基于最大熵模型的越南语交叉歧义消解
2017-10-11熊明明刘艳超郭剑毅余正涛周兰江陈秀琴
熊明明, 刘艳超,郭剑毅,2, 余正涛,2,周兰江,2,陈秀琴
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 智能信息处理重点实验室,云南 昆明 650500;3. 昆明理工大学 国际教育学院,云南 昆明 650093)
基于最大熵模型的越南语交叉歧义消解
熊明明1, 刘艳超1,郭剑毅1,2, 余正涛1,2,周兰江1,2,陈秀琴3
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 智能信息处理重点实验室,云南 昆明 650500;3. 昆明理工大学 国际教育学院,云南 昆明 650093)
越南语中存在大量的交叉歧义片段。为了解决交叉歧义给分词、词性标注、实体识别和机器翻译等带来的影响,该文选取统计特征、上下文特征和歧义字段内部特征,尝试性地构建最大熵模型,对越南语的交叉歧义进行消解。该文通过三种方法整理出包含174 646词条的越南语词典,然后通过正向和逆向最大匹配方法从25 981条人工标注好的越南语分词句子中抽取5 377条歧义字段,分别测试了三类特征对歧义模型的贡献程度,并对歧义字段做五折交叉验证实验,准确率达到了87.86%。同时,与CRFs进行对比实验,结果表明该方法能更有效消解越南语交叉歧义。
交叉歧义;歧义消解;最大熵模型;越南语词典;CRFs
Abstract: To deal with the rich cross ambiguities in Vietnamese, this paper adopts the Maximum Entropy approach using the selected statistical features, contextual features and internal features of the ambiguity segments. It constructs a Vietnamese dictionary of 174 646 entries, which brings about 5 377 segments of cross ambiguities among 25 981 Vietnamese sentences with golden labels. A 5-fold cross validation experiment shows that the accuracy of the proposed method canachieve 87.86% which out performs the CRFs.
Key words: cross ambiguity; disambiguation; maximum entropy model; Vietnamese dictionary; CRFs
收稿日期: 2015-10-25 定稿日期: 2016-03-18
基金项目: 国家自然科学基金(61262041,61472168);云南省自然科学基金(2013FA030)
1 引言
切分歧义在自然语言处理过程中扮演着很重要的角色,比如分词、词性标注、实体识别、机器翻译和信息抽取等。据统计,越南语中包含很多歧义字段,而歧义字段如何正确切分对越南语词法分析来说是一个挑战,直接影响后续环节,比如越南语分词、词性标注等任务。因此,越南语歧义切分在越南语自然语言处理中是一个很重要的任务。
所谓切分歧义就是对某个歧义片段进行正确的分词。在越南语中主要有两种歧义类型: 交叉歧义和组合歧义[1]。由于交叉歧义远远多于组合歧义,且组合歧义的处理难度较大,因此本文只讨论交叉歧义问题。交叉歧义是指当前词素跟前面的词素结合或者跟后面的词素结合都能成词从而引起的歧义。
交叉歧义的消解方法,在对汉语的研究中目前大致可分为以下几类: (1)基于规则的方法[2]; (2)基于字符分类的方法[3]; (3)基于统计的方法[4]。文献[2]中,钟宁等人通过关联规则对交叉歧义进行切分,这种方法只能处理有限的语言现象,取得了一定的效果,但不具备通用性;李蓉等人[3]通过SVM和k-NN相结合的方法,将歧义片段的切分看成是一个分类问题,取得了一定的效果;文献[4]中梁妍采用了词概率统计方法对歧义字段进行切分,取得了一定的成效。
然而,到目前为止,针对越南语的消歧工作才刚刚起步,还没有供学术研究的资源可用,所以有必要对越南语的消歧问题进行研究。Dinh[5]尝试从英语的句法分析树和英语—越南语平行语料库入手,去构建可供训练的歧义语料,但该文献主要是标记英语文本,忽略了越南语特点,并且主要是把这种歧义消解用到了英语—越南语的机器翻译方面;Nguyuen和 Shirai[6]考虑了越南语的特点,并将其融入SVM模型,但它只考虑了越南语词的多义性分类。
如上所述,交叉歧义的消解方法较多,对越南语而言,其不像英语有形态和语态形式,它是一种孤立语言,缺乏形态变化,和中文有一定的相似之处,所以,本文借鉴中文消歧方法,结合越南语特点,选取统计特征、歧义字段上下文特征和歧义字段内部特征,对越南语歧义片段进行准确的切分。另外,由于选取的特征较多,而最大熵模型建模时,只需集中精力选择特征,而不需要花费精力考虑如何使用这些特征,是一个成熟的统计模型,已经在很多领域得到运用[7-8],并取得了较好的效果。因此,本文尝试采用最大熵模型对越南语交叉歧义字段进行建模。
2 越南语交叉歧义字段
2.1 歧义消解的困难与挑战 越南语有其独特的语言特点。越 南 语 中,词 素是最小的语言学单位,一个越南语词可以由一个或者多个词素构成。由于越南语中有的词素单独有多个含义,如越南语词素“bien”有“大海”“招牌”和“很大一群人”三个意思,而且与不同的词素结合又会有不同的意思,所以在确定词边界时会出现歧义现象。如何正确地切分越南语歧义字段是一个挑战。
2.2 交叉歧义字段定义
有两种类型的歧义出现在越南语中,一种是组合歧义,另一种是交叉歧义。分别定义如下。
定义1 若存在越南语字符串“A B”(A和B包含一个或者一个以上音节),如果A、B分别可以单独成词,且A和B合起来也可以成词,这种情况称为组合歧义。如: “Bàn là mt cng cu hoc tp.(桌子是一个学习工具。)” 音节“Bàn”是“桌子”的意思,“là”是“是”的意思,而“Bàn là”又是“铁”的意思。这种歧义很难处理,但是越南语中这种歧义远远少于交叉歧义[9],因此本文只专注于讨论交叉歧义的消解。
2.3 交叉歧义形态
交叉歧义的消解主要有两种情况: 如果存在歧义字段“A B C”,则“A /B C”和“A B/ C”是它的两种切分结果。由于分量A、B和C中所含的词素的个数不确定,导致其表现形式可能有多种,如表1所示。

表1 交叉歧义形态示例

续表
由于歧义字段的音节个数不同,导致其表现形式具有多样性。抽取5 377个歧义片段中的形态进行统计,结果如表2所示。

表2 各个形态特征所占比例
从表2可以看出,表现形式为111、112、211和121的形态特征总和占到总数的98.16%,所以本文只考虑前四种形式的歧义,也就是音节个数为3和4的歧义片段。
2.4 交叉歧义字段获取
有实验结果表明,单纯使用正向最大匹配方法的错误率为0.59%,而逆向最大匹配方法的错误率为0.40%[10]。因此,本文采用正向和逆向最大匹配相结合的方法抽取越南语交叉歧义片段。为了有效的获取歧义片段,越南语词典的完整性是关键的一步。本文使用的词典通过三种方式获取并整合: 第一种方式是前期实验室同学从《新越汉词典》扫描整理得到的词典,包含131 071条词;第二种方式是从越南语网站vdict.com中抽取,然后经过人工方式校对和去重方式获得30 565条词;第三种是从维基百科中抽取,结果包含13 010条实体。三个来源共同组成了包含174 646条词的词典作为本文抽取交叉歧义字段的词典。交叉歧义字段抽取流程如图1所示。
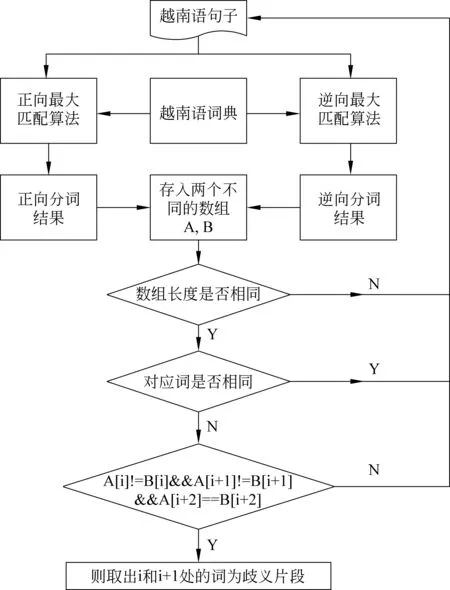
图1 交叉歧义字段抽取流程图
歧义字段抽取的算法如下:
算法 Algorithm Description for getVnAmbiguity
输入: 越南语句子D(D={ S1,S2,S3,…,Sn})
输出: 交叉歧义片段
第一步: 词典匹配分词。分别使用正向和逆向最大匹配方法对越南语句子D进行分词,然后将分词结果分别存到数组A和B中。
第二步: 判断数组长度。判断数组A和数组B的长度,如果两数组长度不相等,则输入下一条句子,执行第一步;如果相等,则执行第三步;
第三步: 判断数组元素。判断数组A和数组B对应元素是否相同,如果相同,则输入下一条句子执行第一步;如果不同,则执行第四步;
第四步: 抽取歧义片段。如果数组A和数组B第i和i+1处的对应元素不相同,且与i+2处对应元素相同,则取出数组A或数组B中的i和i+1处的元素为歧义片段,拼接后保存到List集合中。
3 应用最大熵构建交叉歧义模型
3.1 最大熵理论 在基于特征向量的机器学习算法中,首先需要构建特征向量形式的训练数据格式,然后使用各种机器学习算法来学习,比如支持向量机、最大熵等。本文选用最大熵分类器来得到歧义字段的正确切分。
最大熵模型是最大熵分类器的理论基础,该模型的基本思想就是为所有已知的因素构建模型,并把未知的因素排除在外。它的一个最显著的特点就是不要求特征之间相互独立,可以相对任意地加入对最终分类有用的特征,而不用管它们之间的相互影响;同时,最大熵模型训练的效率相对较高。基于最大熵模型的优点,本文采用最大熵分类器作为解决越南语歧义字段切分的二元分类工具。
在确定一个歧义字段的切分过程中,会涉及各种各样的因素,假设x就是一个由这些因素构成的向量,变量y的值为1(是一种切分方式)或者0(另外一种切分方式)。p(y|x)是指系统对某个歧义字段采用哪种切分方式的概率。这个概率可以用上述思想来估计。最大熵模型要求p(y|x)在满足一定约束的条件下,必须使得下面定义的熵取得最大值,如式(1)所示。

(1)
这里的约束条件实际上就是指所有已知的切分方式,如式(2)所示。
(2)
称fi(x,y)为最大熵模型的特征。n为所有特征的总数。可以看到这些特征描述了向量x与变量y之间的联系。
最终概率输出为:
(3)
其中λi是每个向量的权重,且z(x)的表达式如式(4)所示。

(4)
3.2 特征选取
虽然最大熵模型的特征选择灵活,但是也要保证选择的特征能够反映不同类别之间的差异。在特征选择中,我们着重考虑统计特征、交叉歧义字段的上下文特征和交叉歧义字段内部特征作为本文研究的重点。
3.2.1 统计特征
如果用XYZ来表示交叉歧义片段,则考虑以下四类统计信息: (1)X的独立成词概率是否大于Z; (2)X与Y成词概率是否大于Y与Z; (3)X作为词首的概率是否大于Z作为词尾的概率; (4)Y作为词尾的概率是否大于Y作为词首的概率。以上可以分别作为最大熵模型统计特征,分别定义如下:
以上的概率统计是在已经人工标注好的25 981条越南语分词句子中进行统计计算的。
3.2.2 交叉歧义的上下文特征

3.2.3 交叉歧义字段内部特征

4 构建消歧模型

表3 交叉歧义特征选取示例

续表
最大熵模型的训练文件的格式如图2所示。
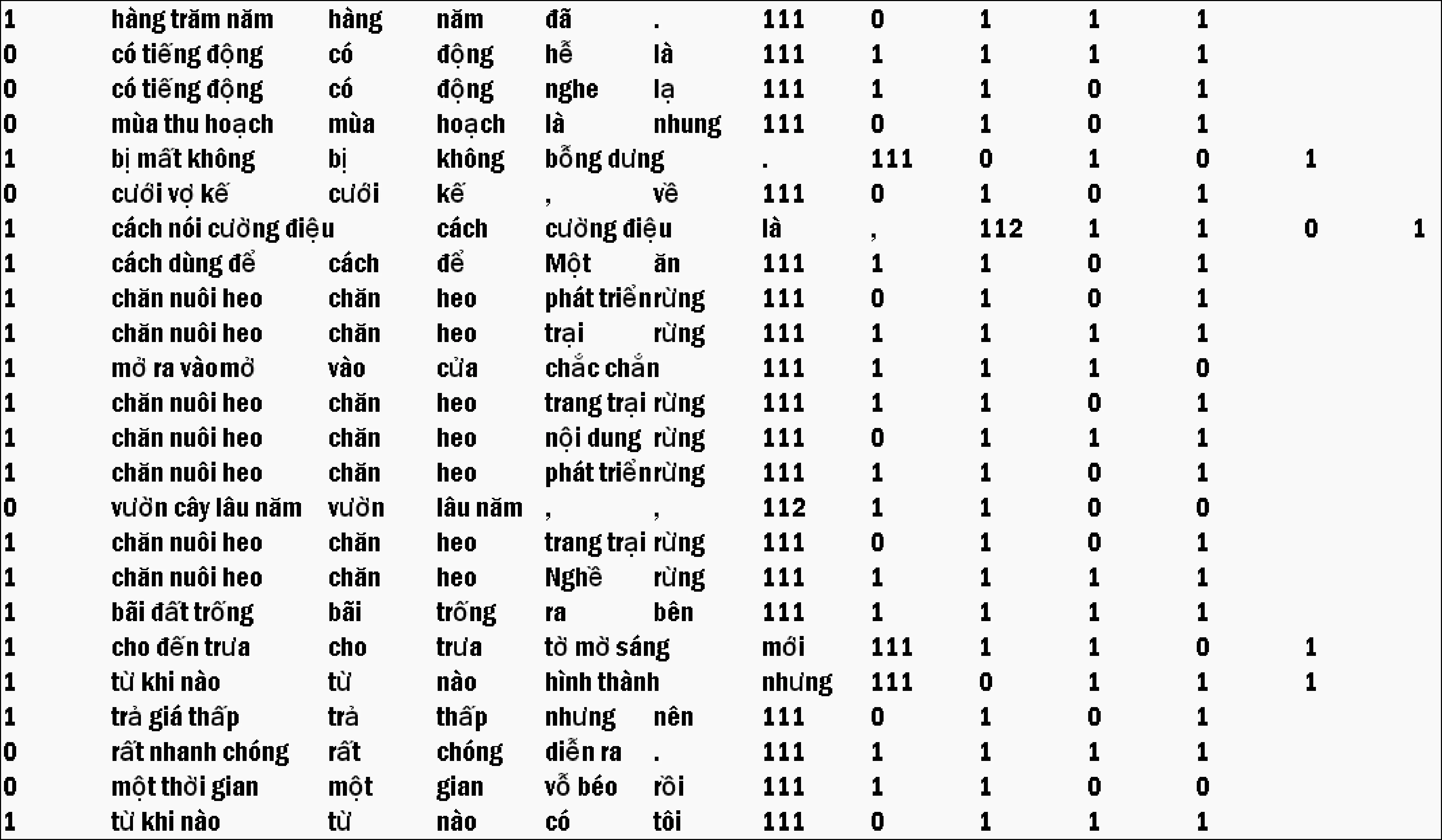
图2 交叉歧义模型的训练文件
图2的训练文件中列与列之间用制表符“ ”分开。设歧义字段为“ABC”,第一列中的1,表示切分方式“A/BC”,0表示切分方式为: “AB/C”。第二列是歧义字段,第三列到最后一列分别表示表3中的三类特征。
5 实验结果及分析
5.1 实验语料的选取 本文采用的主要语料是通过在越南新闻网站收集的越南语句子作为训练语料和测试语料,收集的网页经过规则提取、去重、机器标注和人工校对等步骤形成文本语料库,其规模为25 981条句子。人工标注分词的句子有25 981条。通过词典的正向和逆向最大匹配方式获取歧义字段5 377条,包含174 646词条的越南语词典。所有语料的编码方式均采用UTF-8。
5.2 实验设计
目前,还没有关于越南语交叉歧义切分的文章,所以实验没法和其他方法进行比较,所有实验都是在本实验室自行获取的语料上进行。本文通过三组实验对本文提出的消解模型进行了验证。
实验1 用选取的统计特征、歧义字段上下文特征和歧义字段内部特征分别实验,然后用评价标准评价各个特征的贡献程度;
实验2 把抽取的5 377条越南语交叉歧义片段,均分成五份,做五折交叉验证实验,用平均准确率评价消解模型;
实验3 采用CRFs训练模型,并与最大熵训练模型进行对比实验。
5.3 实验测评标准
实验采用准确率作为对歧义模型的测评标准,准确率为正确的消歧结果。定义如式(9)所示。
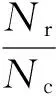
(9)
其中,Nr为测试语料中切分正确的歧义片段的个数,Nc为测试语料中的歧义片段总数。
5.4 各个特征贡献度实验
为了弄清楚三类特征对歧义模型的贡献度,我们将统计特征、上下文特征和内部特征分别作为独立特征构建最大熵模型,各个特征的贡献度通过准确率进行比较,如表4所示。

表4 三类特征的贡献度
从表4可以看出,独立使用统计特征构建歧义模型时的准确率为69.67%,比独立使用上下文特征高出4.13%,比独立使用内部特征高出13.30%。由此可见,4类统计信息对歧义的正确切分有巨大影响,然后是上下文特征,最后是内部特征。
5.5 五倍交叉验证实验
为了评估歧义模型的效果,我们将5 377条歧义字段分为五份,其中一份做测试语料,另外四份作为训练语料,做五折交叉验证实验,然后求平均准确率,作为歧义模型的测评结果。实验结果如表5所示。

表5 五倍交叉验证实验结果
从表5中可以看出,实验2的准确率达到了89.39%,为局部最高。对五折交叉验证的实验结果求平均,得到歧义模型的准确率为87.86%。
5.6 模型对比实验
为了进一步评估歧义模型的效果,我们同时也用CRFs分别对歧义片段构建切分模型,用平均准确率与最大熵模型进行对比实验。实验结果如表6所示。

表6 模型对比实验结果
从表6中可以看出,通过最大熵训练得到的切分模型的平均准确率比CRFs高4.32%。可见本文模型模型在切分歧义的消解问题上比CRFs的效果好。
6 结语
本文通过正向和逆向最大匹配方法从人工标注的25 981条越南语分词句子中,抽取了5 377条越南语交叉歧义字段。对歧义字段的形态特征进行了总结和统计,其中由三个和四个词素构成的歧义片段占总歧义片段的98.16%。因此,本文针对包含三个和四个词素的歧义片段进行实验。为了对歧义片段构建歧义模型,本文考虑了统计特征、歧义字段内部特征和歧义字段的上下文特征三个特征将其融入最大熵模型中,从而得到歧义消解模型。为了保证得到效果的准确性,我们把实验数据均分为五份,进行五折交叉验证实验,平均准确率达到了87.86%。与CRFs实验对比也表明了本文方法的有效性。同时,本文还考察了各个特征对模型的贡献度,通过实验发现,统计特征对歧义模型的贡献度最大。下一步工作准备抽取更多的歧义片段,同时考虑其他有效特征,进一步实验。
[1] Phuong, L H, Huyen,N T M, Azim,R,et al. A hybrid approach to word segmentation of Vietnamese texts[C]//Proceedings of the 2nd International Conference on Language and Automata Theory and Applications,Tarragona,Spain. Springer LNCS 5196, 2008: p240-249.
[2] 钟宁,袁鼑荣.基于关联规则的交集型歧义消解算法[J].郑州大学学报(理学版), 2010,42(1): 66-69.
[3] 李蓉,刘少辉,叶世伟,等.基于SVM和k-NN结合的汉语交集型歧义切分方法[J]. 中文信息学报,2001,15(6): 13-18.
[4] 梁妍.基于统计机器学习的中文词法分析研究[D].南开大学博士学位论文,2009.
[5] Dinh. Building a training corpus for word sense disambiguation in English-to-Vietnamese machine translation[C]//Proceedings of the COLING-02 on Machine Translation in Asia Morristown,NJ,USA, Association for Computational Linguistics,2002: 1-7.
[6] Minh Hai Nguyuen,Kiyoaki Shirai.Study on supervied learning of Vietnamese word sense disambiguation classifier[J].Journal of Natural Language Processing,2012,19(1): 25-50.
[7] 于洪志,李亚超,冷本扎西,等. 融合音节特征的最大熵藏文词性标注研究[J].中文信息学报,2013,27(5): 160-165.
[8] 何钟豪,史晓东,黄研洲,等. 引入集成学习的最大熵短语调序模型[J].中文信息学报,2014,28(1): 87-93.
[9] H P Le,T M H Nguyen,A Roussanaly T V. A Hybrid Approach to Word Segmentation of Vietnamese Text[C]//Proceeding of 2nd LATA.
[10] 翟凤文,赫枫龄,左万利.字典与统计相结合的中文分词方法[J]. 小型微型计算机系统,2006.27(9): 1766-1771.

熊明明(1987—),硕士研究生,主要研究领域为自然语言处理。
E-mail: 504609184@qq.com

刘艳超(1990—),硕士研究生,主要研究领域为自然语言处理与信息抽取。
E-mail: 898559856@qq.com

郭剑毅(1964—),通信作者,教授,硕士生导师,主要研究领域为自然语言处理、信息抽取、机器学习等。
Email: gjade86@hotmail.com
Vietnamese Cross Ambiguity Resolution Based on Maximum Entropy Model
XIONG Mingming1, LIU Yanchao1, GUO Jianyi1,2, YU Zhengtao1,2, ZHOU Lanjiang1,2, CHEN Xiuqin3
(1. School of Information Engineering and Automation, Kunming University of Science and Technology, Kunming, Yunnan 650500,China;2. The Key Laboratory of Intelligent Information Processing,Kunming University of Science and Technology, Kunming, Yunnan 650500,China;3. School of International Education,Kunming University of Science and Technology, Kunming, Yunnan 650093,China)
1003-0077(2017)04-0063-07
TP301
A
