基于深度学习的维吾尔语人称代词指代消解
2017-10-11李冬白田生伟吐尔根依布拉音冯冠军
李冬白,田生伟,禹 龙,吐尔根·依布拉音,冯冠军
(1. 新疆大学 软件学院,新疆 乌鲁木齐 830008; 2. 新疆大学 网络中心,新疆 乌鲁木齐 830046;3. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046; 4. 新疆大学 人文学院,新疆 乌鲁木齐 830046)
基于深度学习的维吾尔语人称代词指代消解
李冬白1,田生伟1,禹 龙2,吐尔根·依布拉音3,冯冠军4
(1. 新疆大学 软件学院,新疆 乌鲁木齐 830008; 2. 新疆大学 网络中心,新疆 乌鲁木齐 830046;3. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046; 4. 新疆大学 人文学院,新疆 乌鲁木齐 830046)
指代消解是自然语言处理技术的核心问题,该文结合维吾尔语语义特征,提出基于深度学习的维吾尔语人称代词指代消解方法。通过堆叠多层无监督RBM网络和一层有监督BP网络,构建DBN深度神经网络学习模型,RBM网络保证特征向量映射达到最优,BP网络对RBM网络的输出向量进行分类,实现维吾尔语人称代词指代消解。经过维吾尔语指代消解语料库测试,F值达到83.81%,比SVM方法高出2.88%。实验结果表明,同等条件下,该方法能有效提升维吾尔语人称代词消解的精度,有助于维吾尔语指代消解研究。
维吾尔语;人称代词;指代消解;深度学习;深度信念网络
Abstract: Coreference resolution is a fundamental issue in natural language processing. Combining the semantic features of Uyghur, a method of Uyghur pronominal anaphora resolution based on Deep Learning is proposed. The proposed DBN (Deep Belief Nets) learning model is composed of several unsupervised RBM networks and a supervised BP network. The RBM layers preserve information as much as possible when feature vectors are mapped to next layer. The BP layer is able to classify the vector output by the last RBM layer. Then the model can be used to implement Uyghur pronominal anaphora resolution. Experiments on Uyghur coreference resolution corpus achieve 83.81% in F-score, 2.88% higher than SVM.
Key words: Uyghur; personal pronoun; anaphora resolution; deep learning; deep belief network
收稿日期: 2016-04-18 定稿日期: 2016-09-23
基金项目: 国家自然科学基金(61563051,61662074);国家自然科学基金(61262064);国家自然科学基金(61331011);新疆自治区科技人才培养项目(QN2016YX0051)
1 引言
指代作为一种常见的语言现象,广泛存在于自然语言表达中。在语言学中,指代是一个抽象的语言学单位anaphor(称为照应语)与之前出现的一个具体的语言单位antecedent(称为先行语)之间存在的一种特殊语义关系。确定照应语的先行语的过程称为指代消解。
指代消解实质上是从内容层面构建篇章中句与句间的衔接。指代的正确消解作为自然语言处理(natural language processing,NLP)研究的关键问题,对机器翻译(machine translation)、信息抽取(information extraction)、自动文摘(automatic abstracting)等诸多NLP应用有着极其重要的支撑作用[1]。
指代消解经过几十年的发展,已从最初基于规则的研究方法转向基于机器学习的研究方法。McCarthy[2]首先提出将判断先行语的问题转为一个二元分类问题,利用分类器判断照应语和候选先行语之间是否有指代关系。之后,Soon[3]根据这一思想,提出基于机器学习的指代消解框架: 从预处理过的语料中抽取12个特征,构建训练集;利用SVM等分类器进行训练,得到分类器模型;用分类器模型对测试语料进行测试[4];在MUC-6测试语料上F值达到62.6%。之后很多学者借鉴这一思想做了大量的研究工作。例如,Ng[5]等在Soon等研究的基础上,充分考虑词法、语法和语义,抽取53个特征构建系统,指代消解效果显著;Yang[6]等人提出一个双候选模型,通过学习更好地确定先行语;Kong[7]等人将中心理论拓展到语义层,探索语义信息对指代消解的影响。研究表明,合理的运用语义信息可以极大地提升英文代词消解的性能。相较于英文,中文指代消解研究起步较晚。许敏[8]等采用人物焦点的变化,对汉语第三人称代词进行了消解研究;王厚峰[9]等人根据人称代词的语义角色信息,给出汉语人称代词的消解规则。之后又从领域知识和语义知识出发,提出一种弱语言化知识的消解方法,解决人称代词消解[10];李国臣[11]等采用决策树算法结合优先选择策略,完成中文人称代词的指代消解;李凡[12]等结合实训学习,提出一种基于Fuzzy Rough集模型的汉语人称代词消解方法;孔芳[4]等基于树核函数,从多方面动态扩展结构化句法树,提升指代消解的性能。
随着研究的不断深入,深层次的语义信息越来越受关注。传统的方法依靠人工抽取样本的平面特征,基于机器学习完成分类。虽然能在一定程度上提升系统性能,但存在一些局限性: (1)人工构造特征过程烦琐,对系统性能影响较大; (2)传统浅层机器学习无法充分表示深层次的语义信息,对复杂问题泛化能力较弱。此外,目前研究都集中在语料资源丰富的英语和中文等语言中,且已取得丰硕成果,但对于像维吾尔语这样语料资源匮乏的小语种研究甚少。基于上述问题,本文提出基于深度学习的维吾尔语人称代词指代消解方法,探索深层次的语义信息。
2 相关工作
2.1 深度学习 基于人工神经网络对人类感知系统中层次结构的研究,研究者提出了深度学习的概念。深度学习是通过模拟人脑神经元和突触处理感知信号的过程,构建含多个隐层的机器学习模型。其优势在于: 自动地学习数据中比浅层特征更加抽象的高层特征表示;经过逐层非监督预训练学习算法获取数据的分布式表示[13];利用多层非线性映射网络结构,完成复杂函数的逼近,图1为一个复杂函数的分解示例图。
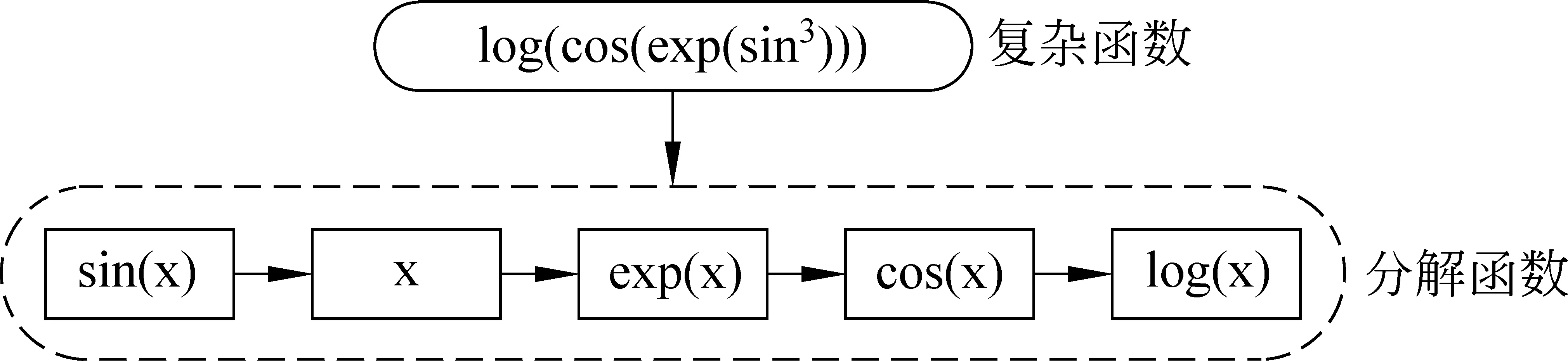
图1 复杂函数分解示例
基于人类对于复杂现实数据中隐含的深层结构的探索,深度学习被有效地应用到图像处理、语音识别、自然语言处理等众多领域[14]。文献[15]利用五层DBN替换GMM-HMM中高斯混合模型,结合单音元素状态,完成语音识别;文献[16]采用三阶玻尔兹曼机改进DBN,进行三维物体识别,结果优于SVMs,接近历史最好识别误差;文献[17]将DNN与HMM相结合,在转写任务中错误率明显下降;文献[18]基于深度学习构建一个自然语言处理框架,处理Chunking、POS、SRL、NER等自然语言处理任务。本文采用深度学习算法处理维吾尔语人称代词指代消解,将这个复杂任务的学习过程转变为对多层抽象表示的非线性推导过程,保证统计和计算的可操作性。
2.2 维吾尔语
维吾尔语,简称维语(Uyghur),属于阿尔泰语系突厥语族葛逻禄语支[19],是一种黏着语。同英语一样,维吾尔语是一种拼音文字,通过在单词原型上附加一定词根完成构词。维吾尔语中将表示名词和其他词在组合过程中产生的各种关系的语法范畴称为格范畴。“格”语法作为一种特殊的语法范畴,根据人称代词的不同与上下文的变化,在人称代词词尾附加不同的“格后缀”,形式见表1。“格”语法能够体现名词在句中的句法功能,在语法形式上具有独立性,在语法意义上具有稳定性,它作为维语人称代词的重要语言特征,为人称代词指代消解研究提供依据。
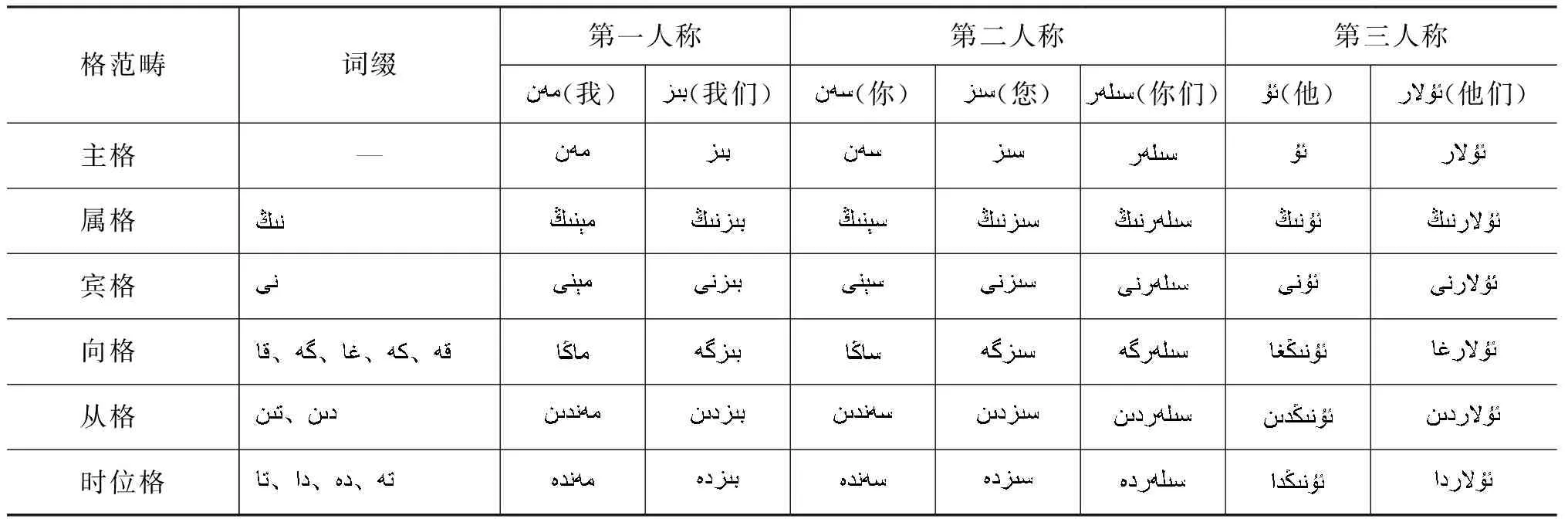
表1 维吾尔语句人称代词“格”语法
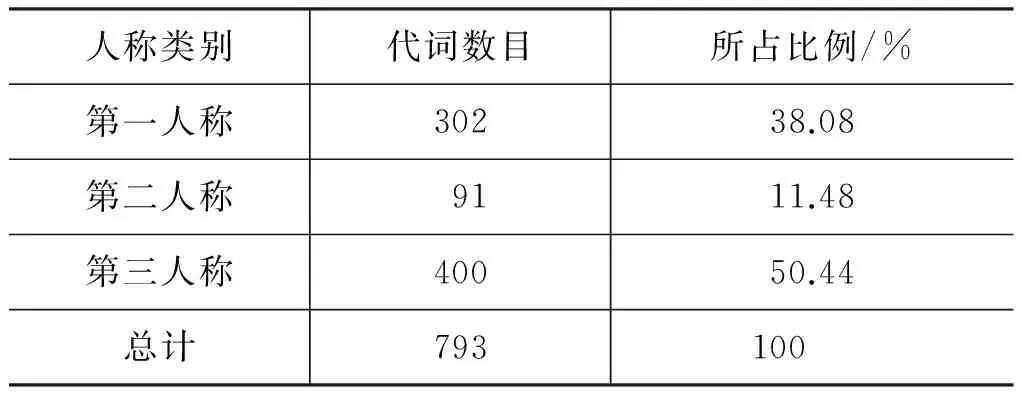
与汉语中起称代作用的人称代词不同,维吾尔语的人称代词中有第一人称、第二人称、第三人称,但不包括反身代词。此外,维吾尔语的人称代词有单复数之分,通过附加不同词尾进行区分。维吾尔语第一人称和第二人称有单复数之分,第三人称没有;第二人称有四种称呼: 普称、尊称、敬称和蔑称,普称和敬称有单复数之分,尊称只有单数,蔑称只有复数;第三人称没有性别之分,形式见表2。人称代词单复数的特征,为构建维吾尔语人称代词指代消解的规则提供依据。
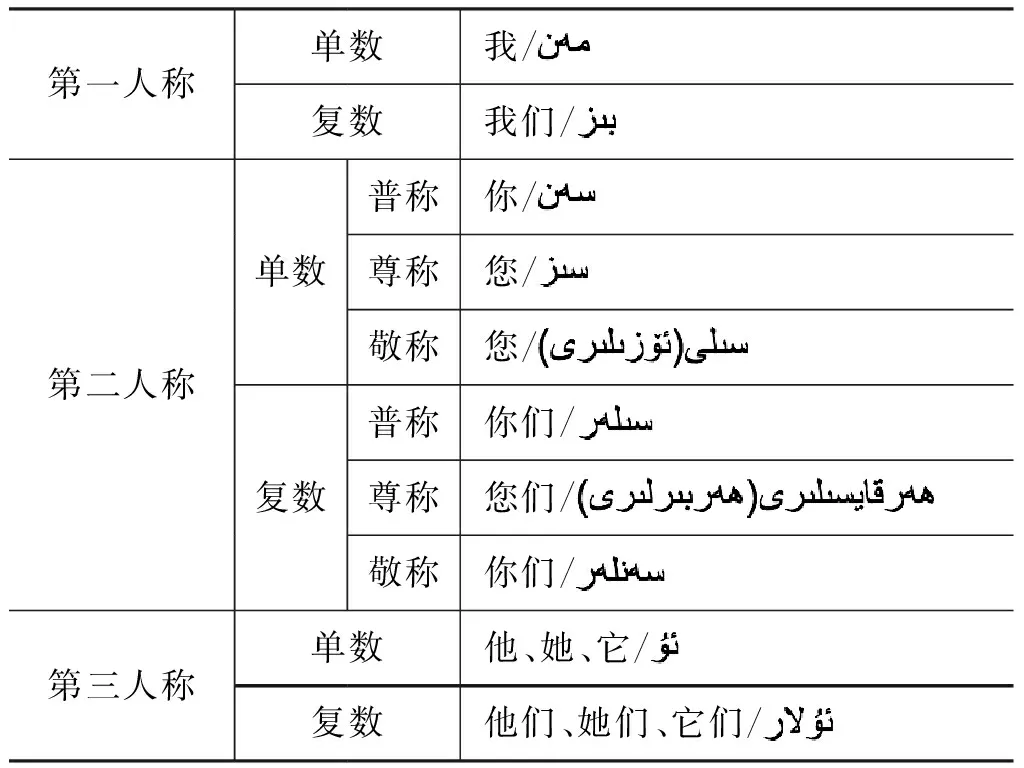
表2 维吾尔语句人称代词单复数
3 维吾尔语人称代词指代消解
3.1 特征向量的选择 特征向量的选择对基于机器学习的指代消解性能具有重要影响。特征的选择要能有效判断照应语和候选先行语间是否存在指代关系。通过查阅国内外对中英文人称代词指代消解的研究成果,结合维吾尔语的特殊性,筛选适合本文使用的特征集。基于传统的浅层机器学习方法,人工提取特征可扩充性差、浅层学习方法泛化能力弱、忽略特征层次类型对分类结果的影响,本文对筛选特征进行分层,共定义五个抽象层,并赋予不同的抽象值。
3.1.1 词法特征
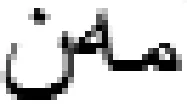
(2) 先行语为代词(candidate pronoun): 特征取值vcp={0,1},表明若候选先行语为代词,特征值取1, 否则取0。
(3) 词性一致性(POS agreement): 特征取值vpos={0,1},表示照应语和候选先行语的词性一致特征值取1,否则取0。
3.1.2 语法特征
(1) 性别一致性(gender agreement): 特征取值vgender={0,0.5,1},如果候选先行语和照应语的性别特征一致,特征值取1;性别特征不一致,特征值取0;当其中一个的性别特征未知时,特征值取0.5。
(2) 语义类别一致性(semanteme agreement): 特征取值vsemanteme={0,0.5,1},若照应语和候选先行语语义类别一致,特征值取1;语义类别不一致,特征值取0;若其中一个的语义类别未知或没有,特征值取0.5。
3.1.3 位置和距离特征
(1) 距离特征(distance): 距离特征是照应语和候选先行语句子编号的空间距离[20]。空间距离越远,候选先行语和照应语发生指代关系的可能性越小,于是定义特征值vdistance=f(d),对空间距离进行逆向取值,并弱化在0~1之间。特征函数如式(1)所示。
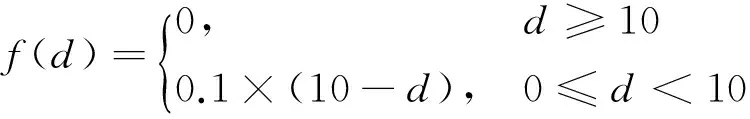
(1)
设空间距离为d,若d大于等于10句 ,则特征值取0 ;若d小于十句 ,则特征值取 0.1×(10-d)。
(2) 是否嵌套(Pps nest): 特征取值vnest={0,1},若照应语和候选先行语相互嵌套,特征值取1,否则取0。
3.1.4 语义特征
(1) 语义角色(semantic role): 特征值vrole,是四维数值向量。设i为照应语,j为候选先行语;arg0(k)表示k的语义角色是否为施事者,若是取1,否则取0;arg1(k)表示k的语义角色是否为受事者,若是取1,否则取0。则vrole={arg0(i),arg1(i),arg0(j),arg1(j)}。
(2) 命名实体特征(name entity): 特征取值vname={1,vw}。若候选先行语实体类型为人名,取值为1;否则依次取值。根据语料地名、机构名、其他所占的比例,赋予不同权重。
(2)
3.1.5 格语法特征
(1) 格语法特征(case grammar): 格语法特征指的是候选先行语和照应语的所属格。特征取值vcase={0,0.5,1}。若照应语和候选先行语的格语法相同,取1;不同取0;其中一个没有格语法则取0.5。
(3) 单复数一致性(number agreement): 特征取值vnumber={0,0.5,1}。若候选先行语和照应语的单复数一致,取1;否则取0;若其中一个不存在或不确定取0.5。与汉语(或英语)相同,维吾尔语也有单数和复数之分,它是通过不同词尾加以区分。单数没有特定的词尾,原型名词本身即含有单数意义;复数需要在原型名词后附加专门的词尾,具体形式如表3所示。
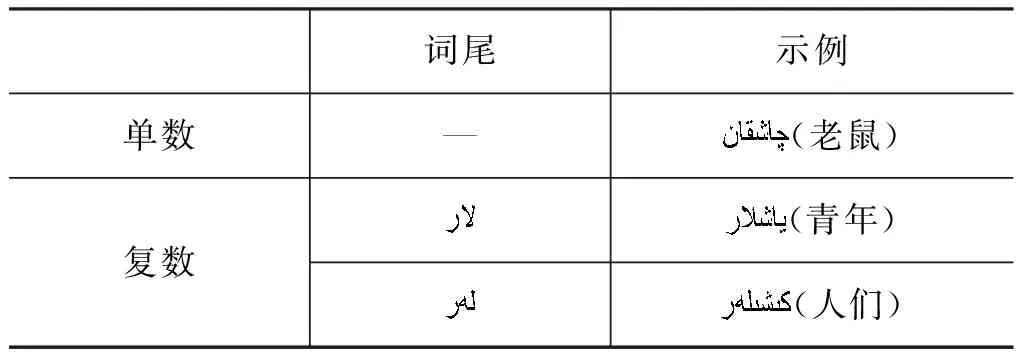
表3 维吾尔语单复数词尾
3.2 构建训练实例和测试实例
3.2.1 构建训练实例
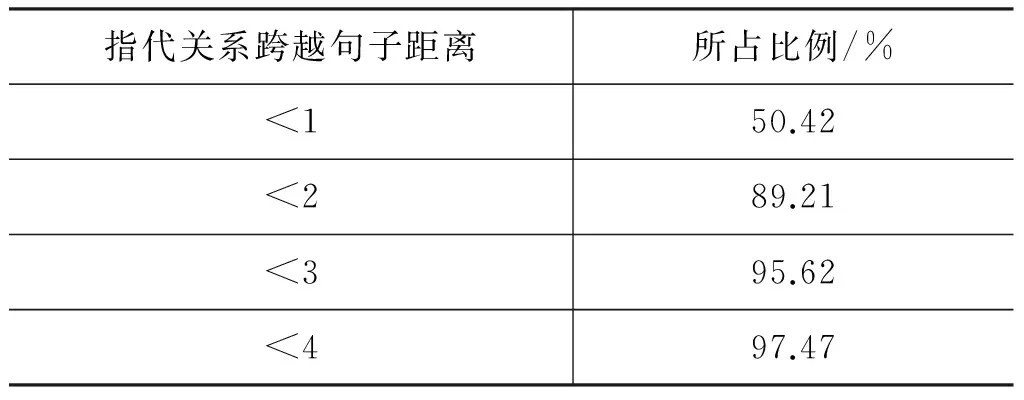
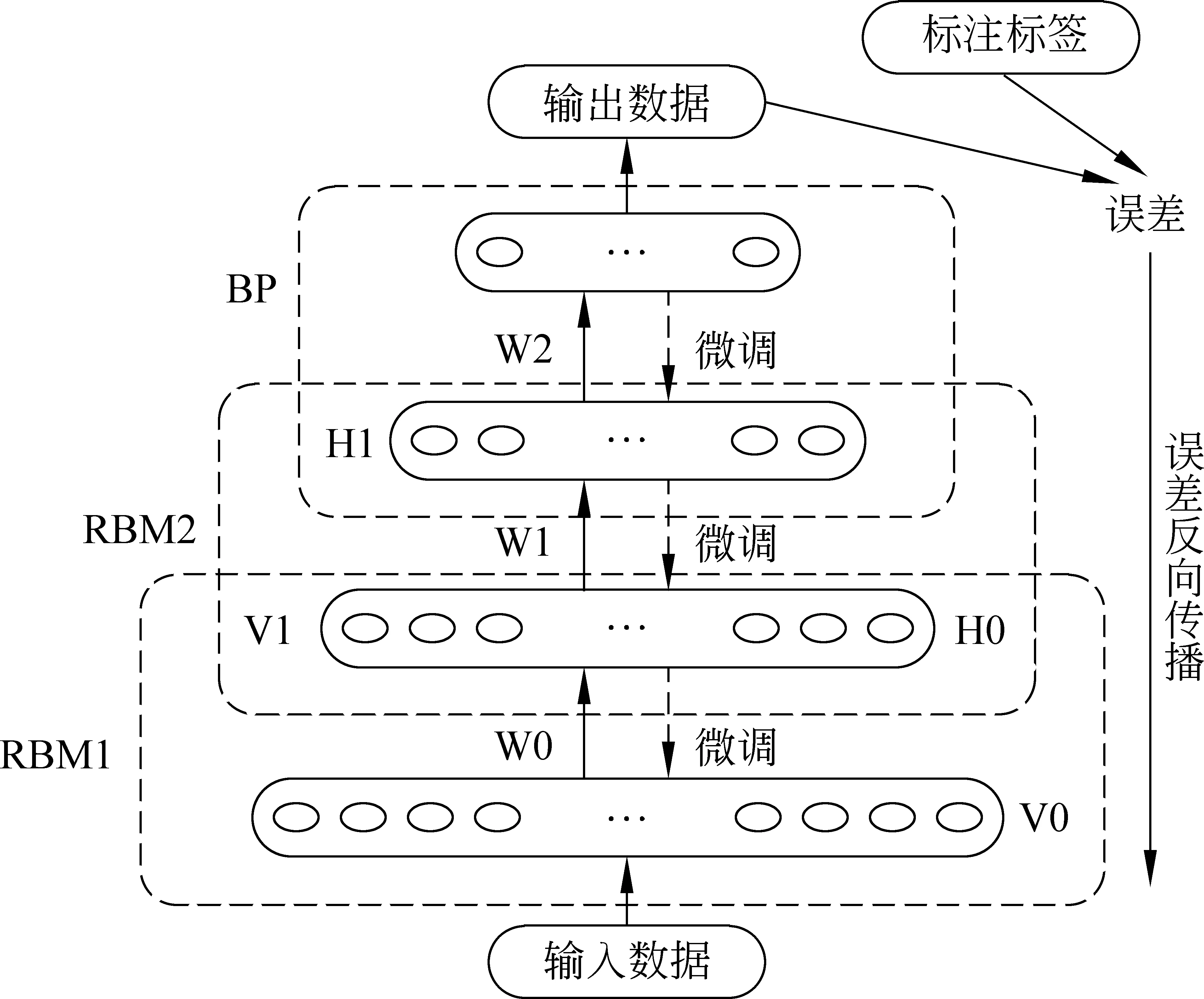
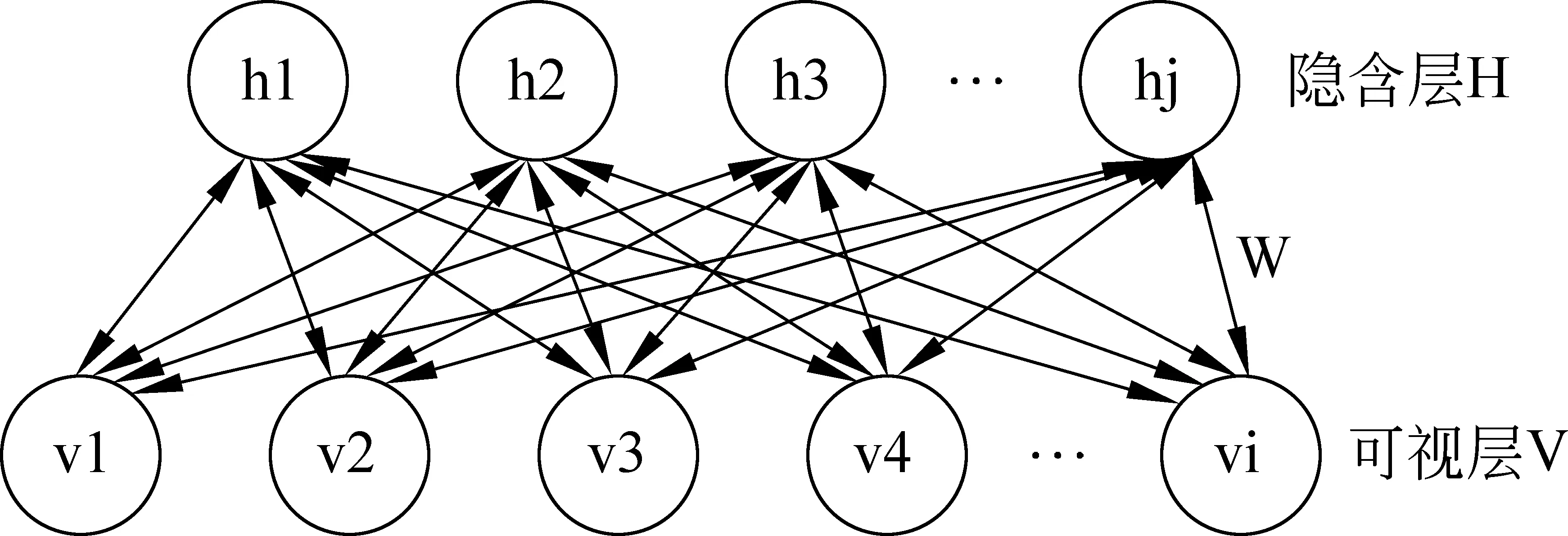
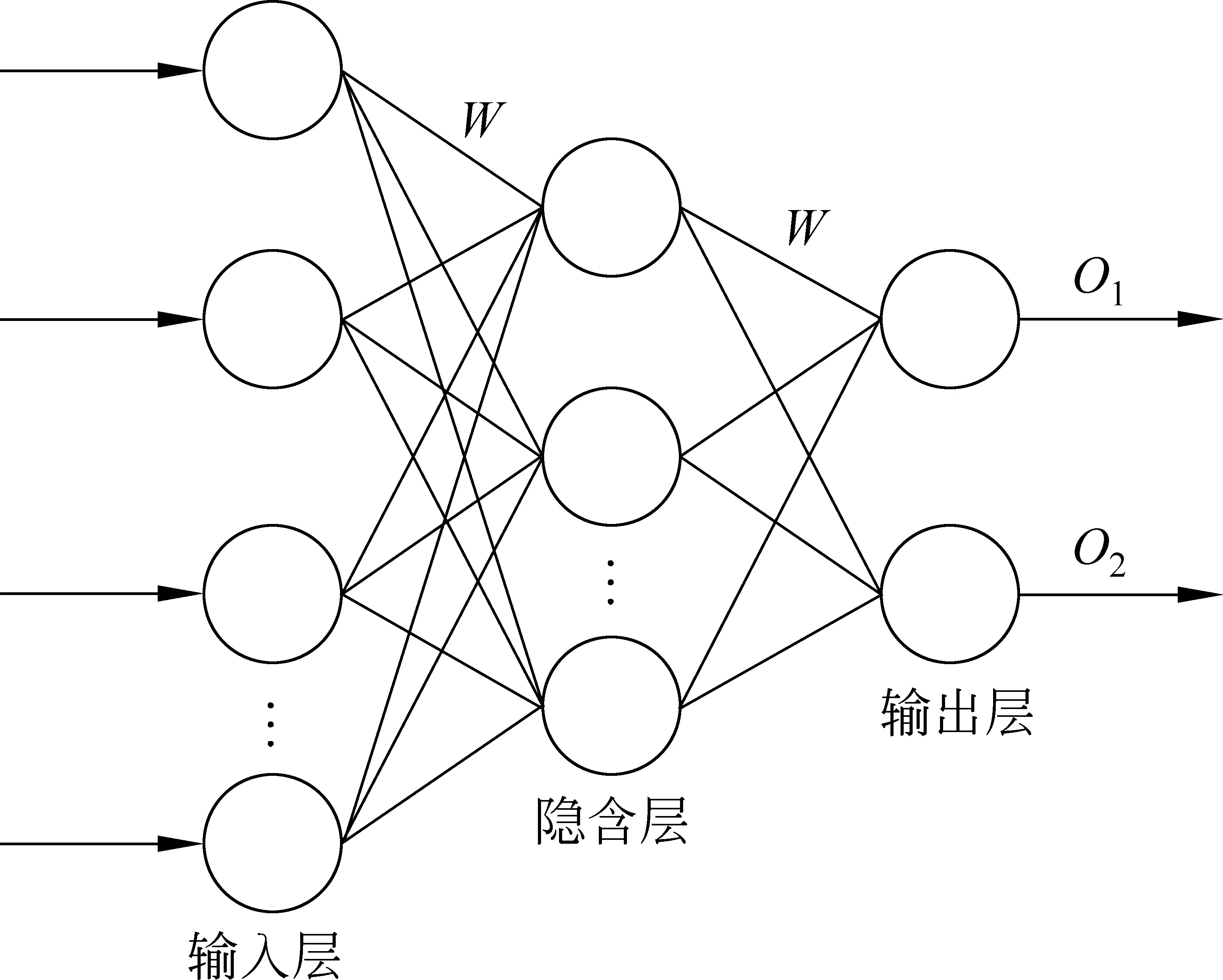
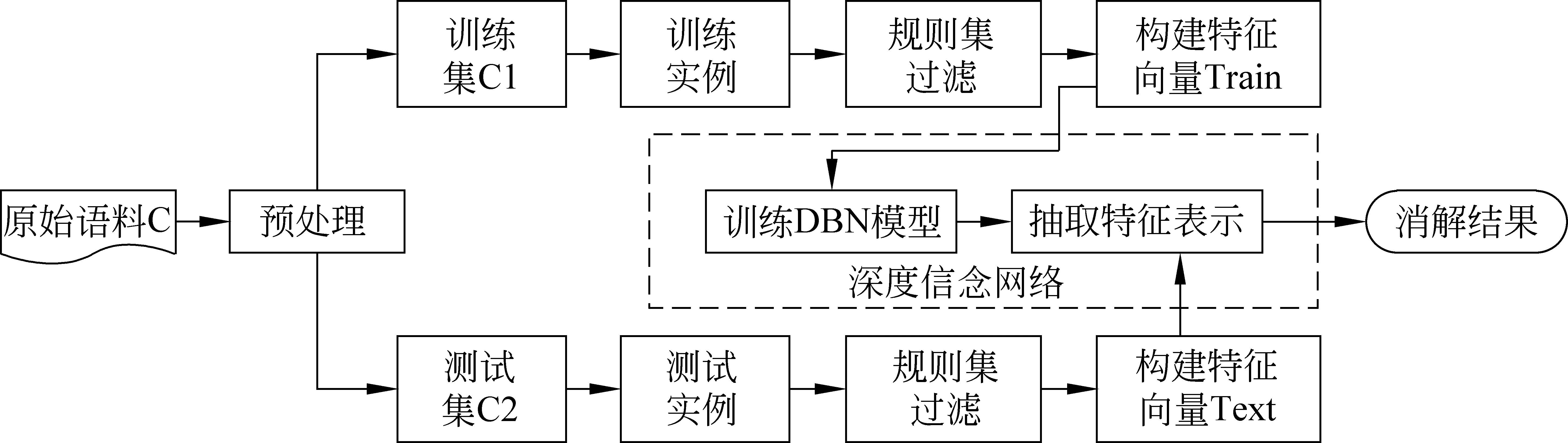
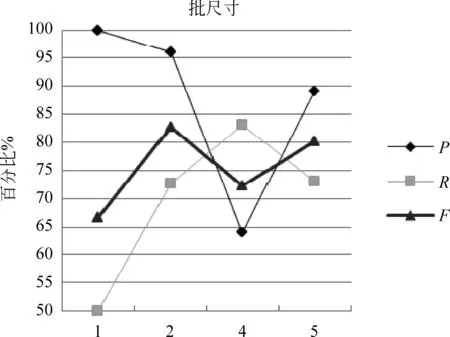
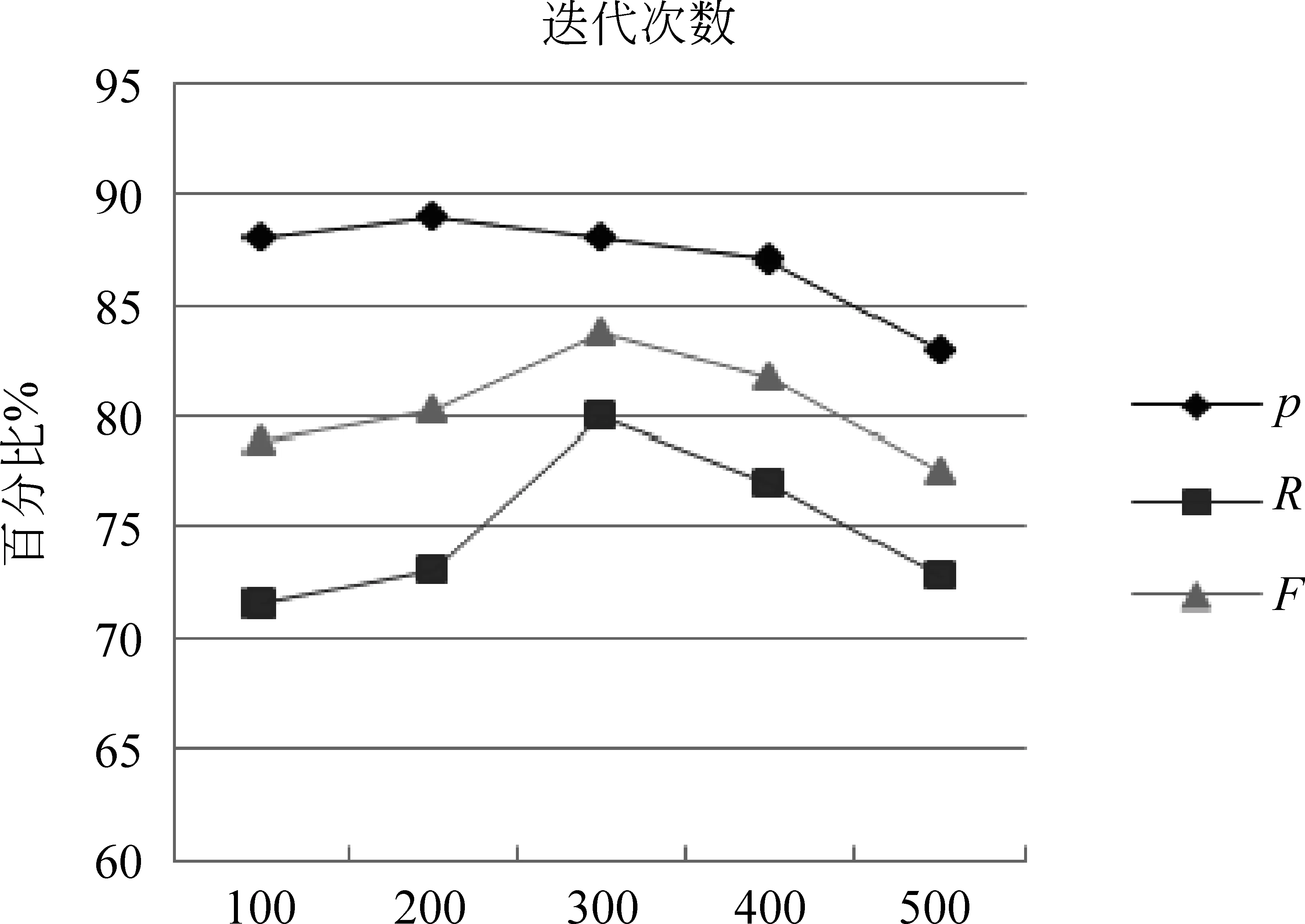
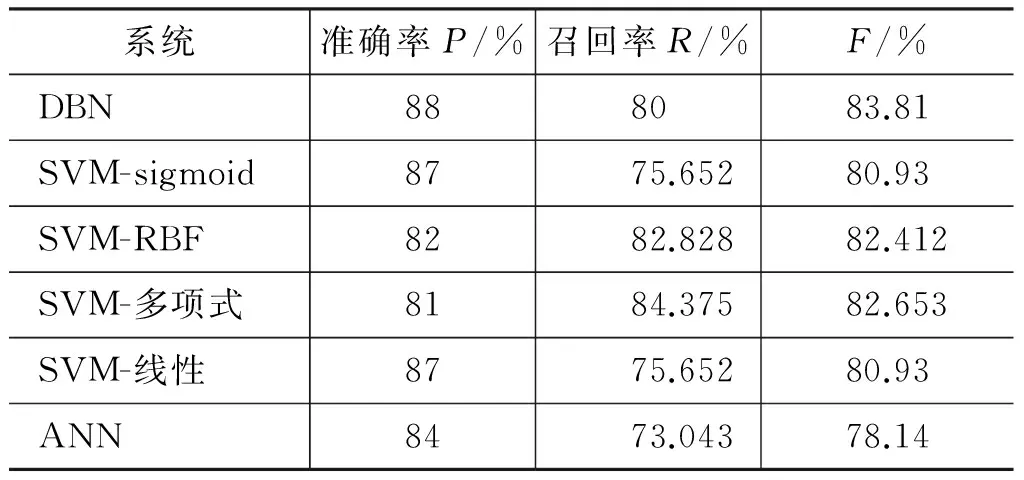
假设训练语料中已标注指代链表述为A1,A2,A3,…,Am,名词短语为NP0,NP1,NP2,…,NPn。对名词短语NPi,查找其是否位于指代链,若不位于指代链中,视为非消解项,不必查找其先行语;若位于某一指代链中,与最近的名词短语NPj组成正例对 表4 训练和测试实例格式 3.2.2 构建测试实例 与训练实例不同,测试实例是没有标注指代链信息的语料,因此在构建测试实例时,识别出的所有名词短语均作为照应语。该照应语之前的所有名词短语均作为它的候选先行语,构成候选先行语集合。根据表5的统计结果,照应语为人称代词,仅需要和距离其四句以内的名词短语进行组队,构成<候选先行语-照应语>对,根据过滤规则进行筛选,提取特征向量构建测试实例。 表5 指代关系跨越句子距离占比统计 深度信念网络(deep beliefr network,DBN),由Geoffrey Hinton于2006年提出。由若干层无监督的受限玻尔兹曼机(restricted boltzmann machine,RBM)和一层有监督的反向传播网络(back propagation,BP)组成[21],通过逐层贪婪算法训练网络层间的权重,依据标准BP进行微调,结构如图2所示。 图2 深度信念网络DBN结构图 图2中,Vi为显性神经元,用于接收输入数据,Hi为隐性神经元,用于提取特征。Wi作为权重,用于微调整个模型。 4.1 受限玻尔兹曼机RBM 受限玻尔兹曼机RBM是一种能量模型,是DBN的核心组件之一。由一个可视层(visible layer)和一个隐含层(hidden layer)组成,如图3所示。 图3 受限玻尔兹曼机RBM结构图 图3中,V表示可视层,由显元vi(0 若可视层的偏置量为a,隐含层的偏置量为b,则在某一特定状态(v,h),利用式(3)由可视层节点值可得到隐含层节点值。 (3) 利用式(4)由隐含层节点值可重构可视层节点值。 (4) RBM可以对一个给定输入信号v=(v1,v2,…,vm),自动生成对应的隐含层特征信号h=(h1,h2,…,hn),此时RBM系统的能量函数定义为: (5) 则给定可视层信号v和隐含层特征向量h的联合概率分布p(v,h)定义为: (6) (7) 其中T为样本数目,E[·]为期望。 4.2 反向传播网络BP 反向传播网络(back-propagation network,BP),是一个有监督的分类器,能够学习和存储“输入-输出”模式的映射关系。采用最速下降算法,通过误差反向传播进行训练,不断调整模型参数,使网络误差平方和达到最小,进而微调整个DBN模型的参数。图4是BP网络示例图。 图4 反向传播网络BP结构图 BP网络训练过程如下: Step1 随机初始化softmax层的网络参数,步长设为N; Step2 前向传播。将输入向量逐层传递到输出层,获得预测分类类别。将实际分类结果与期望类别进行对比得到误差;对于第l层第j个神经元,期望输出为dj,实际输出为Oj,则误差为:ej(n)=dj(n)-Oj(n); Step3 反向传播。误差被逐层反向传播,由输出层传输到输入层,根据式(8)计算局部梯度; (8) Step4 修改权重。根据式(9)修改权值,微调DBN的参数,η为学习速率; (9) Step5 若n=N,训练结束;否则n=n+1,转Step2。 3.3 训练DBN DBN模型的训练主要分为两步: 第一,预训练(pre-training)。单独训练每一层无监督RBM网络,低一层RBM的输出作为高一层RBM的输入,保证特征向量映射到特征空间时保留足够多的特征信息,进而形成概念化的特征;第二,微调(fine-tuning)。采用BP网络,有监督地训练DBN最顶层,将之前学习到的特征进行分类,并将误差逐层向后传播,微调整个DBN网络的权重。具体操作如下。 Step1 充分训练第一层无监督RBM网络; Step2 固定第一层RBM的权重w和偏移量d,之后将其隐层神经元的输出(即学习到的特征)作为第二层RBM的输入向量; Step3 充分训练第二层RBM后,将其堆叠在第一层RBM上; Step4 根据需要重复上述三个步骤任意次数; Step5 若训练数据集中有标签,则在顶层RBM训练时,将标识分类标签的神经元追加到该层的显层中,一起进行训练。 4.4 基于DBN的维吾尔语人称代词指代消解 根据Soon等人的指代消解框架,结合维吾尔语人称代词特征,采用深度学习算法实现维吾尔语人称代词指代消解。基本思想是把指代消解转化为二元分类问题,采用softmax作为分类器,判断照应语和每个候选先行语是否存在指代关系。具体框架结构如图5所示。 对原始语料C进行预处理,分为训练集C1,测试集C2。根据需要,提取C1中的名词短语,两两组对构成训练实例集;根据过滤规则去除不具有指代关系的实例;根据设定特征集R,获取特征取值,结合记录指代链信息确定实例正负关系,构建特征向量Train,形成训练文件;将Train输入DBN模型进行训练,生成训练模型。对测试集C2,与训练集类似,不同之处是构建的特征向量Text中不含有正负例信息;将Text输入DBN模型,进行测试,返回结果与已标注的信息进行对比,最后输出结果。 图5 基于DBN的维吾尔语人称代词消解模型结构图 目前,国际上通用的指代消解语料为MCU和ACE,但关于维吾尔语指代消解测评语料库未见报道,因此需要针对维吾尔语标记特定语料。课题组从天山网的维文版和一些维文商业网站上,搜集了涵盖新闻、童话故事、人物传记等在内的共137篇文章,经人工标注作为实验数据,其中三类人称代词分布比例如表5所示。根据2.1节的特征表示提取人称代词消解所需的特征,根据2.2节构建训练实例和测试实例。之后分别交由DBN模型进行学习和测试。实验采用五倍交叉验证法,取其平均值作为实验结果。 表5 维吾尔语句人称代词类别分布 5.1 测评标准 本文采用自然语言处理中常用的MUC测评标准[22],即准确率P、召回率R和F指数衡量实验结果的优劣,定义如下: (10) 其中,准确率P反映模型的准确程度;召回率P反映模型的完备性;F指数综合反映模型的整体性能,是P和R的调和平均值。 5.2 可变参数选择 DBN模型中可变参数对实验结果有一定影响,本文经过多次实验,从中选取部分参数测试它们对模型性能的影响。本组实验选取批处理参数、迭代次数进行实验,实验过程中其他网络参数均选取最优参数组合(表6)。 表6 最优参数组合 5.2.1 批处理参数 在深度机器学习中,为提高计算效率,将训练集分成包含若干样本的小批量数据进行计算,批处理样本的大小称为批尺寸(batch)。batch决定深度神经网络在优化过程中梯度下降方向。batch过大,模型易收敛到较差的局部最优点;batch太小,模型训练速度慢且不易收敛。图6是不同批尺寸参数下模型指代消解效果。 图6 批尺寸参数 从图6可以发现,当batch取1时,网络收敛不稳定,导致结果比较差;之后随着批尺寸参数的增大,模型的三个评价指标均上下波动,但在批尺寸为5时,效果比较理想,模型收敛精度达到最优,准确率为89%,召回率为72.95%,F值为80.18%。 5.2.2 迭代次数 在实验过程中,使用不同的迭代次数对模型进行调优,为避免过拟合现象,需要为模型选择一个合适的迭代次数。图7是不同迭代次数下模型指代消解效果。 图7 迭代次数 图7中的实验结果表明,对迭代次数进行调整,模型性能更加精确。当迭代次数为300时,模型对实验数据的拟合度较合理,准确率可以达到88%,召回率可以达到80%,F值可以达到83.81%。 5.3 模型对比试验 根据4.2节参数设定,在相同条件下比较DBN模型与不同核函数的SVM模型和ANN人工神经网络对维吾尔语人称代词消解效果,实验结果见表7。ANN模型采用最优参数组合(两层隐藏层、迭代次数700次,批尺寸为20)。 表7 模型对比结果 从表7可以发现,相较于不同核函数的SVM模型,DBN模型召回率虽未达到最高,但准确率和F值提升比较明显,分别达到88%和83.81%;同时,DBN模型的准确率、召回率和F值都高于ANN模型,表明DBN模型是有效的。这是因为SVM和ANN属于传统机器学习模型,特征提取能力相对较弱,对数据的刻画能力欠佳;而DBN学习模型利用多层深度学习思想,获取输入数据的驱动特征,进而提高指代消解质量。 本文结合维吾尔语语言特征讨论了人称代词指代消解问题。针对浅层机器学习对复杂函数泛化能力的局限性,探索DBN多层神经网络模型在维吾尔语人称代词指代消解中的应用。相较于以往研究方法,基于DBN模型处理人称代词消解问题,充分考虑上下文信息,将复杂的学习任务转化为对深层数据信息的挖掘过程,有效提高了指代消解的性能。下一步工作是基于深度学习训练平台,探索深度学习的并行特性对指代消解运行效率的提升效果。 [1] 奚雪峰, 周国栋.基于Deep Learning的代词指代消解[J].北京大学学报(自然科学版), 2014, 50(1): 100-110. [2] McCarthy J,Lehnert W. Using decision trees for coreference resolution[C]//Proceedings of the Fourteenth International Conference on Artificial Intelligence. Montreal, 1995: 1050-1055. [3] Soon W M, Ng H T, Lim C Y. A machine learning approach to coreference resolution of noun phrases[J]. Computational Linguistics, 2001, 27(4): 521-544. [4] 孔芳, 周国栋.基于树核函数的中英文代词消解[J].软件学报, 2012, 23(5): 1085-1099. [5] Ng V, Cardie C. Improving machine learning approaches to coreference resolution[C]//Proceedings of the ACL 2002.2002: 104-111.[doi: 10.3115/ 1073083.1073102] [6] Yang XF, Su J, Tan CL. A twin-candidate model for learning-based anaphora resolution[J]. Computational Linguistics,2008,34(3): 327-356. [doi: 10.1162/coli.2008.07-004-R2-06-57] [7] Kong F, Zhou G D, Zhu Q. Employing the centering theory in pronoun resolution from the semantic perspective[C]//Proceedings of the ENNLP 2009. [8] 许敏, 王能忠, 马彦华. 汉语中指代问题的研究及讨论[J]. 西南师范大学学报(自然科学版), 1999(6): 633-637. [9] 王厚峰, 何婷婷. 汉语中人称代词的消解研究[J]. 计算机学报, 2001, 24(2): 136-143. [10] 王厚峰,梅铮.鲁棒性的汉语人称代词消解[J]. 软件学报, 2005, 16(05): 700-707. [11] 李国臣, 罗云飞.采用优先选择策略的中文人称代词的指代消解[J]. 中文信息学报, 2005, 19(04): 24-30. [12] 李凡, 刘启和, 李洪伟.基于Fuzzy Rough集模型的汉语人称代词消解[J]. 计算机科学, 2010, 37(01): 245-250. [13] 孙志军, 薛磊, 许阳明, 等.深度学习研究综述[J]. 计算机应用研究, 2012, 29(08): 2806-2810. [14] 孙茂松, 刘挺, 姬东鸿, 等.语言计算的重要国际前沿[J]. 中文信息学报, 2014, 28(01): 01-08. [15] Mohamed A, Sainath T N, Dahl G, et al. Deep belief Networks using discriminative features for phone recognition[C]//Proceedings of the 19th IEEE International Conference on Acoustics.2011: 5060-5063. [16] Nair V, Hinton G E.3D object recognition with deep belief nets[C]//Proceedings of A Meeting Held 7-10 December 2009, Vancouver, British Columbia, Canada.2012: 1527-1554. [17] Seide F, Li G, Yu D. Conversational speech transcription using context-dependent deep neural networks[C] //Proceedings of the 12th International Conference on Spoken Language Processing(INTERSPEECH), 2011: 437-440. [18] Collobert R, Weston J, Bottou L, et al. Natural language processing(almost)from scratch [J]. Journal of Machine Learning Research, 2011(12): 2493-2537. [19] 段祥超, 禹龙, 田生伟,等. 维吾尔语意见挖掘关系抽取研究[J].计算机工程与设计, 2013,34(9): 3260-3265. [20] 杨勇, 李艳翠, 周国栋, 等.指代消解中距离特征的研究[J].中文信息学报, 2008,22(05): 39-44. [21] Hinton G E, Osindero S, Teh Y W. A Fast learning algorithm for deep belief nets[J]. Neural Computer, 2006, 18(7): 1527-1554. [22] 董国志, 朱玉全, 程显毅.中文人称代词指代消解的研究[J].计算机应用研究, 2011,28(05): 1774-1779. 李冬白(1989—),硕士研究生,主要研究领域为自然语言处理。 E-mail: db.li@cnnlper.cn 田生伟(1973—),通信作者,博士,教授,研究生导师,主要研究领域为自然语言处理与计算机智能技术等。 E-mail: tianshengwei@163.com 禹龙(1974—),博士,教授,研究生导师,主要研究领域为计算机智能技术与计算机网络等。 E-mail: yul_xju@163.com Deep Learning for Pronominal Anaphora Resolution in Uyghur LI Dongbai1, TIAN Shengwei1, YU Long2, Turgun Ibrahim3, FENG Guanjun4 (1. School of Software, Xinjiang University, Urumqi, Xinjing 830008, China;2. Net Center, Xinjiang University, Urumqi, Xinjing 830046, China;3. School of Information Science and Engineering, Xinjiang University, Urumqi, Xinjing 830046, China;4. College of Humanities,Xinjiang University, Urumqi, Xinjing 830046, China) 1003-0077(2017)04-0080-09 TP391 A

4 深度信念网络DBN

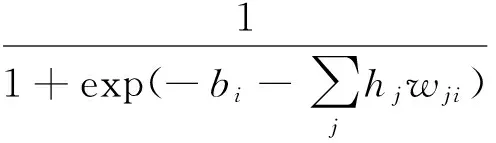
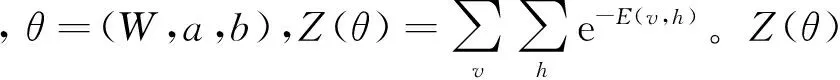
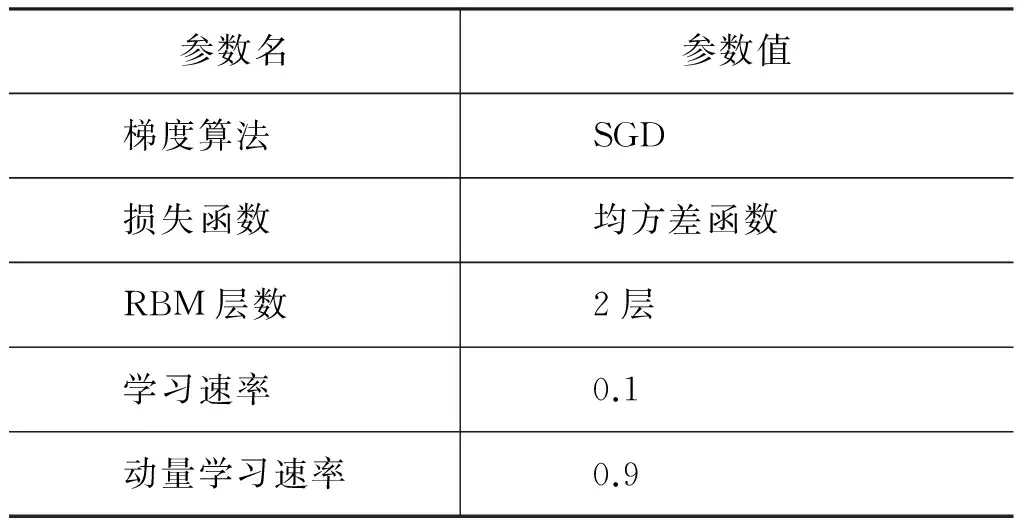
5 实验和结果分析
6 结束语



