基于本体的民国文学专题数据库知识组织研究*
2019-06-05沈立力朱蓓琳
沈立力 朱蓓琳 姜 鹏 王 静
(上海图书馆,上海 200031)
随着信息技术的进一步发展,传统的图书馆文献组织和服务形式无法解决读者在获取知识时的“信息过载”“信息迷航”等问题,也达不到智能化、立体化、个性化的知识服务要求。要解决这些问题,必须在传统文献组织方法(分类法、主题法等)的基础上,运用新的知识组织和知识挖掘方法(本体、关联数据等),探索由二维线性描述方式向多维描述方式转化的知识组织新模式,形成领域内具有逻辑关系的结构化知识网络。
经过前期调研,目前基于本体的知识组织形式被广泛应用于医学、农学等领域。然而,目前本体在文史领域,尤其是针对民国文学领域的应用还处于起步阶段,且民国文学期刊资源市场需求较大,而提供的深层次知识服务却较少。以此为契机,上海图书馆全国报刊索引与芝加哥大学开展了民国文学期刊OCR 项目的合作,目的是通过本体、关联数据等多种研究手段,与传统文学历史及文学评论相结合,建立文学作品、人物、期刊、历史事件等不同实体之间的关系,并以可视化的方式展现,优化现有检索结果,实现知识服务的升级,为用户提供更好的知识服务体验,也为将来的资源共建与共享打下基础。
1 本体及民国文学知识组织现状
1.1 本体构建方法及现状
本体的概念最早出现于哲学领域,而Studer 等学者在上世纪90年代对本体进行大量深入研究后对本体进行了更明确的设定,即“共享概念模型的明确的形式化规范说明”[1]。本体是通过定义类、属性、关系等元素对某一特定领域知识进行层次关系的描述、归纳和抽象化[2]。同时,本体又给数据本身赋予了语义,使机器能够处理数据间的关系[3]。
国内外对于本体的构建方法已经有了一些研究,据岳丽欣[2]归纳,国内外较为成熟的本体构建方法包括:IDEF5法、骨架法、Methontology 法、七步法、循环获取法、基于叙词表构建本体法等。笔者选择斯坦福大学医学院提出的七步法,结合项目本身的特点,使用Protégé 本体编辑工具,根据已有元数据标准建设民国文学知识体系,设计一个向下兼容、易于扩展、多维描述,支持民国文学期刊数据重组和揭示的民国文学本体。
1.2 文史领域本体建设的国内研究现状
近年来,全国各大图书馆、高校及数字出版公司都积极致力于开发深层次的知识组织与知识挖掘方式,更好地揭示馆藏文献资源,并就本体在文史领域的应用进行了研究,在历史领域本体构建、人物关系本体研究、特殊文献体裁本体构建等方面进行了诸多实践。中国社会科学院哲学社会科学创新工程信息化项目“中华人民共和国史教育网”中成功构建了中华人民共和国国史本体,该国史本体描述了1977—1981年这一历史时期关于中华人民共和国的概念、术语、关系等,构建包括时间、人物、事件等8 个大类的本体,并为基于本体的国史知识检索平台构建打下基础[4]。廖作芳[5]以《三国志》为文本,利用七步法构建基于人物、时间、地点、事件、职官为五大核心概念的历史领域本体,并运用SWRL 规则对《三国志》本体蕴含知识做了发现推理,突出了本体在历史领域的应用。汪沛[6]则引入知识元及语义网的相关概念与理论,采用自动抽取的方法对《三国志》中的特征词进行抽取,并作为实例添加到本体中,进行了基于本体的历史领域知识元构建。夏翠娟等[3]则针对上海图书馆馆藏家谱,进行基于书目框架模型的家谱本体构建,并论述了相关的应用场景,既揭示了家谱资源的特殊文献特征和内容属性,又揭示了其内容之间的语义关联。
1 民国文学专题数据库本体模型构建原则和难点
1.1 民国文学本体构建原则
在比较同类型文史领域构建经验的基础上总结了以下两点民国文学本体构建原则。
一是夯实数据来源,覆盖各类文学期刊。中国现代文学发端于“五四运动”,它与当时的政治、经济都有密切的关系,更是社会意识形态和整个文化的重要组成部分,是研究近代历史不可或缺的一部分。据邓集田[7]统计,从中国第一种文学期刊《瀛寰琐纪》起到1949年间共出版传播文学期刊4200 余种。这里所说的文学期刊包括两类:一是以纯文学内容为主的期刊,主要内容涵盖诗歌、小说、散文等,如《人世间》《小说月报》等;另一种则是含有较多文学内容的期刊,但也包括时政、教育等内容,如《太平洋(北平)》《文艺月刊》等。另外,在项目前期对复旦大学文史专家进行调研的过程中发现,除了专门的文学性刊物外,还需关注刊登文学作品的综合性刊物、革命性期刊、学术刊物、女性刊物及报纸副刊等,如《东方杂志》《女学报》等。
二是重视客观内容的知识挖掘,谨慎处理主观内容的揭示。民国文学本体的构建旨在利用技术手段对已有数字资源进行挖掘、重组、研究,而不是深入某一细分领域代替历史人文研究者进行具体的研究工作[8]。在专家调研时,文史专家也提到目前学界的研究方式大多以问题为导向,因此更关注客观著录项的详尽度和准确度。在此基础上,民国文学本体的构建将重视对作者、时间等客观元素的知识挖掘,而对历史事件、文学社团等相对主观元素的揭示将更为谨慎。同时,对于文学派别、地域文学研究等学界还未有综合性研究成果的内容暂不予以揭示,留待之后扩展。
1.2 民国文学本体模型构建难点
综合前期调研和实际构建中遇到的问题,民国文学本体的构建存在以下难点:
一是已有人文历史领域的本体构建更注重理论模型的研究,而真正运用到实际中的本体并不多。依据调研只有家谱、国史、东北抗战史本体等。其他例如三国志等的本体构建与研究只是处于实验室阶段。而在民国文学领域的本体研究与构建更是处于空白,没有直接可复用的本体模型。
二是数据来源不充分。目前已经完成OCR 加工的晚清民国期刊约为300 余种,而全国报刊索引晚清民国期刊全文数据库总共约有两万余种期刊,其中涉及文学内容的约为2000余种,已经进行OCR加工的文学期刊占到所有文学类期刊的15%。文献未进行OCR 加工意味着在构建过程中不能对全文文献进行深层次的挖掘、提取,存在一定缺陷。
三是依据已有的本体构建方法,对民国文学资源的本体构建不能实现自动构建或半自动构建,构建过程人工花费较大。究其原因首先是在人文历史尤其是民国文学领域,并未发现叙词表、数据库资源、或是在线本体库等可以进复用的半自动构建资源。其次,民国期刊文献中没有明确的上下位关系,因此关系的建立需要纯人工完成,同时对人物描述、地点演变等也需逐条进行人工判断。
四是缺乏统一的本体评价机制。本体构建的主观性较强,对于已经构建完成的本体体系成果缺乏成熟的评价标准,不利于对本体进行修正与优化。
2 民国文学本体的分析与设计
2.1 民国文学本体模型构建思路
在前期调研的基础上,选择七步法为基本构建方法,结合民国文学这一特殊学科领域,同时考虑本项目的实际可操作性,提出民国文学本体构建流程。如图1所示。

图1 本体构建流程
首先,确定民国文学本体的领域和范畴。其次调研复用现有本体的可能性,经过前期调研,发现学界已成型且可被使用的文史领域本体系统较少,且未发现涉及民国文学的本体,不具备直接复用现有本体的可能性。因此,民国文学本体将在借鉴“家谱本体”“三国志本体”的基础上进行构建。
接下来是本体库的设计,它是本体构建的关键。主要分为以下3 个步骤。首先,确定民国文学本体的核心概念,即以《中国图书馆分类法(第五版)》中“I2 中国文学”类目,中国新文学大系等作为基础,并汲取其中相关主题词、关键词作为主要概念来源,并将已经OCR完成的300余种65万版30万篇民国文学类期刊作为主要数据来源,在领域专家的帮助下确定其核心概念。接着,建立类与类之间的层次结构,即在确定核心概念后,依据自上而下的顺序对核心概念进行扩展,并对所有概念进行体系建立。最后,确定民国文学本体的属性,包括数值属性和对象属性。并依据需求进一步定义属性的分面,如属性的定义域、值域等。
之后,利用 protégé 软件对本体进行编码和构建。添加相应实例,以便于机器的读取和存储。最后,使用自带推理机为民国文学本体制定推理规则,验证逻辑关系是否正确并进行优化。
2.2 近代期刊民国文学专题数据库的元数据解析
馆藏近代文学期刊的全文OCR 加工为民国文学本体建设奠定了基础。规范化、结构化的元数据是文献资源数字化的成果,OCR 加工更是将这些成果进一步变为知识挖掘、知识组织、知识服务的宝贵素材。本体是元数据方案立体化的过程[9],是将平面的元数据方案通过类(Class)的确定,类与类之间层级关系的确定,属性(Property)等的明确过程最终建立立体的本体模型。对民国文学期刊元数据解析为民国文学本体建设打下基础。
《全国近代中文期刊全文数据库-文学专题》在民国全文数据库基础上进行加工著录,采用XML数据格式,分为图片、广告、正文3种资源类型,共用一套元数据元素著录,而每种资源本身又有特殊的元数据元素和著录规范细则。数据分为期刊、篇名两层数据结构,可对已经著录的刊名、出版社、出版时间等字段进行检索、并在数据库平台上对文献来源、作者、出版时间字段进行聚类。这种以文献本身为组织对象的信息组织方式无法完全满足用户的需求,主要问题是缺乏对人名、地名等字段的规范控制,影响用户的查全率和查准率[3],其次不能有效地提供相关事件、文献等的推荐功能。而民国文学本体的建立正是为了将内容和文献本身同时作为知识组织的对象,更好地为用户服务。
本体的构建应该尽可能多地复用已有本体的类和属性,而当已有本体的类和属性不能完全描述待建本体中的关系时,需自定义新的类及属性。对于民国文学本体而言,虽然没有可完全复用的成熟本体,但其本体建设应建立在民国期刊元数据方案之上。近代期刊元数据对期刊以及文献的揭示较为全面,对于题名项、责任者项、出版社项、出版年份项等文献特征描述完整、定义清晰,可直接在本体构建中复用,有足够的类和属性与之对应。而已有元数据方案不能对一些特殊属性、关系进行描述,如人物籍贯、民族等的属性描述,人物与事件、人物与人物等类与类之间关系的描述等。因此,在本体建立时需要对事件、地点、人物、机构组织这4 个新的类进行定义,并描述新的定义。而对文献、期刊这两个类中某些新的属性,如文学体裁等进行补充定义,在继承已有元数据方案的基础上,保证新增类和属性与原有数据的兼容性。
2.3 民国文学本体模型构建
《全国近代中文期刊全文数据库-文学专题》是全国报刊索引开发的研究晚清民国时期文学发展历史的专题数据库。时间跨度为民国起始(1911年)到1949年为止,其中涉及少量晚清数据内容(1833-1911年)。以下对构建过程中最主要的3 个部分进行论述。
2.3.1 确定核心概念集及层次结构
基于本体的知识组织体系构建中,核心概念集的确定是最重要也是最基础的问题。核心概念集的确定要遵照3 个基本要求,即遵照核心概念即顶级概念无二义性、概念与概念之间互不相交、核心概念覆盖全领域[5]。具体方法是:以已有近代期刊元数据方案为基础,将文献中其他字段提取并归类,确定人物(Figure)、文献(Document)、期刊(Journal)、事件(Event)、地 点(Place)、机 构组 织(Organization Administrator)这6个核心概念。其中新增4个概念:人物一般指文献的责任者,同时又有可能是期刊的主编,或是历史事件中涉及的具有代表性的人物,但不涉及文学作品中创作的人物。事件主要指的是民国文学期刊中所记载的历史事件或机构组织变迁等期刊所涉及的事件本身,大多以政治、文化事件为主。此外,将机构组织单独作为一个核心概念。这里的机构组织是指出版机构、文学社团等在民国文学发展史上起到一定推动作用,有一定历史地位的政府、民间或个人组织。机构组织是非常重要的资源,将其单独设类有助于将关于某一机构组织的信息,如机构负责人、机构地点、主要负责人等信息结构化、规范化揭示。最后,对于地点这个类的处理将参考上海图书馆人名规范档中的地理信息进行规范。
而对于元数据方案中已有的期刊、文献两个核心概念的处理,则尽量复用原有元数据。其中将文献这个核心概念依据体裁分为正文、图片、广告3个二级类(见图2)。
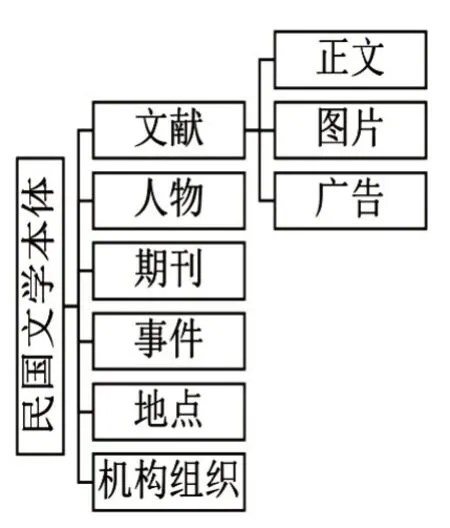
图2 概念层次结构
2.3.2 定义属性、属性的分面、定义域和值域
在确定了核心概念集与层级结构之后,需要为每个核心概念级类(Class)定义属性,通过属性进行概念的描述以及建立不同概念之间的联系。属性可以分为数据属性(Datatype Property)以及对象属性(Object Property)两种。数据属性用于描述概念本身的特性,对于人物这个类可定义性别、籍贯、民族等为数据属性。其次,民国文学领域所涉及事件的描述由人、地、时三要素组成,事件这个类的对象属性可定义为事件开始时间、事件结束时间、事件结果等。另外,为机构组织定义机构名称、存在时间等数据属性。最后,文献、期刊这两个类的数据属性基本复用了原有的元数据,并为正文、广告、图片都定义了不同的数据属性,如栏目、责任者等,并新增文学体裁这个数据属性。对象属性用于描述概念之间的关系。例如人物与文献之间的写作关系,或人物与机构之间的任职关系等为对象属性。
在确定了数据属性和对象属性后依据需求为部分属性添加定义域和值域。例如人物的妻子属性的值域是人物这个类本身,而人物的对象属性参与的值域是事件。表1列出了部分类的部分对象属性和数据属性。
2.3.3 添加实例
实例添加是整个本体建设中最为耗时耗力的部分。虽然学界致力于研究本体的自动或半自动构建,但由于中文文本处理的局限性和不成熟性,自动或半自动处理的本体需要大量的人工干预,因此在尝试后仍然采用人工添加实例的方法。此外,人工建设本体还可在实例添加的过程中对类和属性作适当调整。在实例添加过程中有以下两点需要注意:
一是在实例添加的过程中对于人物的数据属性异名的规范性描述,即分辨该人物在不同时期的笔名、字、号等,在此次实例添加中,该属性的规范参考了上海图书馆人名规范库以及《中国近现代人物名号大辞典》。
二是对于相同事件名称、组织机构名称规范性的问题。目前,学界并没有成文的对于民国文学领域事件和机构组织的规范档可做参考,因此在实例添加的过程中秉持相同事件、相同组织机构采用统一名称,避免后期引起歧义。
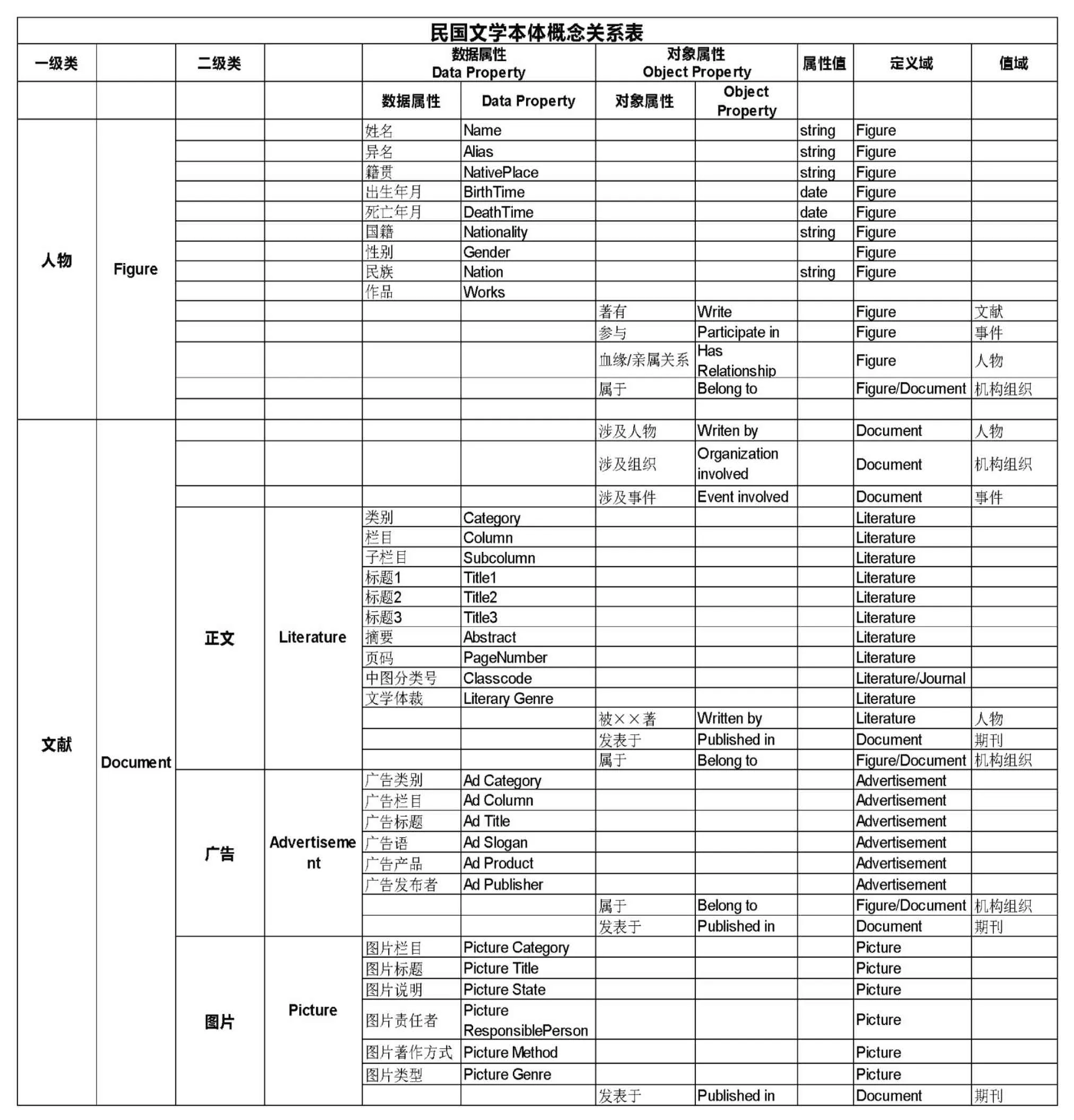
表1 民国文学本体概念关系
3 民国文学本体模型及其应用方向
3.1 民国文学本体模型描述
依据上文论述的构建流程完成民国文学本体模型,该本体模型描述了1911年到1949年期间文学领域所涉及到的概念、关系和术语。本体模型包括人物、文献、期刊、事件、地点、组织机构6 个大类及其之间的关系,具体包含9个本体类(其中6个一级类,3个二级类),60个数据属性,28个对象属性,44个实例(其中涉及 6 篇文献,2 个事件,19 个人物,7 种期刊,8个机构组织,2个地点)。
图3是构建完成的类与类之间的关系图,带箭头的有向线条表示了该本体模型中的对象属性,对象属性的定义域(Domain)和值域(Range)可以从线条的起止方向表示。例如从Figure(人物)类存在有向线条指向Document(文献)类,表示Figure 与Document 之间通过对象属性“Write”连接,即人物(Figure)与文献(Document)存在写作的关系。而对象属性“Write”的值域是“文献(Document)”。

图3 概念与概念之间关系
图4以可视化的方式显示民国文学本体中与“徐志摩”这一人物实例相关的文献、人物等概念,即以人物徐志摩为中心的人物关系,创作关系等。例如徐志摩的人物关系有前妻张幼仪、妻子陆小曼,父亲徐申如,儿子徐积锴。其著有文献《志摩遗稿》,该文献由《新月》杂志出版,而《新月杂志》的出版机构则为新月书店,同时在《徐志摩先生遗著》一文中有提及徐志摩。此实例演示图同时也展示了该本体未来的使用场景之一,便于用户全方位地了解实例信息以及与其他实例的相互关系。
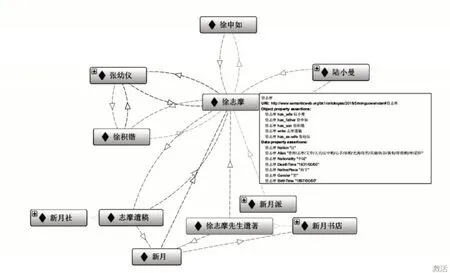
图4 实例演示
最后,建设完成的民国文学本体OWL文档部分片段如下:

3.2 民国文学本体模型的应用方向
民国文学本体模型主要是基于“全国报刊索引中国近代中文期刊全文数据库-文学专题”来设计,最终目的是在该专题数据库中进行语义层面的知识组织和知识挖掘。预期应用场景为对数据库中人物、地点、时间进行可视化的动态显示,揭示人物关系、时空关系、事地联系等;同时对用户检索结果进行语义层面的优化,例如用户检索“眉轩”时,检索结果可同时返回徐志摩相关信息和相关文献,并显示与徐志摩相关的人物关系,以此提升文学专题库的知识服务效果。
目前该本体模型尚处于试验阶段,还未正式投入使用,下一步的工作重心将尝试运用半自动方法为已有本体添加实例,即运用关键词自动抽取,对近代期刊文学专题的OCR 全文进行文本关键词语义信息(人、时、地等)抽取,并添加为实例,以此提升本体构建的工作效率。在这个过程中同时对已经建成的模型做进一步的逻辑检测与推理,以进一步保证民国文学本体的可靠性。另一方面,推动对实例对象属性的关系推理工作,目的在于对目标实例自动赋予相应的对象属性关系,减少本体构建的人工干预程度,加强知识发现机制,挖掘民国文献中潜在的知识关系,提升本体构建项目的自动化和智能化程度。
4 总结与展望
以上是对本体在文史方面应用的一次尝试,初步建立了民国文学本体模型,即揭示了近代期刊文学专题的文献特征和内容特征,能够有效提高近代期刊文学专题资源知识服务的效果,将中国近代的经济政治变化和人文历史变迁以更加清晰的形式展现在读者面前。
