改进机器翻译中的句子切分模型
2017-10-11薛征山张大鲲王丽娜
薛征山,张大鲲,王丽娜,郝 杰
(东芝(中国)研究开发中心,北京100600)
改进机器翻译中的句子切分模型
薛征山,张大鲲,王丽娜,郝 杰
(东芝(中国)研究开发中心,北京100600)
随着统计机器翻译系统训练语料的不断增加,长句子的数量越来越多,如何有效地利用长句子中的信息改进翻译质量是统计机器翻译系统面临的主要问题之一。该文基于Xu的句子切分模型,提出了一种在训练阶段切分长句子的方法,该方法利用自动获取的边界词概率和切分后子句对的长度比例来指导切分过程,从而得到更符合语义信息的句子切分结果。在NIST测试集上的实验结果表明,该方法获得了最大0.5个BLEU值的提升。
统计机器翻译;句子切分模型;边界词概率
Abstract: Long sentence segmentation is a valid issue in optimizing the quality of machine translation. This paper proposes a new method for long sentence segmentation during the training process. This method automatically decides the boundary words and their probabilities without manual intervention, which results more meaningful segmentation in semantics. Also, the length of segmented sub-sentences are balanced through both source and target languages. Experiments on the NIST test sets show an improvement of up to 0.5 BLEU scores.
Key words: statistical machine translation;sentence segmentation model; word boundary probability
收稿日期: 2015-09-18 定稿日期: 2015-12-18
1 引言
近年来,统计机器翻译[1-9]逐渐成为自然语言处理领域的研究热点。基于统计的机器翻译需要大规模的双语平行句对。双语平行句对是非常昂贵的资源,尤其是对于稀缺的语言对来说更是如此。在大规模双语平行句对中,不可避免地存在一些长度很长的句子(句子既可以指平行句对中的源语言句子,也可以指句对中的目标端句子)。长句子的存在,会增加系统训练的开销(内存和时间),所以大多数翻译系统(如Moses[5])通常在训练阶段将长度大于某个固定值的句子移除。这样做存在数据使用不充分的问题,而如果能够将长句子切分成长度适中的较短的句子,就可以充分利用数据。数据量增大(相对于移除长句子),有助于提高翻译质量。由此可见,长句子切分是一项非常有必要的工作。
长句子的切分方法主要分为两类,一类是在训练阶段对句子进行切分,另一类是在解码阶段对句子进行切分。Kim[10]提出了一种在训练阶段基于规则的切分方法,虽然取得了较好的效果,但是这种方法依赖于人工书写规则,费时费力,难以维护。Nevado[11]使用词汇化信息,通过动态程序算法寻找句子切分点,这种方法需要手动收集锚文本(anchor words)词汇,并且句子切分后只允许子句单调对齐。Xu[12]提出了一种基于IBM模型1的句子切分方法,该方法允许单调和非单调对齐,同时,通过加入长度平衡因子和反向对齐模型,在两个中英翻译任务中,均取得较好的效果。然而,该方法并没有考虑切分后的子句是否是有意义的逻辑单位。Meng[13]对Xu的方法进行了改进,加入了语义指导和泊松分布率。Meng的方法仍然需要人工收集一些边界词汇,同时该方法没有考虑同一个边界词既可以作为子句开始,也可以作为子句结束的概率。
其他一些方法关注于解码阶段的句子切分。Doi[14]提出了使用N-gram和三个评测标准进行语音输出的切分。Furuse[15]提出了一种基于语义距离的语音输出切分方法。Sudoh[16]使用句法分析器将训练集和测试集切分成多个子句,而后引入非终结符改写句子,同时提出了基于图的子句对齐模型。这个方法有效地改善了长句子的调序问题,提高了翻译系统的质量。然而该方法依赖于句法分析结果的质量,同时,当一个长句子中的多个子句不存在主从关系时,该方法的效果不是十分明显。
由前人的工作可以看出,在训练阶段对训练语料的切分方法[10-13],大多数都需要人工书写规则或者收集锚文本。Xu的方法虽然不需要人工干预,但是切分点比较任意,切分后可能出现无意义的片段。Meng的方法利用人工定义的边界词集合指导句子切分,可以有效地改进Xu的句子切分模型。但是该方法要求切分点的词都包含在边界词集合里。
针对以上问题,本文提出了一种在训练阶段自动进行的长句子切分方法,这种方法不需要人工书写规则或者收集锚文本、边界词等,因此克服了Meng的方法的不足之处,同时可以处理Xu的方法引起的切分点任意的问题。本方法可以概述为四步: (1)使用GIZA++获得双语词对齐和词汇翻译概率; (2)使用Zhang提出的SRA(shift-reduce-algorithm)方法,获得双语句对的层次型结构树。(3)根据步骤(2)的输出结果,收集边界词集并使用最大似然方法获得词边界概率; (4)将词边界概率集成到Xu的方法当中,计算句子的切分位置。在NIST数据集上的实验表明,这种方法能够有效地提高翻译系统的翻译质量。
后续章节组织结构如下: 第二节介绍Xu和Meng的工作,第三节介绍本文提出的长句子切分模型,第四节给出相关实验结果、分析,以及一些切分样例,最后一节是结束语。
2 句子切分模型
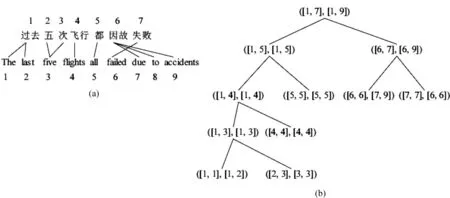
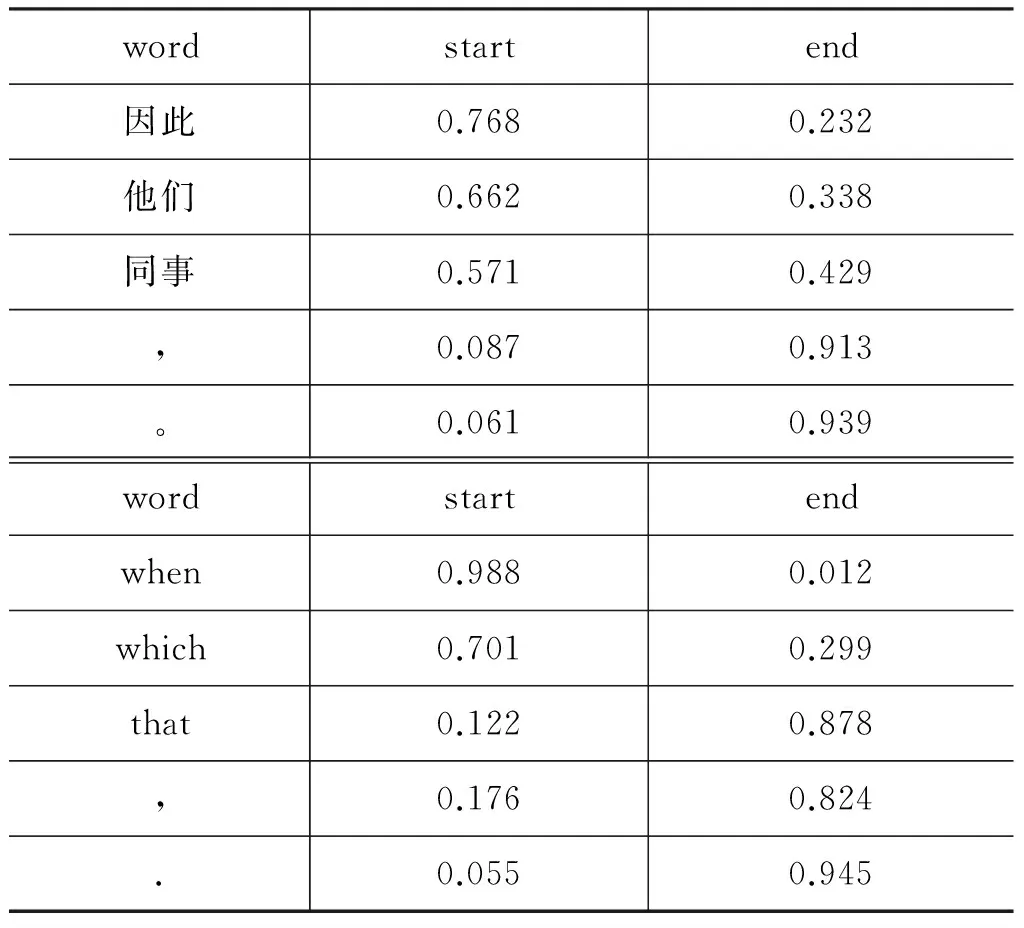
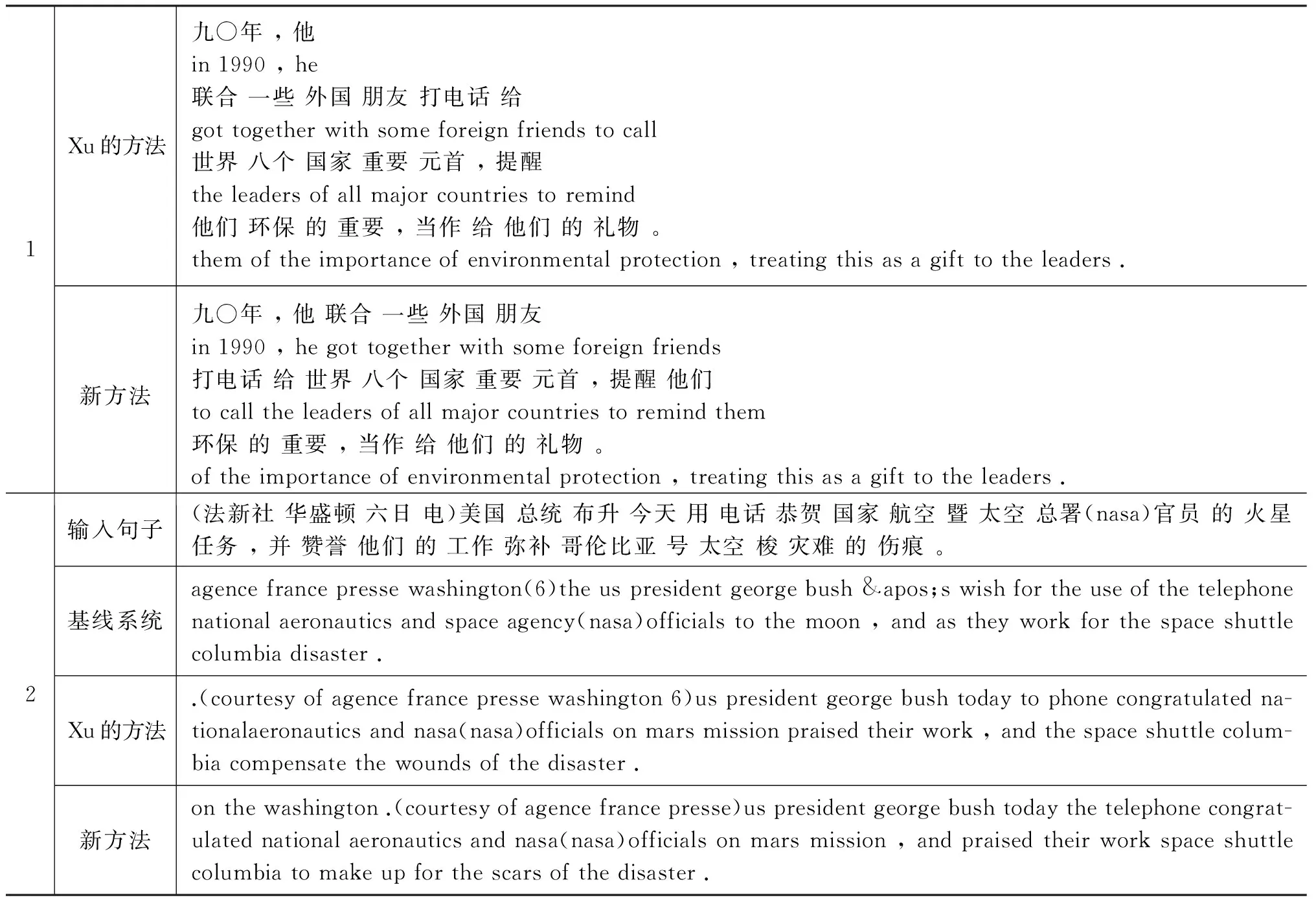
给定双语句对(f,t),其中f=f1f2…fm-1fm表示包含m个词的源语言句子,t=t1t2…tn-1tn表示包含n个词的目标语言句子。定义句对片段(f′,t′),其中f′=fj1fj1+1…fj2-1fj2,t′=ti1ti1+1…ti2-1ti2,存在约束0 2.1Xu的切分模型 Xu的方法首先计算切分后得到的句对翻译概率,利用这一概率信息寻找最优的切分位置。其句对(f′,t′)的翻译概率定义为式(1)。 (1) 其中p(fv|tz)表示由IBM模型1产生的词汇翻译概率。在式(1)的基础上,Xu加入了两个改进因子。 (1) 长度因子(length normalization): β是一个平衡权重。 (2) 反向对齐模型(inverse alignment model): (4) 假设当前需要切分的句对为(f′,t′),(j,i)是任意切分位置,其中j∈[j1,j2-1],i∈[i1,i2-1]。切分后产生两个子句对,子句对的概率使用式(4)进行计算。 存在两种对齐方式: (1) 单调对齐pj,i,1: (5) (2) 非单调对齐pj,i,0: (6) 目标函数: (7) 通过式(7),可以获得切分位置和对齐方式,从而实现句子切分。 2.2 Meng的切分模型 在Xu的方法中切分位置和对齐方式依赖于式(7)的计算,其切分结果没有考虑所得到的切分片段是否具有语言学意义。Meng通过研究发现很多长句子是包含子句的复合句,而子句一般是由引导词引导的,例如英语中的“when”、“which”之类的词。除了引导词之外,还有连词、标点等,这些词通常表示一个完整片段的起始或者结束,其所在的位置可以作为切分候选。如果从这些词的位置进行切分,那么切分出来的片段或者子句,将更符合实际语义。所以,Meng收集了四个词汇集合: 作为子句或者片段开始的源语言和目标语言词汇列表WLf,s、WLt,s,和作为子句或者片段结束的源语言和目标语言词汇列表WLf,e、WLt,e。 对于式(7)中的切分位置(j,i)的词,如果满足式(8)。 则 (8) 实验结果表明,该方法在Xu的方法基础上取得了较好的效果。 3.1 自动获取边界词集 Xiong[17]使用双语词对齐语料,利用Zhang[18] 提出的SRA方法,获得双语句对的层次型结构树,树中的每个节点称为一个翻译域(translation zone),通过给多个词组成的翻译域的首词和尾词定义词类,获得了带有词类标签的训练语料。受Xiong[17]的启发,我们也用同样的方法自动从长句子中获得切分点边界词集合。与Xiong的方法的不同之处在于,我们不仅要获得源语言边界词集,同时也要获得目标语言边界词集。下面以Xiong论文中的例句进行说明。 图1(a)中是一个多对多的对齐案例,图1(b)是利用SRA算法获得的与(a)对应的层次型结构树。图1(b)中的每个节点是一个双语短语对,所以每个节点都包含标识该短语对源语言端和目标语言端的起始和结束边界词。遍历树中长度大于1的节点(长度为1的节点,起始和结束边界词一样),收集到的边界词汇集合如下: WLf,s,WLf,e,WLt,s,WLt,e的定义同上,分别表示源语言端起始边界词集合,源语言端结束边界词集合,目标语言端起始边界词集合和目标语言端结束边界词集合。 图1 双语词对齐及其层次型结构树表示 3.2 计算边界词概率 利用SRA算法可以自动获取四个边界词集合。对于某一个词来说,在不同的上下文情况下可以既属于边界开始,也可以属于边界结尾,因此集合WLf,s和WLf,e,WLt,s和WLt,e可能存在交集。我们定义每个边界词的概率如下,用来表示该词作为边界起始和结尾的可能性。 (9) 其中,f表示源语言端,t表示目标语言端,s表示边界开始,e表示边界结尾。表1是自动抽取的一些边界词概率样例。 表1 边界词概率样例表 3.3 本文的切分方法 在Xu[12]的方法基础上,我们定义了变量v(f,t,j,i)来表示切分位置具有语言学意义的程度,同时定义r1和r2来平衡切分后的子句长度。 本节符号系统仍然与第二节相同。假设(j,i)是任意切分位置,v(f,t,j,i)定义如下: (10) 句子切分后根据子句对的对齐方式不同,定义r1,r2两个变量。 对于单调对齐: 对于非单调对齐: 目标函数: 式(15)能够对有意义的切分位置给予奖励(v(f,t,j,i)值较大),同时对失衡句对给予惩罚(r1×r2较小)。例如,假设切分前句对长度比是27∶20,切分位置是(24,2),对于切分后子句单调对齐来说,r1=1/12,r2=1/6。对于非单调对齐,r1=3/4,r2=2/3。在这种情况下,将更偏向于非单调对齐切分。 式(16)的切分算法递归进行,直到找不到符合条件的切分位置为止。 3.4 动态参数 在句子切分过程中,设置了四个参数用于控制切分。 (1) GlobalMaxLen和GlobalMinLen: 这是两个静态参数,对于所有句子都保持不变。GlobalMaxLen的主要作用是确定双语句对是否需要切分(如果双语句对长度均不超过GlobalMaxLen,则不进行切分,否则就需要切分)。GlobalMinLen用于控制切分后得到的最小子句(片段)长度。 (2) LocalMaxLen和LocalMinLen: 这两个动态参数是为需要切分的每个句子设置的。动态参数根据如下方法确定。 Step2: LocalMaxLen= LocalMinLen= Step3: LocalMaxLen=GlobalMaxLen if LocalMaxLen>GlobalMaxLen; LocalMinLen=GlobalMinLen if LocalMinLen 在实际的切分过程中,我们使用LocalMinLen代替GlobalMinLen,用LocalMaxLen代替GlobalMaxLen来控制切分过程。原因是在实验的过程中,我们发现切分后的子片段或者子句长度,一般都偏向于GlobalMinLen(GlocalMinLen通常被设置为1或者2),这将导致碎片化(切分出很多长度为GlobalMinLen的片段)。通过LocalMinLen和LocalMaxLen的帮助,可以使切分出的子句更趋于平衡。 我们进行了句子切分实验的有效性验证。实验中使用开源的Moses[5]短语模型系统作为实验翻译解码器,短语抽取长度设定为7,语言模型使用五元语言模型。模型训练使用LDC2005T10的中文—英语(Ch-En)语料,语言模型用的是训练数据的目标端语料,开发集使用NIST2002的测试集,测试语料使用NIST2002-NIST2006、NIST2008的测试集,测试集的参考译文均为四个。句子切分参数设置为: GlobalMaxLen=20,GlobalMinLen=1,β=0.9(公式3)。实验语料信息如表2所示。 表2 实验语料基本信息 注: LDC2005T10是经过处理后的语料(去除句对长度比≥9的句对及空对齐句对)。 本文设计了三组实验。(1)基线系统实验,即不对训练语料进行切分。(2)Xu的切分实验,即使用Xu的方法进行训练语料的切分。(3)新的切分方法实验,使用本文所提出的方法进行训练语料切分。在实验(2)和(3)中用到的词汇翻 译 概 率 表来自于实验(1)。实验(3)中用到的边界概率表是从基线系统训练语料中自动获得的。因为Meng的切分实验中使用的人工边界词集合无法确定,所以本文没有和Meng的方法进行比较。实验结果如表3所示。 表3 BLEU值试验结果 从上述实验结果中可以看出,在六个测试集中,我们的方法相比于基线系统,除了NIST2005外,其他测试集上均有不同程度的提高。而Xu的方法相比于基线系统,仅在NIST2002和NIST2006上有所提高。我们的方法和Xu的方法相比,在NIST2005、NIST2006测试集上基本相同(差异不显著),在其他测试集都有提高(0.15、0.51、0.53、0.20 BLEU值)。对于NIST2005测试集,我们的方法和Xu的方法在切分后的翻译质量都有所降低,可能的原因是因为NIST2005测试集的平均句子长度较长,本文的工作中并没有在解码阶段对测试句子进行处理,因此造成翻译质量下降。 我们进一步比较了模型规模方面的差异,我们的方法和Xu的方法相近,与基线系统的模型相比,翻译模型(短语翻译表)大约减小13%,调序模型(短语调序表)大约减小11%。模型减小的原因是由于在训练阶段长句子被切分成了短句子,不再对原来在句子切分点处的短语对和调序对进行统计。表4是一些切分和翻译实例,其中编号1为切分实例,编号2为翻译实例。 表4 一些切分实例 续表 本文提出了一种在训练阶段集成词语边界概率的句子切分方法,该方法不仅能够自动获取词语的边界概率,同时可以有效指导句子切分。和Xu[12]的方法相比,经过该方法切分后的子句具有更直观的语义信息,而不是产生任意的切分片段。此外,我们使用平衡因子来改进切分后的子句长度失衡问题。实验表明,与基准系统相比,本方法能够有效地提高翻译质量。和前人工作相比,本方法能够自动获取切分边界词集合及其边界概率,从而可以对切分位置进行有效指导,得到更好的切分效果。 在基于统计的机器翻译方法中,随着训练语料的不断增加,长句子的比重也越来越大,如何有效地利用长句子的信息改善翻译质量是必须要处理的问题之一。本文提出的在训练阶段的句子切分模型独立于统计翻译方法,所以不仅能够应用于基于短语的机器翻译系统,也适用于基于句法的翻译系统。此外,如何改进解码阶段的长句子切分,以及如何合并切分后子句的翻译结果,是下一步的工作内容之一。 [1] Yamada K, K Knight. A syntax-based statistical translation model[C]//Proceedings of ACL,2001: 523-530. [2] Philipp Koehn, Franz Joseph Och, Daniel Marcu. Statistical phrase-based translation[C]//Procedings of In Human Language Technology Conf. / North American Chapter of the Assoc. for Computational Linguistics Annual Meeting(HLT-NAACL). Edmonton. Canada, May/June,2003: 127-133 [3] 刘群. 统计机器翻译综述[J]. 中文信息学报, 2003,17(4): 1-12. [4] Yang Liu, Qun Liu, Shouxun Lin. Tree-to-string alignment template for statistical machine translation.//Proceedings of COLING/ACL 2006, Sydney, Australia, July,2006: 609-616. [5] Philipp Koehn, Hieu Hoang, Alexandra Birch, et al.Moses: Open source toolkit for statistical machine translation[C]//Annual Meeting of the Association for Computational Linguistics(ACL), demonstration session, Prague, Czech Republic, June 2007: 177-180. [6] David Chiang. Hierarchical phrase-based translation[J]. Computational Linguistics, 2007: 201-208. [7] Yanqing He, Jiajun Zhang, Maoxi Li, et al. The casia statistical machine translation system for iwslt 2008[C]//Proceedings of the IWSLT, 2008: 85-91. [8] Maoxi Li, Jiajun Zhang, Yu Zhou, et al. The casia statistical machine translation system for iwslt 2009[C]//Proceedings of the IWSLT, 2009: 83-90. [9] Tong Xiao, Jingbo Zhu, Hao Zhang NiuTrans: An open source toolkit for phrase-based and syntax-based machine translation[C]//Proceedings of ACL 2012 System Demonstrations,2012: 19-24. [10] Yenu-Bae Kim, Terumasa Thara. A method for partitioning of long Japanese sentences with subject resolution in J/E machine translation[C]//Proceedings of International Conference On Computer Processing of Oriental Language,1994: 467-473. [11] Francisco Nevado, Francisco Casacuberta, Enrique Vidal. Parallel corpora segmentation using anchor words[C]//Proceedings of the 7th International EAMT workshop on MT and other Language Technology Tools, Improving MT through other Language technology tools: resources and tools for building MT, 2003: 33-40. [12] J Xu, R Zens. Sentence segmentation using IBM word alignment model 1[C]//Proceedings the 10th Annual Conference of the European Association for Machine Translation, Budapest, Hungary, 2005: 280-287. [13] B Meng, S Huang, X Dai, et al. J.: Segmenting long sentence pairs for statistical machine translation[C]//Proceedings of International Conference on Asian Language Processing, Singapore, 2009: 53-58. [14] Takao Doi, Eiichiro Sumita. input sentence splitting and translating[C]//Processings of the HLT/NAACL: Workshop on Building and Using Parallel Texts.2003: 104-110. [15] Osamu Furuse, Setsuo Yamada, Kazuhide Yamamoto. Splitting long and ill-formed input for robust spoken-language translstion[C]//Processings of COLING-ACL, 1998: 421-460. [16] Sudoh, K, Duh, K, Tsukada, et al, Divide and translate: improving long distance reordering in statistical machine translation[C]//Proceedings of the Joint 5th Workshop on SMT and Metrics MATR, 2010: 418-427. [17] D Xiong, M Zhang, H Li, Learning translation boundaries for phrase-based decoding.//Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the ACL,Los Angeles, California 2010: 136-144. [18] Hao Zhang, Daniel Gildea, David Chiang. Extracting synchronous grammars rules from word level alignments in linear time[C]//Proceeding of COLING 2008: 1081-1088. 薛征山(1982—), 硕士, 高级研究员,主要研究领域为自然语言处理、机器翻译。 E-mail: xzskmust@163.com 张大鲲(1980—),博士,主要研究领域为自然语言处理、统计机器翻译、深度学习等。 E-mail: zhangdakun@gmail.com 王丽娜(1983—),研究员,主要研究领域为自然语言处理、问答系统。 E-mail: wanglina@toshiba.com.cn An Improved Sentence Segmentation Model for Machine Translation XUE Zhengshan, ZHANG Dakun, WANG Lina, HAO Jie (Toshiba(China)R&D Center, Beijing 100600,China) 1003-0077(2017)04-0050-07 TP391 A3 改进的句子切分模型
4 实验


5 结束语



