基于属性平衡正则化的深度零样本学习
2018-10-24吴凡王康
吴 凡 王 康
(复旦大学计算机科学技术学院上海市智能信息处理重点实验室 上海 200433)
0 引 言
随着社交媒体及数字采集设备的普及,网络上存在着海量的视频及图像数据。然而这些数据却面临着数据样本分布不均衡、以及样本无监督等问题,因此如何在样本量不足甚至零样本、以及样本无标注的情况下,充分利用社交媒体中的数据,成为了计算机视觉领域的开放式问题。在一些实际应用中,标注的训练样本可能无法覆盖所有目标类别,如物种识别[1]、动作识别[2]、异常检测[3]等。零样本学习[3-4]为解决这一类问题提供了一套系统的框架,即利用类的语义信息。这些语义信息,如属性标注,标签词向量等,可以一致地编码成属性向量[5],后者也可称作类嵌入或标签语义嵌入。
零样本学习(ZSL)用可见类的样本训练,学习视觉特征空间到类语义空间的映射,并将这种映射迁移到未见类上[5-6],来进行未见类的分类。
测试阶段,ZSL只考虑对未见类的图像进行分类,这需要假定测试样本均来自未见类,而不含可见类样本。然而,在实际应用中,一个专门的图像识别系统通常需要对那一领域的所有类的新图像进行分类,包括未见类和可见类。这个问题可以被泛化零样本学习GZSL(Generalized Zero-shot Learning)解决。图1展示了ZSL和GZSL任务的情况。

图1 零样本学习ZSL和GZSL示意图
现有的主流ZSL模型[7]可分为以下3类:
1) 学习一个图像特征和类嵌入之间的适配性函数,将ZSL的分类看作是一个适配分数排序问题[4,8-9]。这类方法提供了建立两者联系的通用框架,但也有以下问题:属性标注是单点标注(pointwise)而非成对标注(pairwise),排序失去了绝对距离信息;适配性分数没有上界;基于固定间隔的排序学习不到一些语义结构。
2) 将视觉特征和语义嵌入投影到一个公共的空间,将ZSL的学习问题看作一个脊回归。这个公共空间可以是视觉空间、语义空间、或者两者的共享空间。这类方法的预测过程是一个高维空间的近邻搜索,可能会导致中心化问题(hubness problems)[10]。
3) 文献[11]通过对神经网络最后一层全连接施加一个语义一致正则化来实现基于可见类属性矩阵的端到端的训练。这一工作为端到端ZSL模型提供了一个新的思路,但该方法没有考虑以下几点:(1) 不同属性对分类判别的帮助是不同的; (2) 可见类与未见类的属性关联以及未见类的属性与训练样本特征之间的关系。
为了克服现有方法的问题,本文提出了一种基于属性平衡正则化的深度零样本学习框架ABN(Attribute Balancing Network)。本文主要贡献有:1) 提出了一种简单可扩展的端到端零样本学习框架ABN;2) 针对ABN训练中的问题,针对性地设计了一个属性平衡的正则化约束,并结合现有工作给出了理论上的分析;3) 在主流视觉属性数据集的ZSL和GZSL任务上进行了大量实验,实验结果达到了当前最高的水平,验证了我们方法的有效性。
1 基于属性平衡正则化的零样本学习
1.1 问题定义
零样本学习任务中,有ns个可见类别和nt个未见类别(上标分别表示源source和目标target,与迁移学习一致),总共n=ns+nt个不同的类别。在可见类别空间上,给定N个标注样本的训练集Ds={(Ii,yi),i=1,…,N},其中Ii是第i个训练样本的图像,yi是其对应标签。给定类别属性矩阵A,其中As∈Ra×ns对应可见类别,At∈Ra×nt对应未见类别,a表示属性特征的维度。

1.2 端到端零样本学习框架ABN
现有的ZSL方法已经实现了语义特征约束[11]、语义特征和视觉特征一起端到端训练、多语义特征融合[5]等目标。但是当前最佳的端到端方案,存在以下问题:1) 可见类强关联的属性有足够正样本监督,但未见类关联属性正样本监督相对不足,导致各属性间不平衡,不利于提高ZSL测试准确率;2) 对属性分类准确的依赖很大,ZSL会因为域漂移[12](同一属性在已见类和未见类图片上视觉表现有显著差异)而准确率降低。
针对上述问题,本文提出了一种基于属性平衡正则化的端到端零样本学习框架ABN。如图2所示。
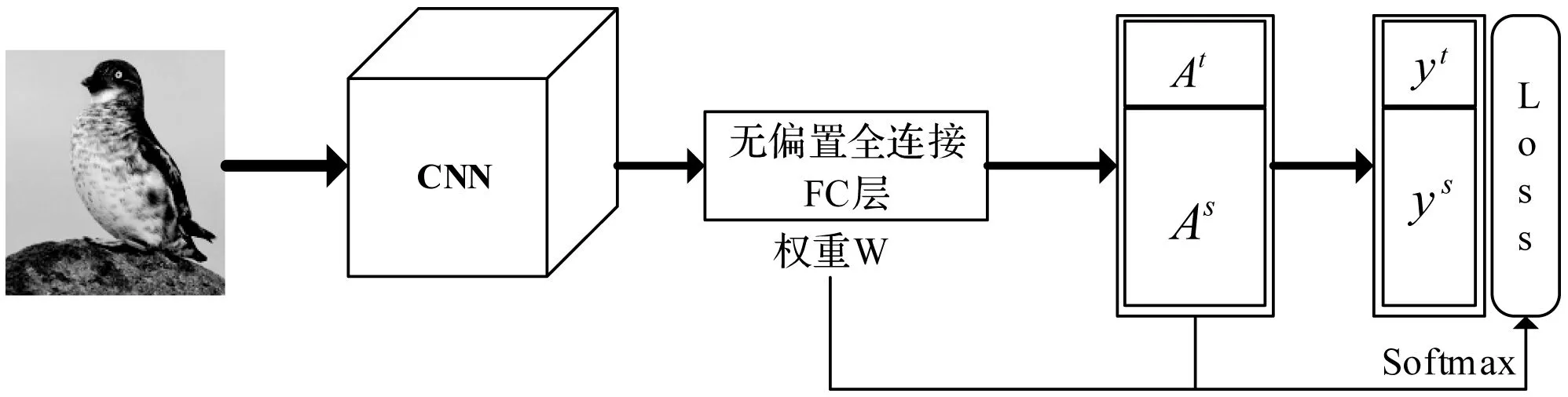
图2 属性平衡网络ABN框架图
ABN零样本学习框架依次包含以下几个模块:
1) CNN模块x=CNN(I)。用在ImageNet2012数据集预训练好的CNN网络,去掉最后一个全连接层,作为图像特征提取器。为了比较方法的一致性,本文实验中均以预训练好的resnet50为例。这一层将输出瓶颈特征(即高级图像特征,这里是df=2 048维)。
2) 全连接FC层xt=WTx。这一全连接FC层将图像的CNN特征x映射到a维的“属性”空间。在端到端的训练收敛后,这一层的输出可以看作是图像在各属性上的评分。由于主要目标是提高在未见类图像上的准确率,因此这一层不带非线性激活和偏置,使得神经网络尽可能训练学到更好的视觉属性的表达。
3) 类语义迁移层y*=softmax(ATxt)。其中AT是全体类别属性矩阵A的转置,矩阵维度为n×a。这一层可以看作是一个固定权重的无偏置全连接层,其权重设定为全体类别属性矩阵A。训练过程让y*尽可能地逼近真实标注对应的one-hot向量,这样就充分考虑了不同类的相对关系。
4) 损失函数层 由于前面的类语义迁移层相当于一个带softmax的全连接层,该网络依旧等价于一个经典的CNN分类网络,考虑采用交叉熵损失:
q(y*,ytrue)=-ytrue·log(y*)
(1)
由于训练过程可见类强关联的属性会有较多的正样本监督,随着训练进行,他们的关联强度会不断加强,因此需要对这些关联的权重做一些约束。总的损失函数L为:

(2)
1.3 与现有方法的联系和区别
受文献[13]中映射可重构性的启发,这里给出可重构性约束的ZSL目标函数如下:
(3)
式中:Xi是第i个样本的视觉特征,Ai是该样本标注类别对应的属性向量。由于Ai固定,上式可转化为:
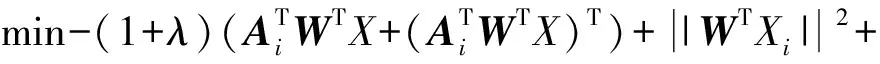
(4)
在我们的ABN框架下,正好有:
yi=softmax(ATWTX)i
(5)

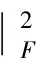
(6)
这与我们上一节的损失函数完全一致。这也从理论上解释了我们的属性平衡约束的合理性。
1.4 泛化零样本学习与新类检测机制
GZSL任务与ZSL类似,只是测试集样本和测试的分类域都扩大到了全体类。现有的ZSL方法,大多基于样本特征与标签嵌入向量的适配度函数(或距离),都可以直接用到GZSL上。但由于训练集只有可见类样本,直接应用到GZSL上的方法都会面临大量未见类样本被分到可见类中。经分析有以下几种角度解决这一问题:
1) 建立类似离群点检测的新类样本检测机制,若测试样本检测为新类,在加入到ZSL分类器中,否则加入到可见类分类器中。这种两步分类的方法优点是可见类和未见类区分后可解释性强,两块的分类准确率也有保障;缺点是计算慢,区分的对待不利于建立可见类和未见类之间的联系。若有部分未见类的图片可加入训练,该方法的性能提升也是局部的而非全局的。
2) 将GZSL看作一个训练集极端不平衡的问题(可见:未见=∞)。通过改进损失函数,借用类属性矩阵As和At,在训练阶段借用A将属性上表达值传递到未见类,在测试阶段对At部分做增强。
我们ABN模型中的属性平衡正则项,起到了对As部分的约束,也有利于GZSL的准确率提高。但是,测试时可见类输出依旧会大于未见类,为了保证相对高的GZSL准确率,设置一个阈值γ(一般γ>1)。当可见类与未见类中最高概率比超过这个阈值γ时取可见类中最匹配类,若未超过,则意味着检测到未见类,故在未见类中取最匹配类为预测结果。预测类c为:
2 实验分析
本文基于pyTorch[14]框架实现了ABN网络,并在三大主流视觉属性数据集上进行实验。实验环境是一台拥有8张12 GB显存的Titan Xp和8块32 GB的CPU内存的Ubuntu服务器。
2.1 数据集配置
对ZSL和GZSL问题,我们参照文献[7]的规范,选取了3个各具特点且有公开原始图片方便端到端训练的数据集,即SUN[15],AWA2[7],CUB[16]等属性数据集。3个数据集基本信息如表1所示。

表1 属性数据集统计(分割方式同文献[7])
表1中的数据集特点是:SUN类别数多,AWA2单类图片多,CUB属性个数多。
2.2 实验配置
如未特殊声明,本文实验均采用resnet50[17]作为CNN模块,其最上层Pooling层输出特征维度是D=1 024。该CNN在ILSVRC2012的1 000分类数据上预训练好[14],top-1错误率为23.85%。所有输入图片大小均调为224×224。正如框架图2所示,训练阶段FC层随机初始化,语义迁移层则权重固定为属性矩阵A,两层均无偏置项。测试阶段ZSL则将语义迁移层权重设为At,GZSL则为A并加上新类检测机制。
新类检测阈值γ一般根据实际数据集训练情况选取。如果训练类的每类样本数量多,意味着已见类影响远大于未见类,需要设置较大的γ。在属性平衡正则化因子λ取0.1的情况下,本文3个数据集γ均取1.4。
训练主要分为两个阶段:
1) 前3个epoch:由于CNN模块已经预训练好来提取ImageNet通用的视觉特征,可将CNN模块参数冻结,用Adam优化训练全连接FC层。
2) 全局训练:这一阶段训练层数复杂,因此采用简单的SGD优化,学习率为0.001,逐渐减小,minibatch大小为32。ZSL任务需要严格防止过拟合,为了提高泛化能力,权值衰减因子β设为0.005,且采取提前终止(early stopping)策略。
2.3 实验结果
为了更好地对比和分析,我们按ABN网络训练,并在每一个训练周期(epoch)对模型进行ZSL/GZSL测试。图3、图4分别表示了训练过程中CUB和SUN数据集上ZSL/GZSL准确率的变化。图中Training-ACC表示在训练集上的分类准确率,val表示在可见类验证集上的分类准确率,ZSL表示在未见类测试集上的ZSL准确率。tr、ts、H为GZSL指标,其中tr表示在可见类测试集上准确率,ts表示在未见类测试集上的GZSL准确率,H为tr和ts的调和平均数。
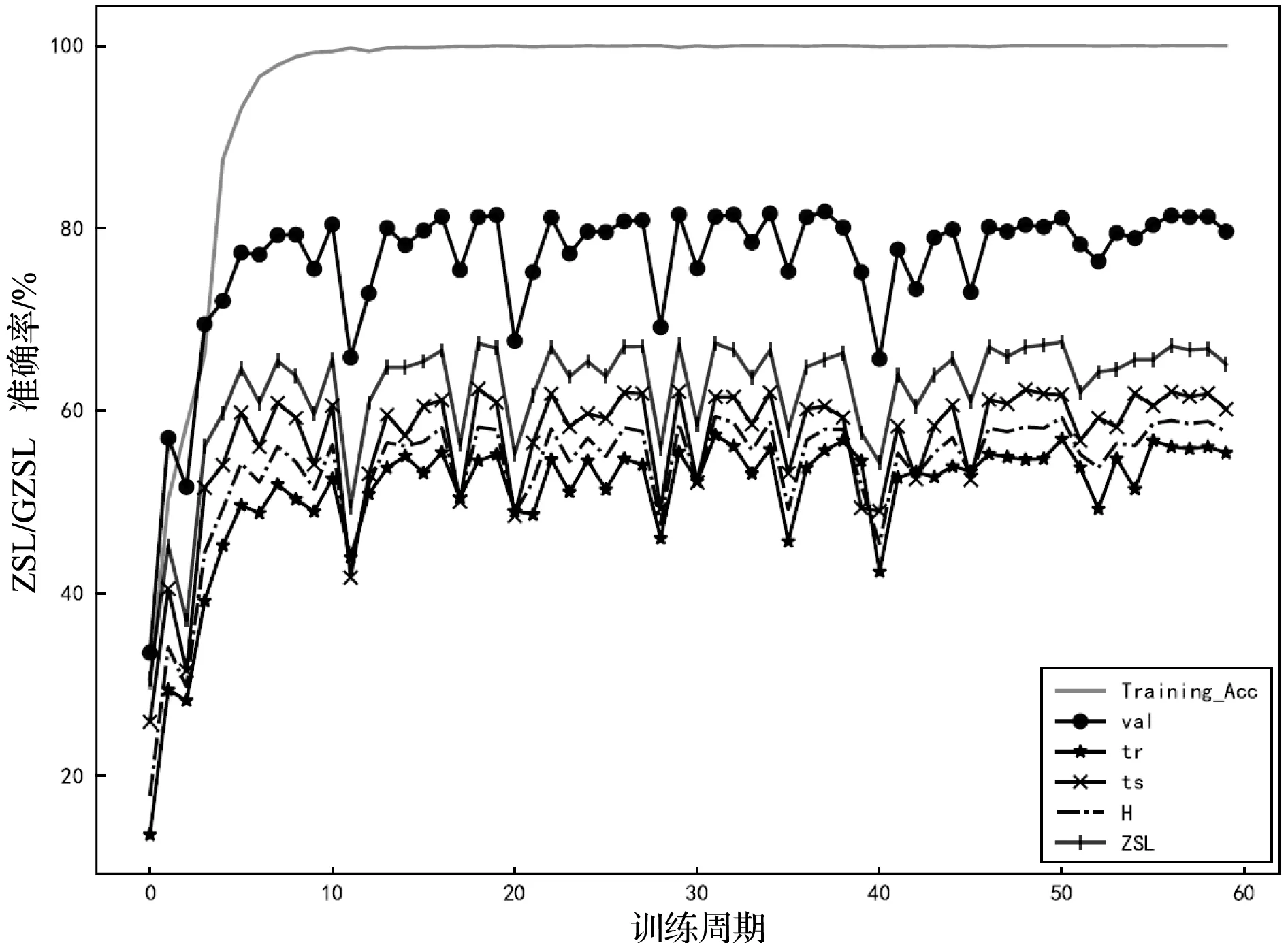
图3 训练过程中CUB数据集上ZSL/GZSL准确率的变化
分析图3和图4可知:
1) ZSL/GZSL测试集各项指标的波动情况与val保持一致,这是因为当val增加时,表示神经网络学到了更好的图像表示和属性评分,从而在ZSL测试中也能有提高。这一现象告诉我们,在实际的零样本学习任务中,可以借助可见类验证集的准确率来选择合适的ZSL模型。
2) 随着训练进行ZSL准确率一开始迅速提高,之后会在一定值附近出现较大波动。这是因为ZSL的训练集可以看作一个极端不平衡的数据集,未见类的样本不参加训练,属性平衡正则项有效地约束了可见类的过拟合现象,但也避免不了出现偶尔的大幅波动。因此,在ZSL实际应用中,建议保存训练过程中每一个val极大值的模型参数,然后综合选择合适的最终模型参数。
我们参照文献[7]将ABN的ZSL结果与最新文献中的结果进行对比,如表2所示。

表2 不同方法在3个数据集上的ZSL结果对比
为了合理对比,我们在同一个预训练模型resnet50上复现了Deep-SCoRe和DEM的结果。表2结果表明,我们提出的ABN模型在3个视觉属性数据集上,都达到了当前的最好水平,且λ=0.1的属性平衡约束对ZSL准确率在3个数据集上都有一定提高,而且远远超过了已有的深度ZSL方法。
同文献[7]的数据集设置,在GZSL任务上不同方法的实验结果如表3和表4所示。
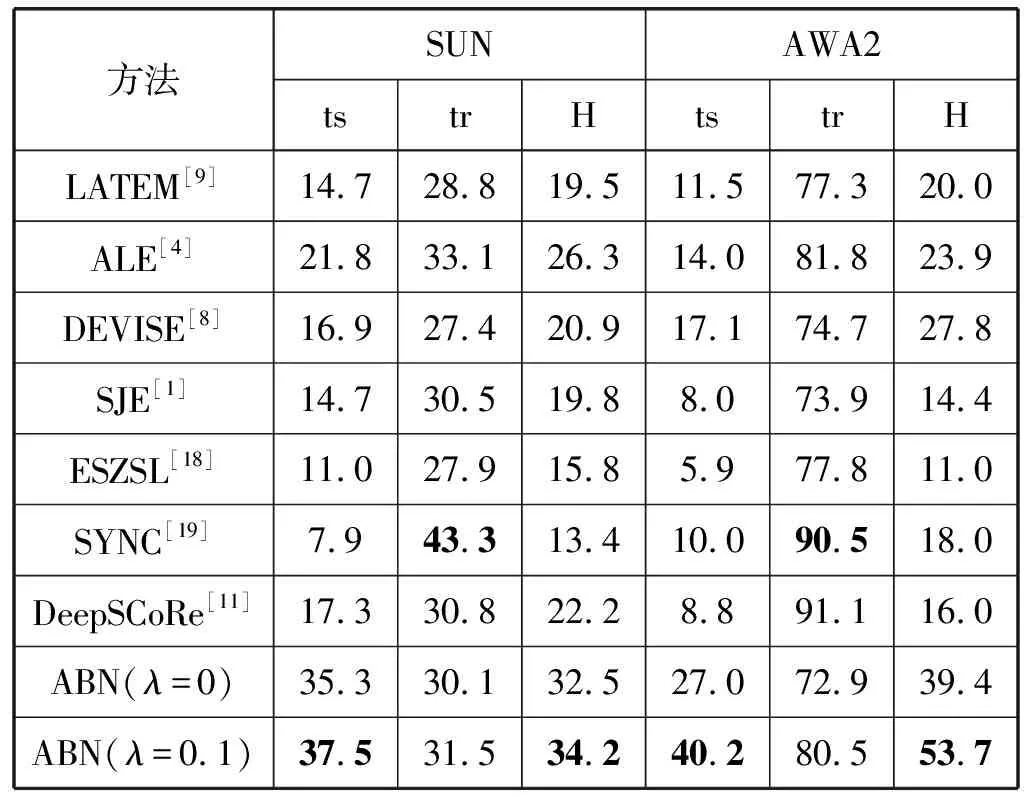
表3 不同方法在SUN和AWA2上的GZSL结果对比
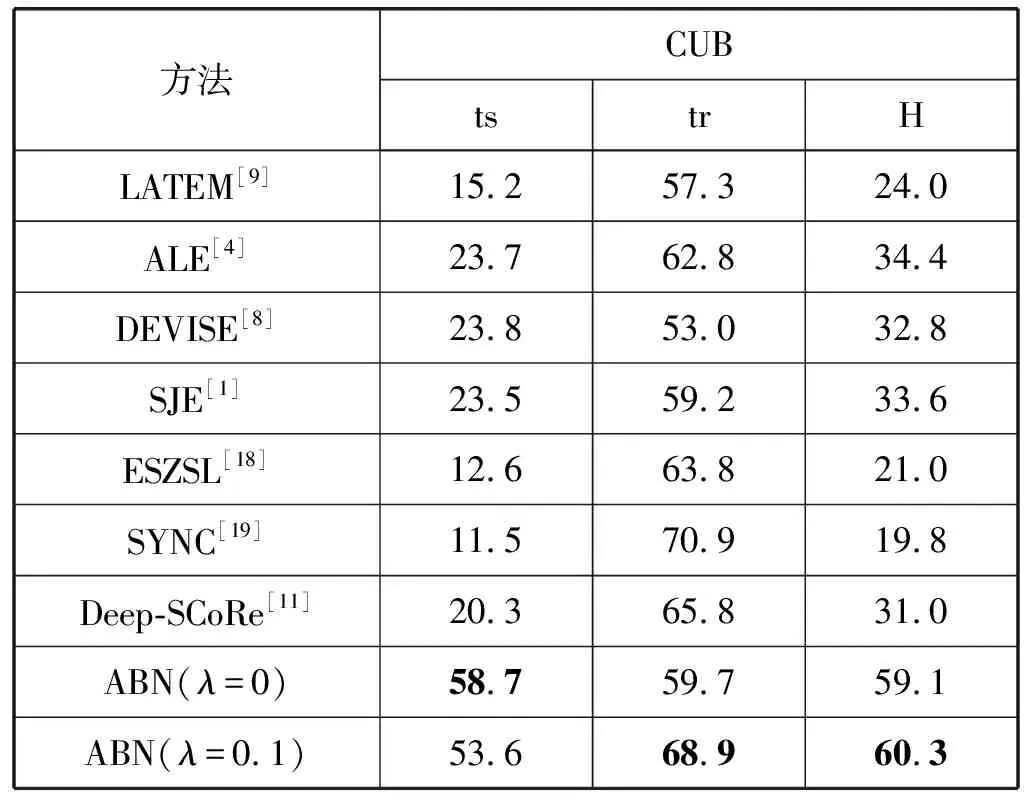
表4 不同方法在CUB上的GZSL结果对比
表3和表4结果表明,我们提出的ABN模型对GZSL的各项指标,均有非常大的提升,其中λ=0.1的属性平衡约束起了非常大的作用。这表明在GZSL训练中添加属性平衡约束,能够很有效地避免过拟合,引导神经网络学到更全面的图像与各类别属性之间的关联。
3 结 语
我们提出的基于属性平衡正则化的深度零样本学习框架ABN,在ZSL和GZSL任务上均取得了当前最好的结果,尤其是在GZSL任务上,相对于不带属性平衡约束,准确率有了非常大的提升。而且ABN框架简单,便于实现和扩展,而且可以很方便地改进为在线学习的框架,以应用于实际场景中。
