行人再识别技术综述
2018-10-15李幼蛟卓力张菁李嘉锋张辉
李幼蛟 卓力 张菁 李嘉锋 张辉
行人再识别(Person re-identification,Re-ID)起源于多摄像头跟踪,用于判断非重叠视域中拍摄到的不同图像中的行人是否属于同一个人.行人再识别涉及计算机视觉、机器学习、模式识别等多个学科领域,可以广泛应用于智能视频监控、安保、刑侦等领域.近年来,行人再识别技术引起了学术界和工业界的广泛关注,已经成为计算机视觉领域的一个研究热点.由于行人兼具刚性和柔性物体的特性,外观易受穿着、姿态和视角变化以及光照、遮挡、环境等各种复杂因素的影响,这使得行人再识别面临着巨大的技术挑战.
对再识别的研究可以追溯到2003年,Porikli[1]利用相关系数矩阵建立相机对之间的非参数模型,获取目标在不同相机间的颜色分布变化,实现了跨视域的目标匹配.2006年,Gheissari等[2]首次提出行人再识别的概念,利用颜色和显著边缘线直方图(Salient edge histograms)实现行人再识别.经过多年的研究,行人再识别取得了诸多有意义的成果.2010年,Farenzena等[3]第一次在计算机视觉领域的顶级会议CVPR(Computer vision and pattern recognition)上发表了关于行人再识别的文章Person re-identification by symmetry-driven accumulation of local features.自此以后,在计算机视觉领域的国际重要会议,如CVPR,ICCV(International conference on computer vision),BMVC(British machine vision conference),ECCV(European conference on computer vision),ICIP(International conference on image processing)和权威期刊,如TPAMI(Transactions on Pattern Analysis and Machine Intelligence),IJCV(International Journal of Computer Vision),Pattern Recognition等,行人再识别都成为一个重要的研究方向,涌现了大量的研究成果.尤其是近年来,很多学者和研究机构陆续公布了专门针对行人再识别问题的数据集,极大地推动了行人再识别研究工作的开展.
行人再识别的典型流程如图1所示.对于摄像头A和B采集的图像/视频,首先进行行人检测,得到行人图像.为了消除行人检测效果对再识别结果的影响,大部分行人再识别算法使用已经裁剪好的行人图像作为输入.然后,针对输入图像中提取稳定、鲁棒的特征,获得能够描述和区分不同行人的特征表达向量.最后根据特征表达向量进行相似性度量,按照相似性大小对图像进行排序,相似度最高的图像将作为最终的识别结果.
行人再识别包括两个核心部分:1)特征提取与表达.从行人外观出发,提取鲁棒性强且具有较强区分性的特征表示向量,有效表达行人图像的特性;2)相似性度量.通过特征向量之间的相似度比对,判断行人的相似性.可以看出,行人再识别与图像检索的思路相同,可以看作是图像检索的子问题.
根据行人再识别采用的数据源,可分为基于图像的行人再识别和基于视频的行人再识别.后者得益于视频中包含更为丰富的时间信息,可以获得更优的性能.
根据采用的特征提取与表达方法,行人再识别技术的发展可以分为两个阶段:1)2012年之前的人工设计特征阶段;2)2012年之后的深度特征阶段.随着深度学习研究的不断深入,各种基于深度学习的行人再识别方法被不断推出,并取得了远超过传统方法的性能[4].
本文对基于人工设计特征和基于深度学习的行人再识别技术的研究进展情况进行综述.第1节介绍基于人工设计特征的行人再识别方法研究进展,重点阐述特征提取与表达、相似性度量的常用方法.第2节介绍基于深度学习的行人再识别方法研究进展,将其分为端到端式、混合式和独立式分别加以介绍.第3节介绍具有代表性的行人再识别数据集,并对各个数据集上取得优异性能的方法进行详细分析和比较.第4节对行人再识别技术的未来发展趋势进行展望.
1 基于人工设计特征的行人再识别
基于人工设计特征的行人再识别主要包含特征提取与表达和相似性度量两部分.特征是整个行人再识别的基础,特征的好坏直接影响到最终的识别性能,合理的相似性度量方法将进一步提高识别准确率.
1.1 特征提取与表达

图1 行人再识别典型流程图Fig.1 Typical flowchart of person Re-ID
行人再识别采用的特征可分为低层视觉特征、中层滤波器特征和高层属性特征三类.另外,在基于视频的行人再识别中,不仅提取空间特征,而且提取时间特征来反映视频的运动信息,提高识别精度.
低层特征是指颜色、纹理等基本的图像视觉特征.低层视觉特征及其组合是行人再识别中常用的特征.多个低层视觉特征组合起来比单个特征含有更加丰富的信息,具有更好的区分能力,因此常将低层视觉特征组合起来用于行人再识别.
中层滤波器特征是指从行人图像中具有较强区分能力的图像块组合中提取出的特征.滤波器是对行人特殊视觉模式的反映,这些视觉模式对应不同的身体部位,可以有效表达行人特有的身体结构信息.
高层属性特征是指服装样式、性别、发型、随身物品等人类属性,属于软生物特征,拥有比低层和中层特征更强大的区分能力.
虽然行人再识别技术最初提出的目的是用于视频追踪,但受限于有限的计算和存储能力,目前大多数行人再识别方法是基于静止图像的,各个摄像头下仅拍摄有一张或少数几张行人图像.然而,静止图像中包含的信息十分有限,导致再识别的准确性难以尽如人意.近年来,许多学者开始利用视频进行行人再识别.相对于静止图像,视频中包含更加丰富的时空信息,充分利用视频中的时空特征,可以获得更优的识别性能.
1.1.1 低层视觉特征
行人外观具有丰富的颜色信息,颜色是行人再识别中最常用的低层视觉特征之一.颜色直方图是应用最为广泛的一种特征,可以表征行人图像的整体颜色分布.此外,颜色矩、颜色相关图、颜色聚合向量等也是主要的颜色特征.Farenzena等[5]提出一种对称驱动的局部特征累计方法(Symmetrydriven accumulation of local features,SDALF).该方法首先取得行人的前景图像,然后分别提取三种互补的颜色特征:加权颜色直方图、最稳定颜色区域和高重复结构颜色块,三种特征结合起来用以描述行人外观的颜色特性.
颜色特征对于姿态和视角变化具有鲁棒性,但易受光照和遮挡的影响,而且由于着装相似问题,只利用颜色特征很难有效区分大规模的行人图像.行人衣着常包含纹理信息,而纹理特征涉及到相邻像素的比较,对光照具有鲁棒性,因此很多研究工作将颜色和纹理特征组合起来使用.文献[6]提出一种ELF(Ensemble of localized features)特征,利用Adaboost算法在一组颜色和纹理特征中选择出合适的特征组合,可以提高识别的准确性.
颜色和纹理特征能够提供行人图像的全局信息,但是缺乏空间信息.因此很多行人再识别方法在颜色和纹理特征中加入空间区域信息.行人图像被分成多个重叠或非重叠的局部图像块,然后分别从中提取颜色或纹理特征,从而为行人特征增加空间区域信息.当计算两幅行人图像的相似度时,对应的图像块内的特征将分别进行比较,然后将各个图像块的对比结果融合,作为最终的识别结果[3,5].或简单地将各个图像块特征级联为一个特征向量,然后进行对比[6−8].
表1是对行人再识别常用的几种典型图像块分割方法进行的归纳和总结.采用局部分割模型的目的是通过对人体结构的多层次建模,提高局部特征的判别性和区分性,尽可能多地过滤掉背景信息.图2是表1中四种分割方式的分割结果示意图.图2(a)~2(d)依次为上下半身分割法、条纹分割法、滑动窗分割法和三角形分割法.其中滑动窗分割方法符合人类的视觉规律,识别效果最好.
图像块分割方法可以利用行人身体子块位置的先验知识.采用这种方法实现的识别过程相对简单,但是无法确保图像子块与身体子块之间的精确匹配,对于强烈的视角变化,鲁棒性较差.
另外,当多种低层特征组合使用时,随着特征数目的增加,特征向量维数会呈指数增长.利用协方差作为行人图像的特征描述,可以大大降低特征维数[9−10].文献[9]提出一种HSCD(Hybrid spatiogram and covariance descriptor)描述符,将空间直方图与协方差算子进行融合.空间直方图由各个图像区域上的多通道颜色直方图累加而成.协方差算子由相同图像区域中包含了颜色和纹理信息的协方差矩阵构成.然而,协方差描述符会去除图像的均值信息,而这些信息对区分行人是非常重要的.文献[11]提出一种GOG(Gaussian of Gaussian)描述符,利用分层高斯算子将图像分为由多个高斯分布进行描述的不同区域来表示颜色和纹理信息,每种高斯分布代表一个小的图像块,每个图像块的特征组合起来得到行人图像的特征向量,用于识别.

表1 典型行人图像分割方法Table 1 Typical segmentation methods of pedestrian image

图2 行人图像块分割方法Fig.2 Patch segmentation methods of pedestrian image
低层特征的提取不需要复杂的训练过程,可解释性较强.但是表达能力较弱,面对复杂的识别环境其泛化能力受到一定制约,无法针对具体的行人再识别任务进行优化.
1.1.2 中层滤波器特征
中层滤波器特征是利用聚类算法,从行人图像中学习出一系列有表达能力的滤波器.每一个滤波器都代表一种与身体特定部位相关的视觉模式,也称显著区域(Salient region).如果在同一行人的多幅图像中存在由若干小的图像块组成的显著区域,例如提包,会有助于做出判断,如图3[12]所示,图中虚线框为显著区域检测结果.如果提包出现在多张图像中的不同空间位置,很多行人再识别算法会将其忽略.这些方法[3,5,13−14]通常只考虑大块的对应上衣和裤子的颜色区域,小的颜色区域因为不属于身体主要区域会被当作异常值而忽略掉.因为显著区域对于光照和视角变换具有较强的鲁棒性,因此合理利用显著区域会有效提高再识别的性能[12,15−16].
Zhao等[12]以非监督的方式得到图像中的显著区域用于行人再识别,对获得的显著区域进行显著性排序,并据此分配权重.Cheng等[17]采用类似SDALF的前景分割方法,利用人们对于行人外观的先验知识首先提取出行人的前景图像.然后基于图画结构训练出包含11个身体部分的人体结构模型,在该模型的基础上提取颜色直方图组成行人图像的特征表达,用于行人再识别.

图3 行人显著区域示意图Fig.3 The illustration of salient region
人体由各个身体部位组成,具有良好的结构特性,使用与人体部位对应的滤波器特征能够平衡行人描述符的区分能力和泛化能力.低层和中层特征结合起来使用能够充分发挥各自的优势,在一定程度上克服行人再识别中的光照和视角变化问题.但是,人体是非刚性目标,外观易受到姿态、遮挡等各种因素的影响,仅利用低层和中层特征会导致识别精度不高,还需要利用其他更高层的特征.
1.1.3 高层属性特征
人类在辨识行人时会使用离散而精确的特有属性(Attribute),例如服装样式、性别、胖瘦等都属于行人的属性特征.行人图像对应的属性特征通常采用离散的二进制向量表示形式,例如图3中的行人,假设定义3个属性(是否男性;是否长发;是否携带提包),则对应的属性特征向量为[1 0 1].与其他特征相比,高层属性特征尽管在提取和表达方面复杂,属性标定需要大量的人工和时间成本,但含有更加丰富的语义信息,而且对于光照和视角变化具有更强的鲁棒性.因此,属性特征与低层特征联合使用,可以有效提高识别性能.
Layne等[18]将属性特征用于行人的再识别.针对服装的样式、发型、随身物品以及性别设计并手工标注了15种基于低层特征的行人属性.在进行基于属性的行人再识别时,首先利用一组人工标定好属性的样本图像训练支持向量机(Support vector machines,SVM)属性分类器,将属性判别结果用于行人再识别.因为训练样本中的某一属性是通过不同摄像头拍摄的图像学习得到的,因此属性分类器具有一定的视角鲁棒性.
属性的标定费时费力,因此研究者们开始探索如何扩展已有的属性.文献[19]借助其他非行人再识别专用的大型数据集训练出一组属性,这些大型数据集带有颜色、纹理和类别标签.训练好的属性通过非监督的方式直接应用到小型的行人再识别数据集上.无论是手工标注还是通过低层特征学习得到的属性特征,彼此之间相互独立.如果能利用属性特征中包含的语义信息,将属性特征投影到连续的有关联的属性空间中,将大大提高属性特征的区分能力.文献[20]利用多任务学习[21]得到行人属性特征的相关性低秩矩阵,通过该矩阵转换后的属性特征向量具有较小的类内差和较大的类间差,因此具有很好的区分性.
属性特征可以对行人图像进行语义层面的解释,能够有效缩小低层视觉特征与高层语义特征之间的语义鸿沟.研究结果表明,与低层特征相比,在再识别过程中使用高层属性特征,性能明显提升,以最常用的VIPeR数据集[22]为例,平均识别精度可以提高6%左右.
1.1.4 视频时空特征
在基于视频的行人再识别中,每个行人至少包含两段跨视域的视频序列,其中包含数量不等的视频帧.这些视频帧能够提供大量的训练样本,可以更方便地训练机器学习算法,从而提高识别的性能.
处理视频最常用的方法是提取每一帧的低层特征,然后利用平均/最大池化方法将其聚合为一个全局特征向量,用以反映行人的外观信息[23].值得注意的是,虽然视频数据量巨大,但是人们感兴趣的信息可能主要集中在某些方面.另外,视频中的冗余信息对识别结果有一定的负面影响.因此,许多学者致力于从视频中挖掘更有效的信息.Gao等[24]提出一种时间对准池化方法,利用行走的周期特性将视频序列分成独立的行走周期,选择最符合正弦信号特性的周期代表该视频序列,提高了识别性能.
与图像相比,视频序列中的帧与帧之间不仅存在空间依赖关系,也存在时间次序关系,合理利用视频的时间特征能够反映行人的运动特性,提高识别准确率.因此,对于基于视频的行人再识别来说,往往提取视频的时空特征用于识别.在判别视频帧选择排序(Discriminative video fragments selection and ranking,DVR)[25]方法中,首先通过计算每个行人视频序列的步态能量图像[26]来提取行人的运动特征,然后融合HOG3D[27]时空特征,最后通过判别视频帧排序模型进行相似性度量.You等[23]采用HOG3D时空特征,并融合行人图像的颜色和纹理特征作为行人的特征表达.
总的来说,时空特征反映了视频中的运动信息,是行人外观特征的有效补充.然而,时空特征易受视角、尺度和速度等因素的影响,在新型的大型行人再识别数据集上表现得差强人意.因为对于大型行人再识别数据集来说,随着行人的大幅增加,行人之间的运动相似性也随之增加,这使得时空特征的区分能力大幅下降.同时,大型数据集中摄像头数量多,使得同一行人的姿态差异增大,运动差异愈加明显,这些都限制了时空特征在行人再识别中的作用.因此,如何设计更具区分性的时空特征是基于视频的行人再识别需要解决的问题.
1.2 相似性度量
行人再识别利用特征之间的相似性来判断行人图像的相似性,特征相似的行人图像将被看作是同一个人,选择合适的相似性度量方法对行人再识别至关重要.根据度量过程中是否使用标签,相似性度量可以分为无监督度量和监督度量.另外,在基于视频的行人再识别中,行人除了外观相似之外,不同行人的运动特性也往往非常相似,这使得行人再识别成为一个挑战性的难题.如何设计相似性度量方法,对特征相似的行人加以区分是提高行人再识别性能需要解决的关键问题.
1.2.1 无监督度量
无监督度量直接利用特征表达阶段获得的特征向量进行相似性度量.特征向量之间的相似性往往通过特征向量之间的距离进行度量,特征向量之间的距离越小,说明行人图像越相似.早期的行人再识别研究工作通常使用简单的欧氏距离或巴氏距离作为相似性度量方法.假设x,y分别代表两个摄像头下的行人图像特征向量,则对应的欧氏距离为
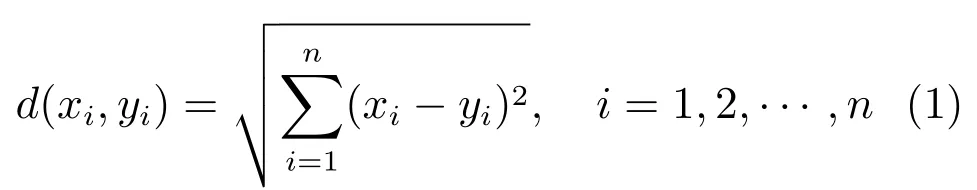
巴氏距离[28]经常在分类任务中用于测量类之间的可分离性,其计算公式为
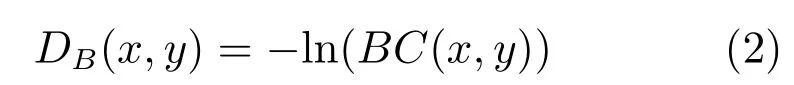
欧氏距离和巴氏距离等简单的几何距离通常将数据的各个维度等同对待,没有考虑不同维度对识别效果的影响程度,因此获得的相似度并不准确.而监督方式利用带标签的训练集样本,通过对目标函数的优化,可以获得能够有效反映样本相似关系的特征空间,成为目前行人再识别中相似性度量的主要方法[7−8,23].
1.2.2 监督度量
距离度量学习是基于成对约束的监督度量方法,基本思路是利用给定的训练样本集学习得到一个能够有效反映数据样本间相似度的度量矩阵,在减少同类样本之间距离的同时,增大非同类样本之间的距离.当特征向量提供的信息足够充足时,距离度量能够获得比非监督方式更高的区分能力.但是,与非监督度量方法相比,距离度量学习需要额外的学习过程,在训练样本不足时容易产生过拟合现象,且图像库和场景变化时需要重新训练.
距离度量学习最常见的是基于马氏距离[29]的度量.给定一个Rd空间上的n个特征向量[x1,x2,···,xn],找到一个半正定矩阵M∈Rd×d,则向量对(xi,xj)之间的马氏距离为
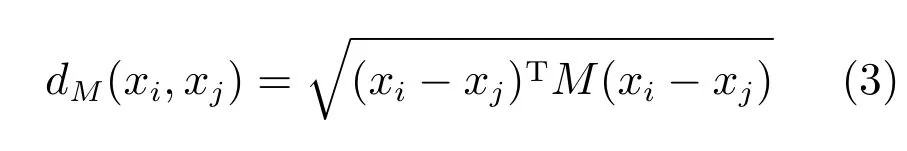
式(3)可以转化为凸优化问题进行求解[30].例如Zheng等[31]提出一种概率相对距离比较(Probabilistic relative distance comparison,PRDC)方法,对行人特征的相对距离函数进行优化.对于每张行人图像,选择同一行人样本和不同行人样本组成三元组,在训练过程通过最小化不同类样本距离与同类样本距离的和,得到满足相对约束的马氏距离度量矩阵.
经典的度量学习方法有大间隔最近邻(Large margin nearest neighbor,LMNN)[32]、基于信息论的度量学习(Information theoretic metric learning,ITML)[33]和基于逻辑判别的度量学习(Logistic discriminant metric learning,LDML)[34]等.在行人再识别问题中,行人的特征表达往往包含图像的多种统计信息,使得行人图像的特征向量结构复杂,维数较高.上述方法由于复杂的优化策略对系统资源造成了过高的负担,因此不适合大规模的行人再识别.
保持简单直接度量算法(Keep it simple and straightforward metric,KISSME)[35]不需要通过复杂的迭代算法计算度量矩阵,因此计算效率更快.实验结果表明,对比ITML等传统算法,KISSME算法在识别准确率和算法效率上都更具有优势.KISSME通过似然比检验的方法将距离度量学习转化为
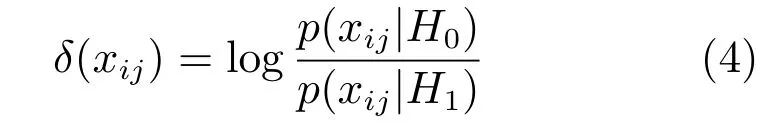
其中,xij=xi−xj,H0,H1分别为样本对相似与否的假设检定.
KISSME包含两个主要阶段:1)进行主成分分析(Principal component analysis,PCA)降维;2)利用PCA子空间上行人类内差和类间差的协方差矩阵学习距离函数.然而,这种两阶段的处理方式在低维空间中很可能无法求得最优解.因为在经过第一阶段之后,隶属于不同类的样本会变得杂乱无章.跨视域二次判别分析方法(Cross-view quadratic discriminant analysis,XQDA)[8]对该方法进行了改进,能够同时学习基于跨视域数据的子空间和低维空间上的距离度量,通过学习行人类内差和类间差的协方差矩阵的核度量来建立距离度量函数.
总的来说,由于具有去耦合和量纲无关两种优良的性质,使得基于马氏距离的距离度量学习方法在行人再识别中应用得最为广泛.在传统的小型数据集上,为了获取更加丰富的行人信息,行人描述符的维度远远超过训练样本的数量,造成距离学习过程中的小样本问题(Small sample size,SSS).为了解决该问题,往往需要对行人特征进行降维和正则化处理,导致距离学习函数只能获得次优解.最近,大型行人再识别数据集的出现有效缓解了距离度量学习的小样本问题.然而,目前的距离度量算法大都是基于成对约束的,约束的数量是训练样本数量的平方,导致大样本时约束数量将变得非常巨大.因此,构建合理的训练约束库,设计更加快速有效的训练机制,将是距离度量学习下一步需要深入研究的问题.
1.2.3 基于视频的距离度量
在基于视频的行人再识别方法中,大多沿用基于马氏距离的度量方法.例如顶推距离学习模型(Top-push distance learning model)[23]是专门为基于视频的行人再识别设计的度量方法,通过对样本对之间最大的干扰项施以较大的惩罚来快速有效地增大类间差异.顶推距离学习比较的不是正样本对与所有相关的负样本对之间的距离,而是正样本对与所有相关负样本对的最小距离.
与顶推距离学习模型采用马氏距离矩阵不同,Karanam 等[36]提出一种SRID(Sparse re-id)方法,利用字典学习进行相似性度量,通过求解共同嵌入空间上的块稀疏恢复问题来确定行人类别.类似地,Karanam等[37]提出的DVDL(Discriminative dictionary learning)方法利用与SRID相同的特征,学习出一个矩阵以及对应的稀疏编码,通过优化稀疏编码的欧氏距离来提升字典的区分能力.
综上所述,基于人工设计特征的行人再识别经过多年研究,已经取得很大的研究进展,积累了许多成功经验.然而,人工设计特征的优劣很大程度上依赖于设计者的先验知识和手工调参.由于在特征设计中允许出现的参数个数十分有限,有效特征的产生需要一个漫长的过程,特征的泛化能力较弱.
2 基于深度学习的行人再识别
自从Krizhevsky等[38]获得ILSVRC′12分类竞赛冠军以来,基于卷积神经网络(Convolutional neural network,CNN)的深度学习被广泛应用于计算机视觉领域[39−42].深度学习与传统方法的最大不同在于其特征是从大数据中自动学习得到的,通过建立类似于人脑的分层模型结构,能够从大量数据中逐级提取由底层到高层的特征,获得适合于分类或者识别的深度特征.
2014年,Li等[43]率先将深度学习应用到行人再识别中,提出一种基于CNN的FPNN(Filter pairing neural network)网络模型.FPNN的第一层是带最大池化操作的卷积层,然后加入块匹配层对跨视域的滤波器响应进行匹配.FPNN能够在一个统一的框架下解决未对准、遮挡和背景等因素对识别性能的影响.
在行人再识别中用到的深度学习模型往往包含三个基本的网络层:卷积层、池化层和全连接层,如图4[43]所示.首先将不同视域中的行人图像作为网络的输入,然后将这些图像分解为不同的颜色通道子图分别进行处理.对于每幅子图,在接下来的卷积层中对其实施卷积滤波操作,得到不同局部图像块的响应,作为局部特征.这些局部特征组合起来,形成特征图,作为该卷积层的输出.卷积层的作用是提取图像的各种信息,例如边缘和形状.在接下来的池化层中对产生的特征图进行最大/平均池化操作.池化层的作用是对卷积后的特征信号进行抽象,从而大幅减少训练参数,另外还可以减少过拟合现象的出现.卷积层和池化层可以出现多次,获得行人抽象的、多层次描述.全连接层的作用是将池化层得到的特征图投影到一维的特征空间,形成行人图像的特征向量.在最后的Softmax层,通过二值函数判断输入的图像对是否输入同一个行人.

图4 深度学习模型各网络层示意图Fig.4 Illustration of the network layers in deep learning model
深度学习模型可以将特征表达和相似性度量两个环节整合在一起,通过二者的联合优化获取远超传统方法的性能.按照两个环节整合方式的不同,将基于深度学习的行人再识别方法分为端到端式、混合式和独立式三种(如图5所示).

图5 基于深度学习的行人再识别方法的三种方式Fig.5 Three ways of deep learning-based person re-identification
2.1 端到端式的深度行人再识别
端到端式的行人再识别利用深度学习模型,将特征提取和相似性度量这两个主要环节整合到一个统一的框架下进行联合优化,形成一种端到端的行人再识别方案.例如Ahmed等[44]利用多输入的近邻差和图像块简要特征,提出一种增强的深度学习框架,用以学习跨视域特征之间的关系.文献[43−44]均以Siamese网络为原型,以不同视域的行人图像对作为网络输入,网络输出是二进制变量,用以指示输入的图像对是否属于同一个人.采用Siamese网络的重要原因是行人再识别数据集规模普遍较小,无法充分发挥深度学习的优势,而采用图像对的输入形式可以大大增加训练样本.
在基于视频的行人再识别中,如何有效利用深度网络提取时间特性是提升识别效果的关键.而CNN假设输入数据是互相独立的,因此无法对时间序列数据进行建模.为此,最近的研究工作是在Siamese网络的基础上引入递归神经网络(Recurrent neural network,RNN)和长短期记忆网络(Long short-term memory,LSTM),将视频的时间特性与深度特征相融合,提升识别准确度.
1)递归神经网络
递归神经网络通过添加跨越时间点的自连接隐藏层,提取视频的时间特性,将时间特性引入到行人特征中.原理是利用建立在隐含层的状态向量,隐式地记录视频序列的历史信息.RNN的输入不仅包括当前的视频帧,还包括上一个视频帧,输出是最后一帧的特征向量.文献[45]中,视频帧及其光流图作为CNN的输入,通过两个对称的CNN模型提取视频序列的深度特征,深度特征再经过一个RNN层投影到一个低维特征空间,并与前一时刻的信息进行组合,从而获取视频中的时间信息.最后利用时间池化层对深度特征进行聚合,降低特征维度,并提升特征的鲁棒性.该方法利用视频帧刻画行人的外观信息,光流图可以直接对行人的运动特性(例如步态)进行编码,通过两种信息的整合来提高行人视频特征的区分能力.
2)长短时记忆网络
RNN结构可以记忆历史信息,但记忆时间极短.LSTM网络是对RNN的改进,可以记忆长时信息,对视频中复杂的动态信息建模.LSTM同样可以利用历史信息更新当前状态,它与传统RNN的不同在于神经元的构造,LSTM中的神经元在下一个加权的时间段内与自身连接,因此可以复制自己的实际状态并累加外部信号,最后一个LSTM节点的输出信息囊括了整个视频序列的信息.文献[46]提出一种递归特征聚合网络(Recurrent feature aggregation network,RFA-Net),利用LSTM记录行人身体部位随时间的变化信息.与文献[45]不同,RFA-Net将低层人工特征,而不是CNN深度特征,作为时间节点的输入,目的是为了避免在小数据上训练CNN带来的过拟合现象.LSTM可以对性能优异的特征进行记忆和传播,同时忽略掉较差特征,RFA-Net利用LSTM 的这一优势,建立视频的全局特征表达.
端到端式的行人再识别方法沿用了在图像分类中常见的深度网络模型,一经提出即引起广泛关注.然而,早期的端到端方法在进行相似性比较时,往往采用简单的欧氏距离或余弦距离,缺少距离学习的过程,影响了识别准确率.常见的解决方法是在深度网络训练过程中加入损失函数约束,使得同类样本距离变小,异类样本距离变大,达到距离学习的效果[47].另外,随着训练样本的增加,Siamese网络模型会变得过于复杂,需要漫长的训练过程.
2.2 混合式的深度行人再识别
人工特征经过多年研究已经较为成熟,在一些应用中取得了较好的结果.例如LBPH特征适用于人脸识别、HoG特征比较适用于行人检测等.为此,人们尝试将深度特征和人工特征相结合,利用距离度量学习进行相似性度量,实现行人再识别,本文称之为混合式的深度行人再识别方法.该方法可以采用较为成熟的人工特征表达行人的局部特性,采用浅层的网络结构提取行人的全局特征,二者结合可以充分发挥各自优势,在一定程度上弥补训练数据的不足,同时可以在一定程度上避免深度网络模型过于复杂、网络训练速度慢的缺点.
Wu等[48]将CNN特征和ELF[6]特征相结合,提出了一种特征融合网络,利用反向传播算法对CNN特征的提取过程进行约束.融合后的特征结合传统的距离度量方法,在三个小型行人再识别数据集上取得了良好的识别效果.文献[49]尝试将PCANet网络[50]特征与LOMO特征[8]结合,提出一种基于多种统计信息的金字塔级联行人描述符,在小型数据集VIPeR上获得了优越的性能.Zheng等[51]提出一种查询自适应融合方法对不同特征的性能进行衡量,并将CNN特征和另外五种人工特征相结合用于行人再识别.研究结果表明,混合式的深度行人再识别方法能够将人工设计特征和深度特征的互补性发挥出来,使结合后的行人描述符对于视角和光照变化等问题具有更强的鲁棒性.
混合式的行人再识别方法适用于中小型的数据集,结合先验知识,已经证明其有效性的人工特征,只采用浅层的网络结构即可达到较高的识别准确率,大大简化了网络训练过程.
2.3 独立式的深度行人再识别
独立式的深度行人再识别方法的框架与基于人工特征的方法相似,不同的是采用深度神经网络提取行人图像的深度特征,然后结合距离度量学习方法完成行人再识别.随着大型行人再识别数据集的不断提出,提取行人的深度特征成为可能,并能获得很好的识别性能.例如文献[52]提出一种姿态融合网络,将原始图像、姿态校正图像和姿态估计置信打分作为深度残差网络(Deep residual network)[53]的输入,再结合KISSME[35]度量学习方法提高识别率.文献[54]首先利用CNN特征学习出一个身份嵌入模型,然后利用置信加权度量学习进行相似性度量,可以有效提高识别性能.
随着深度学习技术的快速发展,性能优异的深度网络模型不断涌现,而独立式的深度行人再识别方法设计思路简单,借助于新的网络模型,能够有效提高行人再识别的性能.表2是在Market-1501数据集上[55]采用不同网络模型获得的首轮识别率.从表2可以看出,随着网络深度的不断增加,识别准确率也相应提升.但是与此同时,网络训练复杂度也随之增加.因此,如何根据应用需求,获得网络深度与识别准确率之间的最优折中是一个值得研究的问题.

表2 Market-1501数据集上不同深度模型对首轮识别率的影响Table 2 Rank-1 matching rates of different deep models in Market-1501
上述三类方法的性能表现与数据集的规模和特点紧密相关,表3列出了三类方法在常用数据集上所能取得的最好效果.
从表3可以看出,在大型数据集Market-1501和MARS上,基于端到端式的深度学习方法取得了最好的效果.因为目前的距离度量学习方法绝大多数是基于成对约束的,当大型数据集中摄像头的数量超过两个时,距离度量学习的效果将大大减弱.而端到端式的方法利用三元损失函数取代距离度量学习,取得了超过另外两种方法的效果.在中型数据集iLIDS-VID和CUHK01上,混合式和独立式的方法借助距离度量学习,通过二次学习的过程提高了识别的准确率,都取得了显著的效果.而在以VIPeR为代表的小型数据集上,无法提供深度模型所需的训练样本规模,通过结合人工特征,提升识别精度.
另外,为了提升小型数据集上的识别性能,可以采用预训练(Pre-training)+细调(Fine-tuning)的策略,即在大型数据集上对网络参数进行预训练,然后利用小型数据集中的样本对网络参数进行细调,将其泛化到小型数据集上.类似的思路也被应用到基于属性的行人再识别中,例如文献[61]提出一种半监督的深度属性学习模型,首先利用带标签的行人再识别数据集训练CNN网络,并对目标数据集进行属性预测.然后利用目标数据集对网络参数进行细调.最后组合两种数据集重新训练网络,更新属性标签,提高属性的分类准确率.文献[62]利用人体部位的先验知识提高属性标签分类的准确性.首先将行人图像分为重叠的图像块,然后送入带有多个属性标签的CNN网络进行训练,属性标签的设计跟图像块的位置紧密相关,得到一个能够同时预测多个行人属性的深度网络模型.
综上所述,基于深度学习的行人再识别方法可以模拟人脑的抽象和迭代过程,获得行人图像的分层特征表达.深度网络的低层特征是从像素中学习得到刻画身体局部特性的边缘和纹理特征;中间层特征则通过将各种边缘滤波器的组合来描述不同的人体部位;高层特征描述的是整个行人的全局特征.因此,基于深度学习的行人再识别方法仅经过极少的预处理就可以得到从原始像素到高层语义的有效特征表达.另外,在行人图像中,各种复杂的因素,包括姿态、性别、着装等,往往以非线性的方式组合在一起,而深度学习可以通过多层非线性映射将这些因素分开,利用不同的神经元代表不同因素,使其变成简单的线性关系,不再相互影响,从而提升识别效果.

表3 基于深度学习的方法目前所取得的最好效果Table 3 The best results of deep learning-based methods
从目前行人再识别采用的深度网络结构来看,网络层数越来越多.通过增加网络深度,可以提升网络的非线性表达能力,使其更好地拟合目标函数,获得具有更优泛化能力的分布式特征表达.但是,这种做法增加了网络整体的复杂度,使网络变得难以优化,这时需要大规模的数据集作为支撑,否则过拟合将不可避免.研究结果表明,行人再识别的精度随数据集规模的增加而增加.
3 数据集及性能比较
目前已经公布了许多专门用于行人再识别的数据集.深度学习出现之前,大部分行人再识别方法都是采用的人工特征,并在小型数据集上验证方法的性能.随着对深度学习研究的深入,出现了许多基于深度学习的行人再识别方法以及大型数据集.其中常用的六个数据集及其主要参数如表4所示.
VIPeR、CUHK01和Market-1501均为基于图像的行人再识别数据集.VIPeR使用最为广泛,包含632个行人,每个人拍摄有两幅照片,均存在不同程度的光照、视角和姿态等变化,具有非常大的挑战性.CUHK01数据集采用手工抠图,包含971个行人的3884幅图像,均归一化到160像素×60像素,图像质量比较好.Market-1501数据集包含32668幅图像,由6个相机在清华大学校园内拍摄1501个行人得到.行人边框采用部分变形模型(Deformable part model,DPM)自动检测得到,很多图像只包含了行人的部分身体.
PRID-2011、iLIDS-VID 和MARS均为基于视频的行人再识别数据集.PRID-2011数据集中的视频对通过两个固定的监控摄像头进行采集,摄像头A包含385个行人,摄像头B中包含749个行人.这些行人中,只有200个行人曾经出现在两个摄像头中.iLIDS-VID是在PRID-2011之后公布的数据集,与PRID-2011相比,数据更加整齐,也更有挑战性.iLIDS-VID数据集是通过机场到达大厅的CCTV监控视频采集得到的,包含300个行人在两个摄像头下的600段视频.视频中存在严重的着装相似、光照和视角变化、复杂背景和遮挡现象,因此识别难度大.MARS数据集是Market-1501数据集的扩充版,图像数量由32668扩展到了1191003幅.
从表3可以看出,随着行人再识别研究工作的不断推进,数据集的规模越来越大,摄像头数目越来越多.其中Market-1501是迄今为止规模最大的行人再识别图像数据集,可以提供足够多的样本数据供深度网络进行训练.另外,小型数据集中的行人边框是手工标定的,而大型数据集中的行人边框则普遍利用DPM之类的行人检测方法自动获得.
接下来对在各个数据集上取得优异性能的行人再识别方法展开分析和比较.在衡量算法性能时,有两种常见的度量准则:累计匹配性能曲线(Cumulative match characteristic,CMC)和Rank-N表格.
累计匹配性能曲线在识别性能评估中被广泛使用,计算公式如下:

从式(5)可以看出,该曲线反映的是在前k个匹配结果中找到正确结果的概率.横坐标表示k,纵坐标是识别率.一般会将几种方法的识别结果画在一个坐标系中,以便能直观地比较性能.图6是五种方法在VIPeR数据集上的实验结果[9].当k=1时,表示首轮识别率(即传统意义上的分类准确率):准确匹配的目标所占的比例.CMC曲线中纵坐标数值越大,表明识别效果越好.随着候选目标的增加,准确率必然上升.因此,CMC曲线随着横坐标的增加呈递增的趋势.

图6 CMC曲线示意图Fig.6 The illustration of CMC curve
在对不同的行人再识别方法进行直观比较时,如果不同方法的性能差别不大,则很难作出清晰的判断.为此,人们往往采用另外一种更加准确的度量方法— Rank-N表格,以数值形式给出关键匹配点的累积匹配准确率.常见的有Rank-1,Rank-5,Rank-10和Rank-20.其中Rank-5代表在前5幅图像中可以正确匹配的概率,概率值越大表示效果越好.
下面以Rank-N表格的形式给出上述六个数据集上取得优异性能的方法.表5是在三个行人再识别图像数据集上取得优异性能的方法对比.
表5中,SCSP方法利用多项式特征图对全局特征与多种局部特征进行整合.Zhang等[63]针对传统距离度量学习中存在的特征维数过高问题,对再识别过程进行改进.WARCA算法将加权逼近排序合成损失函数与满足线性正交投影的正则化项组合以提高识别准确率.上述三种方法是目前公布的三个数据集上采用人工设计特征能得到的最好结果.
表5中的其他方法均属于基于深度学习的方法.FFN网络中同时利用深度CNN特征和人工设计特征ELF对行人图像进行描述.HIPHOP利用深度网络整合行人的全局和局部特征.Zheng等[64]融合了身份认证模型和身份分类模型的损失函数,并参考损失函数的梯度对深度网络进行优化.SOMAnet网络模型利用稀疏的图像对架构获取深度网络模型具体的学习内容.
从表5可以看出,基于人工设计特征的行人再识别算法利用多年积累的先验知识,在中小型数据集上还可以取得类似基于深度学习算法的性能.但是后者在每类行人仅有少数几幅图像(两幅或四幅)的情况下取得了50%以上的首轮识别率,显示出强大的特征提取优势.在大型数据集上,基于深度学习的方法在性能上远超传统方法,平均准确率差距接近30%.
表6是在三个行人再识别视频数据集上取得优异性能的方法对比.TAPR方法通过选择出视频中最符合正弦曲线的行走周期应对视频中噪声对识别结果的影响.Zhang等[60]首先利用流动能量轮廓法找到视频中最有代表性的4帧,然后利用预训练的基于VGG结构的深度模型提取深度特征.McLaughlin等[45]利用递归神经网络捕捉视频中的时间信息.文献[4]以XQDA作为距离度量方法,分别采用深度CNN特征和人工LOMO特征进行行人再识别,给出了在该数据集上的性能对比结果.

表4 常用行人再识别数据集及其参数Table 4 Popular person re-identification datasets and their parameters
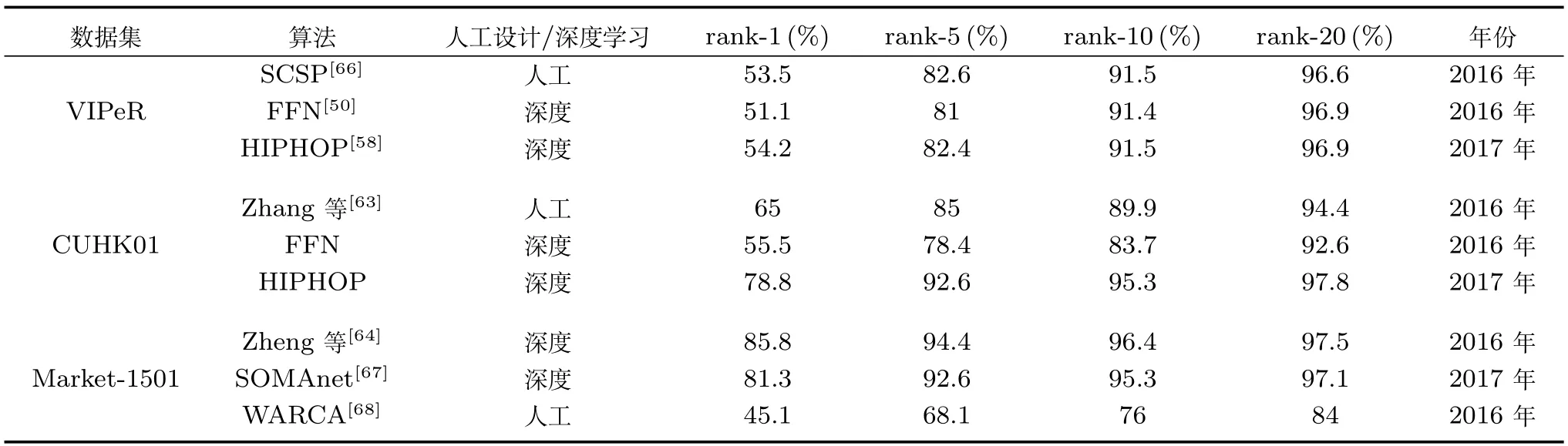
表5 行人再识别图像数据集上取得优异性能的方法对比Table 5 Comparison of state-of-the-art methods on image-based person re-identification datasets
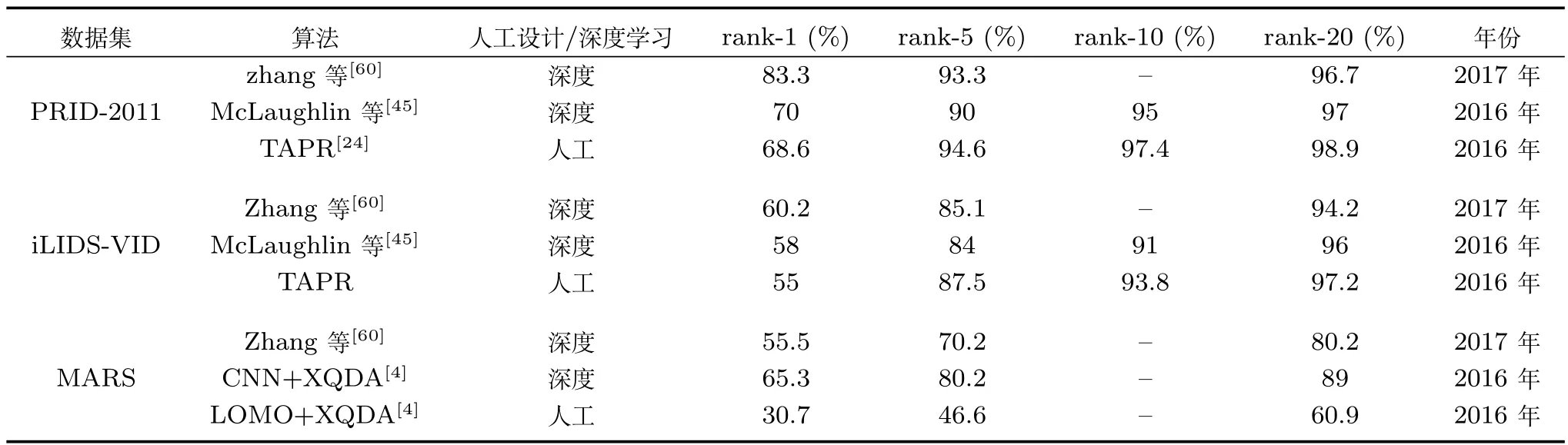
表6 行人再识别视频数据集上取得优异性能的方法对比Table 6 Comparison of state-of-the-art methods on video-based person re-identification datasets
从表6可以看出,利用视频进行行人再识别时,由于每类行人都包含几十幅以上的视频帧,能够提供足够的训练样本.因此,在三种规模的数据集上,深度学习方法的性能都大大超过了传统方法.随着数据集规模的扩大,深度学习的优势也愈加明显.
4 总结与展望
行人再识别是当今计算机视觉领域的核心难点问题,其解决具有重要的理论意义和良好的应用前景.总的来说,目前对于行人再识别尚处于研究探索阶段.由于人体结构和外部环境的复杂性,基于人工特征的方法在性能上还无法令人满意.随着数据规模的不断扩大,基于深度学习的方法展现出巨大的优势,取得了不错的效果[69].虽然识别准确率在不断提高,但是距离实用还存在一定的差距.将来的研究工作可以从以下几方面展开:
1)长时行人再识别.目前大多数行人再识别算法假设行人图像或视频是在较短时间间隔内拍摄得到的,不存在换装问题.而在实际情况中,不同行人图像之间拍摄时间间隔越大,目标更换服装和随身物品的可能性就越大,识别难度也随之加大.因此,长时行人再识别将是一个值得深入研究的问题.
2)结合多模态生物线索的行人再识别.生物线索包括人脸、步态、整体外观等信息,具有良好的区分能力.受限于环境条件,目前的行人再识别方法过于依赖行人的整体外观信息,而使用单一的生物线索很难达到理想的识别效果.因此,结合多模态生物线索将大大促进行人再识别.
3)密集场景与低分辨率环境下的行人再识别.在现实的复杂监控环境下,行人检测框内往往包含两个甚至更多的行人,这种样本会导致身份匹配上的混乱.另外,受到拍摄距离、设备分辨率等因素的影响,部分行人图像的分辨率较低,导致行人再识别的难度增加.如何克服复杂环境因素的干扰仍需进一步探索.
4)设计鲁棒的语义级行人特征表达.目前的行人再识别性能还远无法令人满意,其根本原因是行人特征的表达能力不足.因此,构建有效的图像特征空间与高层语义空间之间的映射关系,实现对行人图像的语义级描述,将大大提升行人特征的区分性和描述性,在这方面还有很大的研究空间.
5)基于深度属性的行人再识别.基于深度学习的特征表达具有强大的数据描述能力,并且在识别精度和泛化能力上都比传统方法更胜一筹.在深度网络的训练过程中加入属性信息的指导,加强神经元对于不同属性的选择性,将有助于提高深度网络对于高层语义信息的表达能力.目前的研究难点在于如何选择最具代表性的、具有较好语义表达能力的属性,各个属性的组合规律也尚未定论.另外,属性的标注需要大量的人工成本,导致现有数据集属性丰富性比较欠缺.因此,开展基于深度属性的行人再识别将极有可能产生突破性的成果,并最终促进该领域的发展.
