醇胺溶液二氧化碳解吸能力的定量构效关系研究
2019-02-18程静星鲁厚芳岳海荣唐思扬
程静星,鲁厚芳,岳海荣,唐思扬*
(四川大学 化学工程学院,四川 成都 610065)
温室效应是对人类生存环境的严重威胁,CO2是温室气体的主要来源之一,因此控制和减少CO2的排放已成为全世界最具挑战性的问题之一[1]。由于技术成熟,醇胺水溶液的化学吸收方法在工业上被广泛用于CO2捕集[2]。在过去的几十年中研究了各种胺基吸收剂,包括伯胺,仲胺,叔胺和混合型胺,例如伯仲单乙醇胺(MEA)、仲胺二乙醇胺(DEA)和叔胺N-甲基二乙醇胺(MDEA)。然而,这些胺吸收剂吸收过程能耗高[3]。CO2捕集的研究重点是减少CO2捕集过程中的能源消耗,研究表明再生能耗占整个系统能耗的70%左右[4]。降低醇胺解吸过程中消耗的能量是控制整个碳捕集过程能源成本的重要因素,醇胺溶液的解吸能力是影响醇胺解吸能耗的重要因素之一[5]。
醇胺溶液的解吸能力受其分子结构的影响,Xiao等[6]通过研究工业上广泛应用的叔胺结构与CO2吸收/解吸反应中的CO2吸收热量与pKa值之间的关系。研究表明,叔胺解吸CO2的热量,能够通过减少羟乙基的数量来降低再生能耗。虽然胺的结构被证实能够影响CO2的解吸过程,但其分子结构与解吸行为之间的定量关系仍不清楚。
定量结构性质/活性关系(QSPR/QSAR)方法是一种利用数学统计工具在微观分子结构与宏观理化性质之间建立预测模型的方法,能够用于预测未知分子结构的目标理化性质并指导设计新型分子。通过对QSAR模型的分析,能够进一步探究影响宏观性质的重要结构因素[7]。定量构效研究与CO2捕集技术的首次结合由Momeni[8]等人进行。研究利用23种胺类CO2吸收剂建立了多元线性回归-遗传算法模型,并确定了影响胺吸收CO2能力的主要参数。 但不足的是,模型中使用的描述符仅限于伯胺基团数量(n(RNH2))和仲胺基团数量(n(RNHR)),而且23种胺中有10种是多胺,对于胺的利用率探究不足。
本研究利用定量构效方法对21种醇胺水溶液的解吸能力建立预测模型。使用遗传函数逼近与人工神经网络算法建立模型并对比,利用内外部验证方法对模型预测性、可靠性进行验证。通过对预测模型的解释,进一步分析影响醇胺水溶液解吸能力的结构因素。
1 研究方法
1.1 数据集

图1 21种醇胺结构图Fig.1 The structures of 21 alkylolamines

表1 21种醇胺解吸CO2解吸量的实验数据集Table 1 Experimental data set of CO2 desorption capacity of 21 alcoholamines
从文献中[9]提取了21种醇胺溶液对CO2的解吸能力(表示从40℃到70℃的解吸曲线积分),组成定量构效研究的基础数据集(如图1、表1所示)。
数据集中有19个是一元醇胺胺分子结构,2个分子结构均含有2个羟基。其中有6个分子带有环结构,其他则是链烷醇胺。数据集中的所有分子解吸CO2反应的实验条件一致,均是在1h后70℃达到最大解吸量。
1.2 结构优化
本研究采用B3LYP和6-311++G(d,p)基组水平的密度泛函理论(DFT)对数据集中的每个分子进行几何优化,该计算在Gaussian09软件中进行。通过比较每一个分子的多种异构体分子能量,根据最低能量原则,选择其中具有最低的分子能量和最稳定的构型作为进行下一步计算的分子结构[10]。
1.3 描述符提取与筛选
将每个分子几何优化后的结构被放入Material Studio 8.0的QSAR模块,进行相关描述符的提取,完成将化学结构转换成适合于计算的数值描述符的过程,并得到每个分子249个描述符,这些描述符分为以下几大类:组成描述符、拓扑描述符、官能团计数、空间类描述符、热力学描述符等。由于分子描述符数据数量过大,可能导致建模的缓慢及不精确,因此在对每个分子的描述符进行筛选,以减少每个胺分子的计算描述符的数量:
(1)消除了描述符矩阵中的零值,然后去除数据集中的所有分子具有相同或接近相同数值、恒定的常数。
(2)对于两个共线描述符,排除了其中相关系数>0.95的共线描述符,保留另一个描述符[8]。
通过上述操作,每个分子共留下131个描述符,由此组成21个分子×131个描述符的数值矩阵。
1.4 QSAR建模及验证
对醇胺分子解吸能力的定量构效研究,采用用遗传函数逼近(GFA)算法和人工神经网络(ANN)在Material Studio 8.0软件的QSAR模块中建立数学模型。ANN用于生成从GFA获得的描述符之间定量的结构-活性/性质关系(QSAR)的预测模型[11]。
对于所有醇胺体系解吸能力预测模型的建立,通过QSAR方法的内部及外部验证进行考察。根据平方回归系数(R2)以及Fisher检验评估QSAR模型的质量。内部验证采用留一交叉验证(Rcv2)进行。
2 结果与讨论
2.1 GFA与ANN建模方法对比
整个数据集被分为训练集与测试集,其中17个醇胺结构作为训练集,4个醇胺结构作为测试集。分别将两种解吸量形式y与Y作为因变量,用醇胺结构提取并筛选后的描述符作为自变量,使用GFA与ANN方法建立数学函数关系。GFA方法与ANN建模的结果对比如表2所示。
关于如何认识和把握哲学社会科学的地位、作用及其发展规律这个问题,这是一个重要而复杂的方法论问题,但是学术界远远没有引起足够的重视。在有关社会科学的综合性研究中,如社会科学史、社会科学方法论、社会科学,仍然不被看作专门的学术领域,甚至可以说,远不如自然科学史、科学技术哲学、科学技术社会学或科学知识社会学那样引起学术界的广泛重视。乐观的是,伴随着社会科学的发展,目前我国社会科学内部的方法论意识日益增长,社会科学的科学性与实践性、本土化与国际化等,正成为经济学、社会学和政治学等社会科学激烈讨论的问题
从表2可以看出,反应前的醇胺结构提取分子描述符,综合F值、R2、Rcv2的指标,表明以y建模结果最佳,F值、R2与Rcv2均高于Y。
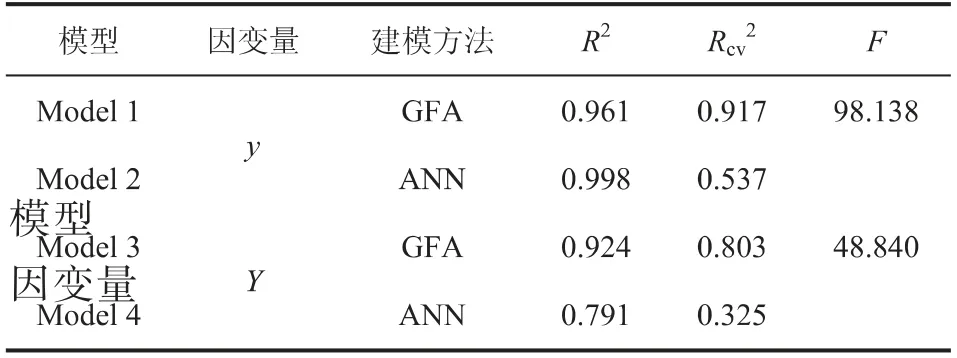
表2 使用GFA与ANN方法建立的解吸能力QSAR模型对比Table 2 QSAR models established by GFA and ANN methods for desorption capacity
GFA方法的F值、R2、Rcv2均高于ANN方法,ANN方法得到模型的预测性较差(Rcv2<0.6)[12],GFA建模方法更为适用。

图2 两种解吸能力形式y与Y的单变量分析Fig.2 Univariate analysis of two CO2 desorption capacity forms y and Y
对y、Y数据集采用因变量单变量分析,由图2可见,Y的数据分布与正态分布差异较大,这也是模型结果F值小于y数据分布的原因之一。
2.2 不同数据集对比
当分别选取y与Y作为因变量建立QSAR模型时,需要通过考察并对比两种模型的预测值准确性来确定模型。图3表示分别以y和Y为因变量数据、提取反应前胺A结构描述符并建立的模型,使用该模型进行预测与实际实验值的对比。图3可以看出,模型1(A-y)的数据点集相比模型3(A-Y)的分布更贴近y=x线,也就是说模型3的预测值与实验值的差异性要更大。且通过F值与Rcv2的对比,可以看出模型1的显著统计性更好。
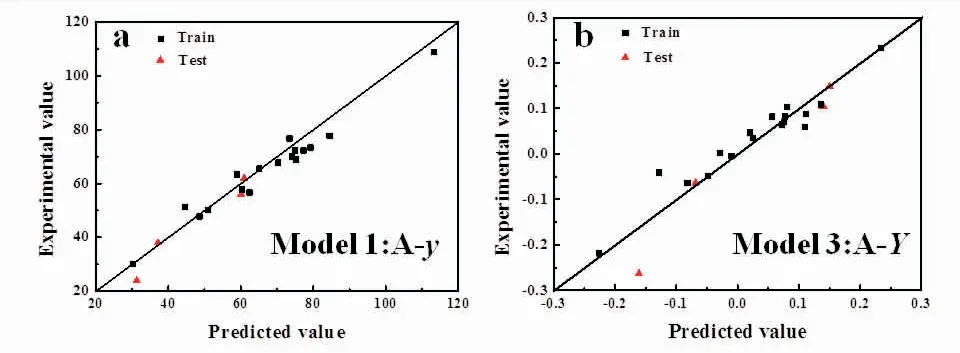
图3 2种解吸能力形式y(a)与Y(b)的模型预测值与实验值对比Fig.3 Predicted and experimental desorption capacities of two models wtih y(a)and Y(b)desorption capacity forms
由于模型3的因变量是通过变换的Y,对比两个模型预测性能的优劣需要还原为对原始解吸能力的预测性能对比。因此将模型3-Y的预测值与实验值对比转换为模型3-y原始数据的预测值-实验值的对比,如图4所示。由图4可以看出,模型3对醇胺解吸能力的预测值/实验值的点集集中分散程度低于模型1的预测点集,说明模型1对醇胺吸收能力的预测准确性较好。

图4 模型1(a)与模型3(b)的y预测值与实验值对比Fig.4 Predicted and experimental desorption capacities of model 1(a)and model 3(b)with desorption capacity y
因此,可以确定结构A作为提取描述符的目标结构、以y数据分布作为因变量、以GFA方法进行建模的模型1作为最佳预测模型。
2.3 不同变量模型对比
由于QSAR方法要求样本集个数是描述符个数的3~5倍[12],需要考察描述符个数对建模结果的影响。如表3所示,列出了模型不同变量数的结果对比。

表3 不同变量的模型对比Table 3 Comparison of models with different variables
如表3所示,当模型变量数n从2增大到4,其模型的R2、Rcv2与F值随之升高;当模型变量4增大到5,Rcv2下降而R2与F值升高得不多,表明n=4是模型最佳的变量数。
2.4 模型解释
可以确定的QSAR模型是以胺结构A作为目标对象、y数据分布为因变量的GFA模型(A-y-GFA:Model 1),其方程如下:

第一个描述符AlogP是一种热力学描述符。logP表示辛醇/水分配系数,用于描述分子的疏水特性,从分子结构计算logP基于分子片段和原子贡献的取代加成性,并考虑分子表面积、分子性质和溶剂化变色参数等因素。这是由Hansch[13]等人开发的计算方法,AlogP在总结的分子的片段常数之后,用于片段之间的分子内相互作用,例如电子、空间或氢键效应作为任何必要的校正因子添加在计算过程中,是一个综合了分子结构状态的描述符。
第二个描述符Subgraph counts(2):path是分子连接指数,表示分子结构的连接状态,包括其分子是否有分支,支链形状等结构信息。表4列出了Subgraph描述符的几种类型。
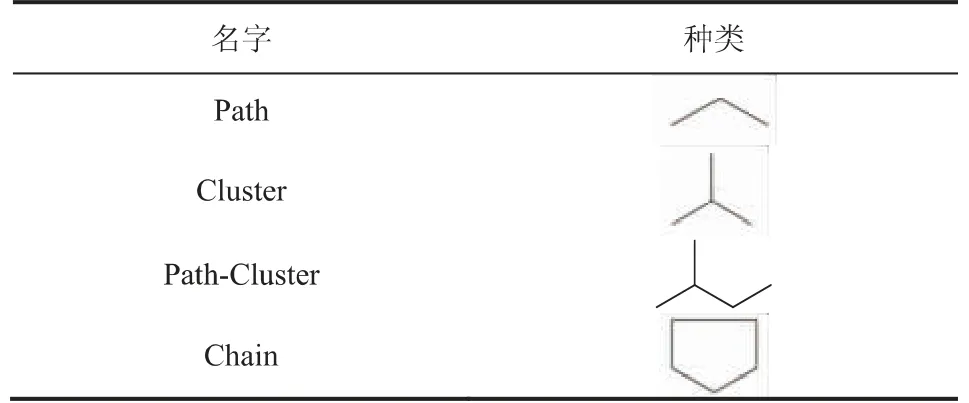
表4 分子连接指数描述符Subgraph的种类Table 4 Type of molecular connection index descriptor Subgraph
第三个描述符the number of OH是官能团计数类描述符,表示分子结构中羟基的数量。这个描述符在描述胺/水溶液吸收CO2能力的模型中也出现过。模型显示,当羟基数量增多,其解吸能力随之下降。
第四个描述符Bond energy是能量类型描述符,是指MS中Forcite模块中计算的键能能量(系统价能的键合拉伸组分,单位为kJ/mol)。模型显示,键能越大,其解吸能力越大。
2.5 最佳模型验证
为了保证确定模型Model 1的可靠性,本研究使用内部验证与外部验证进行考察。内部验证通过对比回归系数(R2),交叉验证系数(Rcv2)、Fisher函数(F)参数进行,外部验证使用模型Model 1对未参加模型建立的测试集进行预测,通过对比其模型预测值与实际实验值来考察其预测性能的可靠性。
如表5中模型1所示,所有数据集的结果表明该模型具有预测性(Rcv2>0.6),统计学显著性意义F值达到了98,表明其解吸能力的模型预测性是稳健的。且测试集、训练集、整体数据集均是Rcv2>0.6,表明其模型的预测性是有效可靠的。
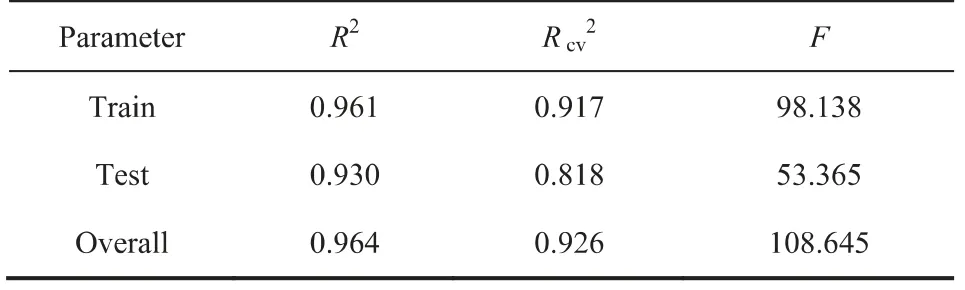
表5 模型1的数学验证相关参数Table 5 Validation of statistical results for model 1

图5 模型1的解吸量(a)、残值(b)的预测值与实验值对比Fig.5 Predicted and experimental desorption capacities(a)and residual values(b)of model 1
为了进一步考察确定的模型1的预测性,将模型1的模型预测值与实际值进行对比,同时对比预测值与实验值之差(即残值))。如图5所示,红色表示用于检测训练集建模的测试集,其不参与建模。由图5a可以看出,解吸能力因变量的测试集均匀地分布在拟合线(y=x)周围,显示其预测性能良好。由图5b可以看出,模型1的预测残值大部分集中在±6区域,其平均误差范围在±5%~±30%内,表示其预测的准确性良好。
3 结论
本文对21种醇胺溶液体系的解吸能力进行了定量构效研究,并对建立的QSAR模型进行了描述符解释与预测性考察。首先,分别对GFA与ANN不同算法、不同数据集分布、不同变量数进行了充分的探讨,最终确定使用GFA算法、y分布数据集、4个变量数进行预测模型的建立。通过内外模型验证确认了醇胺体系对解吸能力的模型具有良好好的预测性、稳健性。模型表明,减少羟基数量、加强分子键能,能够增强醇胺溶液对CO2的解吸能力。同时,热力学描述符、分子连接指数描述符是影响醇胺体系CO2解吸能力的重要结构因素。研究显示,定量构效研究发展在CO2捕集技术具有良好的适用性,对模型描述符的进一步分析能用于指导新型醇胺吸收剂的设计。
