基于深度神经网络的中文命名实体识别
2017-10-11张海楠伍大勇程学旗
张海楠,伍大勇,刘 悦,程学旗
(1. 中国科学院 计算技术研究所,北京 100190; 2. 烟台中科网络技术研究所,山东 烟台 264000)
基于深度神经网络的中文命名实体识别
张海楠1,伍大勇1,刘 悦1,程学旗2
(1. 中国科学院 计算技术研究所,北京 100190; 2. 烟台中科网络技术研究所,山东 烟台 264000)
由于中文词语缺乏明确的边界和大小写特征,单字在不同词语下的意思也不尽相同,较于英文,中文命名实体识别显得更加困难。该文利用词向量的特点,提出了一种用于深度学习框架的字词联合方法,将字特征和词特征统一地结合起来,它弥补了词特征分词错误蔓延和字典稀疏的不足,也改善了字特征因固定窗口大小导致的上下文缺失。在词特征中加入词性信息后,进一步提高了系统的性能。在1998年《人民日报》语料上的实验结果表明,该方法达到了良好的效果,在地名、人名、机构名识别任务上分别提高1.6%、8%、3%,加入词性特征的字词联合方法的F1值可以达到96.8%、94.6%、88.6%。
命名实体识别;深度学习;神经网络;机器学习;词性
Abstract: Chinese NER is challenged by the implicit word boundary, lack of capitalization, and the polysemy of a single character in different words. This paper proposes a novel character-word joint encoding method in a deep learning framework for Chinese NER. It decreases the effect of improper word segmentation and sparse word dictionary in word-only embedding, while improves the results in character-only embedding of context missing. Experiments on the corpus of the Chinese Peoples' Daily Newspaper in 1998 demonstrates a good results: at least 1.6%, 8% and 3% improvements, respectively, in location, person and organization recognition tasks compared with character or word features; and 96.8%, 94.6%, 88.6% in F1, respectively, on location, person and organization recognition tasks if integrated with part of speech feature.
Key words: named entity recognition; deep learning; neural network; machine learning; POS
1 引言
命名实体识别(named entity recognition,NER)是自然语言处理(natural language processing,NLP)的一项基础任务,它的重要作用是从文本中准确地识别出人名、地名、机构名、时间、货币等信息[1],为机器翻译、自动文摘、主题发现、主题跟踪等高级NLP任务提供实用的信息。最初的NER主要采用的是基于规则的识别,通过领域专家和语言学者手工制定有效规则,识别出命名实体。这样的方法仅适用于简单的识别系统,对于复杂的NER,要求规则之间不能产生冲突,因此制定规则会消耗人们大量的时间和精力,且领域迁移性欠佳。因此,随着技术的发展,越来越多的人们采用机器学习的方法来完成NER任务。
近年来,研究者们把NER任务规约为一种序列标注任务[2],对于每一个输入的字,判断其标签类别,根据最终的类别标签判定命名实体的边界和类型。例如,在“SBEIO”策略中,S表示这个字本身就是一个命名实体,B表示该字是命名实体的开始,I表示该字位于命名实体的中间位置,E表示命名实体的结尾,O表示该字不属于命名实体的一部分。序列标注任务有许多适用的机器学习方法,例如,隐马尔科夫模型(hidden markov models, HMM)[3]、最大熵马尔科夫模型(maximum entropy markov models, MEMM )[4]、条件随机场(conditional random fields, CRF)[5]等。这些学习方法需要研究者手工提取有效的语法特征,设定模型的模板进行识别,因此特征模板的选择直接影响NER的结果。Zhou和Su[6]提出使用四种不同的特征去提高HMM在NER的性能。Borthwick[4]等利用了MEMM和额外的知识集合,例如姓氏集,提高了NER标注的准确性。Lafferty[7]等提出CRF用于模式识别和机器学习,后来McCallum和Li[5]提出了特征感应的方法和Viterbi方法,用于寻找最优NER序列。在中文NER领域,存在着一些问题,例如系统的自适应性不强、网页数据复杂、简称机构名识别困难[8]。陈钰枫[9]提出使用双语对齐信息来提高NER性能和双语对齐结果,可以有效提高中文NER的自适应性。邱泉清[10]提出使用CRF模型对微博数据进行命名实体识别,利用知识库和合适的特征模板,取得了良好的效果。本文使用深度神经网络进行NER,可以提高系统的召回率,有效提升系统的自适应性。
机器学习方法需要提取文本特征,如何高效地表示文本的语法和语义特征,是NLP领域亟需解决的问题。近几年,word2vec的提出吸引了无数NLP爱好者的目光。它可以将词语表示成一个固定长度的低维向量,这个向量被认为具有一定的潜在语义信息,近似词语之间具有一定的向量相似性,词向量之间还可以进行加减操作,获得词语之间的语义联系,例如等式“国王-男+女=王后”成立[11]。因此,使用词向量作为输入特征,可以更自然地展示语言的潜在信息,而且不需要手工设置特征模板,对于NER的识别具有一定的积极意义。可以把词向量作为深度神经网络的输入,执行许多NLP任务[12]。深度神经网络是一个用于挖掘潜在有用特征的多层神经网络,网络的每一层的输出是该语句的一种抽象表示,层级越高,表示的信息越抽象。语言本身就是一种抽象的表达,因此采用基于词向量的特征表示,利用深度神经网络进行命名实体识别,可以有效地提高NER的性能[12]。
相较于西方语言如英语的NER,中文命名实体识别显得更加困难,因为中文词语没有明确的边界信息和首字大小写信息。因此,分词错误的漫延和信息缺失会大大降低NER的准确率[13]。中文的字和词都具有其特定的语义信息,相同的字组成不同顺序的词语之间的语义可能差别很大,而且由于词典的不完备性,识别过程中会出现很多的未登录词造成识别的错误,自然地,基于字的命名实体识别方法被提出[14]。但是,基于字的NER也有其自身的局限性。一方面,由于窗口大小的限制,导致无法获得更多的有用信息;另一方面,中文词语具有其特殊的含义,字也有它本身的意义,仅使用字的NER系统无法高效关联出字词之间的联系。因此,我们考虑使用字词结合的方法进行NER。词性是词语的重要属性,词性可以表达更加抽象的词语特征,因此在NER中加入词性特征可以为系统提供更多的有用信息[2],帮助分类算法进行分歧判断。因此,我们提出将词性信息加入特征向量中,该方法可进一步提高中文命名实体识别系统的性能。
本文的主要工作如下: (1)我们提出将深度神经网络应用于中文命名实体识别,该方法可有效提高中文NER的性能; (2)我们利用字向量、词向量的特点,提出了将字词联合的方法用于深度神经网络的中文NER系统; (3)我们方便地在深度神经网络中加入了词性信息,进一步提高了系统的识别性能。
本文的组织结构如下: 第一节介绍了引言及相关工作;第二节主要介绍了深度神经网络的结构和训练方法,详细介绍了字向量、词向量和字词结合向量三种输入特征的表示;第三节对比了不同窗口大小和隐藏节点个数情况下,在字向量、词向量和字词联合向量作为输入特征时,DNN在中文NER上的实验结果;最后一节是本文的结论。
2 深度神经网络
命名实体识别任务可以被抽象为输入的每一个字进行“SBEIO”标签预测的问题。传统的标注方法是人工选择一组适合该任务的特征模板,标注结果的好坏依赖于特征模板的质量。因此,研究者需要学习和掌握语言学知识和领域常识,这会消耗大量的时间、财力和精力。Collobert[12]等提出了一种深度神经网络(deep neural network, DNN)结构,普遍适用于许多NLP标注任务。DNN可以训练一套低维词向量用于词语的特征表示,它不再需要人工设计一个特殊的特征模板,最重要的是词语的向量之间具有潜在的语义关系,因此使用词向量可以提高任务的召回率。除此之外,DNN可以很方便的加入额外的特征信息。所以,我们选择深度神经网络结构进行中文NER任务。
DNN是一个多层的神经网络,它的结构如图1所示。第一层是输入层,它主要负责将输入窗口的字或者词进行词向量的映射,所有出现在字典中的字或者词都有一个固定长度的低维向量,这些向量被存放在Lookup表中,当输入窗口产生新的字词后,输入层将对这些字词进行向量映射,将其按顺序进行组合,获得该窗口下的窗口向量,窗口向量作为DNN第二层的输入。第二层是一个标准的神经网络,它具有两个线性层和一个位于中间的非线性层。第三层是采用Viterbi算法实现的输出层,它主要负责对输入的句子进行最优标签序列的搜索。
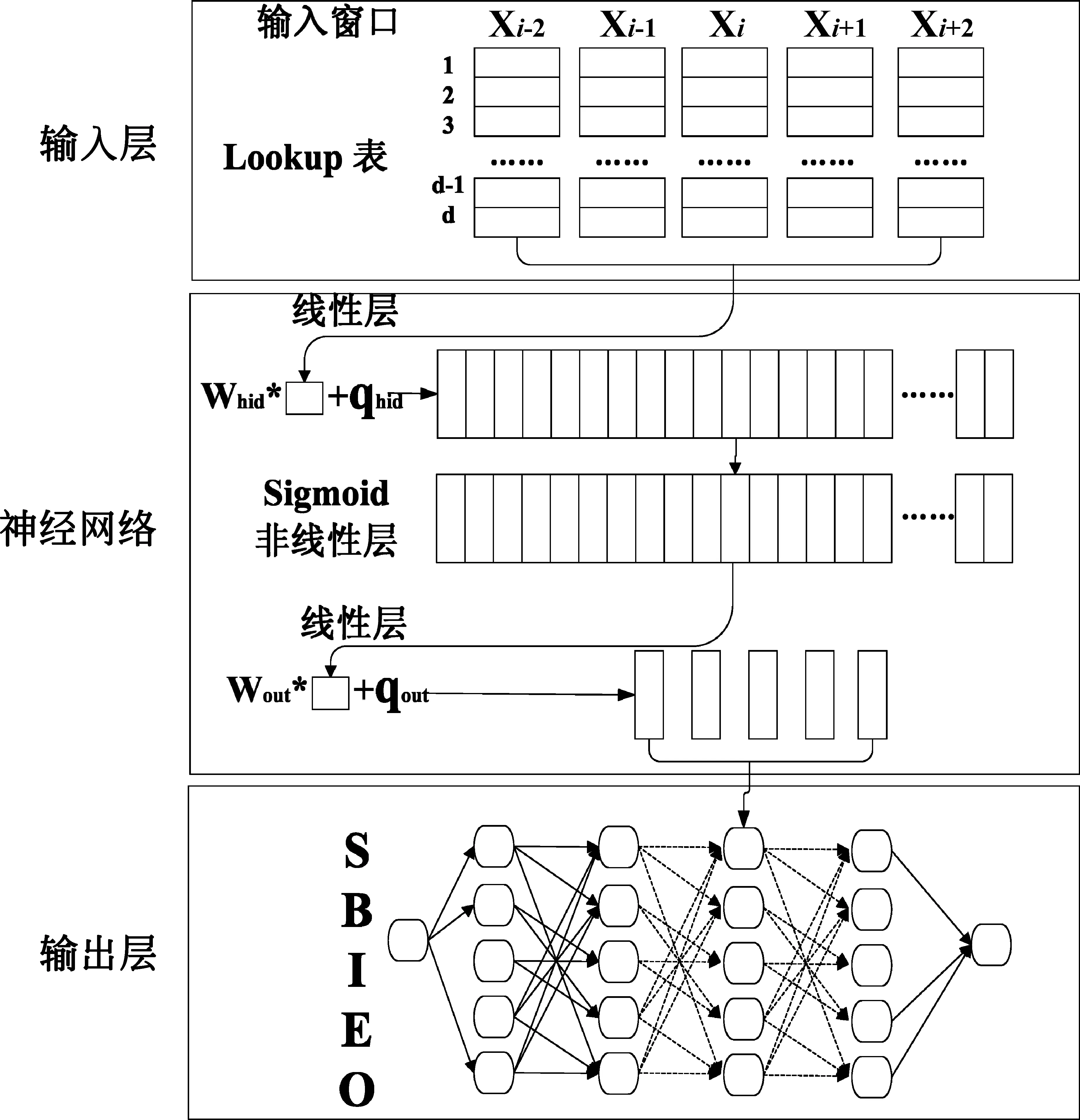
图1 深度神经网络结构图
2.1 词向量特征
我们定义一个字典DC和一个词典DW,所有字向量均保存在字向量矩阵Μc∈Rdc×|DC|中,所有的词向量均保存在词向量矩阵Μw∈Rdw×|DW|中,其中dc和dw分别表示每个字向量和词向量的维度,|DC|和|DW|分别表示字典和词典的大小。
给定一个中文句子c[1∶n],这个句子由n个字ci∈DC,1≤i≤n组成,经过分词以后,这个句子可以被分为m个词语wj∈DW,1≤j≤m。我们使用映射函数Ψc(·)∈Rdc和Ψw(·)∈Rdw,如式(1)、式(2)所示。
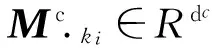
2.1.1 字特征
假定中文句子c[1∶n],首先我们抽取每个字的特征向量作为深度神经网络的输入。对每一个字ci,最简单的方法是直接使用Ψc(ci)作为ci的输入特征,但是每个字的上下文对于这个字所表达的意义具有重要的作用,因此应该尽可能地使用上下文为ci提供更多的信息。由于句子的长短不一,为了适应不同长度的句子,使用滑动窗口的方式进行字特征的提取是合理的。
我们定义字窗口大小为ωc,然后按照从左到右的顺序滑动窗口,对于每一个字ci,它的输入特征定义为:
(3)
如果出现字不在字典中的情况或者超边界,我们将其映射为一个固定的向量,在实验中我们为每一维数值均设定相同的归一化向量。

(4)
假设NER的标签种类用Tc表示,则神经网络的输出是一个|Tc|维的向量。例如,使用“SBEIO”策略则输出层包含五个节点。这个输出向量表示对滑动窗口中字ci预测每个标签的概率。我们可以对每个字按照如式(5)进行概率预测。

(5)
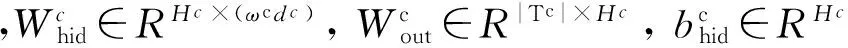
2.1.2 词特征
类似字特征,我们定义词特征窗口为ωw,对于词ωj,它的输入特征可以简单定义为:
(6)
词向量的表示还有一个优点,就是可以方便的添加新的特征。例如,对于词语可以添加词性特征,对于单字可以添加姓氏特征等。由于命名实体的构成依赖于外部语言环境,词性信息可以很好地对词语进行抽象,进一步发现语句的结构联系,所以我们在词特征中加入词性信息,进一步提高NER的性能。
我们定义词性标注集合为POS,现定义一个单位方阵Μp∈R|POS|×|POS|,当词ωj被标记为psj时,其对应的词性序为k,wj的词性向量表示为Ψp(psj)∈R|POS|,它是一个One-hot向量,向量第k值为1,其余全部为0。其映射函数如式(7)所示。
(7)
给定某个中文语句由m个词w[1∶m]组成,词性标注序列为ps[1:m]。那么,词特征可以被定义为:
(8)
带词性的词特征被定义为每个词向量及其词性one-hot向量的拼接,然后首尾相接组成词特征。
2.1.3 字词结合特征
我们选择字词结合的向量主要基于以下两个原因: (1)基于字的NER不能够理解中文汉字的意义,例如“中国”和“印度尼西亚”在仅使用字窗口的情况下,因为窗口限制及字长差异,是无法进行联系扩展并将其正确地识别为地名的; (2)基于词的NER强依赖于分词结果的质量和词典的完备程度,如果分词出现错误会直接影响NER的结果。另外,因为不存在于词典中的词语会被映射为一个特殊的向量,意味着这个词语本身不能够提供任何信息,极有可能造成词语的误判断。因此,我们选择字词结合的方式进行NER,二者之间可以进行有效的互补,从而提高NER系统的识别性能。
设定一种字词映射关系:
ci⊆wj
(9)
其中wj=ci-t…ci…ci+k,t,k≥0。
结合ci的邻近字和wj的上下文,定义字窗口和词窗口大小分别为ωc和ωw,从左至右滑动输入窗口,对于每个字ci⊆wj,它的字词联合输入特征定义为:
(10)
加入词性特征以后的字词联合特征如图2所示,针对“上”字,抽取的5窗口的字特征如图左所示,因为“上”是“上海”的一部分,所以词特征方面是以“上海”为中心的,其窗口的词语如图右所示,关于词性特征,以“上海”是名词为例,词性信息在/n位置显示的是1,其他部分均为0。经过将字特征和词特征进行连接,共同作为“上”的输入特征,进入神经网络进行处理,该输入特征的定义为:
(11)
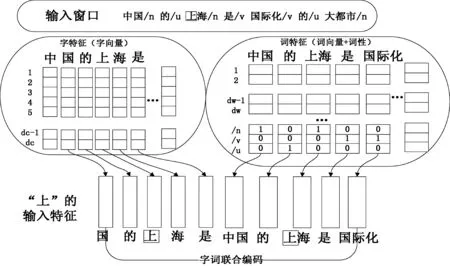
图2 字词联合特征
假设标签集合为T,神经网络的输出为|T|维向量,用于指示输入字ci的标签概率。它的预测函数可以定义为:
(12)
其中Whid∈RH×(ωcdc+ωwdw),bhid∈RH,Wout∈R|T|×H,bout∈R|T|为训练参数,H为隐藏节点个数。
2.2 语句评分
NER的标注结果取决于两个数值,一是神经网络输出层的输出概率,二是标签的转移概率Aij[12]。转移概率Aij表示的是从第i∈T个标签转移到第j∈T个标签的概率,例如B标签后面接E标签的概率要远大于接S标签的概率。对于不会发生的转移,可以采用设置其转移概率为很小的负数来进行简化计算。对于可能出现的转移情况,可以采用随机初始化或者平均初始化其转移概率。最后可以采用Vertibi算法计算最优标签路径。
对于一个给定的句子c[1∶n],神经网络为每一个字输出一个标签概率向量,则对该句子输出层是一个标签概率矩阵score(θ,c[1∶n])∈R|T|×n,其中score(t[i],c[i],θ)表示的是第i个字ci标记为标签ti的概率,其计算方法如式(12)。给定句子c[1∶n],标注的标签t[1∶n],将标签概率和转移概率联合,表示的是整个句子标注得分,该得分定义为:
+score(t[i],c[i],θ)
(13)
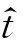
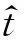
(14)
使用Viterbi算法可以快速计算出句子的最优标签序列。
2.3 梯度下降训练模型
该模型的训练参数为θ={Mc,Mw,Whid,qhid,Wout,qout,Aij},可以选择梯度下降法,对训练集合中的每个训练样本(c,t)进行迭代训练,最大化句子的概率[12]。参数的更新操作如下:
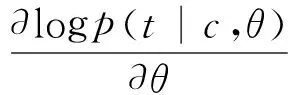
(15)
其中,λ是训练速度,p(·) 是神经网络最终的输出分数[13],t和c分别表示的是标签序列t[1∶n]和输入文本c[1∶n]的简写。p(t|c,θ)表示的是给定句子c标记为序列t的条件概率,我们需要对它进行归一化处理,主要采用softmax方法进行归一化。
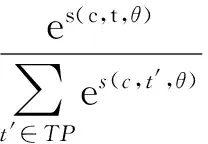
(16)
其中TP表示的是给定句子c,所有可能的标签序列集合。它的对数似然可以表示为:

(17)
随着句子长度的增加,|TP|会迅速增长,虽然计算一次可行路径的耗时是线性的,但是计算所有可行路径却是指数级的。因此我们选用Zheng[15]提出的加速算法,对模型进行更新。
3 实验
我们共进行了三组实验进行人名、地名、机构名的识别,第一组实验的目的是对DNN参数进行选择,第二组实验是对比字向量、词向量和字词结合向量的NER性能,第三组实验是比较加入词性特征后的系统识别性能。
第一组实验选用的是1998年《人民日报》语料1月(RMRB-98-1)的数据,选择前75%共14 860句的数据作为开发训练集,剩余作为开发验证集。第二组实验选用的数据集是1998年《人民日报》语料(RMRB-98)1月至6月的数据,选取80%共100 000句的数据作为训练集,其余部分作为测试集。第三组实验的数据与第二组相同,我们加入一级词性、二级词性特征后,观察识别的F1值的变化情况。除此之外,使用word2vec对新浪新闻*可以在http: //zhangkaixu.github.io/resources.html下载。5个季度635MB的数据进行无监督训练,非线性函数选取的是tanh函数,生成字向量和词向量,分词工具使用的是无字典的ICTCLAS。
实验采用C++编程,运行服务器配置为2.05 GHz AMD Opteron(TM)CPU和8 GB内存,软件使用的是Linux操作系统和g++编译器。实验的评测方法是F1值、准确率、召回率。
3.1 DNN参数实验
我们使用RMRB-98-1作为开发集,对参数的选择进行实验分析。对于人名(PERSON)、地名(LOCA)、机构名(ORGAN)三种识别任务,分别采用字特征(CHAR)、词特征(WORD)、字词联合(CH-WO)特征进行实验,对比在不同窗口大小和不同隐藏层节点的情况下F值的变化情况,实验结果如图2、图3所示。
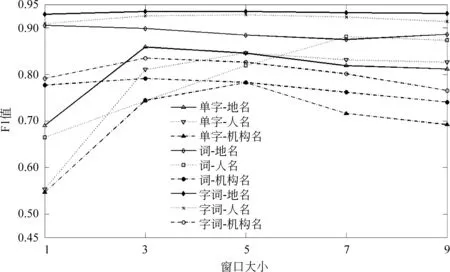
图2 比较不同窗口大小的F1值
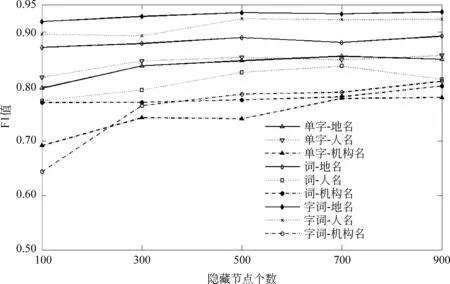
图3 比较不同隐藏节点个数的F1值
从图2可以看出,当窗口大小在3~5时,系统的识别效果较好。我们可以观察到如下现象: 字词结合系统对于大部分识别任务是窗口大小不敏感的,在小窗口下也可以达到很好的效果;人名任务的最优窗口大小为5,因为中文人名一般都小于5并且这样的窗口大小可以带来一部分信息;当窗口大于5时,由于过拟合的原因,机构名的识别准确率急速下降。从图3可以观察到,当隐藏节点足够多时,系统的性能不再受到很大影响,而且隐藏节点数目越多系统运行越缓慢。因此,在余下的实验中,我们设定了300个隐藏节点。
3.2 字词法合向量对比实验
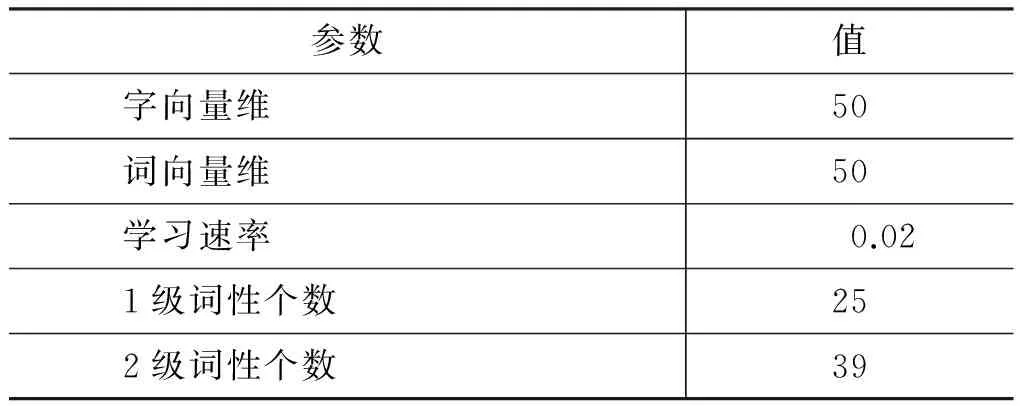
字向量、词向量、字词结合向量对比实验的数据集为RMRB-98,参数设定如表1所示,实验结果如表2所示。

表1 神经网络参数设置
续表
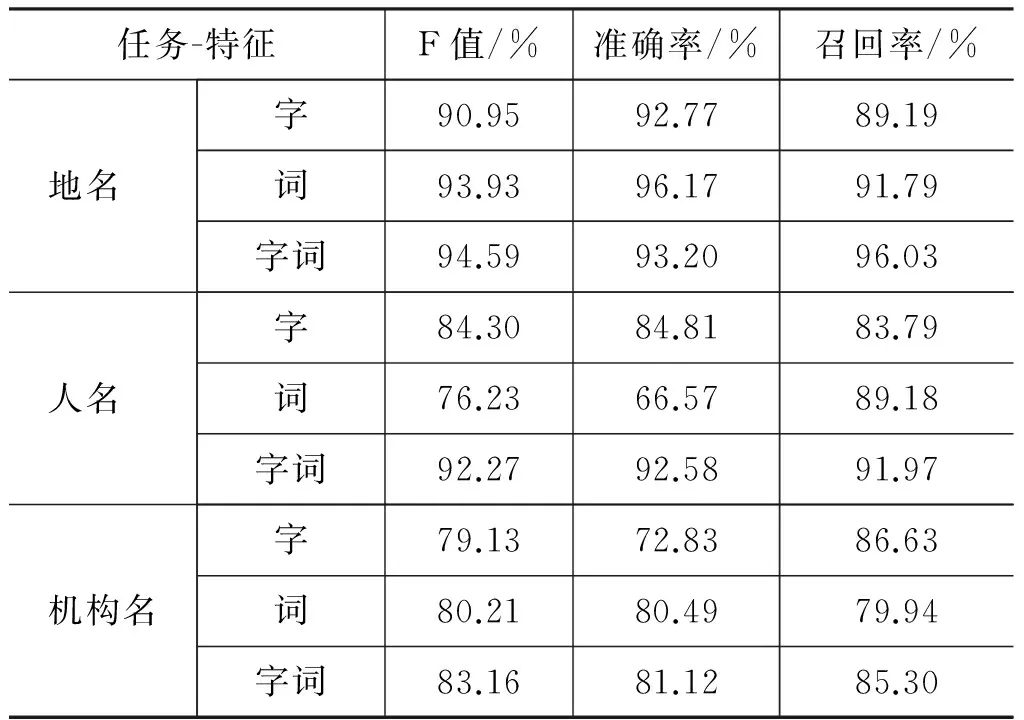
表2 字向量、词向量、字词结合向量对比结果
对于地名和机构名任务,词向量的结果优于字向量,这主要是因为词向量更能表达词语的潜在语义关系。中文句子是由许多词语组成的,相同的字的不同组合,语句中词语意思也可能不相同,而且字特征的窗口受到限制,因此NER的结果普遍不如词向量。但是对于人名识别任务,由于词典稀疏问题,词向量方法中人名会被影射成一个特殊向量,降低了识别效果,而且人名更关注于姓氏和语句结构,因此使用字向量效果更好。
字特征和词特征都有其自身的局限性,因此当使用字词结合向量后,三类任务的取值均有较大提升,对地名、人名、机构名的提升度分别达到了1.6%、8%、3%。
3.3 结合词性特征对比实验
使用DNN结构可以轻松地加入额外的特征信息。例如,当我们加入了词性特征以后,系统的性能有了很大的提高。我们分别对比了不增加词性信息(no-pos)、增加一级词性标注(1-pos)、增加二级词性标注(2-pos)的实验结果。实验中的词性使用《现代汉语语料库加工——词语切分与词性标注规范》中的词性标注符号。其中一级词性有25个,二级词性有39个,如表3所示。实验结果如表4所示。我们和现阶段较好[8]的NER模型——Hybrid Model[13](HM)进行了实验对比,HM模型使用的训练数据和测试数据与本文方法相同,实验结果显示: 加入词性标注的字词联合模型可以超越HM的识别性能,在地名、人名和机构名的识别上,F1值可以达到96.8%、94.6%、88.6%。尤其需要指出的是,本文的方法有效提高了地名、人名和机构名识别任务的召回率,加入2-pos后系统性能提升明显。其中在人名F1值方面我们的模型不如HM好,主要原因是HM进行了人名的细分,它针对不同国家的人名训练了不同的模型并进行混合,而我们的模型是不区分国家人名的,所以我们的结果略差于HM模型。与此同时,我们还使用了CRF模型与本文方法进行比较,实验结果表明,加入2-pos后的系统在地名和人名识别方面表现出色,但机构名识别方面准确率不如CRF高,这可能是由于机构名构成复杂,神经网络语言模型只利用了局部信息而没有利用全局信息导致的。

表3 词性标注设置
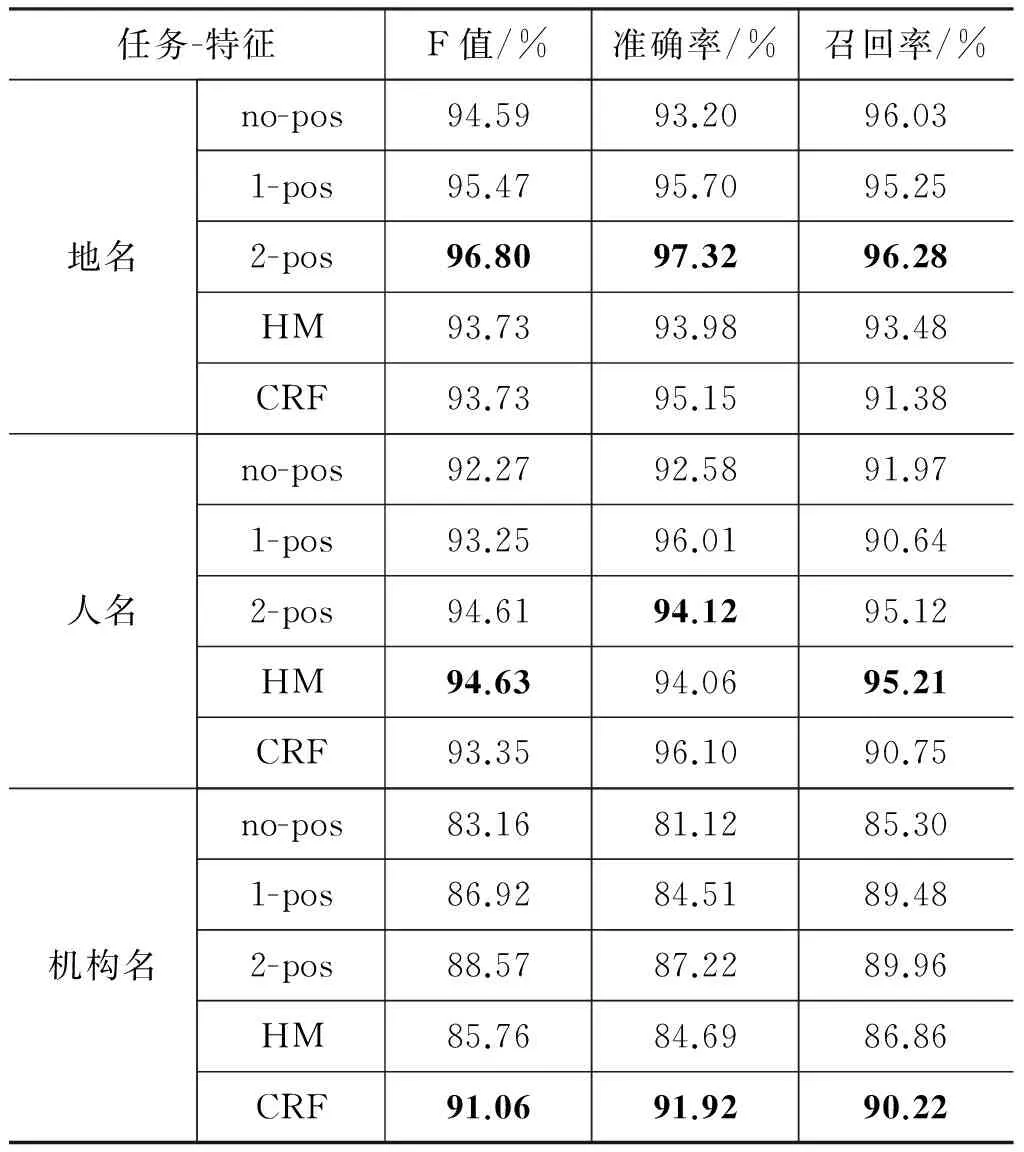
表4 无词性、一级词性、二级词性、HM方法对比结果
4 结论与展望
本文介绍了用于中文命名实体识别的深度神经网络,提出了字词结合方法,有效地弥补了单字识别和单词识别的不足,加入词性特征后的识别系统性能更加鲁棒。实验对比了字向量、词向量和字词结合向量在中文NER上的结果,字词结合方法对中文NER有较大提升。目前,跟命名实体相关的专用特征还没有加入到系统中,我们下一步将考虑加入姓氏集、地区特征集等相关特征,进一步观察该方法的系统性能。
[1] Volk M, Clematide S. Learn-filter-apply-forget. mixed approaches to named entity recognition[C]//Proceedings of NLDB, 2001(1): 153-163.
[2] Finkel J R, Grenager T, Manning C. Incorporating non-local information into information extraction systems by gibbs sampling[C]//Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2005: 363-370.
[3] Bikel D M, Schwartz R, Weischedel R M. An algorithm that learns what's in a name[J]. Machine learning, 1999, 34(1-3): 211-231.
[4] Borthwick A. A maximum entropy approach to named entity recognition[D]. New York University, 1999.
[5] McCallum A, Li W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons[C]//Proceedings of the 7th conference on natural language learning at HLT-NAACL 2003-Volume 4. Association for Computational Linguistics, 2003: 188-191.
[6] Zhou G D, Su J. Named entity recognition using an HMM-based chunk tagger[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2002: 473-480.
[7] Lafferty J, McCallum A, Pereira F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]//Proceedings of 18th Internationl conference on Nachine Learning.Williamstoun: ICML,2001: 282-289.
[8] 赵军. 命名实体识别、排歧和跨语言关联[J]. 中文信息学报, 2009, 23(2): 3-17.
[9] 陈钰枫, 宗成庆, 苏克毅. 汉英双语命名实体识别与对齐的交互式方法[J]. 计算机学报, 2011,34(9): 1688-1696.
[10] 邱泉清, 苗夺谦, 张志飞. 中文微博命名实体识别[J]. 计算机科学, 2013, 40(6): 196-198.
[11] Mikolov T, Yih W, Zweig G. Linguistic regularities in continuous space word representations[C]//Proceedings of HLT-NAACL 2013.ACL,2013: 746-751.
[12] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. The Journal of Machine Learning Research, 2011,12: 2493-2537.
[13] Wu Y, Zhao J, Xu B, et al. Chinese named entity recognition based on multiple features[C]//Proceedings of the conference on human language technology and empirical methods in natural language processing. Association for Computational Linguistics, 2005: 427-434.
[14] Klein D, Smarr J, Nguyen H, et al. Named entity recognition with character-level models[C]//Proceedings of the seventh conference on natural language learning at HLT-NAACL 2003-Volume 4. Association for Computational Linguistics, 2003: 180-183.
[15] Zheng X, Chen H, Xu T. Deep learning for Chinese word segmentation and POS tagging[C]//Proceedings of EMNLP, 2013: 647-657.

张海楠(1990—),博士,主要研究领域为自然语言处理、命名实体识别、对话系统、强化学习。
E-mail: zhanghainan1990@163.com

伍大勇(1976—),博士,主要研究领域为自然语言处理、命名实体识别、分词。
E-mail: wudayong@ict.ac.cn

刘悦(1971—),博士,副研究员,主要研究领域为信息检索、互联网挖掘等。
E-mail: liuyue@ict.ac.cn
Chinese Named Entity Recognition Based on Deep Neural Network
ZHANG Hainan1, WU Dayong1, LIU Yue1, CHENG Xueqi2
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China;2. Institute of Network Technology, ICT(YANTAI), CAS, Yantai, Shandong 264000, China)
1003-0077(2017)04-0028-08
TP391
A
2015-09-25 定稿日期: 2016-04-21
国家重点基础研究发展计划(“973”计划)(2014CB340401);国家自然基金(61232010,61433014,61425016,61472401,61203298);中国科学院青年创新促进会优秀会员项目(20144310,2016102);泰山学者工程专项经费(ts201511082)
