一种面向中文分词的搜索算法
2018-10-24张天皓
张 天 皓
(复旦大学计算机科学技术学院 上海 201203)(上海视频技术与系统工程研究中心 上海 201203)
0 引 言
当今社会是个信息爆炸的时代,面对数之不尽的信息,如何快速精确定位用户想要的信息是最迫切的需求之一。能够完成这个任务的正是搜索引擎,搜索最常见的形式是文本搜索。现在除全文搜索引擎外,针对特定领域的垂直搜索的需求也越来越大。在特定领域,由于资源的种类有局限性,搜索的条件能做到十分明确,另外数据集的大小也局限在一定范围内。在这些前提下,可以对搜索引擎做出很多有针对性的优化。目前汉语使用者越来越多,一些特定领域甚至只面向汉语用户,针对汉语的特性定制搜索引擎以提供高效友好的服务也是搜索引擎的发展趋势。本文提出了一个基于后缀树的搜索算法,能够适应中文场景和域搜索。针对垂直搜索引擎面向的数据规模和特点优化了其时间和空间效率。
1 相关工作
后缀树(suffix tree)是一种数据结构,是PAT树的一种,经常被运用在字符串匹配等字符串相关的问题中。其概念最早由Weiner[1]于1973年提出。后由文献[2-3]对其构造进行大幅简化完善。Farach[4]于1997年提出了对于任何字母表都最优的后缀树的构建算法。该算法成为了此后构建后缀树和后缀数组的新算法的基础。
广义后缀树是对应一系列字符串的后缀树。对于一组字符串集合D=S_1,S_2,…,S_d,总长度为n,该集合对应的广义后缀树即为包含n个后缀的后缀树。广义后缀树最常被用于生物信息学。
倒排索引(inverted index)[5]是一种索引结构。它存储了从内容(单词或者数字)到其在数据库或文档中的位置的一个映射。因其与正排索引恰好相对(正排索引存储了从文档到内容的一个映射),所以被称为倒排索引。倒排索引被广泛应用在快速全文检索中,是文档检索系统中最常见的索引结构。
中文分词[6]是中文自然语言处理中的关键技术之一,其概念于20世纪80年代被提出。时至今日,中文分词技术可以大体分为如下三种类别:基于词典的分词方法、基于统计的分词方法和基于理解的分词方法。
数据压缩指的是将数据以另一种形式编码,使其比原本的表示方法占用更少的比特数的操作。使用数据压缩技术缓解存储原件的压力十分必要。压缩后的索引占用内存也会下降,能提高CPU的缓存命中率,加快搜索速度。
在索引结构中,整数序列是常用的数据结构。整数的压缩算法[7]一般分为以下几类:variable bit压缩、variable byte压缩和variable word压缩。Variable bit压缩的主要算法有variable byte code、Unary code、Golomb code、Elias code、Rice等。Variable byte压缩的主要算法有 PForDelta、Interpolative code、AFOR、SIMD-GVB、Group Variable Byte等。Variable word压缩的主要算法有Simple-9、Simple-16等。
2 基于后缀树的中文索引
2.1 基于中文分词改进广义后缀树模型
分词带来的主要影响是搜索结果的排序。不考虑文档热度等额外信息,语义信息是搜索结果排序的主要决定因素,而语义信息很大程度上会体现在分词结果中。
图1为一个广义后缀树的实例,其中$表示分隔符,#表示终止符。在搜索时$会被忽略,分词在数据结构上没有体现出效果。
假设有两篇文档1和文档2,它们的分词结果分别为“交大$学者#”和“复旦$大学#”,其中$为分隔符,#为终止符。对于搜索串“大学”,文档1和2都应出现在搜索结果当中,但是语义角度上文档2中 “大学”的出现更有意义,而文档1中“大学”的出现只是文字上的巧合,并无实际意义,所以在结果中文档2的排序在文档1之前是更加合理的。基于这个观察结果,现将任意字符串的后缀分为两类:好后缀和坏后缀。好后缀为从字符串的开头或者分隔符$后一个字符开始的后缀,坏后缀为剩余所有后缀。对这两种后缀分别建立广义后缀树,分别称作好后缀树和坏后缀树。
图2和图3为好后缀树和坏后缀树的一个实例。将两树拆分后自然而然达到了语义有意义和无意义的搜索结果的排序。从应用上考虑,搜索结果总是被按批请求的,如请求某搜索串的前N个结果。大多数情况下好后缀树给出的结果数就足够应对请求,这时候不必再搜索坏后缀树。由于拆分后好后缀树比原树结构简单很多,搜索好后缀树比原搜索树速度更快,总体的搜索时间效率不降反升。
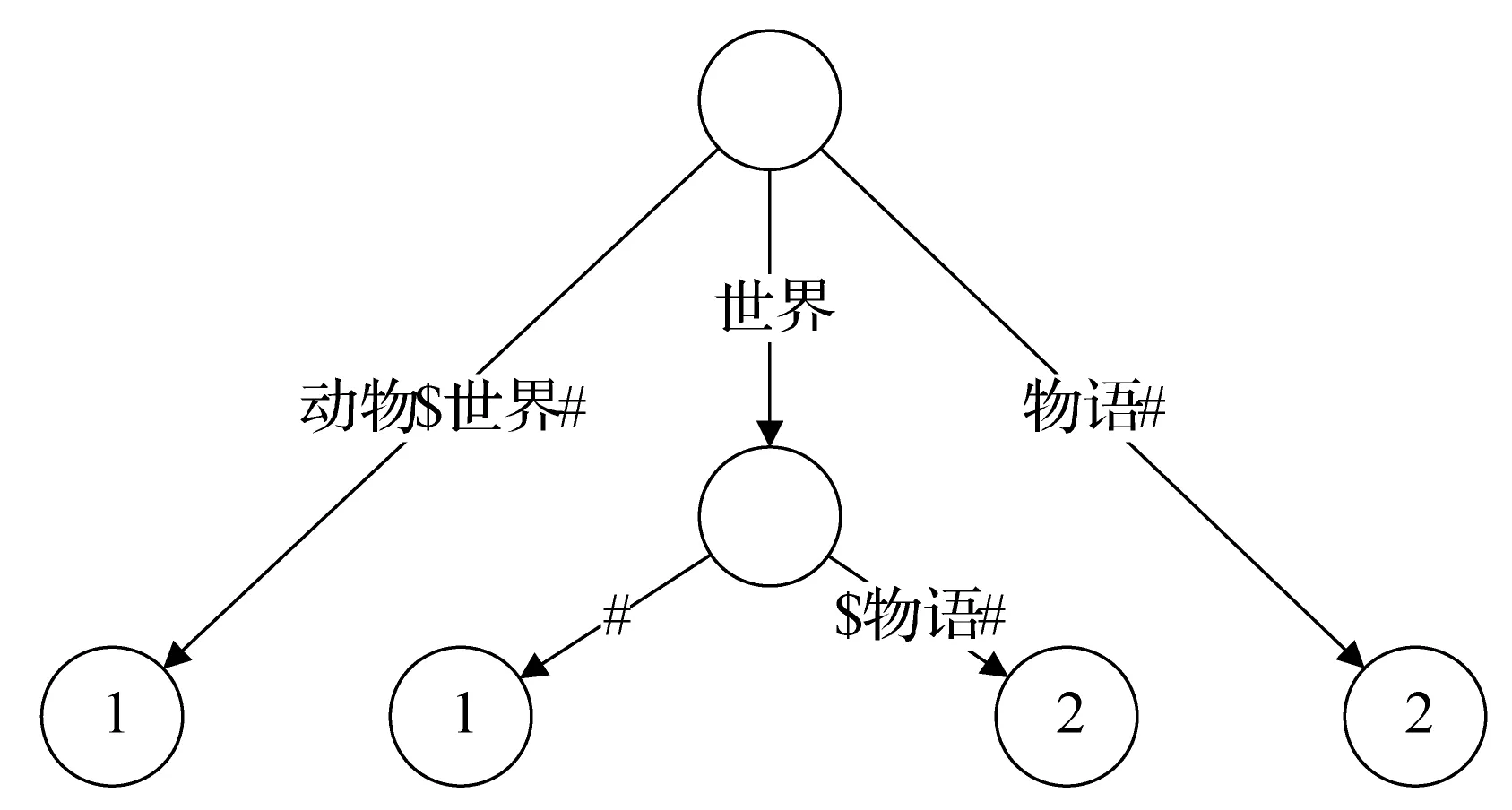
图2 {“动物$世界#”,“世界$物语#”}的好后缀树结构
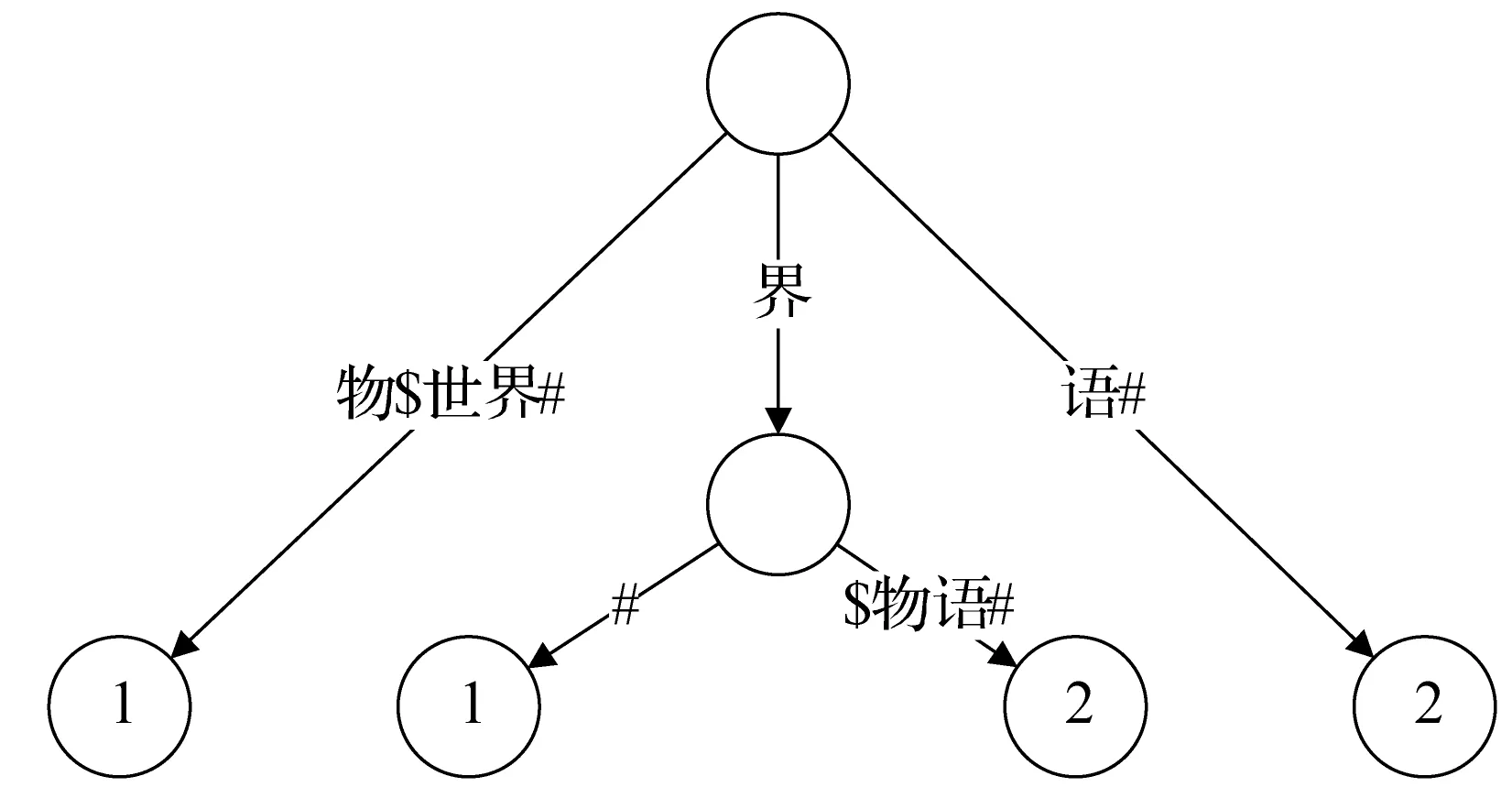
图3 {“动物$世界#”,“世界$物语#”}的坏后缀树结构
2.2 支持域搜索
除了叶子节点外,中间节点也需要记录文档ID。搜索可能最终落在叶子节点或者中间节点上。对于最终落在中间节点的搜索串,因为一定都包含在祖先是该中间节点的所有叶子节点所对应的后缀串中,所以搜索结果集合包含且仅包含这些叶子节点所对应的文档ID。为了快速得到该文档ID集合,在中间节点中记录该节点下的所有叶子节点对应的文档ID的集合。
上述结构有相当多冗余数据,图4是该结构的一个实例。从叶子节点到根节点的路径上都需要记录该叶子节点对应的文档ID。当文档集合增大时,节点的文档ID集合也相应增大,这个现象对于上层节点尤为突出。为了解决该问题,引入如图4所示的结构。

图4 中间节点记录文档ID的广义后缀树结构
文档ID序列包含所有文档ID,初始为空。叶子节点先记录其对应后缀所在的文档ID。后序遍历整棵广义后缀树,对于叶子节点,将其对应的文档ID加入文档ID序列当中。对于其他任何节点,在访问其子节点前记下文档ID序列当前长度S,在访问子节点后也记下文档ID序列当前长度E,则任何节点的文档ID集合就是文档ID序列中下标区间为[S,E)的所有文档ID。
图5是该结构的一个实例。除叶子节点外的所有节点不必记录其对应的所有文档ID集合,只需要记录其对应的所有文档ID集合在文档ID序列中的起止位置,大大降低了索引结构的空间占用。另外,由于文档ID由原来的散落在树状结构的各个位置变成了集中在一个序列当中,可以更有效地对其进行压缩。
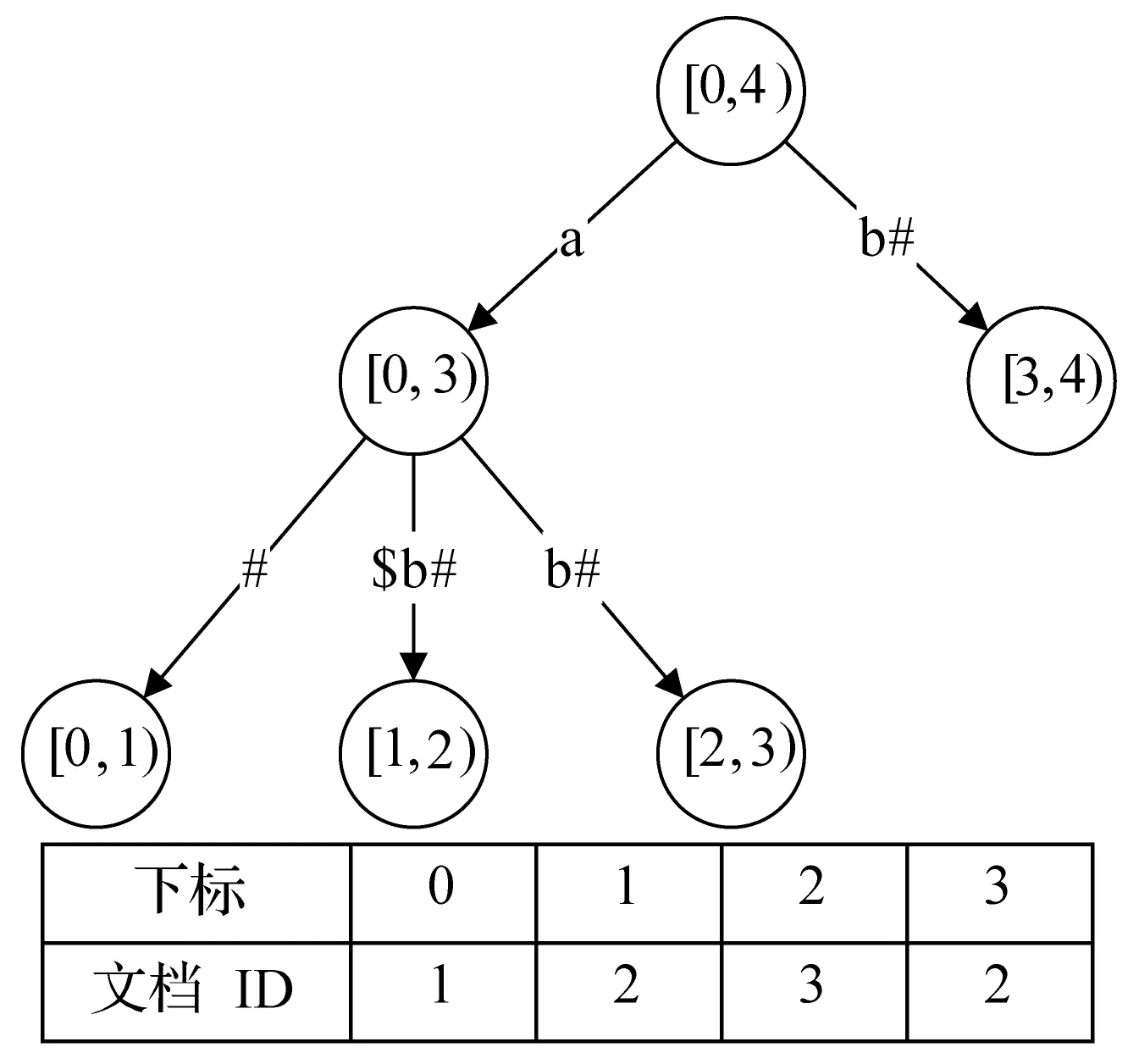
图5 {a#, a$b#, ab#}的文档ID序列结构
域搜索指的是单词本身带有域信息(如属于标题、作者等),在搜索过程中可以指定一个或多个域作为筛选条件,只在符合筛选条件的域中给出搜索结果。在这种情况下,文档中的内容会被划分成多个域,各个域的内容是独立的,在构建索引的过程中,不是将整个文档作为单词加入单词集合,而是将各个域的内容作为单词加入单词集合。为了支持域搜索,在文档ID序列结构的基础上进行改动。
假设总共有n个域,将文档ID序列拆分成n份,每份存储各自域的文档ID,节点存储各个域的起止下标。假设文档1有三个域{1, 2, 3},内容分别为a#、a$b#、ab#,那么仅此文档构建出的上述结构如图6所示。该方案在搜索时只需要将符合域搜索条件的文档ID集合合并,可以直接得到结果文档ID序列。

域1 的文档ID序列

下标0文档ID1
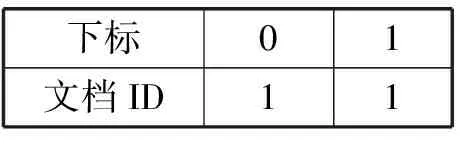
域2的文档ID序列
域3的文档ID序列
图6 支持域搜索的文档ID序列结构
3 广义后缀树索引的压缩
文档ID序列是一个整数序列,压缩使用基于Simple-9和Simple-16的压缩算法。
文献[8]提出了适用于64位的Simple算法(称为SimpleX64)。解决了Simple-9算法适用范围少和浪费存储空间的问题。SimpleX64以长度为64比特的字作为编码解码的最小单位。表1是SimpleX64-16的一种可能的编码方式。
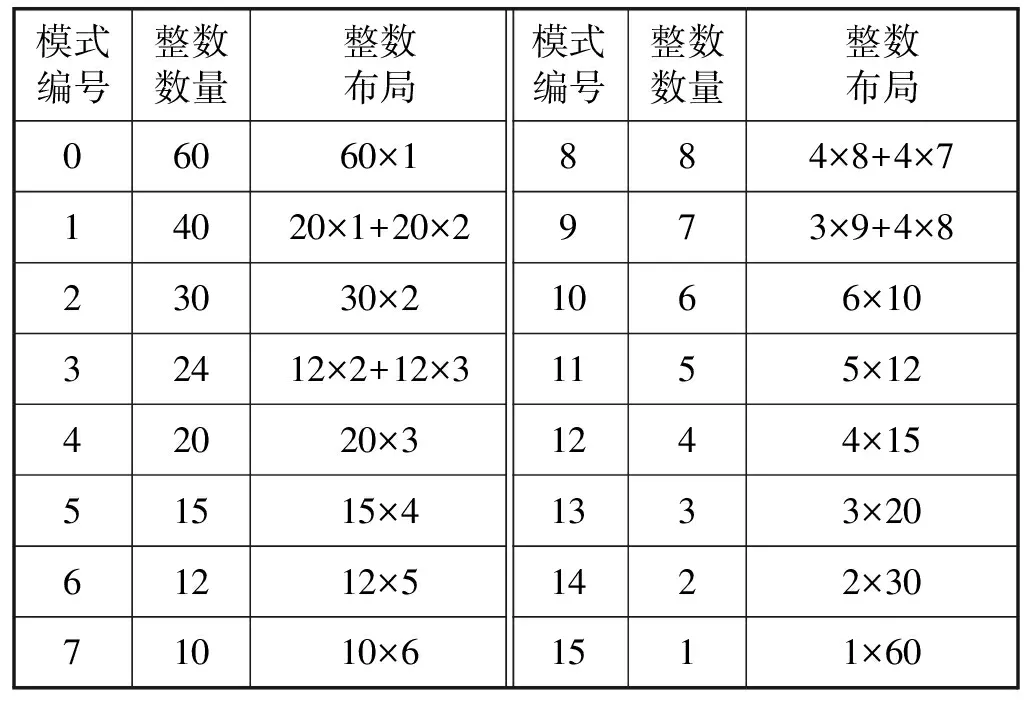
表1 SimpleX64算法的一种实现的各个模式编码方式
表1中一些复杂表达式,如模式1的20×1+20×2的意义为:20个1比特的整数和20个2比特的整数。以整数序列{128, 128, 128, 128, 128, 0, 0, 0}为例,由于128占8字节,所以模式0~7都不适用;由于第5个128也占8个字节,所以模式8也不适用;前7个整数都占8个字节以内,所以模式9适用。将前7个数字编码成一个64比特的字,最后1个0只能适用于模式15,也编码成一个64比特的字,最终该序列被编码成2个64比特的字。
文档ID序列是一个标准的从0开始的整数序列,适合用Simple算法进行压缩。起止位置信息也是一个整数序列,可以进行类似的压缩。另外,将终止位置改成跨越的长度,即 (终止位置-起始位置)。每个整数所占的平均比特数会下降,进一步提升压缩性能。
4 实 验
本实验的实验数据集共包含200 000条节目信息。每条节目信息包含标题、导演、演员、关键字和标签共5个可搜索域。
4.1 文档ID序列结构实验
本实验旨在测试2.2节中提及的文档ID序列结构对搜索效率的影响。对于原解决方案(所有节点中都存储文档ID集合)和文档ID序列解决方案在数据集大小分别为10 000、20 000、50 000和100 000的首字母索引中做以下实验:随机生成长度为2~4不等的搜索串。每一种长度的搜索串25个,总共75种搜索串。对于每一种搜索串,不考虑域筛选的影响,都为如下域筛选条件:{标题,导演,演员,关键字,标签},共75种搜索条件。对于每种搜索条件都进行100 000次串行搜索,在搜索结果正确的前提下,检查它们的时间消耗。实验结果如表2所示。
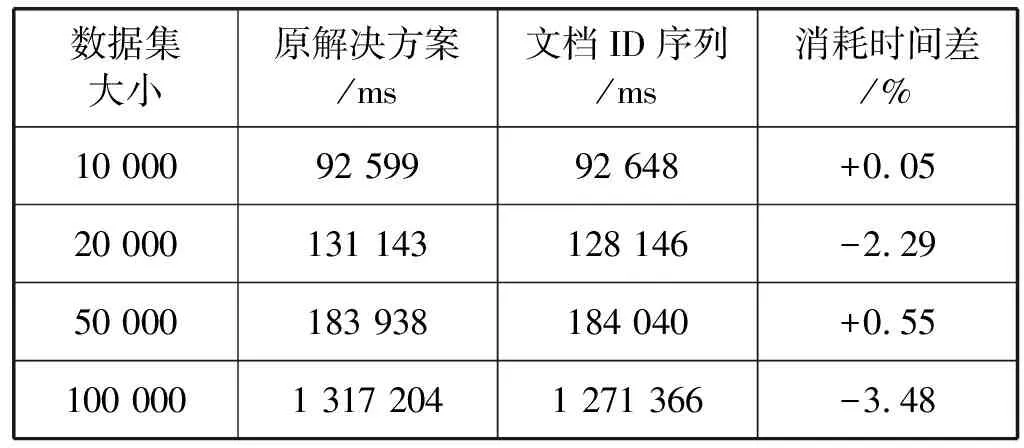
表2 原解决方案和文档ID序列搜索时间效率对比
文档ID序列解决方案和原解决方案在时间效率上几乎不存在差别。表3展示了文档ID序列解决方案和原解决方案在各个数据集上存储文档ID所需空间的对比。
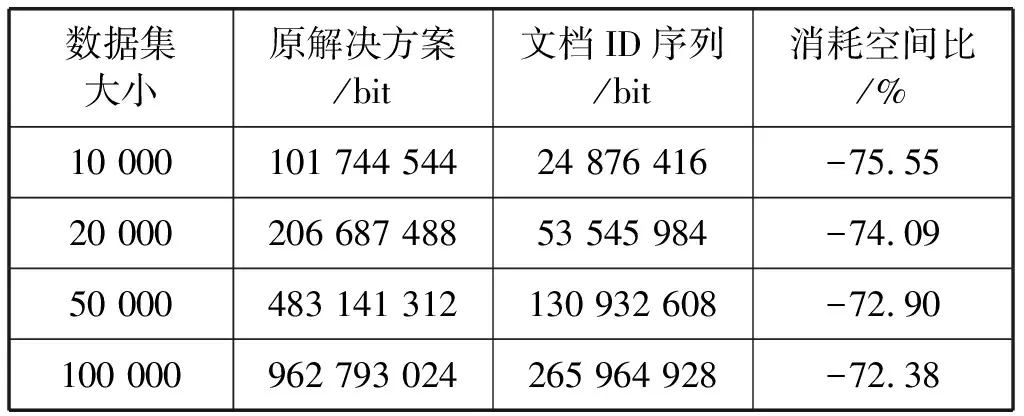
表3 原解决方案和文档ID序列空间效率对比
可以看到文档ID序列方案在处理数据冗余方面有着很好的性能,整数序列形式益于压缩管理,同时不降低搜索时间效率。
4.2 索引压缩实验
本实验旨在对第3节中描述的整数序列压缩算法在本索引结构的文档ID序列结构上的性能进行验证。
实验过程为:在大小分别为10 000、20 000、50 000和100 000的数据集上建立索引和其对应的文档ID序列。对文档ID序列分别以Elias Gamma Code, Elias Delta Code和SimpleX64-16算法进行压缩,对比压缩前和压缩后的文档ID序列大小。实验结果如图7所示。
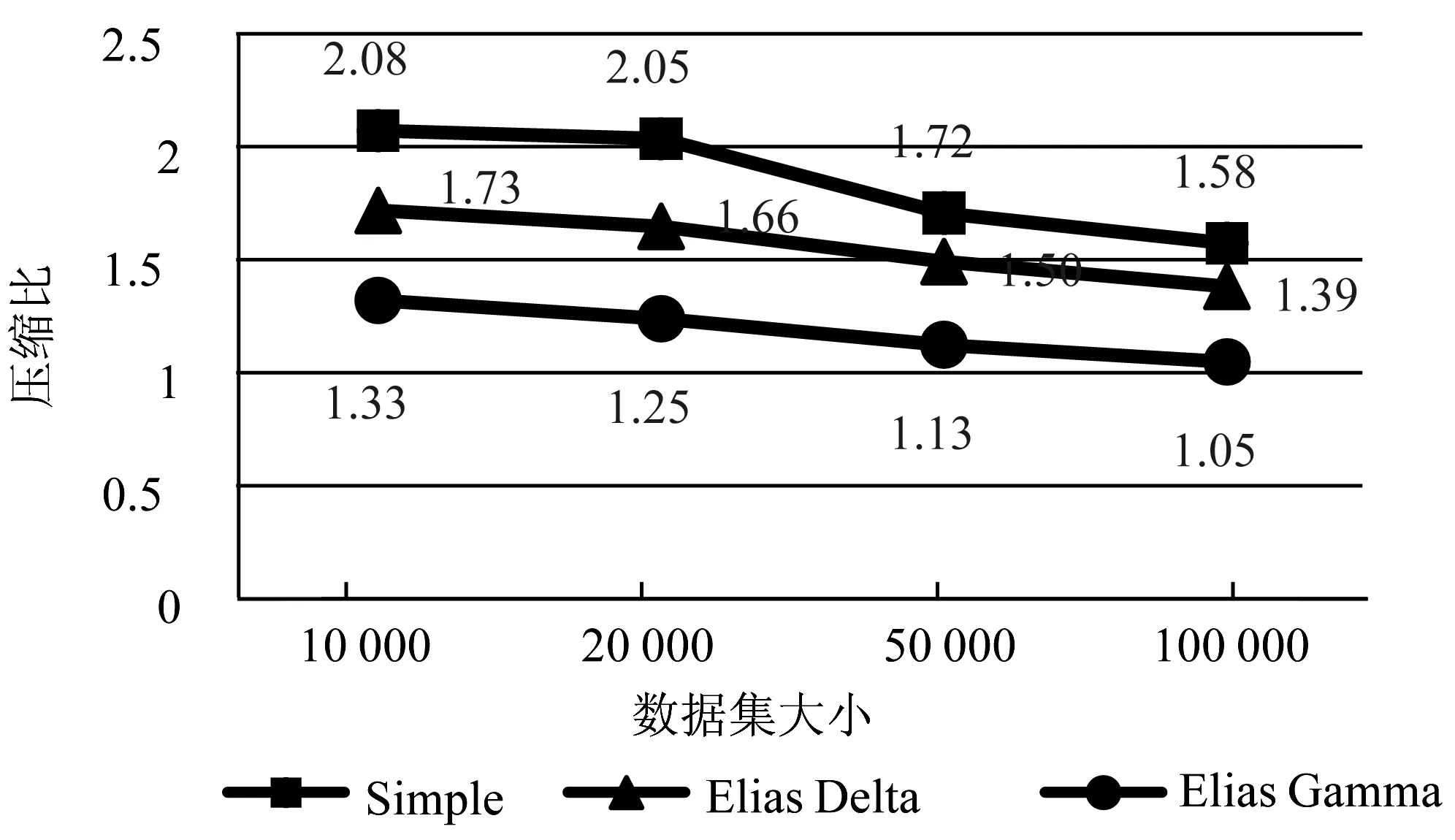
图7 各压缩算法的压缩比
无论是何种数据集,Simple算法的压缩性能都是最优的,加之文档ID序列本身的优化,文档ID总共可以减少82%以上的空间。
4.3 Lucene引擎搜索时间效率对比实验
本实验旨在对比第2节中提出的后缀树索引和基于倒排表的Lucene引擎[9]的搜索时间效率。实验方式为:在大小为10 000、20 000、50 000、100 000和200 000的数据集上用两种方式分别建立首字母索引。随机生成长度为2~4不等的搜索串。每一种长度的搜索串25个,总共75种搜索串。对于每一种搜索串,不考虑域筛选的影响,都为如下域筛选条件:{标题,导演,演员,关键字,标签},共75种搜索条件。对于每种搜索条件都进行100 000次串行搜索,在搜索结果正确的前提下,检查它们的时间消耗。实验结果如图8所示。
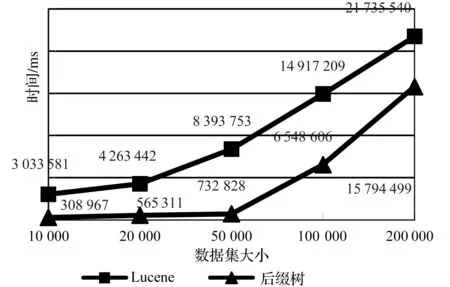
图8 与Lucene的搜索时间效率对比
第2节中描述的后缀树索引在任何数据集上都有着比Lucene更好的搜索时间效率,该结果在小数据集上更加明显。在数据集小于50 000的情况下,本文索引结构的搜索效率可以达到Lucene的7~10倍。
5 结 语
本文提出了一个高效快速的面向中文分词的解决全文检索问题的后缀树索引。在传统的后缀树索引上进行了改良,加快了其搜索时间效率的同时尽量减少其空间占用。经过实验对比,本文的索引结构比Lucene有着更高的搜索时间效率。另外实验分析得出了对文档ID序列压缩效率最高的压缩算法,进一步减少了索引的空间占用。
