面向兴趣主题的个性化好友推荐
2018-03-06齐会敏戴大祥
齐会敏,刘 群,戴大祥
(重庆邮电大学重庆市计算机智能重点实验室,重庆 400065)
1 引言
如今,随着互联网的快速发展,网络用户和产生的信息量也成指数级飙升。因此,作为有效过滤冗余信息和锁定目标信息的工具,推荐系统扮演的角色越来越重要。社交网络的出现旨在帮助人们在网上建立虚拟的“朋友圈子”,实现信息共享和交流。然而,在海量的信息中找到“志同道合”的朋友并扩大自己的社交圈,对用户而言变得越来越困难。所以,个性化的好友推荐不仅可以向用户推荐其感兴趣的潜在好友,而且可以提高用户之间的黏性,增强用户体验,是社交网络得以稳固发展的必备功能。本文提出的结合用户兴趣的推荐算法在拥有推荐精度的基础上,提高了用户对推荐结果的满意度。
2 相关工作
目前,推荐系统相关领域的研究主要分为:项目推荐和好友推荐。之前许多社交媒体的研究主要针对项目推荐,所采用的方法主要有基于内容推荐[1]和协同过滤推荐[1 - 3]。而推荐潜在好友的研究相对较少,也是近年来研究的热点,采用的推荐算法主要包括基于用户特征的好友推荐[4]、基于网络拓扑结构的好友推荐[5]以及利用概率矩阵分解进行推荐等方法[6]。
传统的推荐系统广泛地应用于以搜索引擎为代表的信息检索中,或者向用户推荐满足其需求的资源,例如商品、音乐、热点新闻等[7]。而向用户个性化地推荐潜在好友的研究相对较少。目前相关研究大致可以分为三种:基于内容的推荐[8]、基于共同兴趣的推荐[7]和基于网络拓扑结构的推荐。王玙等人[4]通过研究朋友之间的关系提出了基于关系的社交圈检测算法,使拥有相似社交圈的用户更易成为朋友。Jeckmans等人[9]通过计算文本资料内容相似性进行潜在好友推荐。张鹏等人[10]分析用户之间的网络拓扑结构,提出了基于社区划分和用户相似性好友推荐方法。高永兵等人[8]在考虑有效链接和关键词匹配的基础上提出了基于内容和链接的算法进行好友推荐。Liben-Nowell等人[11]通过链路预测为用户推荐好友。He等人[12]通过构建语义网络,找出用户感兴趣主题实现个性化推荐。利用用户之间的网络拓扑结构进行推荐偏重于现实生活中已经认识的人而忽略虚拟网络中感兴趣的潜在好友推荐,社交网络的紧密度和活跃度很难提高。仅根据内容或兴趣相似性为用户推荐能够更好地挖掘“志趣相投”的朋友,但推荐结果很容易被用户忽略或者拒绝,推荐用户的可接受度不高。
相对于陌生人而言,朋友的朋友更可能被认可,用户也更愿意结识有相似主题兴趣的潜在好友。本文提出的算法思想是在有相似兴趣的基础上,结合用户的社交关系进行推荐,即在“朋友的朋友,更可能成为朋友”的理论基础上引入先验概率计算出有相同属性的用户成为朋友的概率,然后结合兴趣主题相似性进行推荐。通过爬取2015年9月新浪微博数据验证本文提出的算法,结果表明,该算法更能保证好友推荐结果的接受度和满意度。
2.1 基于内容的推荐
基于内容的推荐(Content-based Recommendation)是本文涉及的推荐算法,该方法根据用户感兴趣的微博信息,从推荐对象中选择其他特征相似的对象作为推荐结果。这一推荐策略首先提取被推荐对象的兴趣特征信息,然后与用户兴趣特征匹配,匹配度高的对象作为推荐结果。该推荐策略的匹配度得分计算公式如下:
score(u,v)=sim(feature_u,feature_v)
(1)
其中,feature_u表示用户u的兴趣特征向量,feature_v表示用户v的兴趣特征向量。采用的相似性计算方法是余弦相似性[4],如式(2)所示,然后将计算结果按大小排序,推荐给用户。
(2)
2.2 FOF推荐算法
在社交媒体中好友推荐扮演着重要的角色,研究表明,高质量的好友推荐可以提高用户之间的交互,增强用户对社交媒体的忠诚度。目前主要的方法是朋友的朋友推荐算法FOF(Friend-OF-Friend)和最短路径推荐算法,本文主要涉及到FOF推荐算法。基础理论是如果用户A和用户B之间存在一定数量的共同好友,则A和B也可能成为朋友。将y作为好友推荐给x的得分计算方法如公式(3)所示:
score(x,y):=Γ(x)∩Γ(y)
(3)
其中,Γ(x)作为用户x的朋友集合,Γ(y)作为用户y的朋友集合,若y是用户x的推荐列表中的一员,则y在推荐列表中的排名用x、y共同拥有的好友数量来衡量。
3 面向用户兴趣主题的好友推荐算法ITOR
本文提出的面向用户兴趣主题的好友推荐算法ITOR(Topic-Oriented Recommendation base on Interest),主要依赖于上述两个理论基础,首先经过统计分析目标用户的直接好友、一跳好友与目标用户之间的共邻好友以及一跳好友中已经成为目标用户直接好友的用户,利用先验概率的知识计算拥有不同共邻好友数的用户成为目标用户好友的概率。其次,根据k-core分析得出的兴趣主题关键词的分布情况来计算用户之间兴趣的相似性。
3.1 概率理论
Zhang等人[13]提出了基于总概率原则的推荐算法,某用户成为目标用户A好友的总概率的定义如下:
P(A)=∑P(A|xi)P(xi)
(4)
其中,xi(i∈{1,2,3,4,5,…,m})表示用户第i个属性(包括连续性属性和离散性属性)。
计算出成为目标用户好友的每个属性的概率,例如:拥有属性i和j的用户B成为目标用户好友的先验概率分别为0.6和0.8,则用户B成为目标用户好友的概率为1-0.4*0.2=0.92。通过公式(5)[13]得出候选者成为目标用户好友的总概率。
(5)
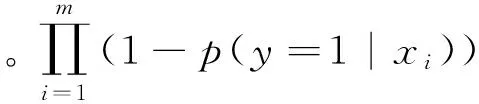
根据大量数据的统计结果分析可知,该属性和对应的概率之间总是表现出一种明显的趋势关系,我们可以通过回归分析计算出该属性对应概率的回归函数,如式(6)所示。
P(x)=F(x)
(6)
其中,F(x)是通过分析统计结果得出的线性函数。
因此,根据目标用户现有的好友关系,我们可以计算出目标用户和每个用户之间的共同邻居数量,目标用户的CN属性的先验概率可以基于目标用户现有的朋友以及FOF所有信息统计得出,如表1所示。
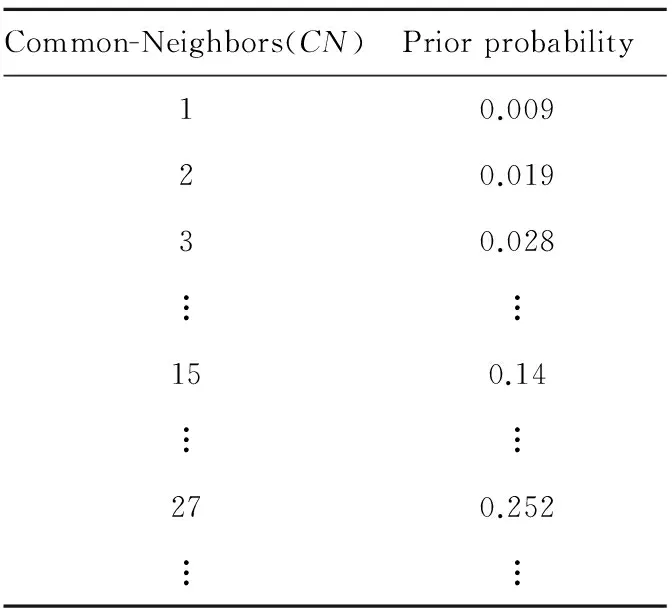
Table 1 Prior probability of Common-Neighbors
在进行线性回归分析前先用SPSS绘制表1中CN和p(CN)对应的散点图,明显可以看出呈线性关系,然后通过线性回归分析的方法,得出方差分析表如表2所示。由于F明显很大,Sig为0.000,即得出相关系数平方略小于1的线性函数,即式(6)中的F(x)。由此证明通过CN计算出的概率值具有可靠性。对于每个候选者通过计算CN和对应的概率P(CN)得出成为目标用户好友的概率,式(6)有效地解决了因查找不到与目标用户CN对应的先验概率而造成无法推荐的问题。

Table 2 Table of Anovab
其中,a.预测变量:(常量)neighber;b.因变量:piror。
3.2 k-core 分析
微博内容是用户传递个人信息途径,很大程度上可以反映用户的兴趣偏好。因此,从微博内容中提取的用户兴趣偏好比兴趣标签更具有准确性。
k-core是基于节点度的凝聚子群[14],如果一个子图的所有节点的度都不小于k,则定义该子图为k-core图。如图1a所示的一个1-core初始图,去除1、2号节点,则变成两个3-core子图。k-core算法可以描述节点位于图的中心位置还是边缘位置,本文以关键词作为节点,关键词的共现关系用节点之间的边表示。节点的k值越大,说明该节点越接近于语义网络的中心,该节点代表的关键词越能表达用户的兴趣主题;k值越小,越不能表达用户的兴趣主题。
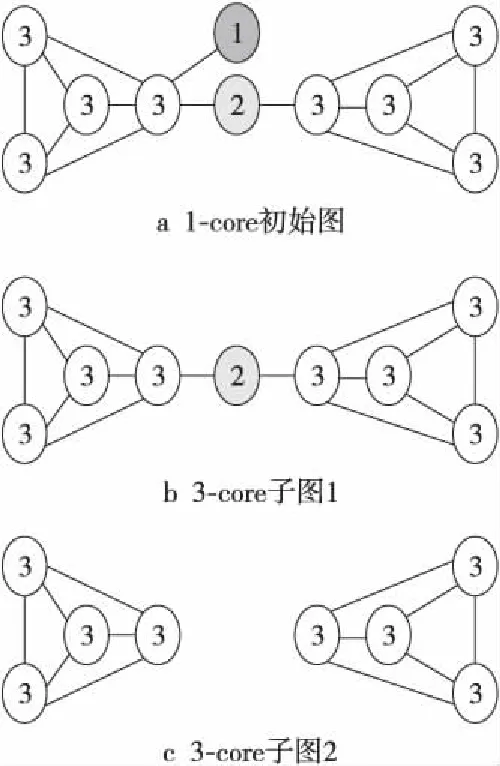
Figure 1 k-core图图1 k-core
从表3可知,用户兴趣特征词构成一个对称的共词矩阵[15,16],例如,用户感兴趣的主题词中“抗战”和“胜利”的共现度是4,“抗战”和“老兵”没有共同出现,即共现度为0。因此,“抗战”节点总的度是与所有主题词与“抗战”共现度总和为12,即节点度的计算公式[14]如式(7)所示。
(7)
其中,co-occurrenceNumi,j表示节点i和节点j共同出现的次数,n是所有节点的个数,di表示i节点的度。通过对节点k-core分析,可得出用户兴趣主题关键词的核分布情况,如图2所示,核心层即代表用户最感兴趣的主题分布情况。

Table 3 Characteristic words and co-word matrix
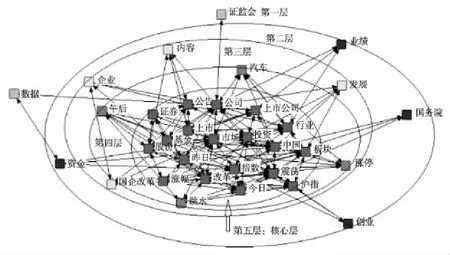
Figure 2 Cores distribution of user’s interest topic-oriented图2 用户兴趣主题的核心分布图
3.3 相似性计算
每个用户关注的兴趣主题不同,由发布的微博内容提取出的兴趣主题词也不同,因此每个用户的兴趣特征向量都具有个性化。所以,我们用兴趣主题词特征向量的相似性来衡量用户关注的兴趣主题相似性。我们利用“有相似兴趣的用户更愿意成为朋友”和“朋友的朋友中有共同属性的用户更可能成为朋友”的理论计算出用户之间成为朋友的可能性。
定义1score(u,v)=α×st(u,v)+(1-α)sp(u,v)表示用户v成为用户u朋友综合得分。其中,st(u,v)表示用户v和用户u兴趣特征相似性,sp(u,v)表示用户v和用户u具有某属性且成为u好友的概率(如表1所示)。

基于以上定义提出的ITOR算法,首先根据微博内容提取用户的兴趣特征,在拥有相似兴趣特征的基础上计算不同CN属性的用户成为目标用户好友的概率,最后综合计算出成为目标用户朋友的score,将排序后的候选者选取TOP-k推荐给目标用户。步骤4到步骤6的时间复杂度为O(N)+O(NlogN)。
算法1面向用户兴趣主题的好友推荐
输入:目标用户vi,用户集合V,用户之间的关注关系。
输出:推荐列表中的TOP-k用户。
步骤1构建用户vi的好友关系,vi朋友的朋友集合为Vt,Vt集合中已经成为用户朋友的集合Vf;
步骤2通过式(4)得出与目标用户vi有共同好友的任意用户vj成为vi好友的先验概率;
步骤3通过k-core分析,初始化用户v的兴趣主题特征;
步骤4FORvj∈V
步骤4.1计算和目标用户vi之间的st相似性以及sp值;
步骤4.2综合考虑st相似性和sp概率,得出成为目标用户好友的总score;
步骤5END FOR
步骤6按照score排序,选取Top-k;
4 实验分析
4.1 数据的获取与处理
新浪API是第三方应用程序接口,在爬取数据时受到访问频率和一次性获取数据量的限制,爬取的数据有很大的局限性。所以,本实验数据是利用模拟登录获取2015年1月到12月的新浪微博内容以及用户之间的关注关系。微博内容发布方式多样化、篇幅短小、口语化等特点,给根据博文内容提取兴趣主题带来很大困难。因此,我们以用户为单位只分析1 000名用户9月份的微博内容以及其对应的关注关系。为了更好地提取用户兴趣主题,我们采取的微博内容处理方式为:首先,删除字数小于15的微博内容。其次,用中国科学院的分词系统(NLPIR)对文本进行分词和停用词处理,根据式(8)计算词频,保留高频关键词。
(8)
其中,I表示词频为1的词的数量。
4.2 评价指标
Top-k的推荐算法中常用到的评价指标是准确率(Precision)、召回率(Recall)和F度量(F-measure)。评价指标的定义如下:
(9)
(10)
其中,hitnum为推荐命中的次数,TestSet为目标用户的真实好友集合,Top-k为向用户推荐的好友数量。
F度量(F-measure)是把准确率和召回率综合考虑的一个衡量值,定义如下所示:
(11)
为了降低实验的复杂度,人为设定α值为0.5,用本文提出的个性化推荐算法ITOR和基于概率原则推荐的算法[13]进行对比分析,分别取Top-k的个数k=2,5,10,20这四种情况进行推荐性能评价。
4.3 实验结果及分析
因为本文提出的算法是基于“共同好友”这一属性基础上结合用户的兴趣进行推荐,是对利用户属性信息强化推荐性能这一算法[13]的改进。所以,实验结果仅对“共同好友”这一属性进行对比分析。
图3显示了在α=0.5时,本文提出的算法和利用属性的先验概率进行好友推荐算法的对比。实验结果表明,当k取5到10时,本文提出的推荐算法效果达到最好,之后随着k值变大,性能逐渐降低。然而,对比算法k值为10性能达到最好但仍小于本文算法的性能,虽然k值为20时对比算法性能优于本文提出的算法性能,但是人们在选择被推荐的好友时一般只关注前两页的用户,之后即便对比算法推荐效果略高于本文算法,由于目标用户几乎不关注那些被推荐的用户,推荐也失去了实际意义。与基于概率原则推荐的算法[13]相比,本文提出的算法偏重于结果的准确度和满意度,增加的时间开销源于算法步骤4文本相似性的计算,总的时间复杂度相差不大。所以,实验结果分析表明本文提出的结合“共邻好友”属性和用户兴趣主题偏好进行推荐的算法具有一定的有效性。
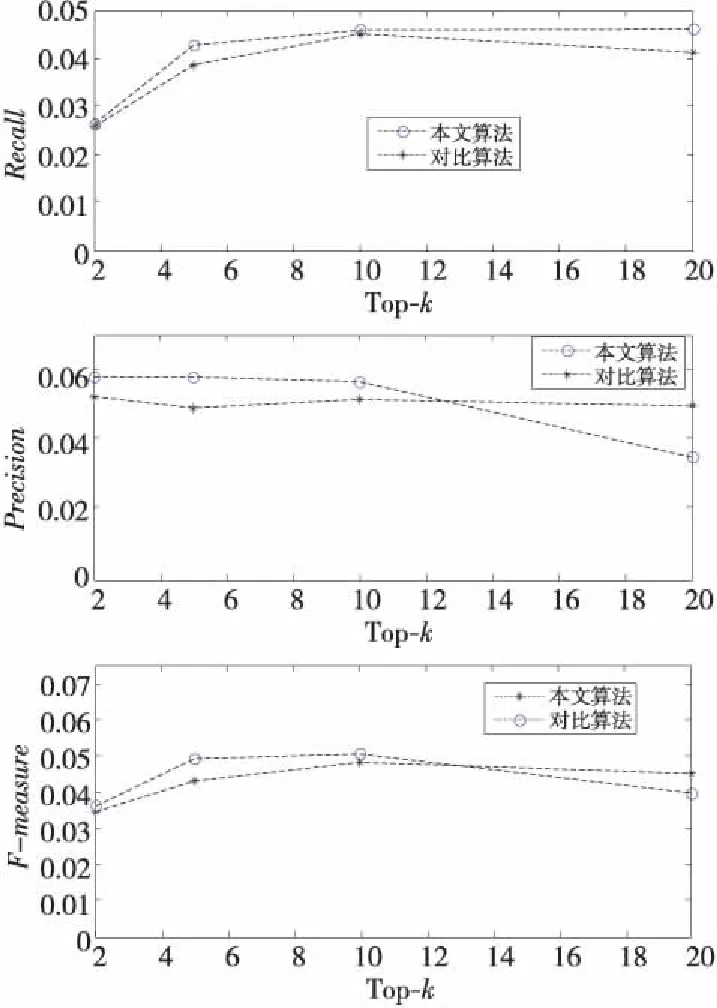
Figure 3 Performance comparison of two algorithms图3 算法性能对比
5 结束语
本文提出一种结合用户社交网络关系和用户兴趣主题相似性的方法来发现社交网络中用户潜在的好友。在“朋友的朋友,更可能成为朋友”的理论基础上引入先验概率,计算出有相同属性的用户成为朋友的概率,然后结合兴趣主题相似性进行荐。新浪数据验证表明,本文提出的算法在一定程度上提高了推荐的性能,具有一定的可行性,结合兴趣的推荐不仅能提高用户对推荐结果的满意度,而且更易于用户接受。
在接下来的工作中,将考虑到α值的优化,降低文本相似度计算的时间开销,采用隐形主题模型LDA(Latent Dirichlet Allocation)提取用户兴趣主题以及用户兴趣的变化等方面问题,根据兴趣变化实时为用户推荐好友。
[1] Yu S J.The dynamic competitive recommendation algorithm in social network services[J].Information Sciences,2012,187(1):1-14.
[2] Ma Hong-wei, Zhang Guang-wei, Li Peng.Survey of collaborative filtering algorithms[J].Journal of Chinese Computer Systems,2009,30(7): 1282-1288.(in Chinese)
[3] Liu F,Hong J L.Use of social network information to enhance collaborative filtering performance[J].Expert Systems with Applications,2010,37(7):4772-4778.
[4] Wang Yu, Gao Lin.Social circle-based algorithm for friend recommendation in online social networks[J].Chinese Journal of Computers,2014,37(4):801-808.(in Chinese)
[5] Armentano M G,Godoy D,Amandi A A.Followee recommendation based on text analysis of micro-blogging activity[J].Information Systems,2013,38(8): 1116-1127.
[6] Jamali M,Ester M.Trustwalker: A random walk model for combining trust-based and item-based recommendation[C]∥Proc of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2009: 397-406.
[7] Weng J,Lim E P,Jiang J,et al.Twitterrank: Finding topic-sensitive influential twitterers[C]∥Proc of the 3rd ACM International Conference on Web Search and Data Mining,2010: 261-270.
[8] Gao Yong-bing, Yang Hong-lei,Liu Chun-xiang,et al.Research on the content and social filtering algorithm for friend recommendation[J].Microcomputer & Its Applications,2013,32(14): 75-78.(in Chinese)
[9] Jeckmans A,Tang Q,Hartel P.Poster: Privacy-preserving profile similarity computation in online social networks[C]∥Proc of ACM Conference on Computer and Communications Security(CCS 2011),2011:793-796.
[10] Zhang Peng, Qiao Xiu-quan,Li Xiao-feng, et al.Friend recommendation based on community dvision and user similarity[EB/OL].[2010-11-02].http:∥www.paper.edu.cn/releasepaper/content/201011-53.(in Chinese)
[11] Liben-Nowell D.An algorithmic approach to social networks[M].Massachusetts:Massachusetts Institute of Technology,2005.
[12] He Y,Tan J.Study on sina micro-blog personalized recommendation based on semantic network[J].Expert Systems with Applications,2015,42(10): 4797-4804.
[13] Zhang Z,Liu Y,Ding W,et al.Proposing a new friend recommendation method,FRUTAI,to enhance social media providers' performance[J].Decision Support Systems,2015,79(C):46-54.
[14] Carmi S,Havlin S,Kirkpatrick S,et al.A model of internet topology using k-shell decomposition[J].Proceedings of the National Academy of Sciences,2007,104(27): 11150-11154.
[15] Su H N,Lee P C.Mapping knowledge structure by keyword co-occurrence: A first look at journal papers in technology foresight[J].Scientometrics,2010,85(1): 65-79.
[16] Hu Chang-ping, Chen Guo. A new feature selection method based on term contribution in co-word analysis[J].New Technology of Library and Information Service,2013,7(8): 89-93.(in Chinese)
附中文参考文献:
[2] 马宏伟,张光卫,李鹏.协同过滤推荐算法综述[J].小型微型计算机系统,2009,30(7): 1282-1288.
[4] 王玙,高琳.基于社交圈的在线社交网络朋友推荐算法[J].计算机学报,2014,37(4):801-808.
[8] 高永兵,杨红磊,刘春祥,等.基于内容与社会过滤的好友推荐算法研究[J].微型机与应用,2013,32(14): 75-78.
[10] 张鹏,乔秀全,李晓峰.基于社区划分和用户相似度的好友推荐[EB/OL].[2010-11-02].http:∥www.paper.edu.cn/releasepaper/content/201011-53.
[16] 胡昌平,陈果.共词分析中的词语贡献度特征选择研究[J].现代图书情报技术,2013,7(8): 89-93.
