汉英双语者视觉词汇加工中的语音启动研究*
2019-06-24韩山师范学院丁雪华
韩山师范学院 丁雪华
提 要: 本文使用翻译启动范式,以汉-英不平衡双语者为被试,研究在四种不同启动词-目标词关系类型(同源、非同源翻译、仅同音、无关)中是否能够得到跨语言的启动效应,以了解语音是否在双语者的视觉词汇加工过程中起作用。本文包括四个实验。结果表明,只要启动词呈现时间足够长,汉语词汇与英语词汇的加工中语音均能得到激活;另外,在汉语词汇的加工中对语义的激活强于语音,而在英语词汇的加工中则先激活语音再激活语义。
1. 引言
人们在阅读时,通过视觉输入的词汇需要在大脑中经过什么样的加工过程,才能通达语义?语音是否在其中发挥作用?根据Wong等(2014) 的总结,与视觉词汇加工过程相关的假设主要有三种: 直接文字通达语义、通过语音中介间接通达语义和双路激活(正字法和语音信息都被激活并相互作用)。更复杂的情况是双语者的词汇通达,这种情况下除了考虑语音及其它因素的作用之外,还需考虑双语的关系,即在双语者加工词汇时,输入的信息是仅通过一种语言直接通达语义,还是两种语言相互作用激活候选的词汇?相关研究更多地支持后一种假设,即语言的非选择性通达假设。如上文所述,在这个过程中,还可能涉及到词汇的语音、正字法等各种因素的交互影响。学者们提出了BIA+模型(Dijkstra & van Heuven,2002)、语音解释(Voga & Grainger,2007)等理论模型来尝试解释这个过程,但目前的研究,特别是以汉语母语者为被试的研究(Wong et al.,2014;高淇、刘希平,2016;Zhou et al.,2010;Zhou et al.,1999),对于语音在这个加工过程中的作用仍存在不少争议。本文尝试利用语音、语义跨语言重叠程度不同的四种双语词对的对比来探索语音在汉-英双语者视觉词汇加工过程中所起的作用。
2. 研究背景
双语同源词是研究双语者两种语言在加工过程中如何互相影响的一个重要素材,其中,对跨文字系统(cross-script)语言间(如汉语-英语)双语同源词的研究在近年来成为热点。跨文字系统语言间的同源词一般指一种语言中来自另一种语言的借词,本研究中的同源词特指外来音译词。相关的研究涉及多种语言、多种实验任务,如Gollan等(1997)发现不管被试的优势语言是希伯来语还是英语,在跨语言掩蔽启动的词汇决定任务中都能得到显著的L1→L2同源词启动优势效应;而Kim & Davis(2003)仅在命名任务中发现了同源词的启动优势,在词汇决定任务和语义分类任务中没有发现同源词相对于非同源翻译词的加工优势;Nakayama 等人(2014)则发现高语音相似性的日-英同源词对的同源词启动效应显著更大。跨文字系统的双语同源词主要在语音和语义上跨语言重叠,而非同源翻译词则一般只在语义上重叠,研究者通过在实验中将两者进行对比,尝试分离出语义与语音分别的作用,如果排除了语义重叠程度不同带来的影响,同源词加工优势的存在,理论上来说就是语音在双语者词汇加工过程中起到促进作用的证据。
以上研究虽然结论不尽一致,但总的来说,大都表现出语音在加工过程中的促进作用,但这个发现却在对汉字的研究中受到了挑战。Wong等人(2014)用带有ERP记录的掩蔽启动范式来考察在阅读中文双字复合词中是否强制激活语音信息,结果在音节相关的条件下并没有发现显著的启动效应,因而Wong等认为,在阅读中文双字复合词的过程中,语音激活不是强制性的,单纯的语音不足以引起显著的启动。然而,在另一项以中英双语者为被试的研究中,Zhou等人(2010)发现不管是使用命名任务,还是使用词汇决定任务,结果都显示了语音的促进作用,且在L1→L2和L2→L1两个启动方向均发现了语音启动效应。对于语音的作用,以上研究显示出对立的结果。Wong 等(2014)及高淇、刘希平(2016)使用的中文实验材料均为双字中文复合词,而Zhou等人(2010)使用的都是单字词,这种材料识别的难度和时间上的差异是否为引起实验结果不同的原因?由于上述研究使用的都是掩蔽启动实验范式,启动词呈现的时间非常短,而汉语书写形式与语音之间没有直接联系,激活语音可能需要比较长的时间,所以确实存在这样的可能性,即在非常短的启动时间内,单字词的语音得到了激活,而双字词的语音没有得到充分激活。
对双语者语音启动的研究也将不可避免地涉及双语间的翻译启动,而L1→L2与L2→L1不同启动方向呈现的跨语言翻译启动效应的不对称是诸多学者关注的另一个问题。以各种不同语言双语者为被试的研究(De Groot & Nas,1991;Gollan et al.,1997;Jiang,1999;Jiang & Forster,2001;王悦、张积家,2014;Chen et al.,2014;Allen et al., 2015)报告了启动方向引起的不对称: 从L1到L2的翻译启动一般比从L2到L1更强,即以L1词汇为启动词,L2翻译对等词为目标词时被试对目标词的识别速度或准确率比以L2为启动词,L1为目标词时更高。Jiang(1999)对已有研究作了统计,发现不管是在掩蔽启动的实验中,还是在非掩蔽启动的实验中,L1→L2的启动量都大于L2→L1的启动量。在掩蔽启动实验中,L2→L1多数没有显著的跨语言启动效应或启动效应非常弱,而在非掩蔽启动实验(启动词呈现时间比掩蔽启动实验长)中,L2→L1一般能产生显著启动效应,但启动量仍低于L1→L2启动。我们知道,不平衡双语者的L2熟练程度较L1低,即识别加工L2词汇需要更长的时间,那么当L2词汇作为启动词时,如果呈现时间不足,则可能导致启动词无法激活或激活不充分,也即无法产生充分的启动效应。这是否可以解释为何在掩蔽启动实验上往往观察不到L2→L1启动效应,而在启动词呈现时间较长的非掩蔽启动实验中却可以观察到L2→L1翻译启动效应,同时L1→L2的启动常常比L2→L1更强?上述研究少有将这几种情况同时考虑进行对比分析,我们需要实验条件得到更严格控制的对比研究来对我们的推测进行验证。
上文提及的很多研究都是利用掩蔽翻译启动范式来研究双语同源词与非同源翻译词的异同。掩蔽翻译启动范式由Forster & Davis于1984年提出,当前在心理语言学的研究中被广泛应用到词汇决定、语义分类、命名等各种任务中,是目前跨语言启动相关行为研究中最重要的一种实验方法。在执行掩蔽翻译启动的词汇决定任务时,会先呈现给被试一个启动词(如 “咖啡”),然后再呈现另一种语言中与启动词语义对应的目标词,目标词可能是真词(如 “coffee” ),也可能是假词 (如 “ boffee”),通过要求被试判断目标词是真词还是假词来确认被试已对目标词进行了加工。在启动词出现前用掩蔽符号进行掩蔽(有时在启动词出现后也同样进行掩蔽,称为后掩蔽),启动词呈现的时间非常短,一般在50ms—60ms,以至在实验后多数被试报告不知道启动词的存在,但心理学及心理语言学的大量实验数据证实了这种启动刺激通过潜意识对被试产生影响(乔晓妹、张鑫雯,2017)。其优势在于能够最大程度地防止被试在实验过程中使用策略。在解读启动实验的结果时,主要关注在不同的启动词→目标词关系下,被试对目标词的反应时及判断错误率。各组启动词及目标词的长度、熟悉度等指标均已在实验前进行匹配,因而如果实验中被试对某组目标词的加工时间显著更短或错误率显著更低,即产生了启动效应,说明该组的启动词在某种程度上激活了目标词,促进了对目标词的加工。
总的来看,对于双语者词汇加工中语音所起的作用,现有的研究仍存在争议和疑问,在以汉语母语者为研究对象的实验中更是对视觉词汇加工过程中语音是否被激活存在对立的观点。上文提到,我们的推测是启动词的加工时间是否充足引起了相关研究实验结果的不同,因而,本研究尝试在实验中操控启动词呈现时间,考察在不同的启动词呈现时间下汉-英双语者对同源词及其他对比组的反应,同时引入L1→L2与L2→L1两个不同启动方向的对比,通过四个实验回答以下问题:
1) L1→L2与L2→L1不同启动方向呈现的启动效应是否对称及其与启动词呈现时间的长短是否有关系?
2) 语音在汉-英双语者视觉词汇加工中是否能够产生促进作用及其与启动词呈现时间的长短是否有关系?
其中,实验1和实验2为启动词呈现时间较短(50ms)的掩蔽启动实验,实验1为L1→L2方向启动,实验2则为L2→L1方向启动;实验3和实验4将启动词呈现时间延长至200ms,实验3为L1→L2方向启动,实验4为L2→L1方向启动。四组不同的被试分别参加四个实验。
Voga & Grainger(2007)提出的语音解释(Phonological Account)中对同源词优势效应作了解释,他们认为同源词优势效应由形式启动(在跨文字系统的双语中指语音启动)和语义启动的效应结合起来产生。那么如果同源词与非同源翻译词的跨语言语义重叠程度无差异,同源词加工优势从理论上来说便是双语者词汇加工过程中的语音效应。这也是本研究实验设计的理论基础。
3. 实验1
1) 研究方法
(1) 被试
来自广东某高校大二的36名(男生7名,女生29名)非英语专业本科生自愿参加实验,所有被试均为汉语母语者,裸眼视力或矫正视力正常,全部被试都参加过全国大学英语四级(CET-4)考试(满分为710分)。具体各项指标见表1,其中汉语水平与英语水平为7点量表自评分数(1=非常不熟练,7=非常熟练)。从各项数据可知,被试的汉语和英语水平不平衡,母语有明显优势。
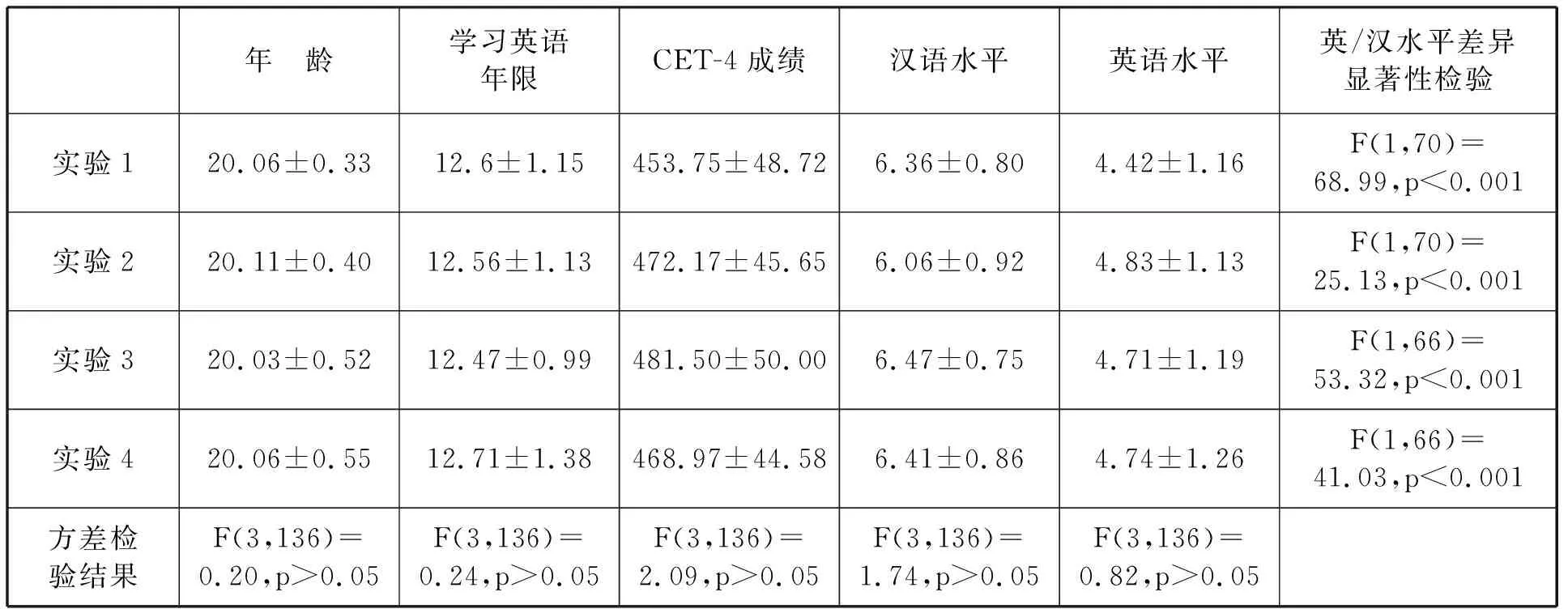
表1. 四个实验中被试各项指标评估(M±SD)
(2) 实验设计
实验采用2X2两因素被试内设计,因素1为启动词与目标词的语义相关性,分为语义对等与语义无关两个水平;因素2为启动词与目标词的语音相关性,分为语音相似与语音无关两个水平,因变量为被试在词汇判断任务中的反应时和错误率。
(3) 材料
实验中启动词和目标词的关系有以下四种: 同源翻译对等词(如吉他-guitar,以下简称同源词对,双语同源词对在语音与语义上跨语言重叠)、非同源翻译对等词(如奴隶-slave,以下简称翻译词对,翻译词对仅在语义上重叠)、语义无关但语音相似(如奈可-neck,以下简称语音相似词对,语音相似词对仅在语音上重叠)、语义与语音皆无关(如老鼠-taxi,以下简称无关词对)。启动词均为L1汉语,目标词均为L2英语。
每种关系各选取30对高频的具体名词。语音相似词对的选择是在确定英语词汇之后,将其按音译的原则翻译成汉语词汇,为了避免现成的汉语词汇引起关于语义的其他联想,翻译时避免使用现成汉语词汇。
31位与被试双语水平相当的大学生(不参加正式实验)使用七点量表对以上材料进行英语词汇熟悉度、词对语义重叠程度、词对语音重叠程度等的评估,根据评估结果保留了每种关系条件各24对词对作为正式实验材料。正式实验材料的所有汉语词汇均为双字词,其他评估指标见表2。方差分析表明,四组材料的英语词汇平均词长差异不显著,F(3,92)=0.57, p>0.05。四组材料英词词汇的平均熟悉度差异不显著,F(3,92)=0.35, p>0.05。四组材料汉英词对的平均语义重叠度差异显著,F(3,92)=2 838.68,p<0.001,同源词对与翻译词对的平均语义重叠程度都显著高于语音相似词对及无关词对,p<0.001;同源词对与翻译词对的平均语义重叠程度差异不显著,p>0.05;语音相似词对与无关词对的平均语义重叠程度差异也不显著,p>0.05。四组材料词对的平均语音重叠程度差异显著,F(3,92)=466.08,p<0.001,同源词对与语音相似词对的平均语音重叠程度都显著高于翻译词对及无关词对,p<0.001;同源词对与语音相似词对的平均语音重叠程度差异不显著,p>0.05;翻译词对与无关词对的平均语音重叠程度差异也不显著,p>0.05。
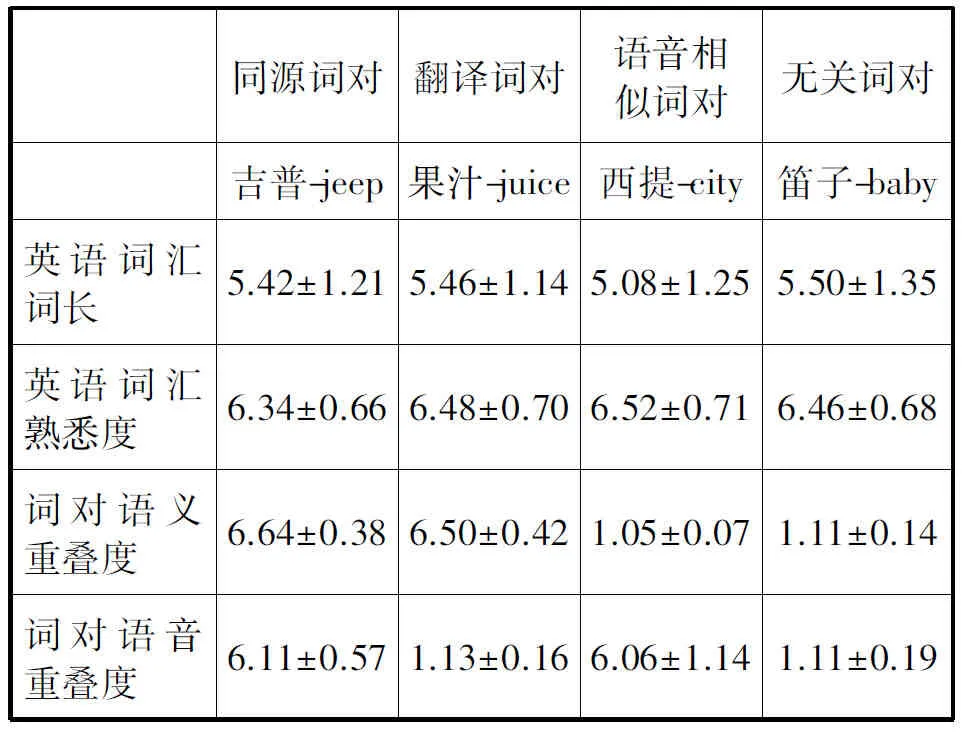
表2. 材料举例及实验材料的各项评估指标(M±SD)
另外再选取每种关系条件各24对词作为填充材料,将填充材料中的英语词汇改编为形态与真词相似、发音符合英语发音规则,但实际上并不存在的假词,如wonan,coard。
填充材料不作实验结果分析。
(4) 程序
实验使用E-prime编写及运行,在每个试次中,先在屏幕中央呈现注视点“+”500ms,接着呈现一个浅灰色的矩形作为汉语启动词的掩蔽符号(Jiang,1999),然后在同样位置呈现汉语启动词50ms,接着再呈现一串后掩蔽符号“#######”,呈现时间为100ms,最后呈现英语目标词,直至被试对目标词作出反应,再接着呈现下一试次。
正式实验前显示中文的指导语,并有10个使用非正式实验材料的试次供被试练习及掌握实验要求。在每个试次中,被试都需决定目标词是真词还是假词,如果是真词,就按J键,如果是假词,则按F键(一半被试的按键按此规定,另一半相反)。
2) 结果与分析
删除总体错误率超过20%的5名被试数据,剩余31名被试的数据用以结果分析。另外删除反应时低于300ms及超过1700ms的数据(Nakayama et al., 2014)和反应时在M±2.5SD之外的极端数据,据此删去7.76%的数据。使用SPSS14.0对各种关系条件下的被试的判断错误率及正确反应的反应时数据进行统计,结果如表3所示。
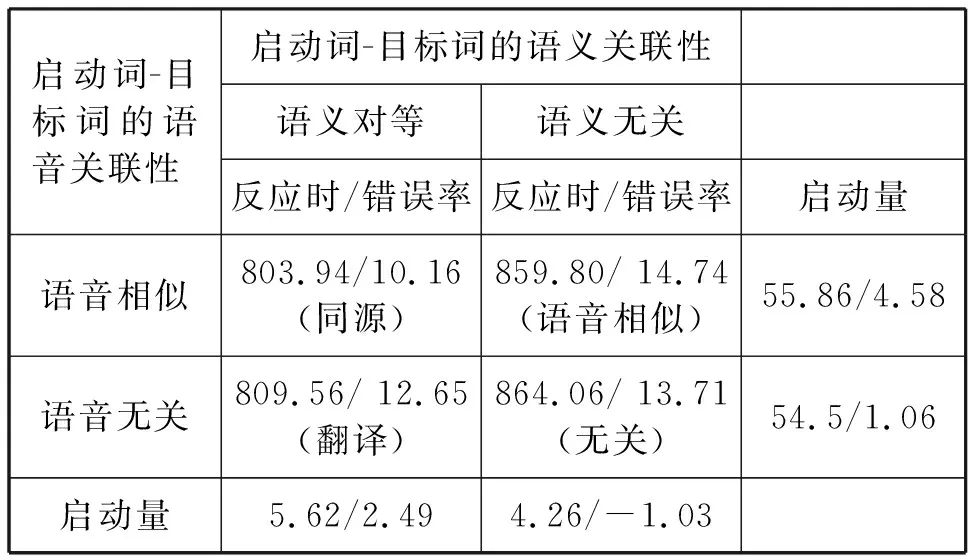
表3. L1→L2掩蔽启动实验中不同条件下的反应时(ms)及错误率(%)
反应时的两因素重复测量方差分析显示,语义关联性的主效应显著,F(1, 30)=6.55,p<0.05,η2=0.179。被试在同源与翻译条件下对目标词的反应时显著低于语音相似与无关条件,启动效应显著。由于同源词对/翻译词对与语音相似词对/无关词对的区别主要在语义上,前两者的启动词与目标词的语义都跨语言重叠,后两者的启动词与目标词都语义无关,说明在本实验中,语义在跨语言词汇启动中起到促进的作用。语音关联性的主效应不显著,F(1, 30)=0.07,p>0.05,被试在同源与翻译条件下对目标词的反应时无显著差异,在语音相似与无关条件下也无显著差异。由于同源词对/语音相似词对与翻译词对/无关词对的区别主要在语音上,前两者的启动词与目标词都语音相似,后两者的启动词与目标词都语音无关,因而说明在本实验中,语音未对语音相似词汇的跨语言激活起到明显的促进作用。两因素的交互效应也不显著,F(1, 30)=0.01,p>0.05。
对被试反应错误率的方差分析显示,语义关联性的主效应显著,F(1, 30)=8.70,p<0.05,η2=0.23。语音关联性的主效应不显著,F(1, 30)=0.76,p>0.05。两因素的交互效应也不显著,F(1, 30)=3.95,p>0.05。结果与反应时的分析结果基本一致。
4. 实验2
1) 研究方法
(1) 被试
与实验1的被试来自相同群体,所有被试均裸眼视力或矫正视力正常。36名被试(男生5名,女生31名)各项指标见表1,方差分析表明各项平均得分均与其他3个实验被试无显著差异。本实验的被试均未参加过实验1。
(2) 材料
本实验启动方向与实验1相反,启动词均为L2英语,目标词均为L1汉语。实验材料除了语音相似词对改为由音译的无意义英语词启动汉语词汇(如leeze-李子)外,其他材料即同源词对、翻译词对及无关词对均沿用实验1材料,仅改变启动方向。语音相似词对的评估筛选过程同实验1,七点量表评估结果显示,本实验中语音相似词对的英语词汇平均词长为6.29个字母,SD=1.49,方差分析显示其与其他3组材料词长无显著差异,F(3,92)=2.46,p>0.05。语音相似词对的平均语义重叠程度为1.06,SD=0.08。四组材料词对的平均语义重叠度差异显著,F(3,92)=2769.51, p<0.001;同源词对与翻译词对的平均语义重叠程度都显著高于语音相似词对及无关词对,p<0.001;语音相似词对与无关词对的平均语义重叠程度差异不显著,p>0.05。语音相似词对的平均语音重叠程度为6.32,SD=0.58。四组材料词对的平均语音重叠度差异显著,F(3,92)=1150.97, p<0.001;同源词对与语音相似词对的平均语音重叠程度都显著高于翻译词对及无关词对,p<0.001;同源词对与语音相似词对的平均语音重叠程度差异不显著,p>0.05。另外,四组材料的汉语词汇熟悉度差异也不显著(M值分别为6.89、6.97、6.93、6.97,F(3,92)=2.40,p>0.05)。其他实验1已作分析的数据此处不重复分析。
另外再选取每种关系条件各24对词作为填充材料,将填充材料中的汉语词汇改为无意义的汉语词,如首而、口灯,填充材料不作实验结果分析。
(3) 程序
本实验与实验1的不同主要在于启动词和目标词的语种进行了调换。在每个试次中,先在屏幕中央呈现注视点“+”500ms,接着呈现一串掩蔽符号“#######”,然后在同样位置呈现英语启动词50ms,接着再呈现一个浅灰色的矩形作为后掩蔽符号,呈现时间为100ms,最后呈现汉语目标词,直至被试对目标词作出反应,再接着呈现下一试次。其他同实验1。
2) 结果与分析
删除总体错误率超过20%的1名被试数据,剩余35名被试的数据用以结果分析。另外删除反应时在300—1700ms之外和反应时在M±2.5SD之外的极端数据,据此删去3.54%的数据。统计结果如表4所示。
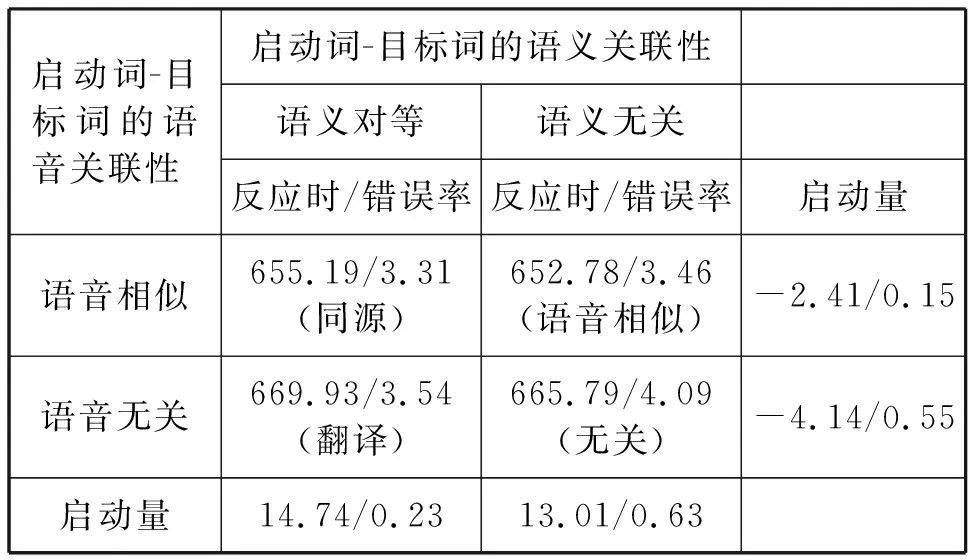
表4. L2→L1掩蔽启动实验中不同条件下的反应时(ms)及错误率(%)
反应时的两因素重复测量方差分析显示,语义关联性的主效应不显著,F(1,34)=0.10,p>0.05。同源条件、翻译条件下被试对目标词的反应时与语音相似条件、无关条件无显著差异,说明在本实验中,语义在从L2到L1的启动中不起促进作用。语音关联性的主效应也不显著,F(1,34)=0.69,p>0.05,说明在本实验中,语音也未对语音相似词汇的跨语言激活起到明显的促进作用。两因素的交互效应同样不显著,F(1,34)=0.001,p>0.05。
错误率方面启动量均很小(不足1%),因而未进行统计分析。
从实验1及实验2来看,语义在L1→L2掩蔽翻译启动中有显著的促进作用,而在L2→L1中则作用不明显,语音则在L1→L2及L2→L1两个方向所起的作用都不明显。
Jiang (1999)通过在启动词和目标词之间增加空白间隔及后掩蔽的方法来延长启动词的加工时间,但仍没有获得L2→L1的翻译启动效应;而Chen等(2014)在将启动词呈现时间延长至250ms之后,观察到L2→L1的翻译启动效应;Tan & Perfetti(1997)则在启动词呈现时间分别为129ms及243ms的实验中观察到了语音激活。参考他们的研究,我们通过延长启动词呈现时间的方法来改进实验。经过反复试测,我们确定了一个可能产生语音启动效应,且尽可能短的启动词呈现时间: 200ms。在本研究的实验3、4中,启动词呈现时间被延长至200ms,被试能够较清楚地看到启动词,这已经不是真正意义上的掩蔽启动,但由于启动词呈现时间被尽量控制到最短,也最大限度地控制了被试在实验中使用策略的可能。
5. 实验3
1) 研究方法
(1) 被试
与前2个实验的被试来自相同群体,所有被试均裸眼视力或矫正视力正常。34名被试(男生4名,女生30名)各项指标评估见表1,方差分析表明各项平均得分均与其他3个实验被试无显著差异。本实验的被试均未参加过前2个实验。
(2) 材料
同实验1。
(3) 程序
本实验与实验1的不同之处在于将启动词的呈现时间由实验1的50ms延长至200ms,其他程序与实验1相同。
2) 结果与分析
删除总体错误率超过20%的3名被试数据,剩余31名被试的数据用以结果分析。另外删除反应时低于300ms及超过1 700ms的数据和反应时在M±2.5SD之外的极端数据,据此删去5.15%的数据。统计结果如表5所示。

表5. L1→L2启动实验中不同条件下的反应时(ms)及错误率(%)
反应时的两因素重复测量方差分析显示,语义关联性的主效应显著,F(1, 30)=5.81,p<0.05,η2=0.16。同源条件与翻译条件下被试对目标词的反应时显著低于语音相似条件与无关条件,启动效应显著。说明在本实验中,语义在跨语言词汇启动中起到促进的作用。语音关联性的主效应显著,F(1, 30)=4.28,p<0.05, η2=0.13,说明在本实验中,语音促进了语音相似词汇的跨语言激活。两因素的交互效应不显著,F(1, 30)=0.005,p>0.05。
对被试反应错误率的方差分析显示,语义关联性的主效应不显著,F(1, 30)=2.08,p>0.05; 语音关联性的主效应也不显著,F(1, 30)=1.93,p>0.05; 两因素的交互效应同样不显著,F(1, 30)=0.12,p>0.05。各关系条件下的被试反应错误率均没有显著差异。
6. 实验4
1) 研究方法
(1) 被试
与前3个实验的被试来自相同群体,所有被试均裸眼视力或矫正视力正常。34名被试(男生5名,女生29名)各项指标评估见表1,方差分析表明各项平均得分均与其他3个实验被试无显著差异。本实验的被试均未参加过前3个实验。
(2) 材料
同实验2。
(3) 程序
本实验与实验2的不同之处在于将启动词的呈现时间由实验2的50ms延长至200ms,其他程序与实验2相同。
2) 结果与分析
删除总体错误率超过20%的2名被试数据,剩余32名被试的数据用以结果分析。另外删除反应时低于300ms及超过1 700ms的数据和反应时在M±2.5SD之外的极端数据,据此删去2.36%的数据。统计结果如表6所示。
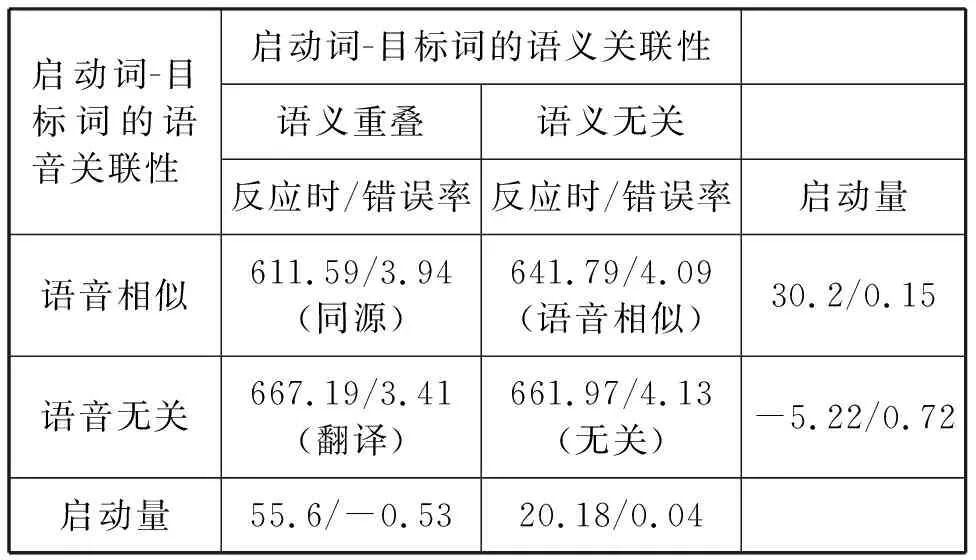
表6. L2→L1启动实验中不同条件下的反应时(ms)及错误率(%)
反应时的两因素重复测量方差分析显示,语义关联性的主效应不显著,F(1,31)=0.26,p>0.05。同源条件、翻译条件下被试对目标词的反应时与语音相似条件、无关条件无显著差异,语义在跨语言词汇启动中的作用不显著。语音关联性则主效应显著,F(1,31)=4.25,p<0.05,η2=0.12。同源条件与语音相似条件的反应时显著低于翻译条件与无关条件,说明在本实验中,语音促进了语音相似词汇的跨语言激活。两因素的交互效应不显著,F(1,31)=0.81,p>0.05。
错误率方面启动量均很小,因而未进行统计分析。
7. 讨论
本研究显示了与现有的很多研究(De Groot & Nas,1991;Gollan et al.,1997; Jiang,1999;Chen et al.,2014)相似的结果: 跨语言翻译启动效应在启动方向上的不对称。在实验1中,我们发现了L1→L2启动方向的翻译启动效应,即用汉语的启动词来启动其翻译对等的英语词汇时,被试对目标词的加工时间短于启动词与目标词之间语义无关的情况,因为这两种情况的差别主要在语义上,所以我们也将之称为语义启动效应。在L2→L1启动方向的实验2中却没有发现对应的语义启动效应。实验1、2的启动词呈现时间都非常短(50ms),而在启动词呈现时间较长(200ms)的实验3和实验4中,同样观察到不对称的启动效应: L1→L2启动方向的实验中语音与语义均出现了启动效应,L2→L1方向却只观察到语音启动效应。与实验1、2相比,实验3、4虽然延长了启动词呈现时间,但观察到的语义启动效应仍不对称。为何在较长的启动词呈现时间下,仍没有出现L2→L1的语义启动效应?其原因我们将在后文讨论。这种双语之间不平衡的情况可以用Kroll & Stewart (1994)提出的修正层级模型(Revised Hierarchical Model)(图1)来解释。修正层级模型认为L1与L2都与概念意义相连,但是L1与概念意义的连接比L2要强,因而可以预见,L2通达概念意义需要更长的时间。在本研究不长的启动词呈现时间(50ms及200ms)中,L1启动词能够通达语义,进而在接下来的阶段激活L2目标词,L2启动词却不足以通达语义,所以在L1词汇作为启动词时出现了语义启动效应,而L2词汇作为启动词时却没有观察到语义启动效应。模型中虽然L2到L1之间也有直接联系,但由于被试对L2不够熟练,L2→L1之间的联系应该弱于L1到概念意义之间的连接,在很短的时间内不足以得到激活。
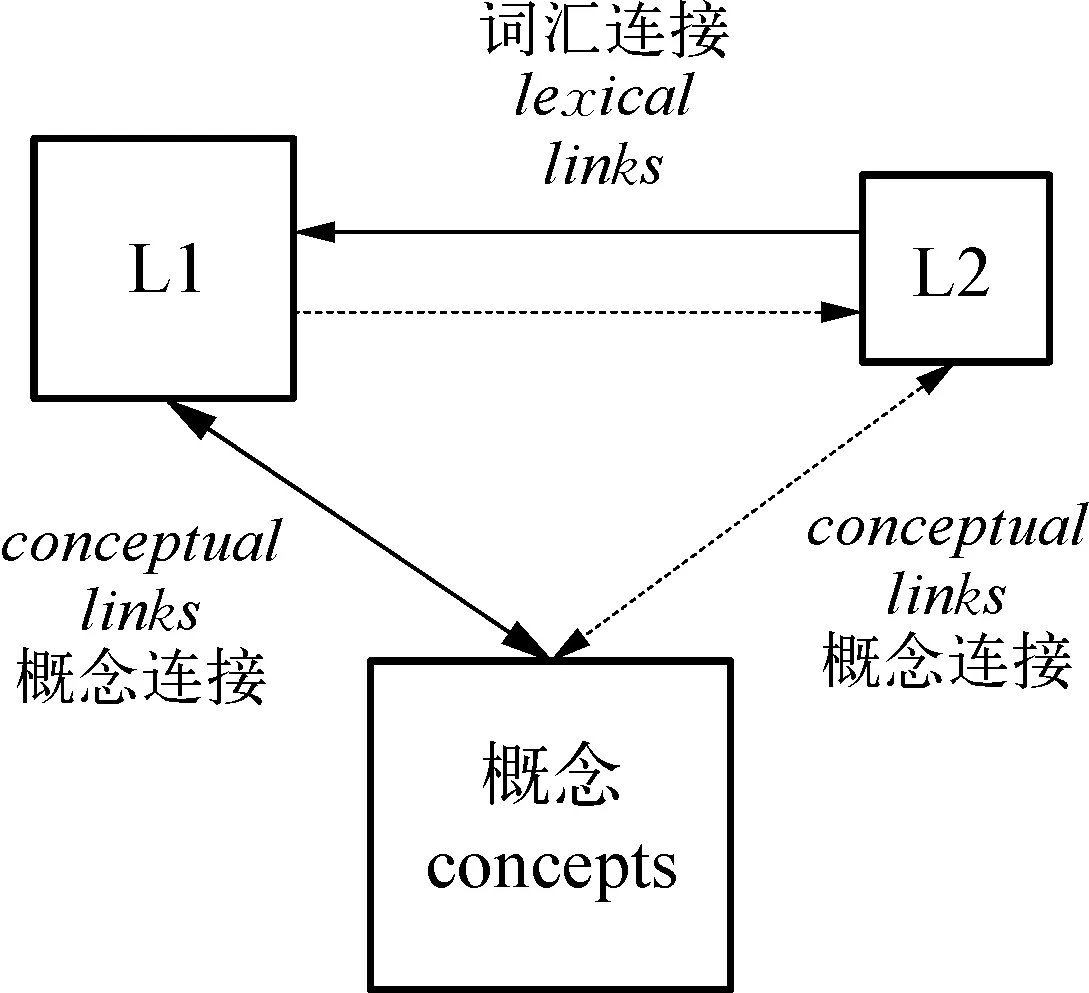
图1. 修正层级模型(Kroll & Stewart,1994)
下面讨论本研究的重点所在: 双语词汇加工中的语音启动。
在L1→L2方向的启动中,实验1没有观察到语音在双语者视觉词汇加工中的启动效应,而在实验3中,由于延长了启动词呈现时间,我们同时观察到了语音及语义启动效应。这说明在启动词呈现时间足够长的情况下,语音在汉语视觉词汇识别中能够被激活,并促进语音相似的对应英语词汇的加工。前文推测Wong等(2014)及高淇、刘希平(2016)的研究中未观察到汉语词汇的语音激活的原因是启动词呈现时间太短,该实验结果证实了我们的推测。这种推测也可以从刘蕴秋和赵烨(2008)的研究中得到佐证: 他们的阅读实验没有时间限制,实验结论是中-日双语者在加工日语汉字时其语音信息得到了激活。
另外,我们发现在实验3中虽然语音产生了启动效应,但语义启动量(46和47.96)远大于语音启动量(22.38和24.34),与实验1仅发现语义启动,未发现语音启动的结果相呼应。说明被试在较短的时间内加工汉语词汇的情况下,对语义的激活强于语音。
在L2→L1方向的启动中,实验2未发现语音启动效应,而在L2启动词呈现时间相对较长的实验4中,我们观察到了语音启动效应。这说明被试在加工L2视觉词汇时,只要启动词呈现时间足够长,即能够激活词汇的语音信息,进而促进对语音相似的对应汉语词汇的加工。这与我们的预测一致,也与吴诗玉、马拯(2015)在语义关联判断任务中获得的实验结果相符: 汉-英双语者在阅读二语词汇时,语音能够得到自动激活。
值得注意的一点是在L2→L1方向启动的实验4中虽然发现了语音启动效应,却没有发现语义启动效应,这与实验1在L1→L2的启动中仅发现语义启动效应,未发现语音启动的情况形成对比。究其原因,Gollan等(1997)曾提到,双语者在L2阅读中对语音更加依赖,而本研究的被试为汉-英双语者,在汉、英两种文字形式的对比下,这种趋势可能会更加明显。一方面,由于被试对L1汉语较为熟悉,因而在视觉输入汉语启动词时,可能更快地通达语义,不需过多激活其语音信息;另一方面,汉语本身的语言特色是文字形式与语音信息没有直接联系,因而在实验1较短的启动词呈现时间下可以得到L1→L2语义启动效应,却没有得到语音启动效应也是正常的,这可以从以往使用汉语双字词作为启动词的掩蔽启动实验(Wong et al.,2014;Zhou et al.,1999)也没有观察到语音启动效应的情况得到佐证,以日语汉字为启动词的研究(Chen et al.,2007)也有类似的结果。而在实验4中,一来因为英语本身的书写形式与语音信息直接相关,二来由于英语对被试来说不够熟练,因而被试在被呈现英词启动词时,首先激活了词汇的语音形式。在实验2中由于L2启动词呈现时间不够长,未能形成语音启动效应,而实验4中L2启动词呈现时间较长,足以让被试激活其语音信息,但可能还不足以激活其语义信息。纵观以汉-英双语者为被试的相关研究,Chen等(2014)在将启动词呈现时间从50ms延长到250ms之后才观察到了L2→L1的语义启动,而Chen & Ng (1989)在L2启动词呈现时间为300ms的实验中获得了显著的跨语言语义启动效应;其他一些启动词呈现时间较短的研究(如Jiang,1999)都未能观察到显著且稳定的L2→L1语义启动效应。据此,我们推测,在L2启动词呈现时间为200ms的实验4中没有观察到语义启动效应的主要原因是启动词呈现时间不够长,还不足以激活语义,因而在实验4中只出现了语音启动效应,没有出现显著的语义启动效应。能够激活L2语义的启动词呈现时间的临界值是多少还需进一步实验研究。这种先激活语音再激活语义的推测也符合Dijkstra & van Heuven(2002)提出的双语词汇识别BIA+模型(图2)的假设。如图2所示,在BIA+模型中,输入的词汇信息先激活正字法候选词,继而激活相应的语音、语义和词汇的其他特征,其中,语音先于语义被激活。BIA+模型主要是基于拼音文字建立的,而本文的实验4中启动词为英语,对其词汇的加工过程符合该模型的假设。
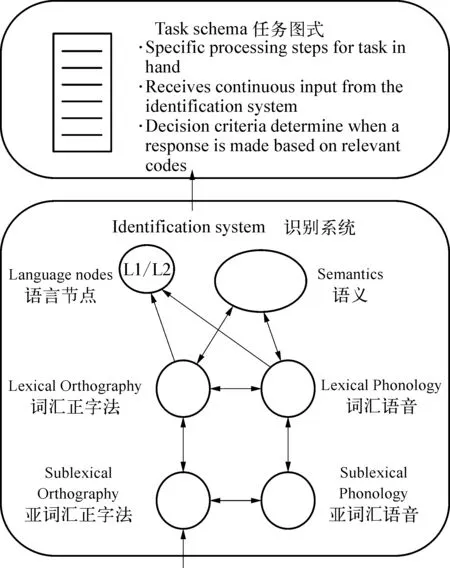
图2. 双语词汇识别的BIA+模型(Dijkstra & van Heuven,2002)
BIA+模型支持双语的非选择性加工假设,认为双语者在加工其中一种语言时,另一种语言也同时被激活。在正字法上完全没有重叠的两种语言(如汉语和英语)虽然无法跨语言直接激活正字法,但相似语音的跨语言激活仍可能发生。另一方面,由于对被试来说,L2词汇使用的频率低于L1词汇,因而L2词汇的激活速度慢于L1词汇。这些观点也都在本研究中得到了验证。
但同时我们也注意到,在实验1及实验3中对汉语启动词的加工过程与模型的预测并不完全一致: BIA+模型假设词汇语音的激活先于语义发生,但是对于语音与正字法之间没有直接联系的汉语来说,情况似乎有所不同。我们在实验1及实验3的研究中发现,在汉语词汇的加工中,语义的激活比语音激活所需的时间更短,也就是说,语义的激活应该早于语音的激活。
这里应注意的是,我们的结论可能并不适用于所有的情况,对于汉语词汇的加工,还有一些特殊的情形。其一,汉语的文字形式虽然不像拼音文字一样与发音直接相关,但是有一部分汉字与其发音间接相关,即汉字中的形声字,如“溢”字,即通过其声旁“益”与发音“yì”关联起来。由于声旁“益”是高频使用的汉字,它的存在可能使“溢”字的语音比其他与“溢”字使用频率相当的非形声汉字更容易被激活。这种情况在形声字为常用高频字时可能表现不明显,而在形声字为使用频率较低的汉字时,可能表现较为明显,也就是说,对于低频使用的形声汉字来说,由于受到声旁的影响,其语音和语义激活的过程不一定与我们的实验结果一致,其语音的激活甚至可能早于语义的激活。
另一种特殊的汉语词汇表征方式是音义一体的双音词,如“踌躇”、“彷徨”等。这些双音词以整词的形式出现时,是使用频率较高的词汇,其语音和语义都可以得到较快的激活;但当它们被拆开以单字形式(如“踌”、“彷”)出现时,则成了使用频率较低的汉字,其语音的激活可能需要比双音整词更长的时间,这与本文研究背景部分提到的双字中文复合词比单字词的加工需要更多时间的情况显然是不一致的。
全面考察汉英双语者词汇加工中的语音激活,必须考虑到汉、英双语不同的语言特点,还必须考虑到上文提到的这些汉语词汇的特殊表征形式。本文由于篇幅的原因未能对这些方面进行独立的实验研究,希望未来可以进行更深入的研究,为双语词汇的加工过程提供更多更详实的实验数据,并最终形成较为完善的双语词汇加工模型。
将本研究的结果应用到对双语者的英语教学中,我们认为应尊重语言本身的特点,重视语音在英语词汇教学中的作用。我们都知道语音在听辨及口语产出中的重要性,而它在词汇习得及视觉词汇识别中的作用却很少引起人们的注意。在我们传统的英语词汇教学中,较为强调对单词的释义、用法的讲解,却经常忽视了语音的作用。拼音文字的语言特点是音形相关,从我们的研究可知,学习者在识别英语词汇时,会先激活其语音的信息,再进一步通达语义,如果我们在教学中能将词汇的读音和拼写更好地结合起来,使读音与拼写的学习相促相长,那么对词汇的拼写及读音的习得都会事半功倍,在识别词汇时也将速度更快、准确率更高。在具体的教学实践中,可以更多采用强调语音作用的自然拼读法(Phonics)及加强音标的教学,在词汇教学时尽量将读音与拼写结合,培养学生看词拼读的能力。
8. 结论
在L1→L2与L2→L1不同启动方向呈现的跨语言翻译启动方面,本研究得到了与现有多数研究一致的实验结果: 跨语言翻译启动效应在L1→L2启动方向与L2→L1启动方向上不对称。对于语音启动,在启动时间较短的实验1和2中未观察到语音启动效应,而在启动时间较长的实验3与实验4中,本研究发现L1→L2启动方向能同时得到语义启动效应与语音启动效应,而L2→L1方向也得到了语音启动效应,可见不管被试接触的视觉词是汉语还是英语,只要接触时间足够长,词汇的语音都能得到激活,且能够进而激活另一种语言对应词汇的语音。综合各实验的结果,我们发现在英语词汇的加工中先激活语音再激活语义,而在汉语词汇的加工中对语义的激活强于语音,也早于语音。但本文的研究结果可能并不适用于所有的情况,全面考察汉语词汇加工过程中语音的作用,还需考虑到形声字等一些特殊的语言形式,在识别它们的过程中对语音、语义等信息的激活可能有别于普通的情况。
由于时间与篇幅的限制,本文的研究尚有许多未尽之处,在未来的研究中可尝试使用不同的启动词呈现时间进行实验,以探索汉英双语者在阅读L2词汇时能够激活其语义的启动词呈现时间的临界值;同时可对汉字的特殊表征形式,如形声字、双音词等进行实验研究,以提供更全面的相关实验数据,帮助我们更好地了解汉-英双语者视觉词汇加工的过程。
