基于词向量与可比语料库的双语词典提取研究
2018-03-06柳路芳周凌寒
柳路芳,李 波,陈 鹏,周凌寒,王 兵
(1.华中师范大学计算机学院,湖北 武汉 430079;2.北京吉威时代软件股份有限公司,北京100043)
1 引言
随着世界经济一体化的持续推进,不同国家和地区的人们交流日趋频繁,跨语言交流中的语言不通问题亟待解决,而传统的语言学习、翻译方式越来越不能适应当今快节奏的生活。在这样的背景下,利用计算机技术来进行跨语言自然语言的自动处理研究变得愈发重要和有价值。在跨语言自然语言处理应用中,双语词典是一项基本资源,具有极其重要的作用。传统的人工方法或基于平行语料库构建双语词典的方法开销较大,且构建的双语词典在时效性和完整性方面不甚理想。近年来,使用计算机技术自动提取双语词典得到了许多研究人员的关注[1]。
一般而言,双语词典提取方法按照所使用的语料库类型进行划分,可以分为以下两类:
第一类为基于平行语料库的方法。该方法将平行语料库作为语料资源,利用平行语料库中的文档对齐信息来进行双语词典提取[2],平行语料库有高质量的互译信息,故在构建双语词典的过程中具有较好的提取效果。但平行语料库存在构建困难的不足,目前平行语料库仅存在于少数语种和领域中,严重影响了该方法的推广使用[3]。
第二类为基于可比语料库的方法。可比语料库中含有大量交叉却又非严格互译的信息,这些互译词语基本出现在语义相近但语言不同的上下文环境中,这也是该抽取方法的基础[4,5]。可比语料库易于获取,覆盖范围广泛,相较于基于平行语料库的方法,在互联网技术不断发展的今天,具有更大的发展空间。
现阶段,基于可比语料库的双语词典抽取相关研究还不够成熟,抽取算法的性能还不能满足实际应用的需求,且大部分研究都集中在特定领域的相关专业术语的抽取。因此,近来有许多学者对其进行优化改进,尤其是最近神经网络算法被应用在机器学习等相关领域并取得了非常好的效果,其在自然语言处理领域应用的代表性成果之一——词向量[6],逐步被广泛应用在语义扩展和情感分析等领域中,在单语种环境中可以对两个词语的词向量直接计算相似度且兼顾平滑功能。鉴于此,本文提出了一种基于词向量与可比语料库的双语词典抽取方法,在一定程度上提升了双语词典的提取准确率。
2 基本假设与相关研究
2.1 基本假设
Rapp等人[7]研究表明,在单语种文本中一个单词尽管会出现在不同的文本中,但是与之共同出现的单词集合是大体相同的,也就是说词语之间的相关关系具有稳定性,后来,有其他研究者将这种相关性扩展到了多种语言中。因此,对于可比语料库中单词之间的相关性,本文做出以下假设:

(2)单词之间的相关性具有对称性。即单词w1和单词w2的相关度与单词w2和单词w1的相关度相同。
2.2 相关研究
目前,基于可比语料库的双语词典抽取算法主要有以下几种:
(1)Tanaka等人[8]提出的基于中间语言的算法。Tanaka等人提出了一种利用中间语言从可比语料库中进行双语词典提取的方法,其主要思想是通过一种相对通用的语言如英语等作为中间语言,然后利用这种中间语言的词表将源语言的单词转换为中间语言,再将转换后的单词转换到目标语言,最终完成双语词典的提取。然而,这种方法是基于单个单词的,其抽取效果受中间语言的词表的影响较大,在实际应用中,单个的单词常常不能表达一个比较完整的含义,而是需要与其他单词结合起来才能表达一个完整的含义,不同的单词组合则表达不同的含义。因此,这种基于单词表的抽取算法的抽取效果不甚理想。
(2)Rapp等人[9]提出的基于词语关系矩阵的算法。基于2.1节的假设,在单语环境中,单词与单词之间存在一定的相关性,因此可以通过先确定源语言语料中的单词与种子词典中源语言单词之间的相关性以及目标语言语料库中的单词与种子词典中目标语言单词之间的相关性来间接确定源语言与目标语言之间的相关性。基于此,Rapp等人提出了基于词语关系矩阵的方法从可比语料库中提取双语词典,其基本思想是通过构建源语言和目标语言的单词共现矩阵,然后通过计算矩阵的相似度来得出源语言和目标语言的相似度。
(3)Fung等人[10]提出的基于上下文空间模型的算法。Fung等人在上述Rapp等人的思想的基础上通过向量空间模型完成了双语词典抽取工作。其基本思想是首先为两种语言语料库中的所有单词构建上下文向量,向量中包含了与该词共同出现的单词信息并且这里的上下文窗口大小不是固定的,它根据单词出现的次数的不同而变化;然后根据一些已知的互译词对完成源语言向量到目标语言向量的映射;接着在目标语言向量空间中将转换后的向量与目标语言中所有单词的向量计算相似度并排序;最终根据排序结果获取候选翻译,从而获得双语词典。由于向量空间模型的原理较为简单,因此许多研究者利用已知的多语种互译词对以及高可比性的语料等外部资源对该模型进行了一系列的优化和改进,并将其应用于各种特定的自然语言处理任务中。
(4)Mikolov等人[11]提出的基于词向量的算法。Mikolov等人于2013年提出了一种将单词进行向量化表示的方式,具体做法是利用神经网络语言模型以及Google海量的语料库将单词训练成为一个低维的实数向量。同时,他利用这种方式将两种语言的语料库中的单词分别表示成词向量,从而构成了源语言和目标语言向量空间,并证明了两个向量空间之间存在线性关系。基于此,通过训练一个线性转换矩阵实现了从源语言向量空间到目标语言向量空间的转换,最后计算词向量之间的相似度通过相似度排名来完成双语词典的提取工作。实验表明,与其他抽取算法相比,其抽取准确率有了较大幅度的提升。
3 基于词间关系的双语词典抽取
根据2.1节所描述的基本假设,我们将单词之间的相关性作为区分单词的重要特征,提出了一种基于词向量利用词语间关系进行可比语料库中双语词典抽取的方法。其基本思路是:
(1)将源语言和目标语言语料库中的词语训练成词向量;
(2)将(1)中转换后得到的词向量结合已知的种子词典构建词间关系矩阵,从而使源语言与目标语言关联起来;
(3)计算(2)中源语言单词与目标语言单词之间的词间关系向量的相似度,获得两种语言中两个单词之间互译程度的量化结果;
(4)对相似度进行排序,选取相似度最大的前N个单词作为源语言中该单词的翻译候选集合。
算法具体流程如图1所示。
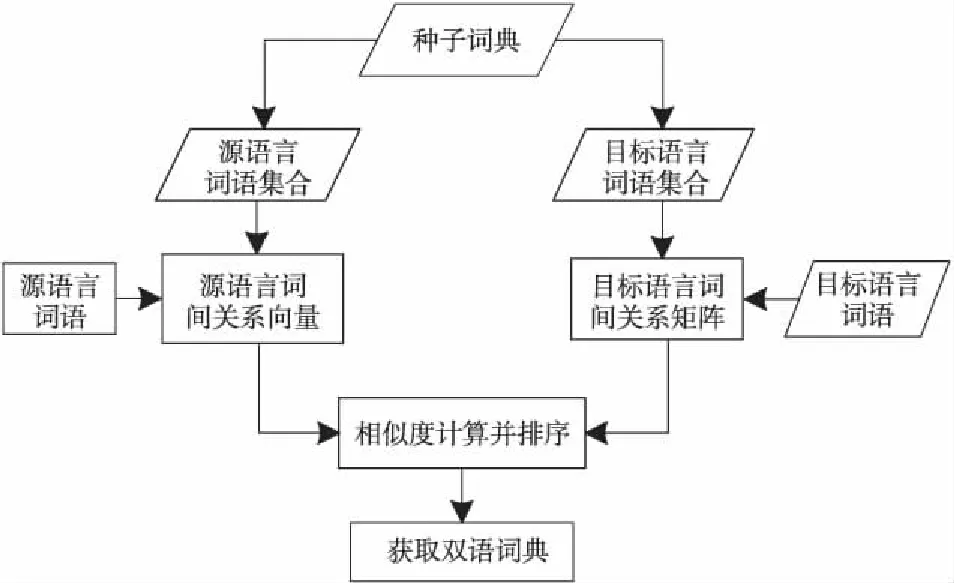
Figure 1 Bilingual lexicon extraction based on words’ correlation 图1 基于词间关系的双语词典抽取
如图1所示,该抽取算法的具体步骤如下:
(1)从通用双语词典中抽取种子词。设种子词对的数量为n,则形成的种子集合表示为{wsi,wti},i∈{1,2,…,n},ws为源语言单词,wt为ws在目标语言中对应的翻译,i为单词ws在种子词典中的索引。
(2)通过已构建的源语言词向量构建源语言语料中每个单词与种子词典中源语言单词的相关度。设种子词典中的单词对数目为k,源语言语料库中单词的词向量为n维,则种子词典中源语言单词集合可表示为{ws1,ws2,…,wsk},其对应的词向量表示为{vs1,vs2,…,vsk},vsi∈Rm,i∈{1,2,…,k}。对于源语言语料库中的某一个测试单词wsx及其对应的词向量表示vsx(vsx∈Rm),其与种子词语集合中的每个词语相关度量化表示如下:
M(vsx,vsi)=∑1 j∈{1,2,…,k} (1) 其中,vsi∈{vs1,vs2,…,vsk},vsxj和vsij分别表示词向量vsx和vsi的第j维分量。 假设上述计算完成后得到的未知单词wsx与种子词语集合的相关度向量用vms表示,其中vms第j维分量的值即表示其与源语言种子词语集合中下标索引值为j的源语言词语的相关度值,且vms∈Rk。 (3)通过已构建的目标语言词向量构建目标语言语料中每个单词与种子词典中目标语单词的相关度。设与源语言使用相同的种子词典,且目标语言语料库中单词的词向量为m维,则种子词典中源语言单词集合可表示为{wt1,wt2,…,wtk},其对应的词向量表示为{vt1,vt2,…,vtk},vti∈Rn,i∈{1,2,…,k}。对于目标语言语料库中的某一个未知单词wtx及其对应的词向量vtx(vtx∈Rn),其与种子词语集合中的每个词语相关度量化表示与源语言相同。 同样假设计算后得到的未知词语wtx与种子词语集合的相关度向量用vmt表示,其中第j维分量的值即表示其与目标语言种子词语集合中下标索引值为j的目标语言词语的相关度值,且vmt∈Rk。最终将目标语言语料库中的每个单词都计算过后即可形成目标语言词间关系矩阵。 (4)根据(3)中得到的目标语言词间关系矩阵,计算源语言词间关系向量vms与目标语言词间关系向量vmt的相似度。根据其相似度的大小来判断二者之间是否为互译关系,相似度越大,其被视为互为翻译的可能性越大。本文采用了夹角余弦公式计算两个向量之间的相似度,其计算公式如下: (2) 其中,vmsi是指源语言单词在第i维上的分量,vmti是指目标语言单词在第i维上的分量,m是指该源语言单词与目标语言单词都有分量的维数,n指源语言单词有分量的维数。 《资治通鉴》选取史料固然严谨,但也存在瑕疵。如何决定材料与记录的真实可靠,往往不可依据权威,而要看材料是否原始。如果有几种相关纪录,可以通过对照比勘看出问题。对于非正史材料,应该谨慎地考察,没有实据,不如用既有材料。唐史史料基本可以追索渊源,不必臆断。在有确实可依的史料时,我们依据最初记录,这是比较可靠的。 (5)对上述得到的相似度进行排序,选取前N个词语作为源语言单词wsx的候选翻译集合,最终完成双语词典的提取。 我们的实验选择英文和法文两个语种,并将英文作为源语言,法文作为目标语言。考虑到语料收集的难度,我们使用跨语言信息检索论坛(http://www.clef-campaign.org)上的相关信息作为实验语料,语料库的具体规模如表1所示。 此外,训练词典也是本文实验中的一项重要资源,本文实验中使用的词典来源于Google翻译[12],具体介绍如表2所示。 Table 1 Experimental corpus Table 2 Training dictionary size 本文实验首先需要对语料库进行预处理。其中主要的预处理工作包括: (1)去除文本中无用的特殊符号; (2)根据指定停用词词表去除文本中停用词; (3)因为本实验只采用语料库中特定词性的单词,因此需要对源语言和目标语言语料库中的所有词语做词根还原以及词性标注工作; 然后,需要对语料库中的词语构建词向量。本文首先将语料库以句子为单位进行切分整合,然后利用Mikolov等人[13]提出的Word2vec工具分别对两种语言的词语构建词向量。此外,为了得到更佳的词向量训练效果,在构建词向量时,我们将源语言的词向量空间和目标语言词向量空间设定不同的维度值,最终训练完成后得到两种语言中词语的词向量。 最后,通过计算两个向量之间的相似度,来得到对应的两个单词之间的相关性程度。计算两个K维向量空间中的词向量vs和vt的相似度,在许多实际应用中常常采用余弦夹角公式,假设使用vsi和vti表示词向量vs和vt在第i维的分量,则其计算公式可以表示为: (3) 同时,本文将传统的向量空间模型VSM(Vector Space Model)与基于词向量的词间关系模型WVR(Word Vector Relation)进行对比实验。首先将两种模型的整体抽取效果进行了对比,然后分析了上下文窗口大小、词典大小、词频等因素对两种模型最终抽取准确率的影响。 我们用P@N(前N个候选翻译的准确率)作为评价指标,其计算公式如下: (4) 其中,RT为抽取结果中源语言单词的数目,即在实验中表示的是测试词典的大小;T(wi)是指抽取算法在单词wi上的抽取结果;d(wi)表示单词wi在词典中的翻译集合。‖S‖是指集合S是否为空,为空则其值为0,否则其值为1。 首先,本文实验对比了VSM和WVR两种模型的整体抽取效果,实验过程中我们使用默认参数(即上下文窗口取10,词频为全部词语),其实验结果如图2所示。 Figure 2 Extract results of VSM model and WVR model图2 VSM模型和WVR模型的抽取结果 如图2所示,当使用默认参数时,在不同N值下,WVR模型的准确率相较于VSM模型均有一定的提升,如WVR的P@1约为7.5%,较VSM(3.1%)有着极大的优势。在实际应用中,P@1的性能越好越有利于后续任务的推进,也就具有更高的实际应用意义。 除了整体准确率的比较,我们通过对以往相关文献的梳理和总结,发现上下文窗口大小、种子词典、词频等因素都会对抽取结果产生一定的影响。因此,下面将对这几个因素逐一进行分析。 首先,对于上下文窗口而言,其主要影响的是单词的表达形式及其有效性。比如在VSM模型中,窗口选择太小会影响单词的上下文环境,其上下文向量不能完整表达该单词的语义特征;窗口选择太大又会出现语义冗余,引入太多噪音产生了语义干扰;而对于WVR模型,窗口的大小不同会影响词向量的表达形式,进而影响词语之间的相关性的量化。因此,将上下文窗口的大小作为变量,其他参数设为默认参数(即N取20,词频为全部词频),则上下文窗口对VSM和WVR两种模型最终抽取准确率的影响如图3所示。 Figure 3 Effect of window size on the result of the extraction图3 窗口大小对抽取结果的影响 如图3所示,上下文窗口对词典抽取的准确率具有较大的影响。在初始阶段,VSM和WVR模型的准确率均随着窗口的增大呈现增大的趋势;当窗口大小达到10之后,WVR的准确率在最优值附近波动,趋于稳定状态;而VSM的准确率反而有所下降。造成这种情况的原因可能是VSM的窗口过大引入了过多无用信息,从而影响抽取的准确率,而WVR中窗口大到一定程度后对其词向量的表达影响变小。 其次,种子词典是从源语言到目标语言转换的中间桥梁,其大小对抽取的准确率也有着不容忽视的影响。实验中将种子词典按比例进行划分,其中0.1代表种子词典的1/10,1.0则代表整个种子词典。实验结果如图4所示。从图4中可以看出,随着词典的增大,两种模型的准确率有着不同程度的提升,在种子词典达到原始种子词典的30%(大约3 000)时,WVR的抽取效果达到最优值并趋于稳定状态,并且其最优值明显高于VSM的。由此可见,相较于VSM模型,WVR的抽取效果受种子词典的影响更小,并且用一个较小的种子词典便可完成跨语言空间的转换,从而取得较好的抽取效果。 Figure 4 Effects of seed dictionary size图4 种子词典大小对抽取结果的影响 最后,为了评估词频对抽取效果的影响,本文将测试单词按照词频大小分为高频词、中频词和低频词三个词段。假设wTF表示词频,则具体划分标准为: 如图5所示,在低频词段VSM的抽取效果略好于WVR,但随着词频的增大,WVR的抽取效果明显比VSM更好,尤其在高频词段,WVR的抽取效果有显著的提升,同时也表明WVR方法更适合运用于高频词的双语词典的抽取。 Figure 5 Effects of word frequency图5 词频对抽取结果的影响 本文提出了一种基于可比语料库与词向量的双语词典抽取方法,该方法首先利用Word2vec工具从可比语料库中构建词向量,然后以种子词典为中间桥梁,构建词间关系矩阵,从而评估不同语种之间单词的相关性,最终获取双语词典。同时,本文将传统的向量空间模型作为参考,进行对比实验,实验表明,相较于基本模型,该算法的整体抽取效果在一定范围内有着较为显著的提升。同时,还通过实验分析了上下文窗口大小、种子词典大小和词频对抽取效果的影响,我们发现,上下文窗口大小在一定程度上对两种模型都有较大的影响,当窗口达到一定值时,词间关系模型的准确率达到一个最优值并趋于稳定状态;对于较高词频的单词,词间关系模型的抽取准确率明显高于基本模型;而种子词典对两种模型的影响也是不同的,当词典较小时,词间关系模型就可以完成跨语言空间的转换,从而获取双语词典,其抽取效果明显好于基本模型。虽然本文提出的模型在准确率上有显著的提升,但实验过程中也发现了一些不足之处,如语料库中无用信息过多等。因此,下一步研究方向将集中在如何获取具有高可比度的语料库上,以进一步提高双语词典的抽取效果。 [1] Miangah T M.Automatic term extraction for cross-language information retrieval using a bilingual parallel corpus[C]∥Proc of the 6th International Conference on Informatics and Systems Special Track on Natural Language Processing,2008:81-84. [2] Veskis K. Generation of bilingual lexicons from a parallel corpus[J].Eesti Rakenduslingvistika Uhingu Aastaraamat,2007(3):355-372. [3] Sun Le. Automatic extraction of bilingual term lexicon from parallel corpora[J].Journal of Chinese Information Processing,2000,14(6):33-39.(in Chinese) [4] Tamura A, Watanabe T,Sumita E.Bilingual lexicon extraction from comparable corpora using label propagation[C]∥Proc of Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,2012:24-36. [5] Fung P, Mckeown K.Finding terminology translations from non-parallel corpora[C]∥Proc of Annual Workshop on Very Large Corpora,1997:192-202. [6] Turian J, Ratinov L,Bengio Y.Word representations:A simple and general method for semi-supervised learning[C]∥Proc of the 48th Annual Meeting of the Association for Computational Linguistics,2010:384-394. [7] Rapp R. Identifying word translations in non-parallel texts[C]∥Proc of the 33rd Annual Meeting on Association for Computational Linguistics,1995:320-322. [8] Tanaka K,Umemura K.Construction of a bilingual dictionary intermediated by a third language[C]∥Proc of the 15th Conference on Computational Linguistics,1994:297-303. [9] Rapp R.Automatic identification of word translations from unrelated English and German corpora[C]∥Proc of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics,1999:519-526. [10] Fung P.Compiling bilingual lexicon entries from a non-parallel English-Chinese corpus[C]∥Proc of the 3rd Workshop on Very Large Corpora,2010:173-183. [11] Mikolov T, Le Q V,Sutskever I.Exploiting similarities among languages for machine translation[J].arXiv preprint arXiv,2013:1309-4168. [12] http://translate.google.cn/. [13] Mikolov T.Word2vec project[EB/OL].[2014-11-10].https://code.google.com/p/ word2vec/. 附中文参考文献: [3] 孙乐.平行语料库中双语术语词典的自动抽取[J].中文信息学报,2000,14(6):33-39.4 实验与结果分析
4.1 实验数据与设计


4.2 实验结果与分析




5 结束语
