论子话题粒度对搜索结果多样化算法的影响
2017-10-11窦志成文继荣
胡 莎,窦志成,文继荣
(1. 西南大学 计算机与信息科学学院,重庆 400715;2. 中国人民大学 信息学院,北京 100086;3. 大数据管理与分析方法研究北京市重点实验室,北京 100086)
论子话题粒度对搜索结果多样化算法的影响
胡 莎1,窦志成2,3,文继荣2,3
(1. 西南大学 计算机与信息科学学院,重庆 400715;2. 中国人民大学 信息学院,北京 100086;3. 大数据管理与分析方法研究北京市重点实验室,北京 100086)
随着生活节奏的加快,用户习惯将简短的查询提交给搜索引擎,并希望搜索引擎能体贴地将自己需要的结果返回在靠前的结果中。面对大量有歧义的或者意义广泛的查询,搜索引擎努力地识别用户意图,并试图用有限的结果取悦更多的用户。为了解决这个问题,搜索结果多样化技术应运而生,其任务是是对搜索结果进行重排序,在有限的搜索结果中满足尽可能多的用户意图。该文重点关注多样化算法中子话题的粒度问题。利用传统方法生成了不同粒度的子话题,并比较了使用不同粒度的子话题对搜索结果多样化算法的影响。实验结果表明,经典多样化算法使用细粒度的子话题时表现更好。
搜索结果多样化;查询意图;子话题
Abstract: The search result diversification re-ranks search results to cover as many user intents as possible in the top ranks. Most intent-aware diversification algorithms use subtopics to diversify results. Focuses on the granularity of subtopics, this paper investigates the performance of diversification algorithms by using subtopics with different granularities. Experimental results show that state-of-the-art diversification algorithms work better by using fine-grained subtopics.
Key words: search result diversification, query intents, subtopics
1 引言
随着互联网信息的快速膨胀,输入一个查询词,搜索引擎通常会找到大量的相关文档。为了尽快找到目标文档,用户都希望自己需要的文档排在尽量靠前的位置。研究发现[1-3],当输入同一个查询词时,不同用户可能在查找不同的内容。例如,查询“人大”,用户可能是要查“中国人民大学”,也可能是要查“全国人民代表大会”。即使搜索引擎能确定用户是找中国人民大学的相关信息,也有很多不同的查找方向,如“人民大学最近新闻”“人民大学招生信息”“人民大学信息学院”等。如何在有限的结果中满足尽可能多的用户需求,是近年信息检索的热点。
为了解决上述问题,两个密切相关的研究方向受到了研究者们的关注: 子话题挖掘技术,即根据查询挖掘用户的实际需求;搜索结果多样化技术,即在有限的结果中覆盖尽可能多的用户需求。一些信息检索机构也组织了该方向相关的竞赛或评测任务,并公开了数据集和评价标注,如TREC Web Track的Diversity task*TREC: http: //plg.uwaterloo.ca/~trecweb/2012.html和NTCIR的IntentIMine task*NTCIR IMine: http: //www.thuir.org/imine/。
在大部分的搜索结果多样化研究中,用户的查询意图被组织成一个子话题集合,其中每一个子话题代表一个用户意图。不同的算法可能采取不同的方式来获取子话题,如用查询的分类作为子话题[4-5],将搜索引擎的查询推荐作为子话题[6-7],或者从文档内容中抽取短语或词组聚类生成子话题[8-9]。
本文主要关注子话题的粒度问题。我 们 发 现,
通过某些传统的子话题生成方法,可生成不同粒度的子话题。一个简单的例子是利用Google suggestions生成子话题。传统的做法是将查询输入Google,抽取其提供的query suggestions作为该查询的子话题,我们称之为粗粒度的子话题。同理,我们将每个子话题分别输入Google并收集其query suggestions,得到子话题的子话题集合,称之为细粒度的子话题。表1展示了对于NTCIR的查询“三毛”(id=13)在Google上取得的粗粒度子话题T1和细粒度子话题T2。

表1 基于Google Suggestions生成的查询“三毛”的粗粒度子话题和细粒度子话题
本文进一步研究了子话题粒度和多样化算法的关系,发现使用不同粒度的子话题,对于多样化算法的表现有直接影响。以表1为例,假设文档d1和d2与子话题“三毛流浪记电影”相关,文档d3和子话题“三毛流浪记电视剧”相关,一个理想的多样化排序为d1→d3→d2。当采用粗粒度子话题时,多样化算法在选择第二个位置的文档时无法区分d2和d3(均与粗粒度子话题“三毛流浪记”相关),可能输出结果d1→d2→d3。此时用细粒度子话题能更好地判断多样性。在另一方面,假设新增文档d4和子话题“三毛作品集下载”相关,一个理想排序为d1→d4→d3→d2。使用细粒度子话题的多样化算法,在选择第二个位置的文档时无法区分d4和d3(不知d3和已选择的d1都与粗粒度子话题“三毛流浪记”相关),可能输出结果d1→d3→d4→d2。此时使用粗粒度子话题,算法输出的排序为d1→d4→d2→d3,避免在第二个位置出错,其结果的多样性更佳。显然,为多样化算法选择合适粒度的子话题,能直接改善多样化的效果。
然而,现有的多样化算法通常直接使用基于某种方法生成的子话题,没有深入考虑子话题粒度对多样化的影响。同时,大多数子话题生成技术重点关注子话题是否能准确覆盖尽可能多的重要用户意图,并未考虑把这些子话题的粒度应用到多样化过程中的影响。因此,研究不同粒度的子话题在多样化算法中的作用,为多样化算法寻找合适粒度的子话题,对基于子话题的搜索结果多样化技术的研究非常重要。
基于以上考虑,本文研究了使用不同粒度的子话题对搜索结果多样化算法的影响。本文分析了常用子话题的粒度,试图为不同的多样化算法找到更适合的子话题粒度,以提升算法的多样化效果。具体地讲,本文利用Google suggestions,生成了三类不同粒度的子话题,即前面介绍的粗粒度子话题和细粒度子话题,以及更细粒度的微粒度子话题。由于本文的重点不是提出新算法,而是为多样化算法寻找最佳子话题粒度。于是,我们选择了两个经典的搜索结果多样化算法xQuAD和PM2,并在NTCIR数据上比较了不同粒度子话题对于两个多样化算法的影响。从NTCIR数据上得到的实验结果表明,与传统的粗粒度子话题相比,使用细粒度的子话题,能直接改善xQuAD和PM2的结果,而使用更进一步的微粒度子话题,在不同的多样性算法上表现并不稳定。因此,使用细粒度的子话题,是一个更好的选择。
2 相关工作
早期的搜索结果多样化研究,通过文档的相似度来含蓄地表现搜索结果的多样性。Carbonell和Goldstein在1998年提出MMR算法(maximal marginal relevance)[10],通过文档内容的余弦相似性计算文档间的相似度,是早期最有影响力的搜索结果多样化工作之一。在文档的排序过程中,MMR权衡文档的相关性和新颖性,试图选择与查询词相关度较高,并且与已选择文档冗余度较低的文档。受此启发,研究者们提出了各种文档相似度的估算方法来实现搜索结果多样性。例如,用Kullback-Leibler divergence来比较文档内容[11],利用吸收马尔可夫链的随机游走模型对文档句子排序[12],基于文档链接结构判断文档间的关系[13]。以上研究研究工作认为,相似的文档会覆盖相似的子话题,但他们并没有明确考虑到底哪些子话题被覆盖。
基于用户意图(子话题)的多样化研究,是近年来比较流行的方法,明确地通过文档对子话题的覆盖情况来描述搜索结果的多样化程度。IA-Select[4]认为文档和查询都可能包含多个子话题,并利用ODP分类*ODP: http: //www.dmoz.org/,获取查询和文档类别相关的子话题(category)。xQuAD[6]采用贪心算法来选择最大化覆盖查询子话题的文档。RxQuAD[5]提出了基于查询子话题相关性的计算方法。PM2[7]将搜索结果多样化划分为两个步骤: 首先找到最需要被覆盖的子话题,然后选择与该子话题最相关的文档。Dang和Croft[9]讨论了单词形式的子话题的多样化算法。Raman等人[14]通过分析后续查询来判断子话题和查询的关系。Yu和Ren[15]将搜索结果多样化模拟为子话题的0~1背包问题。Liang等人[16]利用主题模型来寻找潜在的子话题。在另一方面,研究者们还试图利用各种外部资源来生成不同类别的子话题,以促进搜索结果多样化。例如,根据文档的点击次数判断其所属子话题[17],或者结合不同来源的数据来生成子话题[18-19]。以上的搜索结果多样化研究,主要利用各种不同的子话题来实现多样化算法,而我们的工作,重点在于比较不同粒度的子话题对于多样化算法的影响。
此外,研究者们也试图利用机器学习的相关技术来多样化搜索结果,如结构化SVMs模型[20]和RLTR模型[21]。本文只关注使用子话题的多样化算法。
和本文相关的另一类工作,是子话题挖掘技术[22-25]。尽管这些研究的目的不同,但他们都能生成合理的基于查询或搜索结果的子话题。注意,由于本文的重点是讨论子话题粒度,为了避免子话题挖掘算法的优劣对于子话题粒度的影响,本文选取了一个多样化算法,使用较多的子话题生成方法,即通过Google Suggestions获取子话题[6-7,9]。
3 基于子话题的搜索结果多样化算法
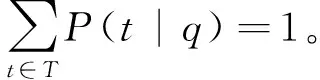
3.1xQuAD算法
xQuAD是主题新颖性模型(topic novelty model)的代表算法。该类模型起源于经典MMR算法[10],其核心思想是在排序中平衡文档相关性和新颖性。即在每次选择最佳文档d*时,不仅考虑待选文档d∈R/S和查询q的相关性,还考虑文档d相对于已选择文档集S在查询q上体现的新颖性。其形式化定义如式(1)所示。
(1)
式(1)中,P(d|q)是待选文档与查询的相关性,Φ(d,S|q)是待选文档d与已选择文档集S在查询q上不相关的概率,即该文档的新颖性。参数λ∈[0,1]控制相关性与新颖性的重要程度。当λ=0.5时,算法认为文档的相关性和新颖性在排序中同样重要;若λ>0.5,算法优先选择新颖性高的文档;若λ<0.5,算法倾向选择相关性高的文档。注意,在选择第一个文档时,已选择文档集为空(S=∅),文档新颖性相同时,算法只考虑文档相关性,选择一个最相关的文档排在最前面。这是大部分现有多样化算法普遍采用的方法。
本文选取的xQuAD算法,由Santos等人[6]在2010年提出,通过子话题的覆盖程度计算文档的新颖性。具体而言,算法首先统计每个子话题t被已选择文档集S覆盖的情况,然后计算待选文档d和子话题之间的相关程度。若文档和未被覆盖的子话题相关程度越高,则该文档的新颖性越高;若文档只和已经被覆盖的子话题相关,即使相关程度非常高,但其新颖性也很低,因为此文档的内容(子话题)已经被前期选出的文档集S覆盖了。如式(2)所示。
(2)
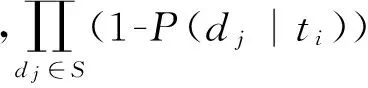
综上所述,xQuAD算法利用文档在子话题中的覆盖情况,计算文档间的相关程度。该算法认为,如果两个文档对子话题的覆盖情况越相似,那么这两个文档就相关。然而,我们发现,对于相同的文档,使用不同粒度的子话题,xQuAD得到文档相关性可能完全不同。继续以表1中的子话题为例,假设文档d1和d2与细粒度子话题“三毛流浪记电影”相关,文档d3和细粒度子话题“三毛流浪记电视剧”相关,文档d4和细粒度子话题“三毛作品集下载”相关。
任务(1) 寻找与d1最相关的文档: 使用粗粒度子话题的xQuAD认为d1、d2和d3都与子话题“三毛流浪记”相关,判断d2和d3都是和d1最相关的文档;使用细粒度子话题的xQuAD发现只有d1和d2属于相同子话题,判断只有d2才是与d1最相关的文档。显然,在任务(1)中,使用细粒度子话题的xQuAD获胜。
任务(2) 寻找与d1最不相关的文档。使用细粒度子话题的xQuAD认为d3和d4都与d1的子话题不同,判断d3和d4都是和d1最不相关的文档;使用粗粒度子话题的xQuAD发现只有d4和d1属于不同子话题,判断d4才是与d1最不相关的文档。于是,在任务(2)中,使用粗粒度子话题的xQuAD获胜。因此,xQuAD对于使用不同粒度子话题是较为敏感的,故本文选用该算法,来测试使用不同粒度子话题对搜索结果多样化的影响。
3.2 PM2算法
PM2是关注主题比例的模型(topic proportionality model)。该类模型认为,一个多样化的搜索结果,其文档包含的子话题分布应该满足某种比例。因此,在每次选择最佳文档d*时,应该优先选择最能改善当前子话题分布的文档。
由Dang和Croft在2012年提出的PM2[7]算法,是主题比例模型的代表算法。该算法将最佳文档的选择过程划分为两个步骤: 首先基于已选择文档的子话题分布情况,选择最需要改善的子话题为最佳子话题t*;然后选择与该子话题尽可能相关,并且与其他子话题比较相关的文档,作为当前的最佳文档d*。
在确定子话题的分布比例时,PM2算法参考了新西兰官方选举时采用的Sainte-Lagu⊇模型*Sainte-Lagu⊇: http: //www.elections.org.nz/voting/mmp/sainte-lague.html。该模型根据党派收到的选票数量来确定党派的席位比例,认为如果一个党派收到的票数越多,目前已有席位越少,则该党派是目前最需要增加席位的党派。同理,子话题的重要性越高,被已选择文档占用的席位越少,则该子话题越需要改善。在选择最佳子话题时,PM2根据子话题ti在查询中的权重P(ti|q),和该子话题ti在已选择文档S中占用的席位si(seat),计算该子话题ti目前需要改善的份额qti(quotient)。具体公式如下:
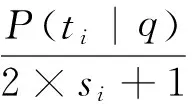
(3)
其中,
(4)
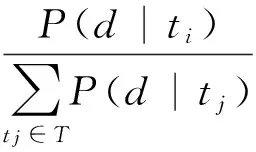
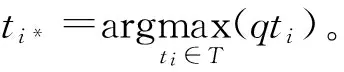
(5)
综上所述,PM2算法利用子话题的占用比例选择最优子话题,并通过最优子话题影响最优文档的选择。我们发现,由于不同粒度子话题本身存在一定差异,使用不同粒度子话题,PM2得到的子话题占有比例很可能不同,选出的最优子话题肯定不同,最终找到的最优文档差别可能更大。继续考虑3.1节中的例子,假设所有子话题的初始比例为均匀分布,已选择的文档为d1,与细粒度子话题“三毛流浪记电影”相关,需要PM2选则下一个最佳文档。使用粗粒度子话题的PM2认为,已被占有的子话题是“三毛流浪记”,下次的文档应该从“三毛作品”中选,于是选择了文档d4(和细粒度子话题“三毛作品集下载”相关)。使用细粒度子话题的PM2认为,已被占有的子话题是“三毛流浪记电影”,子话题“三毛流浪记电视剧”并未被占用,于是选择了文档d3。由于PM2算法本身对子话题的依赖性较强,对于不同粒度的子话题也非常敏感。本文选择在此算法上比较不同粒度的子话题,希望找到一个更合适的子话题粒度,使该算法的表现更稳定。
4 实验
4.1 不同粒度子话题的生成 本文使用Google搜索引擎提供的query suggestions生成子话题[6-7]。在每次抽取query suggestions前,我们清空缓存,以避免Google的个性化推荐功能的影响。
对于每个查询,我们将该查询输入Google并抽取其query suggestions作为子话题T1,称之为粗粒度子话题。随后,我们把T1中的每个子话题依次输入Google,将取得的query suggestions合并为子话题集T2,称之为细粒度子话题。同理,将T2中的子话题输入Google并合并其query suggestions作为子话题集T3,称之为微粒度子话题。我们发现,有时Google对于某些子话题并没有提供query suggestions。即该子话题已经是最细粒度了。此时,我们将该子话题直接加入下一个子话题集合中,以保证两个子话题集合的意义一致性。
若继续重复此过程,我们可以继续获得更细粒度的子话题,在本文中,我们只讨论以上三种粒度的子话题。对于每个查询,我们得到了三个不同粒度的子话题集T1、T2和T3。为了和前人的工作保持一致,我们假设,每个子话题集合中的子话题重要性都是均匀分布的。
4.2 实验设计
4.2.1 数据集 实验使用信息检索竞赛NTCIR-11中的IMine task提供的公开数据。我们使用其中文部分,包含32个有歧义或宽泛的中文查询,以及官方提供的来自SogouT2008*SogouT2008: http: //www.sogou.com/labs/dl/t-e.html的初始搜索结果。注意,在NTCIR数据中,对每个查询,提供两层多样性相关标注: 基于粗粒度子话题的相关评价,基于细粒度子话题的相关评价。
4.2.2 评价标准
实验使用TREC Web Track官方推荐的三个评价标准ERR-IA[26],α-NDCG[27]和NRBP[28],以及NTCIR IMine task提供的官方评价标准D#-measures[29]。实验中,所有评价标准的相关参数均采用官方默认值。实验比较了@5,@10和@20的结果,发现其结果相似。为了节省空间,本文仅报告@20的评价结果。
4.2.3 实验算法
未多样化的基准结果(baseline),传统多样化算法MMR[10],经典多样化算法xQuAD和PM2。其中,MMR通过比较文档内容的冗余来判断新颖性,和子话题无关,在实验中作为基准算法参与比较。传统的xQuAD和PM2算法,使用Google suggestions作为子话题(同4.4节中粗粒度子话题T1)。本文通过Google suggestions提供了三种不同粒度的子话题T1、T2和T3,并将其分别应用于上述两个算法中。我们用xQuAD1、xQuAD2和xQuAD3分别代表使用T1、T2和T3作为子话题的xQuAD算法。同理,我们得到PM21、PM22和PM23。此外,受子话题生成方法影响,本文中粒度较小的子话题包含更多数量的子话题。为了避免子话题数量对算法的影响,我们定义了合并子话题T12=T1∪T2和T123=T1∪T2∪T3,并分别将其应用到算法,记为xQuAD12、PM212、xQuAD123和PM2123。注意,MMR、xQuAD和PM2各有一个可调参数λ,我们用交叉验证分别为各个算法调参数。
4.3 子话题粒度对多样性的影响
本节讨论使用不同粒度的子话题对xQuAD和PM2的影响。实验发现,传统xQuAD和PM2在前50个文档时表现最佳,故本节只比较对前50个文档进行多样化的结果,更多的文档数量的结果将在下节中讨论。表2展示了所有算法在NTCIR数据中的评价结果,包括基于粗粒度用户意图的评价和基于细粒度用户意图的评价。
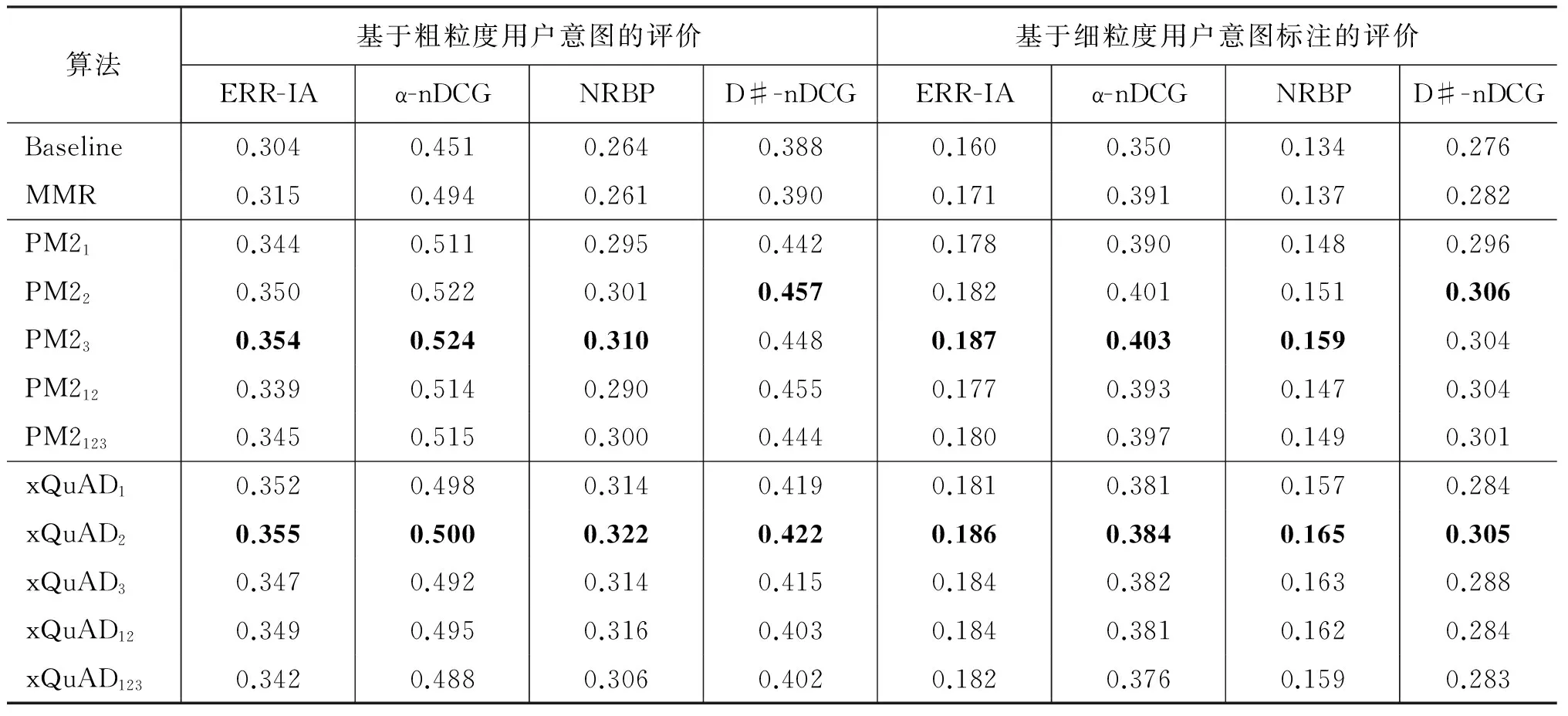
表2 基于不同粒度子话题的算法在NTCIR数据中的结果
注: xQuAD和PM2在每个评价标准上的最佳结果,用黑体表示。
实验结果显示,在PM2相关算法中,PM23在所有评价标准上都取得了最好的结果。在ERR-IA,α-NDCG和NRBP上,PM2相关算法的表现保持一致,即使用微粒度子话题的PM23表现最好,细粒度子话题的PM22其次,传统的粗粒度子话题PM21表现最差。具体地,在基于粗粒度的ERR-IA,α-NDCG和NRBP上,PM23比PM21提升了1%;在基于细粒度的α-NDCG和NRBP上,PM23比PM22提升了1%。同时,在所有评价标准的结果中,PM212比PM22低,PM2123比PM23低,说明引入更多的子话题不能直接改善PM2的结果。因此,PM23的优势是来源于其子话题的粒度。以上结果表明,当使用不同粒度的子话题时,子话题粒度越小,PM2的表现越好,并在使用微粒度子话题时达到最佳。
导致该现象的一个可能的原因是,使用微粒度子话题能帮助PM2模型更好地选择最佳子话题。假设两个极细粒度子话题t1,1,1和t1,1,2来自细粒度子话题t1,1,细粒度子话题t1,1和t1,2来自粗粒度子话题t1,文档d1和d2与t1,1,1相关,文档d3与t1,1,2相关,文档d4与t1,2,1相关。对上述四个文档进行排序时,PM21认为只存在一个子话题t1,所有文档均与其相关,输出结果可能为d1→d2→d3→d4。PM22认为存在两个子话题t1,1和t1,2,其中t1,1相关文档为d1、d2、d3,t1,2的相关文档为d4,最佳子话题的选择顺序可能为t1,1→t1,2→t1,1→t1,1,可能输出结果d1→d4→d2→d3。PM23认为存在三个子话题t1,1,1、t1,1,2、t1,2,1,最佳子话题的选择顺序为t1,1,1→t1,2,1→t1,1,2→t1,1,1,可能输出结果d1→d4→d3→d2。根据多样性定义,应将冗余文档(此处为d2)排在较后的位置,而PM21、PM22、PM23分别将d2排在第2、3、4位,则PM23输出排序的多样性最佳。于是,子话题的粒度越细,PM2模型越能更好地识别文档在更小粒度上的冗余情况,从而提高结果多样性。
在另一方面,xQuAD的实验结果显示,xQuAD2在所有评价标准上的结果均为最佳。此外,当使用不同粒度的用户意图对评价算法时,xQuAD1和xQuAD3的表现不同: 对基于粗粒度用户意图的评价标准ERR-IA,α-NDCG和D#-nDCG,采用粗粒度子话题的xQuAD1较好,极细粒度的xQuAD3较差;对基于细粒度用户意图的所有评价标准,采用微粒度子话题的xQuAD3较好, 粗粒度子话题的xQuAD1较差。同时,xQuAD12和xQuAD123表现较弱,说明xQuAD的表现与子话题的数量没有明显关系。上述结果说明,使用不同粒度子话题的xQuAD,对于评价时选用的真实用户意图的粒度较为敏感: 当使用粗粒度的用户意图做评价时,xQuAD应使用较粗粒度的子话题T1或T2,避免使用微粒度的T3;当使用细粒度的用户意图做评价时,xQuAD应使用较细粒度的子话题T2或T3,避免使用粗粒度的T1。在本文的三类粒度子话题中,子话题T2的粒度居中,其对应的xQuAD算法在两种用户意图的评价中均取得了最佳的表现,是风险最小的子话题粒度。
上述现象的一个可能的原因是,xQuAD算法利用了文档对子话题的覆盖情况来估算文档多样性,而子话题粒度大小对于文档的覆盖情况有直接影响。假设文档d1与子话题t1,1,1和t2,1,1相关,文档d2与子话题t1,1,1和t1,2,1相关,文档d3与子话题t1,1,1和t1,1,2相关,比较上述文档的多样性: 使用粗粒度子话题的xQuAD1认为,d1覆盖了两个子话题t1和t2,d2和d3只覆盖了一个子话题t1,则文档多样性排序为d1>d2=d3;使用细粒度子话题的xQuAD2认为,d1覆盖了两个子话题t1,1和t2,1,d2覆盖了两个子话题t1,1和t1,2,d3只覆盖了一个子话题t1,1,则文档多样性排序为d1=d2>d3;使用微粒度子话题的xQuAD3认为d1、d2、d3都覆盖了两个不同的子话题,其多样性相同d1=d2=d3。显然,当真实用户意图的粒度较粗时,无法分辨极细粒度,用户认为t1,1,1和t1,1,2相同,判断d3只与一个子话题相关,此时xQuAD3不适用;当真实用户意图的粒度较细时,细粒度的区分变得重要,用户认为t1,1,1和t1,2,1不同,判断d2与两个不同子话题相关,此时xQuAD1不适用。而对于xQuAD2,面对粗粒度用户意图时能正确判断d3,面对细粒度用户意图时能正确判断d2,综合表现最佳。于是,使用细粒度的子话题,能帮助xQuAD模型更合理地估算文档对子话题的覆盖情况,在两种用户意图下均能稳定地判断文档多样性,从而提高结果多样性。
4.4 文档数量对不同粒度子话题算法的影响
本节讨论算法在对不同数量的文档进行多样化时的表现,研究文档数量对使用不同粒度子话题算法的影响。实验比较了NTCIR数据上所有评价标准的结果,发现其结果类似,故本文只报告基于粗粒度用户意图的ERR-IA的评价结果。图1展示了使用不同粒度子话题的xQuAD和PM2对不同数量的文档进行多样化的结果。

图1 xQuAD和PM2在对不同数量的文档进行多样化时的ERR-IA结果对比
实验结果显示,xQuAD和PM2在50个文档上表现最好,该结论与前人工作[7]一致。对于xQuAD相关算法,虽然其在不同文档集中的表现不稳定,但当文档数量相同时,表现最佳的都是使用细粒度子话题的xQuAD2,并且参与多样化的文档越多,xQuAD2相对于xQuAD1的优势越大。一个潜在原因是,细粒度子话题的部分新增内容与原查询的相关程度较低,没有出现在靠前的文档中,只有当参与文档的数量够大时,才逐渐有新增内容的相关文档被找到。于是,使用细粒度子话题的xQuAD,在文档数量增加时,能找到更多新颖的文档。
与之不同的是,PM2的相关算法和文档数量的关系较为稳定,随着文档数量的增加,其表现递减。当文档数量相同时,不同粒度的子话题在PM2上表现并不稳定: 在50个文档和100个文档的数据上,PM23表现最好,PM22次之;在150个文档和200个文档的数据上,PM22表现最佳。由于在50个文档中PM23相对于PM22的优势并不明显,因此,对PM2,使用细粒度的子话题是一个更安全的选择。
5 总结
本文关注搜索结果多样化算法中的子话题粒度问题,利用Google suggestions生成了三种不同粒度的子话题,分别称之为粗粒度子话题、细粒度子话题和微粒度子话题,其中粗粒度子话题为传统多样化算法经常使用的子话题。本文将三种子话题运用到经典的搜索结果多样化算法xQuAD和PM2中,比较了不同粒度的子话题对搜索结果多样化算法的影响。从NTCIR数据上得到的实验结果表明,使用细粒度的子话题的多样性算法,比用粗粒度子话题时表现好,比用微粒度子话题时稳定。
[1] Bernard J Jansen, Amanda Spink, Tefko Saracevic. Real life, real users, and real needs: a study and analysis of user queries on the web[J]. Information Processing & Management, 2000,36(2): 207-227.
[2] Dou Z, Song R, Wen J R. A large-scale evaluation and analysis of personalized search strategies[C]//Proceedings of WWW, 2007: 581-590.
[3] Ruihua Song, Zhenxiao Luo, Jianyun Nie, et al. Identification of ambiguous queries in web search[J]. IPM, 2009: 45(2).
[4] Rakesh Agrawal,Sreenivas Gollapudi, Alan Halverson, et al. Diversifying search results[C]//Proceedings of WSDM, 2009.
[5] Saul Vargas, Pablo Castells, DavidVallet. Explicit relevance models in intent-oriented information retrieval diversification[C]//Proceedings of SIGIR, 2012: 75-84.
[6] Rodrygo L T Santos, Craig Macdonald, Iadh Ounis. Exploiting query reformulations for web search result diversification[C]//Proceedings of WWW, 2010: 881-890.
[7] Van Dang, W Bruce Croft. Diversity by proportionality: an election-based approach to search result diversification[C]//Proceedings of SIGIR, 2012: 65-74.
[8] BenCarterette, Praveen Chandar. Probabilistic models of ranking novel documents for faceted topic retrieval[C]//Proceedings of CIKM, Hong Kong, China, 2009: 1287-1296.
[9] Van Dang, W. Bruce Croft. Term level search result diversification[C]//Proceedings of SIGIR, 2013: 603-612.
[10] Jaime Carbonell, Jade Goldstein. The use of MMR, diversity-based reranking for reordering documents and producing summaries[C]//Proceedings of SIGIR, 1998.
[11] Chengxiang Zhai, John Lafferty. A risk minimization framework for information retrieval[J]. IPM, 2006: 42(1): 31-55.
[12] Xiaojin Zhu, Andrew Goldberg, Jurgen Van Gael, et al. Improving diversity in ranking using absorbing random walks[C]//Proceedings of HLT-NAACL, 2007.
[13] Benyu Zhang, Hua Li, Yi Liu, et al. Improving web search results using anity graph[C]//Proceedings of SIGIR, 2005: 504-511.
[14] Karthik Raman, Paul N Bennett, Kevyn Collins-Thompson. Toward whole-session relevance: exploring intrinsic diversity in web search[C]//Proceedings of SIGIR, 2013.
[15] Hai-Tao Yu, Fuji Ren. Search result diversification via filling up multiple knap-sacks[C]//Proceedings of CIKM, Shanghai, China, 2014: 609-618.
[16] Shangsong Liang, Zhaochun Ren, Maarten de Rijke. Fusion helps diversification[C]//Proceedings of SIGIR, 2014: 303-312.
[17] FilipRadlinski, Robert Kleinberg, Thorsten Joachims. Learning diverse rankings with multi-armed bandits[C]//Proceedings of ICML, 2008.
[18] Zhicheng Dou, Sha Hu, Kun Chen, et al. Multi- dimensional search result diversification[C]//Proceedings of WSDM, Hong Kong, China, 2011: 475-484.
[19] Jiyin He, Vera Hollink, Arjen de Vries. Combining implicit and explicit topic representations for result diversification[C]//Proceedings of SIGIR, 2012: 851-860.
[20] Yisong Yue, Thorsten Joachims. Predicting diverse subsets using structural svms[C]//Proceedings of ICML, 2008.
[21] Yadong Zhu, Yanyan Lan, Jiafeng Guo, et al. Learning for search result diversification[C]//Proceedings of SIGIR, 2014: 293-302.
[22] Dawn Lawrie, W. Bruce Croft, Arnold Rosenberg. Finding topic words for hierarchical summarization[C]//Proceedings of SIGIR, New Orleans, Louisiana, USA, 2001: 349-357.
[23] Zhicheng Dou, Sha Hu, Yulong Luo, et al. Finding dimensions for queries[C]//Proceedings of CIKM, 2011.
[24] Yunhua Hu, Yanan Qian, Hang Li, et al. Mining query subtopics from search log data[C]//Proceedings of SIGIR, Portland, Ore-gon, USA, 2012: 305-314.
[25] Shoaib Jameel, Wai Lam. An unsupervised topic segmentation model incorporating word order[C]//Proceedings of SIGIR, Dublin, Ireland, 2013: 203-212.
[26] Olivier Chapelle, Donald Metlzer, Ya Zhang, et al. Expected reciprocal rank for graded relevance[C]//Proceedings of CIKM, Hong Kong, China, 2009: 621-630.
[27] Charles L A Clarke,Maheedhar Kolla, Gordon V Cormack, et al. Novelty and diversity in information retrieval evaluation[C]//Proceedings of SIGIR, 2008: 659-666.
[28] Charles L Clarke,Maheedhar Kolla, Olga Vechtomova. An eectiveness measure for ambiguous and underspecified queries[C]//Proceedings of ICTIR, 2009.
[29] Tetsuya Sakai, Ruihua Song. Evaluating diversified search results using per-intent graded relevance[C]//Proceedings of SIGIR, Beijing, China, 2011: 1043-1052.

胡莎(1985—),博士,讲师,主要研究领域为互联网大数据信息检索,语言本处理,大数据分析和数据挖掘。
E-mail: husha@swu.edu.cn

窦志成(1980—),博士,副教授、博士生导师。主要研究领域为信息检索、自然语言处理、大数据分析和深度学习。
E-mail: dou@ruc.edu.cn

文继荣(1972—),博士,教授,主要研究领域为大数据管理和分析、信息检索、数据挖掘和机器学习。
E-mail: jrwen@ruc.edu.cn
The Impact of Various Grained Subtopics on Search Result Diversification
HU Sha1, DOU Zhicheng2,3, WEN Jirong2,3
(1. College of Computer & Information Science, Southwest University, Chongqing 400715, China;2. Information of School, Renmin University of China, Beijing 100086, China;3. Beijing Key Laboratory of Big Data Management and Analysis Methods, Beijing 100086, China)
1003-0077(2017)04-0165-09
TP311
A
2015-10-12 定稿日期: 2016-03-25
国家重点基础研究发展计划/973计划(2014CB340403);国家自然科学基金(61502501)
