基于动态词对齐的交互式机器翻译
2017-10-11蔡东风
马 斌,蔡东风,季 铎,叶 娜,吴 闯
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
基于动态词对齐的交互式机器翻译
马 斌,蔡东风,季 铎,叶 娜,吴 闯
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
在传统的机器翻译(machine translation,MT)与计算机辅助翻译(computer aided translation,CAT)中,译员与翻译引擎之间的交互受到很大限制,于是产生了交互式机器翻译(interactive machine translation,IMT)技术。但传统的模型只考虑当前源语与部分翻译的目标语的信息,没有将用户交互后的对齐信息加入到之后的预测模型中。该文基于词预测交互式机器翻译的研究思路,将用户交互翻译过程中的鼠标点选行为转化为中间译文的词对齐信息,进而在翻译交互过程中实现了对译文的动态词对齐标注,并在词对齐信息和输入译文的约束下提高了传统词预测的准确性。
交互式机器翻译;词对齐;预测模型
Abstract: The traditional interactive machine translation (IMT) is focused on the current source language and the partial translation of the target language, neglecting the feedback from the translators to better predict the subsequent translations. This paper investigates the translation selection clicks, and proposes a dynamic word alignment model for the partial translation. Experiment indicates this method improves the word prediction accuracy during the interactive machine translation process.
Key words: interactive machine translation;word alignment;prediction model
收稿日期: 2015-09-26 定稿日期: 2015-12-20
基金项目: 国家自然科学基金(61403262,61402299)
1 引言
统计机器翻译(statistical machine translation,SMT)技术的提出为机器翻译技术走向实用化打下了基础。但现有的自动翻译的质量还远没有达到人们的需求,不能完全取代人类[1-3]。计算机辅助翻译(computer aided translation,CAT)的提出,为机器与人类译员提供合作的平台,由计算机完成翻译过程中烦琐而相对简单的任务,由人类译员完成相对重要的翻译任务,有效提高了翻译人员的工作效率。为进一步提高翻译效率[4-5],增大人类译员在翻译过程中的主导地位,提出了交互式机器翻译(interactive machine translation,IMT)的概念,允许人类译员在翻译过程中对机器进行干预和指导,从而获取较高质量的译文[6-8]。近年来,有研究人员将人机交互过程转变为在翻译记忆的参考译文上进行后编辑[9-11](post-editing)。这种方法一方面比较依赖于翻译资料中重复的内容,另一方面也限制了人类译员在翻译过程中的交互。
为此,Foster等开展了一项有趣的研究工作,提出使用词预测(word prediction)技术来实现在人机交互中的预测式交互翻译(interactive-predictive machine translation , IPMT),该方法将用户的翻译行为看作是一个顺序的选词过程,而系统需要在每一个翻译选词的过程中通过前缀不断预测下一译文,每次译员的选择都影响着下一次机器的推荐,真正实现了系统与用户在翻译过程中的深度交互,并在欧盟法案的翻译中获得成功应用。后来Foster[12-13]又进一步开展了面向短语和用户词典的IPMT技术完善工作,Alabau[14]于2012年通过改进IPMT的交互界面对IPMT和PE技术进行了比较分析,在真实的人工评测中,IPMT在翻译效率和用户满意度两个层面获得了肯定。
IPMT的交互式翻译过程如图1所示[15-16],初始时给定输入原语句f,系统预测用户的下一步的输入e,而后用户通过接受系统的预测或者输入正确译文k的方式与系统进行交互,与此同时系统将现有用户的输入ep作为约束,在用户每次操作(单个字母的输入)后动态产生更为符合用户预期的预测。在翻译的过程中,用户与系统不断交互,直到整个句子翻译完成。
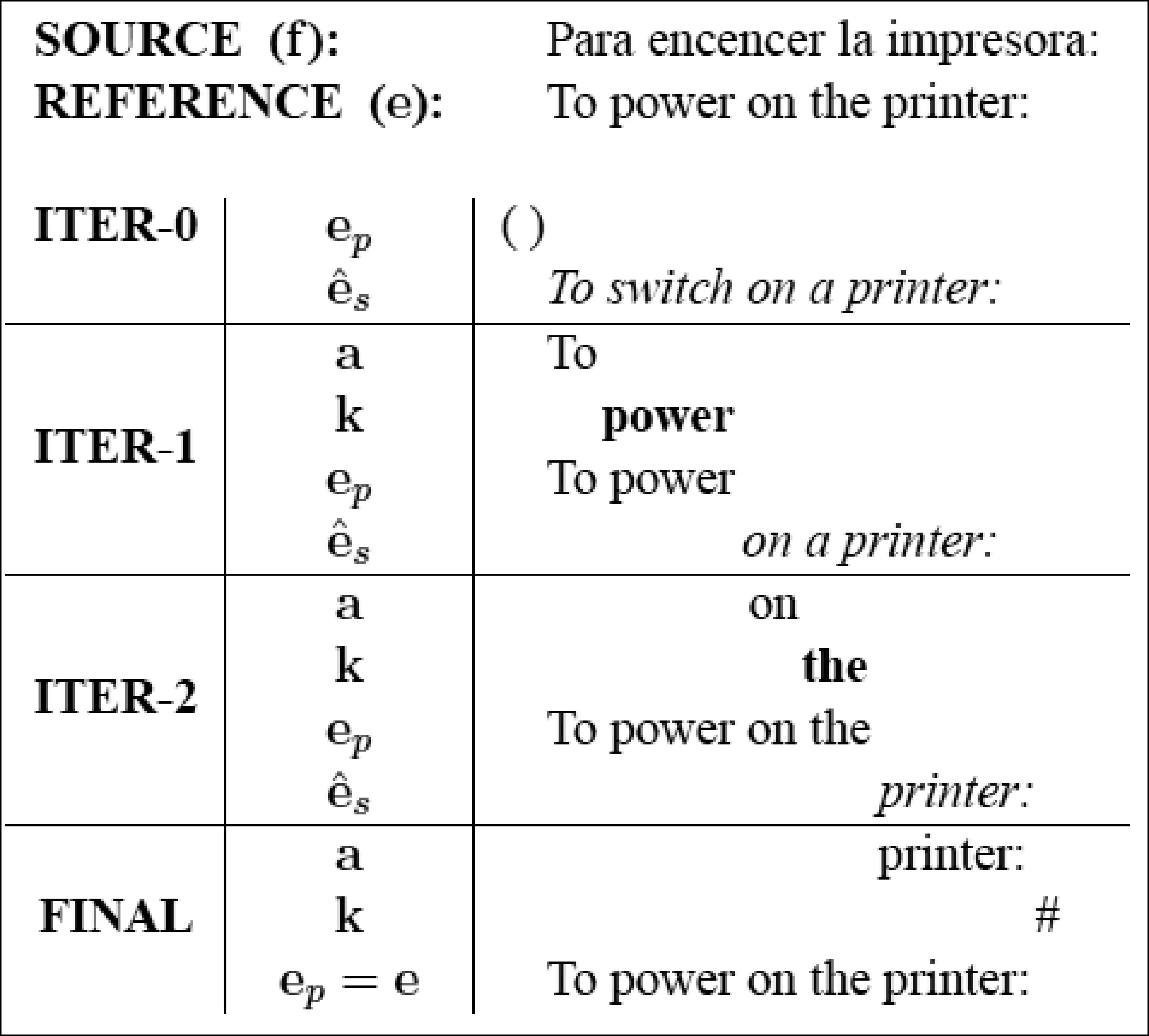
图1 IPMT交互式翻译过程 由西班牙语翻译到英语,系统推荐为斜体字,用户接受的为正常字体,用户输入为粗体字
从上述交互过程中可以看到IPMT在人工翻译的基础上,通过系统的预测自动或半自动地完成用户译文输入,实现了翻译效率的提高。因此,交互过程中用户实际单词输入数量与原句子单词总数的比(word stroke rate,WSR)也自然作为衡量IPMT技术的主要指标。
IPMT的研究工作主要集中在三个层面,首先从算法效率方面,Kern最早提出采用词图(word graph)的方法尽可能对翻译候选进行优化存储,提高用户每次操作的相应速度,Sanchis-Trilles[17]在2014年采用三种策略对词图进行了裁枝,在保证指标不变的情况下提升了系统的效率;与此同时,更多研究人员希望IPMT在一次操作中能够提供更多的预测内容,并将主要的预测单元从词扩展到短语和句子,尽管后期的人工评价对此也给予了积极的评价,但由于更长的预测不仅使得相关模型更为复杂,影响了交互体验,同时也给用户理解机器的预测带来了较多的困扰;为进一步丰富IPMT的交互方法,手写、语音输入等交互手段也被引入到IPMT系统中,在交互式机器学习(interactive machine learning)的理论框架中,既提高了相关输入的识别准确率,又保证了用户通过简单的人机交互获得更好的翻译体验。
然而从IPMT的技术发展来看,研究人员主要还是从用户的输入角度讨论人机的翻译交互,而忽略了其他的用户交互行为对翻译效率的影响,例如用户利用鼠标完成的译文点选、用户视觉关注内容及利用电子词典的查词行为等。本文基于词预测交互式机器翻译的研究思路,将用户交互翻译过程中的鼠标点选行为转化为中间译文的词对齐信息,进而在翻译交互过程中实现了对译文的动态词对齐标注,并在对齐信息和输入译文的约束下提高了传统词预测的准确性。
2 词预测模型
2.1 传统词预测模型 翻译交互过程中的上下文环境主要是由原语S=s1,s2,…,sn-1,sn以及p(x|S,T)部分的翻译结果T=t1,t2,…,tk-2,tk-1构成,则待预测译文x的概率可转化为条件概率。但由于S,T对于当前预测都为常量,因此Foster利用线性插值对其进行了近似求解,即:
(1)
由于输入译文是从左向右依次构成的,随着输入的不断增加,也导致语言模型p(x|T)在预测模型中的重要程度不同,因此λ(S,T)被定义为S和T的线性插值函数,用于调节在翻译过程中的不同时期语言模型和翻译模型的比重。
上式中p(x|T)为语言模型,由SRILM工具训练得到;p(x|S)为翻译模型,由词典,双语对齐语料及词对齐关系训练得到,其计算方法如式(2)。
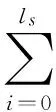
(2)
其中ls表示原语S的长度,si代表原语中第i个位置的单元,k代表译文x所处的位置。p(x|si)为传统的词翻译模型,a(i|k,ls)代表原语第i个位置与译文第k个位置在原语ls条件下的对齐概率。
尽管用户的输入译文T作为约束是交互翻译的重要参考,但是上述模型中该约束仅用于语言模型,而在翻译模型中未引入上述约束,并也由此导致其预测准确率不高。
2.2 基于词对齐的词预测模型
设A为原语S以及部分的翻译结果T间的对齐关系,但由于T是不完整的译文,因此从原语到目标语的对齐关系不完整。因此,本文将对齐关系设定为从目标语到原语,即(t,at)(以下用at表示),at∈A代表目标语中第t个词与原语第at个词存在翻译对齐关系。
待预测译文x将被置于翻译结果的第k个位置,其对齐关系为ak,则译文x的预测概率可转化为条件概率p(x,ak|S,A,T)。此时译文的预测就变成对上述概率最大值的寻找,可以通过式(3)给出。
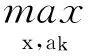
(3)
依据贝叶斯公式上述计算式(3)又可直接推导为:
(4)
其中,p(x|S,A,ak,T)为译文x在对齐关系{ak}∪A的预测概率;p(ak|S,A,T)为对齐关系的预测概率。
有了部分对齐结果后,设{ak}∪A=A′,则,p(x|S,A,ak,T)=p(x|S,A′,T),进一步利用贝叶斯公式可得到:
(5)
p(x|T)为语言模型,而p(S,A′|T,x)为词对齐关系A′条件下,原语S以及部分的翻译结果T,x=t1,t2,…,tk-2,tk-1,x的翻译概率。本文采用IBM model3方法对翻译概率进行求解,进一步我们将上述公式分解:
(6)
其中d(aj|aj-1,ls)为方向位变概率,是沿着翻译方向构造的,根据输入词的位置预测输出词的位置的概率分布;ng(φi|si)为繁衍概率,表示对于每个源语词si通常被翻译成多少个输出单词的概率分布。但与传统的繁衍概率ng(φi|si)不同,由于交互翻译中的译文是部分的翻译结果,导致依据当前对齐获得的繁衍数量φi不准确,因此本文采用的繁衍概率为原语si繁衍数量大于φi的概率,可表示为:
(7)
在给定用户输入T的前提下
的数值可以近似为常量,因此:
(8)
2.3 算法实现
本文在生成预测模型前,使用Niutrans的GIZA++做词对齐处理,得到词对齐结果;使用SRILM工具得到语言模型。使用训练语料训练得到以下模型:
• 对齐概率模型,源语的某一位置对齐到目标语某一位置的概率模型,使用词对齐结果统计得到;
• 方向位变概率模型,在当前翻译位置的前词所对齐的源语的位置条件下,源语的某一位置与当前翻译位置的对齐概率模型,使用词对齐结果统计得到;
• 翻译概率模型,源语某词翻译到目标语某词的概率模型,利用双语词典和词对齐结果使用式(2)得到;
• 繁衍概率模型,源语某已经翻译过n次的词再次被翻译m次概率模型,使用双语词典和词对齐结果统计得到。
将式(4)、式(5)、式(8)整合可以得到式(3),将方向位变概率模型、繁衍概率模型、翻译概率模型整合到一起,得到基于翻译模型的条件概率p(x,ak|S,A,T)。通过式(1)使用8 000句开发集语料进行迭代,选出不同预测位置时能使正确答案平均排名最高的参数值,即得到线性插值参数λ(S,T)。
预测算法的伪代码如下:
Step1: 载入双语对齐的测试语料
(源语S长度为m,目标语T长度为n,提供h个候选)
Step2: 总预测数all=0,
正确预测数right=0翻译正确标记tag=0
for i=0 to n-1 do
得到得分从大到小排序的
翻译候选列表answer。
tag=0
all++
for j=0 to h do
if answer[0]==T[i]
tag=1
记录对齐位置
break
else do
continue
if tag do
right++
更新预测模型
Step3: score=right/all
在翻译目标语的每个词后,会记录其对齐关系,以及源语端的词。通过这些信息,更新方向位变概率模型,语言模型,繁衍概率模型等,重新生成预测模型,进行下一位置的预测。
3 实验
3.1 实验设置 本文实验是在英语到汉语的翻译工作中做的。双语平行语料是LDC2003E14的十万句平行句对,使用Niutrans的GIZA++做词对齐处理。单语语料为搜狗实验室的SogouCA的150万句中文新闻语料,并使用SRILM工具进行语言模型的训练。所有中文语料使用中科院分词工具对汉语进行分词。
使用人工标注的1 000句双语对齐语料进行测试。统计计算在不同候选数下的正确率。具体过程为:
本文采用n-best的推荐方式,根据提供的原语,系统在当前翻译位置上给出n(n取1,3,5,10)个翻译候选词供用户选择,使用翻译候选词的正确率来评价模型,如式(9)所示。
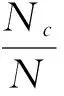
(9)
其中,N表示译文预测的总次数,Nc表示用户使用的翻译候选次数,即译文预测正确的次数。
本文以Foster的线性插值方法作为Baseline同现有方法作比较。
3.2 实验结果
图2横坐标为预测的候选数,纵坐标为Baseline和动态词对齐方法DWA的预测正确率。
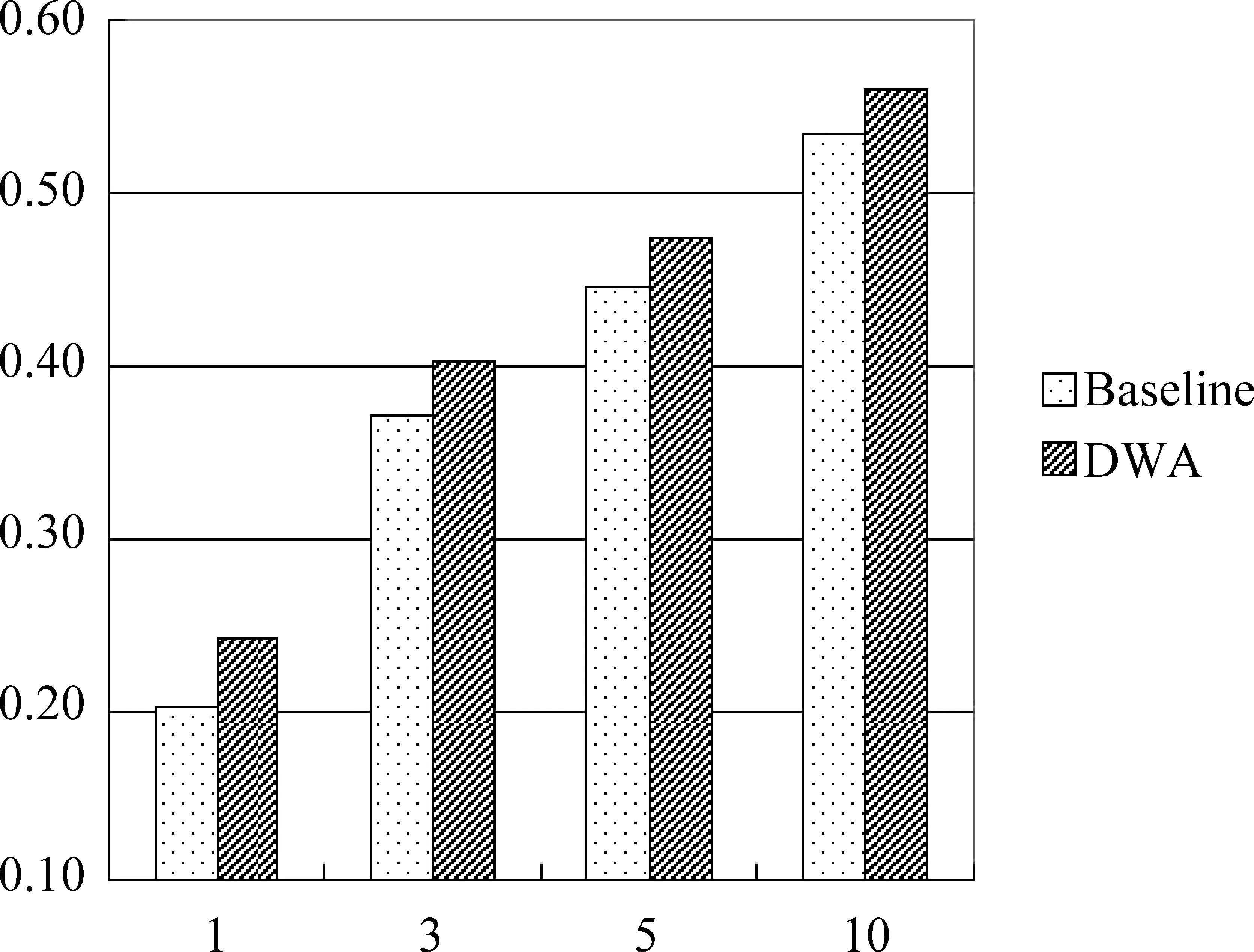
图2 所有词预测正确率
如图2所示,随着候选数的增加,两种方法的正确率均有所提高,而DWA方法的正确率始终高于Baseline的方法。在1候选时DWA预测正确率为24.25%,Baseline的预测正确率为20.24%,此时DWA方法提升效果最明显,提高了4.01%。
经过实验我们发现,该模型对实词的预测提高较为明显,以下我们从停用词和实词的角度研究了预测效果。
3.2.1 不同种类的预测分析
图3为两种方法下目标语中停用词的预测正确率。停用词约占目标语中词汇的20%。
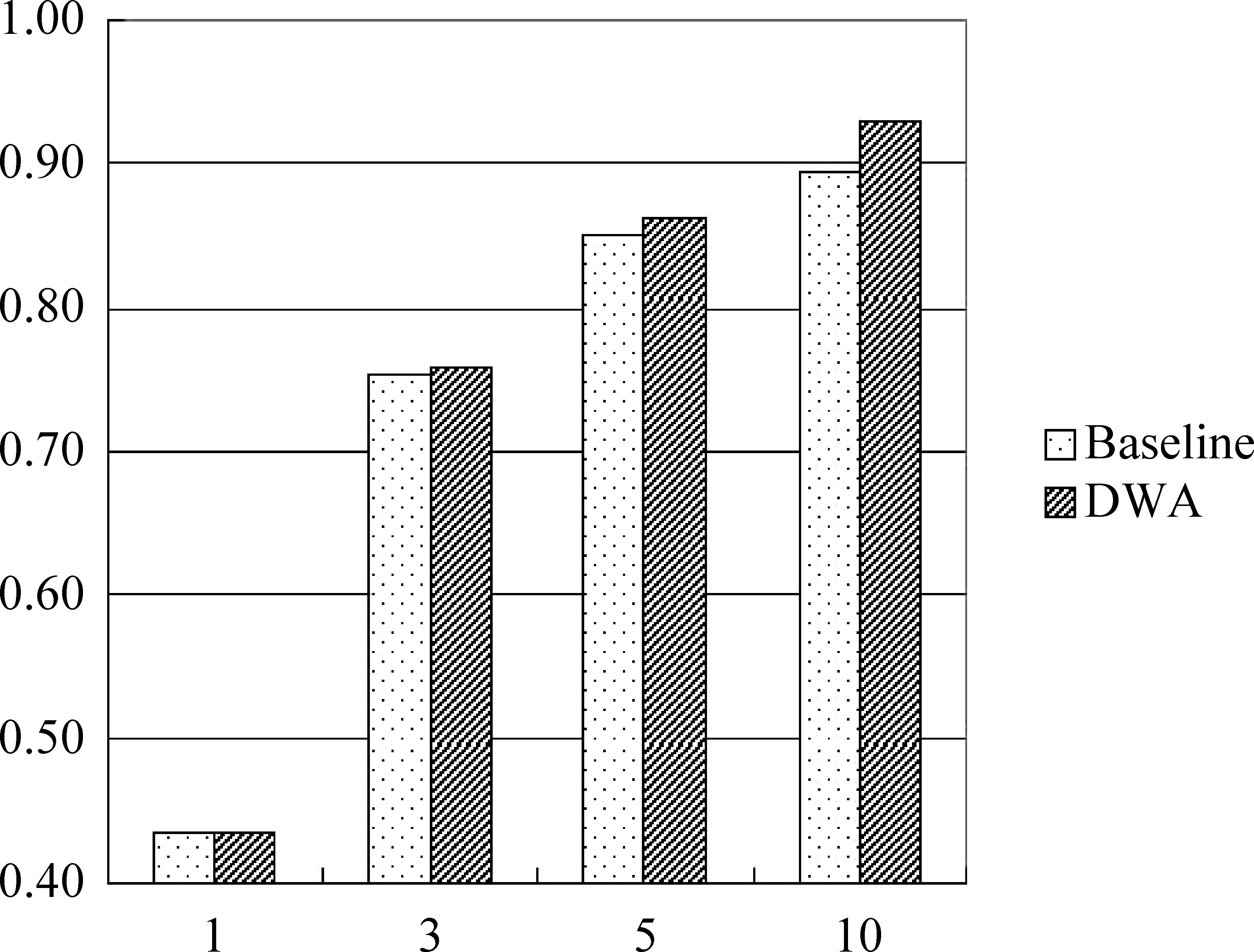
图3 停用词的预测正确率
如图3所示,停用词的预测正确率从第一候选开始就比较高。主要原因是,停用词数目相对实词来说很少,同时比较好预测,所以一开始候选数为1的时候停用词的预测正确率就很高。
另外,随着候选数的增大,提升效果有所提高。主要原因是,停用词相对实词数目少了很多,也较容易预测,随着候选数的增大,停用词在n-best 预测列表里数目越大,使预测准确率的提升增大。
图4为两种方法下目标语中实词的预测正确率,虽然相对于图2正确率下降很多,但是DWA方法相对于Baseline的提升也很大。当候选数为1时,DWA方法的正确率为19.36%,而Baseline的预测正确率为14.35%,高出了5.01%。从这一角度也体现出DWA模型对词预测的提升有实质性的提高。

图4 实词的预测正确率
另一方面,随着候选数的增大,提升效果有所降低。主要原因是,当候选数增大时,数目少且较好预测的停用词在翻译候选中的比例增大,此时对实词的预测受到影响,使实词的预测准确率提升效果有所减低。
3.2.2 词对齐关系对预测正确率的影响
为了进一步研究词对齐结果对模型的影响,我们把正确的词对齐结果加入到模型中。如图5所示,在当前翻译位置,给定上一翻译的正确对齐位置后,得到DWA(Max)的预测正 确 率,从 图5可 以 看出,DWA(Max)的预测正确率相对于DWA方法有所提升,主要原因是,在提供了正确的词对齐关系后,模型的预测效果会达到最好。但是只提升了约0.7%的主要原因是,测试语料中的词对齐结果是由GIZA++处理得到的,由于测试语料自身问题,其中有很多对空的情况,无法在每次预测时给出目标语前词的对齐的位置。
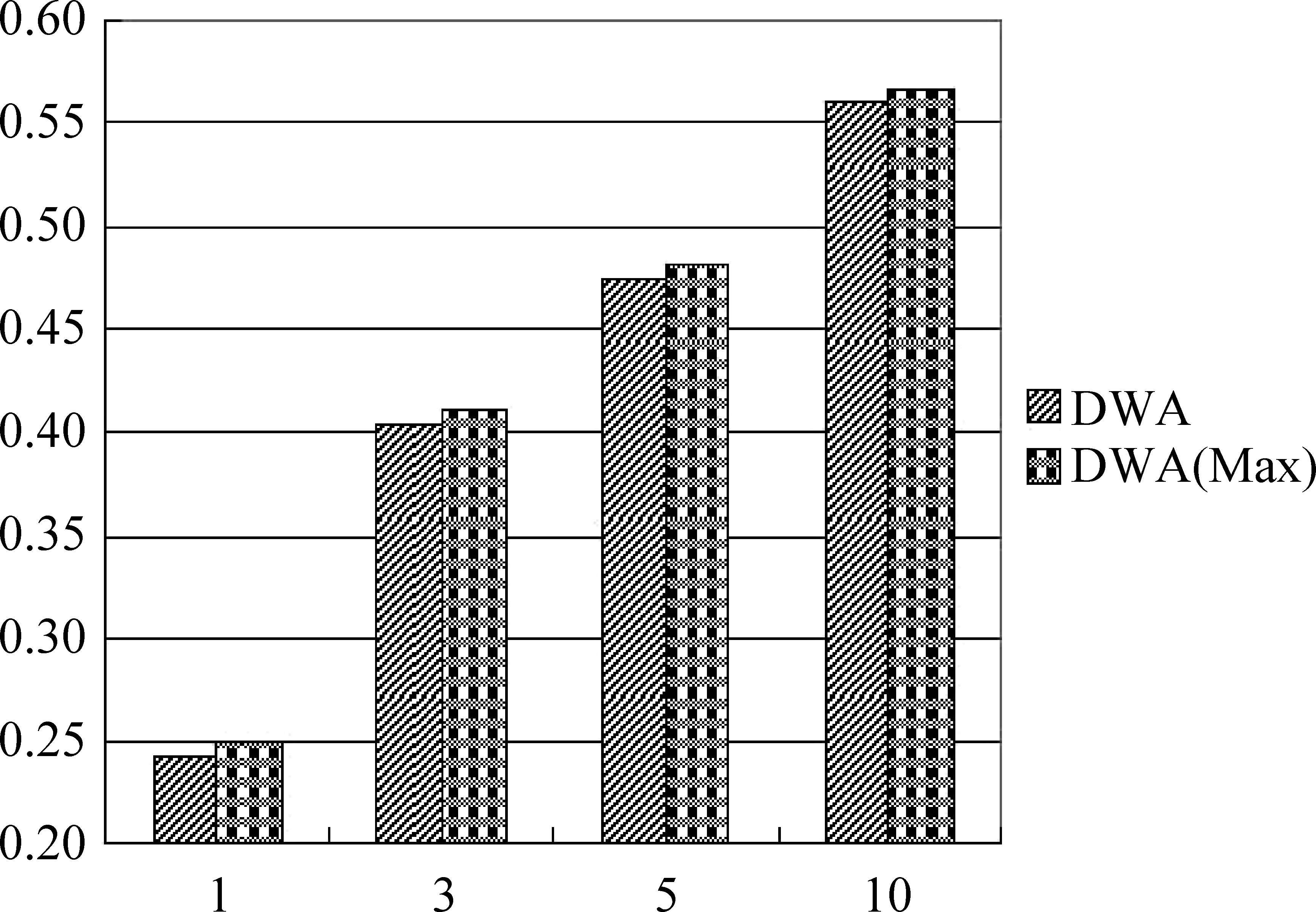
图5 不同词对齐关系下的预测正确率
4 总结和展望
本文提出一种动态词对齐的方法,在传统交互式机器翻译的基础上,将用户与翻译引擎交互后的词对齐信息加入到其后的预测模型中,减少了模型中的搜索空间,提高了模型的效率和预测准确率。为进一步分析模型的预测效果,加入了正确的词对齐结果,并对最后预测效果进行分析。从实验结果可以看出,词对齐信息对预测效果有一定的影响,而且本文的动态词对齐策略已经接近人工指定的效果,相对于传统方法正确率可提高4.01%。
下一步的研究工作的重点是优化调序模型,同时在模型中加入短语的预测,减少用户翻译句子时的选择操作,进一步提高模型的预测正确率,提升翻译的工作效率。
[1] Kay M.The proper place of men and machines in language translation[J].machine translation,1997,12(1-2): 3-23.
[2] Och F J, Zens R, Ney H. Efficient search for interactive statistical machine translation[C] //Proceedings of the 10 Conference on European Chapter of the Association for Computational Linguistics-Volume 1. Association for Computational Linguistics, 2003: 387-393.
[3] Foster G, Isabelle P, Plamondon P. Target-text mediated interactive machine translation[J]. Machine Translation, 1997, 12(1-2): 175-194.
[4] Och F J, Ney H.Discriminative training and maximum entropy models for statistical machine translation[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics.Association for Computational Linguistics,2002: 295-302.
[5] Simard M, Foster G. Pepr: Postedit propagation using phrase-based statistical machine translation[C]//Proceedings of the XIV Machine Translation Summit, 2013: 191-198.
[6] Foster G,Isabelle P,Plamondon P.Target-text mediated interactive machine translation[J].Machine Translation,1997,12(1-2): 175-194.
[7] Alabau V, Leiva L A, Ortiz-Martnez D, et al. User evaluation of interactive machine translation systems[C]//Proceedings of the 16th EAMT,2012: 20-23.
[8] González-Rubio J, Ortiz-Martínez D, Casacuberta F. On the use of confidence measures within an interactive-predictive machine translation system[C]//Proceedings of the 14th EAMT,2010.
[9] Sanchis-Trilles G, Ortiz-Martnez D, Casacuberta F. Efficient wordgraph pruning for interactive translation prediction[C]//Proceedings of the 188Annual Conference of the European Association for Machine Translation(EAMT),2014.
[10] Och F J, Ney H. Discriminative training and maximum entropy models for statistical machine translation[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2002: 295-302.
[11] Koehn P, Och F J, Marcu D. Statistical phrase-based translation[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1. Association for Computational Linguistics, 2003: 48-54.
[12] Arnold D. Why translation is difcult for computers[J]. Computers and Translation: A translator’s guide, Amsterdam and Philadelphia: John Benjamins, 2003: 119-42.
[13] Kay M. The proper place of men and machines in language translation[J]. machine translation, 1997, 12(1-2): 3-23.
[14] Alabau V,Leiva L A,Ortiz-Martinezz D,et al.User evaluation of interactive machine translation systems[C]//Proceedings of the 16th EAMT.2012: 20-23.
[15] Och F J, Ney H. Improved statistical alignment models[C]//Proceedings of the 38th Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2000: 440-447.
[16] Ortiz-Martnez D, Garca-Varea I, Casacuberta F. Interactive machine translation based on partial statistical phrase-based alignments[C]//Proceedings of the RANLP 2009,Borvet: ACl,2009: 330.
[17] Langlais P, Foster G, Lapalme G. TransType: a computer-aided translation typing system [C]//Proceedings of the 2000 NAACL-ANLP Workshop on Embedded machine translation systems-Volume 5. Association for Computational Linguistics, 2000: 46-51.
[18] 刘群. 基于句法的统计机器翻译模型与方法[J]. 中文信息学报, 2011, 25(6): 63-71.

马斌(1990—),硕士研究生,主要研究领域为自然语言处理,机器翻译。
E-mail: bin371502@163.com

蔡东风(1958—),博士,教授,主要研究领域为人工智能,自然语言处理。
E-mail: caidf @vip.163.com

季铎(1981—),硕士,副教授,主要研究领域为自然语言处理,机器翻译。
E-mail: 18640037173@163.com
Interactive Machine Translation by Dynamic Word Alignment
MA Bin, CAI Dongfeng, JI Duo, YE Na, WU Chuang
(Human-Computer Intelligence Research Center, Shenyang Aerospace University, Shenyang, Liaoning 110136, China)
1003-0077(2017)04-0044-06
TP391
A
