严重失真。在这种情况下,如果普查登记分类相对简单,就从普查登记人口数估计量中剔除普查正确登记人口数估计量,得到普查多报估计量。本文采用这种方法构造普查多报估计量。如果普查登记分类详细,就从普查登记人口数估计量中减去普查目标总体人口数估计量,得到普查多报估计量。其中,普查目标总体人口数估计量为“总体普查信息登记完整人口数”乘以“普查目标总体人口数线性估计量或普查信息登记完整人口数线性估计量”。普查信息登记完整是指登记了全部普查项目。
(四)总体或区域的普查多报率和重报率估计量及方差估计量
1.总体普查多报率估计量。构造总体(全国、省等)普查多报比率估计量的目的是使不同国家或同一国家不同时期的普查多报估计结果具有可比性。中国和其他国家的政府统计部门出于保密考虑只对外发布普查多报率(对内提供普查多报人数及多报率),其公式为:
(1)
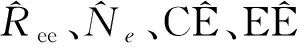
讨论式(1)E名单j人的普查正确登记概率Pce,j在不同情形下的计算方法。首先,如果有信息证明一个人在普查中正确登记,那么其正确登记概率为1;其次,如果有证据显示一个人是普查错误登记,那么其正确登记概率为零;再次,如果没有收集到证明某人是普查正确登记还是普查错误登记的信息,那么其正确登记概率需要估计。如果E名单中的每一个人都是正确登记,那么估计的普查正确登记人数等于估计的普查登记人数。
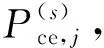
(2)
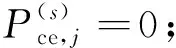
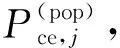
(3)
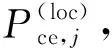
(4)
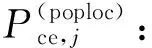
(5)
2.总体普查重报率估计量。它为重报人口数与普查登记人口数之比:
(6)
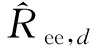
(7)
(8)
4.总体和区域的普查多报率及重报率的抽样方差估计量。在构造普查多报率或重报率估计量后,还要建立其抽样方差估计量。式(1)、式(6)、式(7)和式(8)属于复杂估计量,抽样方差通常使用分层刀切估计量或泰勒扩张估计量计算[18]。分层刀切估计量优势是容易理解,在西方国家政府统计部门组织的人口普查质量评估中应用广泛。中国国家统计局迄今尚未使用分层刀切估计量构造重报率的抽样方差估计量。然而,分层刀切估计量也有明显的缺陷,即样本普查小区复制权数及总体参数估计量的复制估计量的计算量大。复制次数等于第一重样本小区数目。每复制1次,就要计算一组第一重样本普查小区的复制权数,以及据此计算一组总体参数复制估计量。在大规模人口普查质量评估抽样调查中,第一重样本规模通常很大。泰勒扩张方法能够避免分层刀切估计量的缺陷,计算量减少许多,尤其是对比率估计量的计算量减少更加明显。采用泰勒扩张估计量计算式(1)、式(6)、式(7)和式(8)的抽样方差为:
(9)
(10)
(11)
(12)
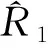
(13)
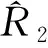
(14)
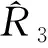
(15)
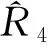
(16)
(17)
(18)
(19)
(20)
/nh。
四、实证分析
1.样本资料。实证调查范围为重庆市南岸区,实证调查时间为2000年11月1日。数据来源于美国明尼苏达大学人口中心于1995年建立的IPUMS普查微观数据库[19]。从1995年到2017年年底,IPUMS数据库收集了中国、美国、白俄罗斯、印度、英国等85个国家的政府统计部门的约6.77亿人在301次人口普查中的微观个人记录(迄今117个国家与IPUMS签订了合作备忘录)。该数据库用于科学研究与教育研究,用户在签订数据使用协议后,可以免费使用数据。中国国家统计局在1982年、1990年和2000年向IPUMS提供1%样本普查微观数据。我们从该数据库获得了2000年重庆市南岸区1%街道或镇(层)小区的普查个人资料。样本采取分层整群抽样法抽取,抽样单位为普查小区,样本小区单位答复率为100%。样本资料如表1和表2。
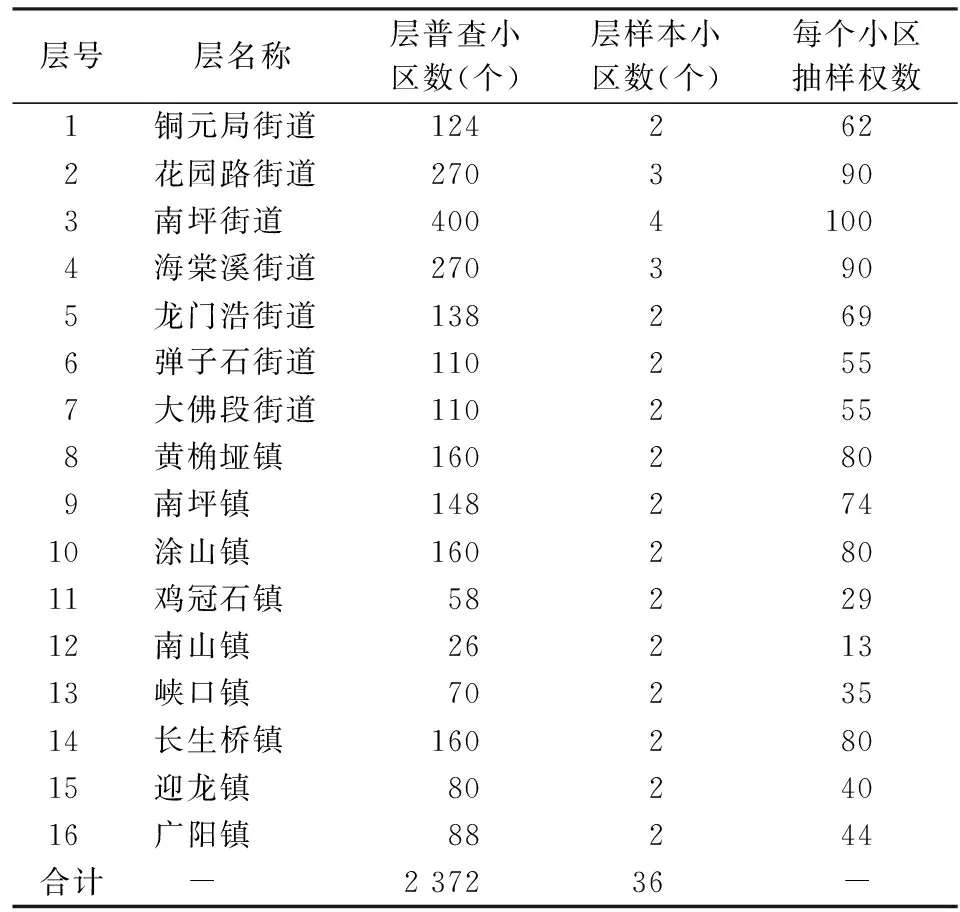
表1 2000年重庆市南岸区街道或镇的普查小区及其样本
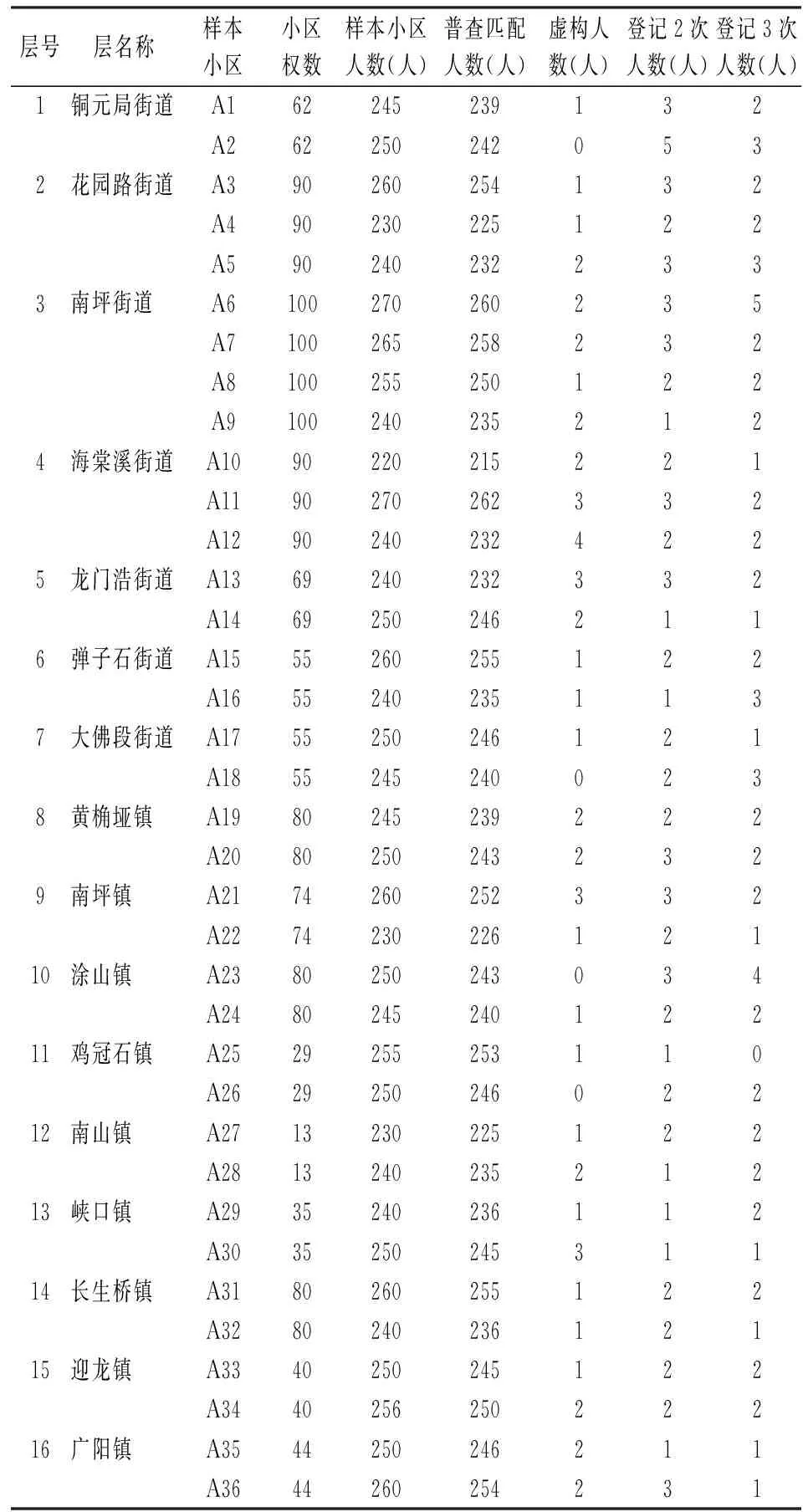
表2 样本小区普查登记结果
2.总体和区域的普查多报率及重报率计算。根据式(1)、式(6)、式(7)和式(8)及表2样本数据,得到总体及各个区域(在这里指每一层)普查多报的估计结果,具体见表3。
从表3可以看出:第一,估计的总体普查多报人数为9 795人,即估计的普查登记人口数589 670人与估计的普查正确登记579 875之差,估计的总体普查多报率为1.66%,即估计的普查多报人数与估计的普查登记人数之比,估计的总体重报5 990人,即在普查登记中有5 990人被重复登记过,估计的总体重报率1.02%,即估计的重报人数5 990人与估计的普查登记人口数589 670人之比;第二,从每一层(区域)来看,海棠溪街道的普查多报率最高(2.17%),说明该街道普查多报问题最为严重,而铜元局街道的重报率最高(1.48%),表明该街道重报最为严重。第三,各层的普查多报率及重报率差异较大,表明各层的普查登记质量不同。
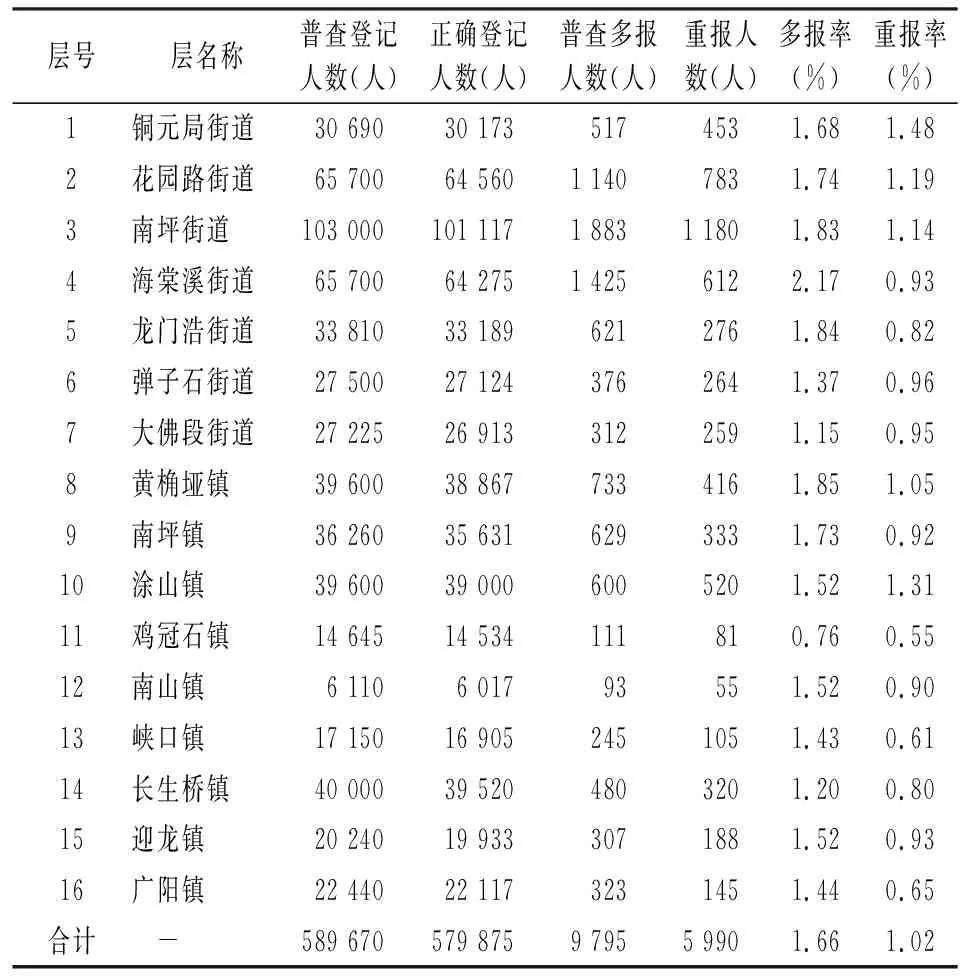
表3 总体及各层普查多报及重报估计值
3.总体普查多报率及重报率的抽样方差计算。在得到了普查多报率及重报率估计值后,利用式(17)~式(20),以及表1、表2和表3数据,计算式(1)、式(6)、式(7)和式(8)的抽样方差估计值。计算结果为:总体普查多报率1.66%(即每100人中有1.66个人不应该在普查中登记)的抽样标准误差为0.000 813 14(0.000 000 661 20的平方根),而总体重报率1.02%(即每100人中有1.02人在普查中重复登记过)的抽样标准误差为0.039 2(0.001 536 641的平方根)。需要了解抽样误差计算内容的读者请和作者联系。
4.区域的普查多报率及重报率及抽样方差计算。使用式(7)和式(8),以及式(19)和式(20)计算区域的普查多报率及重报率,以及它们的抽样标准误差。计算结果为:铜元局街道的普查多报率及普查重复率的估计值分别为1.68%和1.48%,其抽样标准误差分别为0.001 184 900和0.003 282 970,即估计的多报率及重报率分别与其实际平均相差0.118%和0.328%。在概率把握程度为95.45%情况下,铜元局街道普查多报率及重报率所在置信区间分别为1.269%~1.916% 和0.824%~2.136%。无论是铜元局街道,还是南岸区街道总体,普查多报率的估计精度均高于普查重报率。这表明,在不考虑非抽样误差的情况下,样本对普查多报率指标有更好的代表性。所有国家在人口普查质量评估中所估计的不同指标的估计精度均存在差异。
五、结论与建议
应该充分重视普查多报及重报调查。认为普查多报或重报研究意义不大这一观点不仅与现实相违背,而且会阻碍普查多报估计理论发展,对人口普查质量评估工作造成困扰。
估计普查多报率及重报率需要解决三个问题。一是普查登记位置与普查多报人口认定的关系;二是重报者正确登记概率的估计;三是重报率的估计。对第一个问题,为了避免普查多报人口虚增,只要某人在普查中登记在质量评估调查研究范围内,并且未发现其他登记错误,就当作普查正确登记。对第二个问题,如果没有收集到重报人口的哪个记录是基本记录(普查正确登记),哪个记录是重复记录,就采取简单算术平均法计算正确登记概率。如果收集了相关信息,就根据信息决定重报人口的正确登记概率为1或零。对第三个问题,用估计的在普查中重复登记过的人数除以普查登记总人口数,得到重报率估计值。建议中国在2020年普查多报估计中将多报认定区域由目前的普查小区扩大到全国各省份,对多报中的重报人口引入正确登记概率变量。
普查登记中不只会发生重报,还会发生其他普查多报。如果普查多报估计量只是包括重报,必然低估普查多报,掩盖本次普查登记中的其他问题。为了全方位、多角度研究普查多报,应当分别估计普查多报率、重报率、其他多报率。中国自1982年起只估计重报率,建议中国政府在2020年构造普查多报率估计量、重报率估计量和其他多报率估计量。
普查多报估计的对象既可以是全国的总人口及不同类别人口,也可以是省、自治区、直辖市的总人口及类别人口。中国在每次人口普查质量评估工作中只是估计全国总人口的重报率。建议以后将普查多报估计对象扩大到全国各省份的城乡人口、不同文化程度人口、不同民族人口。为提高不同区域、不同类别人口普查多报率的估计精度,要确保各个区域、各类人口的样本规模。
