基于多核CPU+GPU运算的电磁场高效体绘制算法研究
2018-09-18陈宇峰
陈宇峰,张 铂,李 林
北京理工大学 计算机学院,北京 100081
1 引言
电磁场被发现以来就一直是人类在生产生活过程中一种重要的物理环境。但是,电磁场难以被人的感官直接感受到,在某种程度上限制了人的观察能力和思考范围。因此,研究如何将这种看不见的电磁场及其与物质相互作用的现象能直接转变为易被人的肉眼观察到的方法,即电磁场可视化方法,具有重要的现实意义。
近年来对以雷达探测范围为例的电磁场可视化的研究取得了日新月异的发展。伴随着计算机图形学的快速发展,雷达探测范围可视化方法已经由传统的数值参数、二维雷达威力图方法转为三维可视化技术[1]。国防科技大学的杨超,陈鹏等人研究了在大气吸收衰减的条件下,雷达探测范围并且生成了三维仿真场景[2]。空军工程大学的张敬卓、袁修久等人为了解决在虚拟战场环境下数据场内密外疏的难题,采用了数据环拼接的方式,最终实现了雷达在虚拟战场环境下自然环境干扰的三维探测范围可视化[3]。但是这些方法采用的都是面绘制,其缺点是边缘提取不准确,并且容易造成数据场信息丢失。如果采用体绘制的方法可视化雷达探测范围,可以很好地保留整体数据场的细节,然而体绘制采用的光线跟踪算法对内存资源需求大,对场景雷达探测范围的碰撞检测效率低,所以并没有被广泛的使用。
体绘制起始于20世纪70年代中期,它是由于医学技术断层投影(CT)、核磁共振(MRI)等发展而兴起的一种可视化技术。在医学领域中,动态体绘制可视化技术庞大的数据量使得计算的复杂度大大提高,基于CUDA的高效体绘制技术可以进一步提高数据处理效率[4]。体绘制也是电磁场可视化仿真领域中的重要组成部分。其优点是不仅仅可以显示高质量的图片,而且这些图片可以表达出三维物体的内部信息,这一点是传统的计算机图形学不可企及的[5-6]。基于以上的优点,体绘制技术更加适用于绘制不可见的数据场信息,例如,人体骨骼密度,雷达探测范围等。然而体绘制方法的缺点就是算法执行的时间效率问题。由于从视点投射出的每一条光线都需要和场景进行碰撞检测,所以体绘制效率改善的关键问题就是改善光线求交运算的碰撞检测效率。
本文采用OSG(Open Scene Graph)作为渲染引擎。采用体绘制技术来可视化雷达探测范围,实验结果表明,OSG引擎对雷达探测范围的体绘制的可视化效果良好。并且在OSG场景中针对体绘制渲染效率慢的缺点,实现了多核CPU+GPU体绘制的并行计算。最终较好地实现了电磁场的可视化,降低了可视化的渲染时间。
2 电磁场探测范围的体绘制
2.1 体绘制方法概述
体绘制是将三维数据场的信息变换生成屏幕上的二维图像。体绘制主要的方法有:
(1)光线投射算法(Ray Casting)。
(2)光线跟踪算法(Splatting)。
(3)频域体绘制算法(Shear-warp)。
(4)硬件辅助的三维纹理映射法(3D Texture Mapping)[7]。
光线跟踪算法是现阶段体绘制使用最多的方法,它是指从三维数据场中的视点绘制出覆盖整个屏幕像素点的光线,并且查找阻挡光线最近的那个物体,然后根据材料的特性以及场景中光线的效果来确定渲染在二维图片上的每一个像素点的颜色值。相比光线投射算法,光线跟踪算法的重点并不是进行色彩的积累,如图1所示,光线跟踪算法仅仅只考虑光线和几何体的相交情况。
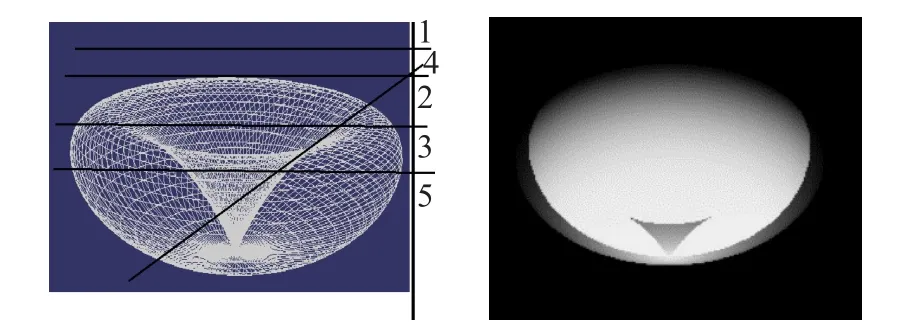
图1 采用光线跟踪算法的电磁场可视化图
本文采用了光线跟踪算法,要求判断每一条光线和模型的交点个数,从而确定二维图像的像素值。因为每一次光线绘制和求交过程中数据之间不存在依赖,所以在光线绘制和求交计算过程是比较好的并行选择。
2.2 电磁场体绘制技术
光线是从视点到屏幕像素点的多条射线。根据交点的个数的不同对交点进行判断,根据式(1)找出一个交点的坐标(xi,yi,zi)。其中(xi,yi,zi)分别表示第i个交点的坐标值,(oxi,oyi,ozi)分别表示第i个交点的雷达波发射中心的坐标值。
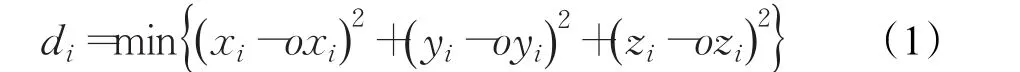
然后根据雷达波能量衰减函数,获得该点的能量函数Pr;Pt表示雷达发射机峰值的功率;Gt表示发射天线增益;Gr表示接收天线增益;σ表示雷达反射截面积;τ表示雷达工作波长。如果假设发射天线增益和接收天线增益相等。式(2)可以表示为如下形式[8]:
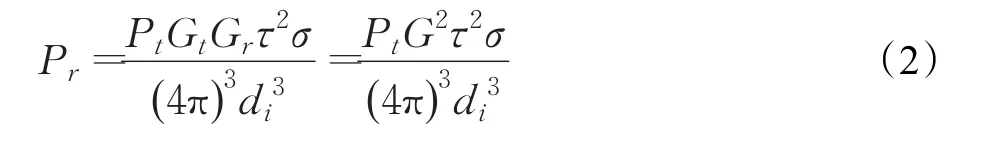
最后按照式(3)将能量值转化为光学属性进行绘制,形成体绘制二维图。其中Pixel表示的是渲染在投影平面上像素点的RGB和∂值。

在上述过程中造成体绘制效率低主要表现在两个方面:(1)在渲染场景中的使用光线跟踪算法绘制光线;(2)光线跟踪算法中光线和雷达波探测范围模型的交点计算。本文针对雷达探测范围体绘制的这两个低效问题进行了改进,主要贡献如下:(1)将电磁场能量值转化为光学属性在计算机中进行绘制;(2)采用GPU进行光线的绘制,采用多核CPU进行光线和电磁场探测范围模型的交点计算。
张文波,曹耀钦等人将体绘制技术创新地运用在电磁场仿真领域,并且采用CUDA将电磁场传播模型(ITM)的计算移植到GPU中进行,最终基于CUDA架构实现了较高的加速比[9]。但是这种方法有两个缺陷:(1)ITM模型是一种高效预测电磁波衰减的模型,文章的加速效果受限于所选取的ITM模型;(2)电磁场体绘制技术的时间开销主要表现在两个方面:①在渲染引擎中绘制光线的计算。②电磁场数据的计算以及交点信息的计算。而上述方法仅仅改进了电磁场数据的计算以及交点计算,对于体绘制信息数据渲染的并行化算法并没有涉及。
而本文针对这两个时间开销都进行了改进。在3.1节中使用GPU提高光线绘制的效率;在3.2节中使用多核CPU提高电磁场数据计算和交点计算效率。实验表明,对于光线绘制效率的改进可以提高模型的可视化效果。
3 基于OSG的光线跟踪并行计算
OSG(OpenSceneGraph)诞生于1990年,是C++编写的、使用标准模板库(STL)作为容器的图形引擎。OSG使用场景图的方法来构造3D世界,其中场景图中的每一个NODE节点都是存在于场景中,并且与场景中的其他节点存在一定的从属关系。OSG最大的优点是模块化和可拓展性,并且容易学习,所以现如今受到了大多数计算机图形学工作者的青睐[10]。
OSG场景图是采用AABB包围盒和包围球技术来实现碰撞检测的相交测试,并且对于碰撞检测进行了类的封装。这种封装对于初学者来说可以快速地实现三维场景的碰撞检测功能,但是其缺点是实现的功能仅限于是OSG自带的碰撞检测方法。如果开发者想要拓展新的方法来提高OSG程序执行的效率,则是非常困难的。
在第2章已经介绍了光线跟踪算法在计算机中耗时最多的两个步骤:(1)光线绘制;(2)相交检测并根据交点的数量绘制像素点的颜色值。本文在3.1节和3.2节分别进行了时间效率的改进。
3.1 基于GPU的光线绘制
CUDA(Compute Unified Device Architecture)是由NVIDIA公司提出的建立在GPU上的统一计算架构。充分利用GPU强大的多线程浮点数计算能力和多计算核心的特点,可以将问题划分为粗放子问题,以并行的方式独立解决[11-12]。文献[13]提出了CUDA所使用的从内存拷贝数据到显存的方法很低效,这也正是使用CUDA架构进行并行计算编程的瓶颈所在。而光线绘制并不需要对大量的数据进行内存到显存的拷贝,因此可以极大地发挥CUDA的多线程浮点数运算的特性。
光线绘制是指在视点和屏幕像素点之间分别绘制射线,射线指向屏幕像素点。视点的位置是固定不变的,因此光线绘制阶段主要的任务就是确定屏幕像素点的坐标值。本文采用CUDA来计算屏幕像素点的坐标值。屏幕像素点的坐标值与如下几个量有关:
(1)投影平面的分辨率。
(2)投影平面的起始点坐标值。
(3)投影平面的像素仿真步长。
(4)场景漫游器camera的坐标值。
以下内容将会介绍在OSG引擎中如何避免文献[13]中提到的数据拷贝效率低下的问题,进一步介绍如何使用CUDA计算屏幕像素点坐标值。
本文光线绘制算法步骤如下:
CUDA输入。投影平面的仿真步长(s_dx),投影平面起始点坐标值(m.x,m.y,m.z),场景漫游器camera的坐标值(p.x,p.y,p.z)。
CUDA输出。绘制完成的若干光线。
步骤1 在显存中申请大小为sizeof(float3)×THREAD_NUM×BLOCK_NUM的空间用于存放计算结果(其中BLOCK_NUM为CUDA内核开启的线程块数量,THREAD_NUM为每个CUDA线程块开启的线程数量)。
步骤2 CUDA计算阶段:申请float3类型的变量dir来表示屏幕像素点的坐标值。
步骤2.1 CUDA的__global__函数中通过threadIdx.x和blockIdx.x函数获得线程和线程块的ID。
tid=threadIdx.x
bid=blockIdx.x
步骤2.2在__global__中分别计算dir的x、y、z坐标值。以计算dir的x值为例:
dir[bid×512+tid].x=(m.x+tid×s_dx)-p.x
步骤3 CUDA光线绘制阶段:根据屏幕像素点的坐标值和camera的坐标值绘制光线向量。
此方法在CUDA内核中开启了多线程,改进了光线绘制在内存中的单线程执行,节省了内存空间,提高了光线绘制效率。
3.2 基于多核CPU的交点计算
在传统的单核CPU架构中,通过提高CPU频率来提高程序运行速度已经使CPU频率发展到了极限。如今越来越多的多核CPU模型被设计出来,以此来充分利用CPU空闲资源。文献[14-15]分析了一些现有的典型计算模型,以Jacobi迭代算法为例,说明了多核CPU模型可以改善运行的性能。文献[16]通过以遗传算法(GP)——机器学习的典型算法之一为例,证明了通过利用cache(高速缓冲存储器),基于多核CPU的GP算法的实现可以达到与GPU同样级别的效率。因此,多核CPU也是重要的计算资源,不应该忽略这种资源。
在本文中,投影平面像素点的颜色值与检测到的交点数目有关。使用OSG+CUDA引擎进行光线交点计算的弊端是:有大量的数据需要从内存拷贝到显存,由于OSG引擎的模块化架构,数据从内存传递到显存的时间消耗要近似等于CUDA提升的计算效率。因此,采用OSG+CUDA架构进行光线跟踪的相交计算并不会很好地提高程序执行的效率。所以,本文采用利用多核CPU来处理交点计算任务。
光线跟踪算法的交点计算部分从原理上说是不存在数据依赖的,因此光线相交计算的每一次迭代都是可以使用多核CPU进行并行化处理的。本文采用OpenMp来实现多核CPU的并行编程。
图2是基于OSG体绘制方法的算法流程图。
4 实验结果
图3是在同一个OSG场景下,关于雷达探测范围面绘制和体绘制效果的对比。其中,图3(a)和(b)是对同一个雷达发射源分别进行面绘制和加速体绘制的结果。从图中可以看出,(a)图中面绘制有明显的块状效果,对背景数据保留得较少,有部分空间数据丢失。(b)图中体绘制的结果比较连续,很好地保留了背景数据。(c)图是投影平面和3D场景的侧视图。

表1 体绘制和加速体绘制耗时关系
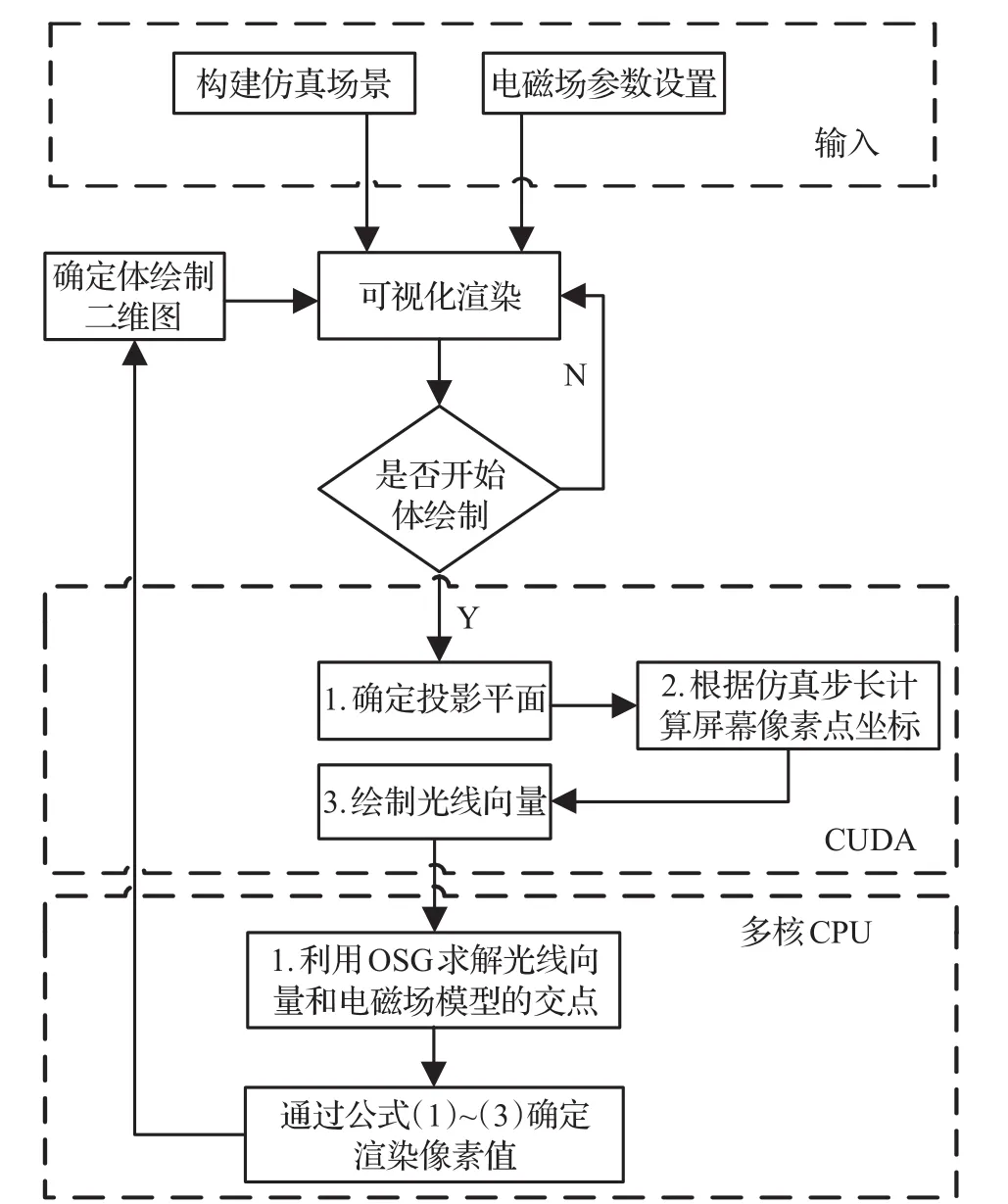
图2 基于OSG实现体绘制计算流程

图3 雷达探测范围面绘制与加速体绘制对比图
运行参数设置:体绘制投影平面分辨率为1 024×1 024,THREAD_NUM设置为512,BLOCK_NUM设置为512,开启8个线程计算射线交点。
(1)GPU:NVIDIA GeForce GTX 750Ti,显存2 GB,显存带宽86.4 GB/s,时钟频率1 020 MHz,渲染到屏幕的像素点率16.3 GPixel/s。现阶段属于中端显卡。
(2)CPU:Inter Core i7 2600,高速缓冲存储器(cache memory)32 KB×4,4核8线程,主频3.4 GHz,峰值时运算能力37.63 GFLOP/s。
分别使用分辨率为512×512、1 024×1 024、2 048×2 048的投影平面进行体绘制,采用以上的配置的计算机进行加速体绘制,结果如表1所示。
从表1中可以看出,对于OSG引擎来实现雷达波探测范围的可视化效率较低。通过GPU光线绘制方法,可以极大程度地提升光线绘制的时间,加速比达到11~18倍。
(1)当投影屏幕分辨率为1 024×1 024时,基于OSG的交点计算耗时明显增加,已经不满足实时性的要求,通过多核CPU+GPU的加速体绘制算法,可以使交点计算的时间缩短到不到8 s。
(2)当投影屏幕分辨率为2 048×2 048时,基于OSG的交点计算耗时已经无法正常测量,采用多核CPU进行交点计算后可以改进这一缺陷。
图4是本算法在大地形战场环境中的应用效果展示图,从图中可以看出对三维数据场的体绘制方法可以保留大量的背景信息。

图4 战场环境中体绘制算法的应用
5 结语
本文针对面绘制三维数据场带来的空间信息丢失问题,采用体绘制算法弥补了这个问题,提高了可视化效果,并利用GPU和多核CPU的并行处理能力提高算法的执行效率。在OSG引擎下,实现了基于多核CPU+GPU的加速体绘制算法。可以完成对电磁场体绘制的实时渲染功能。本算法应用在战场环境的雷达波体绘制仿真中,已经取得了很好的效果。
