决策树算法引入机械装配技术课程形成性评价的模型构建与测度
2019-03-06郑小龙王丹浓陈丽娜
郑小龙,王丹浓,陈丽娜
(宁波第二技师学院 机械工程系,浙江 宁波 315012)
一、问题的提出
熵原本是一个热力学的概念,用来表征热力学系统内部微粒的混乱程度,熵值越大,系统中微粒分布越不均匀混乱程度越高;反之,越均匀,越有序。1948年,香农提出了信息熵的概念,将热力学中的熵引进到了信息量化度量的问题中,用来表示信息的不确定性。[1]决策树算法是在信息熵的基础上,对数据处理的一种方法,其本质是在系统的多个变量属性中,找到对结果而言可分辨能力最大的属性,将数据分成若干子集,对应即决策树的分支,然后循环以上分支过程,直到子集中对应的结果属性统一为止。[2-7]该算法也是目前机器学习进行数据挖掘的一种重要手段。
本文以机械装配技术课为研究对象,该课程的特征在于教学评价重点不仅在于结果性评价,还在于整个装配和精度调整过程的规范性和工艺性,所以评价过程是一个形成性评价与结果性评价的综合。结果性评价比较直观,可通过有无零件遗漏、设备流畅性、检测精度等方法来完成。形成性评价是教师观察中间过程是否有不规范操作和错误操作,但教师很难将整个班级的形成性评价量化,并找出潜在规律,如学生多项操作都出现错误,错误操作是否有相关性,先纠正哪项错误操作最合理,该判断更多的是根据教师已有经验,所以教师的能力和经验决定着该课程的教学效果。由于该课程的教学评价有相当一部分集中在形成性评价中,因此将信息熵引入到机械装配技术的实训课程中,使每一项操作都有相应的标准操作,即只要出现不规范操作就相当于出现了熵增。并且,通过计算熵值来确定某项操作的混乱度,从而对教学评价起到量化作用,避免了教师对整个班级大样本的技能操作掌握程度的主观估计。
二、评价过程设计
首先进行采集数据,横坐标第i项操作,纵坐标为第j个小组,得到一个矩阵A:


K=1/Ln(m),当学生只进行一种规范、标准操作时,信息熵最小,混乱程度低;当学生错误操作比较多时,信息熵大,混乱程度高。
在信息熵的基础上计算各项错误操作的熵权:

通过熵权的量化,明确各项错误操作的权重,为学生纠正错误提供数据支持,形成性评分即概率值和熵权的乘积。

再利用决策树ID3算法进行数据挖掘,确定各项错误操作信息增益,探究各项错误操作的前后的关联性和纠正顺序性。

三、模型建立与计算
在机械装配技术课程中,以直线导轨与基准面的平行度为例进行研究,安装前需要将安装面先进行清洗,再将导轨滑块副预安装到安装面上,用螺钉进行预紧,然后在滑块上安装杠杆百分表,测量头对准基准面,如图1所示。滑块沿导轨滑动,通过观察杠杆百分表的值来判断平行度是否达标,如超标,则需要用紫铜棒或者橡皮锤敲击导轨进行调整,最终达到要求得平行度。在笔者任教的机械装配技术课程中,有20位学生,按前期表现均匀分成10组,每组2人,进行直线导轨平行度调整的教学,教学后进行平行度调整测试,结果性评价指标合格为导轨平行度≤0.02mm,调整时间≤5min,即结果性评价为Y,未达标则为N;形成性评价指标设置四项:D1为杠杆百分表判断方向准确率、D2为判断时间长度、D3为调节次数、D4为安装百分表时间。建立表 1,其中,D2、D3、D4因为数值越大,越负面,所以将这三项数值取为负,利用公式(1)、(2)、(3)进行形成性评价计算,结果如表1所示。形成性评价的绝对值越小,该小组形成性评分就越好。
该过程对每个小组目前状态进行量化,特别是各小组在量变的过程中且结果性评价尚未改变,形成性评价的得分就能体现这一变化。根据表1呈现的结果,形成性评价和结果性评价有高度的相关性,即使同样Y或N的结果也有高低之分,可见形成性评价是对结果性评价的有力补充。

图1 导轨滑块副平行度调整

表1 直线导轨平行度调整测试信息熵采样
采样数据被量化后,利用决策树算法采样项目进行数据挖掘。由于决策树的剪枝是针对离散变量进行计算的,如果当变量为连续值时,必须进行离散化,才能进行信息增益大小的判断,即直线导轨平行度各变量优先级的判断。[8]



根据以上的离散化的采样项目集合,将四个采样变量分为进行离散化划分,结果如表2所示。
根据采样项目离散化的结果,将结果代入公式3进行计算,信息增益值的结果如表3所示,表格中信息增益值越大,对应的优先越高。
表3中采样项目信息增益值越大,说明该项被纠正或改进后,结果性评价会更大概率的趋向于统一,也就是能快速降低结果性评价的信息熵,所以信息增益值越大的采样变量应该优先被关注,可以认为是教学中的重点,而在其他的采用变量按照信息增益值大小确定优先级,可以确定为第二、三、四重点,量化知识点,为教学提供支持。
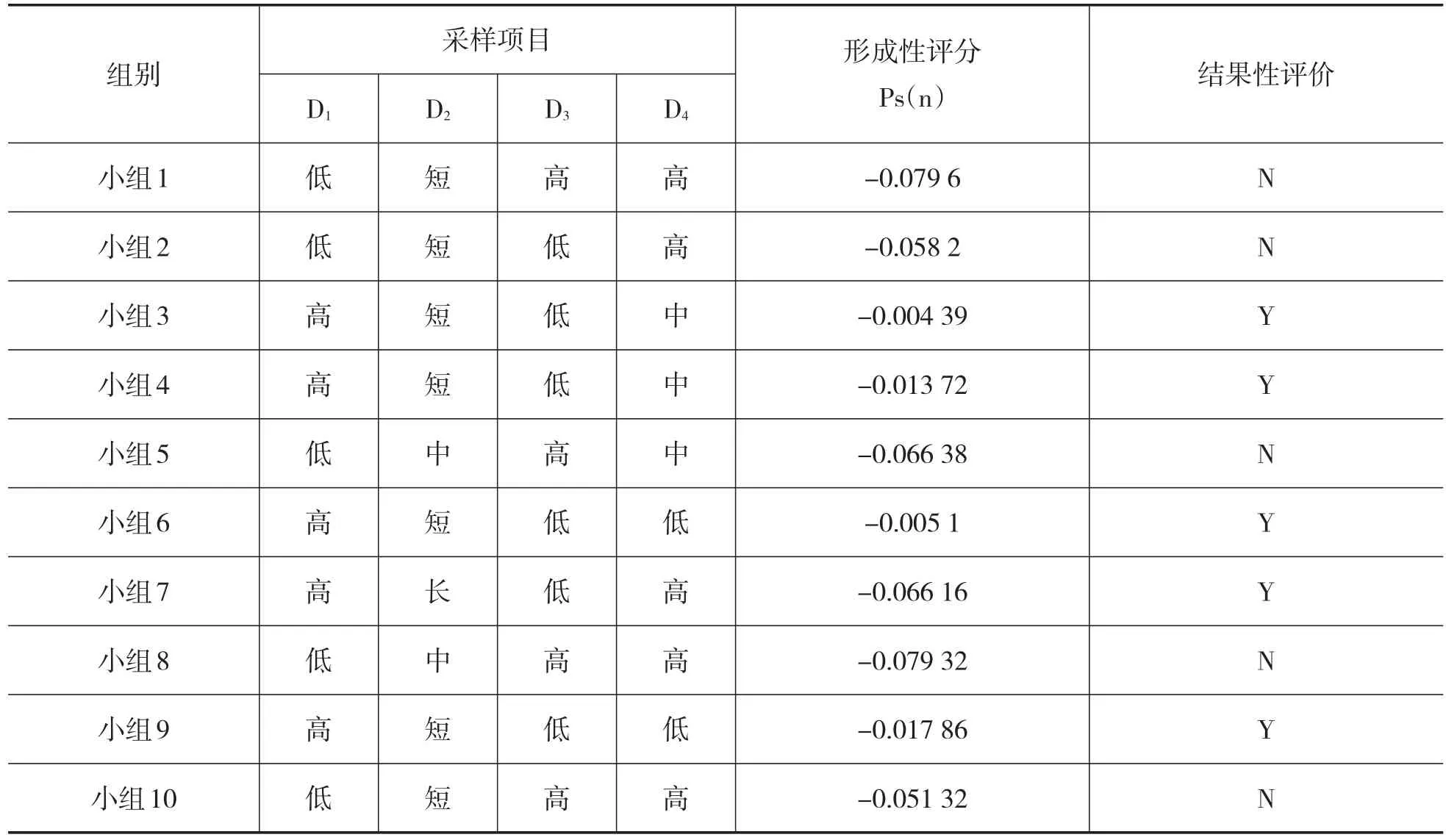
表2 采样项目离散化结果

表3 信息增益值结果
四、结论与展望
按照表3的优先级判断,与教学经验相结合分析得出以下五点结论:(1)由于班级人数和设备有限,D1判向准确率信息增益值出现1的情况,即D1将决策树划分到根节点,D1高对应的结果性评价都是Y,所以决策树图形无法形成,但本次研究只进行信息增益值计算和优先级的判断,已满足研究要求。(2)判向准确率对应能否准确使用杠杆百分表,如果使用错误,无法完成导轨平行度调整,学生可能没有真正掌握杠杆百分表的使用方法。(3)调节次数过多,很大程度是由于导轨调整方向错误导致,另一种情况是铜棒调节力度未掌握到位,致使调节过度,需多次进行调节,此准确性须长时间练习提升。(4)装表时间长短是熟练度导致,初学者在固定杠杆百分表时会将指针顶到极限位置,需重复固定,浪费时间。(5)判向时长也与熟练度相关,但判向的准确率更重要,所以判向时长的信息增益比较小,即相关性较低。
本研究的前提是利用教师经验制定采样项目,教师再利用计算数据辅助教学,两者相辅相成。由于统计数据较小,本方法价值大于结论,如果依托决策树理论,增加数据量,结合机器学习继续实验,可提供更准确、可靠的教学辅助信息。同时,该方法也可为护士、电工、运动员等的规范操作评价提供参考。
