基于改进关联规则算法的中医处方规律挖掘研究*
2019-07-05汪玉薇李晓东吴辉坤
汪玉薇,解 丹**,李晓东,吴辉坤
(1.湖北中医药大学信息工程学院 武汉 430065;2.湖北省中医院肝病研究所 武汉 430061)
1 引言
中医处方用药规律研究是中医药传承与创新的关键内容之一[1]。中医处方数据挖掘多以“处方”类别为划分依据,其中以中药处方挖掘最为常见[2,3](下文“处方”均指“中药处方”)。中药处方是由多种药物组成的,但并不是药物的随机组合,中医组方的原则可概括为“依法立方”[4]。目前,临床处方中的药物之间虽没有严格的剂量要求,但“剂量”仍是处方药物的药力标识,药物的用量不同,其在方剂中的药力也不同。例如“小承气汤”与“厚朴三物汤”均由大黄、厚朴、枳实组成,但前者组成为:大黄四两、枳实三枚、厚朴二两,主治阳明里实热结证;后者组成为:厚朴八两、枳实五枚、大黄四两,主治气滞腹满、大便不通[5]。因此,处方中药物剂量特征是药物在处方中确切功用与主治的标识,若用量失宜则达不到疗效。另外,药物间的配伍遵循一定规律,例如“甘草配大枣”,其中甘草甘润平和,既益气养心又和中缓急;大枣甘温,益气养血安神。两药组合使用,甘缓滋补,共奏补脾和中、养心安神之功,适用于心虚、肝郁所致之脏躁[6]。《临床中药学》中给出了每味药物常见的配伍及禁忌,并注明了减毒或增效作用,药物配伍减毒增效关系对于中药处方挖掘有较强研究价值。
由于中医处方中的药物间具有较为复杂的非线性关系,除了常规的统计方法外,常见的数据挖掘方法包括:关联规则[7]、因子分析、改进互信息法和复杂熵系统聚类、贝叶斯、复杂网络等,其中又以关联规则最为常见。关联规则挖掘分为“搜索频繁项集”和“生成规则”两个阶段,目前最常用的算法是Apriori[8]和FP-growth算法[9],此后陆续又有其他研究者对关联规则算法做出了改进。这些算法的提出在不同程度上改进了关联规则的挖掘效率,但这些算法并没有考虑中药处方“依法立方”的中医特色。传统关联规则算法,多关注药物出现的频次,普遍将药物视为独立的分析对象,忽略了处方药物的剂量、组合药效等特征,只能达到体现处方药物间的“共现规律”,而不能揭示“组方规律”。本文试图通过纳入处方药物剂量特征及药物配伍减毒增效关系,通过加权方式改进现有关联规则模型以探寻一条新的组方规律挖掘,挖掘结果更接近真实世界处方的用药规律,为中医临床用药规律研究提供一条新思路。
2 实验
2.1 构建模型
在关联规则模型中引入权值,需要综合考虑如何设定权值和如何分配权值[10]。目前有水平加权、垂直加权以及混合加权三种解决方案[11]。其中,水平加权以项目重要程度设定权值,权值按项进行分配;垂直加权以时间因素设定权值,权值按事务进行分配;混合加权则综合了前二种方法,权值为前两种方式的混合。本文采用混合加权法。对于如何引入处方药物剂量作为权值,有多种加权思路,通过文献调研以及中医专家实际讨论,最为医生接受的剂量加权是根据药物的平均剂量。本文根据专家的建议,以基准剂量模型为区分依据,分别构建了平均剂量加权和配伍减毒增效关系加权两种加权模型。第一种模型源于不同处方中药物剂量不同,将包含有相同药物的处方进行统计,计算出该药物在所有处方中的平均使用剂量,然后根据某个处方中所含药物与这一平均值进行对比。而第二种模型是依据《药典》中描述的药物配伍规律,对于有减毒增效作用的设置权重。
遍历事务集T,所有项目构成的集合为I={i1,i2,…,in},每一首处方t均为I的一个真子集,并具有一个唯一标识符tid。对于给定的项集itemset={i1,i2,…,ip},给itemset中的每一个项 ij赋权值 wj(wj∈[0,1],j∈[1,n])。设X={x1,x2,…,xp},Y={y1,y2,…,yp}(X、Y均是I的真子集且X∩Y=∅),记Support(X)为X在T中的支持度,Confidence(X→Y)为规则X→Y在T中的置信度,min_sup为加权支持度阈值,min_conf为加权置信度阈值,规则的加权支持度wsup及加权置信度wconf的计算公式如下:
加权支持度:
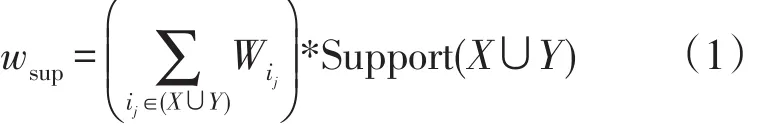
加权置信度:
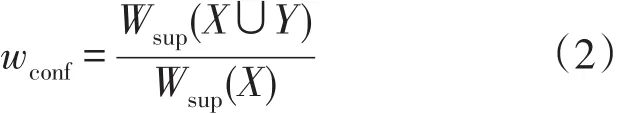
加权关联规则是同时满足加权支持度阈值和加权置信度阈值的关联规则。根据本文构建的二种加权模型,给出二种加权计算公式如下:
药物平均剂量加权公式:
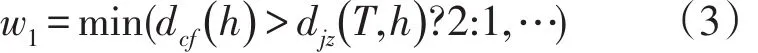
药物配伍减毒增效关系加权公式:
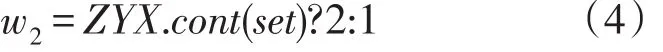
其中,h代表当前需要计算权值的药物,dcf(h)为药物h在处方中的剂量值,djz(T,h)为处方T中药物h的剂量平均值,若大于平均剂量权重为2,否则为1。ZYX代表的是《临床中药学》整理的药物配伍减毒增效表,cont(set)表示当前药物组合set是否是减毒增效的配伍药对,若是则权重为2,否则为1。
在这二种改进的关联规则算法中,第一种算法的流程为:首先初始化项目集set的支持度(设为0),然后遍历事务集,若当前事务中包含项目集set,且项目集set中所有药物对应事务集中药物的剂量均大于其纵向平均剂量,则支持度累计加2,若当前事务中包含项目集set,但项目集set中存在药物对应事务集中药物剂量小于或等于其纵向平均剂量,则支持度累计加1,直到遍历结束。第二种算法的流程为:首先初始化项目集set的支持度(设为0),然后遍历事务集,若当前事务中包含项目集set,且项目集set在ZYX中,则支持度累计加2,若当前事务中包含项目集set,但项目集set不在ZYX中,则支持度累计加1,直到遍历结束。
改进的关联规则模型利用处方药物的剂量特征及药物配伍的减毒增效关系构建加权支持度,突出了处方中的关键药物(或药物组合),提高了挖掘模型对真实世界的拟合度,使挖掘结果具有更高的临床研究价值。
2.2 数据预处理
数据来源为某中医院2012年7月至2015年8月间所有诊断为乙肝肝硬化的8617例门诊记录(参照2011年8月中国中西医结合学会消化系统疾病专业委员会制定的《肝硬化中西医结合诊疗共识》[12])。本文纳入分析的字段包括患者的门诊号、西医诊断、性别、年龄、首次检查总胆红素、首次检查凝血酶原时间、首次检查白蛋白、末次检查总胆红素、末次检查凝血酶原时间、末次检查白蛋白以及全部处方信息。为确保挖掘实验质量,利用ETL技术进行数据清洗,清洗过程如下:
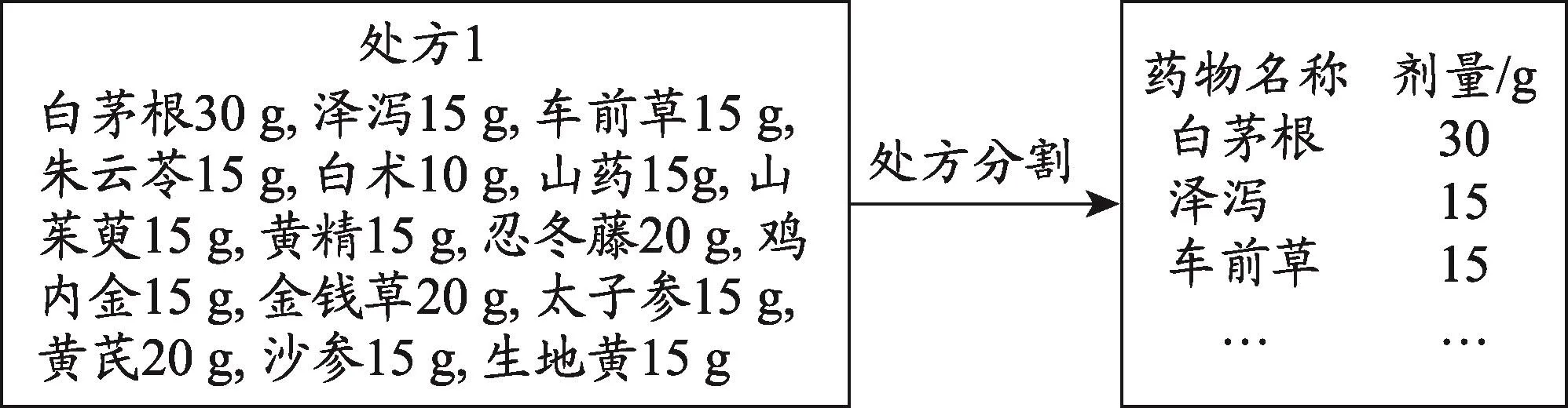
图1 处方长文本分割前后结果对比示例

图2 中药名称规范化前后对比示例
2.2.1 确定有效记录
在中医临床专家指导下对原始数据中的检验值进行填补与修正,然后依据肝功能Child-Puge分级标准计算患者诊疗前后得分,筛选评分下降的案例作为实验阶段的有效数据,最终获得4549份有效案例。
2.2.2 确定有效处方
由中医临床专家对同一案例中的多处方现象进行归并,并通过识别数值与逗号的方式对原始处方进行文本分割。针对原始处方数据的长文本格式,通过识别数值与逗号对原始处方进行分割(图1)。最终获得4473首有效处方数据。
2.2.3 规范中药名称
在4473首处方数据中共包含407种中药名称。经中医临床专家审核,其中不规范的中药名称有188种,包含中药别名97种、中药简称3种以及炮制中药88种。在中医临床专家的指导下,对中药名称进行了规范化处理,参照《中药编码规则集编码》(中华人民共和国国家标准[GB/T 31774-2015])与《中国药典》(2015年版)对预处理后的药物进行严格规范化(图2)。最终获得257种规范化中药名称。
经过上述处理后,所得数据集可直接作为下面挖掘实验的输入数据集。
2.3 挖掘实验
为观察改进模型的效果,应与传统模型进行对比。为此,采用Python语言共建立了三种模型,分别是传统关联规则模型、药物平均剂量加权模型和药物配伍减毒增效关系加权模型,其中传统模型算法与SPSS和wika中内置的关联规则算法相同。
根据前面得到的输入数据集,经过多次探索性实验,以生成频繁项集及规则数量适中为依据,最终确定选用最小支持度分别为7%、8%、9%,最小置信度分别为85%、90%、95%的9组挖掘模型参数组合。分别使用SPSS Modeler、Weka与仿真平台,结合传统关联规则算法与上述各组模型参数挖掘实证研究数据,分析发现使用三种工具得到的挖掘结果完全一致(表1)。
以支持度阈值min_sup=8%、置信度阈值min_conf=95%为例,对于频繁二项集(Fset2),传统关联规则模型发现的频繁二项集数量为43个,药物平均剂量加权模型发现了56个,药物配伍减毒增效加权模型发现了73个(表1)。当支持度阈值为9%、置信度阈值为85%时,对于频繁二项集,传统模型挖掘到28个,平均剂量和配伍减毒增效模型分别挖掘了35个和44个。无论是何种频繁项集,二个加权模型得到的频繁项集数量均明显增多,表明找到了更多药物组合,对于发现用药规律有积极作用(表1)。
2.4 结果可视化
2.4.1 频繁项集
由于中医临床频繁二项集恰好对应中医处方中的药对,能够体现中医处方中不同药味之间的两两配伍关系,本文以二项集为例,进行频繁二项集的可视化展示。在频繁项集网络中,节点的大小代表了该节点对应药物参与构成频繁项集的多少,节点越大代表其出现次数越多。连线的颜色深浅代表了两端药物构成的频繁项集的频次高低,颜色越深代表这对药物组合出现次数越多。当支持度阈值为9%、置信度阈值为85%时,三种模型挖掘到的频繁二项集分别为28、35和44个,同时三组模型获得的所有频繁二项集中出现药物的数量分别为24、30和27味,按药物参与构成项集的频数排序(表1,表2)。
以药对频次为权重,绘制三个模型所得频繁二项集药物组成的复杂网络(图3)。
在Gephi中调整预览比例为10%,可获得最小支持度为9%的三组核心药对:(ct)茯苓、丹参、茵陈蒿;(pj)茯苓、丹参、茵陈蒿、郁金;(zx)丹参、白术、郁金。
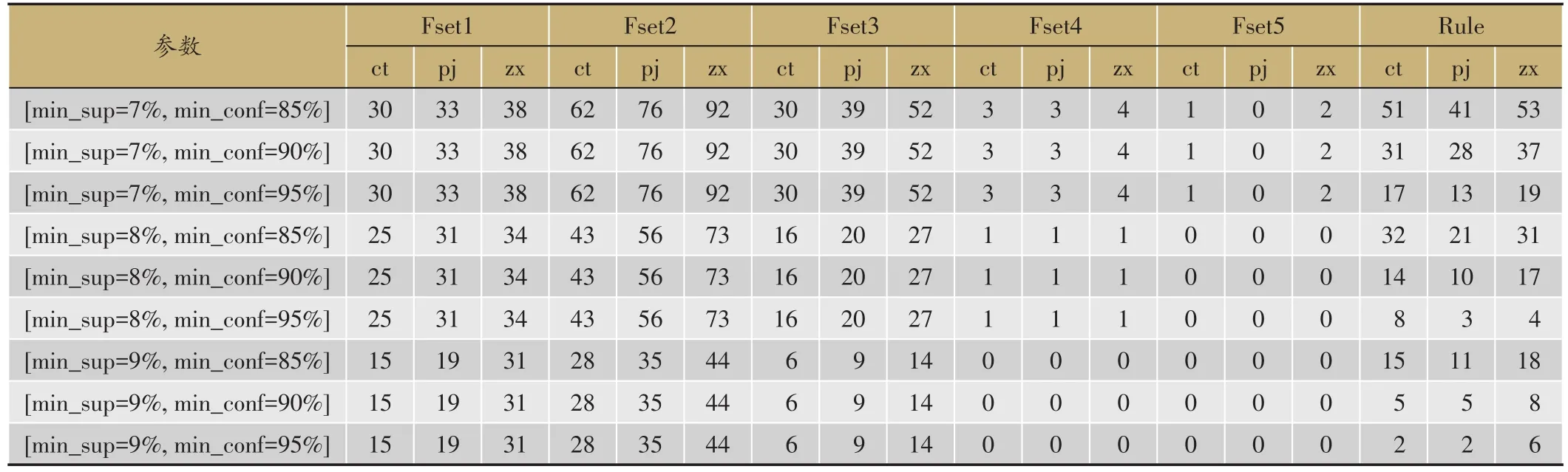
表1 三种模型挖掘结果对比
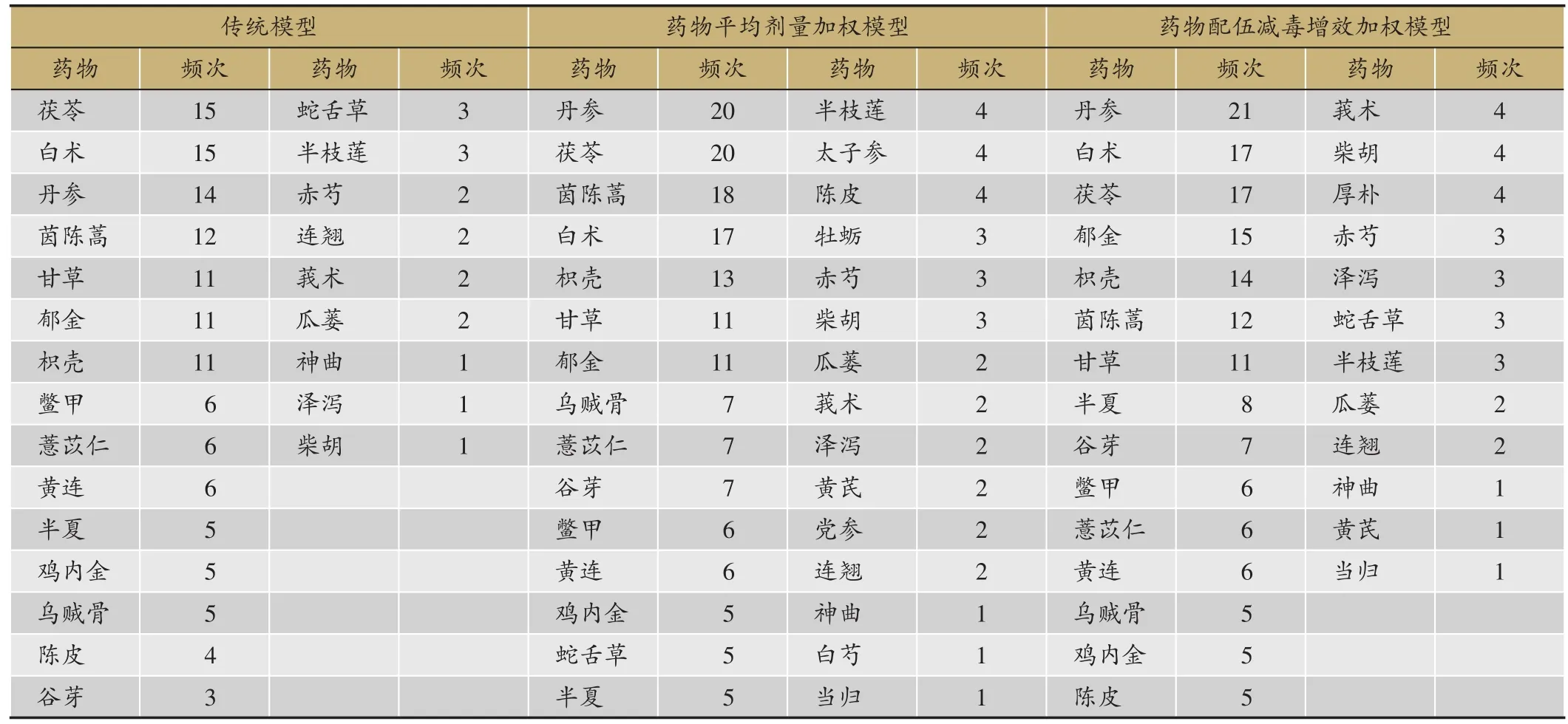
表2 药物组成频繁2项集频次表(min_sup=9%,min_conf=85%)
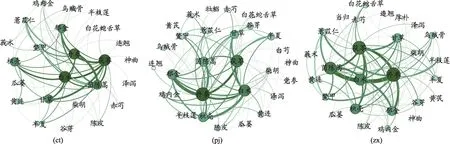
图3 药物组成频繁2项集复杂网络图(min_sup=9%,min_conf=85%)
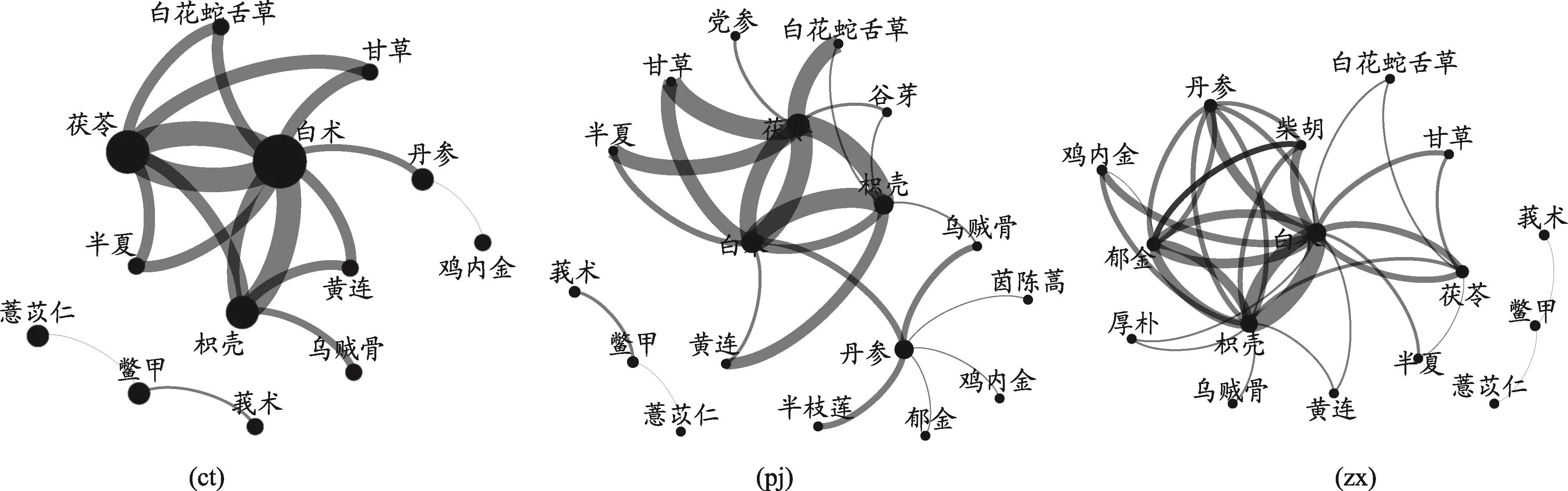
图4 规则网络图(min_sup=9%,min_conf=85%)
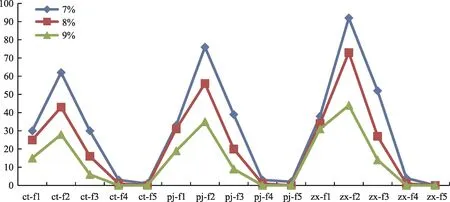
图5 三种模式的频繁1-5项集数量折线图
2.4.2 有效规则
在支持度阈值为9%、置信度阈值为85%时,传统模型、药物平均剂量加权和药物配伍减毒增效加权模型分别获得规则的条数为15、11和18。使用Gephi绘制三组规则的复杂网络图(图4)。
在取支持度阈值为9%、置信度阈值为95%时,药物间的复杂网络最为精简,在Gephi中调整预览比例为10%,可获得三组模型所得规则中的关键药物(或组合):(ct)白术;(pj)乌贼骨;(zx)白花蛇舌草-茯苓。当置信度阈值升为90%时,构成网络的药物有所增加,获得三组模型所得规则中的关键药物(或组合):(ct)白花蛇舌草-茯苓;(pj)白花蛇舌草-茯苓;(zx)白花蛇舌草-茯苓。此外,在支持度阈值控制为9%、置信度阈值分别取85%和90%时,使用Gephi分析三组模型生成的规则,均在规则网络中出现了“莪术-鳖甲-薏苡仁”这样一个独立的分支。
2.5 结果分析
根据实验结果,绘制不同支持度下三组模型获得频繁项集数量变化趋势的折线图(图5)。
三条折线存在明显分离,从上到下分别对应了7%、8%和9%的支持度,说明不同模型获得的频繁项集数量均受最小支持度取值影响(图5)。图中存在三个明显的波形,在不同支持度取值的条件下,两种加权模型获得的频繁项集数量均比传统模型多,能够获得更多的候选规则,从而降低了遗漏有用知识的概率。
3 讨论
基于药物剂量可以体现不同药物(或组合)在处方中地位这一思想,本文在传统关联规则算法基础上,引入了中药的剂量特征。从临床实用性出发,提出了二种基于剂量加权的关联规则改进模型,并利用可视化技术进行挖掘模型的构建与实证研究。经中医临床专家鉴定,本文提出的这2种加权模型较传统关联规则模型均得到了较好的结果,获得了更多有价值的药物组合,其中药物配伍减毒增效关系加权模型表现得更为突出,充分体现了中医治疗肝病从解毒入手的思想[12]。使用本文提出的改进挖掘模型可以挖掘到更多频繁项集,减少用药规律的遗漏,有较强实用价值,为中医处方用药规律研究提供了新思路与方法。
中医处方数据挖掘正在兴起,挖掘过程中还有许多问题值得探索。首先是本文实验中仅涉及了肝病科室的处方数据,下一步可考虑将本模型推广到其它科室,进一步验证模型有效性。其次是数据质量不高,预处理工作占据了大量时间,今后随着数据质量的提升,可以有效降低预处理时间。最后一点是中药处方的药物特征,除了剂量外,还有炮制、性味归经等多种特性,后面可以从处方的这些特性出发,进一步扩展思路。
